↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) primarily utilize the Transformer architecture, but recent research seeks more efficient and interpretable alternatives. This paper explores Auto-Regressive Decision Trees (ARDTs) for language modeling, a previously unexplored area. The limitations of existing LLMs include high computational cost and lack of transparency.
This research investigates the theoretical and practical power of ARDTs. Theoretically, it proves ARDTs can compute complex functions via “chain-of-thought” computations. Empirically, experiments show that ARDTs generate coherent text and achieve comparable performance to smaller Transformers in language generation and reasoning tasks. The findings suggest that ARDTs offer a unique approach with potential advantages in efficiency and interpretability for language model development.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces Auto-Regressive Decision Trees (ARDTs) for language modeling, offering a novel, interpretable, and potentially more efficient alternative to Transformers. Its theoretical analysis demonstrates ARDTs’ surprising computational power, opening new avenues for research in model architectures and interpretability. The empirical results show ARDTs’ capability in language generation and reasoning tasks, challenging the dominance of Transformers and prompting further investigation into tree-based models for various NLP tasks. This could lead to more efficient and transparent language models.
Visual Insights#
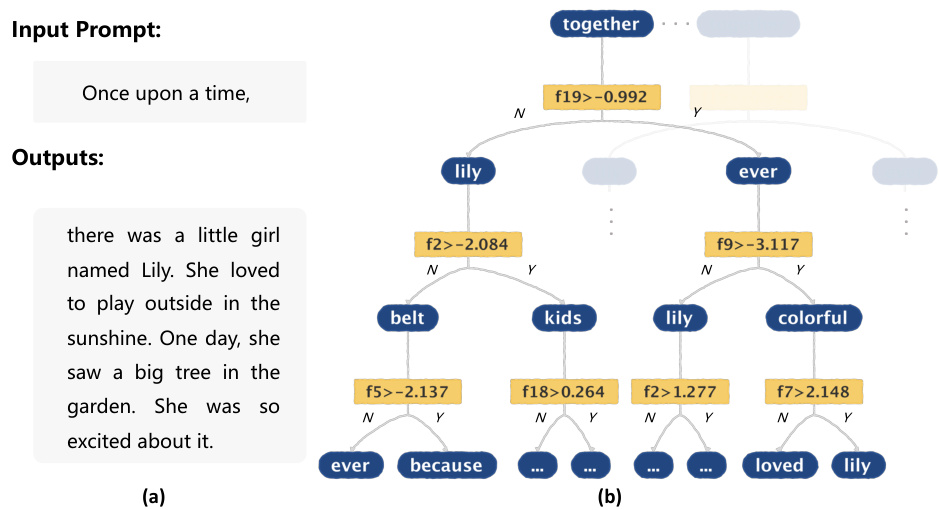
This figure shows an example of story continuation generated by Auto-Regressive Decision Trees (ARDTs). Part (a) displays a sample story continuation generated by the model, demonstrating its ability to produce fluent and coherent text comparable to Transformer models. Part (b) visualizes a portion of the ARDT’s decision-making process, illustrating how the model uses decision trees to determine the next word in the sequence based on word relevance.

This table presents a comparison of the performance of different language models, including Auto-Regressive Decision Trees (ARDTs), on the TinyStories dataset. The models are evaluated based on four metrics: grammar, creativity, consistency, and plot. The table shows parameter counts for each model and highlights the ARDT’s surprisingly strong performance relative to its size.
In-depth insights#
ARDT Theory#
The theoretical foundation of Auto-Regressive Decision Trees (ARDTs) for language modeling is explored. The core argument centers on demonstrating that ARDTs, unlike traditional decision trees, can compute significantly more complex functions. This is achieved by leveraging “chain-of-thought” computations, where intermediate steps are generated before arriving at the final prediction. The authors rigorously prove that ARDTs can simulate automata and Turing machines, highlighting their surprising computational capacity. Key theoretical results establish bounds on the size and depth of the ARDTs required to simulate these complex function classes, showing a significant efficiency advantage over direct computation using standard decision trees. Furthermore, the theoretical framework extends to the simulation of sparse circuits, further showcasing ARDTs’ power in modeling intricate relationships within sequential data. This theoretical analysis provides a strong foundation for the practical applications of ARDTs, showing their potential to be a powerful and interpretable alternative to traditional language models.
ARDT Exp.#
The heading ‘ARDT Exp.’ suggests an experimental section evaluating Auto-Regressive Decision Trees (ARDTs). A thoughtful analysis would expect this section to detail the experimental setup, including the datasets used (likely text corpora or time series data), the specific ARDT architecture implemented (e.g., tree depth, ensemble size), the training methodology (optimization algorithm, hyperparameters), and the evaluation metrics employed (e.g., perplexity, accuracy). Crucially, a strong ARDT Exp. section would compare ARDT performance against established baselines, such as standard Transformer models, to demonstrate its effectiveness and efficiency. The results should include quantitative measures showing the ARDT’s capabilities in tasks like text generation, sequence prediction, or other relevant applications. A key element would be an analysis of the ARDT’s interpretability, contrasting its explainability with the ‘black box’ nature of complex neural networks. Furthermore, the section should discuss any limitations or challenges encountered during experimentation, contributing to a comprehensive and rigorous evaluation of ARDTs.
Interpretability#
The section on ‘Interpretability’ highlights a crucial advantage of decision trees over complex neural networks: enhanced transparency. Unlike the opaque computations of neural networks, decision trees employ straightforward logic, making their decision-making process readily understandable. However, the paper acknowledges a challenge: using word embeddings complicates interpretability. Decision trees operate on aggregations of word vector embeddings, obscuring the direct semantic meaning of individual splitting rules. To address this, the authors employed a novel method to generate interpretable embeddings by mapping word vectors into a lower-dimensional space based on cluster centers, ultimately enabling the interpretation of splitting rules in terms of semantic similarity to specific words. This approach allows for a more intuitive understanding of the model’s decision-making process, bridging the gap between the inherent interpretability of decision trees and the use of complex word representations in natural language processing. The visualization of a decision tree using these methods demonstrates the effectiveness of this technique in making the decision-making process semantically meaningful. This approach represents a significant contribution to improving the interpretability of tree-based models in NLP.
Future Work#
Future research directions stemming from this paper on Auto-Regressive Decision Trees (ARDTs) for language modeling could explore several promising avenues. Extending the theoretical analysis to encompass more complex reasoning tasks and more sophisticated architectures would be valuable. Investigating different tree-based models and ensemble methods beyond XGBoost, like random forests or gradient boosting machines, could improve performance. Addressing the limitations of interpretability is crucial, potentially by developing novel visualization techniques or incorporating attention mechanisms for explainability. Exploring the potential of hybrid models that combine ARDTs with Transformers would likely improve performance and robustness. Finally, empirical evaluation on larger and more diverse datasets, such as those focusing on diverse languages or code generation tasks, would be essential to ascertain the broader applicability of ARDTs and establish benchmarks.
Limitations#
A thoughtful analysis of the limitations section in a research paper would explore several key aspects. Firstly, it’s crucial to assess whether the authors acknowledged the inherent limitations of their methodology, data, and scope. A thorough discussion should detail any simplifying assumptions made, potential biases in the dataset, and the generalizability of findings to other contexts. For instance, did the authors sufficiently discuss limitations imposed by the specific dataset used? Were there potential confounding factors that might skew results? Another critical area involves the computational constraints of the proposed approach. Were there limitations in the size or complexity of problems the model could effectively handle? Was the method computationally expensive or did it scale poorly with large datasets? This should be addressed in terms of runtime, memory usage, and algorithmic efficiency. Finally, a comprehensive limitations section will also address the interpretability or transparency of the methods. This is critical because, while a model might achieve high accuracy, its decision-making process might remain opaque, hindering its utility for certain applications. Addressing these points thoroughly demonstrates a level of intellectual honesty, promoting trust in the research findings and offering future research directions.
More visual insights#
More on figures

This figure shows an example of text generation using Autoregressive Decision Trees (ARDTs). Part (a) displays a story continuation generated by the ARDT model, demonstrating its ability to produce fluent and coherent text comparable to transformer-based models. Part (b) visualizes the decision-making process of the ARDT by showing a portion of the decision tree ensemble, highlighting how the model selects the most relevant words for its prediction based on the splitting rules.

This figure shows an example of story continuation generated by the proposed Autoregressive Decision Trees (ARDTs). The (a) part demonstrates the model’s ability to generate fluent and grammatically correct text comparable to Transformers. The (b) part visualizes a section of the ARDT’s decision-making process, highlighting the word selection at each node.
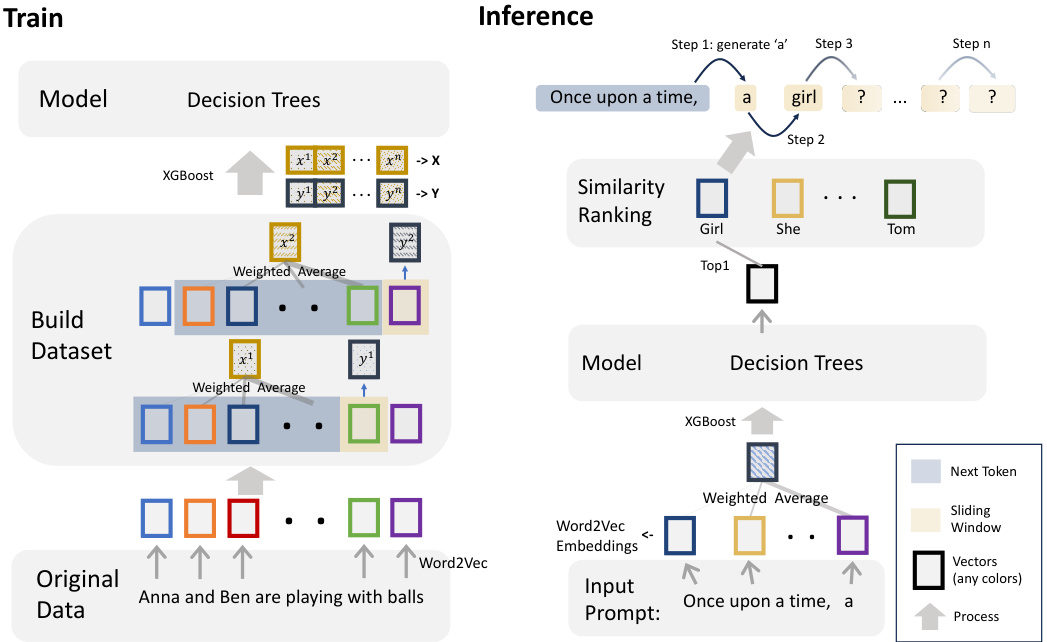
This figure illustrates the training and inference pipeline of the proposed Auto-Regressive Decision Trees (ARDTs) model. The training process involves using Word2Vec to generate word embeddings, employing a sliding window to create training data, calculating a weighted average of the embeddings within the window, and using the next token after the window as a label. This data is then used to train an ensemble of decision trees using XGBoost. The inference process uses the trained model to predict the next token in a sequence, given a current input sequence. It uses a weighted average of word embeddings and the trained decision trees to make its prediction, selecting the output with the highest similarity score.
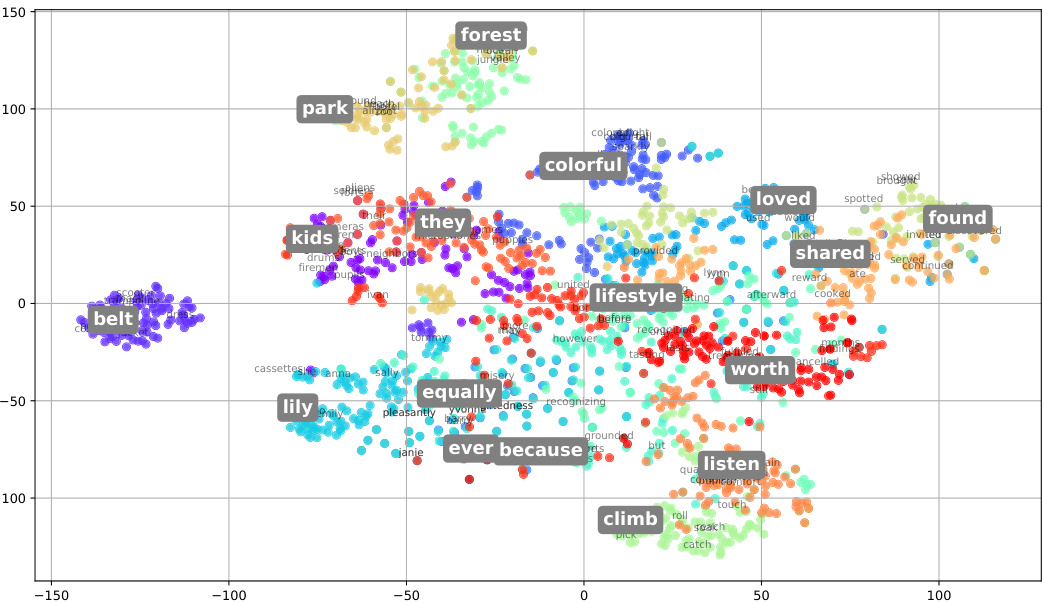
This figure shows a t-SNE visualization of 20 word clusters from the TinyStories dataset. The t-SNE algorithm reduces the dimensionality of the word embeddings, allowing for a 2D representation where semantically similar words cluster together. The visualization helps to illustrate the interpretability of the decision trees, as splitting rules can be interpreted in terms of semantic similarity to the words representing each cluster. Four words closest to each cluster center are displayed for better understanding.

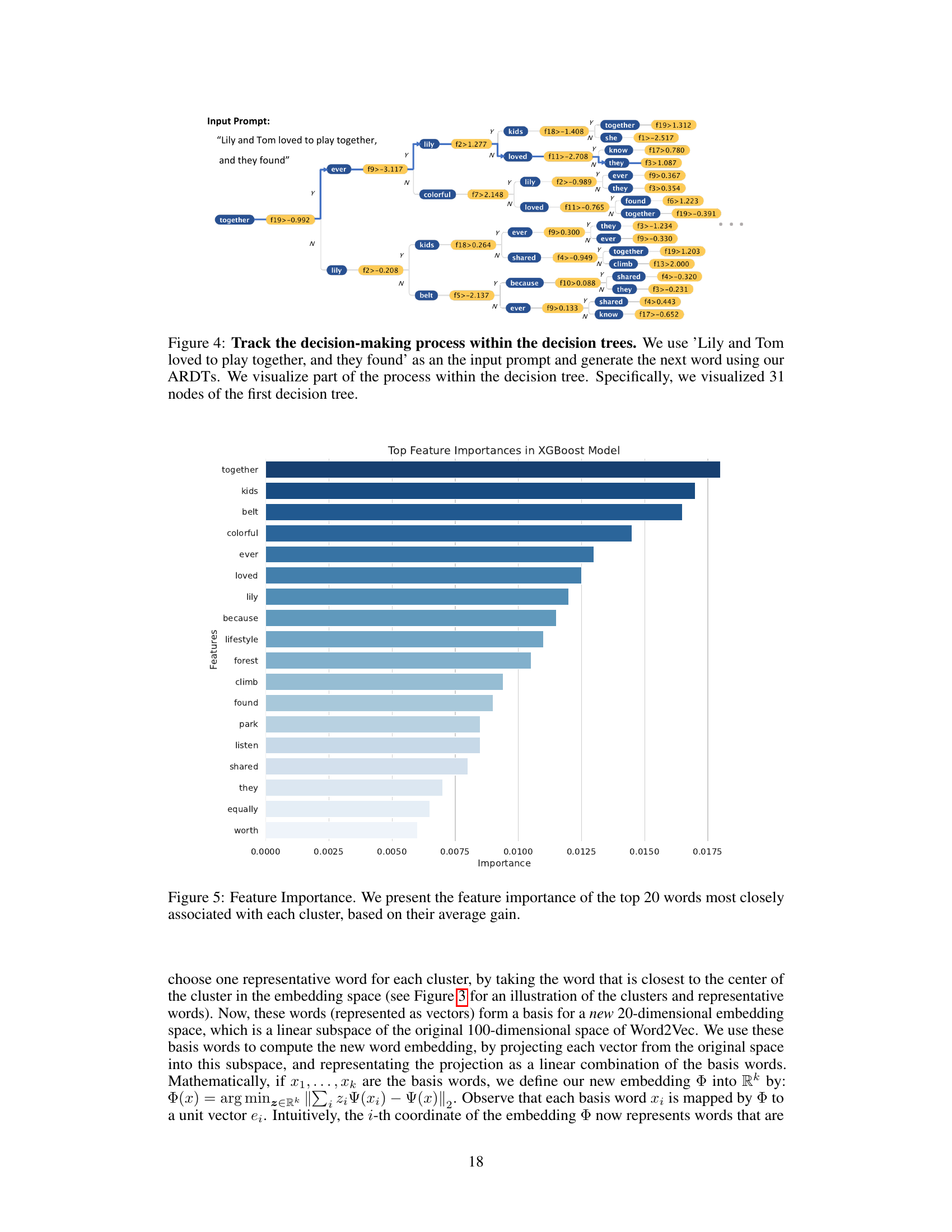
This figure visualizes a portion of the decision-making process within a single decision tree from an ensemble of Auto-Regressive Decision Trees (ARDTs). The input prompt is the sentence, ‘Lily and Tom loved to play together, and they found.’ The figure shows a section of the tree, highlighting the nodes and decision splits, with the associated feature values and their corresponding branch selections (Y/N). This illustrates how the ARDT determines the next word in a sequence. The visualization allows one to trace the path the model takes from the root node to a leaf node, which predicts the next word based on the input sequence.

This figure shows the feature importance of the top 20 words in an XGBoost model, ranked by their average gain. The words represent clusters of semantically similar words, and their importance reflects how much they contribute to the model’s ability to make accurate predictions. Words higher on the chart are more important to the model’s decision-making process.
More on tables

This table compares the performance of different language models, including an autoregressive decision tree (ARDT), on the TinyStories dataset. The models are evaluated on four metrics: grammar, creativity, consistency, and plot. The table shows that the ARDT achieves performance comparable to more complex models such as GPT-4 and TinyStories-33M, despite having significantly fewer parameters.
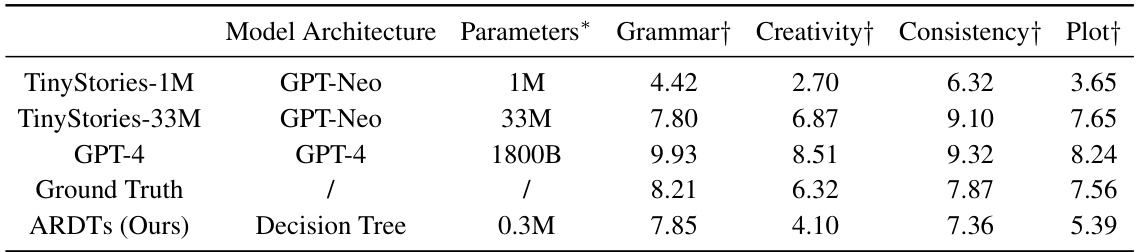
This table presents the quantitative results of story generation experiments using various models, including the proposed ARDTs model and several baselines such as TinyStories-1M, TinyStories-33M, and GPT-4. The models are evaluated using four metrics: Grammar, Creativity, Consistency, and Plot. Higher scores indicate better performance. The ARDTs model, despite having significantly fewer parameters than the GPT-4 and even the larger TinyStories-33M, achieves competitive performance, highlighting its efficiency.
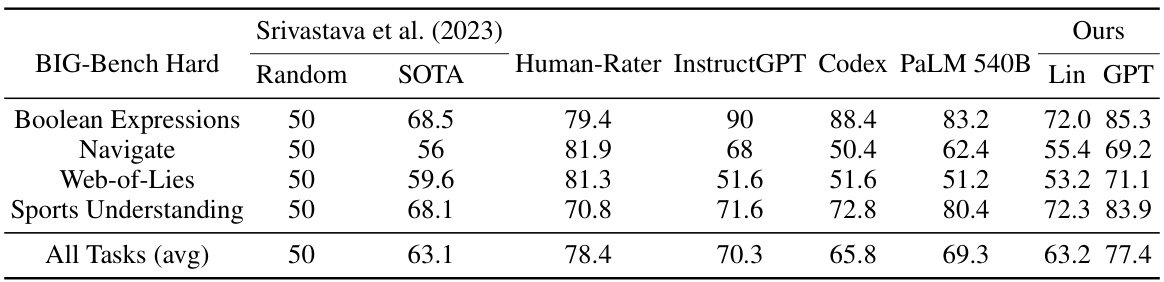
This table presents the performance of ARDTs (Auto-Regressive Decision Trees) on the BIG-Bench Hard dataset, a benchmark for challenging logical reasoning tasks. It compares the ARDT’s performance using both linear embeddings and GPT-2 embeddings against several strong baselines: Human raters, InstructGPT, Codex, and PaLM 540B. The results show how ARDTs, despite their simpler architecture, achieve competitive performance on various tasks, indicating their potential for handling complex reasoning problems.

This table presents a summary of the TinyStories dataset, providing key statistics for both the training and validation sets. Specifically, it shows the number of stories, the total number of tokens, the range of word counts per story, and the size of the vocabulary (unique words) in each set. These statistics are useful for understanding the scale and characteristics of the dataset used to train and evaluate the autoregressive decision tree (ARDT) language model described in the paper.

This table compares the performance of different language models on the TinyStories dataset, focusing on metrics such as grammar, creativity, consistency, and plot. The models compared include two small Transformers (TinyStories-1M and TinyStories-33M), GPT-4, and the authors’ proposed Auto-Regressive Decision Trees (ARDTs). The table highlights that the ARDTs, despite having fewer parameters than the small transformer models, achieve comparable or even better performance in several aspects.

This table presents a comparison of the performance of different language models, including an Auto-Regressive Decision Tree (ARDT) model, on the TinyStories dataset. The models are evaluated on four metrics: grammar, creativity, consistency, and plot. The ARDT model achieves comparable performance to larger, more complex models like GPT-4 and TinyStories-33M, demonstrating the potential of ARDTs for language generation tasks.

This table presents a comparison of the performance of various language models, including the proposed Auto-Regressive Decision Trees (ARDTs), on the TinyStories dataset. The models are evaluated on four metrics: grammar, creativity, consistency, and plot. The table shows parameter counts for each model to help assess the efficiency of the ARDT approach. Note that the ARDT model outperforms a smaller transformer model (TinyStories-1M) despite having fewer parameters.

This table presents a comparison of the performance of different language models, including the proposed Auto-Regressive Decision Trees (ARDTs), on the TinyStories dataset. The models are evaluated based on four metrics: grammar, creativity, consistency, and plot. The table shows that the ARDTs achieve comparable performance to larger, more complex models like GPT-4 and TinyStories-33M, despite having significantly fewer parameters. This demonstrates the effectiveness of the ARDT approach for language generation tasks.
Full paper#