TL;DR#
Training many agents to coordinate efficiently in large-scale multi-agent systems (MAS) is extremely challenging due to the exponential growth of agent interactions and the curse of dimensionality. Existing methods struggle with learning efficient coordination from scratch. Furthermore, they often rely on high-quality, comprehensive human demonstrations, which are time-consuming and difficult to obtain, particularly for complex tasks.
This paper introduces a novel knowledge-guided MARL framework (hhk-MARL) to overcome these limitations. hhk-MARL combines human abstract knowledge with hierarchical reinforcement learning. It uses fuzzy logic to represent suboptimal human knowledge and allows agents to freely adjust how much they rely on this prior knowledge. A graph-based group controller further enhances agent coordination. Experiments show that hhk-MARL significantly accelerates the training process and improves final performance even when using low-quality human prior knowledge, showcasing its effectiveness in handling challenging large-scale MAS scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the scalability challenges in multi-agent reinforcement learning (MARL), a critical issue hindering the application of MARL in complex, real-world scenarios. By integrating suboptimal human knowledge effectively, it significantly improves both learning speed and final performance, opening exciting new avenues for research in knowledge-guided MARL and hierarchical learning methods. The end-to-end framework’s compatibility with various existing MARL algorithms further enhances its practical significance and broad applicability.
Visual Insights#

🔼 This figure illustrates the hierarchical control in daily human activities. The prefrontal cortex (top level) generates high-level commands (e.g., ‘get up and walk’). These commands are then executed by a lower-level neural network, Central Pattern Generators (CPGs), in the spinal cord which controls the intricate muscle coordination without conscious attention. This reflects how humans can abstract and provide high-level knowledge while lower-level details are handled automatically.
read the caption
Figure 1: Human daily hierarchical control.
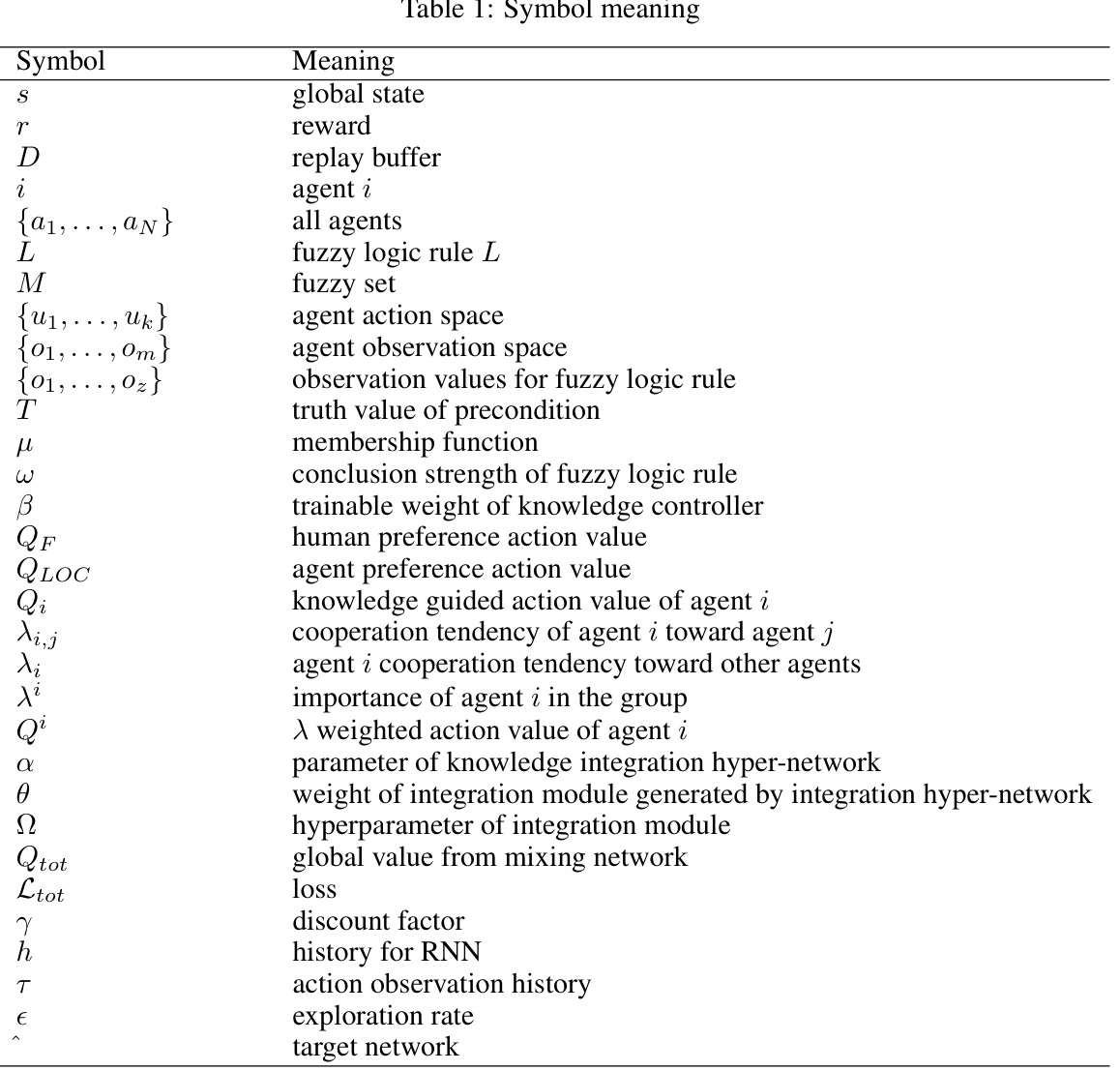
🔼 This table lists the symbols used in the paper and their corresponding meanings. It serves as a glossary for the various mathematical notations and abbreviations used throughout the paper, particularly within the algorithms and equations.
read the caption
Table 1: Symbol meaning
In-depth insights#
Suboptimal Knowledge#
The concept of “Suboptimal Knowledge” in multi-agent reinforcement learning (MARL) is crucial because perfect, comprehensive knowledge is often unavailable or impractical to obtain in complex, large-scale systems. Human expertise, while valuable, is frequently suboptimal, incomplete, or expressed at an abstract level. The paper cleverly addresses this by proposing a framework where agents can leverage such imperfect human input effectively. This approach is superior to methods relying on perfect demonstrations, as it acknowledges the reality of human expertise and its limitations. The integration of fuzzy logic enables the system to handle the uncertainty and imprecision inherent in human knowledge. By allowing agents to freely choose the level of reliance on this knowledge, the system is both robust and adaptable. This strategy is particularly beneficial in large-scale settings where complete knowledge is computationally infeasible, making the approach efficient and scalable.
Hierarchical MARL#
Hierarchical Multi-Agent Reinforcement Learning (MARL) addresses the complexity of large-scale multi-agent systems by decomposing the overall task into a hierarchy of subtasks. This approach offers several key advantages. Improved scalability: By breaking down the problem, the state and action spaces become more manageable, mitigating the curse of dimensionality that plagues traditional MARL methods. Enhanced efficiency: Agents can focus on learning simpler, localized policies within their respective subtasks, speeding up the learning process and reducing the amount of data required. Better coordination: The hierarchical structure promotes more structured and efficient coordination between agents. Higher-level agents can guide the behavior of lower-level agents, leading to more effective collective actions. Improved generalization: Hierarchical MARL tends to be more robust, adapting to unseen situations more effectively. However, challenges remain. Hierarchical design: Designing an effective hierarchy requires careful consideration of the problem’s structure and the agents’ roles and capabilities. Credit assignment: Determining how rewards should be distributed across levels of the hierarchy is crucial and often a complex problem. Communication: Effective communication between agents at different levels is essential for smooth cooperation but can be challenging to implement. Despite these hurdles, hierarchical MARL represents a promising area of research for addressing scalability and coordination issues in complex multi-agent environments.
Fuzzy Logic Rules#
The application of fuzzy logic rules in multi-agent reinforcement learning (MARL) offers a powerful mechanism for integrating human knowledge, particularly valuable in scenarios with high dimensionality and sparse rewards. Fuzzy logic’s ability to handle uncertainty and imprecision makes it well-suited for representing the often-suboptimal but insightful knowledge humans possess. The rules themselves serve as a bridge between abstract human understanding and the precise actions required within the MARL framework. Trainable weights associated with these rules add an adaptive layer, allowing the system to refine the human-provided knowledge based on its experience within the environment. This dynamic adaptation is crucial because human knowledge might not be perfectly applicable in all situations. However, a challenge lies in designing effective fuzzy logic rules that are both descriptive enough to capture meaningful insights and concise enough to avoid overly complex rule sets. The balance between detail and efficiency will significantly impact both learning speed and overall performance of the system. Successfully addressing this challenge is key to unlocking the full potential of integrating human expertise into complex MARL systems.
Scalability in MAS#
Scalability in multi-agent systems (MAS) is a crucial challenge, as the complexity grows exponentially with the number of agents. The curse of dimensionality, stemming from the expanding joint action-state space, significantly impacts learning efficiency and performance. Sparse rewards and sample inefficiency further exacerbate this problem, often leading to agents getting trapped in local optima or failing to learn effective coordination strategies. Addressing these issues requires innovative approaches. Hierarchical structures, inspired by human cognition, enable efficient control and knowledge transfer by decomposing complex tasks into manageable subtasks. Graphical models facilitate scalability by simplifying agent interactions, reducing complexity, and improving coordination. Knowledge transfer techniques prove vital, transferring human expertise or learning from existing policies to accelerate the learning process, overcome sparse rewards, and improve overall system performance. However, relying on optimal human knowledge might be unrealistic and transferring suboptimal knowledge warrants careful consideration, hence methods like fuzzy logic for handling uncertainty become necessary. Ultimately, effective solutions balance the inherent challenges of scaling MAS with innovative architectures and knowledge integration approaches.
Future Research#
The paper’s ‘Future Research’ section could explore several promising avenues. Extending the framework to heterogeneous agents is crucial, moving beyond the homogeneous agent assumption. This requires investigating how diverse agent capabilities and knowledge representations can be effectively integrated into the hierarchical framework. Addressing the scalability issue further is also vital; while the current work shows promising results, rigorously evaluating performance with significantly larger numbers of agents is essential. Moreover, exploring different types of human prior knowledge (e.g., strategic advice, high-level goals instead of low-level rules) and their integration would enhance the framework’s flexibility. Finally, formal theoretical analysis of the algorithm’s convergence properties and sample complexity should be explored to strengthen the theoretical underpinnings and potentially identify ways to further improve efficiency. Investigating different MARL algorithms beyond the tested ones would reveal the framework’s general applicability and robustness.
More visual insights#
More on figures
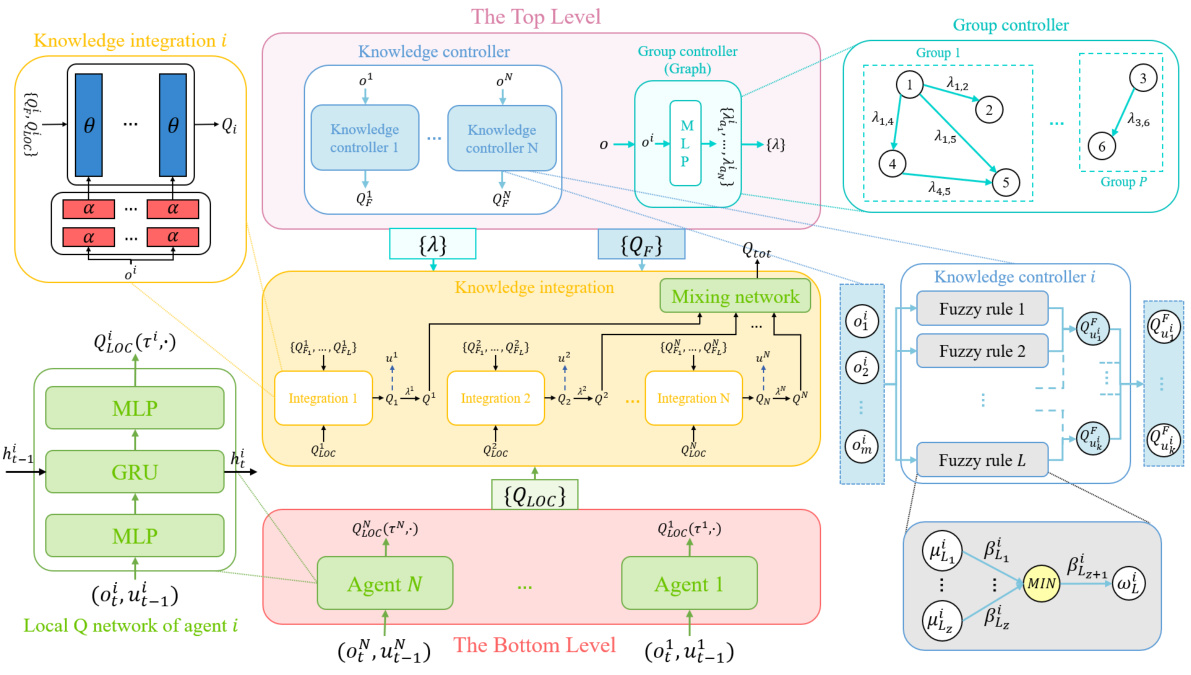
🔼 This figure presents the overall framework of the proposed Hierarchical Human Knowledge-guided Multi-Agent Reinforcement Learning (hhk-MARL) method. It shows how three main components, namely the knowledge controller, group controller, and knowledge integration, work together to improve the learning efficiency of MARL agents. The hierarchical structure of the framework is also depicted, which consists of a top level knowledge controller that provides high-level knowledge, a bottom level local agent networks that learn individual policies, and a middle level knowledge integration that combines these two levels effectively.
read the caption
Figure 2: The overall framework of the human knowledge guided hierarchical MARL. The general architecture is proposed in the middle which is separated into three levels. Agents can develop their own policies with traditional MARL algorithm shown at bottom left. The graph-based group controller is depicted at top right to enhance agents' coordination. The knowledge controller is comprised with fuzzy logic rules to represent human knowledge which is demonstrated at bottom right. The hyper-networks of knowledge integration is illustrated at top left to allow agents freely decide the use of proposed human knowledge.
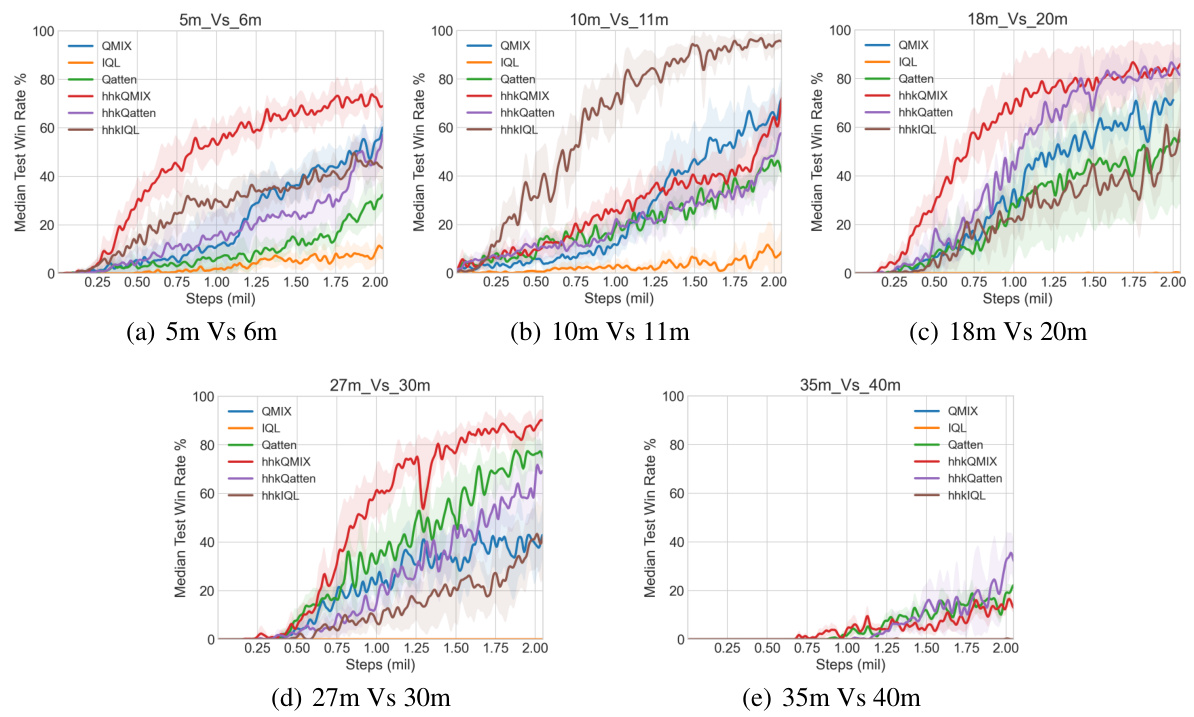
🔼 This figure presents the experimental results comparing the performance of the proposed Hhk-MARL framework with three different MARL algorithms (IQL, QMIX, Qatten) against their baselines across five different scenarios in the StarCraft Multi-Agent Challenge (SMAC) environment. Each scenario involves a varying number of agents (5 vs 6, 10 vs 11, 18 vs 20, 27 vs 30, and 35 vs 40). The x-axis represents the number of training steps (in millions), and the y-axis represents the median test win rate (%). The shaded area around each line indicates the standard deviation across three independent trials. The results show that the Hhk-MARL framework, even with suboptimal human prior knowledge, consistently improves the performance and training speed compared to the baseline MARL algorithms.
read the caption
Figure 4: Experimental results for our approaches and their corresponding baselines in five scenarios. The shaded region denotes standard deviation of average evaluation over 3 trials.

🔼 This figure shows a membership function graph for a fuzzy logic rule. The x-axis represents the observed distance to the nearest enemy (e_d), and the y-axis represents the degree to which the condition ’e_d is small’ is satisfied. The graph illustrates how the fuzzy set ‘small’ maps the distance values to a degree of membership between 0 and 1. This function determines the weight assigned to the rule ‘If the enemy is close, attack’ in the knowledge controller.
read the caption
Figure 3: Membership function: 'e_d is small'. X-axis denotes the observation value for variable e_d and Y-axis denotes the truth value.

🔼 This figure compares the performance of three baseline multi-agent reinforcement learning (MARL) algorithms (IQL, QMIX, Qatten) with their corresponding versions enhanced by the proposed hierarchical human knowledge-guided MARL framework (hhk-MARL). The median test win rates are shown across five scenarios with varying numbers of agents (5, 10, 18, 27, 35). Error bars represent standard deviation, indicating variability in performance. The figure demonstrates that the hhk-MARL framework consistently improves performance across all algorithms and varying agent counts, highlighting its scalability and effectiveness.
read the caption
Figure 5: Performance comparison between baselines and our methods under the number of agents increase. The error bar is based on standard deviation
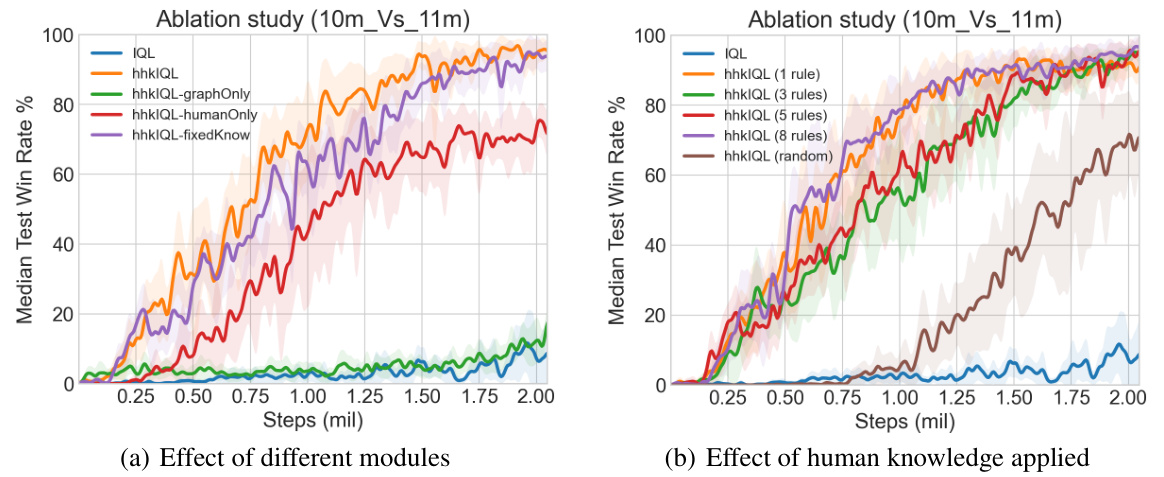
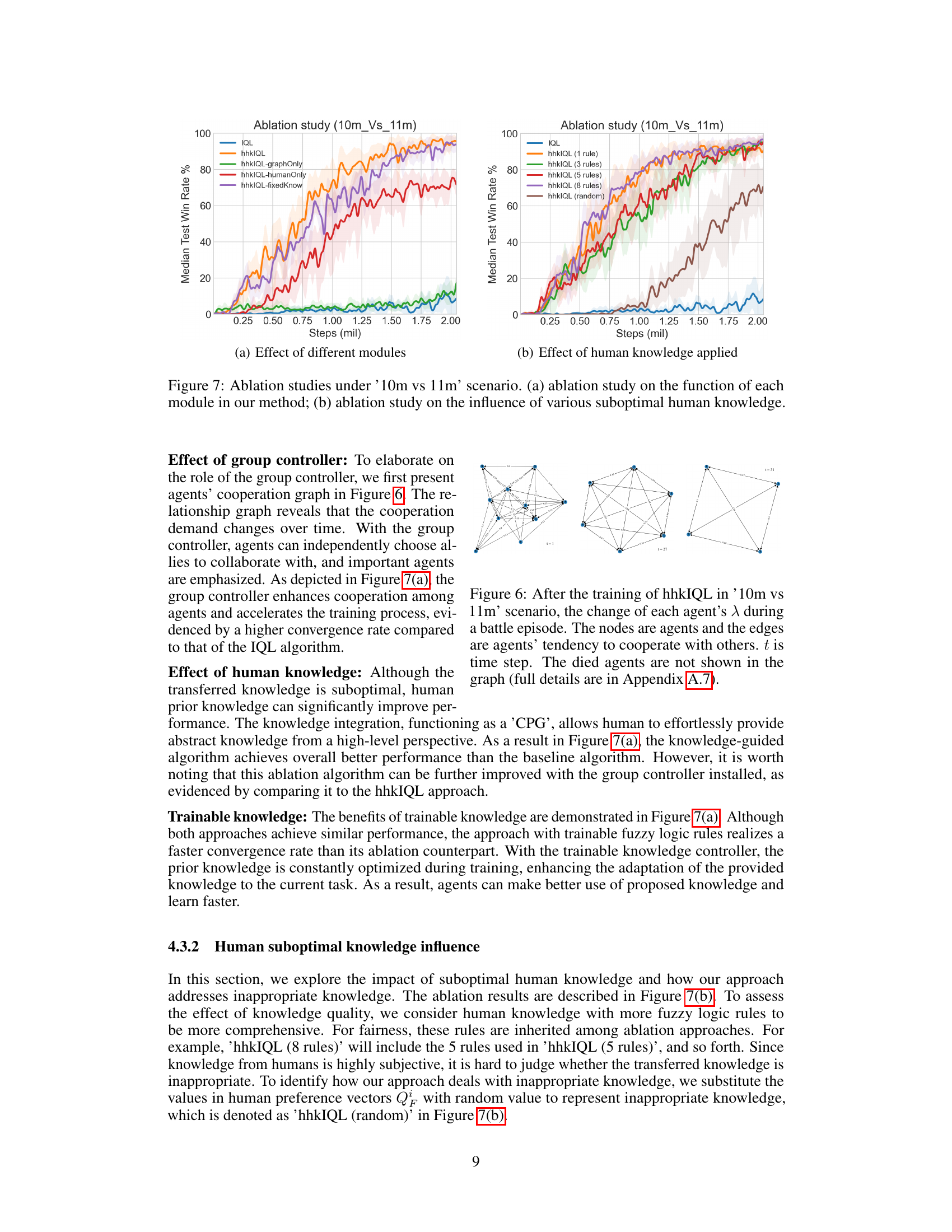
🔼 This figure presents the results of ablation studies conducted on the proposed ‘human knowledge guided hierarchical MARL’ framework. Panel (a) shows the impact of removing individual components of the framework (group controller, human knowledge, and trainable weights) on the learning performance. Panel (b) illustrates how different amounts and qualities of human knowledge affect the learning process, comparing results using 1, 3, 5, and 8 fuzzy logic rules, as well as random knowledge. The figure helps understand the contribution of each component of the framework and how robustness to noisy human input is achieved.
read the caption
Figure 7: Ablation studies under '10m vs 11m' scenario. (a) ablation study on the function of each module in our method; (b) ablation study on the influence of various suboptimal human knowledge.
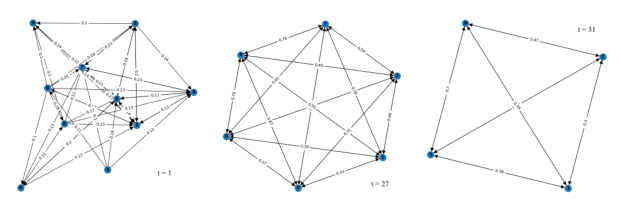
🔼 This figure shows the dynamic cooperation graph generated by the group controller in the hhkIQL algorithm during a single episode of the ‘10m vs 11m’ scenario in the StarCraft Multi-Agent Challenge (SMAC). Each node represents an agent, and the edges represent the cooperation tendency between agents. The weights on the edges (λi,j values) indicate the strength of the cooperative tendency. The figure visualizes how the cooperation relationships between agents evolve over time during the battle. The graph changes dynamically as agents interact and their observations change.
read the caption
Figure 9: The cooperation graph from hhkIQL during one battle episode based on the change of each agent's λ under '10m vs 11m' scenario.

🔼 This figure shows the membership functions used for the fuzzy logic rules in the StarCraft Multi-Agent Challenge (SMAC) environment. Each subplot displays the membership function for a specific fuzzy set used as a precondition in the fuzzy rules. These functions map observation values to degrees of membership, indicating the extent to which a particular observation satisfies a specific linguistic term, such as ‘small’, ’large’, etc. These functions are essential for determining the truth value of fuzzy logic rule preconditions and calculating the action taken by an agent.
read the caption
Figure 8: Membership functions used in SMAC.
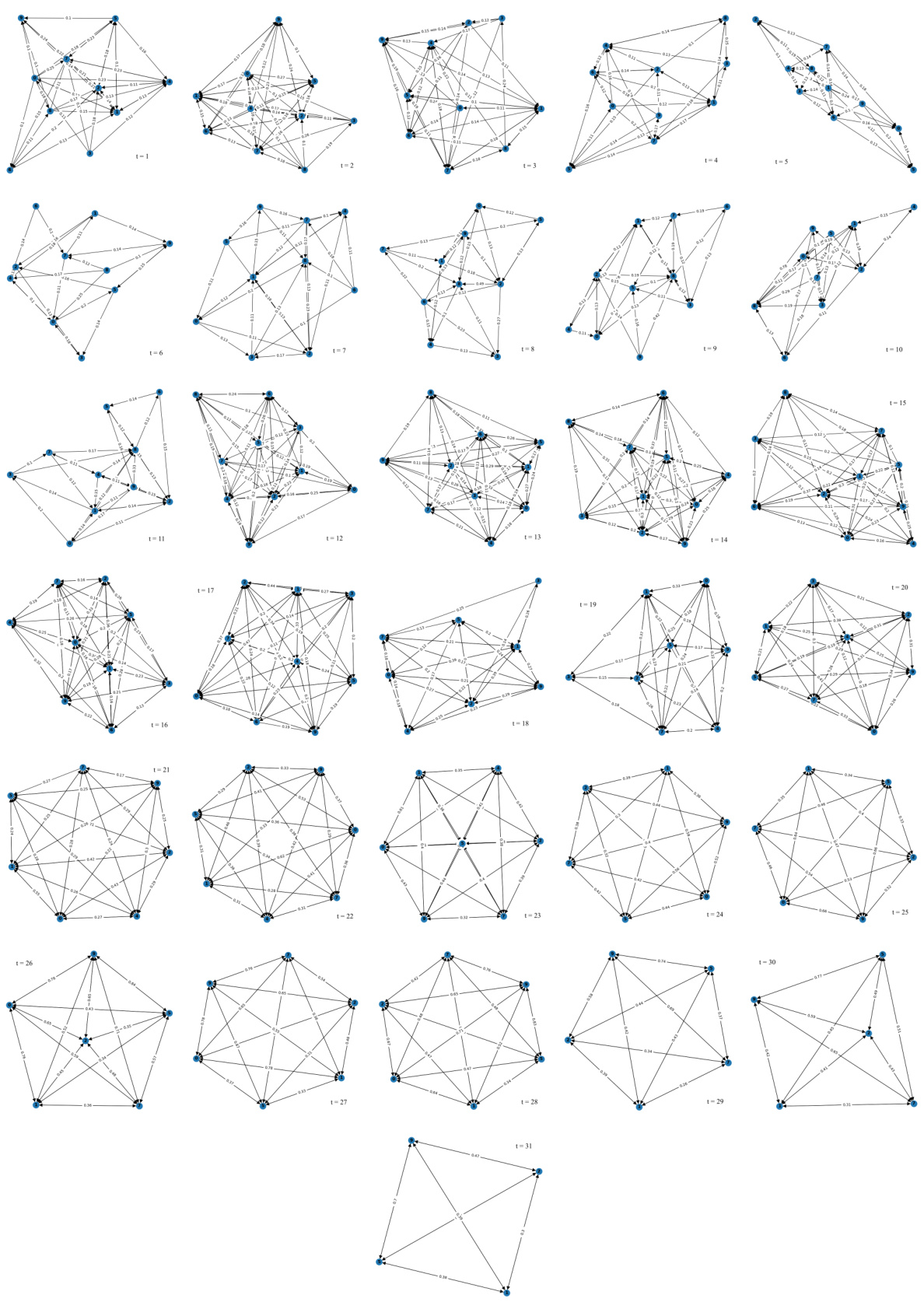
🔼 This figure shows the dynamic cooperation graph generated by the group controller module of the hhkIQL algorithm during a single episode of the 10m vs 11m scenario in the StarCraft Multi-Agent Challenge (SMAC). Each node represents an agent, and the edges represent the cooperation tendency between agents, calculated based on local observations. The graph illustrates how agent collaborations evolve over time within a single episode. The thickness or presence of an edge suggests the strength of the cooperative relationship between the two agents.
read the caption
Figure 9: The cooperation graph from hhkIQL during one battle episode based on the change of each agent's λi under '10m vs 11m' scenario.
Full paper#