TL;DR#
Large Language Models (LLMs) often suffer from issues like hallucination and a lack of source attribution for their generated text. Existing semi-parametric models like kNN-LM try to solve these problems by using nearest neighbor matches in a data store, but they are slow and create less fluent outputs. This research introduces a new problem and solution.
The proposed solution, Nearest Neighbor Speculative Decoding (NEST), improves upon these existing methods. It uses a two-stage retrieval process to find relevant information, incorporates it into the model’s generation process in a dynamic and flexible way, and uses a ‘relaxed speculative decoding’ technique to improve fluency and speed. NEST demonstrates significant enhancements in generation quality and attribution rate, outperforming kNN-LM and showing competitive performance against the common method of in-context retrieval augmentation. The model achieves a substantial 1.8x speedup in inference time when tested on Llama-2-Chat 70B.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) because it directly addresses the persistent issues of hallucination and lack of source attribution. By introducing NEST, a novel semi-parametric method, the research offers a significant advancement in enhancing LLM generation quality, providing accurate source attribution, and improving inference speed. This work opens exciting avenues for future research in developing more reliable and efficient LLMs capable of handling knowledge-intensive tasks. The improved speed is particularly important as it allows for the deployment of larger, more capable models in real-world applications.
Visual Insights#
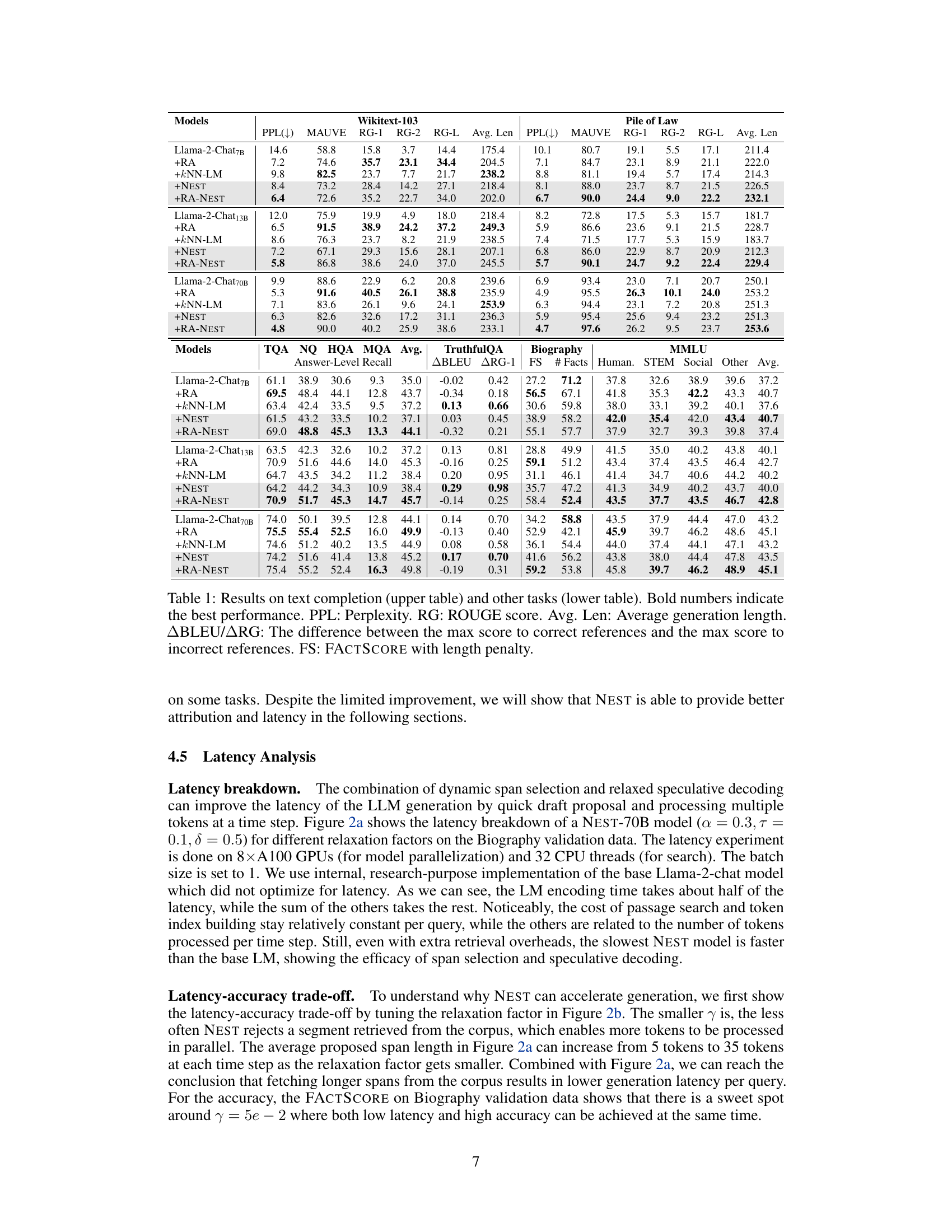
🔼 This figure illustrates the three main steps of the NEST approach: First, it uses the language model’s hidden states to locate relevant tokens within a corpus. Second, it dynamically interpolates the retrieved token distribution with the language model’s distribution based on retrieval confidence. Third, it selects a token and its continuation (span) using a speculative decoding method, which helps to ensure fluency and avoid hallucinations. The final output incorporates spans from the corpus which provides source attribution for generated text, improving both accuracy and efficiency. The figure also shows the amortized generation latency, highlighting the efficiency gains offered by NEST.
read the caption
Figure 1: The NEST approach first locates the tokens in the corpus using the LM hidden states. The retrieval distribution Pk-NN is dynamically interpolated with PLM based on the retriever's uncertainty λt. The token and its n-gram continuation are then selected from the mixture distribution Pм, while the final span length is determined by speculative decoding to remove undesired tokens. The spans incorporated in the final generation provide direct attribution and amortize the generation latency.
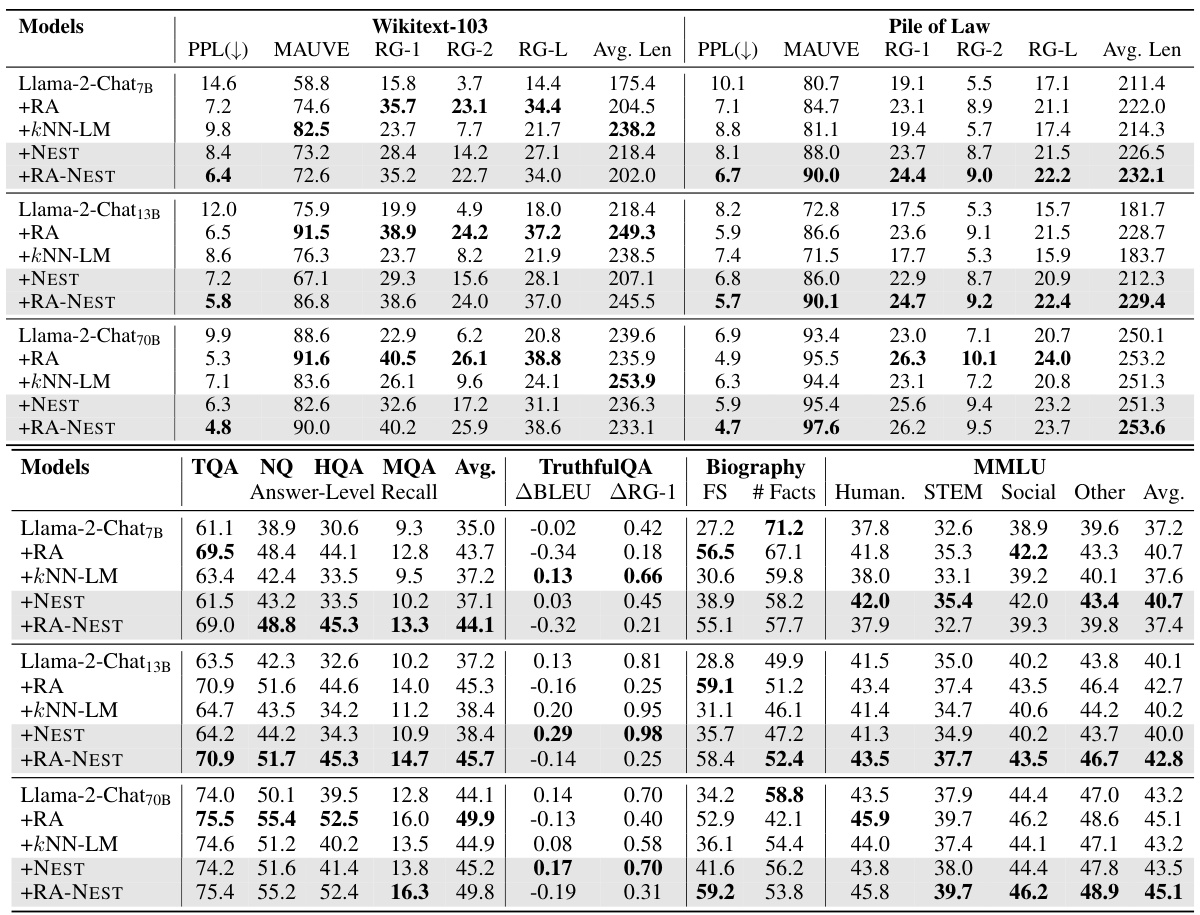
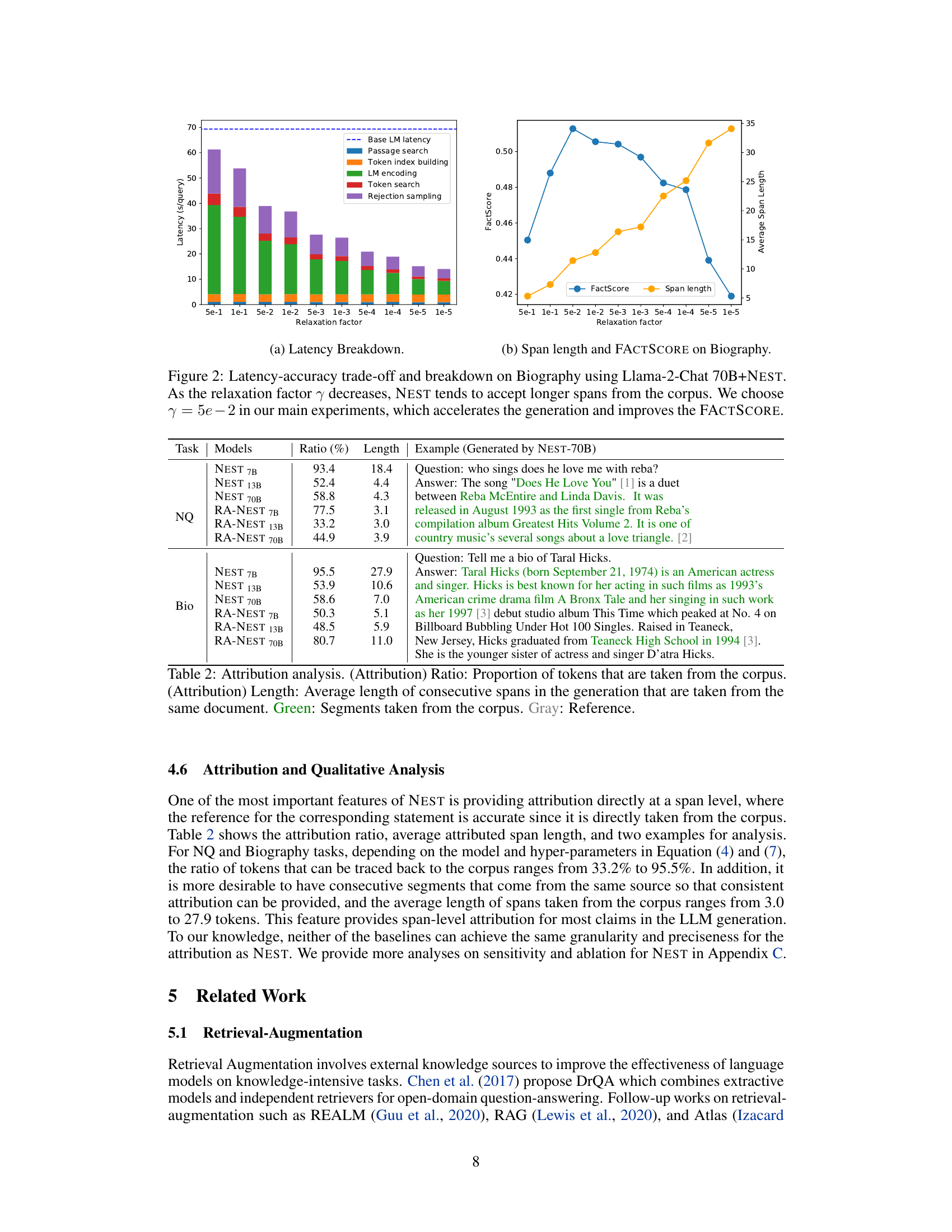
🔼 This table presents the quantitative results of the proposed NEST model and several baseline models on various downstream tasks. The upper half shows results for text completion tasks (WikiText-103 and Pile of Law), evaluating metrics like perplexity, ROUGE scores, and average length. The lower half shows results for question answering (TQA, NQ, HQA, MQA), fact verification (TruthfulQA, Biography), and multi-task learning (MMLU), reporting metrics like answer-level recall, BLEU, ROUGE, FACTSCORE, and accuracy. The results are presented for different sizes of the Llama-2-Chat language model (7B, 13B, and 70B) with and without retrieval augmentation (RA), kNN-LM, NEST, and a combination of RA and NEST. The bold numbers indicate the best-performing model for each metric.
read the caption
Table 1: Results on text completion (upper table) and other tasks (lower table). Bold numbers indicate the best performance. PPL: Perplexity. RG: ROUGE score. Avg. Len: Average generation length. ABLEU/ARG: The difference between the max score to correct references and the max score to incorrect references. FS: FACTSCORE with length penalty.
In-depth insights#
NEST: Core Idea#
The core idea behind NEST (Nearest Neighbor Speculative Decoding) is to enhance Large Language Model (LLM) generation and attribution by cleverly integrating a corpus of real-world text. NEST addresses LLMs’ tendency to hallucinate and lack source attribution by performing token-level retrieval at each generation step. This retrieval isn’t a simple prepending of retrieved context; instead, NEST computes a mixture distribution combining the LLM’s own predictions with probabilities derived from nearest neighbor spans in the corpus. This mixture informs a novel speculative decoding process, allowing NEST to either continue with a retrieved span or generate a new token based on likelihood. The dynamic span selection mechanism allows for the incorporation of longer, relevant text segments, improving fluency and factuality. Confidence-based interpolation helps NEST adapt to different tasks, gracefully incorporating retrieved information as needed. This approach achieves a superior balance between generation quality, attribution rate, and inference speed compared to existing methods like kNN-LM.
Two-Stage Search#
The concept of a ‘Two-Stage Search’ in the context of information retrieval within a large language model (LLM) suggests a significant advancement in efficiency and accuracy. The first stage likely focuses on broad, semantic retrieval, identifying relevant passages or documents using techniques like dense or sparse retrieval methods. This initial filtering step reduces the search space drastically, preventing computationally expensive searches through the entire corpus. The second stage then performs a fine-grained, lexical search within the narrowed set of retrieved documents. This could involve techniques like k-NN search on token embeddings to identify specific textual spans that best match the query’s lexical and semantic needs. This two-stage approach offers a compelling balance between recall (finding relevant information) and precision (avoiding irrelevant information), a crucial consideration for LLMs where the search speed is often a major bottleneck. The approach also likely helps mitigate the risk of retrieving semantically similar but contextually inappropriate information, improving the overall quality and relevance of the LLM’s output.
Span Selection#
The concept of span selection within the context of large language models (LLMs) is crucial for improving the quality and efficiency of text generation. Span selection aims to intelligently choose segments of text, or spans, from a retrieved corpus to incorporate into the LLM’s output. This offers a significant advantage over simply selecting individual tokens, as it allows for the preservation of contextual information and fluency. Effective span selection mechanisms must weigh the confidence of the retrieval system against the likelihood of generating a fluent and coherent continuation. This may involve incorporating confidence scores, as seen in the Relative Retrieval Confidence (RRC) score, to determine the appropriate level of interpolation between the LLM’s predictions and the retrieved spans. A critical aspect is balancing the length of the selected spans. Too short, and the benefits of contextual information are diminished; too long, and the risk of generating irrelevant or hallucinated text increases. Techniques such as speculative decoding can help to refine the selected span by evaluating the likelihood of different span prefixes, and rejecting unlikely continuations. The goal is to create a system that leverages real-world text effectively to boost LLM performance, while avoiding the pitfalls of slower inference speeds and non-fluent outputs.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a language model, this might involve removing specific modules or techniques like the relative retrieval confidence score, dynamic span selection, or relaxed speculative decoding to understand their impact on the overall performance metrics (ROUGE-1, Answer-Level Recall, FACTSCORE). The results help determine which parts are most crucial for the model’s effectiveness, improving future designs by focusing on the most important components and streamlining less critical ones. A significant drop in performance after removing a module highlights its importance, indicating a need to refine or retain it. Conversely, a minimal change shows that the module can be potentially simplified or removed to optimize efficiency without significant loss. Ultimately, ablation studies reveal a deeper understanding of model architectures and are essential in guiding iterative improvements.
Limitations#
A critical analysis of the ‘Limitations’ section of a research paper would delve into the methodological constraints, exploring whether the study design adequately addressed potential biases or confounding factors. It would assess the generalizability of the findings, questioning whether the sample size and characteristics were representative enough to draw broader conclusions. Specific attention would be paid to the scope of the analysis, identifying whether any aspects of the problem were overlooked or simplified, leading to a potentially incomplete understanding. The discussion should also evaluate the feasibility and practical limitations associated with implementing the proposed approach in real-world settings. This section is crucial to show self-awareness regarding the boundaries of the research and to highlight avenues for future investigation. A strong ‘Limitations’ section demonstrates rigor, fostering trust in the work’s conclusions and facilitating constructive criticism.
More visual insights#
More on figures
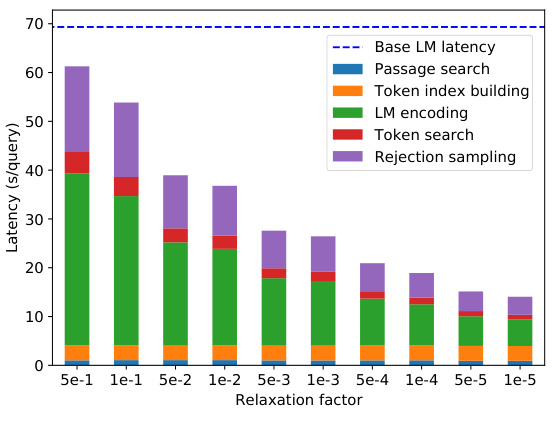
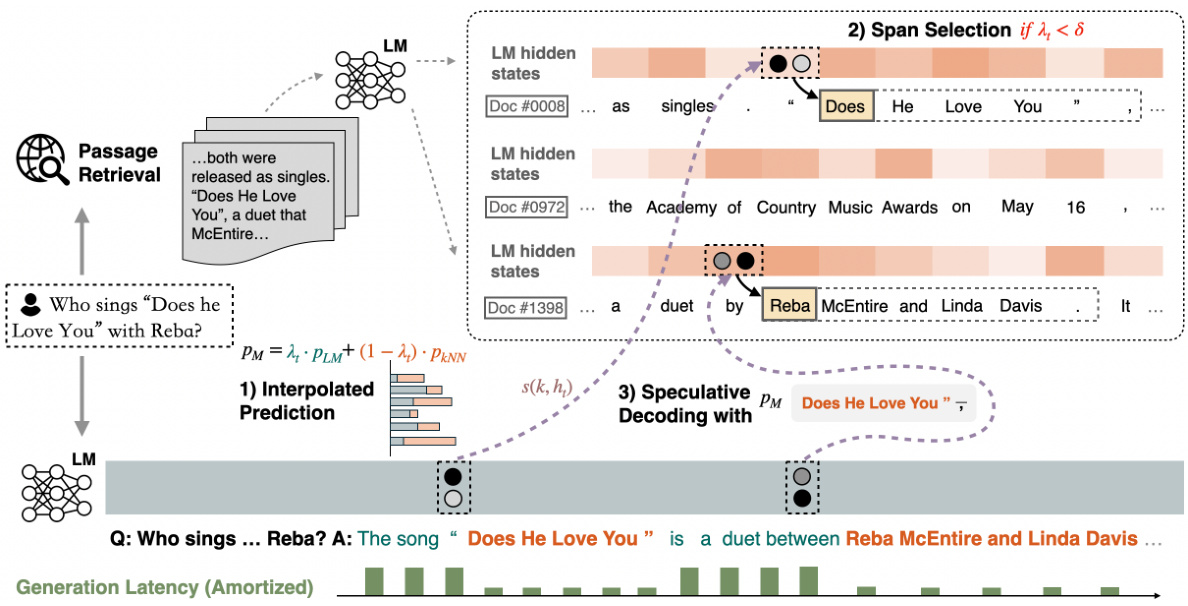
🔼 This figure presents a latency-accuracy trade-off analysis and a latency breakdown for the Llama-2-Chat 70B model enhanced with NEST on the Biography dataset. The left chart (a) shows the breakdown of latency across different components of the NEST model (passage search, token index building, LM encoding, token search, rejection sampling) for various values of the relaxation factor (γ). The right chart (b) shows the relationship between the relaxation factor, average span length selected from the corpus, and FACTSCORE. Lower relaxation factors (γ) correlate with longer span lengths and higher FACTSCORE. The main experiment used γ = 5e-2, balancing speed and accuracy improvements.
read the caption
Figure 2: Latency-accuracy trade-off and breakdown on Biography using Llama-2-Chat 70B+NEST. As the relaxation factor γ decreases, NEST tends to accept longer spans from the corpus. We choose γ = 5e-2 in our main experiments, which accelerates the generation and improves the FACTSCORE.
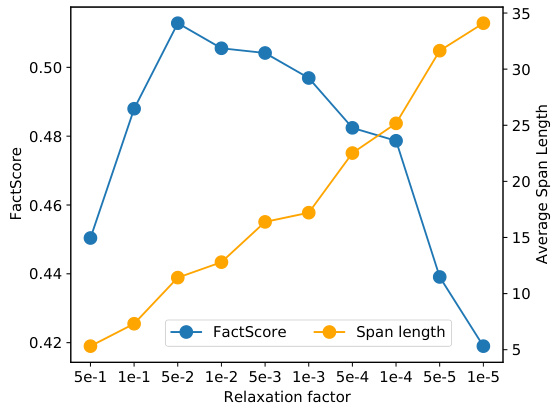
🔼 This figure shows two sub-figures. (a) shows a bar chart representing the latency breakdown of the NEST model (a = 0.3, r = 0.1, δ = 0.5) for different relaxation factors on the Biography validation data. The latency experiment is done on 8xA100 GPUs (for model parallelization) and 32 CPU threads (for search). The batch size is set to 1. The sub-figure shows the components: base LM latency, passage search, token index building, LM encoding, token search and rejection sampling. (b) is a line chart showing the FACTSCORE and average span length (number of tokens) as a function of the relaxation factor (γ). The FACTSCORE is shown in blue and the span length is shown in orange. This sub-figure visually illustrates the latency-accuracy trade-off by tuning the relaxation factor. It shows that smaller γ values lead to longer spans but may not always result in higher FACTSCORE, indicating an optimal point for the relaxation factor that balances both latency and accuracy.
read the caption
Figure 2: Latency-accuracy trade-off and breakdown on Biography using Llama-2-Chat 70B+NEST. As the relaxation factor γ decreases, NEST tends to accept longer spans from the corpus. We choose γ = 5e-2 in our main experiments, which accelerates the generation and improves the FACTSCORE.
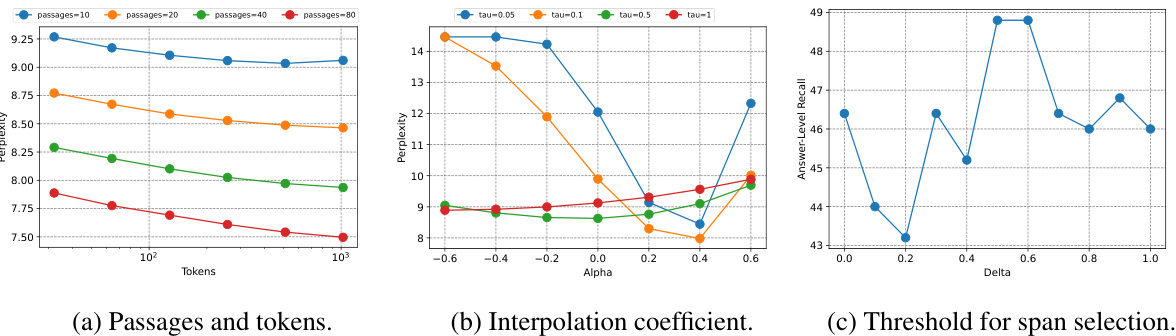
🔼 This figure illustrates the Nearest Neighbor Speculative Decoding (NEST) approach. It begins by using the language model’s hidden states to identify relevant tokens within a corpus. A retrieval distribution (Pk-NN) is then created, which is dynamically combined with the language model’s probability distribution (PLM) based on the uncertainty of the retrieval process. The algorithm selects the most likely token and its n-gram continuation from the resulting mixed distribution. Speculative decoding is then employed to refine the span length and eliminate unwanted tokens. The final generated text incorporates these spans, thereby providing source attribution and improving generation speed.
read the caption
Figure 1: The NEST approach first locates the tokens in the corpus using the LM hidden states. The retrieval distribution Pk-NN is dynamically interpolated with PLM based on the retriever's uncertainty λt. The token and its n-gram continuation are then selected from the mixture distribution Pм, while the final span length is determined by speculative decoding to remove undesired tokens. The spans incorporated in the final generation provide direct attribution and amortize the generation latency.
More on tables

🔼 This table presents the results of various experiments conducted on different language models using the proposed NEST method and several baseline methods for various tasks like text completion, question answering, fact verification, and multi-choice tasks. The upper half shows the results for text completion, with metrics such as Perplexity, ROUGE scores, and average generation length. The lower half shows the results for other tasks, with metrics tailored to the specific task. The table allows comparison of the performance of different models and methods across various downstream applications.
read the caption
Table 1: Results on text completion (upper table) and other tasks (lower table). Bold numbers indicate the best performance. PPL: Perplexity. RG: ROUGE score. Avg. Len: Average generation length. ABLUE/ARG: The difference between the max score to correct references and the max score to incorrect references. FS: FACTSCORE with length penalty.
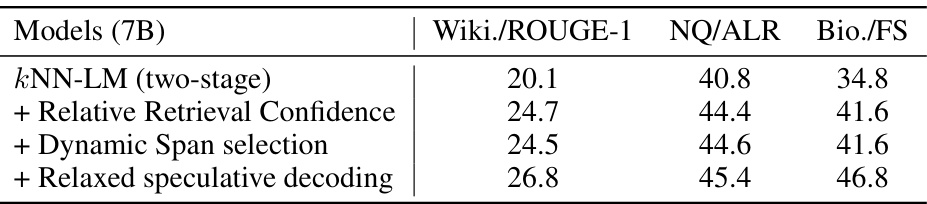
🔼 This ablation study shows the effect of progressively adding components of NEST to a two-stage kNN-LM baseline on three different datasets. It demonstrates the contribution of each component: Relative Retrieval Confidence, Dynamic Span Selection, and Relaxed Speculative Decoding, to the overall performance measured by ROUGE-1, Answer-Level Recall (ALR), and FACTSCORE.
read the caption
Table 3: Ablation study on the validation set of WikiText-103, NQ, and Biography. ROUGE-1 is reported for WikiText-103, ALR is reported for NQ, and FACTSCORE is reported for Biography.
Full paper#