↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Reinforcement learning often requires manually designing reward functions for training agents, which is time-consuming and can be intractable for complex behaviors. This paper introduces Text-Aware Diffusion for Policy Learning (TADPoLe), a novel method to address this challenge. TADPoLe leverages a pre-trained text-conditioned diffusion model to automatically generate reward signals based on natural language descriptions of desired behaviors. This removes the need for manual reward design.
The core of TADPoLe lies in its use of a pretrained diffusion model to assess the alignment between the agent’s actions in an environment and the textual description of the desired behavior. The method computes a reward signal reflecting this alignment, enabling the training of policies without explicit reward engineering. The experiments show that TADPoLe can effectively learn policies for various tasks in different simulated environments. This zero-shot learning capability, coupled with the use of pretrained models, significantly simplifies the policy learning process and paves the way for developing more versatile and human-friendly AI agents.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to policy learning in reinforcement learning that uses pretrained text-conditioned diffusion models to generate reward signals. This method eliminates the need for manually designing reward functions, significantly reducing development time and complexity and thereby enabling researchers to learn policies for diverse behaviors. This approach is also highly relevant to the current trends in generative AI and multimodal learning, which opens new avenues for future investigation in zero-shot learning and bridging the gap between language and action.
Visual Insights#

This figure shows examples of the diverse text-conditioned goals achieved by the TADPoLe model in different simulated environments. The environments include a humanoid robot, a dog, and robotic arms in a Meta-World setting. Each image shows a different task successfully completed by the AI agent, based solely on the given textual description, such as ‘a person in lotus position’, ‘a person doing splits’, etc. The figure highlights the framework’s ability to learn policies for novel behaviors directly from natural language instructions without requiring manually-designed reward functions or expert demonstrations.

This table presents the results of goal-achievement experiments conducted on the DeepMind Control Suite’s Dog and Humanoid environments. It compares different methods for achieving various goals specified through natural language prompts. Numerical results (mean and standard deviation over 5 seeds) are given where ground-truth reward functions exist. For novel, zero-shot learning tasks, checkmarks indicate whether the learned policy aligns with the text prompt, as judged by human evaluators.
In-depth insights#
TADPoLe Framework#
The TADPoLe framework presents a novel approach to policy learning in reinforcement learning by leveraging pretrained text-conditioned diffusion models. Its core innovation lies in using a frozen, pretrained diffusion model to generate dense, zero-shot reward signals for a policy learning agent. This eliminates the need for manually designing reward functions, which is often a major bottleneck in reinforcement learning. The framework leverages the rich priors encoded in large-scale generative models to guide the agent’s behavior, ensuring both text alignment and a sense of naturalness. TADPoLe’s ability to learn policies for novel goals specified by natural language, without ground-truth rewards or demonstrations, is a significant advancement. The framework’s application across diverse environments (Humanoid, Dog, Meta-World) further showcases its generality and robustness. A key strength is the framework’s domain agnosticism, using a general-purpose generative model rather than one trained on environment-specific data. The utilization of both text-to-image and text-to-video diffusion models expands the framework’s applicability to various tasks. However, the computational cost associated with using diffusion models and the potential challenges in interpreting the resulting reward signals need further investigation.
Reward Signal Design#
The effectiveness of reinforcement learning hinges critically on the design of reward signals. Poorly designed rewards can lead to agents achieving unintended objectives or exhibiting unnatural behaviors. This paper tackles this challenge by introducing a novel approach: leveraging a pre-trained, frozen text-conditioned diffusion model to generate dense, zero-shot reward signals. This bypasses the need for hand-crafting reward functions, a significant hurdle in many reinforcement learning tasks. The model’s pre-training on massive datasets provides rich priors that enable the model to assess both the alignment between the agent’s actions and a textual description of the desired behavior and the naturalness of those actions. This dual reward signal design encourages the agent to act not only according to the specifications but also in a way that aligns with common sense or human intuition. A significant advantage is the model’s domain-agnostic nature, enabling it to generate rewards in various environments without task-specific training, thus increasing scalability and reducing engineering effort. The use of a pretrained, frozen model also promotes efficiency by eliminating the need for additional training cycles specific to reward generation. The efficacy of this approach is demonstrated through evaluations on Humanoid, Dog, and Meta-World robotic manipulation tasks, showcasing the model’s ability to learn novel, zero-shot policies that are textually aligned and perceptually natural.
Zero-Shot Learning#
Zero-shot learning (ZSL) aims to enable models to recognize unseen classes during testing, which were not present during training. This is achieved by leveraging auxiliary information such as semantic attributes, word embeddings, or visual features of seen classes to bridge the gap between seen and unseen classes. A key challenge in ZSL is the domain adaptation problem, as the distribution of features for unseen classes can differ significantly from that of seen classes. Approaches often use generative models to create synthetic samples of unseen classes, or rely on transfer learning methods from large pretrained models. Despite significant advancements, ZSL remains inherently challenging due to the fundamental difficulty of inferring knowledge about entirely novel concepts from limited data. The paper explores this challenge by using pretrained, frozen diffusion models which encode rich priors, to generate dense rewards for reinforcement learning. By using a domain-agnostic model that already understands the general concept of a
Empirical Evaluation#
A robust empirical evaluation section is crucial for validating the claims of a research paper. It should present a comprehensive assessment of the proposed method’s performance, comparing it against relevant baselines and showcasing its effectiveness across various settings. Clearly defined metrics, including both quantitative and qualitative measures, are essential for a thorough evaluation. Quantitative metrics should provide numerical results, ideally accompanied by error bars or other statistical measures to indicate significance and reliability. Qualitative assessments, such as human evaluations, can provide additional insights into aspects not easily captured by numbers alone. Control experiments are necessary to isolate and measure the effect of the specific contributions of the study, while ablation studies should be performed to demonstrate the value of each component of the proposed approach. The choice of baselines should be justified, ensuring that the comparison is fair and informative. Finally, detailed descriptions of the experimental setup, including data splits, hyperparameters, and resource utilization, are crucial for reproducibility and transparency. A well-executed empirical evaluation significantly enhances the credibility and impact of the research.
Future Work#
The paper’s ‘Future Work’ section hints at several crucial directions. Improving fine-grained control over text conditioning is vital; currently, the model’s response to nuanced language prompts is limited. Addressing this necessitates more sophisticated methods for parsing and prioritizing words within a prompt. Utilizing multiple camera views to enhance reward signal computation is another important area, potentially leading to more robust and realistic behavior learning. The inherent stochasticity of the diffusion model’s reward generation is a concern; future work should focus on improving the stability and consistency of policy learning across multiple trials. Investigating the effect of various noise levels on the learning process and exploring the trade-off between exploration and exploitation could lead to significant improvements in training efficiency and performance. Finally, exploring alternative generative model architectures and studying the impact of model size and pretraining data on the resulting policies is a compelling avenue of research that could further enhance the approach’s capability and generalizability.
More visual insights#
More on figures
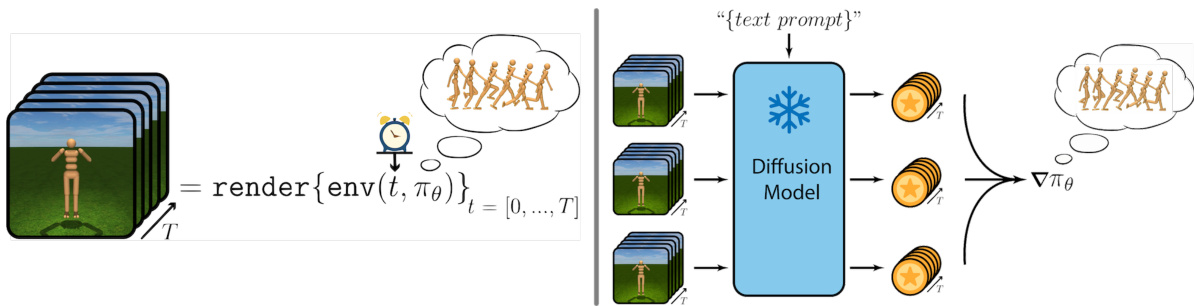
This figure illustrates the core idea of TADPoLe. It shows how a policy interacting with an environment can be seen as implicitly generating a video. Each frame in this video is a result of the agent’s actions and the environment’s rendering. This video is then evaluated by a text-conditioned diffusion model. The model compares the generated frames to what it would generate given a text description of the desired behavior. This comparison generates a reward signal, guiding the learning process of the policy to produce videos/behaviors that are aligned with the text input. The left side shows how the policy generates frames sequentially over time, while the right side visualizes how the diffusion model uses those frames to provide text-conditioned reward signals for policy optimization.

This figure illustrates the Text-Aware Diffusion for Policy Learning (TADPoLe) pipeline. The process starts with an agent (π) interacting with an environment. The environment’s render function produces a frame (ot+1) at each timestep. This frame is then corrupted by adding Gaussian noise (ϵ0). This noisy frame is input, along with the text prompt, to a pretrained text-conditioned diffusion model. The diffusion model predicts the noise that was added (ϵφ). Finally, a reward (rt) is calculated based on the difference between the predicted noise and the actual noise. A higher reward indicates better alignment between the generated frame and the text prompt. The reward is then used to update the agent’s policy.

This figure showcases the capabilities of the proposed Text-Aware Diffusion for Policy Learning (TADPoLe) method. It demonstrates the model’s ability to achieve various text-conditioned goals across different simulated environments. The images depict successful zero-shot policy learning for diverse tasks specified in natural language, highlighting the method’s flexibility and potential for complex behavior generation.
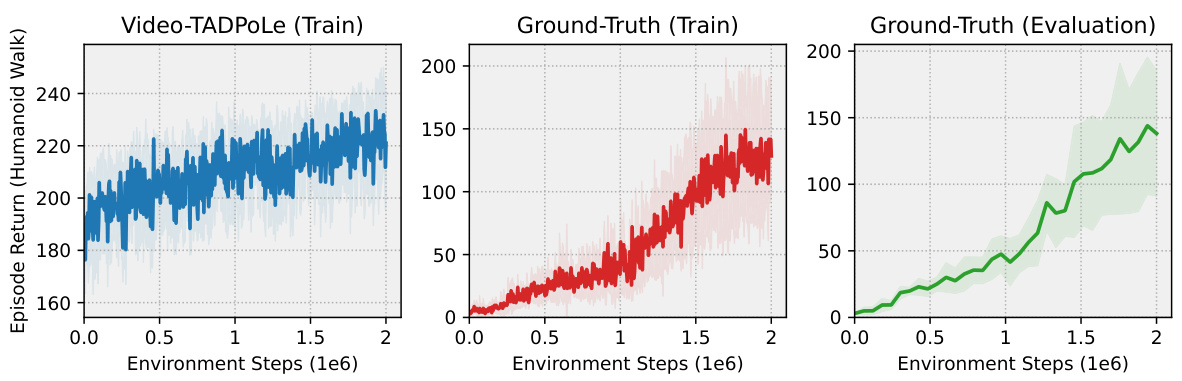
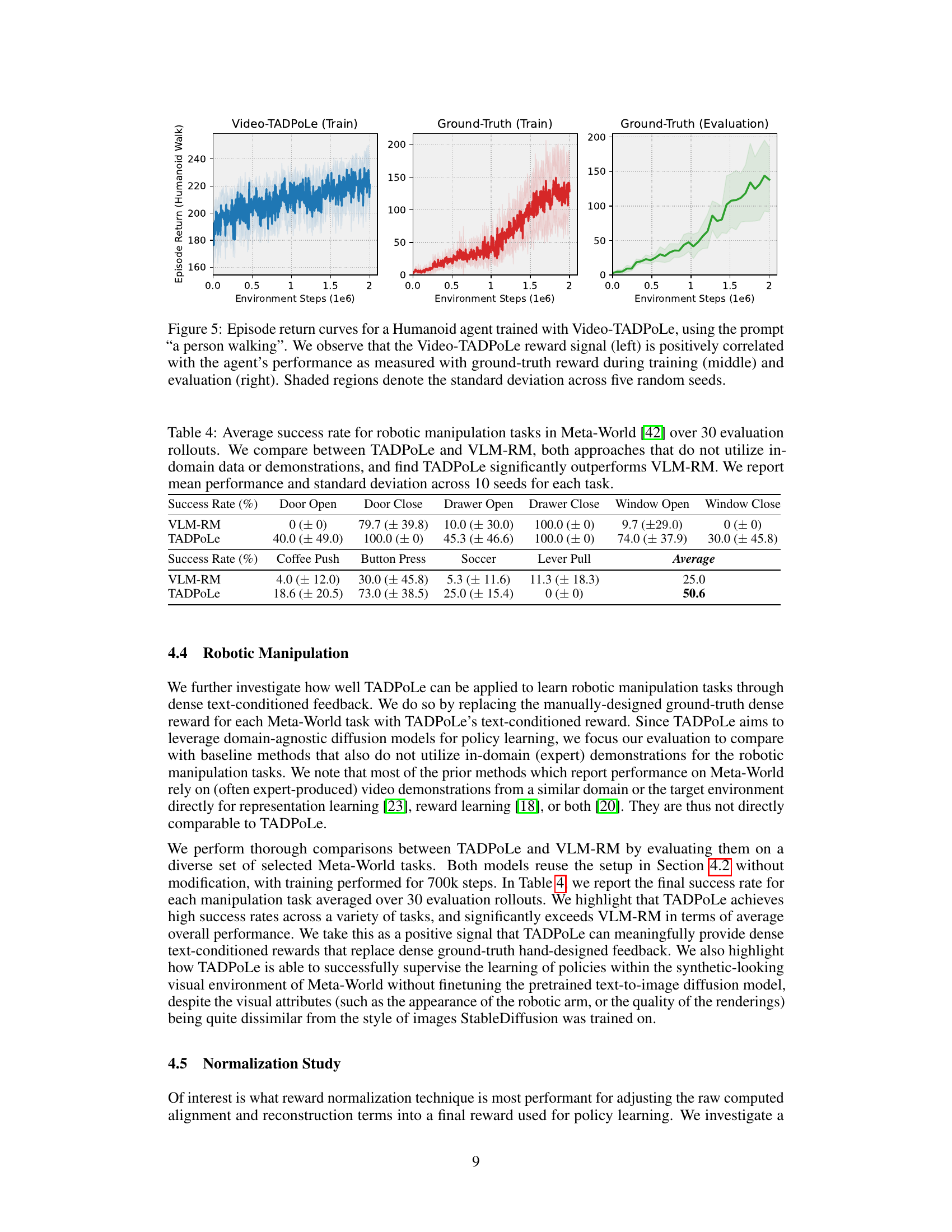
This figure displays three graphs showing the training and evaluation performance of a humanoid agent trained using Video-TADPoLe with the text prompt ‘a person walking’. The left graph shows the Video-TADPoLe reward during training. The middle graph shows the ground truth reward during training, and the right graph shows the ground truth reward during evaluation. The shaded areas represent the standard deviation across five random seeds. The figure demonstrates a positive correlation between the Video-TADPoLe reward and the ground truth reward, indicating the effectiveness of the proposed method in learning locomotion behaviors.
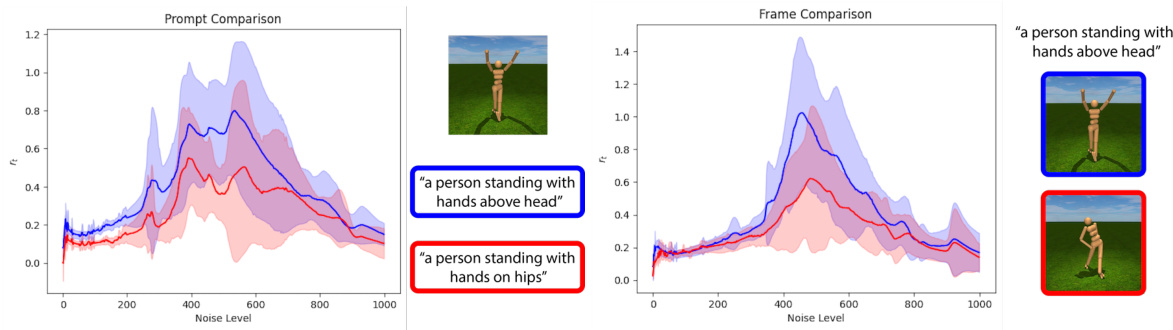
This figure shows the results of an experiment to determine the optimal noise level range for the TADPoLe reward function. The experiment involved varying the noise level applied to rendered images and comparing the resulting reward signals for both well-aligned (text and image match) and misaligned (text and image mismatch) pairs. The results suggest that a noise level range of U(400, 500) provides the best discrimination between well-aligned and misaligned cases.

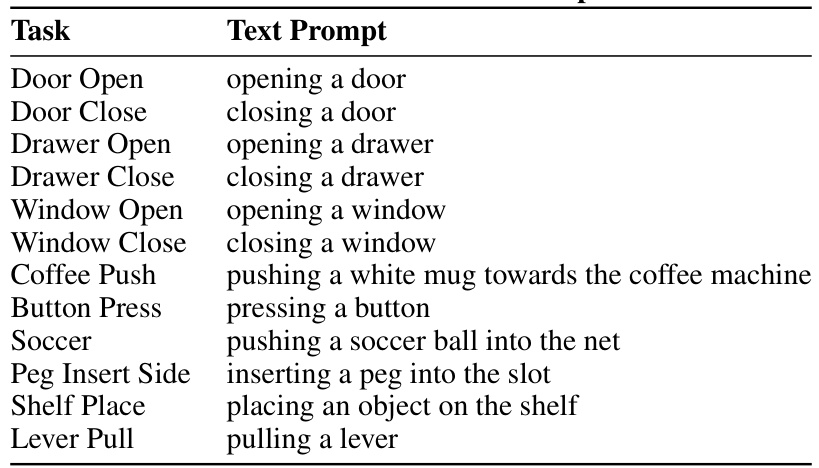
This figure visualizes the twelve robotic manipulation tasks selected from the Meta-World benchmark for evaluating the performance of TADPoLe. The tasks represent a diverse range of challenges in terms of complexity and the required motor skills. The image shows a different setup for each of the 12 tasks, showcasing the variety of environments and object interactions involved.
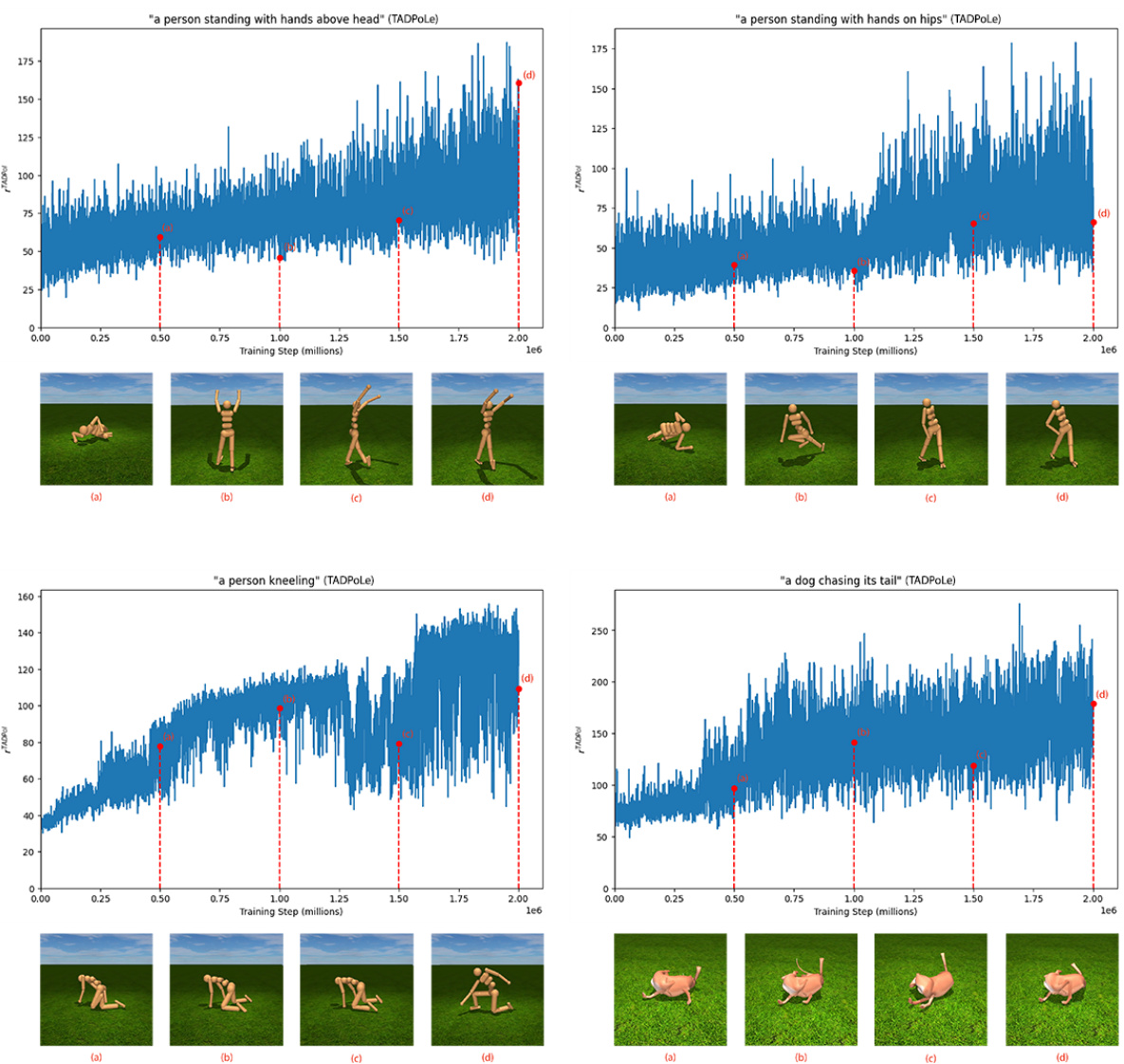
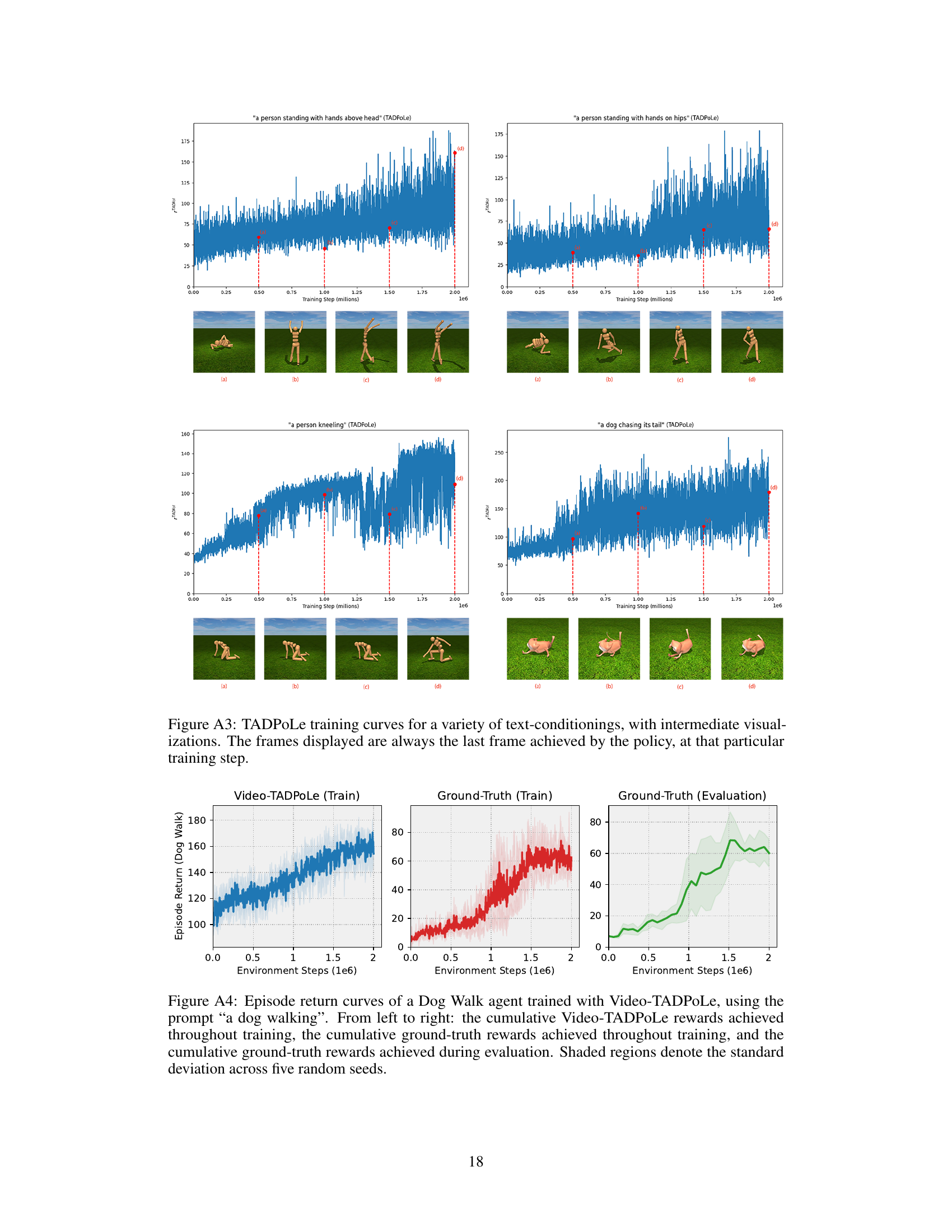
This figure shows the training curves for four different text prompts used with TADPoLe: ‘a person standing with hands above head’, ‘a person standing with hands on hips’, ‘a person kneeling’, and ‘a dog chasing its tail’. Each plot shows the episode return over training steps (in millions). Below each plot are four images showing the last frame of the video generated by the policy at different training steps, visualizing the progress over training. This helps illustrate the effectiveness of the algorithm in learning complex behaviors from textual descriptions.
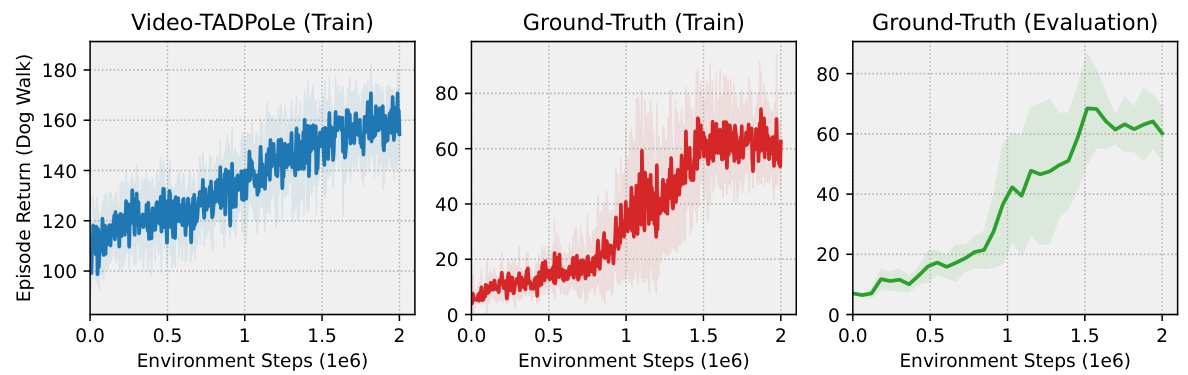
This figure displays the training and evaluation performance of a humanoid agent trained using the Video-TADPoLe method. The left panel shows the episode return (a measure of performance) obtained during training using the Video-TADPoLe reward. The middle panel shows the episode return using ground truth reward during training, and the right panel shows the episode return during evaluation with ground truth reward. The positive correlation between the Video-TADPoLe reward and the agent’s performance indicates that the method effectively guides the agent towards the desired behavior. The shaded regions represent the standard deviation, suggesting the variability in the results.

This figure shows training curves for four different text prompts used with TADPoLe. The curves illustrate the progress of the agent’s learning over time, while the accompanying images display the agent’s behavior at various stages of training. This demonstrates the evolution of the policy from initial attempts to the final behavior. Each row represents a different text prompt: ‘a person standing with hands above head’, ‘a person standing with hands on hips’, ‘a person kneeling’, and ‘a dog chasing its tail’.

This figure shows the training curves for several text-conditioned policies. The plots display the episode return over training steps (in millions). Below each plot are a series of images showing the last frame of the video generated by the trained policy at various stages during training. This allows visualization of how the learned policy’s behavior changes over the course of training and how it gradually aligns with the text prompt.

This figure visualizes the denoising process of a successful dog walking trajectory using Stable Diffusion. It shows a sequence of images, starting from a noisy version of the original video frames at a noise level of 500, and progressively denoising to reconstruct the original clean frames. Each row represents a frame from the sequence, with the top row being the most noisy version and the bottom row the cleanest reconstruction, demonstrating how Stable Diffusion effectively removes noise while retaining the essential visual characteristics of the dog’s motion.

This figure shows the training curves for four different text prompts: “a person standing with hands above head”, “a person standing with hands on hips”, “a person kneeling”, and “a dog chasing its tail”. For each prompt, the figure displays the episode return over time (training steps in millions) along with four example frames from the last frame of the achieved video at several training step checkpoints: 500k, 1M, 1.5M, and 2M. This visualizes how the policy learns over time, demonstrating the evolution of the agent’s behavior from an initial state to a state that aligns with the text prompt.

This figure shows the denoising process of a successful dog walking trajectory using Stable Diffusion. The top row displays the original frames from the trajectory. The middle row shows the noisy frames after adding Gaussian noise with a noise level of 500. The bottom row presents the denoised frames produced by Stable Diffusion. The consistent and successful reconstruction of the dog walking across the frames demonstrates the model’s ability to accurately reconstruct good query trajectories.

This figure shows training curves and intermediate results of TADPoLe for four different text prompts: ‘a person standing with hands above head’, ‘a person standing with hands on hips’, ‘a person kneeling’, and ‘a dog chasing its tail’. Each subplot displays the episode return over training steps (x-axis) and the corresponding last frame of the video generated by the policy at different training steps (bottom). The figure visually demonstrates how the policy learns to achieve the desired behavior over time, with each frame showcasing progress towards the final goal.

This figure visualizes training curves of TADPoLe for various text prompts and shows the last frames of the resulting videos at different training steps (500k, 1M, 1.5M, and 2M). This allows for a visual understanding of how the learned policies evolve over training and how well they match the intended text prompt at different stages.

This figure shows training curves for four different text prompts used with TADPoLe. For each prompt, the figure displays a training curve and a sequence of images showing the final frame of each policy at specific training steps (500k, 1M, 1.5M, and 2M). The images illustrate how the agent’s behavior evolves over the training process, progressing from initially random movements to those increasingly aligned with the intended text prompt.
More on tables

This table presents the results of continuous locomotion experiments using different methods. It compares the performance of several approaches, including LIV, Text2Reward, Video-TADPoLe, and ViCLIP-RM, across two environments (Humanoid and Dog) and two prompts (‘a person walking’ and ‘a dog walking’). The table shows numerical results (mean and standard deviation) for methods with ground-truth reward functions and qualitative assessment (checkmark/x-mark) for text alignment. The key finding is that Video-TADPoLe significantly outperforms other methods in terms of continuous locomotion performance and text alignment.

This table presents a comparison of the success rates achieved by TADPoLe and VLM-RM on various robotic manipulation tasks within the Meta-World environment. Both methods operate without using in-domain data or demonstrations. The results show that TADPoLe substantially outperforms VLM-RM across different tasks, demonstrating the effectiveness of the proposed method.

This table presents the results of continuous locomotion experiments using different methods. It shows the performance (mean and standard deviation across 5 trials) of various methods, including Video-TADPoLe and ViCLIP-RM, on Humanoid and Dog locomotion tasks. The table also indicates whether the resulting policy aligns with the text prompt used. Video-TADPoLe significantly outperforms ViCLIP-RM.
This table presents the results of goal-achievement experiments using the DeepMind Control Suite’s Dog and Humanoid environments. For experiments where a ground-truth reward function was available, the table shows numerical results (mean and standard deviation across 5 seeds). For novel tasks learned using only text-based conditioning (zero-shot learning), a checkmark indicates whether the learned policy successfully matched the text description according to human evaluation.

This table presents the results of goal-achievement experiments using the DeepMind Control Suite’s Dog and Humanoid environments. It compares the performance of different methods, including the proposed TADPoLe, on various text-conditioned tasks. For tasks with ground truth reward functions, numerical results (mean and standard deviation) are shown, while for novel zero-shot tasks, the table shows whether the policy successfully aligned with the text prompt according to human evaluation.

This table presents the results of goal-achievement experiments conducted on the DeepMind Control Suite’s Dog and Humanoid environments. It compares different methods for learning policies based on natural language instructions. Numerical results (mean and standard deviation across 5 seeds) are shown where applicable (ground-truth reward function exists). For novel behaviors learned without ground-truth rewards, a checkmark indicates if the resulting policy aligned with the textual instructions according to human evaluation.
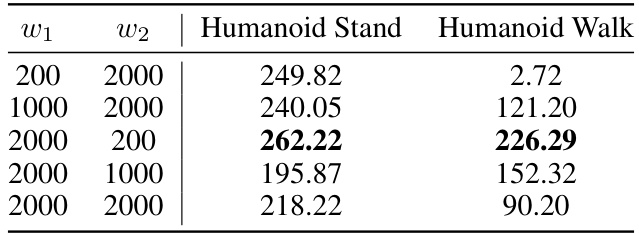
This table presents the ablation study results on the impact of hyperparameters w₁ and w₂ on the Humanoid Stand and Walk tasks. Different combinations of w₁ and w₂ were tested, and the resulting performance (in terms of cumulative reward) is reported for both tasks. This helps to determine the optimal values of w₁ and w₂ that lead to the best performance in each task.
This table presents the results of goal-achievement experiments conducted on the DeepMind Control Suite Dog and Humanoid environments. For tasks with a ground-truth reward function, the table shows quantitative results (mean and standard deviation across 5 seeds). For novel tasks where a ground-truth reward isn’t available, a qualitative assessment is provided, indicating whether the learned policy successfully aligns with the specified text prompt based on human evaluation. The table compares different methods, including the proposed TADPoLe method, showing whether each method successfully achieved the text-specified goal.

This table presents a comparison of the success rates of TADPoLe and VLM-RM on 12 robotic manipulation tasks from the Meta-World benchmark. Both methods operate without using in-domain demonstrations or data. The table shows the average success rate (percentage of successful task completions) and standard deviation across ten trials for each task, highlighting TADPoLe’s superior performance.

This table presents the results of goal-achievement experiments conducted on the DeepMind Control Suite’s Dog and Humanoid environments. For tasks with ground truth reward functions, the table shows quantitative results (mean and standard deviation across 5 random seeds) of different methods. For novel tasks where ground-truth rewards were not available, the table shows qualitative results, indicating whether the learned policies successfully matched the given text prompts according to human evaluation.
Full paper#