↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large-scale vision models require substantial parameters for fine-tuning, prompting research into parameter-efficient fine-tuning (PEFT) methods. However, existing PEFT techniques often suffer from significant performance degradation when there’s a large disparity between pre-training and fine-tuning datasets. This issue limits the broader application of PEFT methods, creating a significant challenge for researchers.
To address this challenge, the authors propose Visual Fourier Prompt Tuning (VFPT). VFPT innovatively integrates the Fast Fourier Transform (FFT) into prompt embeddings, incorporating both spatial and frequency domain information. This method outperforms several state-of-the-art baselines, demonstrating superior performance and efficiency across various tasks with low parameter usage. The authors also provide intuitive visualizations to explain the effectiveness of VFPT, showcasing its simplicity, generality, and superior performance in handling data disparity issues. VFPT’s success demonstrates a significant advancement in PEFT methods for large vision models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on parameter-efficient fine-tuning (PEFT) methods for large vision models. It addresses the significant performance drop observed when the training data differs substantially from the pre-training data, a common challenge in PEFT. The proposed Visual Fourier Prompt Tuning (VFPT) method offers a novel, effective, and efficient solution and opens new avenues for research into cross-dataset generalization and the incorporation of frequency domain information in visual prompt tuning.
Visual Insights#

This figure compares the original visual prompt tuning (VPT) method with the proposed Visual Fourier Prompt Tuning (VFPT) method. It highlights the key difference: VFPT incorporates the Fast Fourier Transform (FFT) into partial visual prompts, processing them in both the spatial and frequency domains before inputting them into the transformer encoder layers. The figure visually represents the workflow of both methods, showing how VFPT enhances VPT by integrating frequency domain information.
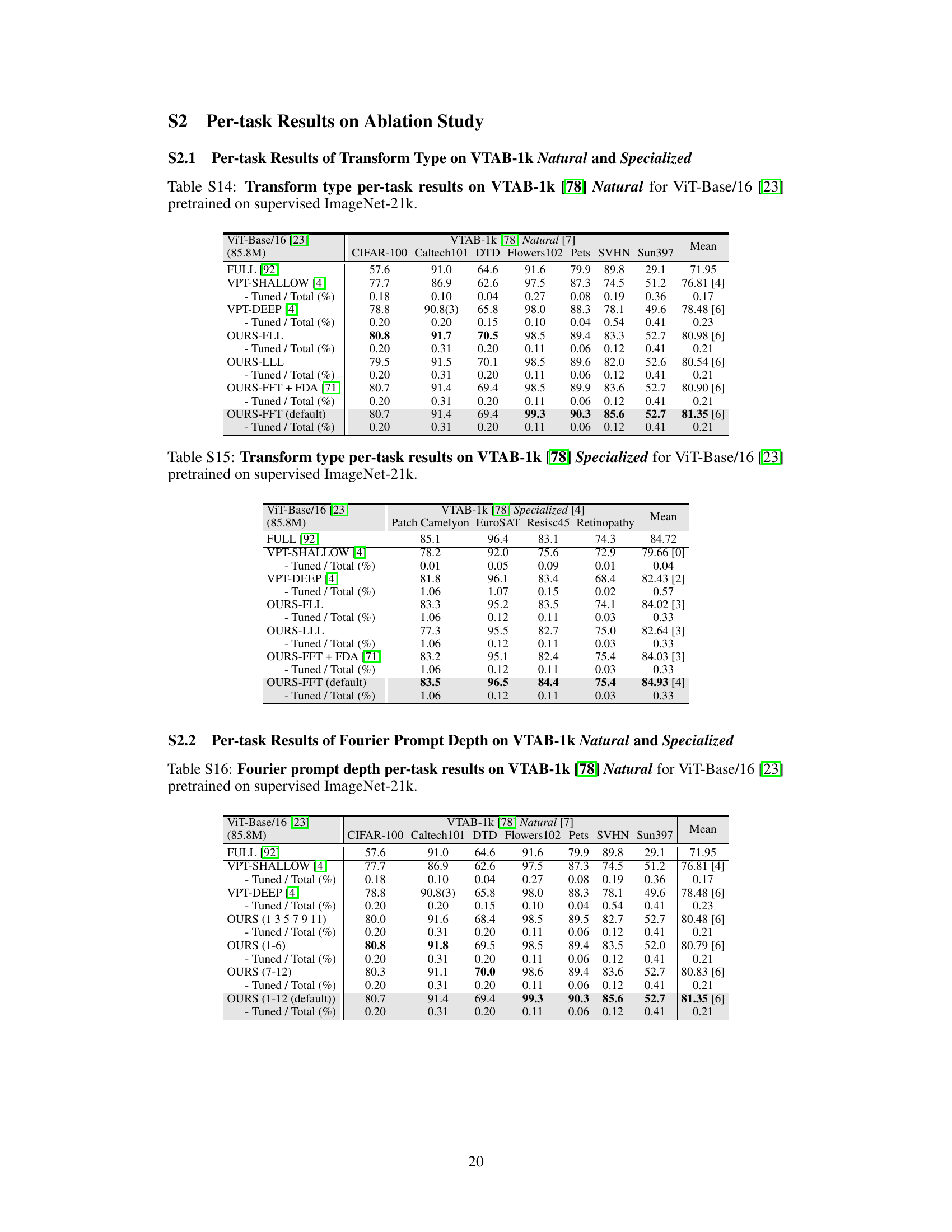
This table presents a comparison of various parameter-efficient fine-tuning (PEFT) methods on two image classification benchmarks: FGVC and VTAB-1k. The methods are evaluated based on their average test accuracy (across three runs), the number of times they outperform full fine-tuning, and their parameter usage. The table highlights the superior performance of VFPT compared to other state-of-the-art PEFT methods while using significantly fewer parameters.
In-depth insights#
Fourier Prompt Tuning#
The concept of “Fourier Prompt Tuning” blends the power of prompt tuning with Fourier transforms to enhance model adaptability. Prompt tuning already provides a parameter-efficient way to fine-tune large models, but it often struggles when the training and test data significantly differ. Fourier transforms offer a potential solution by incorporating both spatial and frequency-domain information into prompt embeddings. This approach mirrors human visual cognition, which seamlessly integrates various information sources. By combining spatial and frequency details, the method aims to improve a model’s ability to generalize to new tasks with differing data distributions. The integration of Fourier transforms adds complexity but promises to enhance the robustness and flexibility of prompt tuning, leading to superior performance across various tasks. This approach is innovative and has the potential for broader applications, though the extent to which it overcomes the limitations of traditional prompt tuning remains to be fully explored. The effectiveness and efficiency of Fourier prompt tuning compared to other parameter-efficient fine-tuning methods should be carefully examined through empirical evaluations.
VFPT Methodology#
The VFPT methodology section would detail the innovative approach of integrating the Fast Fourier Transform (FFT) into prompt embeddings within a large-scale transformer-based vision model. The core idea is to leverage FFT’s ability to represent data in both spatial and frequency domains, thus enriching the information available to the model during fine-tuning. The method would likely describe the precise steps involved in applying the FFT to selected prompt embeddings, potentially specifying which prompts are transformed and whether the FFT is applied along the sequence or hidden dimensions of the embeddings. A key aspect would be explaining how the transformed frequency information seamlessly integrates with the original spatial information within the transformer’s architecture, potentially involving techniques to handle complex numbers resulting from FFT. The section should also include details about the model’s training process, highlighting how the Fourier components affect the optimization landscape and overall performance. It would be crucial to explain how this approach addresses the challenge of significant performance degradation when pretraining and fine-tuning data distributions differ, emphasizing the improved generalization and adaptability offered by VFPT. Experimental setup details, including datasets and hyperparameters, would further validate the proposed methodology.
VFPT Advantages#
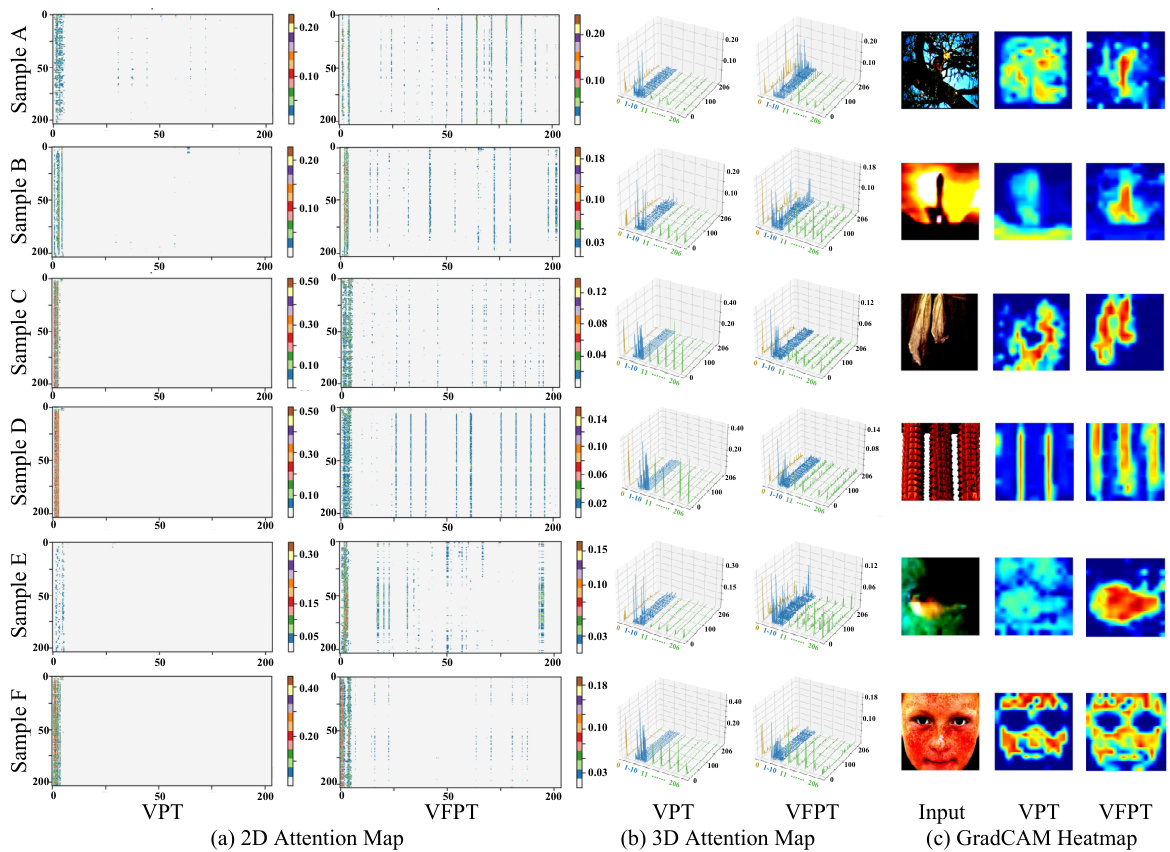
The proposed Visual Fourier Prompt Tuning (VFPT) method offers several key advantages for adapting large-scale transformer-based vision models. Simplicity is a core strength; VFPT’s innovative use of the Fast Fourier Transform within prompt embeddings is elegant and straightforward to implement, requiring minimal code changes. This ease of integration contrasts with more complex PEFT approaches. Generality is another significant advantage; by seamlessly incorporating both spatial and frequency-domain information, VFPT demonstrates superior performance across diverse tasks and datasets, even those with substantial disparities between pretraining and finetuning data. This robustness addresses a major limitation of other PEFT methods. Finally, VFPT offers improved interpretability: the integration of Fourier transforms leads to a higher concentration of attention scores within the Transformer’s input space, visually demonstrating enhanced feature extraction and a more favorable optimization landscape, promoting better generalization. Overall, VFPT’s combination of simplicity, generality, and improved interpretability makes it a compelling and efficient solution for adapting large-scale vision models.
Generalization Study#
A robust generalization study is crucial for evaluating the practical applicability of any machine learning model, especially those based on large-scale pretrained models. In such a study, one should rigorously assess model performance across various unseen datasets, tasks, and distribution shifts, aiming to understand how well the model adapts and extrapolates beyond its training environment. This includes examining performance on diverse benchmarks that represent real-world conditions and are different from the training data. Key aspects to consider include evaluating performance under varying data complexities, assessing the sensitivity to hyperparameter choices, and studying the impact of domain disparities between the training and testing datasets. A high-quality generalization study should provide clear quantitative and qualitative results, including error bars to ensure statistical significance and visualizations for gaining deeper insights. Furthermore, analyzing and discussing any patterns or correlations between model performance and dataset characteristics is vital. Ultimately, the generalization study aims to demonstrate that the model is not just memorizing the training data but has genuinely learned transferable knowledge and capabilities that enable robust performance in novel situations.
Future of VFPT#
The future of Visual Fourier Prompt Tuning (VFPT) appears bright, given its strong performance and conceptual elegance. Further research could explore automating the selection of the Fourier percentage, currently a hyperparameter, to enhance efficiency and usability across diverse tasks. The method’s adaptability could be expanded beyond image and language domains, potentially integrating other modalities such as audio or multimodal data. Investigating various Fourier transform types and their effectiveness for distinct tasks warrants attention. Combining VFPT with other parameter-efficient fine-tuning techniques might lead to even greater improvements. A thorough investigation into the optimization landscape and how to leverage this for better generalization across vastly different data distributions is key. Finally, exploring VFPT’s theoretical underpinnings and the correlation between frequency and spatial components will significantly enrich our understanding of prompt tuning.
More visual insights#
More on figures

This figure compares the original visual prompt tuning (VPT) method with the proposed Visual Fourier Prompt Tuning (VFPT) method. It highlights the key difference: VFPT incorporates the Fast Fourier Transform (FFT) to process visual prompts, adding frequency domain information to the spatial information used in VPT. Panel (a) shows the VPT architecture, (b) illustrates the FFT operations applied to prompts in VFPT, and (c) presents the complete VFPT architecture. The figure visually represents the integration of FFT into prompt embeddings to enhance model performance.

This figure compares the original visual prompt tuning (VPT) with the proposed visual Fourier prompt tuning (VFPT). Panel (a) shows the standard VPT architecture, while panel (b) illustrates the incorporation of a 2D Fast Fourier Transform (FFT) into the visual prompts. Finally, panel (c) provides a complete schematic of the VFPT model, demonstrating how FFT is integrated into the VPT framework.

This figure compares the original visual prompt tuning (VPT) framework with the proposed visual Fourier prompt tuning (VFPT) method. Panel (a) shows the standard VPT approach. Panel (b) illustrates how the fast Fourier transform (FFT) is applied to the visual prompts, transforming them into both spatial and frequency domains. Finally, panel (c) presents the complete VFPT architecture, incorporating FFT into the prompt embeddings.
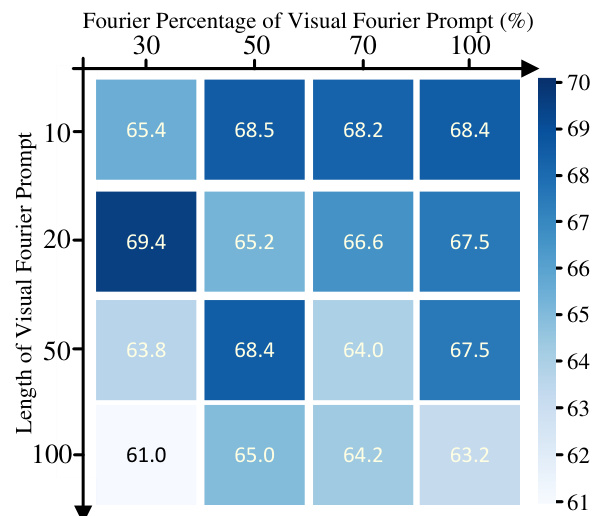
This figure compares the original Visual Prompt Tuning (VPT) framework with the proposed Visual Fourier Prompt Tuning (VFPT) framework. Panel (a) shows the VPT architecture, which uses learnable prompts in the input space of a transformer-based model. Panel (b) illustrates the incorporation of 2D Fast Fourier Transforms (FFT) into the visual prompts of VFPT, transforming spatial information into the frequency domain. Finally, panel (c) presents the complete architecture of VFPT, highlighting the integration of both spatial and frequency domain information through FFT operations within the prompt embeddings. This seamlessly integrates spatial and frequency information, enabling adaptation across various datasets.
This figure provides a visual comparison of three different visual prompt tuning methods: (a) shows the original visual prompt tuning (VPT) method, (b) illustrates the incorporation of 2D Fast Fourier Transform (FFT) operations into partial visual prompts, and (c) presents the overall architecture of the proposed Visual Fourier Prompt Tuning (VFPT) method. The VFPT method integrates FFT to leverage both spatial and frequency information for improved performance.

This figure provides a visual comparison of three different visual prompt tuning approaches. (a) shows the original visual prompt tuning (VPT) method, where learnable prompts are added to the input of each transformer encoder layer. (b) illustrates the incorporation of the 2D Fast Fourier Transform (FFT) into the visual prompts, transforming the spatial domain information into the frequency domain. (c) presents the proposed Visual Fourier Prompt Tuning (VFPT) method, which integrates both spatial and frequency domain information through FFT operations, enhancing the performance and generalizability of the model.

This figure compares the original visual prompt tuning (VPT) framework with the proposed Visual Fourier Prompt Tuning (VFPT) method. Panel (a) shows the standard VPT architecture. Panel (b) highlights the incorporation of the 2D Fast Fourier Transform (FFT) applied to partial visual prompts, showing the transformation in both the hidden and sequence dimensions. Panel (c) presents the complete VFPT architecture, illustrating how the FFT-processed prompts are integrated into the overall model.

The figure compares the original visual prompt tuning (VPT) with the proposed visual Fourier prompt tuning (VFPT). Panel (a) shows the VPT architecture, highlighting the learnable visual prompts added to the input of each transformer encoder layer. Panel (b) illustrates the application of the Fast Fourier Transform (FFT) to the visual prompts in the VFPT method, showing both sequence-wise and hidden-wise FFT operations. Panel (c) provides a comprehensive overview of the VFPT architecture, indicating how the FFT-processed prompts are integrated into the overall model.
More on tables

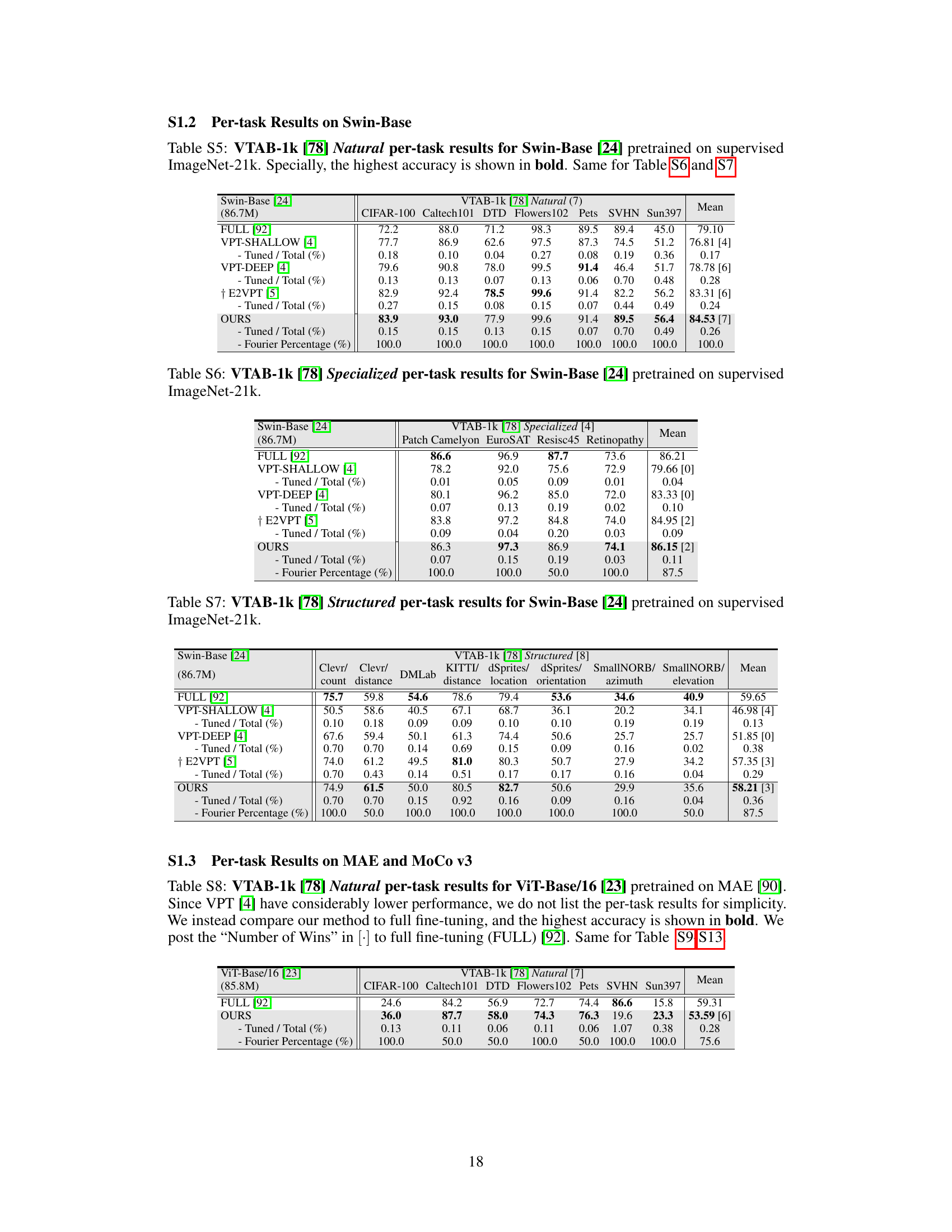
This table presents the average test accuracy (over three runs) achieved by different parameter-efficient fine-tuning methods on the Swin-Base model pretrained on the ImageNet-21k dataset. The methods are evaluated on the VTAB-1k benchmark across three task groups (Natural, Specialized, and Structured) representing varying levels of dataset disparity. The table shows the percentage of tuned parameters used by each method, along with the accuracy for each task group. The results highlight the performance of Visual Fourier Prompt Tuning (VFPT) compared to baselines.

This table presents a comparison of various parameter-efficient fine-tuning (PEFT) methods on two image classification benchmarks: FGVC and VTAB-1k. For each method, the average test accuracy across three runs, the number of wins against full fine-tuning, the percentage of tuned parameters, and the tuning scope are reported. The table highlights VFPT’s superior performance and efficiency compared to other state-of-the-art baselines.
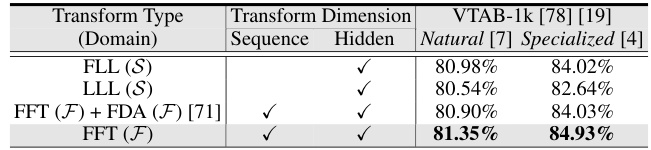
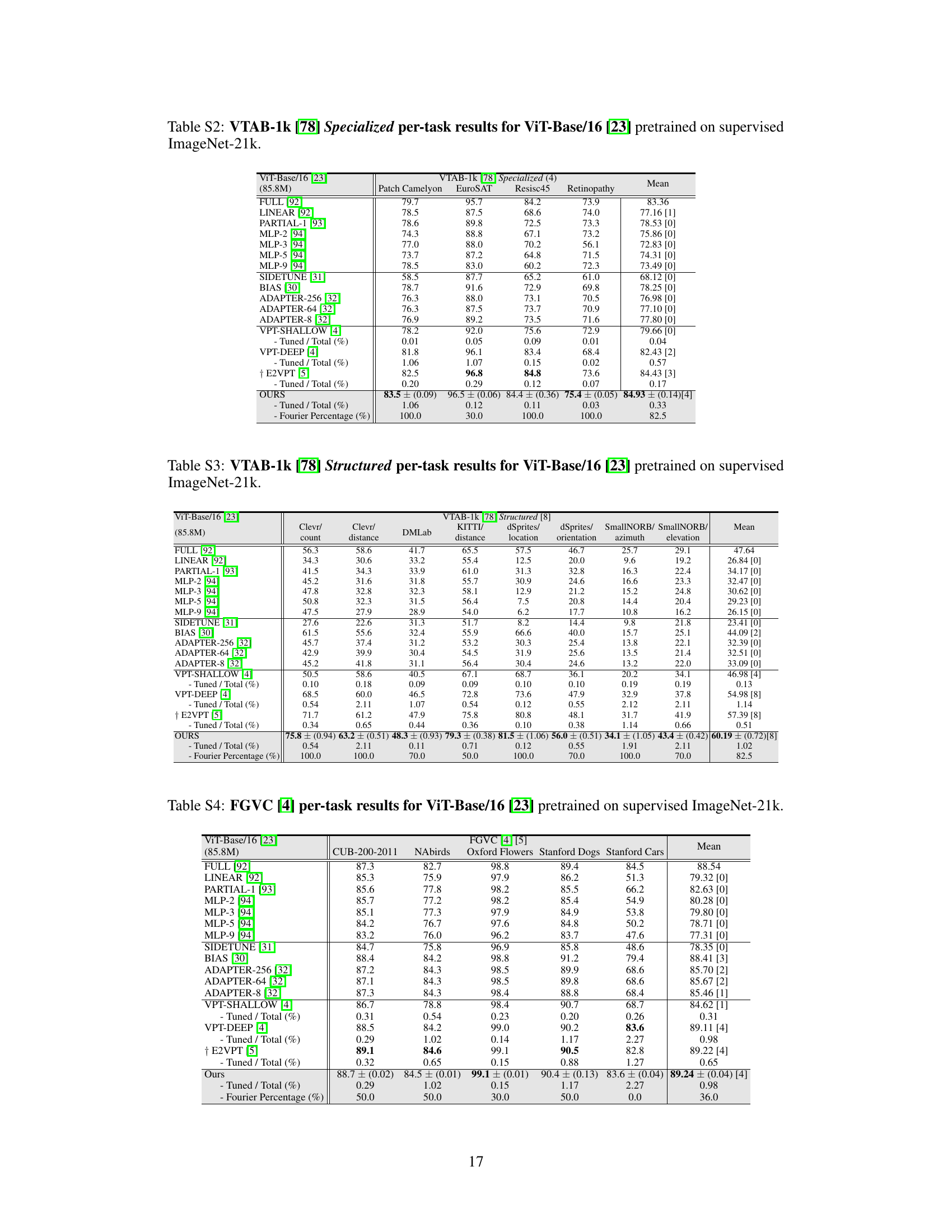
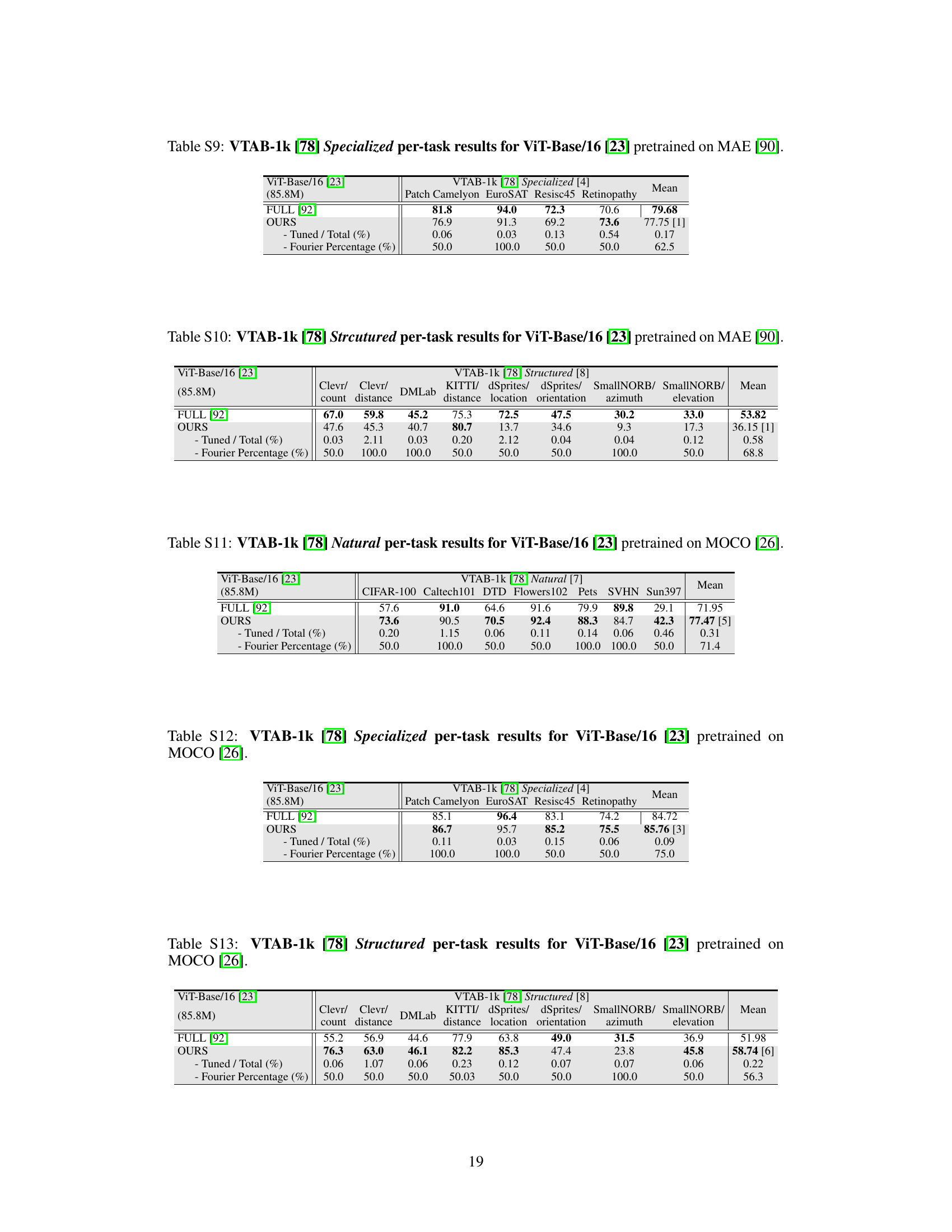
This table presents a comparison of different parameter-efficient fine-tuning (PEFT) methods on image classification tasks using the ViT-Base/16 model pretrained on ImageNet-21k. The methods are evaluated on the FGVC and VTAB-1k benchmarks, which include tasks with varying data disparities. Metrics reported include average test accuracy, the number of wins against full fine-tuning, the percentage of tuned parameters, and tuning scope. The table highlights the superior performance and parameter efficiency of the proposed VFPT method, demonstrating its ability to outperform existing methods even when dataset disparities exist.

This table presents a comparison of the image classification accuracy achieved by various parameter-efficient fine-tuning (PEFT) methods on the VTAB-1k and FGVC benchmarks, using a ViT-Base/16 model pretrained on ImageNet-21k. It shows the average test accuracy across three runs for each method, the percentage of tuned parameters relative to the total number of parameters, and the tuning scope of each method. The table also indicates which methods outperform full fine-tuning on various tasks and which ones outperform the state-of-the-art Visual Prompt Tuning (VPT) method. It highlights the superior performance and parameter efficiency of the proposed Visual Fourier Prompt Tuning (VFPT) method compared to other approaches.

This table presents a comparison of image classification accuracy across various parameter-efficient fine-tuning (PEFT) methods on the FGVC and VTAB-1k benchmarks using a ViT-Base/16 model pretrained on ImageNet-21k. It shows the average test accuracy (over three runs), the number of times each method outperformed full fine-tuning across 24 tasks, the percentage of tuned parameters used, and the tuning scope. The table highlights VFPT’s superior performance and efficiency compared to other PEFT methods.

This table presents a comparison of image classification accuracies achieved by various parameter-efficient fine-tuning (PEFT) methods and full fine-tuning on the VTAB-1k and FGVC benchmark datasets. The results are broken down by task category within VTAB-1k (Natural, Specialized, Structured) and across FGVC tasks. The table shows the average test accuracy across three runs for each method, along with the percentage of tuned parameters and the number of times each method outperforms full fine-tuning or VPT. It highlights the superior performance and parameter efficiency of the proposed VFPT method.
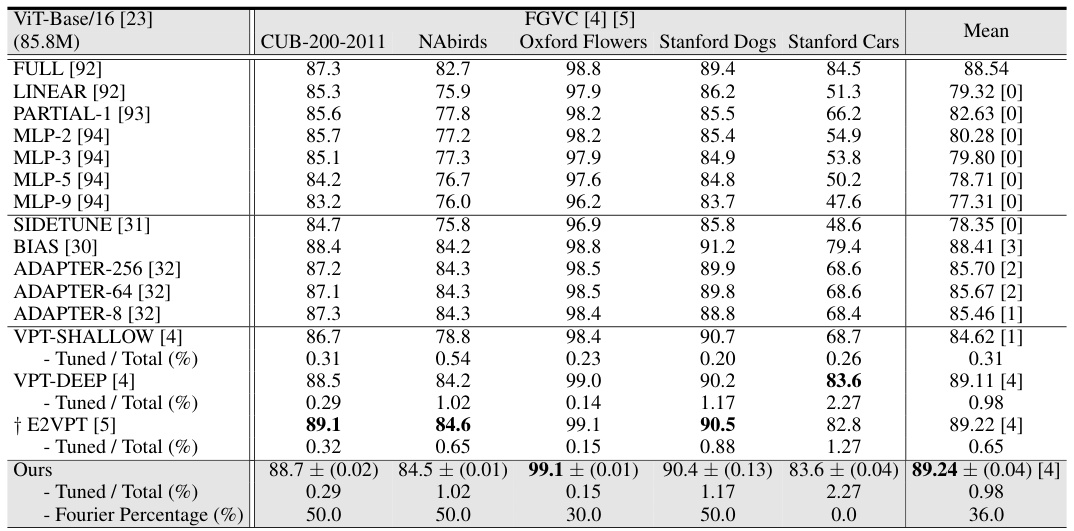
This table presents the average test accuracy (over three runs) achieved by various parameter-efficient fine-tuning (PEFT) methods on two image classification benchmarks: FGVC and VTAB-1k. The methods are compared against full fine-tuning (Full), with metrics including the number of wins against Full, the percentage of tuned parameters, and the tuning scope. The table highlights the superior performance of VFPT (ours) compared to other methods, particularly its high number of wins against Full and low parameter usage.
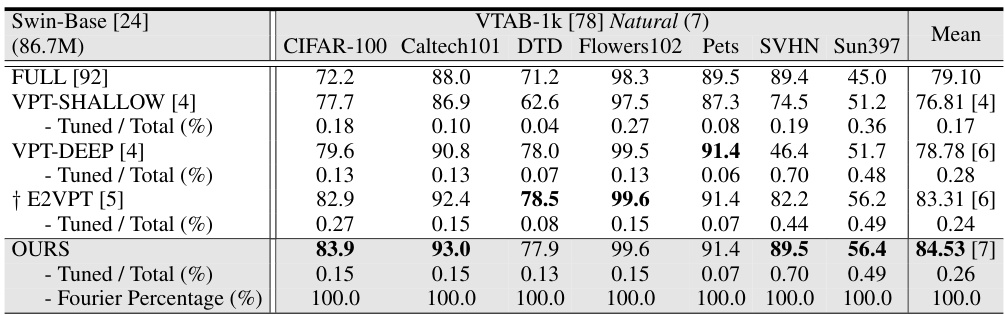
This table presents a comparison of various parameter-efficient fine-tuning (PEFT) methods on the image classification task using the ViT-Base/16 model pretrained on ImageNet-21k. The methods are evaluated on the FGVC and VTAB-1k benchmarks. Metrics include average test accuracy, the number of wins compared to full fine-tuning, and the percentage of tuned parameters. The table highlights the superior performance and parameter efficiency of the proposed Visual Fourier Prompt Tuning (VFPT) method.
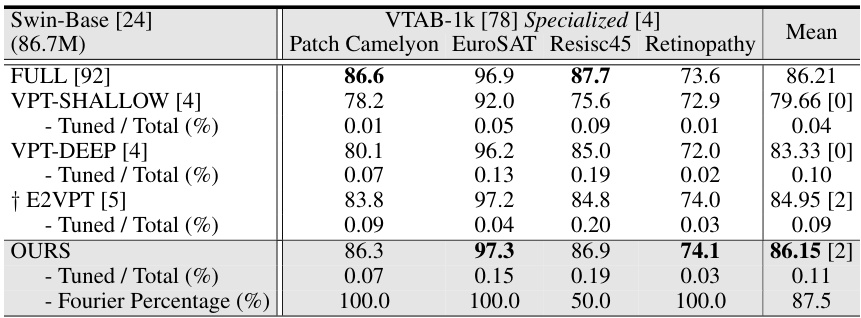
This table presents a comparison of various parameter-efficient fine-tuning (PEFT) methods on two image classification benchmarks: FGVC and VTAB-1k. The results show the average test accuracy (over three runs) for each method across the benchmarks. Key metrics include the number of parameters used relative to the total number of model parameters and the number of times each method outperforms full fine-tuning and VPT (another PEFT method) on each task. The table highlights VFPT’s superior performance compared to other methods, particularly regarding low parameter usage and high accuracy, especially on tasks with greater differences between the pre-training and fine-tuning datasets.

This table presents the average test accuracy (over three runs) achieved by various parameter-efficient fine-tuning (PEFT) methods and full fine-tuning on two image classification benchmark datasets: FGVC and VTAB-1k. The methods are compared based on their number of wins against full fine-tuning, the percentage of tuned parameters, and the scope of their tuning. The table highlights VFPT’s superior performance and efficiency compared to other PEFT approaches and full fine-tuning.

This table presents a comparison of various parameter-efficient fine-tuning (PEFT) methods on two image classification benchmarks, FGVC and VTAB-1k, using the ViT-Base/16 model pretrained on ImageNet-21k. The table shows the average test accuracy across three runs for each method. Key metrics included are the number of wins against full fine-tuning, the percentage of tuned parameters, the tuning scope of each method, and whether additional parameters were used beyond the pretrained backbone and linear head. The table highlights VFPT’s superior performance and efficiency compared to other PEFT methods.
This table presents the average test accuracy (over three runs) achieved by various methods on two image classification benchmarks: FGVC [4] and VTAB-1k [78]. The methods are compared to a full fine-tuning baseline, indicating the number of times each method outperforms the full fine-tuning approach on each dataset. The table also lists the percentage of parameters tuned in each method, the tuning scope, and additional parameters used beyond the pretrained backbone and linear head. The results highlight the performance and parameter efficiency of the proposed method.

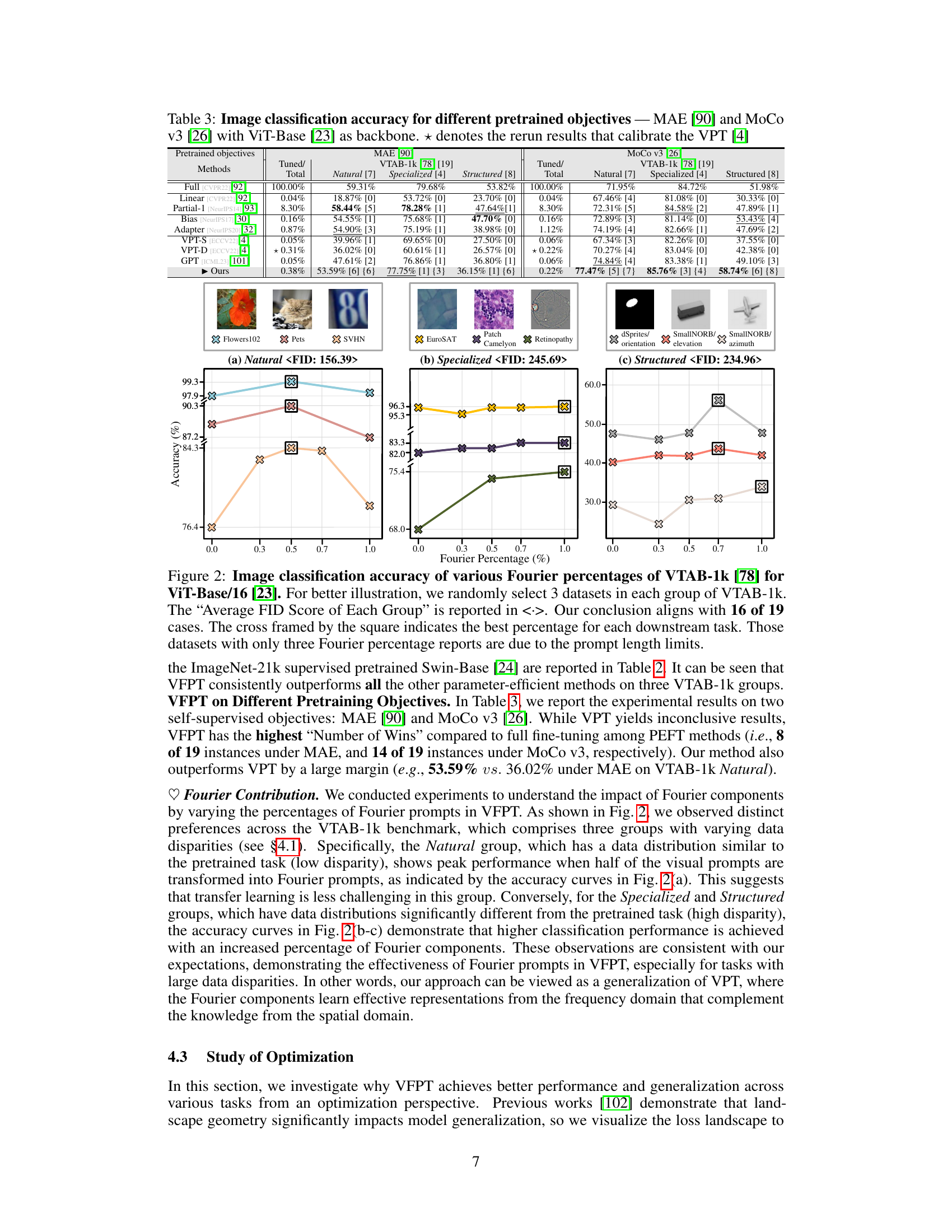
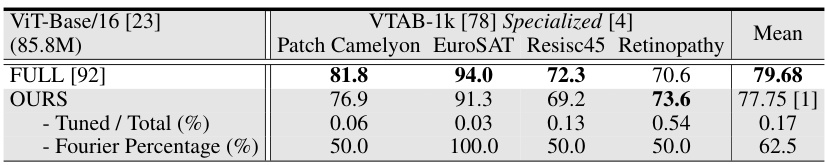
This table presents the image classification accuracy results on the VTAB-1k benchmark for different pre-trained objectives (MAE and MoCo v3) using the ViT-Base backbone. It compares the performance of the proposed VFPT method against several baselines, including full fine-tuning and the original visual prompt tuning (VPT) method. The table highlights the average test accuracy across three runs for different task groups within the VTAB-1k benchmark (Natural, Specialized, and Structured). The ‘Tuned/Total’ column indicates the percentage of tuned parameters used in each method, while ‘Fourier Percentage’ shows the percentage of Fourier components used in VFPT. The results demonstrate VFPT’s superior performance and parameter efficiency compared to other methods, particularly in tasks with significant data disparity.

This table presents a comparison of various parameter-efficient fine-tuning (PEFT) methods on the VTAB-1k and FGVC image classification benchmarks using ViT-Base/16 as the backbone model. It shows the average test accuracy, the number of times each method outperforms full fine-tuning, the percentage of tuned parameters, the tuning scope, and whether additional parameters were used. The table highlights the superior performance and efficiency of the proposed VFPT method compared to baselines.

This table presents a comparison of different parameter-efficient fine-tuning (PEFT) methods on image classification tasks using the ViT-Base/16 model pretrained on ImageNet-21k. It shows the average test accuracy, number of times each method outperforms full fine-tuning, and the percentage of tuned parameters. The table highlights VFPT’s superior performance and parameter efficiency compared to other methods, especially VPT, across various image classification datasets.

This table presents a comparison of image classification accuracies achieved by various parameter-efficient fine-tuning (PEFT) methods and full fine-tuning on the VTAB-1k and FGVC benchmark datasets using a ViT-Base/16 model pre-trained on ImageNet-21k. It shows the average test accuracy across three runs, the percentage of tuned parameters, the tuning scope of each method, and whether additional parameters were used beyond the pretrained backbone and linear head. The table highlights the superior performance of Visual Fourier Prompt Tuning (VFPT) in terms of accuracy and parameter efficiency compared to other PEFT methods and full fine-tuning.

This table presents a comparison of the performance of various parameter-efficient fine-tuning (PEFT) methods on the VTAB-1k and FGVC image classification benchmarks. The methods are compared against full fine-tuning and Visual Prompt Tuning (VPT). The table shows the average test accuracy, the number of times each method outperforms full fine-tuning, the percentage of parameters tuned for each method, and the scope of tuning for each method. The results highlight that the proposed method, Visual Fourier Prompt Tuning (VFPT), achieves superior performance with low parameter usage.

This table presents the average test accuracy (over three runs) achieved by various parameter-efficient fine-tuning (PEFT) methods on the FGVC [4] and VTAB-1k [78] benchmarks. It compares the performance of Visual Fourier Prompt Tuning (VFPT) against full fine-tuning (Full), several other PEFT techniques, and visual prompt tuning methods. Key metrics include the number of wins against full fine-tuning and VPT, the percentage of tuned parameters, the tuning scope, and whether additional parameters were used. The table highlights VFPT’s superior performance and parameter efficiency.

This table presents a comparison of various parameter-efficient fine-tuning (PEFT) methods on the VTAB-1k and FGVC image classification benchmarks. It shows the average test accuracy (over three runs) for each method on each benchmark, the number of times each method outperforms full fine-tuning, the percentage of tuned parameters relative to the total number of parameters in the model, and the scope of tuning for each method. The table highlights the superior performance of Visual Fourier Prompt Tuning (VFPT) compared to other methods, especially on tasks with high data disparity between the pre-training and fine-tuning datasets.
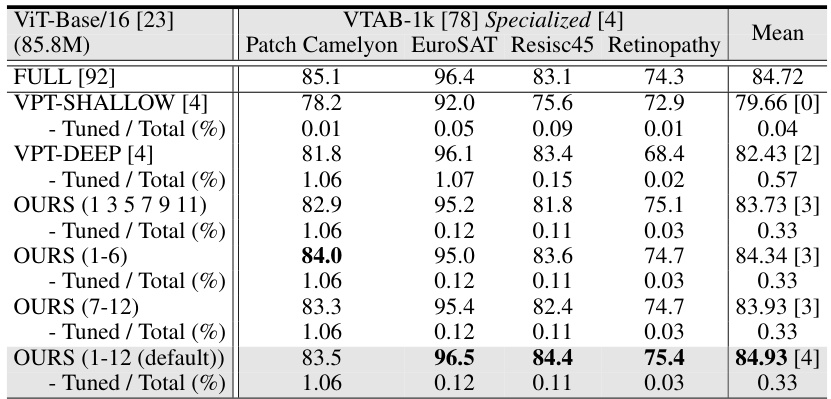
This table presents the average test accuracy (over three runs) achieved by various parameter-efficient fine-tuning (PEFT) methods and full fine-tuning on the FGVC and VTAB-1k benchmarks. It compares the performance of Visual Fourier Prompt Tuning (VFPT) against baselines, highlighting VFPT’s superior performance and lower parameter usage. Metrics include average accuracy, the number of tasks where a method outperforms full fine-tuning, and the percentage of tuned parameters. The table also indicates whether the methods use additional parameters beyond the pretrained backbone and linear head, and the tuning scope applied.
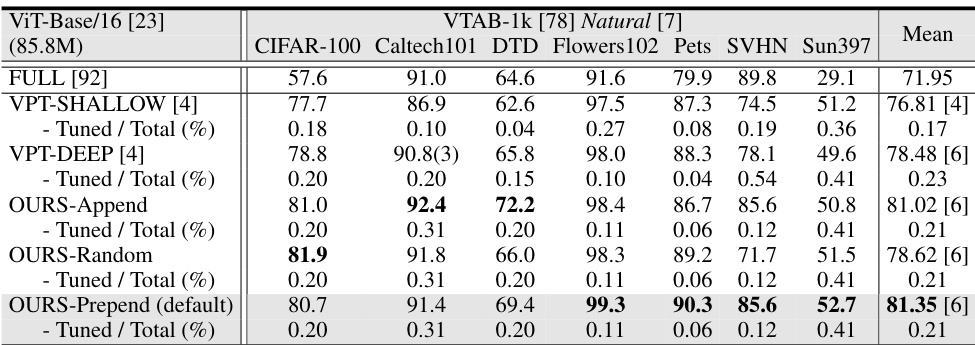
This table presents the average test accuracy (over three runs) achieved by various parameter-efficient fine-tuning (PEFT) methods on two image classification benchmarks: FGVC and VTAB-1k. The methods are compared against full fine-tuning, providing the number of times each method outperforms full fine-tuning and visual prompt tuning (VPT). The table also shows the percentage of tuned parameters used by each method across the 24 tasks, along with the tuning scope and additional parameters employed. The results highlight the superior performance of VFPT while using fewer parameters than other PEFT approaches.

This table presents the average test accuracy (over three runs) achieved by various parameter-efficient fine-tuning (PEFT) methods on the FGVC and VTAB-1k benchmarks, compared to full fine-tuning. It shows the number of times each method outperformed full fine-tuning and VPT across the 24 tasks. Key metrics such as the percentage of tuned parameters, the tuning scope, and the presence of additional parameters are also provided for each method. Bold and underlined values indicate the best and second-best results, respectively.
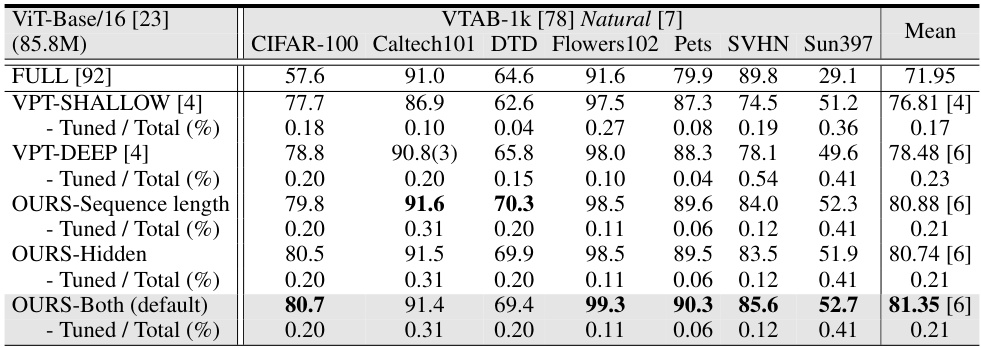
This table presents a comparison of the image classification accuracy achieved by various parameter-efficient fine-tuning (PEFT) methods and full fine-tuning on the ViT-Base/16 model pretrained on the ImageNet-21k dataset. The methods are evaluated across 24 tasks from the FGVC and VTAB-1k benchmarks. The table highlights the average test accuracy, the number of wins compared to full fine-tuning, the percentage of tuned parameters, and the tuning scope of each method. It provides a quantitative assessment of VFPT’s performance against state-of-the-art baselines in terms of accuracy and parameter efficiency.

This table presents a comparison of image classification accuracies achieved by various parameter-efficient fine-tuning (PEFT) methods and full fine-tuning on the VTAB-1k and FGVC benchmarks using the ViT-Base/16 model pretrained on ImageNet-21k. The table shows the average test accuracy across three runs for each method, the number of times each method outperforms full fine-tuning, and the percentage of tuned parameters used relative to the total number of parameters in the model. It highlights the superior performance and parameter efficiency of the proposed Visual Fourier Prompt Tuning (VFPT) method compared to existing PEFT approaches and full fine-tuning, especially in scenarios with large data disparities between pretraining and finetuning phases.

This table presents the image classification accuracy results for the ViT-Base/16 model pretrained on the supervised ImageNet-21k dataset. It compares the performance of Visual Fourier Prompt Tuning (VFPT) against several state-of-the-art baselines across two benchmarks, FGVC and VTAB-1k, focusing on different task categories within VTAB-1k (Natural, Specialized, Structured). The table shows the average test accuracy across three runs, the number of wins compared to full fine-tuning, the percentage of tuned parameters, and the tuning scope of each method. It highlights VFPT’s superior performance with low parameter usage.

This table presents the image classification accuracy results for the ViT-Base/16 model pretrained on the supervised ImageNet-21k dataset. It compares the performance of Visual Fourier Prompt Tuning (VFPT) against various other parameter-efficient fine-tuning methods and full fine-tuning on the FGVC and VTAB-1k benchmarks. The table includes metrics such as average test accuracy, number of wins against full fine-tuning, the percentage of tuned parameters, and the tuning scope of each method. The results highlight VFPT’s superior performance and efficiency.

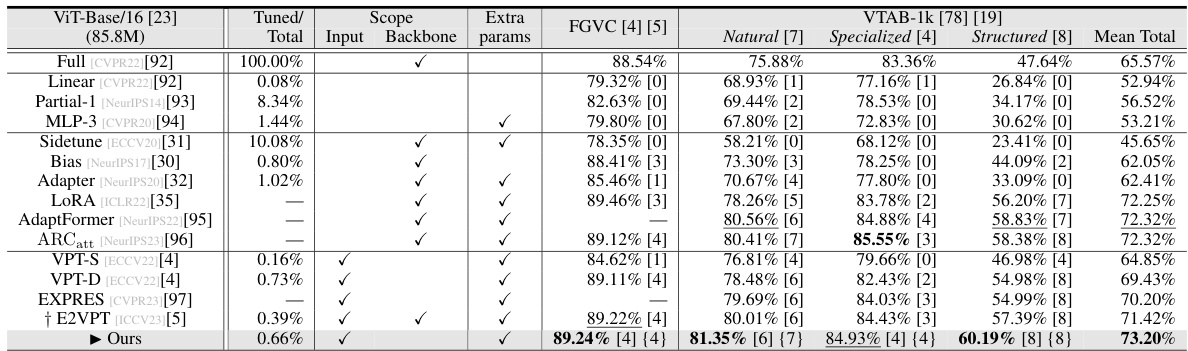
This table presents the per-task results on the VTAB-1k Structured benchmark for ViT-Base/16, using different Fourier percentages (0%, 30%, 50%, 70%, and 100%). It shows the impact of varying the Fourier percentage on the model’s performance across various sub-tasks within the Structured group of VTAB-1k.

This table presents a comparison of the image classification accuracy achieved by various parameter-efficient fine-tuning (PEFT) methods and full fine-tuning on the VTAB-1k and FGVC benchmarks using the ViT-Base/16 model pretrained on the ImageNet-21k dataset. The table includes the average test accuracy (over three runs) for each method, the percentage of tuned parameters relative to the total number of parameters, the scope of tuning (input, backbone, etc.), and whether additional parameters were added beyond the pretrained backbone and linear head. It also indicates the number of times each method outperformed full fine-tuning and VPT across the different tasks.

This table presents a comparison of various parameter-efficient fine-tuning (PEFT) methods on two image classification benchmarks: FGVC and VTAB-1k. The methods are evaluated based on their average test accuracy, the number of times they outperform full fine-tuning, the percentage of tuned parameters, and the tuning scope. The table highlights the performance and efficiency of VFPT in comparison to other PEFT methods, especially in scenarios with high data disparity between pretraining and finetuning datasets.
Full paper#