TL;DR#
Current large vision-language models struggle with the high computational cost of processing numerous vision tokens from dense video streams, especially in real-time applications. This limitation hinders the development of truly responsive online video assistants. Existing solutions like Q-Former and Perceiver Resampler try to reduce the number of vision tokens, but this can lead to information loss.
VIDEOLLM-MOD tackles this problem by dynamically skipping the computation for a high proportion of vision tokens at certain transformer layers instead of decreasing the overall token count. This approach, inspired by mixture-of-depths LLMs, significantly reduces computational costs (~42% training time and ~30% memory savings) without sacrificing performance. Extensive experiments on multiple benchmarks demonstrate the effectiveness of VIDEOLLM-MOD and its state-of-the-art performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient video-language models. It addresses the significant computational challenges of processing dense video frames in real-time, a critical issue in developing practical online video assistants. The proposed method, VIDEOLLM-MOD, offers a significant advancement in model efficiency, enabling the development of more powerful and responsive online video AI systems. It also opens new avenues for research into efficient vision token computation within large language models, pushing the boundaries of what’s possible in the field.
Visual Insights#

🔼 This figure compares the challenges of processing videos in offline versus online settings. Offline video processing methods often involve sparse sampling of frames or attention-based merging, which can lead to incomplete contexts or high latency. Online video processing, on the other hand, requires dense frame processing and real-time responses, necessitating more efficient approaches. The figure highlights three key challenges of transitioning from offline to online video processing: maintaining causal context, managing the heavy computational cost and latency, and preventing performance degradation.
read the caption
Figure 1: Comparison of efficient processing challenges in offline and online video. Online video introduces distinct challenges due to the need for real-time processing as frames stream continuously.
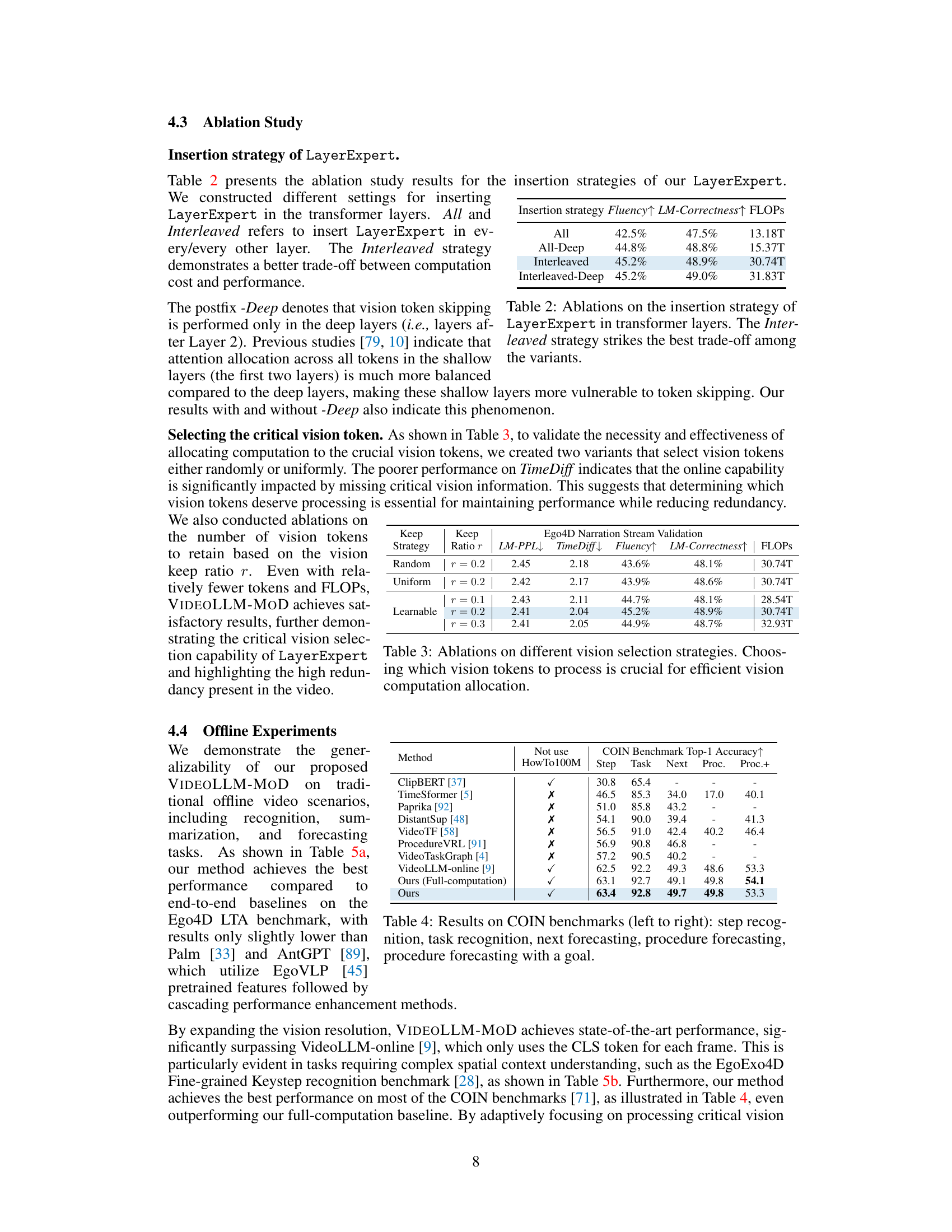
🔼 This table presents the results of online experiments conducted on the Ego4D narration benchmark. It compares the performance of VIDEOLLM-MOD against several baseline methods, including VideoLLM-online, a full-computation model, an EarlyExit approach, and a LayerSkip approach. The metrics used for comparison are Language Model Perplexity (LM-PPL), Time Difference (TimeDiff), Fluency, and LM-Correctness. The table also shows the FLOPS (floating-point operations per second) and training time for each method, highlighting the computational efficiency gains achieved by VIDEOLLM-MOD.
read the caption
Table 1: Online experiments on the Ego4D narration benchmark. VIDEOLLM-MOD achieves comparable metrics to the Full-computation baseline with less computation cost.
In-depth insights#
Vision Token Sparsity#
Vision token sparsity is a crucial technique in optimizing video-language models. By strategically reducing the number of visual tokens processed, it aims to improve efficiency without significantly compromising performance. The core idea is to identify and discard redundant or less informative visual tokens, thereby decreasing computational costs and memory requirements. This approach directly addresses the quadratic complexity associated with processing dense video frames, a significant bottleneck in many video understanding tasks. Effective sparsity methods typically leverage learnable mechanisms to determine which tokens are essential, for instance, by employing attention scores or other relevance metrics. The choice of sparsity strategy can significantly impact computational savings. A well-designed sparsity approach should prioritize retaining crucial visual tokens, ensuring the model preserves sufficient visual context to maintain accuracy. This balance between efficiency and performance necessitates careful consideration of various factors, including model architecture, training data, and the specific application needs.
MoD for VideoLLMs#
The concept of “MoD for VideoLLMs” introduces a novel approach to enhance the efficiency of large video language models. By drawing inspiration from Mixture-of-Depth (MoD) architectures used in LLMs, this method aims to selectively skip computations for less crucial vision tokens within specific layers of the transformer. This selective processing leverages the redundancy often found in video data, leading to significant computational savings without sacrificing model performance. The core innovation lies in the use of a learnable module, LayerExpert, to dynamically determine which vision tokens are essential and should undergo full processing, while the rest bypass computational-intensive layers through residual connections. The strategy differs from previous approaches that simply reduce the number of vision tokens, thus preserving the crucial contextual information needed for accurate video understanding. This method promises to be particularly beneficial for online, streaming video applications, where efficiency and real-time performance are paramount.
Online Efficiency Gains#
The concept of ‘Online Efficiency Gains’ in video processing is crucial for real-time applications. It centers on reducing computational costs and memory usage without sacrificing performance. This is particularly challenging with long videos or streaming video, where the number of vision tokens, representing visual information, grows rapidly. Methods like skipping computation for non-critical tokens or using early exit mechanisms can contribute to efficiency, but preserving important visual cues for accurate understanding is vital. Maintaining causal context is also critical, as the temporal order of information is essential for understanding. Therefore, effective online efficiency gains require smart strategies to balance computational savings with the retention of crucial visual and temporal information, focusing on dynamic token selection and computation allocation based on the importance of visual information rather than blanket pruning or early exits.
Benchmarking & Results#
A robust ‘Benchmarking & Results’ section would meticulously detail the experimental setup, datasets used (including their characteristics and limitations), and evaluation metrics. It should clearly present the performance of the proposed VIDEOLLM-MoD model against relevant baselines, ideally using statistically significant comparisons. Visualizations like charts and graphs are crucial for conveying performance across different datasets and tasks. The discussion should go beyond simple performance numbers; it should analyze strengths and weaknesses, explain any unexpected results, and address limitations of the benchmarking process itself. For instance, did the choice of baselines accurately reflect the current state-of-the-art? Were there any biases in dataset selection or metric choices that might influence the interpretation of the results? A strong section would also offer an in-depth qualitative analysis, perhaps showcasing illustrative examples demonstrating both the model’s successes and failures in specific scenarios. This approach would allow readers to form a comprehensive understanding of the model’s capabilities and limitations in relation to existing solutions.
Future Directions#
Future research directions for efficient video-language models could explore several promising avenues. Improving the scalability of Mixture-of-Depth (MoD) approaches is crucial, potentially investigating more sophisticated gating mechanisms or exploring alternative architectures entirely. Addressing the computational cost of online video processing is another key area; this could involve developing more efficient attention mechanisms or leveraging advanced hardware acceleration. Investigating the impact of vision token selection on downstream tasks is important; more detailed analysis into which aspects of visual information are crucial for specific tasks could lead to significant improvements in model performance and efficiency. Extending the approach to different video modalities, like incorporating audio and depth information, would greatly enhance the richness of the model’s understanding of video content. Finally, rigorous benchmarking and evaluation should be conducted on a wider range of datasets and tasks to provide a better understanding of the method’s capabilities and limitations.
More visual insights#
More on figures

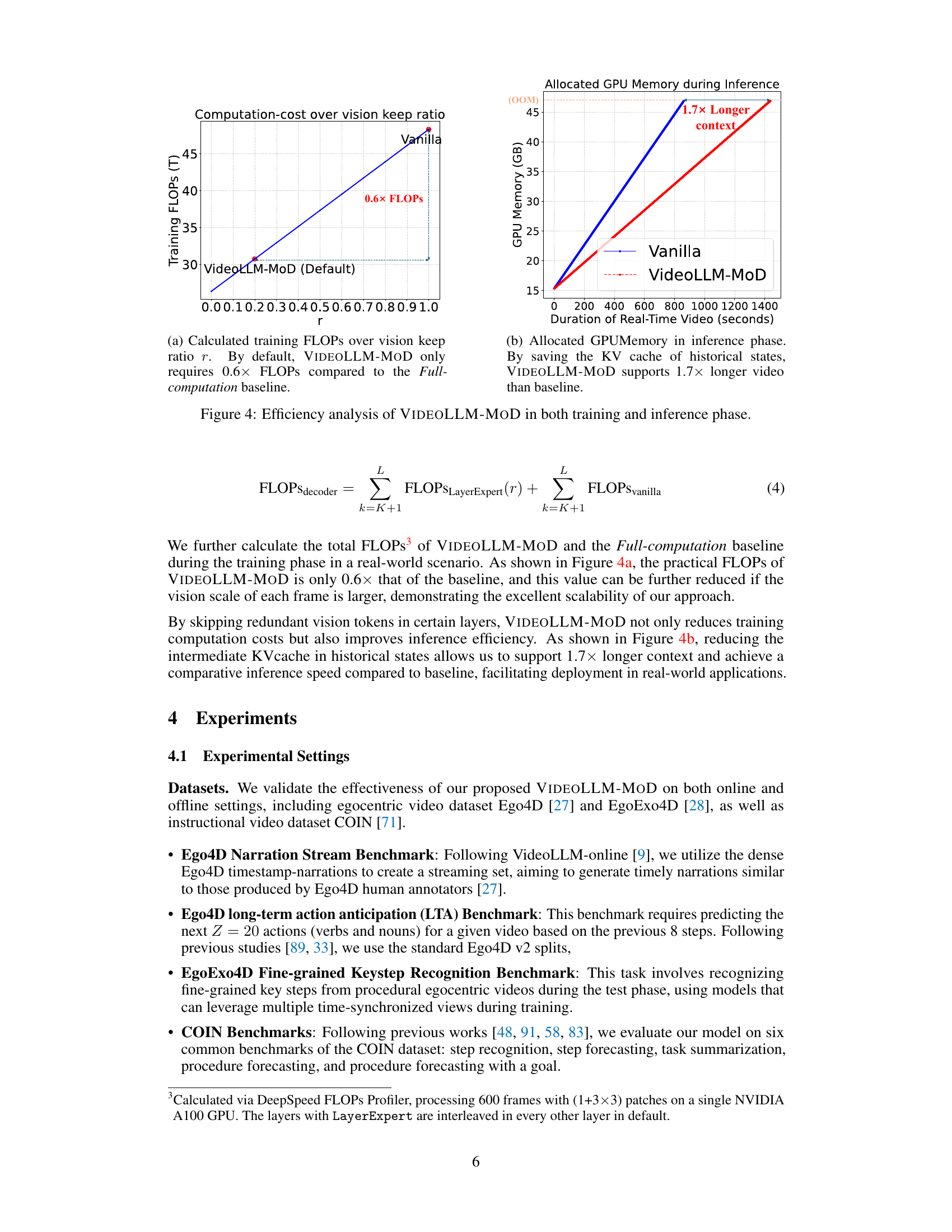
🔼 This figure shows a comparison of the training computation cost and memory usage between the baseline model and VIDEOLLM-MOD. The x-axis represents the training memory in GB, and the y-axis represents the single forward pass time in seconds. The baseline model shows a steep increase in computation cost and memory consumption as the number of vision tokens increases, while VIDEOLLM-MOD demonstrates significantly better efficiency with approximately 1.5x speedup and 0.3x GPU memory savings. This highlights the effectiveness of VIDEOLLM-MOD in reducing the computational burden associated with processing numerous vision tokens in long-term or streaming video.
read the caption
Figure 2: Training Computation Cost. VIDEOLLM-MOD exhibits greater efficiency compared to the baseline.

🔼 This figure illustrates the three different approaches for processing vision tokens in VIDEOLLM-MOD compared to a baseline. The first is the full computation of every vision token in every layer. The second, ‘Early Exit’, stops computing tokens early in the layers which causes a loss of important information and performance. The third, ‘Top-k route via LayerExpert’, intelligently selects and processes only the most crucial vision tokens per frame at certain layers, preserving performance and significantly reducing computation costs compared to the full computation method.
read the caption
Figure 3: VIDEOLLM-MOD selects the top-k vision tokens within each frame in certain layers via LayerExpert. We observe that performance drops dramatically with Early-exit as critical vision tokens miss subsequent processing. By retaining crucial vision tokens in certain layers and reducing redundant tokens that may mislead understanding, VIDEOLLM-MOD achieves better performance with significantly lower computation costs compared to Full-computation baseline.

🔼 This figure shows a comparison of VIDEOLLM-MOD and the baseline model in terms of computational cost and GPU memory usage during both training and inference. The left subplot (a) illustrates how the training FLOPs (floating-point operations) of VIDEOLLM-MOD scale with the vision keep ratio (r), demonstrating a significant reduction in computational cost compared to the baseline (0.6x FLOPs). The right subplot (b) highlights the improvement in memory efficiency during inference, enabling VIDEOLLM-MOD to handle 1.7 times longer videos than the baseline by saving on the KV cache storage of historical states.
read the caption
Figure 4: Efficiency analysis of VIDEOLLM-MOD in both training and inference phase.

🔼 This figure shows a comparison of VIDEOLLM-MOD and the vanilla model in terms of training FLOPs and inference GPU memory usage. Panel (a) shows that VIDEOLLM-MOD requires only 0.6x the FLOPs of the vanilla model during training, demonstrating its efficiency. Panel (b) shows that VIDEOLLM-MOD supports 1.7x longer video contexts than the vanilla model during inference, indicating its ability to handle long videos effectively. This improved efficiency is due to VIDEOLLM-MOD’s ability to skip redundant computation on vision tokens, resulting in significant memory savings.
read the caption
Figure 4: Efficiency analysis of VIDEOLLM-MOD in both training and inference phase.

🔼 This figure illustrates the VIDEOLLM-MOD approach and compares it to other methods for processing vision tokens in video. It shows how VIDEOLLM-MOD’s selective token processing (top-k route) leads to better performance and efficiency compared to full computation, where all tokens are processed in all layers, and early exit, which drops computation in later layers. The selective processing avoids losing important information while saving computation.
read the caption
Figure 3: VIDEOLLM-MOD selects the top-k vision tokens within each frame in certain layers via LayerExpert. We observe that performance drops dramatically with Early-exit as critical vision tokens miss subsequent processing. By retaining crucial vision tokens in certain layers and reducing redundant tokens that may mislead understanding, VIDEOLLM-MOD achieves better performance with significantly lower computation costs compared to Full-computation baseline.
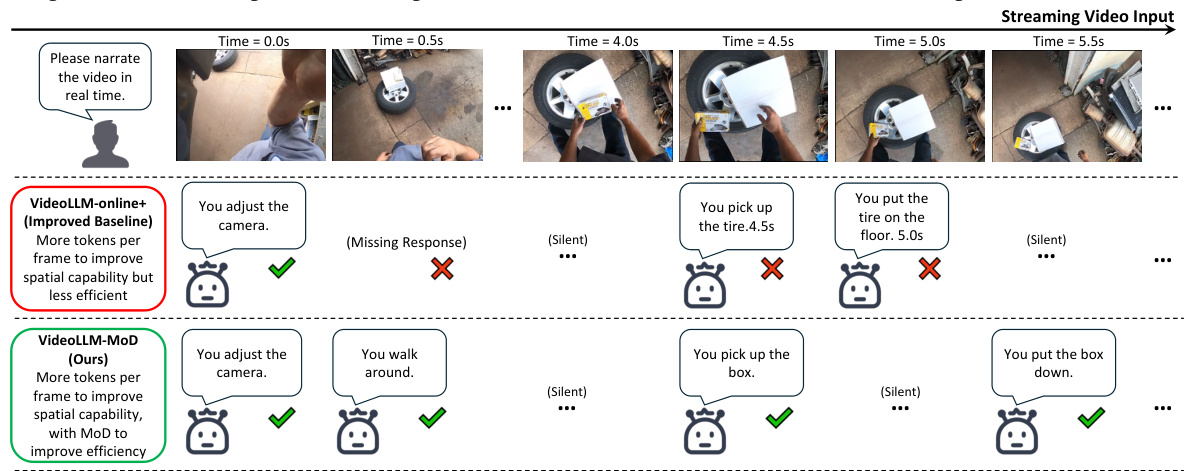
🔼 This figure shows a comparison of the performance of VIDEOLLM-MOD and VideoLLM-online+ (an improved baseline) on the Ego4D GoalStep dataset. The top row shows the video frames, and the bottom two rows show the results of each method. The results show that VIDEOLLM-MOD is able to correctly identify actions and provide more accurate narrations than VideoLLM-online+, even though it uses fewer computational resources. This demonstrates the effectiveness of VIDEOLLM-MOD for online video understanding.
read the caption
Figure 5: Cases of VIDEOLLM-MOD on Ego4D GoalStep [70] video data.

🔼 This figure illustrates three different approaches for processing vision tokens in a video-language model: full computation, early exit, and top-k routing via LayerExpert. The full computation approach processes all vision tokens in all layers. Early exit skips processing of a portion of vision tokens in intermediate layers which often leads to a performance degradation. The top-k routing via LayerExpert, which is VIDEOLLM-MOD’s approach, dynamically selects only the most critical vision tokens within each frame for processing in specific layers. This approach reduces computation cost without significantly harming model performance because it preserves essential visual information while eliminating redundant ones.
read the caption
Figure 3: VIDEOLLM-MOD selects the top-k vision tokens within each frame in certain layers via LayerExpert. We observe that performance drops dramatically with Early-exit as critical vision tokens miss subsequent processing. By retaining crucial vision tokens in certain layers and reducing redundant tokens that may mislead understanding, VIDEOLLM-MOD achieves better performance with significantly lower computation costs compared to Full-computation baseline.
More on tables

🔼 This ablation study examines the impact of different LayerExpert insertion strategies on model performance. The ‘All’ strategy inserts LayerExpert in every layer, while ‘All-Deep’ only inserts it in the deeper layers. The ‘Interleaved’ strategy inserts LayerExpert in every other layer, and ‘Interleaved-Deep’ does the same but only in deeper layers. The table shows that the Interleaved strategy provides the best balance between performance (Fluency and LM-Correctness) and computational cost (FLOPs).
read the caption
Table 2: Ablations on the insertion strategy of LayerExpert in transformer layers. The Interleaved strategy strikes the best trade-off among the variants.
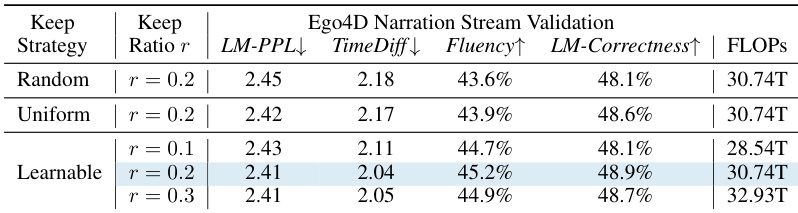
🔼 This table presents the ablation study on different vision token selection strategies used in VIDEOLLM-MOD. It compares the performance (LM-PPL, TimeDiff, Fluency, LM-Correctness) and computational cost (FLOPs) across three strategies: random selection, uniform selection, and the learnable approach (LayerExpert). The learnable method, which dynamically selects tokens based on importance, demonstrates the best performance while balancing efficiency. Different keep ratios (r) are also tested within the learnable method to demonstrate performance across different levels of vision token sparsity.
read the caption
Table 3: Ablations on different vision selection strategies. Choosing which vision tokens to process is crucial for efficient vision computation allocation.

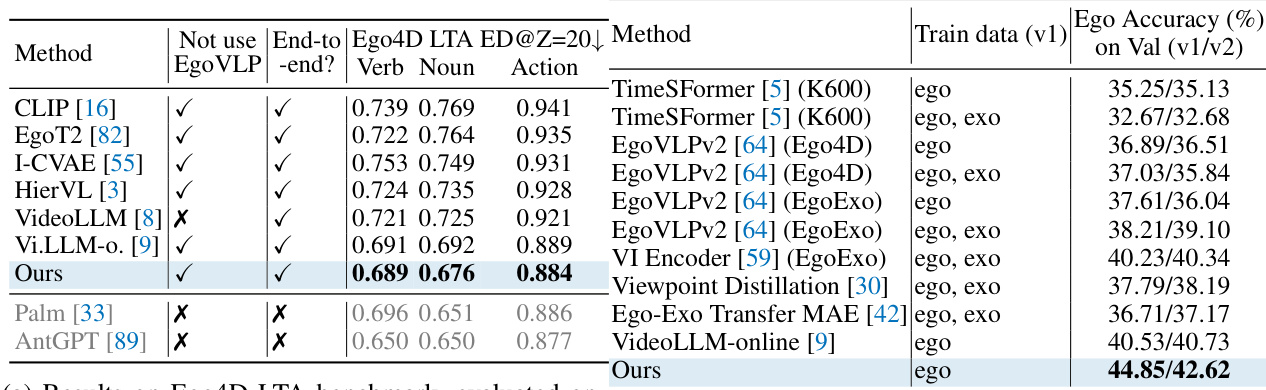
🔼 This table presents the results of the VIDEOLLM-MOD model and several baseline models on six common benchmarks from the COIN dataset. The benchmarks assess the model’s performance on various tasks related to instructional videos, including step recognition, task recognition, and several forecasting tasks. The ‘Not use HowTo100M’ column indicates whether the HowTo100M dataset was used in training.
read the caption
Table 4: Results on COIN benchmarks (left to right): step recognition, task recognition, next forecasting, procedure forecasting, procedure forecasting with a goal.
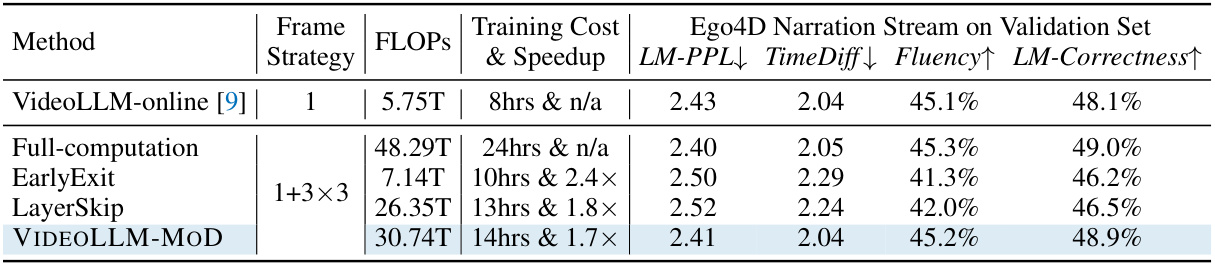
🔼 This table presents the results of online experiments conducted on the Ego4D narration stream benchmark. It compares the performance of VIDEOLLM-MOD against several baseline methods, including the full-computation model (which processes all vision tokens), early exit, and LayerSkip. The metrics used for comparison include Language Modeling Perplexity (LM-PPL), Time Difference (TimeDiff), Fluency, and LM-Correctness. The table highlights that VIDEOLLM-MOD achieves similar performance to the full-computation model but at a significantly reduced computational cost.
read the caption
Table 1: Online experiments on the Ego4D narration benchmark. VIDEOLLM-MOD achieves comparable metrics to the Full-computation baseline with less computation cost.

🔼 This table presents the results of online experiments conducted on the Ego4D narration benchmark. Several models are compared, including a baseline with full computation and the proposed VideoLLM-MoD. Metrics shown include language model perplexity (LM-PPL), time difference (TimeDiff), fluency, and LM correctness. The table highlights VideoLLM-MoD’s ability to achieve comparable performance to the full-computation model while significantly reducing computational cost, indicating improved efficiency.
read the caption
Table 1: Online experiments on the Ego4D narration benchmark. VIDEOLLM-MOD achieves comparable metrics to the Full-computation baseline with less computation cost.

🔼 This table presents the results of the proposed VIDEOLLM-MOD and the baseline method LLaMA-VID on four general image benchmarks: GQA, MME, POPE, and SQA. It compares the performance (accuracy scores) of both models while highlighting the significant reduction in training cost achieved by VIDEOLLM-MOD (5.8 TFLOPs and 10.5 hours compared to 9.8 TFLOPs and 52.5 hours for LLaMA-VID). This demonstrates the efficiency gains offered by VIDEOLLM-MOD without compromising performance.
read the caption
Table 7: Results on general image benchmarks.

🔼 This table presents the results of the proposed VIDEOLLM-MOD model and the baseline model LLaMA-VID on three common video question answering benchmarks: MSVD-QA, MSRVTT-QA, and ActivityNet-QA. The results show accuracy (Acc) and score for each benchmark and highlight the improvement in performance and training efficiency achieved by VIDEOLLM-MOD compared to LLaMA-VID.
read the caption
Table 8: Results on general video benchmarks.
🔼 This table presents the results of online experiments conducted on the Ego4D narration benchmark, comparing the performance of different methods. It shows that VIDEOLLM-MOD achieves comparable results to the full computation method, but with significantly reduced computational cost. The methods compared include the VideoLLM-online baseline, Full-computation, EarlyExit and LayerSkip. The metrics used for comparison include Language Modeling Perplexity (LM-PPL), Time Difference (TimeDiff), Fluency, and Language Model Correctness (LM-Correctness).
read the caption
Table 1: Online experiments on the Ego4D narration benchmark. VIDEOLLM-MOD achieves comparable metrics to the Full-computation baseline with less computation cost.
Full paper#