↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning (FL) faces challenges when adapting foundation models to diverse tasks while maintaining privacy. Existing methods struggle with test-time distribution shifts and aligning user preferences. This paper introduces FedDPA, a novel framework that addresses these issues.
FedDPA employs a dual-adapter approach. A global adapter learns general features through federated training, while a local adapter personalizes the model for each client. An instance-wise weighting mechanism dynamically combines these adapters during inference, optimizing for both personalization and robustness to unseen data distributions. Experiments on benchmark NLP tasks show FedDPA outperforms existing methods in test-time personalization, demonstrating its effectiveness in real-world applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning and foundation models. It addresses the critical and under-researched problem of test-time distribution shifts in personalized federated foundation models, offering a novel solution for improving model robustness and performance in real-world applications. The proposed method, FedDPA, is efficient and effective, opening new avenues for research in personalized FL and paving the way for more practical FedFM implementations.
Visual Insights#
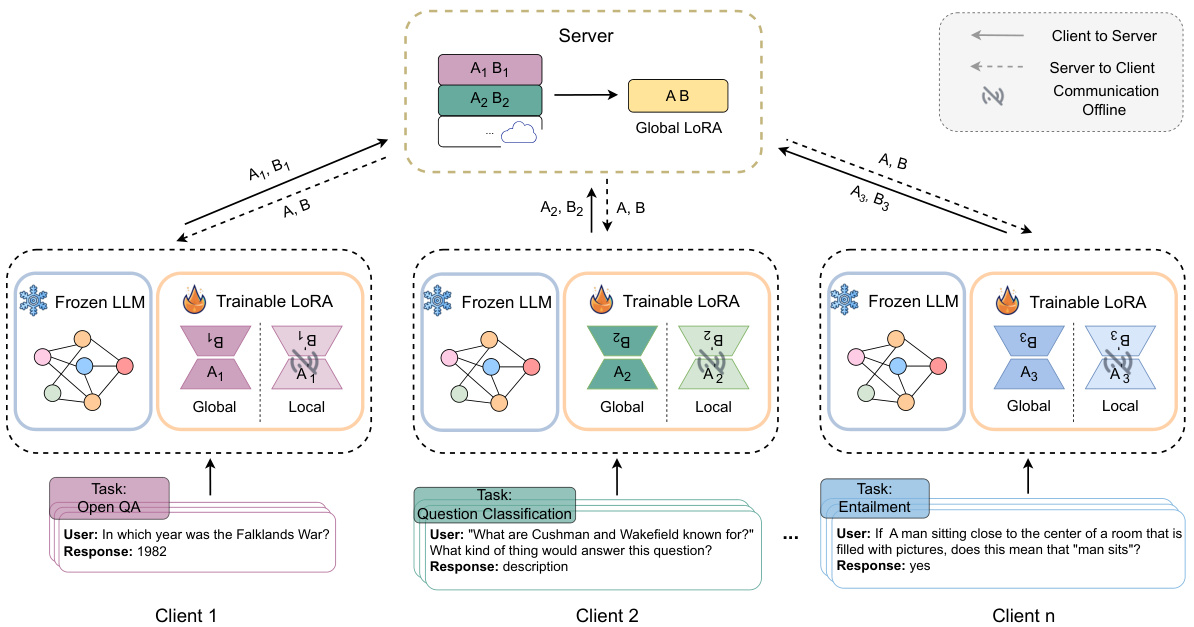
This figure illustrates the architecture of the Federated Dual-Personalizing Adapter (FedDPA) framework. Each client has a frozen large language model (LLM) with two adapters: a global adapter for handling unseen test-time tasks and a local adapter for personalization. During training, only the global adapter’s parameters are sent to the server for aggregation, enhancing efficiency and privacy. The figure showcases three clients, each with different tasks (Open QA, Question Classification, and Entailment), highlighting the distributed and personalized nature of the FedDPA approach.
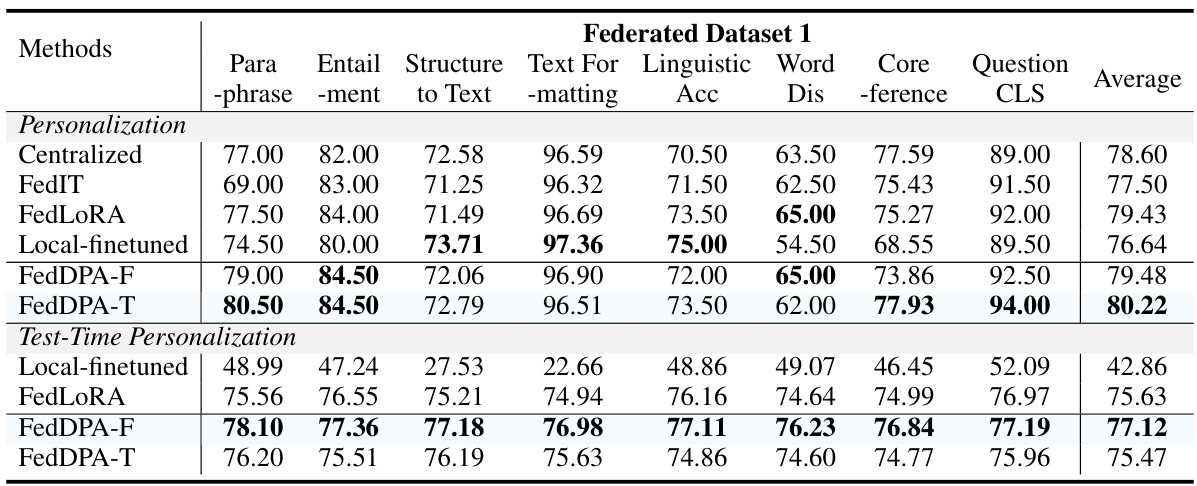
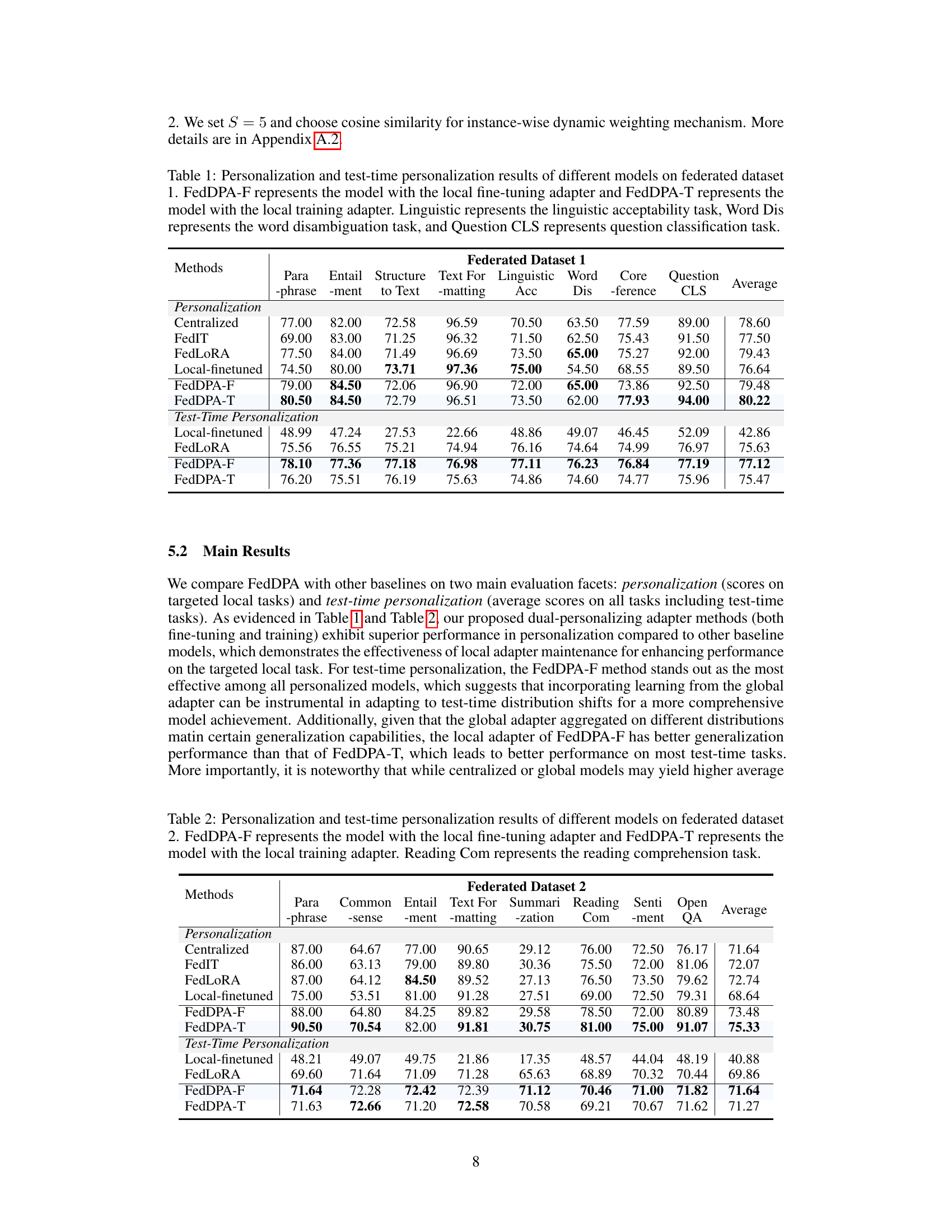
This table presents the performance comparison of various models (Centralized, FedIT, FedLORA, Local-finetuned, FedDPA-F, and FedDPA-T) on a federated dataset for both personalization (performance on the targeted local task) and test-time personalization (performance on unseen test tasks). The results are broken down by individual NLP tasks (Paraphrase, Entailment, Structure to Text, Text Formatting, Linguistic Acceptability, Word Disambiguation, Coreference, and Question Classification) and provide average scores across tasks.
In-depth insights#
FedFM Personalization#
Federated Foundation Models (FedFMs) personalization presents a unique challenge in adapting powerful foundation models to individual user preferences while preserving data privacy. The core tension lies in balancing the benefits of centralized model learning (for efficiency and generalization) with the need for personalized adaptations specific to each client’s data distribution. Parameter-efficient fine-tuning (PEFT) methods are often leveraged to mitigate communication and computational overheads inherent in traditional federated learning approaches. However, even with PEFT, ensuring that personalization effectively caters to diverse user preferences without compromising model accuracy or overall system efficiency remains a significant hurdle. A key consideration is the non-IID nature of client data, which can lead to performance discrepancies among clients. Solutions often involve techniques such as federated averaging or more sophisticated personalization strategies that aim to account for heterogeneity and potentially changing data distributions across clients over time. Security and privacy implications are paramount; solutions must ensure that no sensitive user data is exposed during the personalization process. The balance between personalization and robust generalization to unseen data (test-time distribution shift) requires careful consideration of model architecture, training methodology and post-training adaptation strategies.
Dual-Adapter Approach#
A dual-adapter approach in federated learning, particularly for foundation models, offers a compelling strategy to address test-time distribution shifts and personalization simultaneously. By employing separate global and local adapters, the framework aims to learn generic features robust to unseen data distributions while also tailoring the model to individual client preferences. The global adapter, trained collaboratively across clients using federated learning, captures shared knowledge applicable to various tasks, enhancing generalization. In contrast, the local adapter, trained on a client’s private data, facilitates personalization. Dynamic weighting mechanisms elegantly integrate these adapters during inference, achieving a balance between generalization and personalization tailored to each test instance. This innovative approach not only tackles the limitations of existing parameter-efficient fine-tuning methods in dealing with distribution shifts but also enhances the efficiency and privacy aspects inherent in federated learning systems. The success of such a method hinges critically on the effectiveness of the dynamic weighting, which needs to be carefully designed to appropriately balance global and local model contributions.
Dynamic Weighting#
The concept of ‘dynamic weighting’ in the context of a research paper likely involves an adaptive mechanism that adjusts the influence of different components or factors over time or across various instances. This could manifest in several ways. For example, in a federated learning setting, dynamic weighting could balance the contributions of globally aggregated knowledge and locally specific data. This could involve weighting the contributions of each client’s model based on factors such as data quality, distribution similarity, or model performance. Another application could be adjusting the weights of individual parameters or layers in a neural network, modifying their impact on the final output. This might be based on input characteristics, error signals, or even user-specified preferences. A key aspect of dynamic weighting is its responsiveness to changing conditions. This implies the presence of a feedback loop or other monitoring mechanism that triggers adjustments to the weights. The in-depth analysis would likely delve into the specific algorithm, parameters, and factors influencing the weighting process, as well as the performance gains obtained through the use of this adaptive method.
Test-Time Shifts#
Test-time shifts, a critical concern in machine learning, pose unique challenges when deploying models in real-world scenarios. These shifts refer to discrepancies between the training data distribution and the distribution encountered during the model’s operational phase. This is particularly problematic for federated learning, where data is decentralized and may exhibit significant heterogeneity. Robustness to such shifts is paramount for reliable performance. Strategies to address this issue include incorporating data augmentation techniques to expand the training set and make it more representative of deployment environments, as well as developing models with strong generalization capabilities. Furthermore, parameter-efficient fine-tuning methods coupled with techniques to adjust the model based on feedback from the real-world data can mitigate the effect of distribution drifts. Addressing test-time shifts in the context of federated learning is particularly challenging due to data privacy concerns and communication bandwidth constraints. Therefore, methods that minimize the amount of data transmission and processing while maintaining adaptability are crucial for practical applications.
Future of FedFM#
The future of Federated Foundation Models (FedFM) hinges on addressing several key challenges. Improving efficiency is paramount, as current FedFM methods often suffer from high communication and computational overheads, especially when dealing with large language models. Enhanced personalization techniques are needed to better tailor models to individual user preferences and diverse data distributions across clients. Robustness against test-time distribution shifts is crucial for real-world deployment, as models must generalize well to unseen data and tasks. Privacy-preserving techniques need to be further strengthened to mitigate potential risks associated with sharing model updates and data across a decentralized network. Research into novel model architectures and training strategies is essential for optimizing FedFM performance, possibly involving techniques such as federated learning with differential privacy or secure multi-party computation. Finally, standardization and interoperability across different FedFM implementations are crucial for wider adoption and collaboration among researchers and practitioners. Addressing these challenges will unlock the full potential of FedFM for diverse applications, including personalized medicine, collaborative scientific discovery, and privacy-preserving AI development.
More visual insights#
More on figures

This figure illustrates two different approaches for training the local adapter (LoRA) within the Federated Dual-Personalizing Adapter (FedDPA) framework. The left side shows the two local adapter training methods: (a) FedDPA-F, where the local adapter is fine-tuned after global adapter training, and (b) FedDPA-T, where the local adapter is trained iteratively alongside the global adapter. The right side depicts the overall learning process for each method, showing the stages of global LoRA learning and local LoRA learning (fine-tuning or training) across communication rounds. The different training schedules highlight the key difference in how the global and local adapters are updated and how this influences their interaction during prediction.

This figure illustrates the architecture of the Federated Dual-Personalizing Adapter (FedDPA) framework. Each client in the federated learning system has a frozen large language model (LLM), a global adapter (LoRA) for learning generic knowledge applicable to various tasks, and a local adapter (LoRA) for personalization. During training, only the global adapter’s parameters are sent to the server for aggregation, enhancing efficiency and privacy. The figure shows data flow between clients and the server, highlighting the communication process and model components for both training and testing.
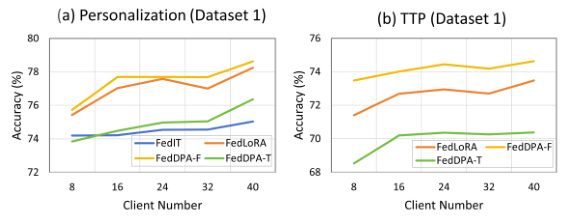
This figure presents two subfigures showing the convergence analysis of the proposed FedDPA methods against other baselines for personalization and test-time personalization. The first subfigure (a) displays the average performance on target local tasks across all clients, demonstrating the faster convergence of FedDPA methods compared to FedIT and superior performance compared to FedLoRA. The second subfigure (b) illustrates the average performance on all tasks, including test-time tasks, reinforcing that FedDPA achieves faster convergence.

This figure illustrates two different methods for training the local adapter in the Federated Dual-Personalizing Adapter (FedDPA) framework. The left side shows the two approaches: (a) FedDPA-F (fine-tuning): The global adapter is trained first, and then the local adapter is initialized with the global adapter’s parameters and fine-tuned. (b) FedDPA-T (training): The global and local adapters are trained iteratively in each communication round. The right side shows the overall learning process for each approach, highlighting the interaction between the local and global adapter training and the communication rounds with the server.
More on tables

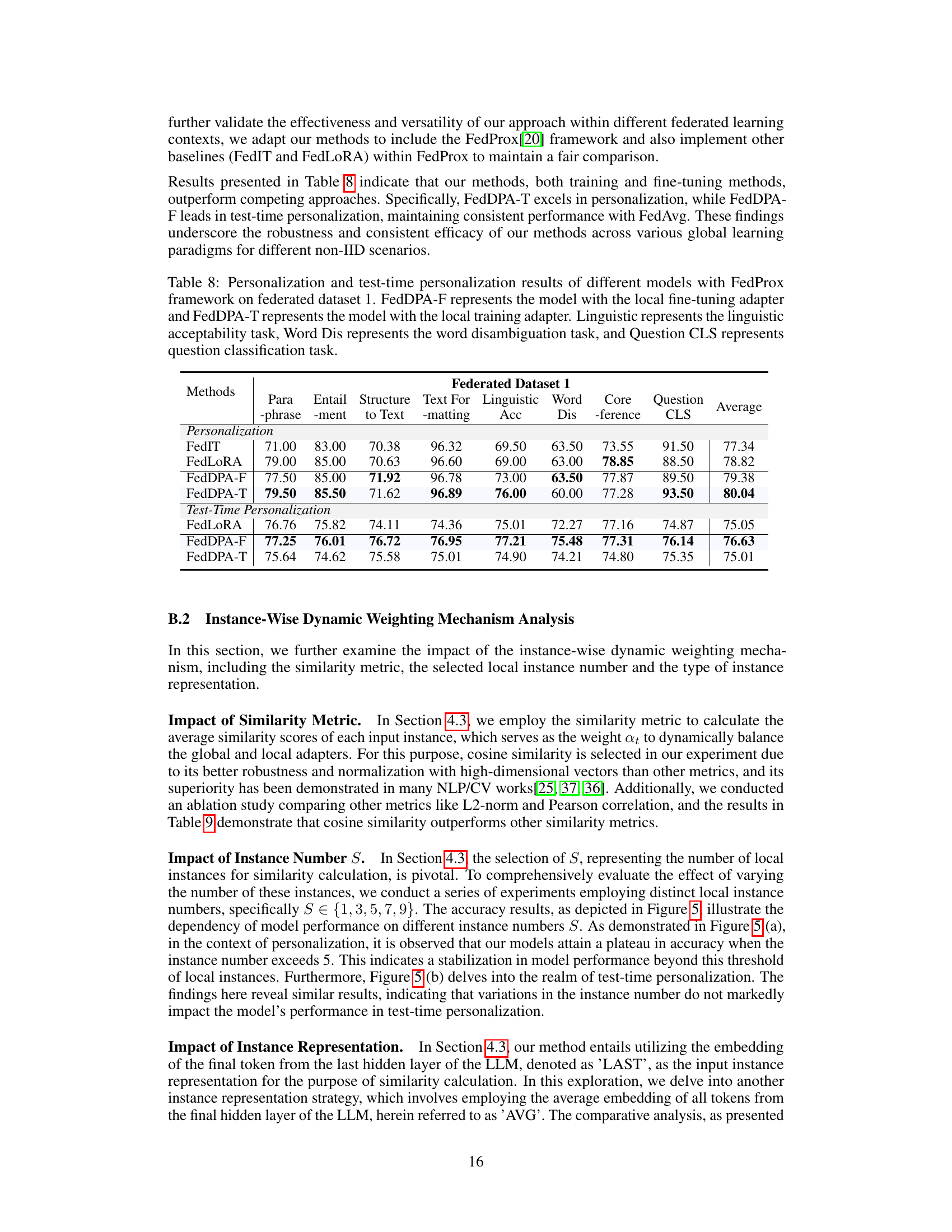
This table presents the performance of various federated learning models on a second federated dataset. It shows how well the models perform in terms of personalization (on the targeted tasks for each client) and test-time personalization (on tasks unseen during training). FedDPA-F and FedDPA-T are the authors’ proposed methods, distinguished by whether local adapters are fine-tuned or trained from scratch. The table provides a quantitative comparison across multiple tasks.
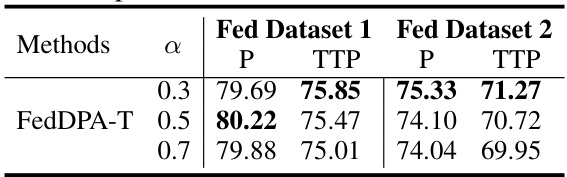
This table presents the results of an ablation study on the updating weight (α) used in the FedDPA-T model. It shows the performance of the model in terms of personalization (P) and test-time personalization (TTP) across two federated datasets (Dataset 1 and Dataset 2) with different values of α (0.3, 0.5, and 0.7). The results demonstrate how the weighting of the local and global adapters affects the model’s performance on both targeted tasks and unseen test-time tasks. The aim is to find the optimal balance between personalization and generalization.
This table presents a comparison of different models’ performance on a federated dataset in terms of personalization (accuracy on the targeted task) and test-time personalization (average accuracy across all tasks including unseen test-time tasks). The models compared include a centralized model, FedIT, FedLoRA, a locally finetuned model, and two variants of the proposed Federated Dual-Personalizing Adapter (FedDPA): one with local fine-tuning (FedDPA-F) and one with local training (FedDPA-T). The table shows the performance for three specific tasks: Linguistic Acceptability, Word Disambiguation, and Question Classification, alongside an average score across all tasks.

This table presents a comparison of the performance of different models on a federated dataset focusing on two key aspects: personalization (how well the model adapts to individual client data) and test-time personalization (how well the model generalizes to new, unseen tasks during the testing phase). The models compared include centralized training (all data combined), FedIT, FedLORA, a locally fine-tuned model, and two versions of the proposed FedDPA method (one with fine-tuning of the local adapter and one with training of the local adapter). The results are shown for several NLP tasks: linguistic acceptability, word disambiguation, coreference, paraphrase, entailment, question classification, and text-to-structure.

This table presents a comparison of the performance of various models on a federated dataset, focusing on two key aspects: personalization (how well the model adapts to specific client data) and test-time personalization (how well the model generalizes to unseen tasks during testing). The models compared include centralized, FedIT, FedLoRA, locally fine-tuned models, and the proposed FedDPA models (FedDPA-F and FedDPA-T). The table shows performance metrics for several NLP tasks.

This table presents a comparison of various Federated Foundation Models (FFMs) on two key performance metrics: personalization and test-time personalization. Personalization measures how well each model adapts to the specific tasks of individual clients, whereas test-time personalization assesses the models’ ability to generalize to new, unseen tasks during the testing phase. The table includes results for several baseline FFMs, as well as the proposed FedDPA-F and FedDPA-T models. The results are broken down by individual tasks (Linguistic, Word Disambiguation, Question Classification) to provide a detailed comparison of model performance.

This table presents a comparison of different model’s performance on a federated dataset focusing on two key aspects: personalization (how well the model adapts to each client’s specific task) and test-time personalization (how well it generalizes to unseen tasks during testing). It compares a centralized model, FedIT, FedLoRA, a local-finetuned model, and two versions of the proposed FedDPA model (FedDPA-F and FedDPA-T). The results are broken down by specific NLP tasks (Linguistic, Word Disambiguation, Coreference, Paraphrase, Question Classification, and Text-to-Text).

This table presents the performance comparison of various federated learning models on a specific dataset. It shows the performance in terms of personalization (how well the model adapts to individual user preferences) and test-time personalization (how well the model generalizes to new, unseen tasks). The models compared include a centralized model (trained on all data), a local-finetuned model (trained only on local data), FedIT, FedLoRA, and two versions of the proposed FedDPA model (FedDPA-F and FedDPA-T, which differ in how the local adapter is trained). Results are presented for several NLP tasks, including linguistic acceptability, word disambiguation, and question classification.
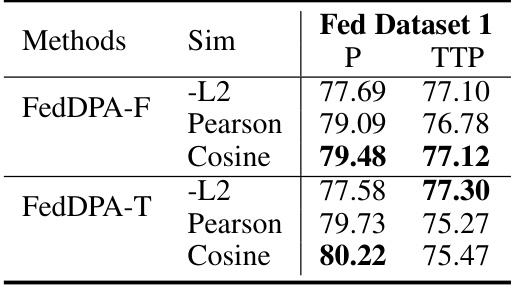
This table presents the ablation study results on the impact of different similarity metrics used in the instance-wise dynamic weighting mechanism of the FedDPA model. It compares the performance of the model using three different similarity metrics: L2-norm, Pearson correlation, and cosine similarity, for both personalization and test-time personalization tasks. The results show that the cosine similarity metric outperforms the other two metrics in terms of both personalization and test-time personalization performance.
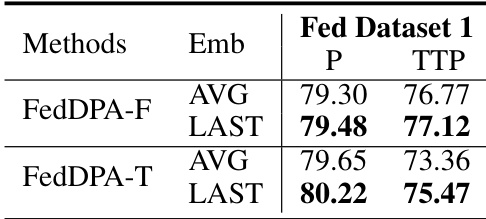
This table presents the ablation study result of the instance representation method in the proposed FedDPA model. Two different methods were compared: using the embedding of the last token from the final hidden layer of the LLM (LAST) and using the average embedding of all tokens from the final hidden layer of the LLM (AVG). The results are reported for both personalization (P) and test-time personalization (TTP) performance on Federated Dataset 1.
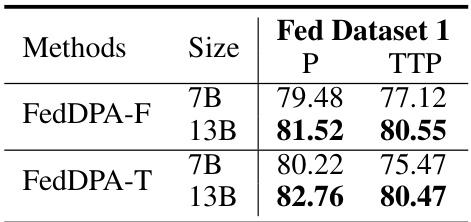
This table presents a comparison of different models’ performance on a federated dataset focusing on two aspects: personalization (how well the model performs on the specific tasks for each client) and test-time personalization (how well the model generalizes to unseen tasks). It shows the average performance across several NLP tasks for each model, including the proposed FedDPA models (FedDPA-F and FedDPA-T, which represent different approaches to local adapter training). The results highlight the trade-offs between personalization and generalization to new tasks.

This table compares the performance of different models (Centralized, FedIT, FedLORA, Local-finetuned, FedDPA-F, and FedDPA-T) on a federated dataset for both personalization (performance on the target local task) and test-time personalization (average performance across all tasks, including test-time tasks). The results show that FedDPA models generally outperform other methods, particularly FedDPA-F for test-time personalization.

This table presents the average inference time per instance for different models. It compares the inference time of FedLoRA, FedDPA without the instance-wise dynamic weighting mechanism (FedDPA (w/o auto)), and FedDPA with the mechanism. The table shows that adding the instance-wise dynamic weighting mechanism increases the inference time slightly, but the increase is minimal, demonstrating that the improved performance comes at a low computational cost.

This table presents the results of applying four different federated learning models (FedIT, FedLORA, FedDPA-F, and FedDPA-T) to three unseen test-time tasks: summarization, reading comprehension, and open-domain question answering. The models were initially trained on Federated Dataset 1, which contained seen tasks. The table shows both the average (AVG) and maximum (MAX) performance scores across all clients for each model on each unseen task. The purpose is to evaluate the models’ ability to generalize to tasks not seen during training, simulating a real-world scenario.
Full paper#