TL;DR#
Many existing image fusion techniques struggle with dynamic fusion and lack theoretical justification, leading to potential deployment risks. This paper tackles this challenge by introducing a generalized form of image fusion and deriving a new test-time dynamic image fusion (TTD) paradigm. The core issue is that most existing methods are unable to adapt dynamically to varying conditions in the input images. This often leads to suboptimal results, especially when dealing with complex scenes or multiple sources of information.
The proposed TTD method addresses these limitations by decomposing the fused image into multiple components representing information from each source. The relative dominance of each source, referred to as Relative Dominability (RD), is used as a dynamic fusion weight. Theoretically, this approach is proven to reduce the upper bound of generalization error. Experiments show that TTD consistently outperforms existing methods across various fusion tasks, demonstrating its robustness and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers in image fusion because it provides a novel test-time dynamic image fusion paradigm with a theoretical guarantee. This addresses a critical limitation of existing methods and opens up new avenues for research in dynamic image fusion with clear theoretical justifications. The proposed approach shows improved performance across various image fusion tasks without the need for additional training or parameters, which is highly valuable. It also provides insights into the relationship between fusion weights and generalization error, offering a valuable contribution to the theoretical foundations of image fusion.
Visual Insights#

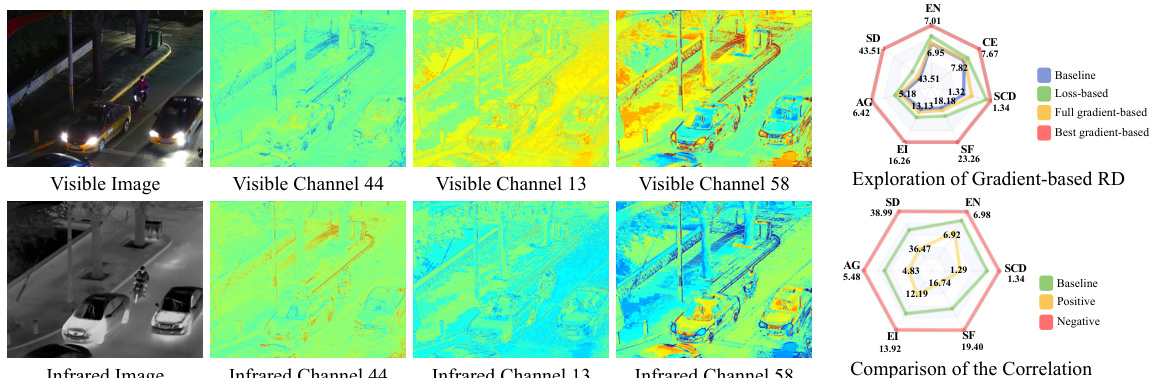
🔼 This figure visualizes the Relative Dominability (RD) for each source image across four different image fusion tasks: Visible-Infrared Fusion (VIF), Medical Image Fusion (MIF), Multi-Exposure Fusion (MEF), and Multi-Focus Fusion (MFF). The RD metric quantifies the importance of each individual source image in the fusion process. For each task, and for each source image, a heatmap shows the RD values. Higher RD values indicate greater dominance in the resultant fused image. This visualization is meant to demonstrate how the Relative Dominability dynamically highlights the dominant regions of each source image during fusion, which is a key component of their proposed Test-Time Dynamic Image Fusion (TTD) method.
read the caption
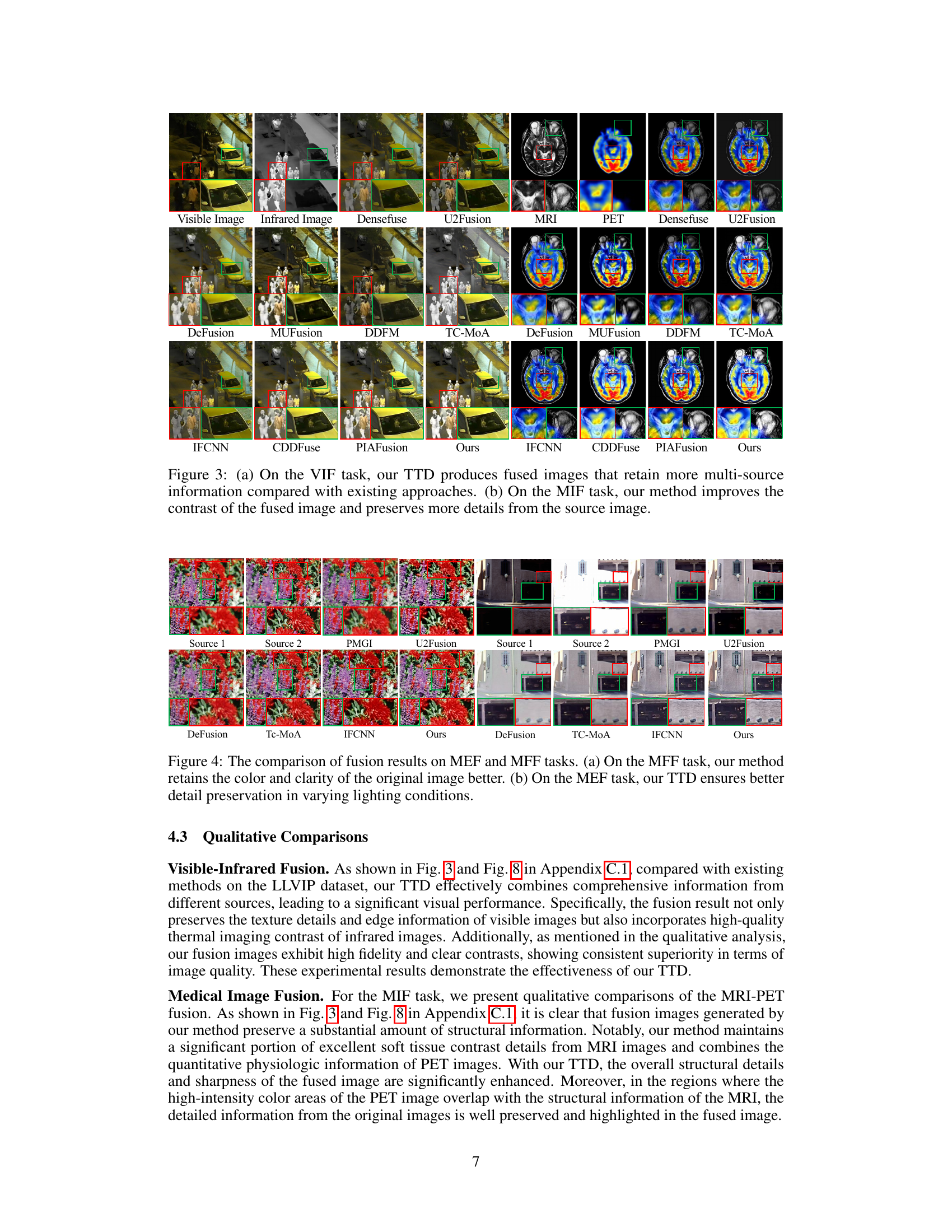
Figure 1: We visualized the Relative Dominablity (RD) of each source on four tasks, which effectively highlights the dominance of uni-source in image fusion.
🔼 This table presents a quantitative comparison of various image fusion methods on two visible-infrared datasets (LLVIP and MSRS). The performance is evaluated using seven metrics (EN, SD, AG, EI, SF, SCD, and CE). The table includes both baseline methods and those enhanced with the proposed TTD (Test-Time Dynamic) approach. The color-coding and bolding highlight the best and second-best performing methods and improvements achieved by adding the TTD.
read the caption
Table 1: Quantitative performance comparison of different fusion strategies on visible-infrared datasets. The 'TTD' suffix and gray background indicates our method is applied to this baseline. The red and blue represent the best and second-best result respectively. The bold indicates the baseline w/ TTD performance better than that w/o TTD. We used to illustrate the amount of improvement our TTD method achieved compared to the baseline.
In-depth insights#
Dynamic Fusion#
Dynamic image fusion aims to intelligently integrate information from multiple sources, adapting to the varying importance of each source across different image regions. Unlike static fusion methods that apply a fixed weighting scheme, dynamic fusion allows the weights to change based on the local content of the input images. This adaptability leads to superior performance in preserving details and enhancing visual quality. The core concept revolves around the Relative Dominability (RD), a measure of how influential a particular source is for a specific image region. RD allows the algorithm to dynamically adjust weights, emphasizing the most relevant source for each pixel. The theoretical justification for dynamic fusion often centers on reducing the generalization error, demonstrating the advantage of this adaptive approach over static methods. The RD, as a dynamic fusion weight, has been shown to improve performance across a range of image fusion tasks, including visible-infrared, multi-exposure, and multi-focus fusion, by enhancing both objective and perceptual quality. Although computationally more complex than static methods, the improved results demonstrate that the added computational cost is justified.
TTD Paradigm#
The core of the proposed research lies in the introduction of a novel Test-Time Dynamic (TTD) image fusion paradigm. This paradigm fundamentally shifts the approach to image fusion by dynamically adjusting fusion weights during the testing phase, rather than relying on static weights learned during training. This dynamic adjustment is data-driven and is based on a theoretical understanding of generalization error, aiming to improve the model’s ability to generalize to unseen data. The key innovation is the introduction of Relative Dominability (RD), a measure that quantifies the relative importance of each source image in constructing the fused image. RD is directly used as a dynamic fusion weight, which theoretically reduces the upper bound of generalization error. Instead of fixed weights, RD dynamically highlights dominant regions within each source image, leading to a more robust and adaptive fusion process. This approach avoids the need for additional training or fine-tuning, thus reducing computational costs and complexity while showing promising results across multiple image fusion benchmarks. The method’s theoretical foundation and demonstrated empirical success positions TTD as a significant step forward in the field.
Generalization Error#
The concept of ‘Generalization Error’ is central to understanding the paper’s contribution to test-time dynamic image fusion. The authors theoretically prove that dynamic fusion methods outperform static ones by analyzing the upper bound of generalization error. They achieve this by decomposing the fused image into uni-source components, revealing that the key to reducing error is the negative correlation between the fusion weights and the reconstruction loss of these components. This decomposition allows for the introduction of Relative Dominability (RD), a dynamic fusion weight directly correlated with generalization performance, thereby enhancing the model’s ability to generalize to unseen data. This theoretical grounding distinguishes this work from previous dynamic fusion methods that largely lacked such guarantees, making this a significant contribution. The use of RD is thus not merely an empirical choice but a principled approach with provable benefits. The analysis highlights the importance of choosing fusion weights that dynamically adjust to the dominance of different sources based on reconstruction loss, ultimately improving generalization and leading to more robust fusion results.
RD Weighting#
The concept of ‘RD Weighting,’ likely referring to Relative Dominability weighting, is a crucial component of the proposed Test-Time Dynamic Image Fusion (TTD) method. It introduces a dynamic fusion strategy that adapts to the varying dominance of different image sources in different regions, directly impacting the quality of the fused image. By decomposing the fused image into multiple components, each corresponding to a source, RD quantifies the relative importance of each source in each region of the fused image. This pixel-level RD score is then used as a weight to combine those components, effectively highlighting dominant regions and suppressing less relevant ones. The theoretical underpinning of RD weighting rests on minimizing generalization error. The key finding is that a negative correlation between RD and the reconstruction error for each source component leads to better generalization. This means that regions where a source’s contribution is weak (high reconstruction loss) get down-weighted by the RD score, while regions of strong contribution receive higher weights. This ensures robust fusion results even with noisy or incomplete information from individual sources, effectively balancing the information contribution of all input sources.
Future works#
The paper’s core contribution is a novel Test-Time Dynamic Image Fusion (TTD) paradigm, theoretically proven superior to static methods. Future work could explore several avenues to expand on this foundation. Firstly, investigating alternative dynamic weight mechanisms beyond the Relative Dominability (RD) approach, perhaps incorporating more sophisticated learning strategies or multi-scale analysis, could further improve performance and adaptability. Secondly, extending the TTD framework to handle more complex fusion tasks involving greater numbers of input sources or diverse data modalities would showcase its true generalization capabilities. Finally, the paper’s reliance on pre-trained encoders suggests a rich area for future research; developing a unified framework that learns both the fusion weights and feature extractors concurrently would eliminate the need for separate model training and potentially enhance overall performance. Such advancements could solidify TTD’s role as a state-of-the-art image fusion technique.
More visual insights#
More on figures

🔼 This figure illustrates the Test-Time Dynamic (TTD) image fusion framework. It shows how the fused image is decomposed into uni-source components (visible and infrared in this example). The key to reducing generalization error is a negative correlation between the fusion weight and the reconstruction loss of each component. The Relative Dominability (RD) of each source is calculated, and this RD serves as the dynamic fusion weight, highlighting the dominant regions of each source in the fused image.
read the caption
Figure 2: The framework of our TTD. Deriving from the generalization theory, we decompose fused images into uni-source components and find the key to reducing generalization error upper bound is the negative correlation between the fusion weight and reconstruction loss. Accordingly, we propose pixel-wise Relative Dominablity (RD) for each source, which is negatively correlation with the reconstruction loss and highlights the dominant regions of uni-source in constructing fusion images.

🔼 This figure visualizes the Relative Dominability (RD) for four different image fusion tasks: Visible-Infrared Fusion (VIF), Medical Image Fusion (MIF), Multi-Exposure Fusion (MEF), and Multi-Focus Fusion (MFF). For each task, it shows the RD heatmaps for each source image. The RD values indicate the relative importance of each source image in constructing the final fused image. High RD values in a specific region indicate that the corresponding source image is more dominant in that region of the fused image. This visualization demonstrates how the proposed method dynamically weights the contribution of different source images according to their relative dominance in different regions, leading to an improved fused image.
read the caption
Figure 1: We visualized the Relative Dominablity (RD) of each source on four tasks, which effectively highlights the dominance of uni-source in image fusion.

🔼 This figure visualizes the Relative Dominability (RD) for each source across four different image fusion tasks: Visible-Infrared Fusion (VIF), Medical Image Fusion (MIF), Multi-Exposure Fusion (MEF), and Multi-Focus Fusion (MFF). For each task, it shows the RD maps for each source image, highlighting the regions where each source is most dominant in contributing to the fused image. This helps to demonstrate the effectiveness of using RD as a dynamic fusion weight, as it highlights the regions where individual sources contribute the most information, rather than relying on a fixed weighting scheme.
read the caption
Figure 1: We visualized the Relative Dominablity (RD) of each source on four tasks, which effectively highlights the dominance of uni-source in image fusion.
🔼 This figure visualizes the Relative Dominability (RD) for four different image fusion tasks: Visible-Infrared Fusion (VIF), Medical Image Fusion (MIF), Multi-Exposure Fusion (MEF), and Multi-Focus Fusion (MFF). For each task, it shows the RD maps for each source image. The RD values highlight the regions where each source image is most dominant in constructing the final fused image. High RD values indicate that the corresponding source image provides more effective information for that specific region in the fused image. This visualization helps to understand how the proposed method dynamically weighs different source images based on their relative importance in different regions.
read the caption
Figure 1: We visualized the Relative Dominablity (RD) of each source on four tasks, which effectively highlights the dominance of uni-source in image fusion.

🔼 This figure shows the visualization of Relative Dominability (RD) for each source image across four different image fusion tasks: Visible-Infrared Fusion (VIF), Medical Image Fusion (MIF), Multi-Exposure Fusion (MEF), and Multi-Focus Fusion (MFF). The RD values are represented as heatmaps, indicating the relative importance of each source image in contributing to the final fused image. High RD values suggest that a particular source image is highly influential in a specific region of the fused image, whereas lower values indicate less influence. The figure visually demonstrates how RD dynamically highlights dominant regions of each source, adapting to the specific characteristics of each fusion task. This dynamic highlighting is a key element of the proposed Test-Time Dynamic Image Fusion (TTD) approach.
read the caption
Figure 1: We visualized the Relative Dominablity (RD) of each source on four tasks, which effectively highlights the dominance of uni-source in image fusion.

🔼 This figure shows how the Relative Dominability (RD) changes with varying contrast in visible images. As contrast decreases (due to added noise or other factors), the RD of visible image features decreases while the RD of infrared features increases. This demonstrates the robustness and adaptability of the proposed RD method to different image qualities.
read the caption
Figure 7: Visualization of RDs with varying contrast visible images. With the corruption severity level (contrast perturbation) increasing, the dominant regions of visible modality are gradually reduced. Our RD effectively perceives the changes on visible modality in the visualizations, while the unchanged infrared modality gains an increasing RD.

🔼 This figure visualizes the Relative Dominability (RD) for each source image across four different image fusion tasks: Visible-Infrared Fusion (VIF), Medical Image Fusion (MIF), Multi-Exposure Fusion (MEF), and Multi-Focus Fusion (MFF). The RD metric quantifies the importance of each source image in constructing the final fused image. Higher RD values indicate that a particular source image is more dominant in that specific region. The visualization shows that the RD values effectively highlight the regions where each source image is most influential in the fusion process. For instance, in VIF, infrared images provide dominant information at thermal targets. Similarly, overexposed/underexposed images are dominant at the corresponding regions of MEF and foreground/background is dominant at MFF.
read the caption
Figure 1: We visualized the Relative Dominablity (RD) of each source on four tasks, which effectively highlights the dominance of uni-source in image fusion.

🔼 This figure visualizes the Relative Dominability (RD) for each source image in four different image fusion tasks: Visible-Infrared Fusion (VIF), Medical Image Fusion (MIF), Multi-Exposure Fusion (MEF), and Multi-Focus Fusion (MFF). Relative Dominability represents the degree to which each source image contributes to the final fused image. Higher RD values indicate a greater contribution from that source. The visualization shows that the RD effectively highlights the dominant regions of each source image for each fusion task, illustrating the dynamic nature of information contribution across various sources and scenarios.
read the caption
Figure 1: We visualized the Relative Dominablity (RD) of each source on four tasks, which effectively highlights the dominance of uni-source in image fusion.

🔼 This figure visualizes the Relative Dominability (RD) for four different image fusion tasks: Visible-Infrared Fusion (VIF), Medical Image Fusion (MIF), Multi-Exposure Fusion (MEF), and Multi-Focus Fusion (MFF). For each task, the RD is shown for each source image, effectively highlighting the dominant regions of each source in constructing the final fused image. The RD values are represented as heatmaps, where brighter colors indicate stronger dominance.
read the caption
Figure 1: We visualized the Relative Dominablity (RD) of each source on four tasks, which effectively highlights the dominance of uni-source in image fusion.
More on tables
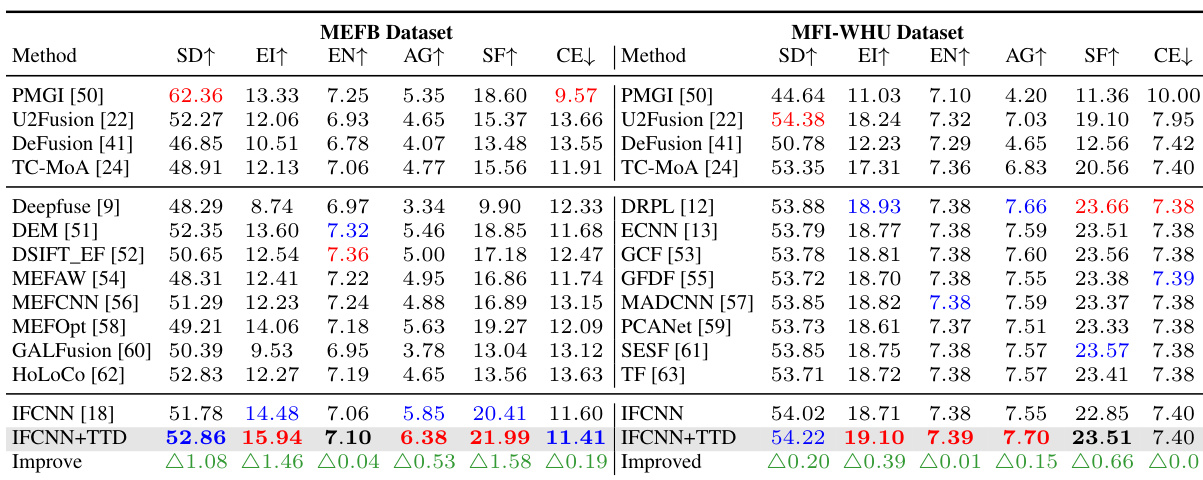
🔼 This table presents a quantitative comparison of different image fusion methods on two datasets: MFI-WHU (Multi-Focus Image Fusion) and MEFB (Multi-Exposure Image Fusion). For each dataset and method, several metrics are reported to evaluate the performance of the fusion process. These metrics likely assess aspects like image quality, information preservation, and edge enhancement. The table allows for a comparison of the proposed method against other state-of-the-art techniques across different fusion tasks.
read the caption
Table 2: Quantitative comparison on MFI-WHU dataset in MFF task and MEFB dataset in MEF task.

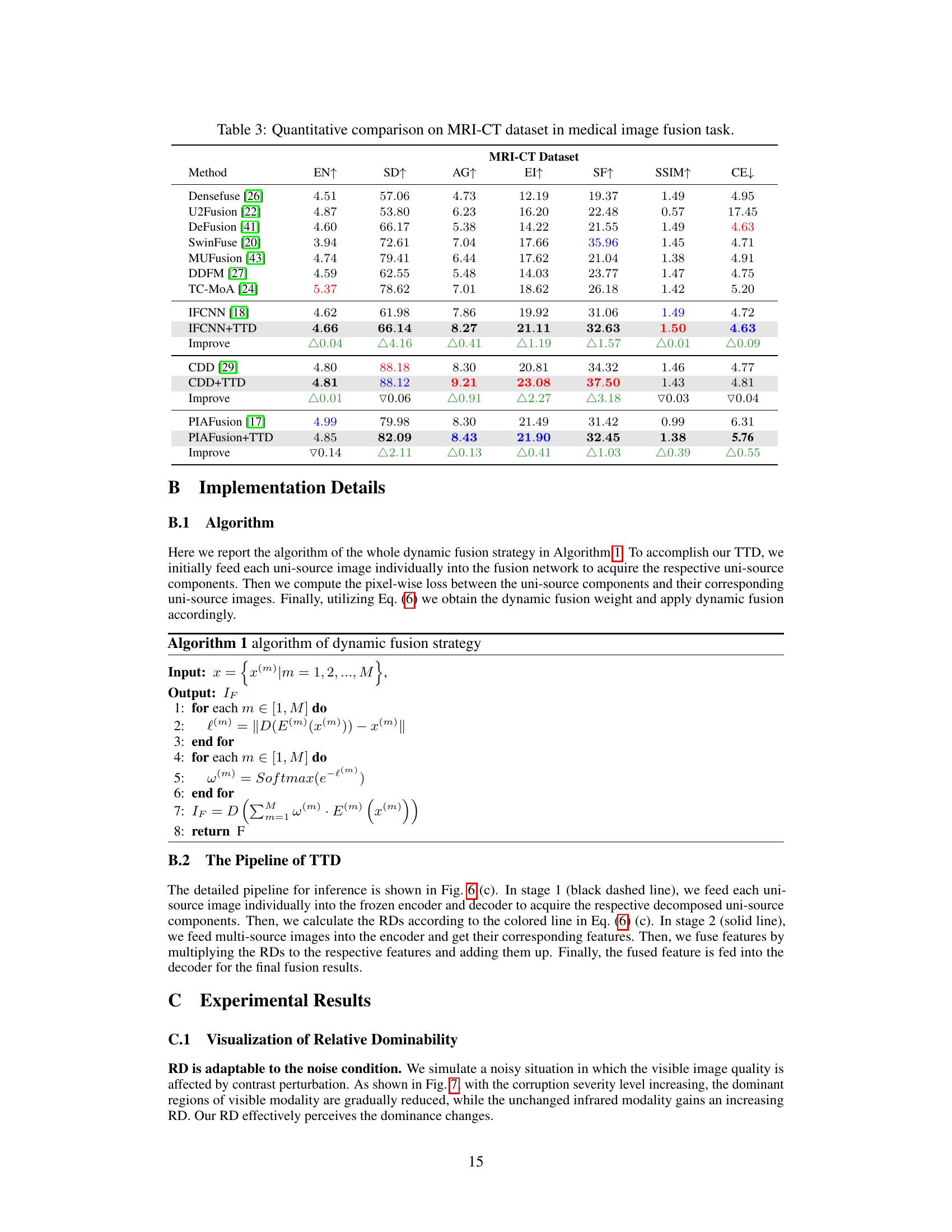
🔼 This table presents a quantitative comparison of different image fusion methods on the MRI-CT dataset. The methods are evaluated across several metrics, including information theory metrics (EN, CE), image feature metrics (SD, AG, EI, SF), and structural similarity (SSIM). The table shows the performance of various methods, both baseline methods and those combined with the proposed Test-Time Dynamic (TTD) image fusion approach. The ‘Improve’ rows highlight the performance differences between the baseline methods and their TTD-enhanced counterparts.
read the caption
Table 3: Quantitative comparison on MRI-CT dataset in medical image fusion task.

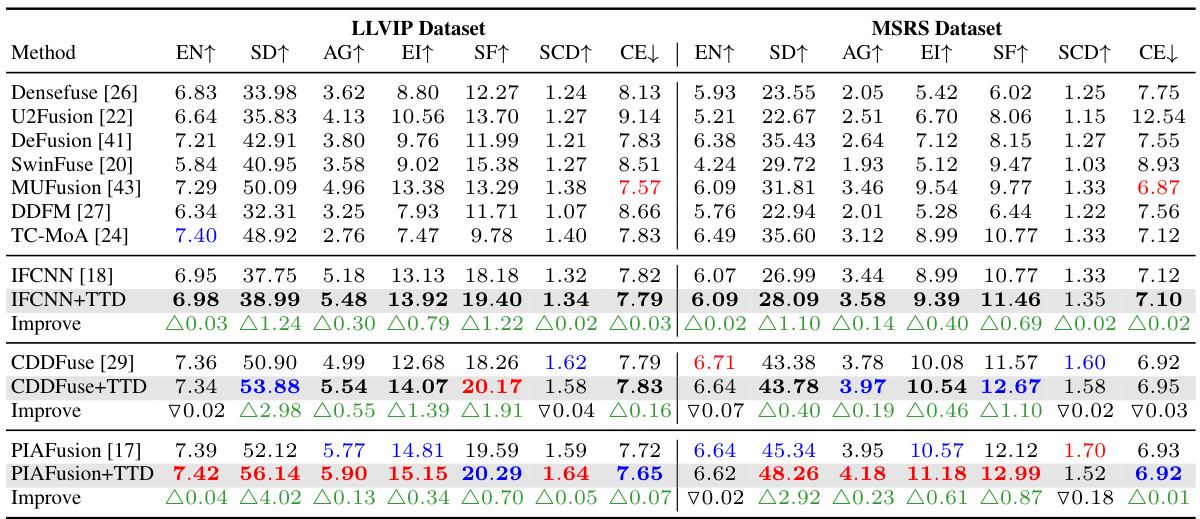
🔼 This table presents a quantitative comparison of various image fusion methods’ performance on two visible-infrared datasets (LLVIP and MSRS). It compares the performance of several state-of-the-art methods with and without the proposed Test-Time Dynamic (TTD) fusion strategy. Metrics used include entropy, standard deviation, average gradient, edge intensity, spatial frequency, sum of correlations of differences, and cross entropy. The table highlights the improvements achieved by incorporating the TTD method and indicates the best and second-best performing methods for each metric.
read the caption
Table 1: Quantitative performance comparison of different fusion strategies on visible-infrared datasets. The 'TTD' suffix and gray background indicates our method is applied to this baseline. The red and blue represent the best and second-best result respectively. The bold indicates the baseline w/ TTD performance better than that w/o TTD. We used to illustrate the amount of improvement our TTD method achieved compared to the baseline.

🔼 This table presents the ablation study on different forms of fusion weights. The goal is to find the best way to combine information from different sources in image fusion. Four different methods were tested: a simple average (w = 0.5), softmax applied to the negative loss, softmax applied to the sigmoid of the negative loss, and softmax applied to the exponential of the negative loss. The results show that using softmax with the exponential of the negative loss performs the best, improving several metrics including EN, SD, AG, EI, SF, and SSIM while reducing CE. This suggests that this method is most effective at combining information from different sources to generate a high-quality fused image.
read the caption
Table 4: Ablation study on different forms of fusion weights on LLVIP dataset.

🔼 This table presents an ablation study on the impact of different normalization methods on the fusion weights used in the LLVIP dataset. It compares the performance of four weight normalization techniques: no normalization, proportional normalization, and softmax normalization (the authors’ proposed method). The performance metrics used are EN, SD, AG, EI, SF, SSIM, and CE, all of which are image quality metrics. The results show that softmax normalization leads to the best performance, outperforming both no normalization and proportional normalization across all metrics.
read the caption
Table 5: Ablation study on the normalization of the weights on LLVIP dataset.

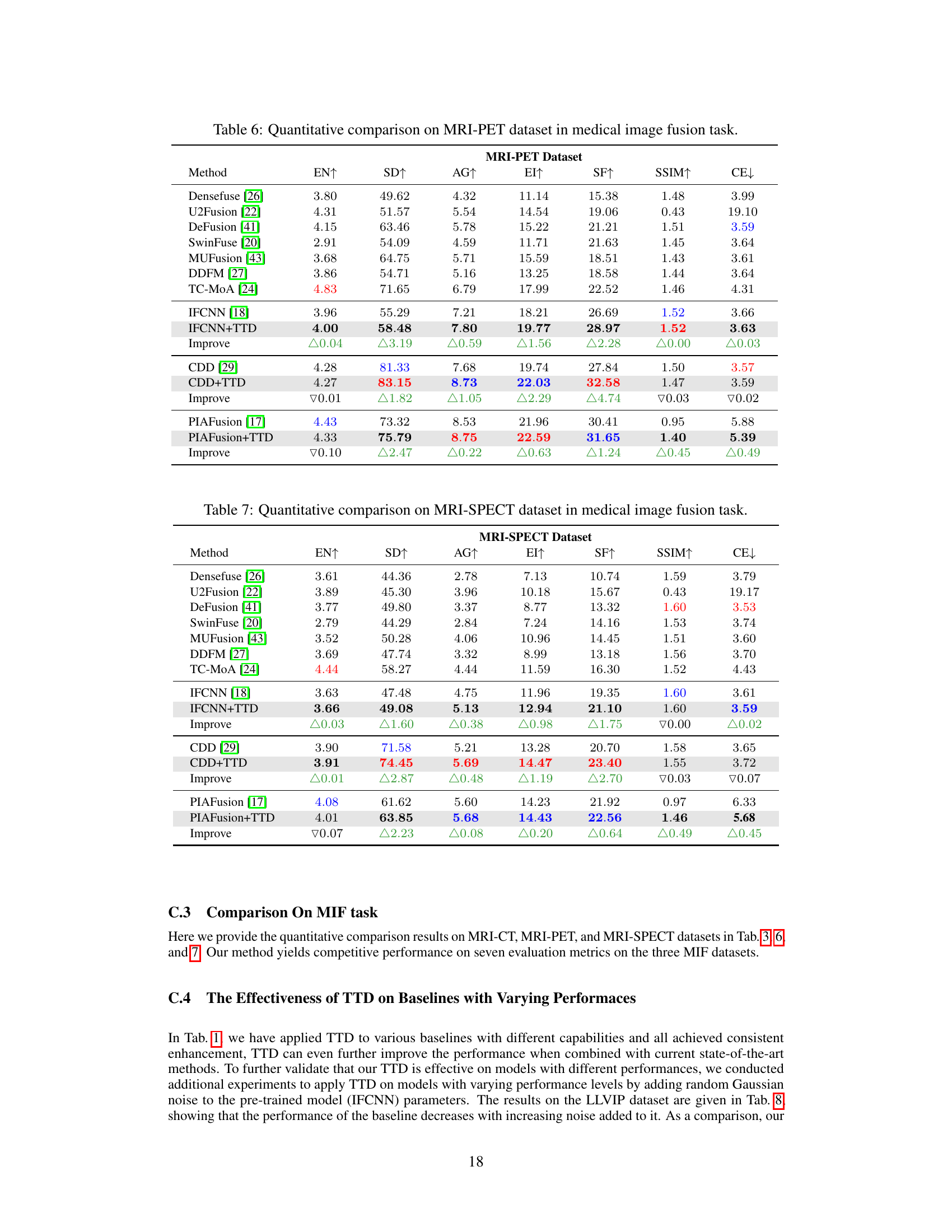
🔼 This table presents a quantitative comparison of different image fusion methods on the MRI-PET dataset. The methods are evaluated across several metrics including entropy (EN), standard deviation (SD), average gradient (AG), edge intensity (EI), spatial frequency (SF), structural similarity (SSIM), and cross entropy (CE). The table shows the performance of baseline methods, and the same methods enhanced with the proposed Test-Time Dynamic (TTD) image fusion paradigm. The ‘Improve’ row highlights the performance differences between baseline methods and their TTD-enhanced versions.
read the caption
Table 6: Quantitative comparison on MRI-PET dataset in medical image fusion task.

🔼 This table presents a quantitative comparison of different image fusion methods on the MRI-CT dataset. It shows the performance of various methods across several metrics including entropy (EN), standard deviation (SD), average gradient (AG), edge intensity (EI), spatial frequency (SF), structural similarity (SSIM), and cross-entropy (CE). The results allow for a comparison of the methods’ effectiveness in preserving details and improving the quality of the fused images.
read the caption
Table 3: Quantitative comparison on MRI-CT dataset in medical image fusion task.
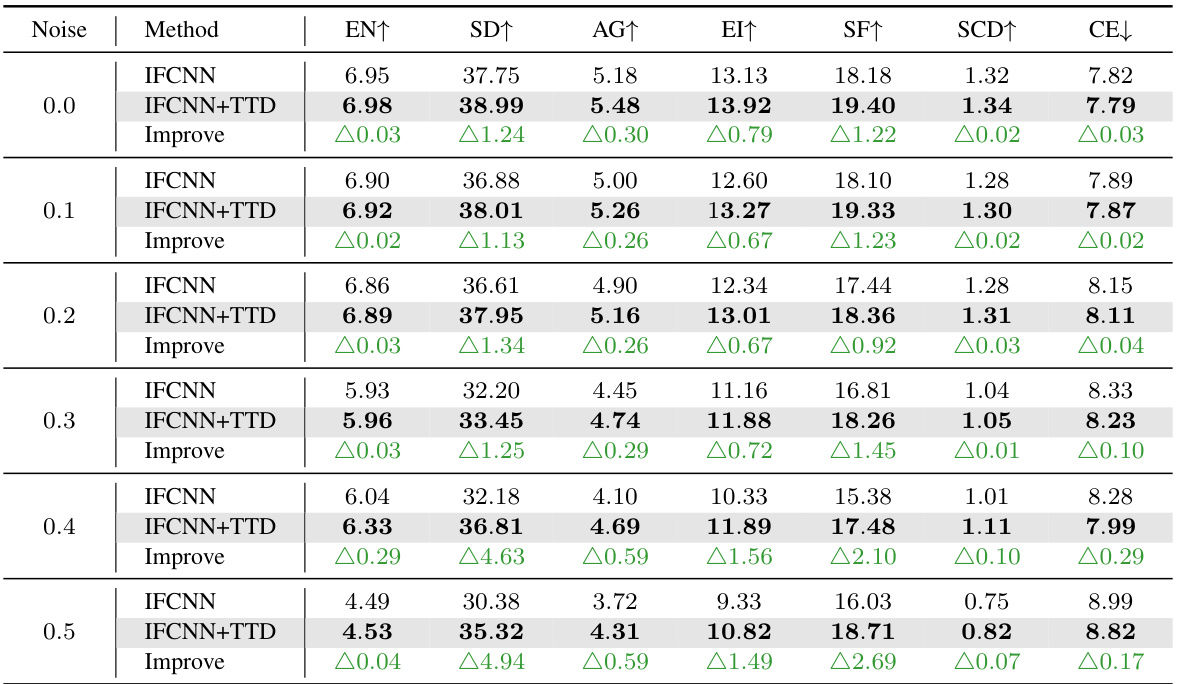
🔼 This table presents an ablation study evaluating the effectiveness of the proposed Test-Time Dynamic (TTD) image fusion method on baselines with varying performance levels. Different levels of random Gaussian noise were added to the pre-trained IFCNN model to simulate varying baseline performance. The table shows that the TTD method consistently improves the performance of the baseline model across various metrics (EN, SD, AG, EI, SF, SCD, and CE) even when the baseline model’s performance is degraded by noise addition. The improvements are presented as the difference (△) between the IFCNN+TTD and the baseline IFCNN.
read the caption
Table 8: The effectiveness of TTD on baselines with varying performances.

🔼 This table presents a quantitative comparison of various image fusion methods on two visible-infrared datasets (LLVIP and MSRS). It compares the performance of several state-of-the-art methods and shows how these methods perform when combined with the proposed Test-Time Dynamic (TTD) image fusion approach. Metrics used for comparison include information theory measures (entropy, cross-entropy, sum of correlations of differences), image features (standard deviation, average gradient, edge intensity, spatial frequency), and structural similarity (SSIM). The table highlights the improvements achieved by adding TTD to the baseline methods, indicating the effectiveness of the proposed approach.
read the caption
Table 1: Quantitative performance comparison of different fusion strategies on visible-infrared datasets. The 'TTD' suffix and gray background indicates our method is applied to this baseline. The red and blue represent the best and second-best result respectively. The bold indicates the baseline w/ TTD performance better than that w/o TTD. We used to illustrate the amount of improvement our TTD method achieved compared to the baseline.
Full paper#