↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current text-to-video (T2V) models struggle to generate videos with realistic motion, often producing static or minimally dynamic outputs. This limitation stems from biases in text encoding that overlooks motion and inadequate conditioning mechanisms in T2V models. The lack of accurate motion representation in text hinders the generation of dynamic and compelling videos.
This paper introduces DEMO, a novel framework to address these issues by decomposing both text encoding and conditioning into content and motion components. This allows the model to better understand and represent static elements and dynamic motions separately. Crucially, DEMO incorporates text-motion and video-motion supervision to enhance motion understanding and generation, ultimately leading to videos with enhanced motion dynamics and high visual quality. The evaluations on various benchmarks showcase DEMO’s superior performance in generating videos with realistic and complex motion, significantly advancing the state-of-the-art in T2V generation. The core contribution is a novel framework that effectively leverages decomposed text encoding and conditioning, along with specialized supervision techniques, to generate videos with substantially improved motion.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in text-to-video generation because it directly addresses the persistent challenge of generating videos with realistic and complex motion. The proposed method offers a significant advancement, providing a novel framework and supervision techniques to enhance motion synthesis, impacting the field and opening avenues for new research in motion understanding and realistic video generation.
Visual Insights#
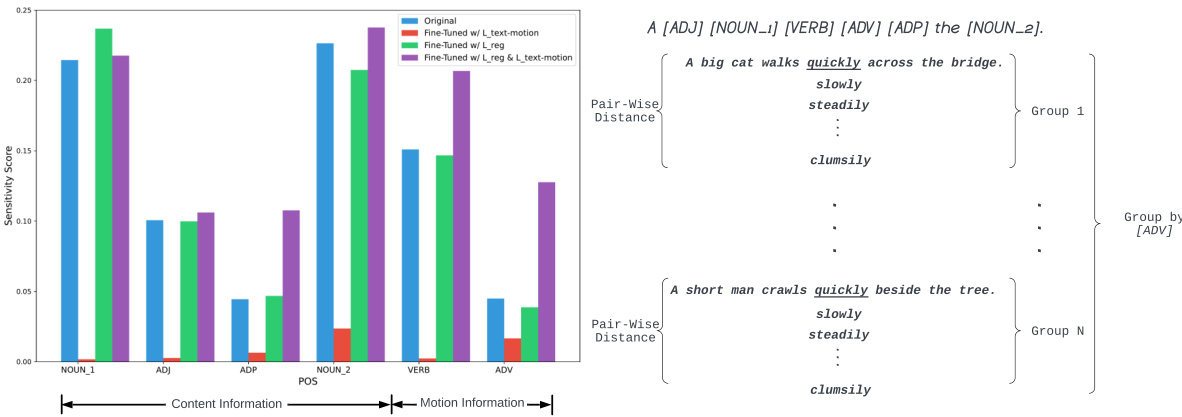
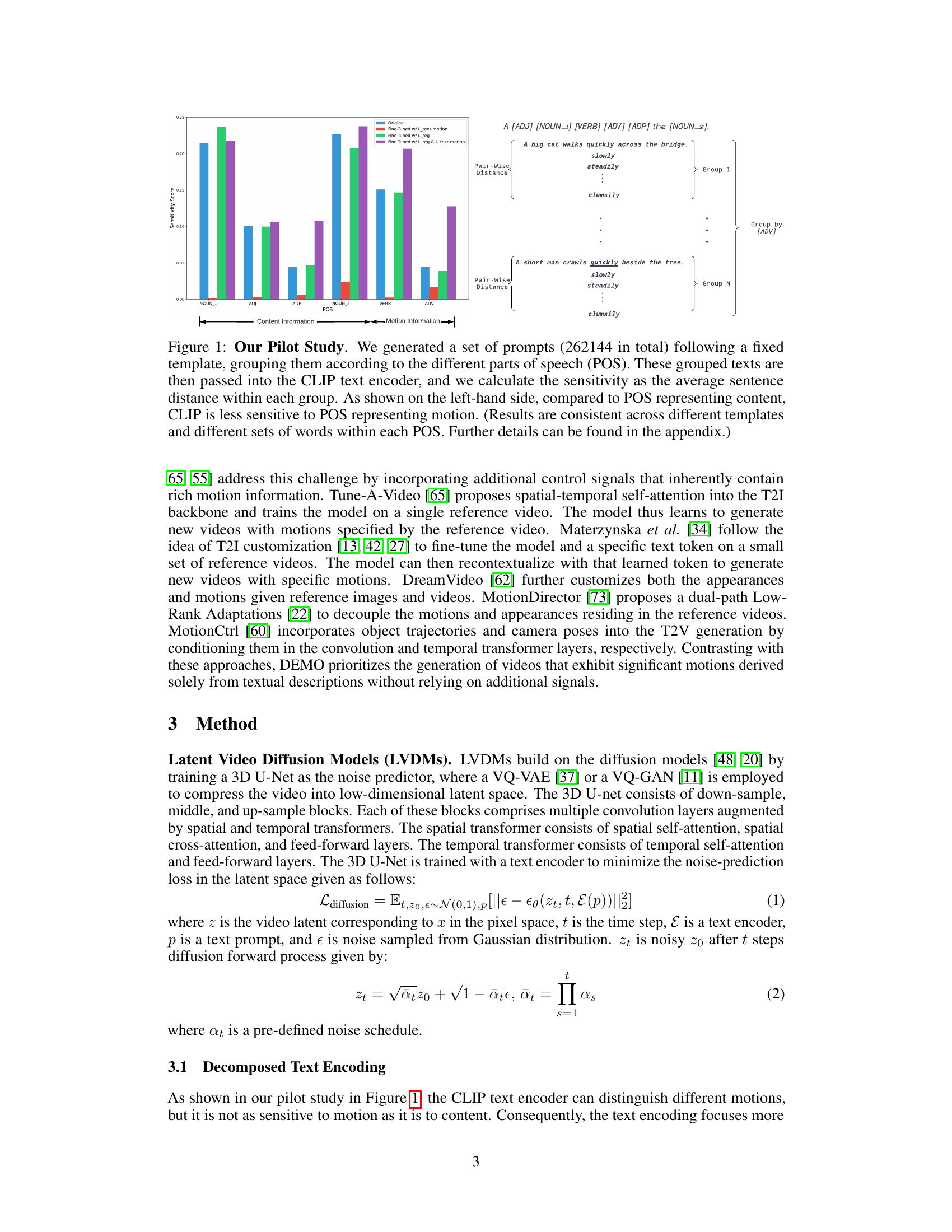
This figure presents a pilot study to evaluate the sensitivity of the CLIP text encoder to different parts of speech (POS) related to content and motion. By generating a large set of prompts with fixed templates and varying POS, the study measures how well CLIP distinguishes between motion and content words. The results show that CLIP is less sensitive to POS related to motion, indicating a need for improved motion encoding in text-to-video models.

This table presents the quantitative results of zero-shot text-to-video (T2V) generation on the MSR-VTT benchmark dataset. It compares several different models (Magic Video, Make-A-Video, Show-1, Video LDM, LaVie, PYOCO, VideoFactory, EMU VIDEO, SVD, ModelScopeT2V, a fine-tuned version of ModelScopeT2V, and the proposed DEMO model) using three metrics: FID (Frechet Inception Distance), FVD (Fréchet Video Distance), and CLIPSIM (CLIP Similarity). Lower FID and FVD scores indicate better visual quality, while a higher CLIPSIM score indicates better alignment between the generated videos and their corresponding text descriptions. The table shows that the DEMO model outperforms other models in terms of these metrics, achieving superior performance in generating high-quality videos with good text-image alignment.
In-depth insights#
Motion Enhancement#
Enhancing motion in text-to-video generation is a significant challenge, as current models often produce static or minimally dynamic results. A key aspect of addressing this is improving the encoding and conditioning mechanisms within the model. Decomposing the text encoding into content and motion components, separately handling static visual elements and the dynamic aspects of motion described in the text, is crucial. This enables a more nuanced understanding of motion. Furthermore, incorporating separate content and motion conditioning processes helps the model to distinctly handle static and dynamic aspects within the video generation. Supervised learning techniques, including text-motion and video-motion supervision, are essential in training the model to understand and appropriately generate these motion dynamics. By aligning cross-attention maps with temporal changes in real videos and constraining predicted video latent patterns, the model develops a deeper understanding of the connection between textual descriptions and realistic motion patterns. These techniques are critical for overcoming limitations in existing models and creating videos with significantly enhanced motion realism.
Decomposed Encoding#
Decomposed encoding, in the context of text-to-video generation, tackles the challenge of encoding rich textual descriptions that encompass both static content and dynamic motion. Traditional methods often fall short, either overlooking motion details crucial for realistic video generation or struggling to effectively incorporate this temporal information. The core idea of decomposed encoding is to separate the encoding process into distinct pathways for handling content and motion information. This disentanglement enables the model to more accurately capture both the static scene elements and the implied actions or movements described in the text. By splitting the encoding, the model avoids potential bias and interference inherent in the traditional approach, resulting in improved representation of motion nuances. Consequently, the subsequent conditioning and generation processes can leverage these cleaner, more distinct representations, ultimately producing videos with significantly more realistic and complex motion. This technique highlights a paradigm shift towards a more comprehensive understanding of textual descriptions, moving beyond static elements and towards a more complete representation of the dynamic temporal aspects of the narrative.
Dual Conditioning#
Dual conditioning, in the context of text-to-video generation, likely refers to a model architecture that leverages two distinct conditioning signals to guide the video generation process. This approach contrasts with single conditioning methods, which typically use only text or an image as a guide. One conditioning signal could focus on the semantic content, encompassing objects, actions, and their spatial relationships as described in the text. The other would emphasize the temporal dynamics of the video, including motion, speed, and changes in the scene over time. This dual-path conditioning enables a more sophisticated and nuanced control over the generated video. The key advantage lies in the ability to independently control the static aspects (content) and dynamic elements (motion), leading to potentially more realistic and coherent video outputs. Effective implementation would require careful design of both conditioning pathways and appropriate integration mechanisms, potentially involving separate encoders for content and motion, and specific architectural modifications within the video generation model to effectively incorporate both signals. Failure to achieve effective integration could result in suboptimal video quality and inconsistencies between the intended content and motion.
Ablation Study#
An ablation study systematically removes components or features of a model to assess their individual contributions. In the context of a text-to-video generation model, this might involve removing one or more of the following: the motion encoder, the content encoder, motion conditioning, content conditioning, or specific loss functions like text-motion supervision or video-motion supervision. By observing how performance metrics (e.g., FID, FVD, CLIPSIM, VQAA) change with each ablation, researchers can pinpoint which parts are most crucial for generating high-quality and dynamic videos. A well-designed ablation study isolates the impact of each module, allowing researchers to confidently attribute success or failure to specific components. Careful analysis reveals the relative importance of different architectural choices and training strategies. Results help optimize future model designs, guide future research directions, and overall provide a deeper understanding of the model’s inner workings.
Future Works#
The ‘Future Works’ section of a research paper on enhancing motion in text-to-video generation could explore several avenues. Improving the handling of sequential actions within a single video is crucial; current methods often struggle to represent complex, temporally ordered events described in text. Developing more sophisticated motion encoding techniques that go beyond simple directional cues would greatly improve realism. This might involve incorporating more nuanced representations of physics, human biomechanics, or object interactions. Another key area is expanding the range and diversity of motion styles. While the current work focuses on realistic motion, the potential for stylistic control, such as cartoonish or exaggerated movements, remains largely untapped. Finally, addressing potential biases and limitations in the training data is important. This could involve developing methods to mitigate biases inherent in existing datasets or exploring alternative training methodologies that lead to more robust and fair video generation.
More visual insights#
More on figures
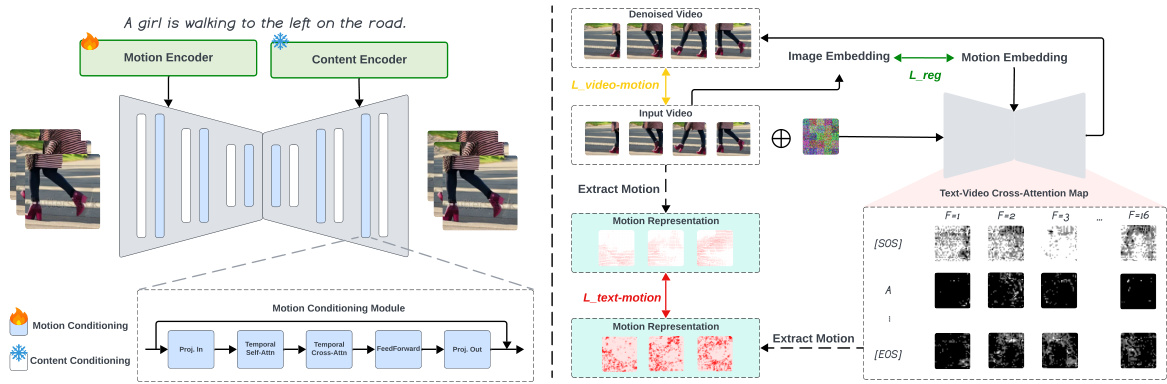
This figure illustrates the DEMO (Decomposed Motion) framework for text-to-video generation. The left side shows the architecture’s dual text encoding (content and motion) and conditioning, highlighting the separation of content and motion information processing. The right side details the training process, emphasizing three key loss functions: L_text-motion (aligning cross-attention maps with temporal changes), L_reg (preventing catastrophic forgetting in the text encoder), and L_video-motion (constraining predicted video latent to real video motion). Frozen and trainable parameters are also identified.

This figure shows a qualitative comparison of video generation results from four different models: LaVie, VideoCrafter2, ModelScopeT2V, and DEMO. Three example video generation prompts are used: slow-motion falling flower petals, an old man speaking, and a horse race. The figure displays selected frames from each generated video to highlight the visual quality and motion dynamics produced by each model. The full videos are available in supplementary materials.

This figure shows the limitations of the DEMO model in generating videos with sequential motions. The caption points out that DEMO struggles to create videos where multiple actions occur one after another, instead generating a video where all actions happen simultaneously. The example image shows a man both talking and the appearance of a mixer and milk carton at the same time; these actions should occur sequentially.

This figure shows a qualitative comparison of video generation results from four different models (LaVie, VideoCrafter2, ModelScopeT2V, and DEMO) on three different prompts. Each model generated a 16-frame video, and the figure displays selected frames (1, 2, 4, 6, 8, 10, 12, 14, 15, and 16) for visual comparison. The prompts depict various scenes, with different levels of dynamic movement. The comparison aims to visually demonstrate the quality and realism of motion in the generated videos.
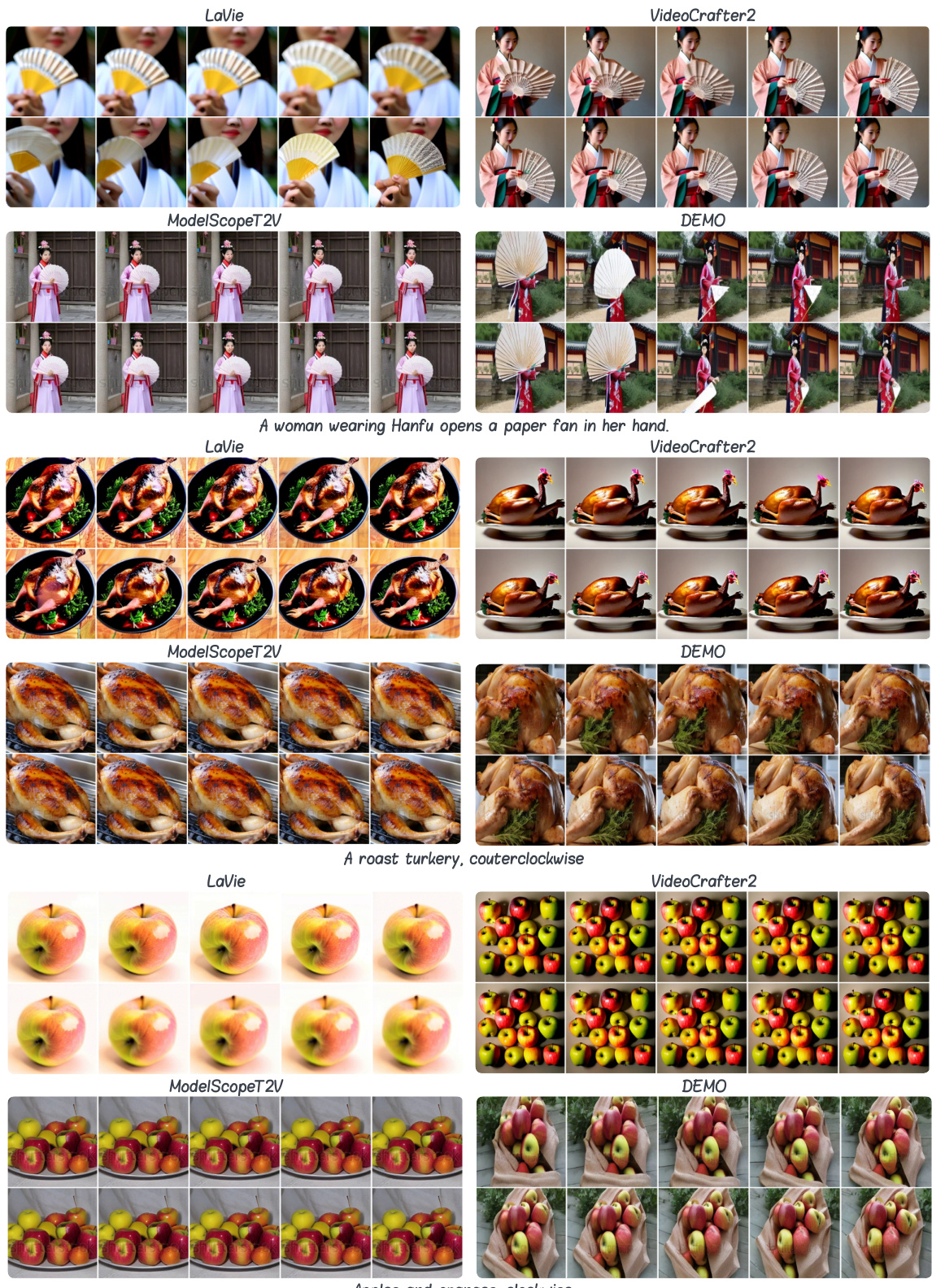
This figure shows a qualitative comparison of video generation results from four different models: LaVie, VideoCrafter2, ModelScopeT2V, and DEMO. Each model generated a short video (16 frames) based on three textual prompts: ‘A woman wearing Hanfu opens a paper fan in her hand.’, ‘A roast turkey, counterclockwise’, and ‘Apples and oranges, clockwise.’ The figure displays selected frames (1, 2, 4, 6, 8, 10, 12, 14, 15, 16) of each video to illustrate the motion quality and visual fidelity of each model’s output. Full videos are available in the supplementary materials.

This figure compares the video generation results of four different models: LaVie, VideoCrafter2, ModelScopeT2V, and DEMO. Three different scenarios are shown, each with a different level of complexity: giraffes in a savanna, Superman and Spiderman shaking hands in a watercolor style, and a lion catching its prey. Each scenario is represented by a sequence of 16 frames, with a subset of the frames displayed for comparison. The comparison highlights the differences in motion realism and quality achieved by the four methods. The full videos for each comparison can be found in the supplementary materials.

This figure shows a qualitative comparison of video generation results for three different prompts, comparing the outputs of four different models: LaVie, VideoCrafter2, ModelScopeT2V, and DEMO. Each row represents a single prompt, with the generated videos displayed for each model. The models are compared based on their ability to generate realistic and visually appealing videos that accurately reflect the text prompt. The frames shown are a subset of the full 16-frame videos available in the supplementary materials.
More on tables

This table presents the quantitative results of zero-shot text-to-video generation on the WebVid-10M validation set. Three models are compared: the original ModelScopeT2V, a fine-tuned version of ModelScopeT2V, and the proposed DEMO model. The metrics used for evaluation are FID (Fréchet Inception Distance), FVD (Fréchet Video Distance), and CLIPSIM (CLIP Similarity). Lower FID and FVD scores indicate better video quality, while a higher CLIPSIM score indicates better alignment between the generated video and the input text description.

This table presents the quantitative evaluation results of zero-shot text-to-video (T2V) generation on the EvalCrafter benchmark. It compares the performance of four different models: ModelScopeT2V, a fine-tuned version of ModelScopeT2V, DEMO without video-motion loss (Lvideo-motion), and the full DEMO model. The metrics used assess both video quality (VQAA, VQAT, IS) and motion quality (Action Score, Motion AC-Score, Flow Score). Higher scores indicate better performance. The results demonstrate that the DEMO model, particularly with the inclusion of video-motion loss, significantly improves motion quality while maintaining good video quality compared to the baseline and other variations.

This table presents a quantitative comparison of the performance of three different models on the VBench benchmark. The models compared are ModelScopeT2V, a fine-tuned version of ModelScopeT2V, and the proposed DEMO model. The evaluation metrics used are Motion Dynamics, Human Action, Temporal Flickering, and Motion Smoothness. Higher scores generally indicate better performance. The results show that DEMO outperforms the other two models across all metrics, particularly in Motion Dynamics.
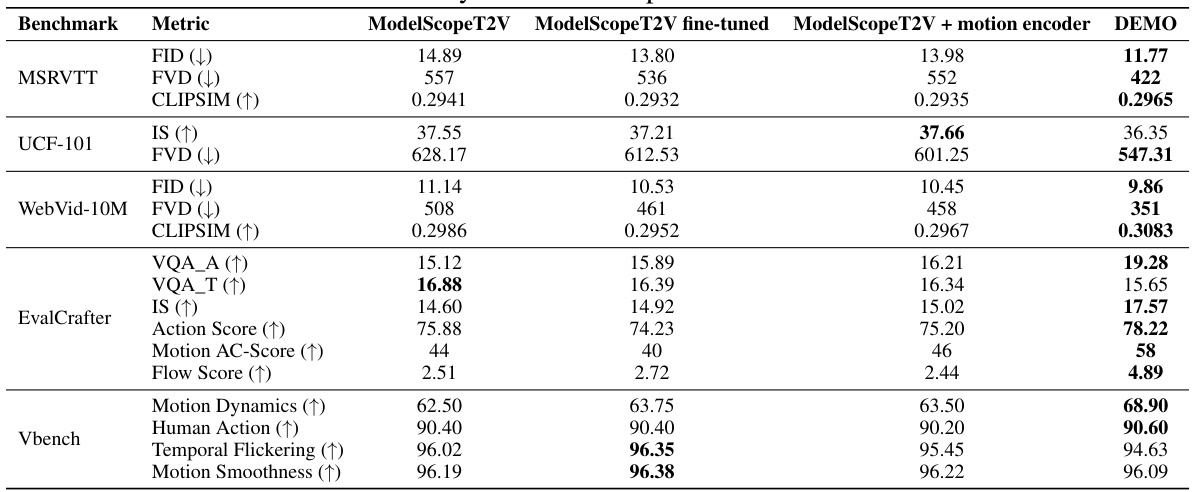
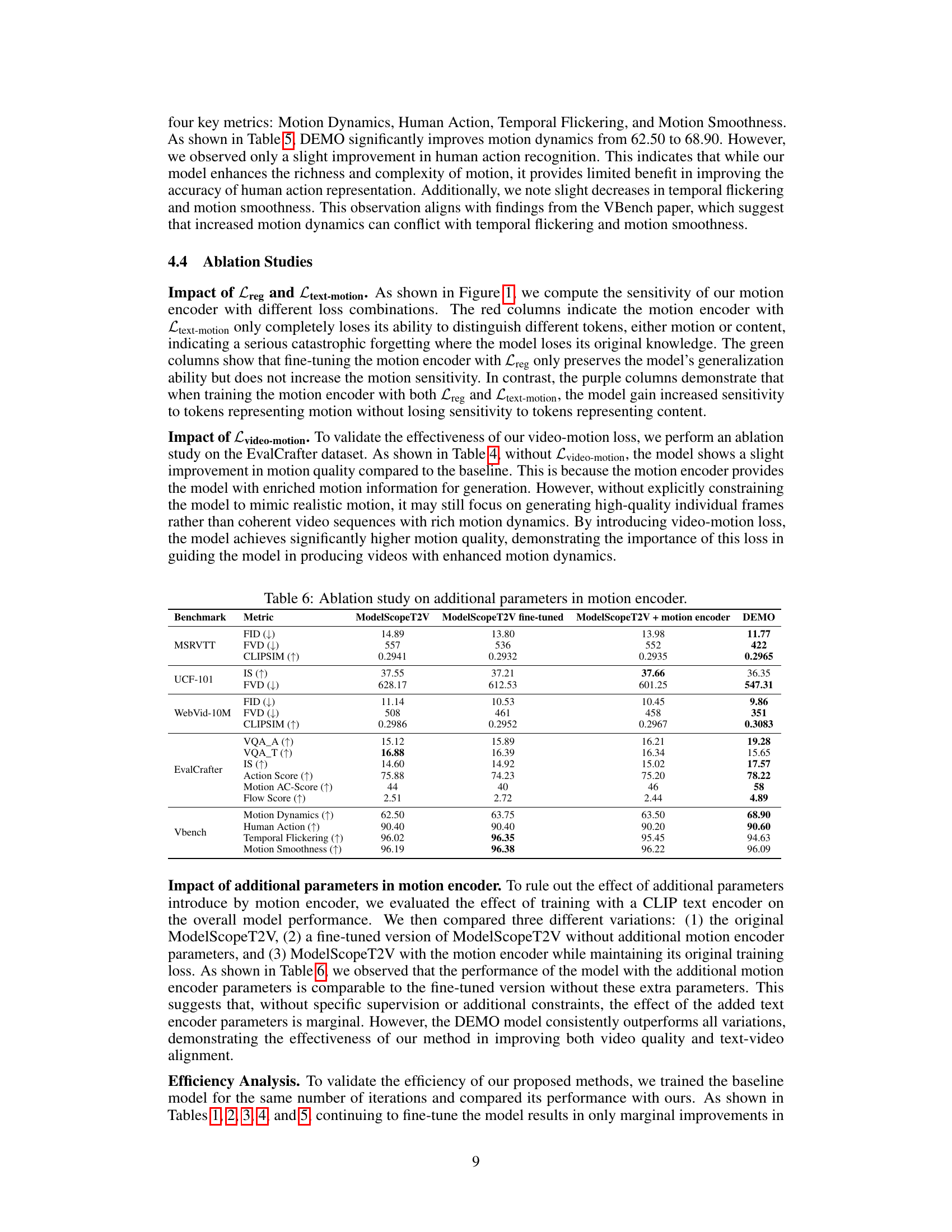
This ablation study compares the performance of ModelScopeT2V, a fine-tuned version of ModelScopeT2V, ModelScopeT2V with an added motion encoder, and the proposed DEMO model across various benchmarks and metrics. The metrics include FID, FVD, and CLIPSIM for video quality assessment on MSR-VTT, UCF-101, and WebVid-10M. For EvalCrafter, video and motion quality are evaluated using VQA-A, VQA-T, IS, Action Score, Motion AC-Score, and Flow Score. Finally, on VBench, Motion Dynamics, Human Action, Temporal Flickering, and Motion Smoothness are assessed. The table highlights how the addition of the motion encoder and the complete DEMO model affect these metrics, demonstrating the impact of the proposed model components.

This table lists the hyperparameters used during the training of the proposed DEMO model and its base model, LDM. It includes hyperparameters related to the LDM model, U-Net, Motion Encoder, Motion Conditioning, and Training process, as well as the inference parameters. The table details settings for compression rate, latent shape, channel dimensions, attention resolutions, number of parameters, dropout rate, token length, activation functions (e.g., GELU), normalization methods (e.g., GroupNorm), optimizer (Adam), learning rate scheduling (OneCycle), classifier-free guidance scale, loss weightings, and DDIM sampling steps.
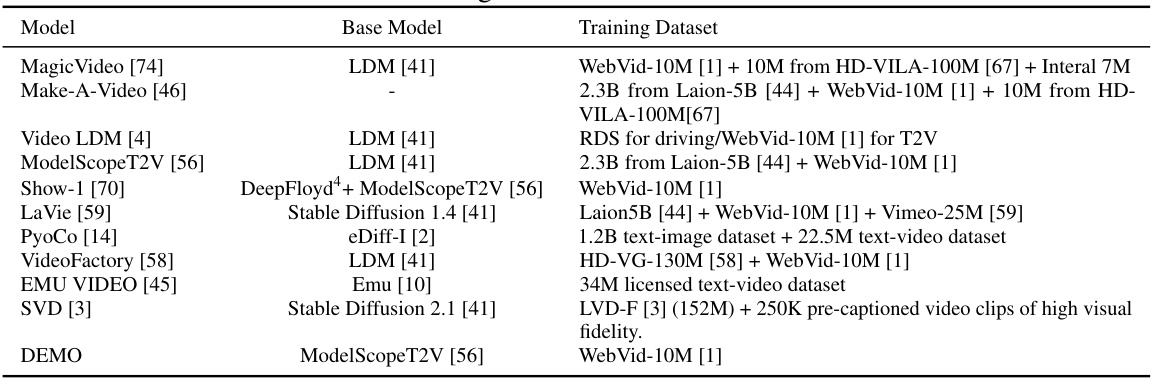
This table lists various Text-to-Video (T2V) models and specifies the base model and training dataset used for each. The base model column indicates the foundational model architecture upon which each T2V model was built. The training dataset column details the specific datasets used to train each model, often including a combination of image-text and video-text datasets. Understanding these base models and datasets helps to contextualize the differences in performance and capabilities observed between various T2V models.

This table presents a comparison of the performance of different text-to-video (T2V) generation models on the MSR-VTT benchmark. The comparison focuses on zero-shot generation, meaning the models are not fine-tuned on the MSR-VTT dataset. The table includes several metrics for evaluating video generation quality, including FID, which measures the difference between generated and real images; FVD, which assesses the temporal consistency of generated videos; and CLIPSIM, which quantifies the semantic similarity between text prompts and generated videos. The different evaluation protocols used in other studies are also noted for clarity and comparison.
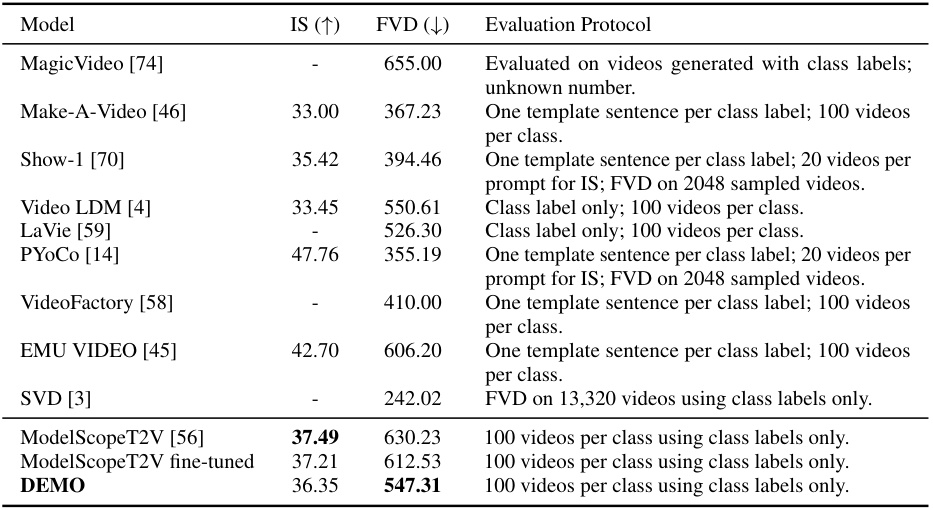
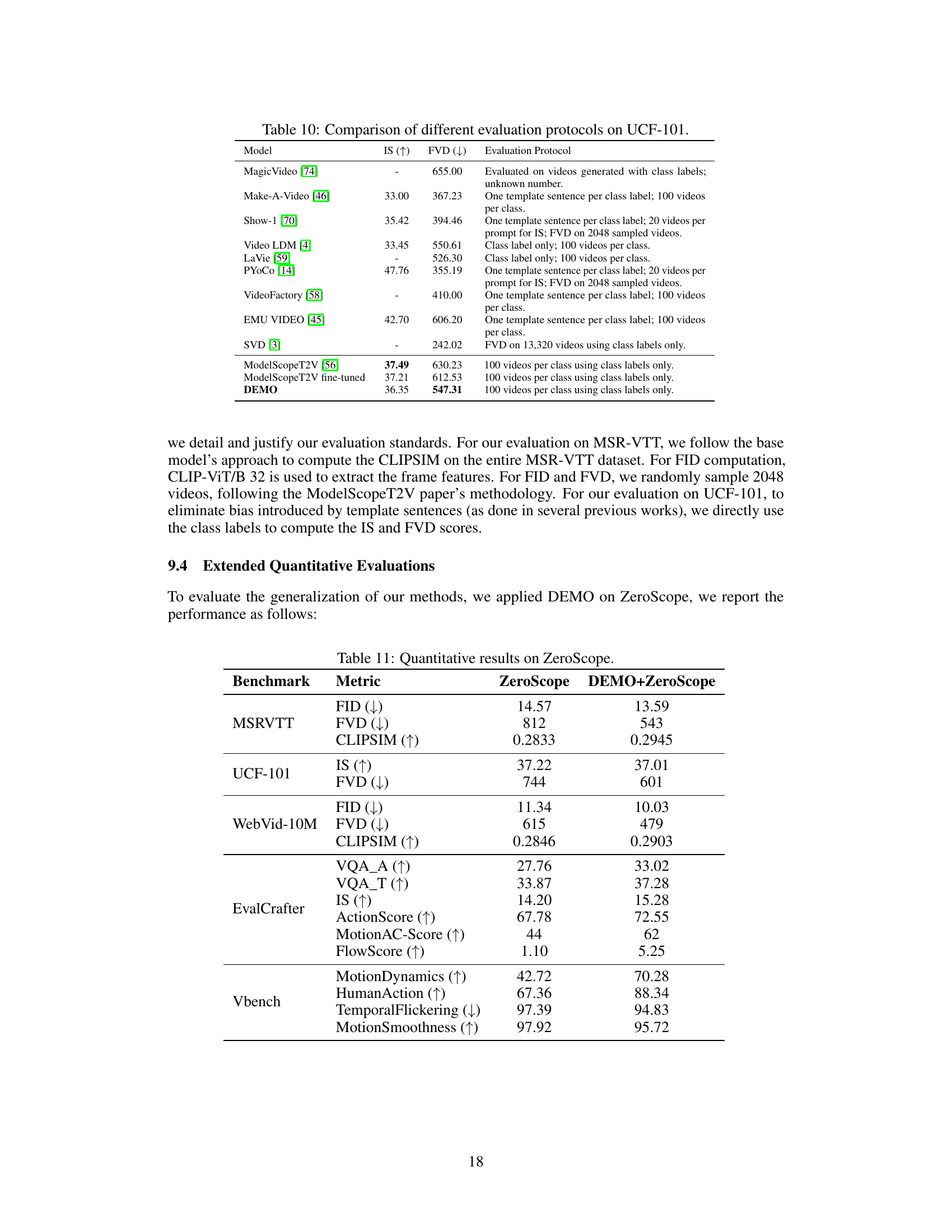
This table presents a comparison of the performance of different Text-to-Video (T2V) generation models on the UCF-101 dataset. The models are evaluated using Inception Score (IS), which measures the quality of generated images and Fréchet Video Distance (FVD), which measures the similarity between real and generated videos. Higher IS indicates better image quality, while lower FVD indicates better video quality. The table shows the results for several models, including MagicVideo, Make-A-Video, Show-1, Video LDM, LaVie, PYoCo, VideoFactory, EMU VIDEO, SVD, ModelScopeT2V, a fine-tuned version of ModelScopeT2V, and DEMO (the proposed method). The evaluation protocol is detailed in the appendix.
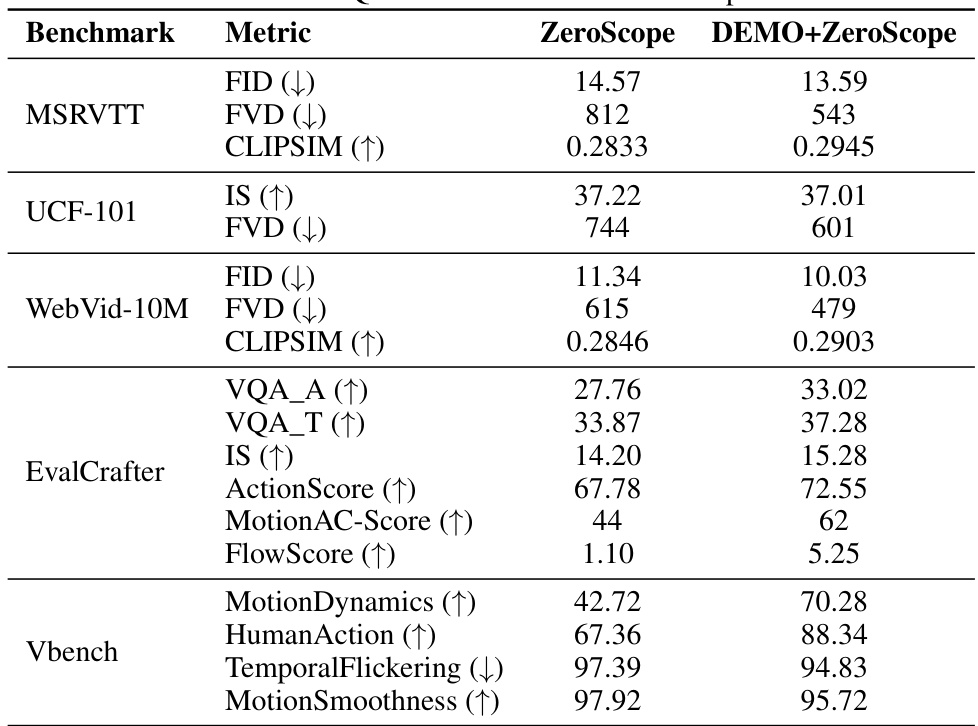
This table presents a quantitative comparison of the proposed DEMO model against a baseline model (ZeroScope) across various metrics on three benchmark datasets: MSR-VTT, UCF-101, and WebVid-10M. The metrics include FID, FVD, CLIPSIM (for video quality), and IS (for image quality). It also includes VQAA, VQAT, ActionScore, MotionAC-Score, and FlowScore (for video quality and motion quality) on the EvalCrafter dataset and MotionDynamics, HumanAction, TemporalFlickering, and MotionSmoothness on the Vbench dataset. The results show that DEMO+ZeroScope generally outperforms ZeroScope across most metrics, particularly in motion quality related metrics, indicating that the proposed method enhances motion synthesis in video generation.

This table presents the results of a user study comparing the performance of the proposed DEMO model against three other state-of-the-art video generation models: ModelScopeT2V, LaVie, and VideoCrafter2. The user study evaluated the models across three key aspects: Text-Video Alignment, Visual Quality, and Motion Quality. Each comparison shows the percentage of times users preferred DEMO over the competing model for each of the three criteria. Additionally, it shows a comparison of DEMO to DEMO without the video-motion loss, Lvideo-motion, to assess its contribution. The results highlight DEMO’s superior performance across the criteria, especially in terms of motion quality.
Full paper#