TL;DR#
Diffusion Transformers (DiTs) are powerful image generation models but computationally expensive. Their wide deployment is hindered by this high cost, especially for real-time applications. Post-training quantization (PTQ) offers a solution by reducing model size and computation, but applying it to DiTs has proven difficult because of the unique structure of DiTs, which has salient channels and temporal variability.
PTQ4DiT is a specifically designed PTQ method for DiTs. It introduces Channel-wise Salience Balancing (CSB) and Spearman’s p-guided Salience Calibration (SSC) to address these challenges. CSB redistributes extreme values in channels, while SSC dynamically adjusts the balancing across time steps. An offline re-parameterization eliminates extra computation during inference. Experiments show that PTQ4DiT successfully quantizes DiTs to 8-bit precision (W8A8) and, for the first time, to 4-bit weight precision (W4A8) while maintaining comparable image quality.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI and computer vision because it addresses the computational limitations of Diffusion Transformers (DiTs), a cutting-edge image generation model. By presenting a novel post-training quantization method, PTQ4DiT, the research enables wider application of DiTs in real-time applications. Its findings provide a practical solution for enhancing the efficiency of DiTs while preserving comparable image generation quality. Further research could build upon this work to explore additional quantization techniques or to improve the performance of existing techniques.
Visual Insights#

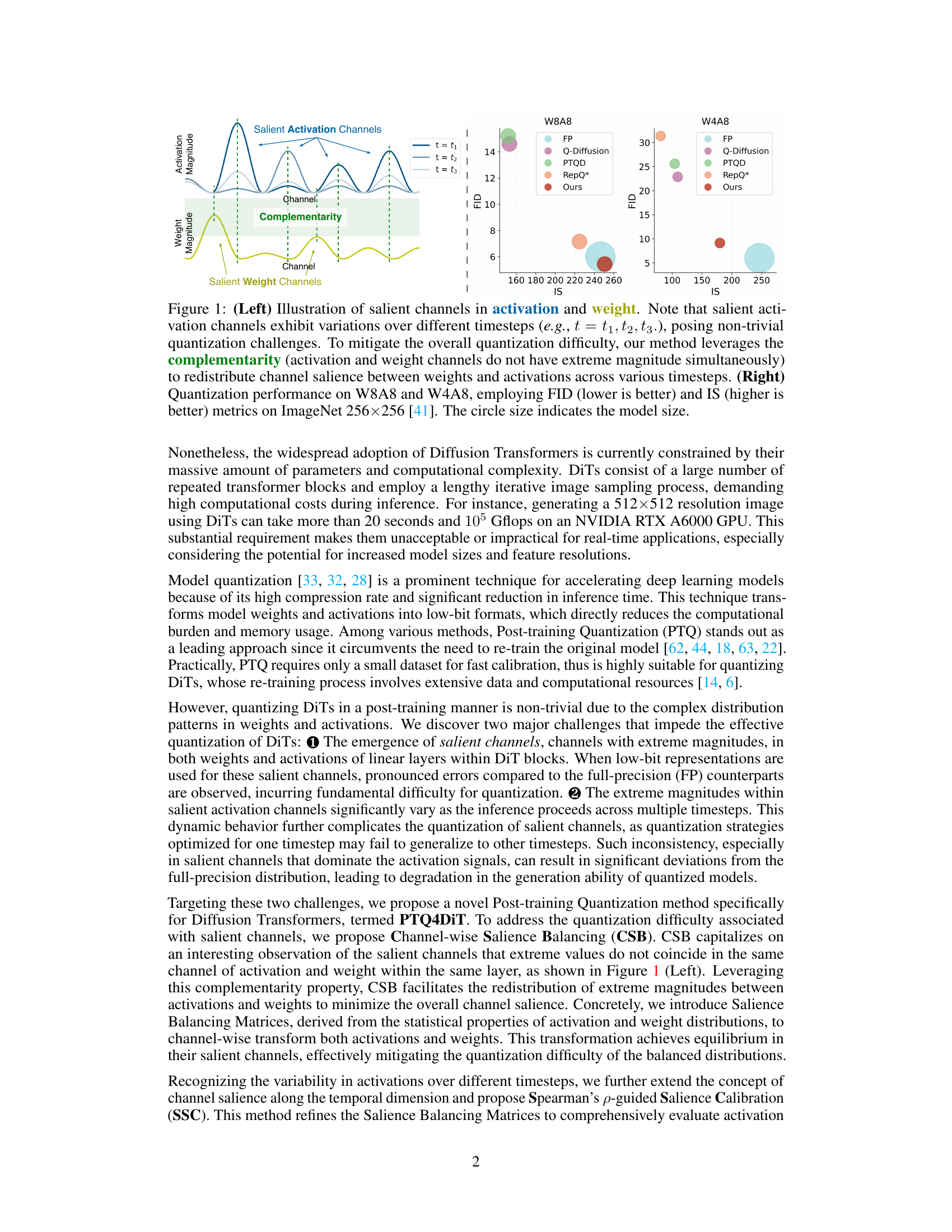
🔼 The figure demonstrates two key challenges in quantizing Diffusion Transformers: the presence of salient channels (with extreme magnitudes) in both activations and weights, and the temporal variability of salient activation distributions across multiple timesteps. The left panel illustrates these challenges, while the right panel shows the effectiveness of the proposed PTQ4DiT method compared to other quantization techniques on ImageNet in terms of FID and IS scores for different bit-widths (W8A8 and W4A8).
read the caption
Figure 1: (Left) Illustration of salient channels in activation and weight. Note that salient activation channels exhibit variations over different timesteps (e.g., t = t1, t2, t3.), posing non-trivial quantization challenges. To mitigate the overall quantization difficulty, our method leverages the complementarity (activation and weight channels do not have extreme magnitude simultaneously) to redistribute channel salience between weights and activations across various timesteps. (Right) Quantization performance on W8A8 and W4A8, employing FID (lower is better) and IS (higher is better) metrics on ImageNet 256x256 [41]. The circle size indicates the model size.
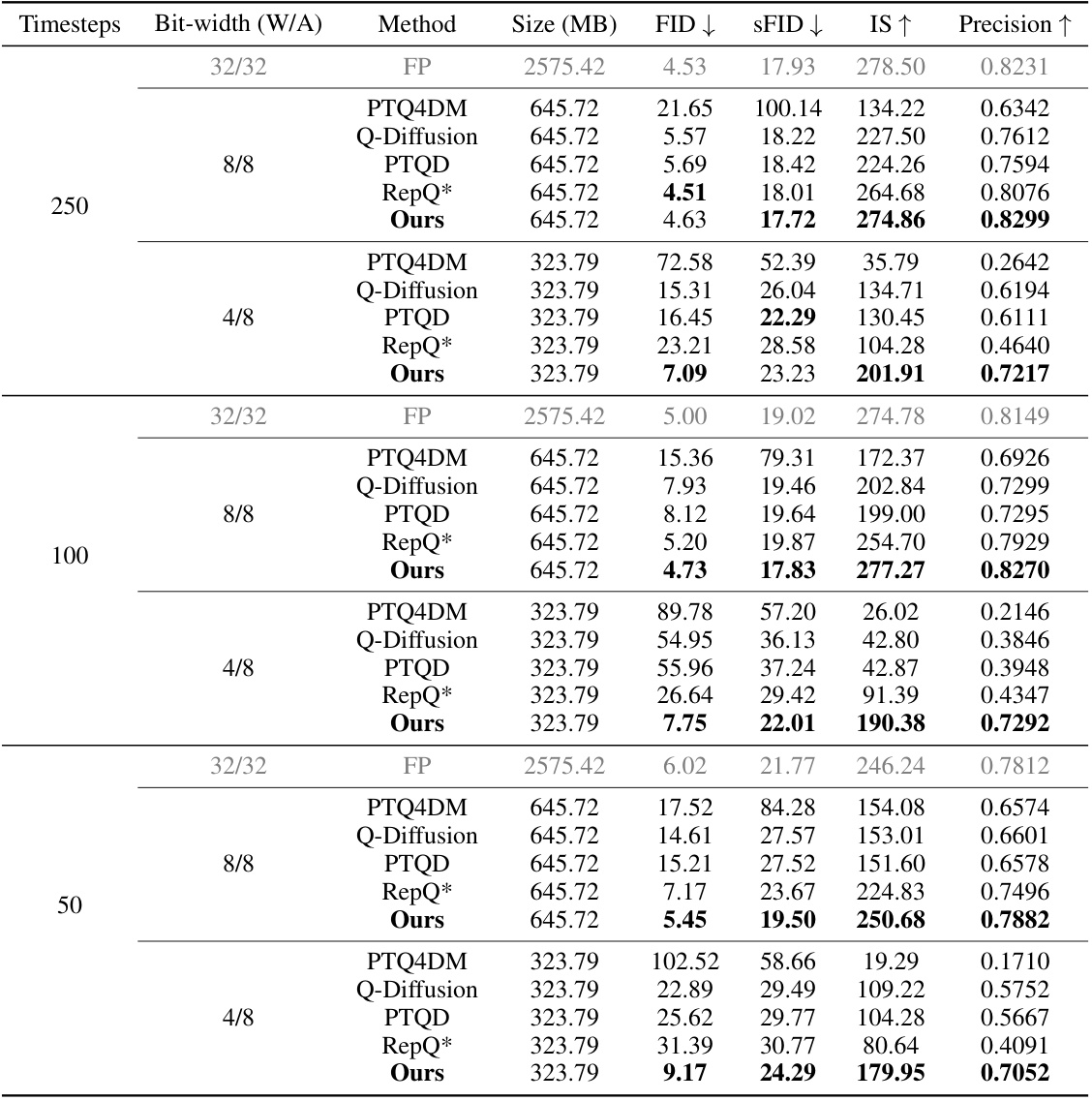
🔼 This table presents a quantitative comparison of different post-training quantization (PTQ) methods on the ImageNet dataset with 256x256 image resolution. It compares the performance of several methods including PTQ4DM, Q-Diffusion, PTQD, and RepQ*, against the full precision (FP) model. The comparison uses different quantization bit-widths (8-bit and 4-bit for both weights and activations) and varying numbers of timesteps (250, 100, and 50) during the image generation process. The metrics used for evaluation are FID, SFID, IS, and Precision. Lower FID and SFID scores, and higher IS and Precision scores indicate better performance.
read the caption
Table 1: Performance comparison on ImageNet 256x256. ‘(W/A)’ indicates that the precision of weights and activations are W and A bits, respectively.
In-depth insights#
DiT Quantization#
The research explores post-training quantization (PTQ) for Diffusion Transformers (DiTs), focusing on the unique challenges posed by their architecture. DiTs present two main hurdles to effective PTQ: the presence of channels with extreme magnitudes (salient channels), and the temporal variability in activation distributions across multiple timesteps. To address these, the authors propose Channel-wise Salience Balancing (CSB), which leverages the complementarity of extreme values in activations and weights to alleviate quantization errors, and Spearman’s p-guided Salience Calibration (SSC), which dynamically adjusts channel salience to capture temporal changes. Further, they introduce an offline re-parameterization to eliminate additional computational costs during inference. The result is PTQ4DiT, capable of achieving 8-bit precision (W8A8) while maintaining comparable generation ability and demonstrating successful 4-bit weight precision (W4A8) for the first time. This work significantly advances the applicability of DiTs to resource-constrained environments by providing an effective and efficient PTQ method.
CSB & SSC#
The paper introduces Channel-wise Salience Balancing (CSB) and Spearman’s ρ-guided Salience Calibration (SSC) as novel techniques to address the challenges of quantizing diffusion transformers. CSB leverages the observation that salient channels (those with extreme magnitudes) in activations and weights rarely coincide. By redistributing this salience, CSB aims to mitigate quantization errors. SSC further refines this approach by dynamically adjusting the salience balance across multiple timesteps. Diffusion models’ iterative denoising process introduces temporal variability in activation distributions; SSC accounts for this by weighting the salience based on the correlation between activation and weight salience at each timestep. Together, CSB and SSC form a powerful combination for effective post-training quantization of diffusion transformers, improving the balance of accuracy and efficiency.
PTQ4DiT#
PTQ4DiT, as a novel Post-training Quantization (PTQ) method for Diffusion Transformers (DiTs), tackles the challenges of DiT’s unique architecture. The core innovation is a two-pronged approach: Channel-wise Salience Balancing (CSB) redistributes extreme values between weights and activations, mitigating quantization errors. Secondly, Spearman’s p-guided Salience Calibration (SSC) dynamically adjusts this balancing across timesteps, addressing the temporal variability in DiT activations. This combined strategy effectively quantizes DiTs, achieving 8-bit precision (W8A8) with minimal performance degradation, and even 4-bit weight precision (W4A8) – a significant achievement. The offline re-parameterization further ensures that the improved quantization doesn’t add computational overhead during inference. PTQ4DiT thus offers a practical solution for deploying DiTs in resource-constrained environments, paving the way for wider adoption of these powerful generative models.
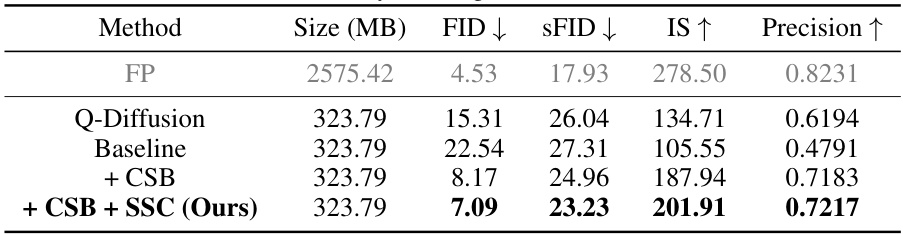
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a complex system. In the context of a research paper, this often involves removing or disabling specific features to assess their impact on overall performance. For example, in a machine learning model, an ablation study might test the impact of removing certain layers, algorithms, or data preprocessing steps. The results of an ablation study help researchers understand which parts are crucial for success and which may be redundant or even detrimental. This allows them to refine their approach, improve efficiency, and gain deeper insight into the underlying mechanisms. A well-designed ablation study can be a powerful tool for validating a proposed method or model, providing strong evidence for the claims made in the paper. A key aspect is the selection of appropriate baseline models and the clear definition of what constitutes an ablation. The analysis should carefully examine the performance changes resulting from each ablation, ideally supported by statistically significant evidence and thoughtful discussion of potential explanations.
Future Work#
Future research directions stemming from this PTQ4DiT paper could explore several promising avenues. Extending PTQ4DiT’s applicability to other diffusion model architectures, beyond the transformer-based models, would broaden its impact. Investigating the effectiveness of PTQ4DiT across diverse image generation tasks, such as high-resolution image synthesis or video generation, could reveal valuable insights into its robustness. Furthermore, a more detailed analysis of the trade-offs between quantization levels, model size, and generation quality, incorporating both quantitative metrics and qualitative visual assessments, would offer a more holistic understanding of the method’s practical limitations. Finally, addressing the limitations of the current calibration strategy by exploring more efficient and data-adaptive calibration methods is crucial for real-world deployment. This research could pave the way for effective and efficient low-bit quantization in the field of generative AI.
More visual insights#
More on figures
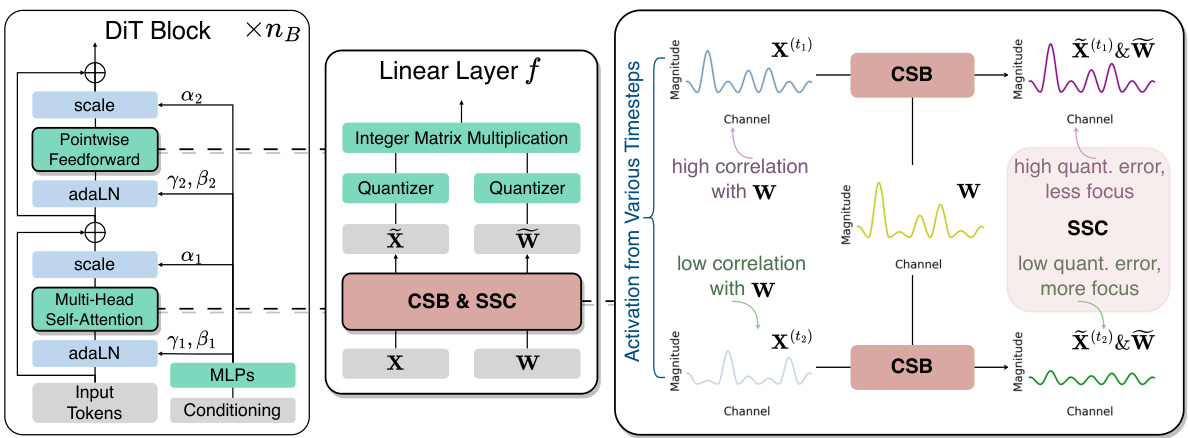
🔼 This figure illustrates the architecture of the DiT block, focusing on the linear layer within the MHSA and PF modules. It shows how the proposed methods, Channel-wise Salience Balancing (CSB) and Spearman’s p-guided Salience Calibration (SSC), are integrated to handle the challenges of quantizing diffusion transformers. The right panel visually explains how CSB redistributes salient channels across timesteps to minimize quantization errors, and how SSC dynamically adjusts the focus on specific timesteps based on error levels.
read the caption
Figure 2: (Left) Overview of the Diffusion Transformer (DiT) Block [37]. (Middle) Illustration of the linear layer in Multi-Head Self-Attention (MHSA) and Pointwise Feedforward (PF) modules, which incorporates our proposed Channel-wise Salience Balancing (CSB) and Spearman's p-guided Salience Calibration (SSC) to address quantization difficulties for both activation X and weight W. Appendix A depicts detailed structures of the MHSA and PF modules with adjusted linear layers. (Right) Illustration of CSB and SSC in PTQ4DiT. CSB redistributes salient channels between weights and activations from various timesteps to reduce overall quantization errors. SSC calibrates the activation salience across multiple timesteps via selective aggregation, with more focus on timesteps where quantization errors can be significantly reduced by CSB.
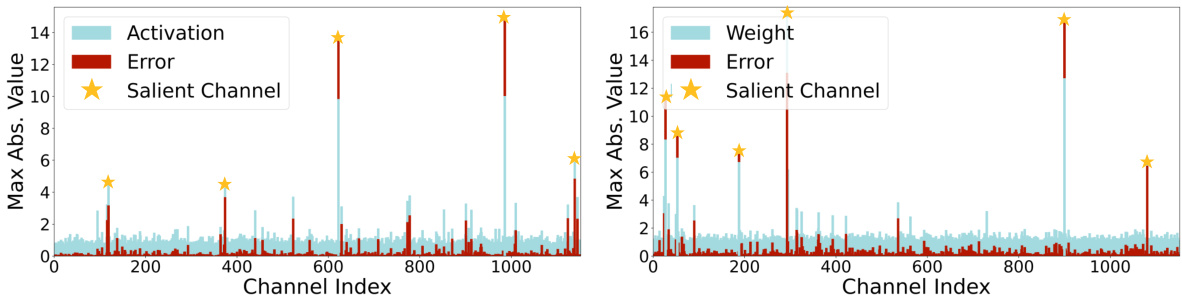
🔼 This figure shows the distribution of maximal absolute values for both activation and weight channels in a linear layer of a Diffusion Transformer (DiT). The left panel shows activation channels while the right panel shows weight channels. The y-axis represents the maximum absolute values, and the x-axis represents the channel index. Overlaid on the channel values are bars representing the quantization error (MSE) for each channel. The figure highlights that channels with larger maximal absolute values (marked with stars) tend to experience significantly higher quantization errors. This observation demonstrates a key challenge in quantizing DiTs, where channels with extreme magnitudes cause substantial quantization errors.
read the caption
Figure 3: Illustration of maximal absolute magnitudes of activation (left) and weight (right) channels in a DiT linear layer, alongside their corresponding quantization Error (MSE). Channels with greater maximal absolute values tend to incur larger errors, presenting a fundamental quantization difficulty.
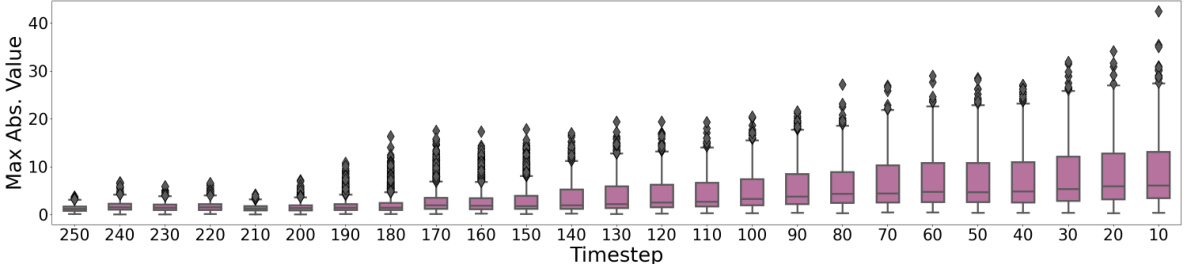
🔼 This figure shows how the maximum absolute values of activation channels in a linear layer of a Diffusion Transformer model change over different timesteps during the image generation process. The box plots illustrate the distribution of these maximum values for each timestep. The significant variation across timesteps highlights a key challenge in applying post-training quantization to DiTs: the distributions of salient channels (those with extreme magnitudes) are not static but change dynamically throughout the inference process.
read the caption
Figure 4: Boxplot of maximal absolute magnitudes of activation channels in a linear layer within DiT over different timesteps, which exhibit significant temporal variations.

🔼 This figure compares the image generation quality of PTQ4DiT with two other state-of-the-art post-training quantization methods (RepQ* and Q-Diffusion) for diffusion transformers. The images show that PTQ4DiT generates images with better details and overall quality, particularly noticeable in the W4A8 (4-bit weight, 8-bit activation) quantization setting. The comparison is done using the ImageNet dataset at both 512x512 and 256x256 resolutions.
read the caption
Figure 5: Random samples generated by PTQ4DiT and two strong baselines: RepQ* [21] and Q-Diffusion [18], with W4A8 quantization on ImageNet 512x512 and 256x256. Our method can produce high-quality images with finer details. Appendix E presents more visualization results.
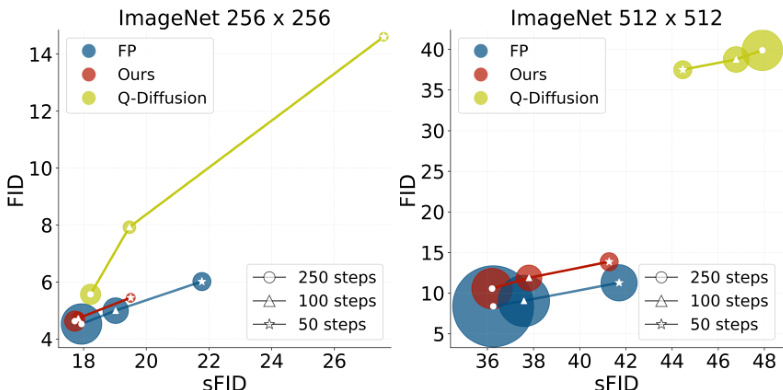
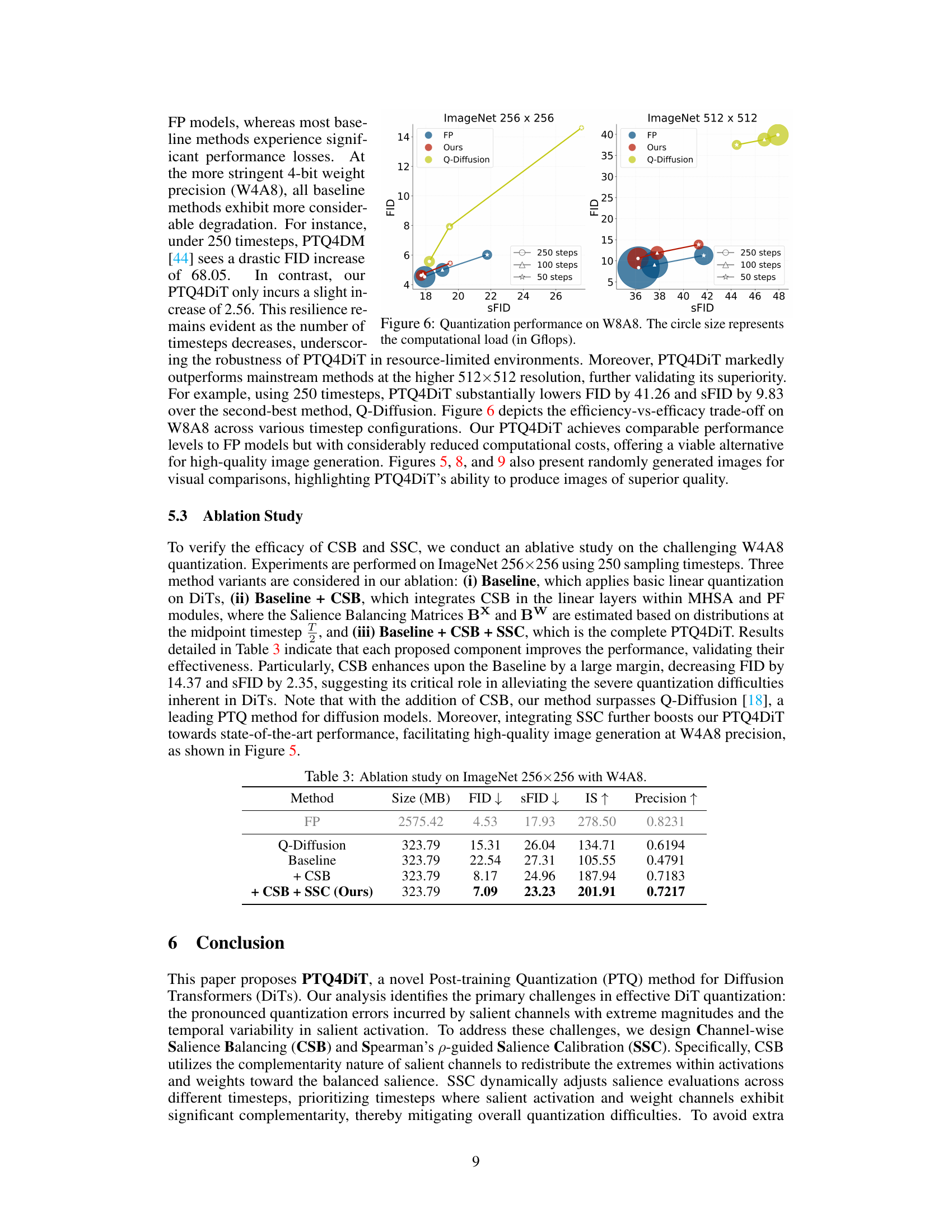
🔼 This figure shows the quantization performance results on W8A8 for different numbers of sampling steps (250, 100, and 50) on ImageNet datasets with resolutions of 256x256 and 512x512. The x-axis represents the SFID (Spatial Fréchet Inception Distance), and the y-axis represents the FID (Fréchet Inception Distance). The circle size of each point indicates the model size and correlates to computational cost. The results demonstrate that PTQ4DiT achieves comparable performance to the full-precision (FP) model while significantly reducing computational costs, especially at higher resolutions and fewer sampling steps.
read the caption
Figure 6: Quantization performance on W8A8. The circle size represents the computational load (in Gflops).
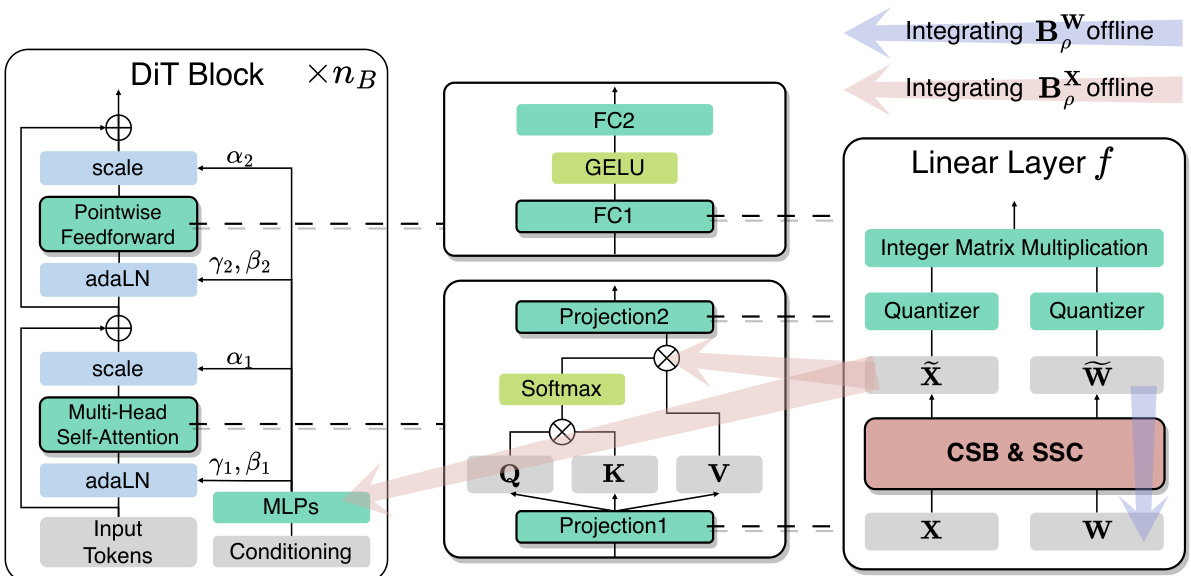
🔼 This figure illustrates how Channel-wise Salience Balancing (CSB) and Spearman’s ρ-guided Salience Calibration (SSC) are integrated into the Multi-Head Self-Attention (MHSA) and Pointwise Feedforward (PF) modules of Diffusion Transformer (DiT) blocks to address the challenges of salient channels and temporal variability in DiT quantization. It shows how the salience balancing matrices are incorporated into the linear layers (Projection1, Projection2, FC1) to redistribute salience between activations and weights, thereby mitigating quantization errors. The offline integration of the matrices into the weight matrix and MLPs prevents added computational cost during inference.
read the caption
Figure 7: Illustration of structures of the MHSA and PF modules within DiT Blocks [37]. Our proposed CSB and SSC are embedded in their linear layers, including Projection1, Projection2, and FC1. CSB and SSC collectively mitigate the quantization difficulties by transforming both activations and weights using Salience Balancing Matrices, BW and BX. To prevent extra computational burdens at inference time, BW is absorbed into the weight matrix of the linear layer f. Meanwhile, BX is integrated offline into the MLPs layer prior to adaLN modules for Projection1 and FC1, and into the preceding matrix multiplication operation for Projection2.

🔼 This figure compares the image generation quality of PTQ4DiT with two other state-of-the-art post-training quantization methods (RepQ* and Q-Diffusion) and the full-precision model. The comparison is made using W4A8 quantization (4-bit weights, 8-bit activations) on the ImageNet dataset at 256x256 and 512x512 resolution. The figure shows example image samples from each method, highlighting that PTQ4DiT produces images with greater detail and quality compared to the baselines. Appendix E contains additional visualization results.
read the caption
Figure 5: Random samples generated by PTQ4DiT and two strong baselines: RepQ* [21] and Q-Diffusion [18], with W4A8 quantization on ImageNet 512x512 and 256x256. Our method can produce high-quality images with finer details. Appendix E presents more visualization results.

🔼 This figure compares image samples generated using different post-training quantization (PTQ) methods, including RepQ*, Q-Diffusion, PTQD, and the proposed PTQ4DiT, with a weight and activation precision of 8 bits (W8A8). It also includes samples from the full-precision DiT model for comparison. The images were generated using the ImageNet 256x256 dataset. The purpose is to visually demonstrate the relative quality of images produced by each PTQ method compared to the original, unquantized model. The visual comparison helps assess the impact of each quantization technique on the generative capabilities of the diffusion transformer model.
read the caption
Figure 9: Random samples generated by different PTQ methods with W8A8 quantization, alongside the full-precision DiTs [37], on ImageNet 256x256.
More on tables
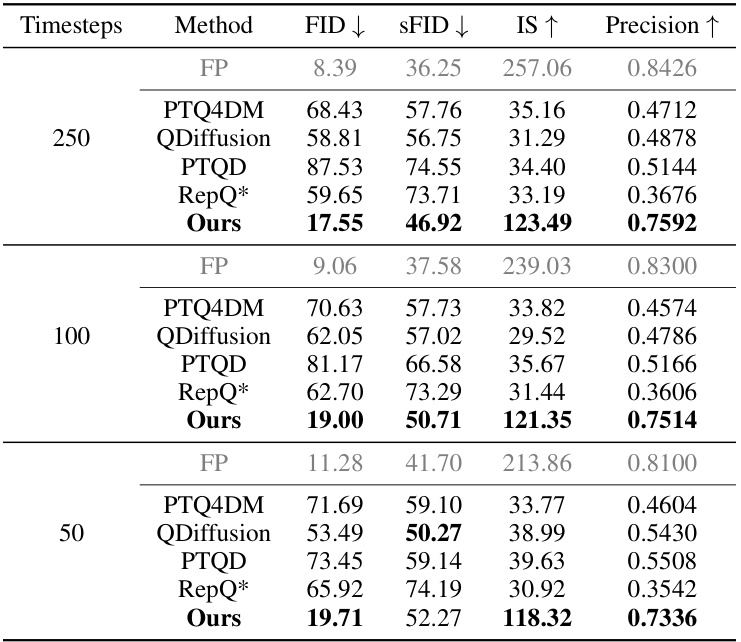
🔼 This table presents a comparison of the performance of different post-training quantization (PTQ) methods on the ImageNet 256x256 dataset. The methods are compared using FID, sFID, IS, and Precision metrics at various bit-widths (W/A) for weights and activations. The results show the effectiveness of the proposed PTQ4DiT method in maintaining high performance compared to existing methods, even at lower bit-widths.
read the caption
Table 1: Performance comparison on ImageNet 256x256. ‘(W/A)’ indicates that the precision of weights and activations are W and A bits, respectively.
🔼 This table compares the performance of different post-training quantization (PTQ) methods on the ImageNet 256x256 dataset. The methods are evaluated using various metrics (FID, sFID, IS, Precision) at different bit-widths (8-bit and 4-bit) for weights and activations and different numbers of sampling steps. It allows for assessing the effectiveness of each quantization method in preserving image generation quality while reducing computational cost.
read the caption
Table 1: Performance comparison on ImageNet 256x256. ‘(W/A)’ indicates that the precision of weights and activations are W and A bits, respectively.
Full paper#