↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Visual emotion recognition systems are often evaluated using accuracy, which treats all misclassifications equally. However, misclassifying “excitement” as “anger” is more significant than misclassifying it as “awe” due to psychological similarities. This paper addresses this limitation.
The authors propose novel metrics, ECC and EMC, which incorporate emotional distance from a psychological model (Mikel’s emotion wheel) to assess the severity of different misclassifications. They demonstrate the effectiveness of these metrics in semi-supervised learning tasks, showing that ECC and EMC better reflect human emotional cognition compared to accuracy alone, leading to improved model selection and performance.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the limitations of traditional accuracy-based metrics in visual emotion recognition by proposing novel metrics that consider emotional similarity. This is important because it improves the evaluation of emotion recognition models, leading to better-performing systems.
Visual Insights#
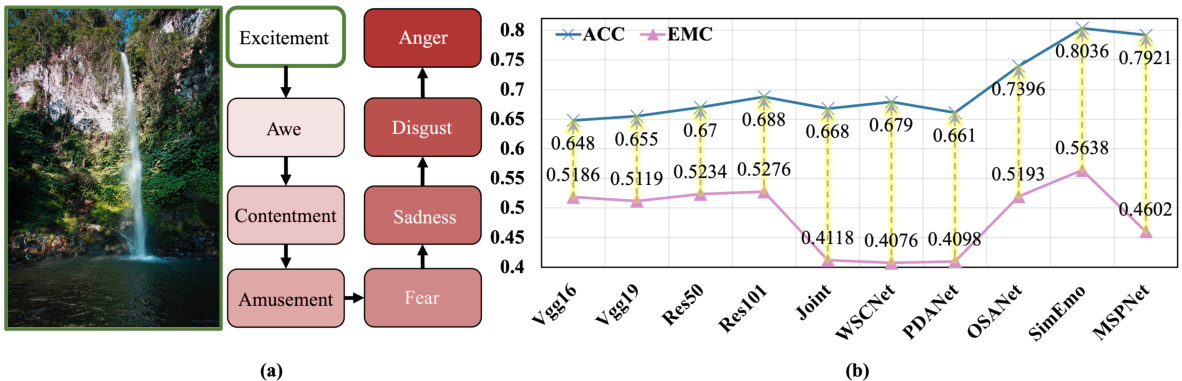
This figure shows two key aspects of visual emotion recognition evaluation. (a) illustrates the concept of emotional distance, highlighting that misclassifying ’excitement’ as ‘anger’ is more severe than misclassifying it as ‘awe’ due to their psychological proximity. (b) presents a comparison of accuracy (ACC) and emotional misclassification confidence (EMC) across various state-of-the-art models. While accuracy has improved significantly, EMC has not, indicating that although models classify images correctly more often, the severity of misclassifications remains a concern.
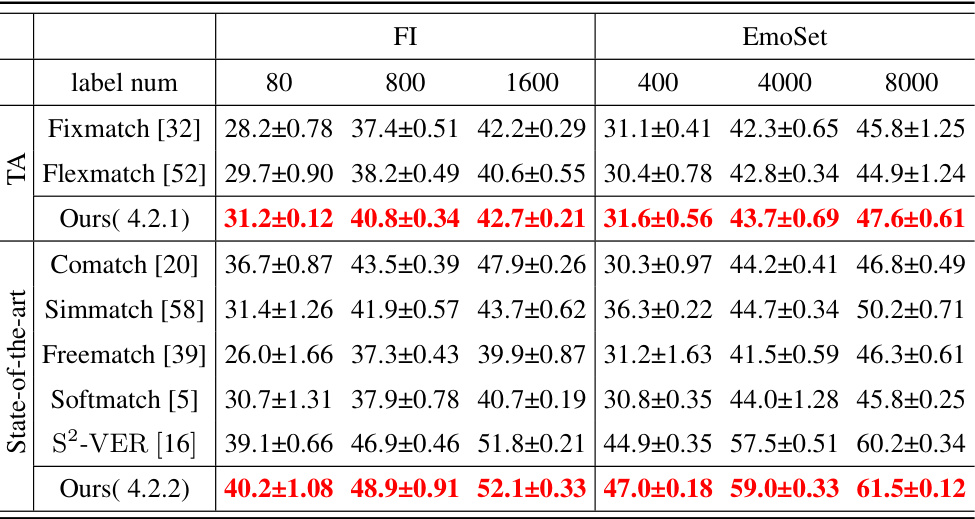
This table presents the results of semi-supervised learning experiments on two datasets, FI and EmoSet, using different methods. The methods are compared based on their accuracy (ACC) achieved with varying numbers of labeled samples. It highlights a comparison of the proposed method with two similar approaches (FixMatch and FlexMatch) using a threshold adjustment technique, and a broader comparison against other state-of-the-art semi-supervised methods.
In-depth insights#
Affective Bias Metrics#
Affective bias metrics represent a crucial advancement in evaluating emotion recognition systems. Standard accuracy metrics fail to capture the nuanced nature of emotional similarity; misclassifying ‘joy’ as ‘surprise’ is less problematic than mistaking ‘joy’ for ‘sadness’. Affective bias metrics address this by incorporating psychological models of emotional relationships, such as the emotional distance between categories on a wheel, weighting misclassifications based on their semantic proximity. This approach aligns with human cognitive processes, yielding a more meaningful performance evaluation. The development of these metrics not only enhances the assessment of existing systems but also guides the design of future models that are more attuned to the complexities of human emotion. They encourage building systems that are robust and less prone to high-impact misclassifications, rather than simply maximizing overall accuracy. This approach emphasizes the importance of understanding the psychological implications of misclassifications, which is pivotal for applications where accuracy alone is insufficient, such as mental health diagnosis or personalized affective computing systems. Ultimately, incorporating affective bias metrics promotes the creation of more empathetic and effective AI.
ECC & EMC Measures#
The proposed ECC and EMC measures offer a novel approach to evaluating visual emotion recognition models by moving beyond simple accuracy. ECC (Emotion Confusion Confidence) considers the emotional distance between misclassified emotions, weighting errors based on their psychological similarity. This addresses the limitation of traditional accuracy metrics which treat all misclassifications equally. EMC (Emotional Misclassification Confidence) focuses specifically on misclassifications, providing a more nuanced evaluation of error severity. The integration of Mikel’s emotion wheel into the calculation of emotional distance is a key strength, aligning the metrics with psychological understanding of emotional proximity. By incorporating emotional distance, ECC and EMC offer a more sensitive and informative assessment of model performance, providing a more holistic evaluation than traditional accuracy metrics alone. The measures show greater alignment with human perception of emotional errors, reflecting a more psychologically-grounded evaluation.
Semi-Supervised Tests#
In semi-supervised learning, a key challenge lies in effectively leveraging unlabeled data alongside limited labeled examples. Semi-supervised tests would rigorously evaluate how well a model generalizes to unseen data by employing various strategies. These might involve techniques such as pseudo-labeling, where the model assigns labels to unlabeled data based on its confidence, or self-training, where the model iteratively trains on its own predictions. Robust evaluation metrics would be essential, going beyond simple accuracy to consider aspects like uncertainty calibration and the effect of label noise. Careful consideration of the dataset composition is also crucial to avoid biases in the evaluation process. The experiments should consider diverse scenarios, exploring different amounts of labeled data, varying levels of label noise, and potentially different model architectures to understand their robustness and identify potential limitations of the proposed approach. The ultimate goal is to gain valuable insights into the effectiveness of semi-supervised methods and provide guidelines for best practices.
User Study Results#
A user study designed to validate the proposed metrics, ECC and EMC, which consider emotional distance during misclassification, would involve carefully selecting participants and images. The images should represent a range of emotions and varying degrees of ambiguity. Participants would be asked to compare the model’s emotion classifications to the true labels, judging not only correctness, but also the severity of errors. The core of the study should assess whether the human perception of misclassification severity aligns with the metrics’ calculations. The study design should control for potential biases, and statistical analysis of the results will determine if the proposed metrics are effective at capturing the human understanding of emotion similarity and misclassification severity. Results should show a significant positive correlation between participant judgments and the calculated values of ECC and EMC, demonstrating a higher accuracy and a better reflection of actual emotion perception compared to traditional accuracy metrics. Successful results would strongly support the adoption of ECC and EMC as more robust and psychologically informed evaluation metrics for visual emotion recognition.
Future Work#
Future research directions stemming from this work on affective bias-inspired measures for visual emotion recognition evaluation could focus on several key areas. Extending the methodology to encompass a wider range of emotions and cultural contexts is crucial to enhance generalizability. Investigating the impact of different modalities (e.g., text, audio) on emotion recognition and the effectiveness of the proposed metrics in multimodal settings is another promising avenue. Furthermore, exploring the integration of affective bias measures with other state-of-the-art emotion recognition techniques could lead to improved performance. A deeper analysis into the relationship between specific types of misclassifications and underlying cognitive processes would contribute significantly to our understanding of emotion perception. Finally, developing new loss functions that incorporate emotional distance to optimize model training and minimize affective bias-driven misclassifications should be explored. The practical application of these findings in real-world systems (e.g., mental health diagnostics, human-computer interaction, personalized education) is a key next step.
More visual insights#
More on figures
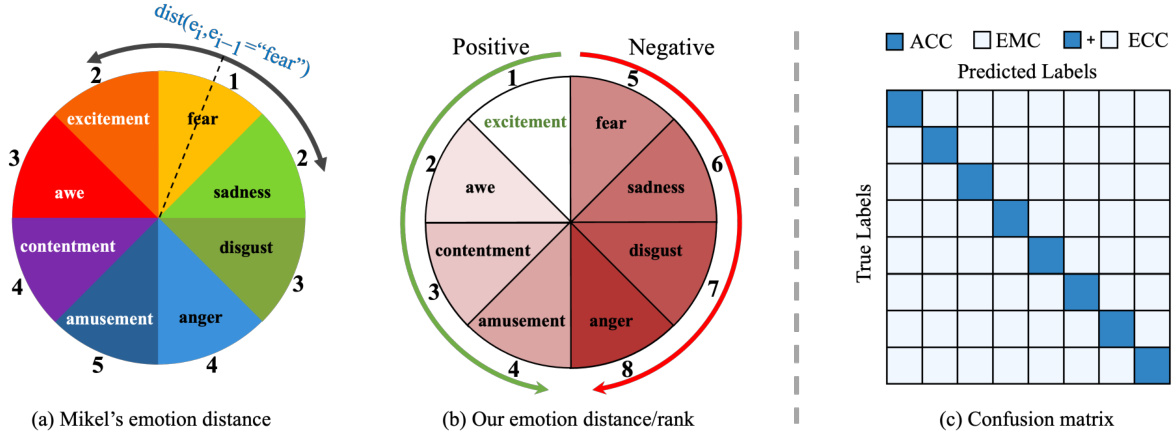
This figure shows three parts: (a) Mikel’s emotion distance, which is a circular representation of eight basic emotions, with distances between emotions indicating their psychological proximity; (b) the authors’ proposed emotion distance/rank, modifying Mikel’s model to better reflect the emotional polarity and calculating the distance as a combination of the number of steps and polarity difference; (c) a confusion matrix illustrating how the proposed measures ACC (accuracy), ECC (emotion confusion confidence), and EMC (emotional misclassification confidence) are calculated. The confusion matrix shows the relationship between true and predicted emotion labels, with ECC and EMC incorporating the emotional distance to more accurately reflect the severity of misclassifications.
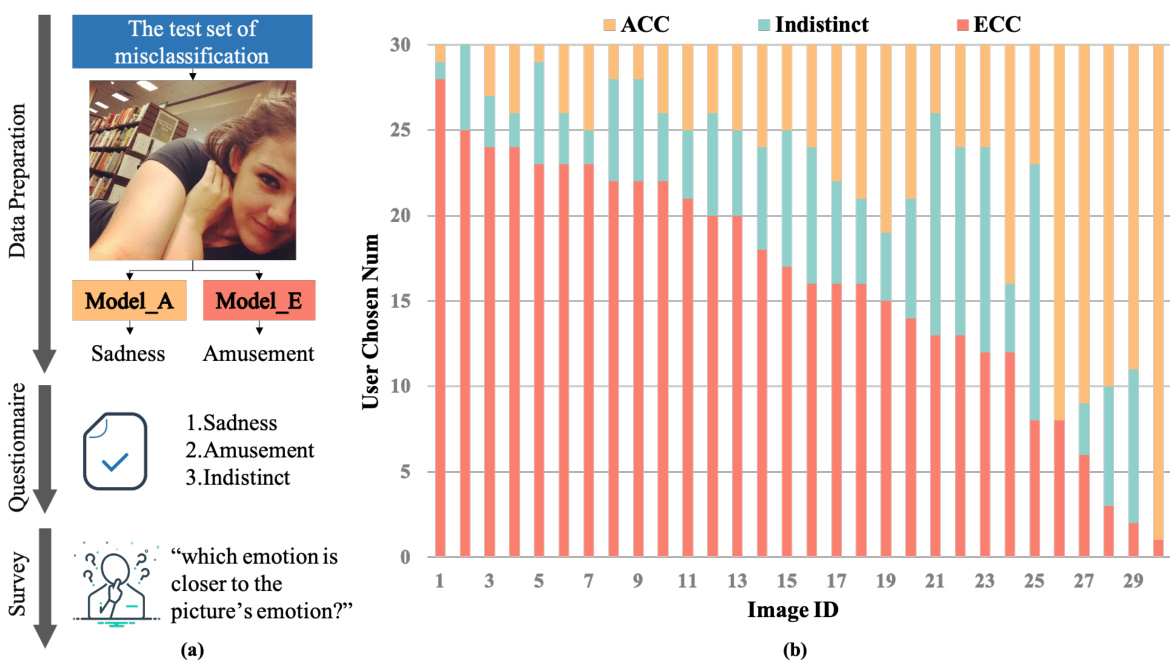
This figure presents the results of a user study designed to validate the proposed emotional distance metrics. Panel (a) shows the workflow of the study: a set of misclassified images from two different models were presented to participants; participants were asked to choose which of three emotional labels (the incorrect label predicted by one model, the incorrect label predicted by the other model, or ‘Indistinct’) was closest to the image’s actual emotion. Panel (b) displays the results: a bar chart showing the number of votes for each option (ACC, Indistinct, and ECC) for each of 30 test images. The chart visually demonstrates participant preference for the model with higher emotional confusion confidence (ECC) in most cases.

This figure compares the t-SNE visualizations of emotion embeddings from two different network architectures (ResNet18 and ResNet50) trained with two different loss functions (cross-entropy and a combination of cross-entropy and ListMLE). The parameter alpha in the combined loss function controls the weight of ListMLE. Alpha values of 0 and 1 represent different emphasis on ListMLE. The plots show how the distribution of emotion embeddings changes with the network architecture and loss function, visualizing the effect of incorporating ListMLE (which considers emotional relationships) on the learned representation of emotions.
More on tables

This table presents the results of experiments conducted on two datasets (FI and EmoSet) using three different CNN backbones (ResNet18, ResNet50, and ResNet101). Two loss functions were used: cross-entropy loss (LCE) and a combined loss (Lc) which incorporates LCE and ListMLE. The table shows the performance metrics for each combination of dataset, backbone, and loss function, including Accuracy (ACC), Accuracy considering only the same polarity (ACC2), Emotion Confusion Confidence (ECC), and Emotional Misclassification Confidence (EMC). The results demonstrate the impact of the different loss functions on the accuracy and the proposed metrics.
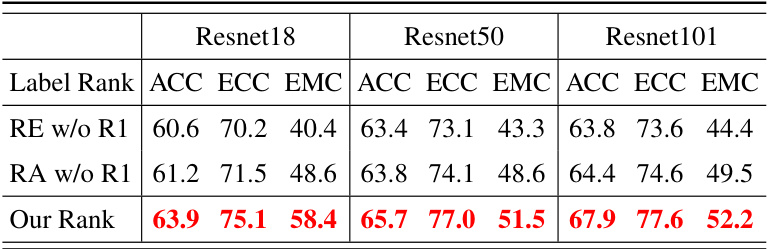
This table presents a comparative analysis of the impact of different label ranking methods on the performance of single visual emotion classification tasks using the FI dataset. The experiment used the ListMLE loss function. Three ranking methods were tested: ‘Our Rank’ (based on Mikel’s emotion wheel), ‘RA’ (randomly scrambled labels), and ‘RE’ (reverse-ranked labels). A variant of each method (‘w/o R1’) kept the ground truth rank in the first position. The table shows the accuracy (ACC), emotional confusion confidence (ECC), and emotional misclassification confidence (EMC) for each ranking method and three different network backbones (ResNet18, ResNet50, ResNet101). The best results for each metric and backbone are highlighted in red.
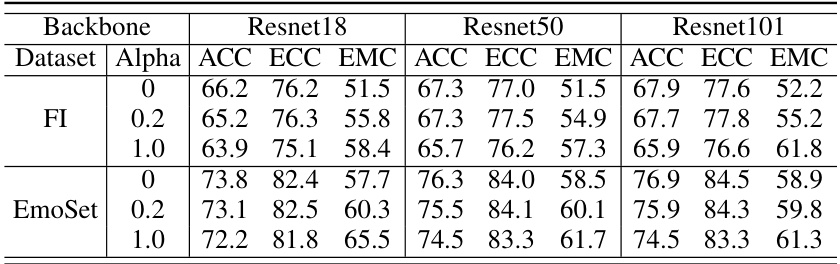
This table presents the results of experiments conducted on three different datasets (FI, EmoSet, and UnbiasedEmo) using three different backbones (ResNet18, ResNet50, and ResNet101) to evaluate the performance of a proposed loss function. The experiments compare the performance of the proposed method with multiple classical baseline methods. The performance is measured using three metrics: Accuracy (ACC), Emotion Confusion Confidence (ECC), and Emotional Misclassification Confidence (EMC), for different alpha values (0, 0.2, and 1.0) which represents a hyperparameter in the loss function. The table showcases how the proposed loss function impacts the performance of different models across various datasets and evaluation metrics.
Full paper#



















