TL;DR#
Many studies have explored aligning vision models with human perception, particularly for specific tasks like image generation. However, the impact of perceptual alignment on general-purpose vision tasks remained unclear. This paper addresses this gap by evaluating the impact of human perceptual alignment on various tasks. The study highlighted an issue where existing vision models, despite understanding semantic abstractions, improperly weigh visual attributes like scene layout and object locations, thus making inferences misaligned with human perception.
This research investigated how aligning vision representations with human perceptual judgments affected various downstream tasks. They fine-tuned state-of-the-art models using human similarity judgments for image triplets and then assessed performance on tasks including counting, segmentation, depth estimation, and retrieval. The key finding was that perceptual alignment significantly improved performance on tasks like counting and segmentation but reduced performance on natural classification. The work also analyzed the influence of various types of similarity annotations, finding mid-level judgments to be the most beneficial. These findings offer valuable insights into the nature of human perception and its influence on vision models.
Key Takeaways#
Why does it matter?#
This paper is crucial for vision researchers as it reveals how aligning vision models with human perceptual judgments improves performance on various downstream tasks. It challenges the conventional wisdom about alignment and opens new avenues for improving the generalizability and human-likeness of vision models. The findings have implications for a wide range of applications, including robotics and image generation.
Visual Insights#

🔼 This figure illustrates the research question and methodology of the paper. A pretrained vision model is fine-tuned using human perceptual similarity judgments. The resulting model is then evaluated on various downstream tasks, such as counting, segmentation, depth estimation, and retrieval-augmented generation, to determine if aligning vision models with human perception improves performance. The figure visually depicts the process and includes example tasks and datasets.
read the caption
Figure 1: Does human perceptual alignment improve vision representations? Vision models have been shown to learn useful image representations through large-scale pretraining (e.g., CLIP, DINO). We find that additionally aligning these models to human perceptual judgments yields representations that improve upon the original backbones across many downstream tasks, including counting, segmentation, depth estimation, instance retrieval, and retrieval-augmented generation, while degrading performance in natural classification tasks. Our blog post and code are available at percep-align.github.io.
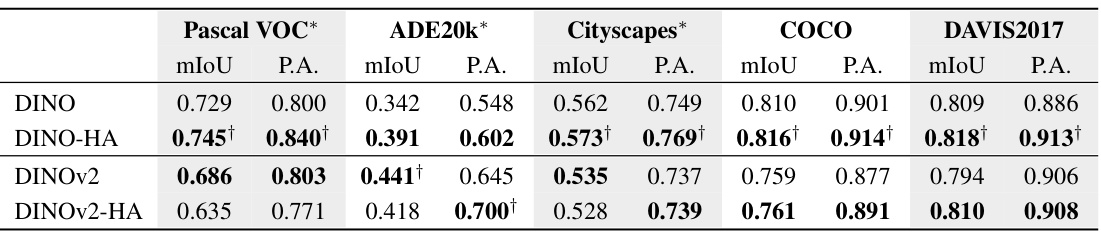
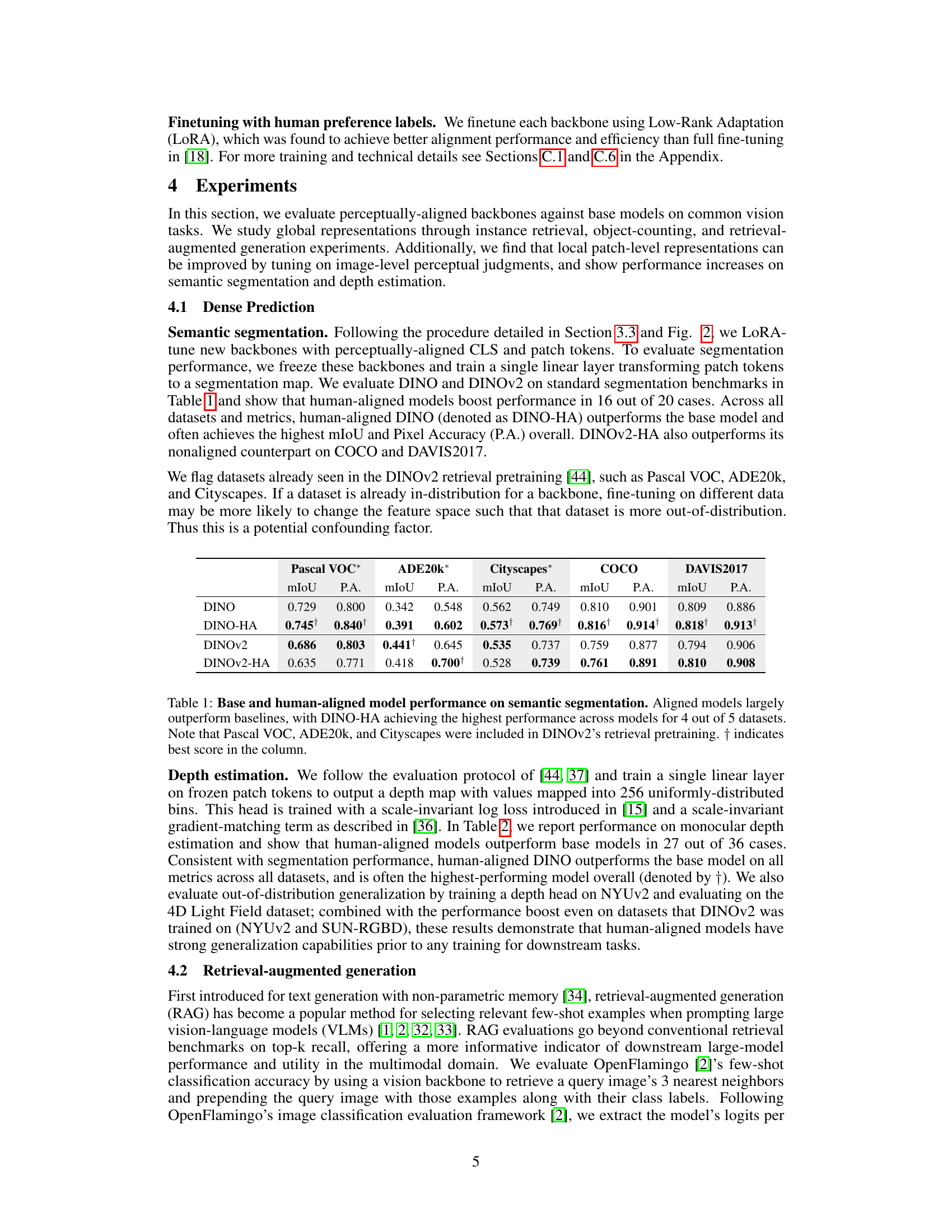
🔼 This table presents the performance comparison of base and human-aligned vision models on semantic segmentation tasks across five datasets: Pascal VOC, ADE20k, Cityscapes, COCO, and DAVIS2017. The results show the mean Intersection over Union (mIoU) and Pixel Accuracy (P.A.) for each model. It highlights that models fine-tuned with human perceptual judgments generally outperform their baselines, particularly DINO-HA (human-aligned DINO). The note clarifies that some of these datasets were already used in the pre-training of DINOv2, which might impact the results.
read the caption
Table 1: Base and human-aligned model performance on semantic segmentation. Aligned models largely outperform baselines, with DINO-HA achieving the highest performance across models for 4 out of 5 datasets. Note that Pascal VOC, ADE20k, and Cityscapes were included in DINOv2's retrieval pretraining. † indicates best score in the column.
In-depth insights#
Perceptual Alignment#
The concept of perceptual alignment in computer vision focuses on aligning the way machine vision models perceive and understand images with how humans do. This involves training models not just on semantic labels (e.g., ‘cat’, ‘dog’), but also on human judgments of perceptual similarity; for example, determining which of two images is more similar to a reference image based on human perception of visual attributes like color, texture, and composition. The key benefit is that perceptually aligned models tend to generalize better to diverse downstream tasks, showing improved performance on object counting, segmentation, and image retrieval compared to models trained only on standard semantic labels. However, this comes with the caveat that performance on some natural image classification tasks might degrade, suggesting a nuanced relationship between perceptual alignment and task-specific performance. The effectiveness of perceptual alignment also strongly depends on the characteristics of the dataset used to train the alignment. Using datasets focused on mid-level image attributes seems most beneficial. Thus, perceptual alignment presents a valuable technique in improving the robustness and human-like qualities of computer vision, albeit one that requires careful consideration of dataset selection and downstream task.
Vision Task Impact#
The paper investigates how aligning vision representations to human perceptual judgments affects performance across diverse vision tasks. The core finding is that perceptual alignment significantly improves performance on certain tasks, notably those involving dense prediction (segmentation, depth estimation), object counting, and retrieval-augmented generation. This suggests that incorporating human perceptual knowledge, especially mid-level visual features, can improve the generalizability and robustness of vision models. However, this improvement isn’t universal, with a notable decline observed in natural image classification tasks. This highlights a key trade-off: enhancing alignment with human perception might compromise performance on tasks where models already possess strong pre-trained capabilities. The study underscores the complex relationship between model architecture, training data, and the type of human feedback used. The choice of human perceptual annotation significantly impacts results, indicating that careful consideration of the specific perceptual attributes used for alignment is crucial for achieving targeted improvements.
Human-Aligned Models#
The concept of “Human-Aligned Models” in the context of computer vision involves aligning the performance and internal representations of machine learning models with human perception and judgment. This alignment process, often achieved through fine-tuning on datasets of human perceptual judgments, aims to bridge the gap between how machines and humans interpret visual information. The benefits of such alignment extend to improving performance in various downstream tasks, including object counting, segmentation, and retrieval tasks, where models are required to exhibit perception similar to that of humans. However, this alignment isn’t universally beneficial and can sometimes negatively impact performance on certain tasks, such as standard image classification tasks, suggesting that the nature of human perception is multifaceted and not easily captured by a single alignment strategy. Therefore, a nuanced understanding of both the benefits and potential limitations of human alignment is crucial for building more effective and human-centric vision systems. Further research may explore more sophisticated alignment strategies that cater to task-specific nuances of human visual understanding.
Dataset Ablation#
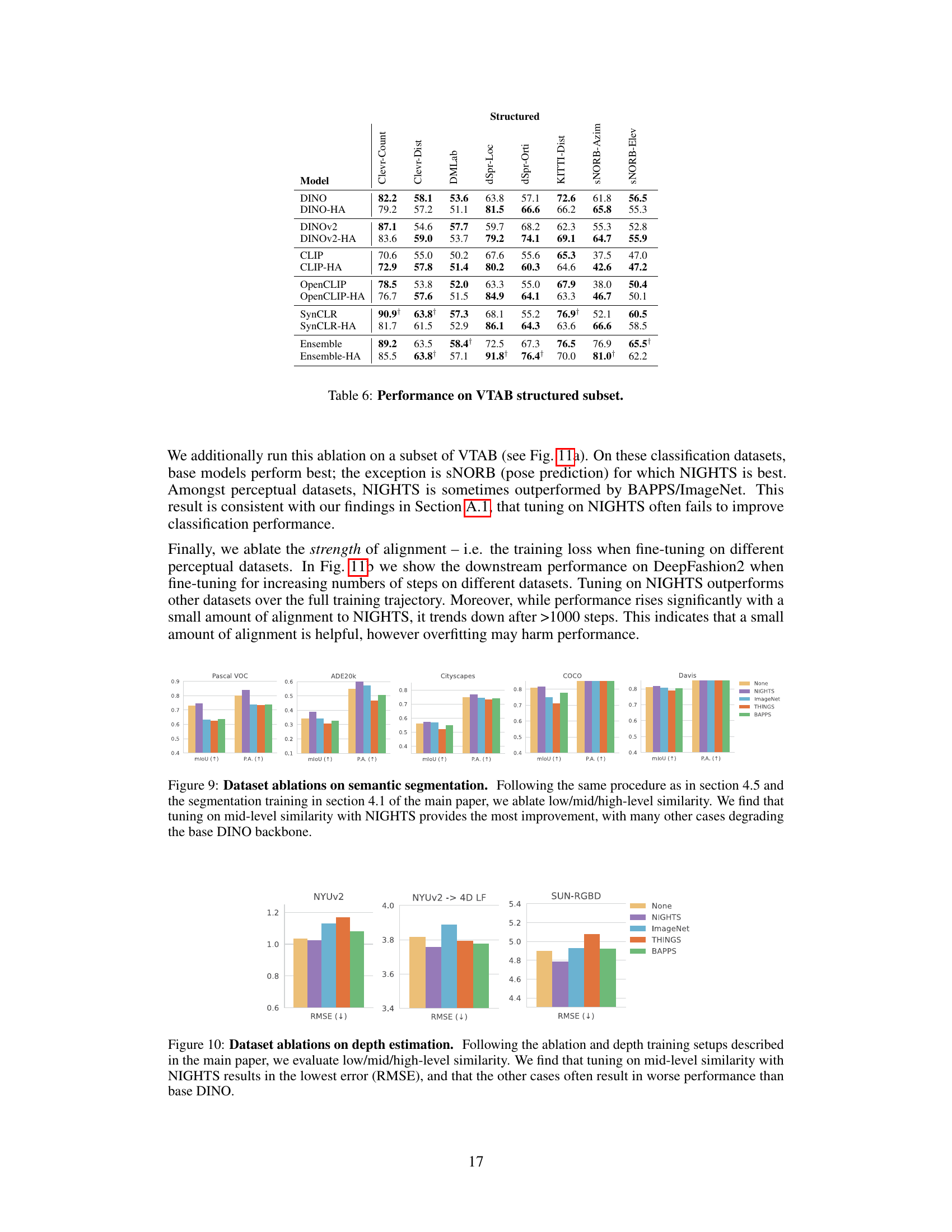
The goal of the dataset ablation is to determine the impact of different human perceptual similarity datasets on downstream vision tasks. The authors systematically replace the primary dataset (NIGHTS) with three alternatives: BAPPS, THINGS, and ImageNet. Results reveal a significant dependence on dataset choice, highlighting NIGHTS’ superiority in improving performance on object counting and instance retrieval tasks. BAPPS and ImageNet show minimal to no impact, indicating mid-level perceptual attributes are more beneficial for these tasks than low-level (BAPPS) or high-level (ImageNet) features. The THINGS dataset even resulted in performance degradation, suggesting that aligning to certain higher-level conceptual similarities may not always benefit general-purpose vision. This ablation effectively demonstrates the importance of human perception in model training and the critical need to select datasets tailored to specific downstream task requirements. The findings strongly suggest that mid-level perceptual features captured in the NIGHTS dataset are optimal for applications requiring understanding of object relations, counts, and spatial understanding.
Future Directions#
Future research could explore extending perceptual alignment to more complex visual tasks, such as video understanding and 3D scene reconstruction, to assess the generalizability of the approach beyond static images. Investigating the impact of different types of human perceptual judgments (low-level, mid-level, high-level) on various downstream tasks would provide a more nuanced understanding of the inductive bias injected. A key area to explore is reconciling perceptual alignment with fairness and robustness by developing methods that mitigate the risk of amplifying biases present in the training data. The development of more efficient training strategies for human-aligned models is crucial for broader adoption. Finally, applying this work to other modalities such as audio or natural language, and examining cross-modal perceptual alignment could lead to more holistic and human-like AI systems. These explorations promise a deeper understanding of human visual perception and its application in machine learning.
More visual insights#
More on figures

🔼 This figure illustrates the feature extraction process for training with a patch-level objective. The left side shows how the CLS (classification) token and patch embeddings are extracted from a vision transformer model (like DINO or DINOv2). These are then spatially average-pooled and concatenated. The right side demonstrates how these concatenated features are used in training with a hinge loss, which is the same loss used for the image-level objective. This patch-level approach allows for incorporating human similarity judgments at a more granular level, aligning local features with global perceptual similarity.
read the caption
Figure 2: Diagram of our feature extraction method when training with a patch-level objective. Left: We extract the CLS and patch embeddings from DINO and DINOv2, perform a spatial average-pool on the patch embeddings, and concatenate [CLS, patch] vectors. Right: We train these concatenated features with a hinge loss, identical to the image-level objective.
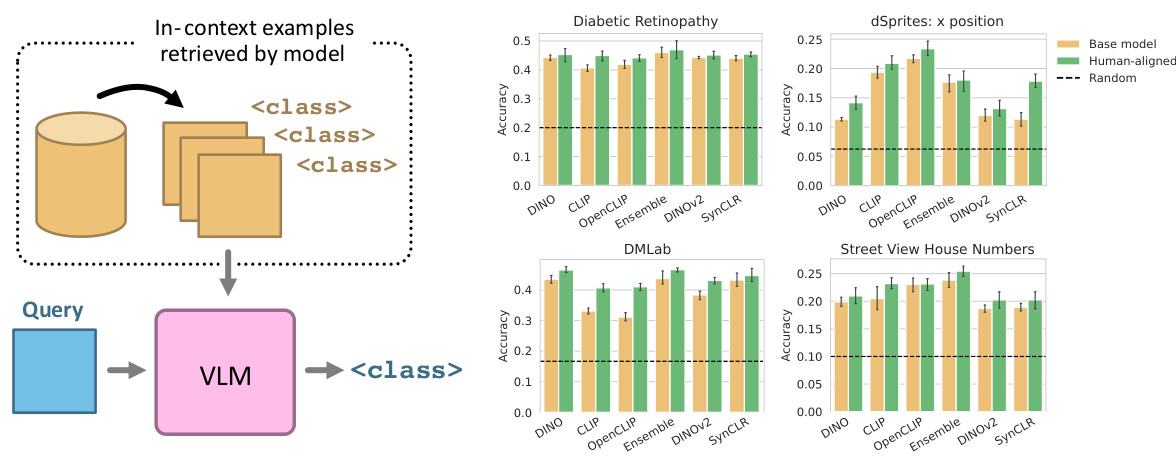
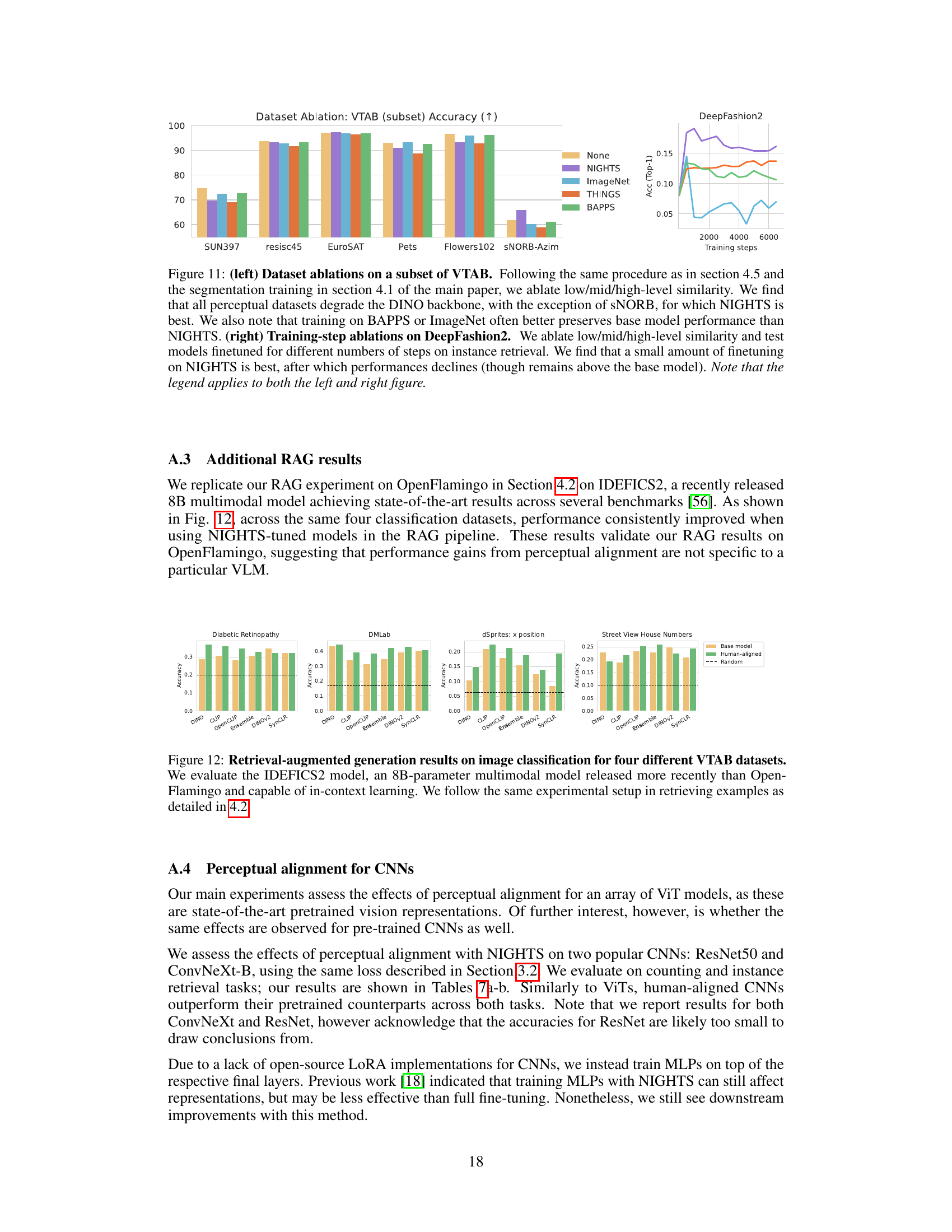
🔼 The figure illustrates the evaluation process of retrieval-augmented generation and shows the results of classification accuracy on various domains of VTAB. The left part describes the process where top 3 nearest image-prompt examples are retrieved and used to prompt OpenFlamingo before inputting the query image to perform classification. The right part presents a bar chart showing the classification accuracy with error bars across different domains.
read the caption
Figure 3: Left: Diagram of evaluation setup for retrieval-augmented generation. We retrieve the top-3 nearest image-prompt examples for each datasets and prompt OpenFlamingo with them before inputting the query image. Right: Classification accuracy on VTAB [35] from wide-varying domains. Error bars indicate 95% confidence interval over 5 random seeds.
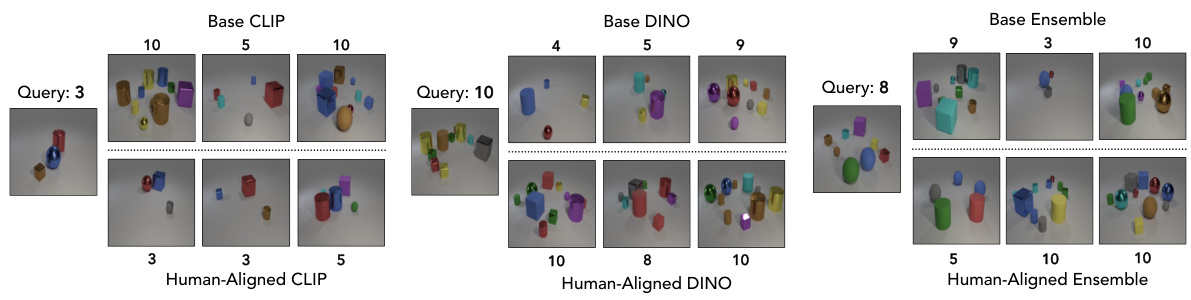
🔼 This figure shows visualizations of nearest neighbor examples retrieved using three different vision models (CLIP, DINO, and Ensemble) and their human-aligned counterparts for object counting tasks. The goal is to demonstrate how aligning the models to human perceptual judgments improves the accuracy of the object count in the retrieved images. Each row represents a query image with a specific number of objects, followed by retrieved images from each model, showing that human-aligned models more often retrieve images with the correct object count.
read the caption
Figure 4: Visualizations of nearest-neighbor examples retrieved by CLIP, DINO, and Ensemble models as well as their human-aligned versions. Overall, we see retrieved images with more accurate object counts in CLIP-HA, DINO-HA, and Ensemble-HA across multiple nearest neighbors.
🔼 This figure visualizes the results of nearest-neighbor image retrieval for different models (CLIP, DINO, Ensemble) and their human-aligned counterparts. The goal is to demonstrate the improvement in object counting accuracy achieved by aligning the models with human perceptual judgments. Each set of images shows the query image and the top three retrieved images, highlighting how the human-aligned models tend to retrieve images with more accurate object counts than the base models.
read the caption
Figure 4: Visualizations of nearest-neighbor examples retrieved by CLIP, DINO, and Ensemble models as well as their human-aligned versions. Overall, we see retrieved images with more accurate object counts in CLIP-HA, DINO-HA, and Ensemble-HA across multiple nearest neighbors.
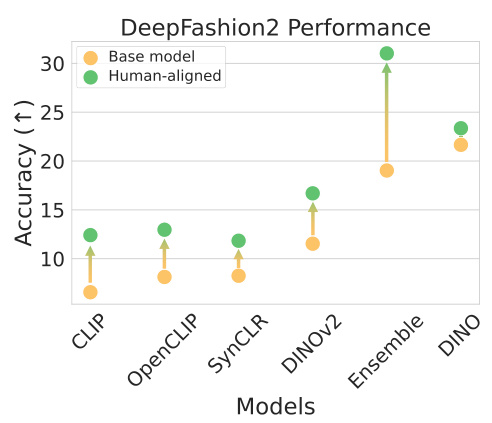
🔼 This figure shows the improvement in accuracy for the instance retrieval task on the DeepFashion2 dataset after aligning the vision models to human perceptual judgments. The accuracy is shown for different vision models (CLIP, OpenCLIP, SynCLR, DINOv2, Ensemble, and DINO) and their corresponding human-aligned versions. The figure clearly demonstrates that human alignment significantly improves the performance across all models.
read the caption
Figure 6: Performance improvements on the DeepFashion2 instance retrieval, task visualized by backbone and averaged across all k for top-k recall. Higher is better.

🔼 This figure shows examples of nearest-neighbor image retrieval results for three different models (CLIP, DINO, and Ensemble) and their human-aligned counterparts. The goal is to assess how well each model can retrieve images with similar object counts to the query image. The visualizations demonstrate that human-aligned models tend to retrieve images with more accurate object counts compared to their base counterparts.
read the caption
Figure 4: Visualizations of nearest-neighbor examples retrieved by CLIP, DINO, and Ensemble models as well as their human-aligned versions. Overall, we see retrieved images with more accurate object counts in CLIP-HA, DINO-HA, and Ensemble-HA across multiple nearest neighbors.

🔼 This figure shows visualizations of nearest neighbor examples retrieved using CLIP, DINO, and Ensemble models, as well as their human-aligned counterparts. The goal is to demonstrate how human perceptual alignment impacts object counting accuracy. By comparing the retrieved images, it’s shown that human-aligned models generally produce retrievals with more accurate object counts.
read the caption
Figure 4: Visualizations of nearest-neighbor examples retrieved by CLIP, DINO, and Ensemble models as well as their human-aligned versions. Overall, we see retrieved images with more accurate object counts in CLIP-HA, DINO-HA, and Ensemble-HA across multiple nearest neighbors.

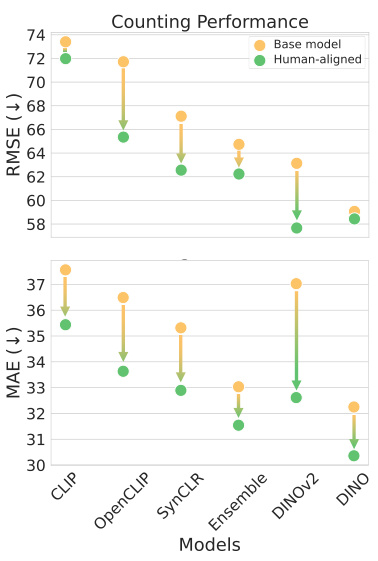
🔼 This figure displays bar charts showing the performance improvements on counting tasks (measured by RMSE) and instance retrieval tasks (measured by recall@k) when the models are fine-tuned using different datasets: NIGHTS, THINGS, BAPPS, ImageNet and a baseline of no fine-tuning. The results indicate that fine-tuning with NIGHTS leads to the highest performance gains, while THINGS negatively impacts performance. Fine-tuning with BAPPS and ImageNet has minimal impact on performance.
read the caption
Figure 8: Evaluations comparing dataset utility on counting tasks (lower RMSE is better) and DeepFashion2 instance retrieval (higher recall is better). Across each task, tuning on NIGHTS yields the largest improvements while THINGS worsens performance and BAPPS/ImageNet makes minimal changes.

🔼 This figure visualizes the results of nearest-neighbor image retrieval for different models (CLIP, DINO, Ensemble) and their human-aligned counterparts (CLIP-HA, DINO-HA, Ensemble-HA). The goal is to demonstrate improved object counting accuracy in the human-aligned models. Each row shows a query image and its top 3 nearest neighbors for each model type, highlighting how the human-aligned models tend to return images with more accurate object counts.
read the caption
Figure 4: Visualizations of nearest-neighbor examples retrieved by CLIP, DINO, and Ensemble models as well as their human-aligned versions. Overall, we see retrieved images with more accurate object counts in CLIP-HA, DINO-HA, and Ensemble-HA across multiple nearest neighbors.
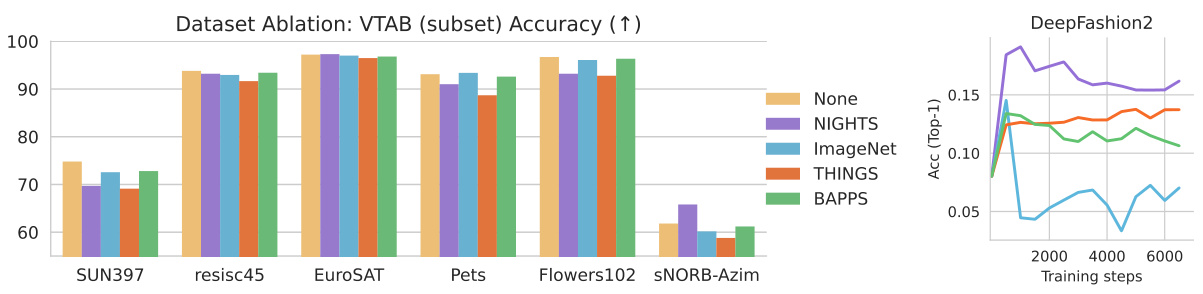
🔼 This figure shows the results of ablating the training dataset used for aligning vision models to human perceptual judgments. The three datasets compared against NIGHTS are BAPPS, THINGS, and ImageNet. The figure demonstrates that training with the NIGHTS dataset leads to the best performance on both object counting and instance retrieval tasks, while training with THINGS leads to worse performance and using BAPPS or ImageNet has minimal effect. This highlights the importance of using the appropriate dataset for aligning vision models to human perceptual judgments.
read the caption
Figure 8: Evaluations comparing dataset utility on counting tasks (lower RMSE is better) and DeepFashion2 instance retrieval (higher recall is better). Across each task, tuning on NIGHTS yields the largest improvements while THINGS worsens performance and BAPPS/ImageNet makes minimal changes.

🔼 The figure shows the evaluation setup for retrieval-augmented generation using OpenFlamingo and the classification accuracy results on various VTAB datasets. The left panel illustrates the process of retrieving the top 3 nearest image-prompt examples for each dataset and using them as context for OpenFlamingo before feeding the query image. The right panel displays the classification accuracy across different datasets, with error bars representing the 95% confidence interval over 5 random seeds. This helps to show the improvement in few-shot generalization abilities of the downstream multimodal VLM when using human-aligned models for retrieving relevant examples.
read the caption
Figure 3: Left: Diagram of evaluation setup for retrieval-augmented generation. We retrieve the top-3 nearest image-prompt examples for each datasets and prompt OpenFlamingo with them before inputting the query image. Right: Classification accuracy on VTAB [35] from wide-varying domains. Error bars indicate 95% confidence interval over 5 random seeds.

🔼 This figure shows examples of top-3 image retrievals for different queries using both base and human-aligned models on the DeepFashion2 dataset. The goal is to retrieve images from a gallery that contain similar clothing items as the query image. The figure visually demonstrates that human-aligned models, which have been fine-tuned using human perceptual similarity judgments, tend to retrieve more accurate and relevant results (matching clothing items) compared to the base models.
read the caption
Figure 7: Examples of top-3 retrievals for a given query image on DeepFashion2. Overall, the human-aligned models return matching clothing items more frequently.

🔼 This figure visualizes the nearest neighbor examples retrieved by three different models (CLIP, DINO, and Ensemble) and their human-aligned counterparts for three different query images, each containing a different number of objects. The goal is to demonstrate the improvement in object counting accuracy achieved by aligning the models to human perceptual judgments. The visualization shows that the human-aligned models tend to retrieve images with object counts closer to the query image’s count.
read the caption
Figure 4: Visualizations of nearest-neighbor examples retrieved by CLIP, DINO, and Ensemble models as well as their human-aligned versions. Overall, we see retrieved images with more accurate object counts in CLIP-HA, DINO-HA, and Ensemble-HA across multiple nearest neighbors.

🔼 This figure shows example triplets from four different datasets used in the paper to investigate the impact of different types of human similarity judgments on model performance. The NIGHTS dataset features triplets with mid-level perceptual similarities, such as variations in object count, pose, layout, and color. The BAPPS dataset contains triplets with low-level variations like color jitter, blur, and JPEG compression artifacts. THINGS triplets differ in high-level semantic concepts, and ImageNet triplets are composed of two images from the same category and one from a different category. The figure illustrates the differences in image variations across these datasets, highlighting the varied levels of perceptual similarity they represent.
read the caption
Figure 15: Examples of triplets from the NIGHTS, BAPPS, THINGS, and ImageNet datasets, with the bordered images labeled as more similar to the reference (middle image in each triplet).
More on tables
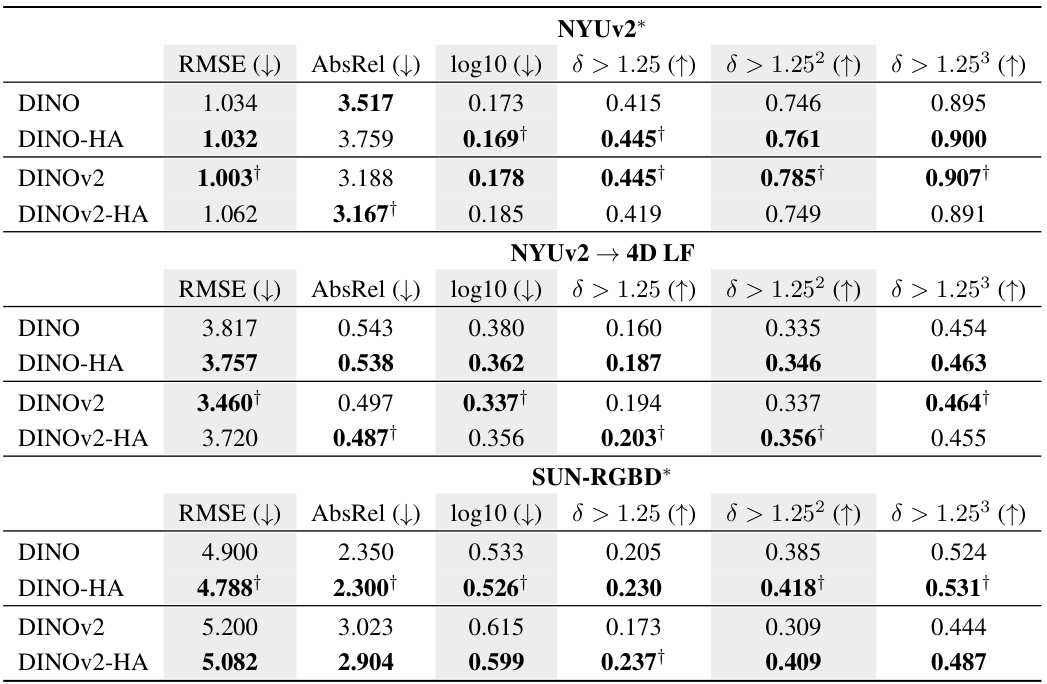
🔼 This table presents the results of the monocular depth estimation experiments. It compares the performance of the original DINO and DINOv2 models against their human-aligned counterparts across three datasets: NYUv2, a transfer experiment from NYUv2 to 4D Light Field, and SUN-RGBD. The metrics used for evaluation are RMSE, AbsRel, log10, δ > 1.25, δ > 1.252, and δ > 1.253. The results highlight the improved performance of human-aligned models, especially on the SUN-RGBD dataset, which was included in the DINOv2 pretraining data. The table also shows strong generalization capabilities, evidenced by the improvement even on unseen data.
read the caption
Table 2: Human-aligned DINO and DINOv2 performance on monocular depth estimation benchmarks. Note that NYUv2 and SUN-RGBD were included in DINOv2's retrieval pretraining set, yet human-aligned DINOV2 still outperforms the base model on SUN-RGBD. Along with the results on an unseen test data domain (train on NYUv2 → test on 4D Light Field), these results demonstrate strong generalization performance of models aligned to human perceptual judgments. † indicates best score in the column.
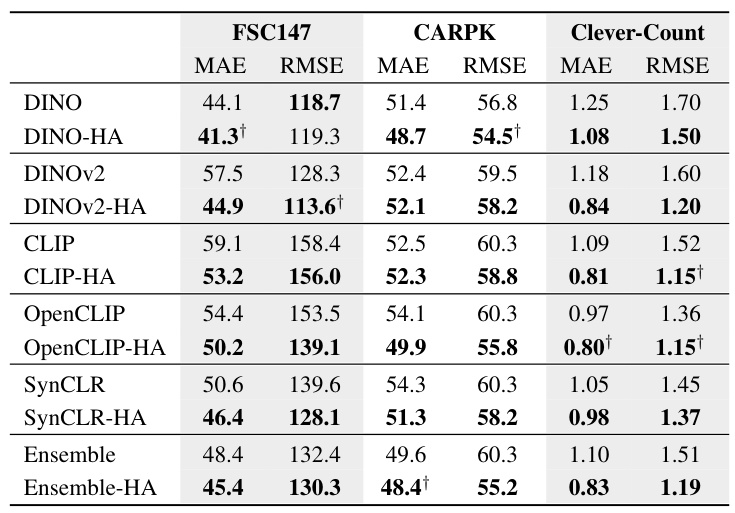
🔼 This table presents a comparison of the performance of base and human-aligned vision models on three object counting benchmarks: FSC147, CARPK, and Clevr-Count. The results show the mean absolute error (MAE) and root mean squared error (RMSE) for each model. Despite the fact that the FSC147 and CARPK datasets contain object counts far exceeding those in the training data, human-aligned models consistently outperform their base counterparts.
read the caption
Table 3: Error comparisons for base and human-aligned models on standard counting benchmarks. Though FSC147 and CARPK have examples with extreme object counts (tens and hundreds) unseen in the NIGHTS data, human-aligned models still achieve higher performance in each pair. † indicates best score in the column, lower is better.

🔼 This table presents the performance of various vision models (both base and human-aligned versions) on the DeepFashion2 instance retrieval benchmark. The benchmark involves retrieving images containing similar clothing items from a gallery of images given a query image. The table shows the top-1, top-3, and top-5 recall scores, indicating the percentage of queries where the correct matching image was found within the top 1, 3, or 5 retrieved images, respectively. Higher recall scores denote better performance.
read the caption
Table 4: Top-1, -3, and -5 recall scores for instance retrieval on DeepFashion2. † indicates best score in the column, higher is better.

🔼 This table presents the results of semantic segmentation experiments comparing the performance of base and human-aligned vision models (DINO and DINOv2) across five datasets. It shows that aligning models to human perceptual judgments improves performance on most datasets, particularly DINO-HA, with some exceptions possibly due to datasets already present in the training of the DINOv2 model.
read the caption
Table 1: Base and human-aligned model performance on semantic segmentation. Aligned models largely outperform baselines, with DINO-HA achieving the highest performance across models for 4 out of 5 datasets. Note that Pascal VOC, ADE20k, and Cityscapes were included in DINOv2's retrieval pretraining. † indicates best score in the column.

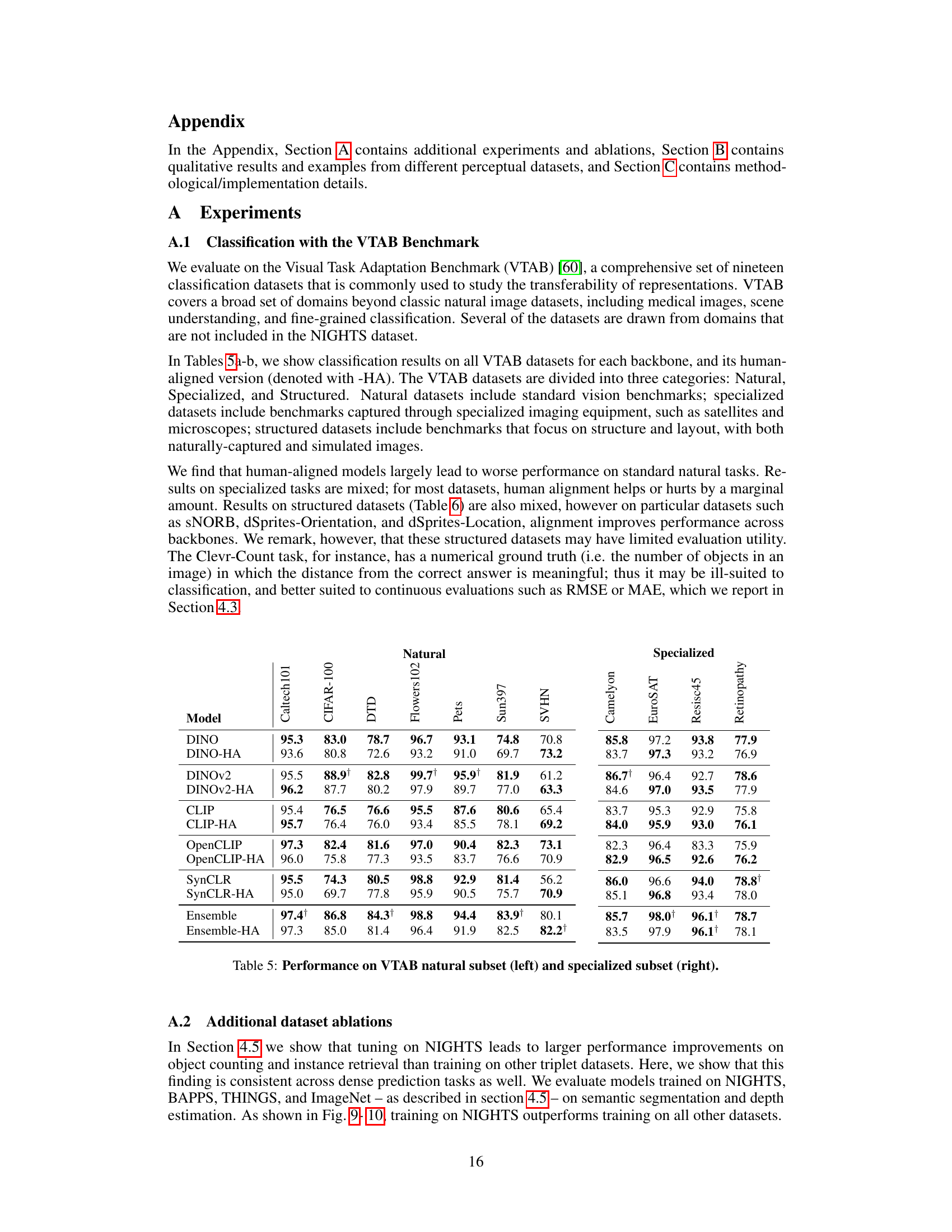
🔼 This table presents the performance of various vision models (both base and human-aligned versions) on a subset of the VTAB benchmark focusing on structured datasets. The results show the accuracy of each model on several tasks that evaluate different aspects of visual understanding, such as object counting, distance estimation, and scene layout analysis. The table helps in evaluating the impact of aligning vision models to human perceptual judgments on these specific structured tasks.
read the caption
Table 6: Performance on VTAB structured subset.

🔼 This table presents the results of monocular depth estimation experiments using DINO and DINOv2 models, both with and without human perceptual alignment. The results are shown for different metrics (RMSE, AbsRel, log10, δ > 1.25, δ > 1.252, δ > 1.253) and datasets (NYUv2, NYUv2 → 4D LF, SUN-RGBD). The ‘+’ symbol indicates that the aligned model outperforms the baseline. The key finding is that human-aligned models not only perform better on in-distribution datasets but also generalize well to out-of-distribution datasets. The table highlights that alignment with human perception improves the model’s depth estimation ability and its generalization capabilities.
read the caption
Table 2: Human-aligned DINO and DINOv2 performance on monocular depth estimation benchmarks. Note that NYUv2 and SUN-RGBD were included in DINOv2's retrieval pretraining set, yet human-aligned DINOV2 still outperforms the base model on SUN-RGBD. Along with the results on an unseen test data domain (train on NYUv2 → test on 4D Light Field), these results demonstrate strong generalization performance of models aligned to human perceptual judgments. † indicates best score in the column.

🔼 This table presents the results of semantic segmentation experiments. It compares the performance of baseline models (DINO and DINOv2) against their human-aligned counterparts (DINO-HA and DINOv2-HA) across five datasets: Pascal VOC, ADE20k, Cityscapes, COCO, and DAVIS2017. The table shows that human alignment generally improves performance, especially for DINO-HA, with improvements in mIoU (mean Intersection over Union) and PA (Pixel Accuracy). It notes that three of the datasets were already used in the pretraining of the DINOv2 model, which might affect the results.
read the caption
Table 1: Base and human-aligned model performance on semantic segmentation. Aligned models largely outperform baselines, with DINO-HA achieving the highest performance across models for 4 out of 5 datasets. Note that Pascal VOC, ADE20k, and Cityscapes were included in DINOv2's retrieval pretraining. † indicates best score in the column.

🔼 This table presents the results of semantic segmentation experiments using both base and human-aligned vision models. It compares the performance (mIoU and Pixel Accuracy) of different models on five standard datasets (Pascal VOC, ADE20K, Cityscapes, COCO, and DAVIS2017). The results demonstrate that aligning vision models with human perceptual judgments generally improves performance on semantic segmentation tasks, particularly for the DINO-HA model. The table notes that three of the datasets were used in the pretraining of one of the base models (DINOv2), which could be a confounding factor.
read the caption
Table 1: Base and human-aligned model performance on semantic segmentation. Aligned models largely outperform baselines, with DINO-HA achieving the highest performance across models for 4 out of 5 datasets. Note that Pascal VOC, ADE20k, and Cityscapes were included in DINOv2's retrieval pretraining. † indicates best score in the column.
Full paper#