↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are often improved using in-context learning (ICL) or supervised fine-tuning (SFT), but it’s unclear if they create similar internal representations. Prior research mainly compared performance; this study delves into the internal representation differences. This paper investigates this through analyzing probability landscapes of hidden representations in LLMs performing question-answering tasks. It finds that ICL and SFT lead to drastically different internal structures within the LLMs.
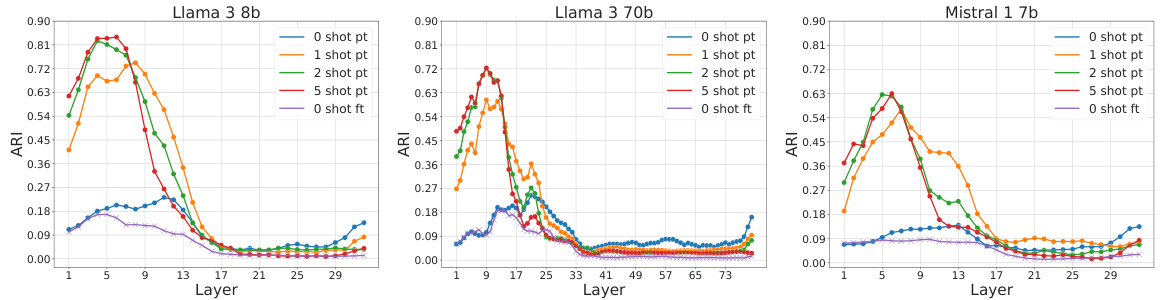
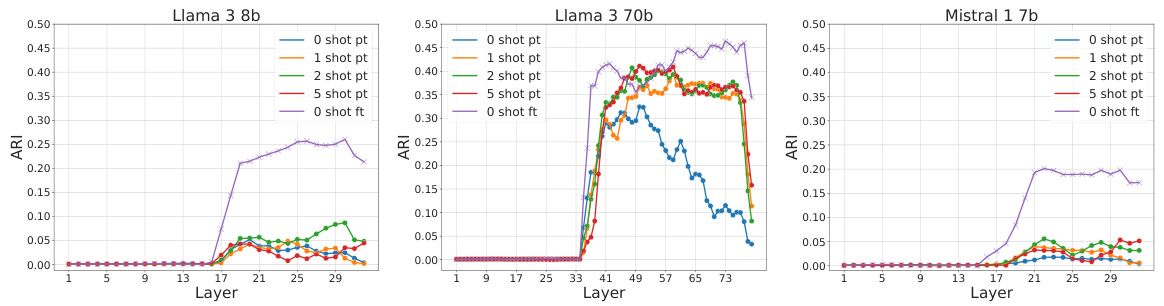
The research used a density-based approach to analyze the probability landscape of hidden representations in LLMs solving a question-answering task. They found a clear division within network layers between those encoding semantic content and those related to final answers. ICL produced hierarchically organized representations in the first half, while SFT showed fuzzier, semantically mixed representations. Fine-tuned models displayed clearer answer encoding in the second half, unlike ICL models. This research reveals that different computational strategies are employed by LLMs for ICL and SFT.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals the distinct computational strategies employed by LLMs in few-shot learning and fine-tuning, despite achieving similar performance. This understanding can inform the design of optimal methods for information extraction and improve LLM performance by allowing researchers to focus on specific layers and strategies for more efficient information processing and task adaptation. It also opens new avenues of research in the geometry of LLM representations and adaptive low-rank fine-tuning techniques.
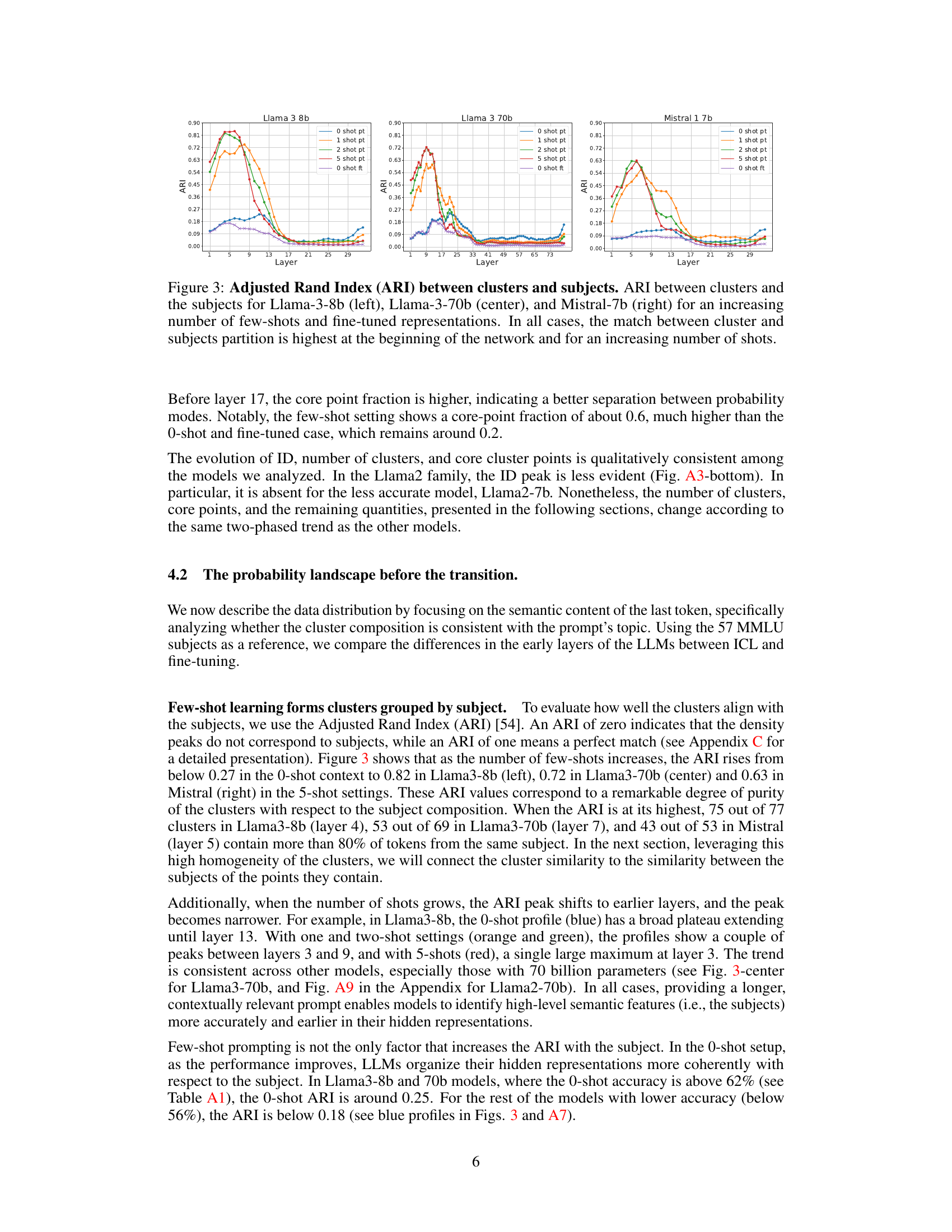
Visual Insights#

This figure shows how the internal representations of large language models (LLMs) differ when using few-shot learning and fine-tuning. The top row displays representations from layers closer to the input, while the bottom shows those closer to the output. Three scenarios are compared: zero-shot, few-shot (in-context learning), and fine-tuned. Few-shot learning creates more interpretable representations based on semantic content in the early layers, while fine-tuning better encodes the answers in later layers.
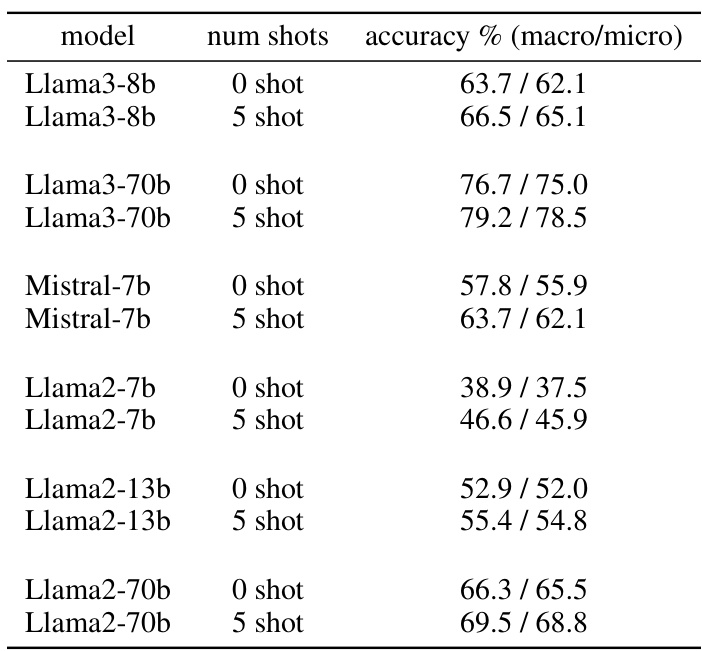
This table presents the zero-shot and five-shot accuracies for different large language models on the Massive Multitask Language Understanding (MMLU) test set. The accuracies are given as both macro and micro averages. Macro average is the arithmetic mean of the accuracies per subject, while the micro average is the total number of correct answers divided by the total number of questions. The difference between these reflects the class imbalance in the dataset.
In-depth insights#
LLM Representation#
LLM internal representations are a crucial, yet poorly understood aspect of large language model (LLM) function. This research paper investigates how different training paradigms, specifically in-context learning (ICL) and supervised fine-tuning (SFT), shape these internal representations. The study uses a density-based approach to analyze the probability landscape of hidden layer activations, revealing a two-phased behavior across the network. Early layers in ICL develop semantically organized representations while SFT results in fuzzier, less interpretable structures in these early layers. Conversely, fine-tuning leads to the emergence of sharply defined probability modes in later layers, better reflecting the identity of the answers compared to ICL. This reveals distinct computational strategies used by LLMs, underscoring the need for a deeper understanding of these internal mechanisms to optimize LLM performance and information extraction.
ICL vs. SFT#
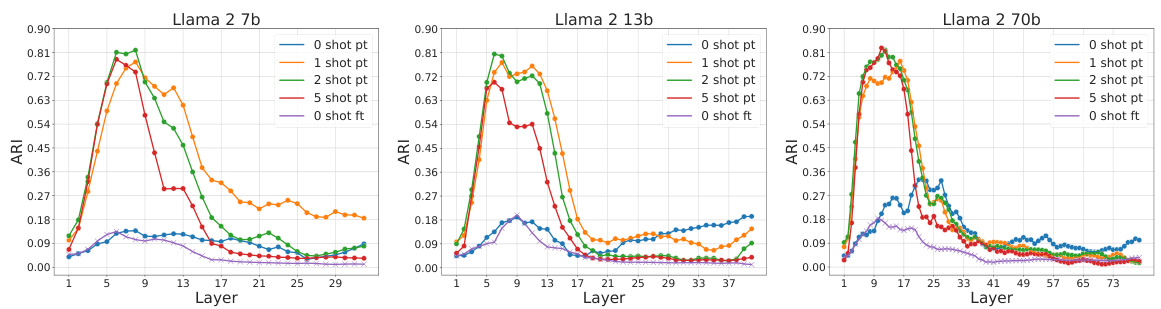
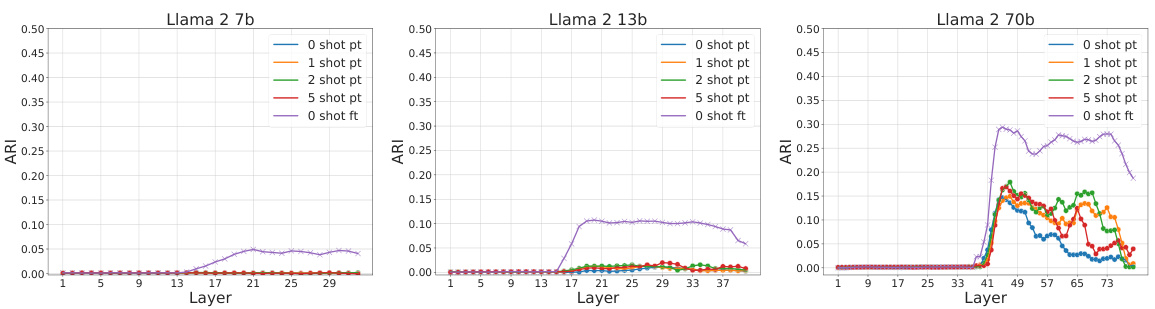
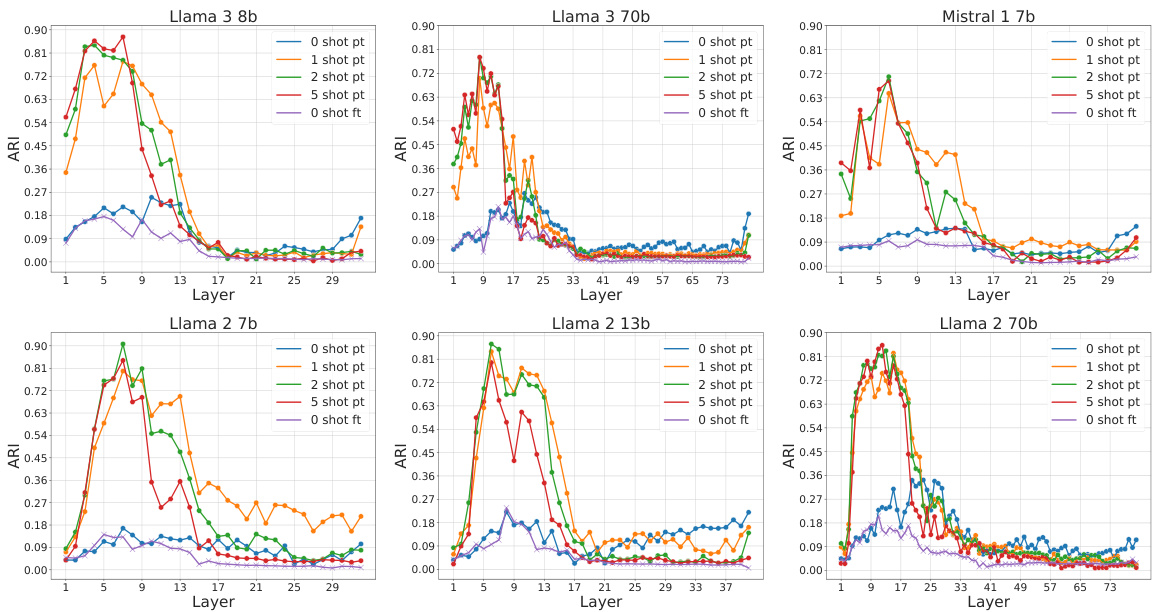
The core of the study lies in contrasting In-context Learning (ICL) and Supervised Fine-tuning (SFT), two prominent large language model (LLM) training methodologies. While both boost LLM performance on specific tasks, their impact on internal representations differs significantly. ICL, which involves providing a few examples within the prompt, shapes representations hierarchically and semantically in the initial network layers. In contrast, SFT, which modifies model parameters using labeled examples, leads to fuzzier, semantically mixed representations in these early layers. A key observation is the sharp transition in representation patterns midway through the network, with fine-tuned models showing clearer separation of answer identities in later layers compared to ICL. This suggests that while achieving similar accuracy, ICL and SFT employ fundamentally distinct computational strategies. The geometry of the LLMs’ internal representations reveals a two-phased approach to problem-solving. Understanding this contrast could lead to more efficient methods for information extraction and better LLM design.
Density Peaks#
The concept of Density Peaks in the context of analyzing LLMs’ internal representations offers a unique perspective on understanding how these models solve tasks. Instead of relying on dimensionality reduction techniques, this approach directly analyzes the probability density of hidden layer embeddings. This allows the identification of probability modes or “peaks” which, in the case of few-shot learning, seem to cluster semantically, reflecting the hierarchical organization of information. In contrast, fine-tuning leads to fuzzier, less interpretable probability landscapes. The transition between these distinct representation styles is especially noteworthy, occurring mid-network. This transition might correspond to a shift from semantically rich representations to those focused on answer identity. This method provides a novel way to understand LLMs’ diverse computational strategies, revealing how different learning paradigms impact internal model structures, going beyond simple performance comparisons.
Two-Phased Geom#
The concept of “Two-Phased Geom” suggests a significant shift in the geometric properties of internal representations within a neural network model, likely a Large Language Model (LLM). This transition is not gradual but rather abrupt, occurring around the midpoint of the network’s layers. The first phase might be characterized by a focus on semantic organization, with hidden representations clustering according to the semantic content of the input. The second phase, however, prioritizes task-specific output, potentially reflecting a shift towards encoding aspects crucial for generating the final answer. This two-phased nature highlights diverse computational strategies within the LLM, suggesting different processing priorities depending on the network’s depth. Investigating this phenomenon provides insights into the internal mechanisms of LLMs and could inform the development of more effective methods for information extraction or model optimization. The analysis of this transition, particularly its sharpness and location, could reveal fundamental aspects of LLM architecture and information processing.
Future Research#
Future research directions stemming from this paper could explore several avenues. Extending the density-based approach to other LLMs and tasks is crucial for validating the generalizability of the findings. Investigating the influence of different prompting techniques and dataset characteristics on the representation landscape would provide valuable insights. A deeper investigation into the computational mechanisms underlying the two-phased behavior and the transition point between layers is also needed. Furthermore, research should focus on leveraging the distinct geometrical properties of ICL and SFT representations to develop improved methods for knowledge extraction and efficient fine-tuning. This could involve creating new algorithms that specifically target the geometrical structures identified in this study, resulting in improved performance and efficiency for various downstream tasks. Finally, exploring the practical implications of these findings for developing adaptive low-rank fine-tuning techniques could yield significant advancements in the field of efficient language model adaptation.
More visual insights#
More on figures

This figure shows how the internal representations of LLMs differ when using few-shot learning versus fine-tuning for a question answering task. The top row displays representations from layers closer to the input, while the bottom shows layers closer to the output. Three scenarios are compared: zero-shot, few-shot (in-context learning), and fine-tuned. The visualization reveals that few-shot learning leads to a more structured organization of representations, particularly in early layers. Fine-tuning, on the other hand, seems to create more distinct, well-defined clusters representing answer identities primarily in later layers.

This figure shows the probability density landscape of hidden representations in LLMs for three scenarios: zero-shot, few-shot learning, and fine-tuning. The top row displays the representations from layers closer to the input, and the bottom row displays those from layers closer to the output. The visualization shows that few-shot learning develops better representations of the data’s semantic content in the early layers while fine-tuning produces representations that better encode the identity of the answers in the later layers.
This figure displays the probability landscape of a large language model’s hidden representations when solving a question answering task using three different methods: zero-shot, few-shot learning, and fine-tuning. The top row shows the representations in layers near the input, while the bottom row shows those near the output. The visualization highlights how different learning paradigms structure the internal representations of the model. Few-shot learning creates more interpretable, semantically organized representations in early layers, while fine-tuning develops probability modes better encoding the identity of answers in later layers.

This figure shows how in-context learning (ICL) and supervised fine-tuning (SFT) affect the internal representations of LLMs. It compares the probability density landscapes of hidden representations in LLMs solving a question-answering task under three conditions: zero-shot, few-shot, and fine-tuned. The results highlight a key difference in how the two learning methods structure the model’s internal representations. ICL creates more interpretable, semantically-organized representations in early layers, while SFT better encodes answer identity in later layers. A sharp transition is observed in the middle of the network for both methods.
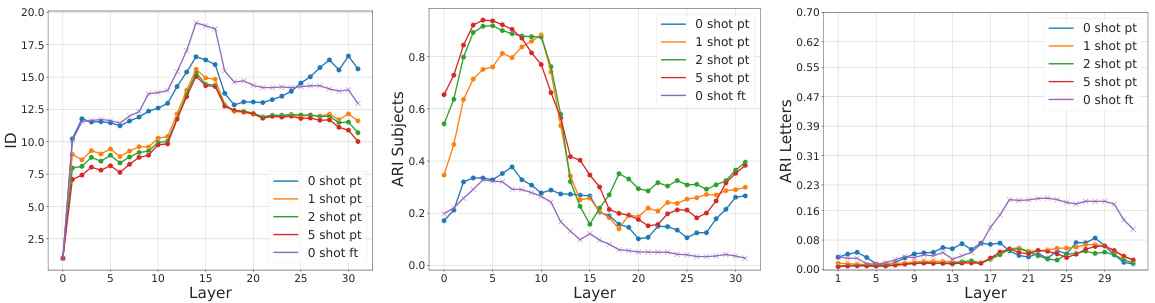
This figure shows the probability landscape of hidden representations in LLMs for three scenarios: zero-shot, in-context learning (5-shot), and fine-tuning. It compares how LLMs solve a question answering task. The top row displays the representations from the layers close to the input, and the bottom row displays representations from layers near the output. In the 5-shot scenario, early layers show better representation of the dataset’s subjects while the fine-tuned model’s late layers show better encoding of the answers.

This figure shows the probability landscape of hidden representations in LLMs for few-shot learning and fine-tuning on a question answering task. It compares zero-shot, few-shot, and fine-tuned approaches, visualizing the probability mode distributions in early and late layers of the network. The results reveal that these two learning paradigms generate distinct internal structures; few-shot learning creates more interpretable representations in the early layers, hierarchically organized by semantic content, while fine-tuning generates fuzzier representations until late layers, where distinct probability modes better encode answer identities.
This figure visualizes how different learning paradigms (zero-shot, few-shot, and fine-tuned) shape the probability distributions within a large language model’s hidden layers when performing a question-answering task. It shows that early layers develop semantically organized representations for few-shot learning, while fine-tuning leads to representations better encoding the final answers in later layers.

This figure shows how in-context learning (ICL) and supervised fine-tuning (SFT) affect the representation landscape of LLMs. It compares the probability distributions of hidden representations in LLMs solving a question answering task under three conditions: zero-shot, 5-shot (ICL), and fine-tuned (SFT). The top row shows early layers, revealing that ICL forms semantically organized representations, while SFT representations are fuzzier. The bottom row displays late layers, showing fine-tuned representations encoding answer identity better than ICL representations.
This figure visualizes how the probability distributions of hidden layer representations in LLMs change depending on the learning paradigm used (zero-shot, few-shot, and fine-tuned). It highlights the different ways LLMs process information across different layers and learning methods, showing a transition point in the middle of the network. Early layers show better subject representation with few-shot learning, while late layers of fine-tuned models represent the answers more precisely. This demonstrates the distinct computational strategies employed by LLMs under varying conditions.

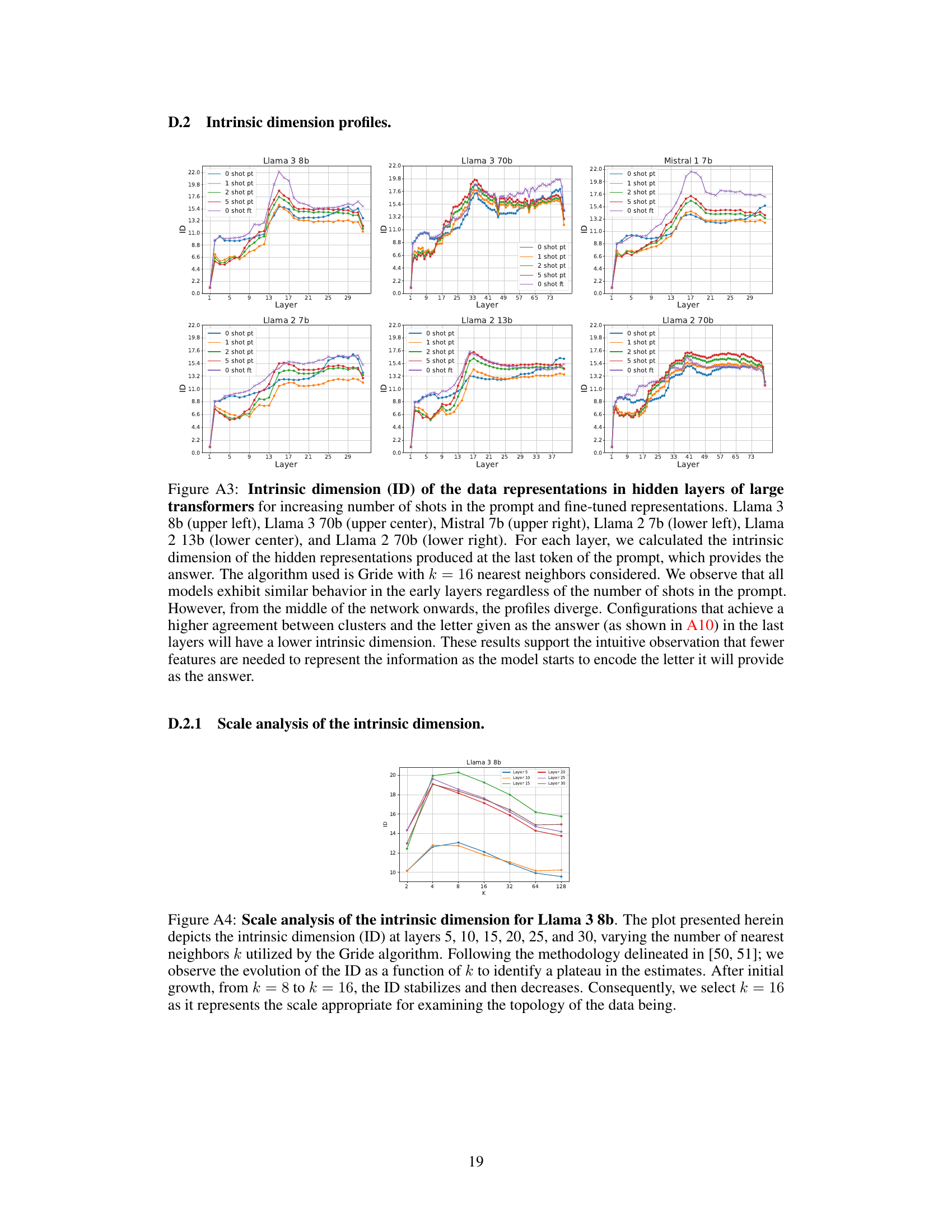
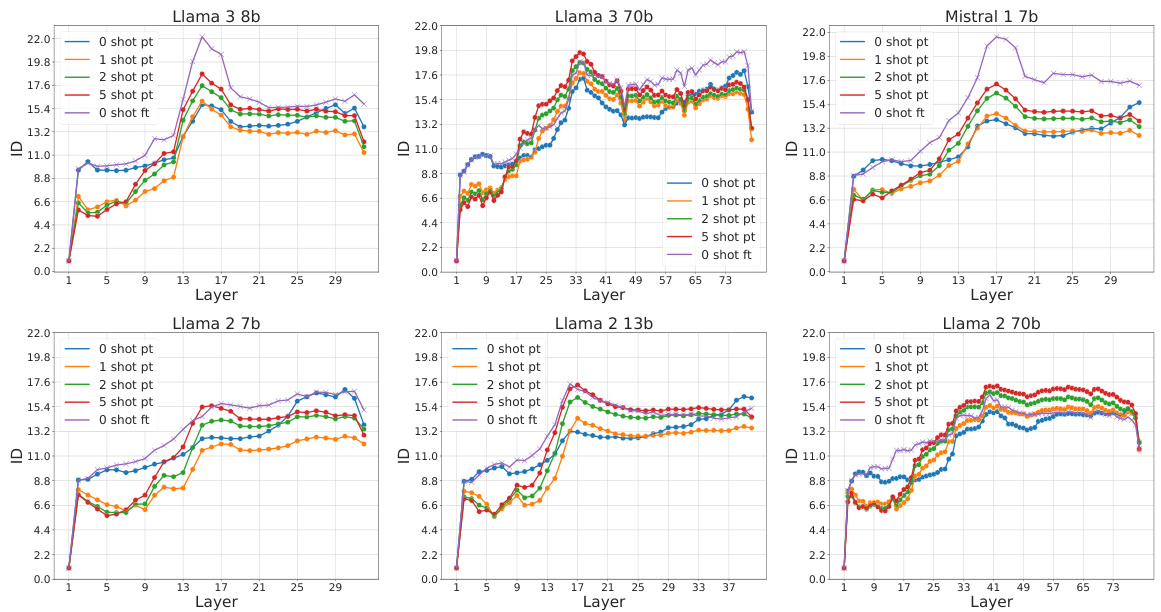
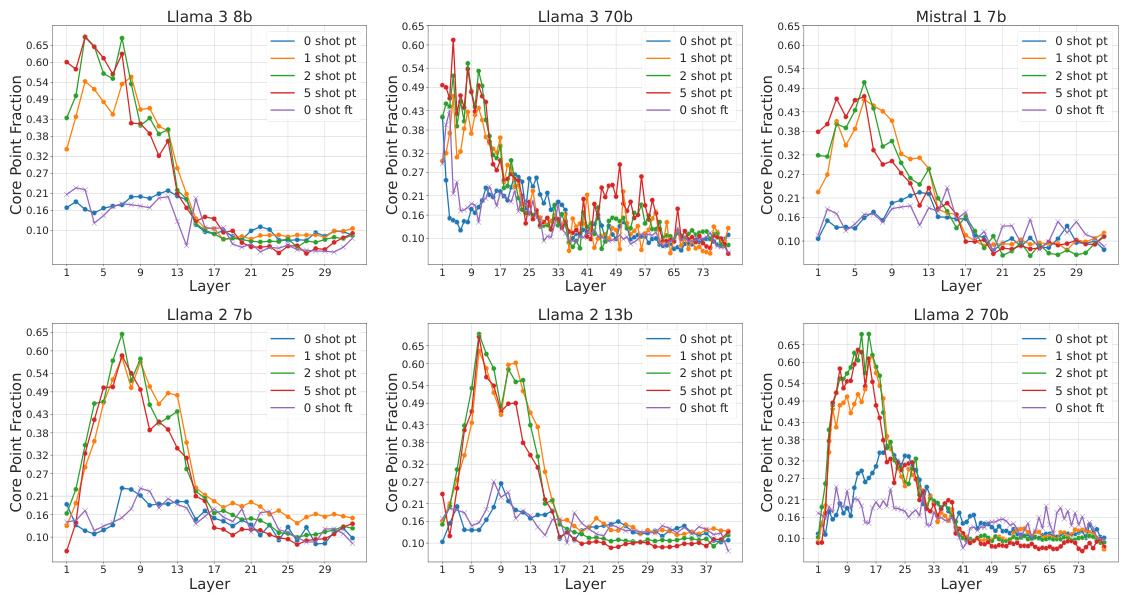
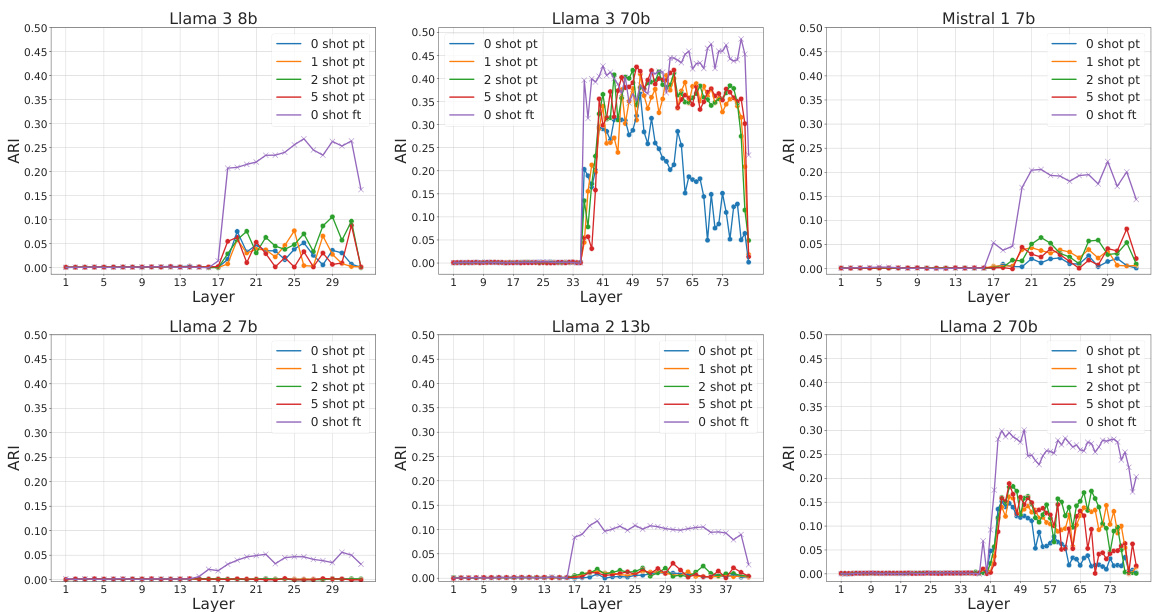
This figure displays the intrinsic dimension, number of density peaks, and fraction of core points across different layers of the Llama3-8b language model for various conditions (zero-shot, few-shot with increasing numbers of examples, and fine-tuned). It highlights a two-phased behavior around layer 17, showing abrupt changes in these geometric properties of the model’s representation. This transition suggests a shift in how the model processes information.

This figure shows how the internal representations of large language models (LLMs) differ when solving a question-answering task using two different approaches: few-shot learning and fine-tuning. The top row displays representations from layers closer to the input, while the bottom shows layers near the output. The three columns represent zero-shot, few-shot learning (with 5 examples), and fine-tuning. The visualization shows that few-shot learning develops better subject representations in early layers, while fine-tuning better encodes answer identities in later layers. This highlights the diverse computational strategies LLMs employ for the same task.
This figure shows how the probability landscape of hidden representations in LLMs changes depending on the learning paradigm used (zero-shot, few-shot, fine-tuned). The top row displays the representations closer to the input layer, while the bottom row illustrates the representations closer to the output layer. It highlights differences in how these paradigms structure internal representations, particularly a transition that occurs in the middle of the network. Few-shot learning creates more interpretable representations in early layers, while fine-tuning better encodes the answers in the later layers.
This figure shows the probability landscape of hidden representations in LLMs for few-shot learning and fine-tuning. It compares how LLMs solve a question-answering task under three conditions: zero-shot, few-shot in-context learning, and fine-tuning. The top row displays representations from layers closer to the input, while the bottom row shows those closer to the output. The figure highlights that ICL and SFT induce different internal structures within the LLMs, with ICL showing hierarchical organization by semantic content in early layers and SFT showing fuzzier, semantically mixed representations before developing clearer answer identity encoding in later layers.
This figure shows how the representation landscape of LLMs changes when solving a question answering task using different methods: zero-shot, few-shot learning, and fine-tuning. It visualizes the probability modes in the hidden layers of the model, showing distinct patterns for each learning paradigm in the early and late layers of the network. Few-shot learning creates more interpretable representations in early layers that are semantically organized, whereas fine-tuning results in a fuzzier representation that is more semantically mixed in the early layers, with later layers showing clear distinctions in probability modes that better encode the identity of the answers.
This figure shows the representation landscape of LLMs in three scenarios: zero-shot, few-shot, and fine-tuned. The top row shows the representations from layers near the input, and the bottom row shows those near the output. The figure illustrates how different learning paradigms (zero-shot, few-shot, fine-tuned) shape the probability landscape of hidden representations within LLMs during a question-answering task. It highlights distinct patterns in early versus late layers and differences between the internal structures created by in-context learning and fine-tuning.
This figure shows how the probability landscape of hidden representations in LLMs changes when solving a question answering task using three different learning methods: zero-shot, few-shot, and fine-tuning. The top row displays representations from layers closer to the input, while the bottom row shows representations from layers closer to the output. The visualization reveals that each method leads to different internal structures in the network.

This figure shows how the internal representations of LLMs differ when using few-shot learning and fine-tuning for question answering. It visualizes the probability distributions in the hidden layers of the model. The top row shows early layers, closer to the input, while the bottom row shows later layers closer to the output. Three scenarios are compared: zero-shot, few-shot (5 examples), and fine-tuned. The results highlight that the early layers of few-shot learning focus on representing the semantic content of the questions (subjects), while the later layers of the fine-tuned model focus on the answers themselves.

This figure shows how the internal representations of LLMs differ when using few-shot learning and fine-tuning for a question answering task. It visualizes probability density distributions in the early and late layers of the model for three scenarios: zero-shot, 5-shot (few-shot learning), and fine-tuned. Few-shot learning shows clear semantic organization in the early layers, while fine-tuning shows better encoding of the answers in the later layers.

This figure shows the probability density landscape of hidden representations in LLMs for three different learning paradigms: zero-shot, few-shot, and fine-tuned. It compares how the models solve a question-answering task, highlighting differences in representation structure across the network layers (early vs. late). Few-shot learning creates more interpretable representations in the early layers, while fine-tuning leads to a more refined encoding of answers in the late layers. The visualization demonstrates how different learning methods impact the internal representations within LLMs.

This figure shows how the probability landscape of hidden representations in LLMs changes depending on the learning paradigm used (zero-shot, few-shot, fine-tuned) when solving a multiple-choice question-answering task. The top row displays representations from the early layers (near input), and the bottom row from later layers (near output). The results indicate that the learning paradigms create very different internal structures within the LLMs, particularly showing a sharp transition in the middle of the network.

This figure shows how the internal representations of LLMs differ when using few-shot learning versus fine-tuning for a question answering task. It visualizes the probability density of hidden layer representations in the model, showing a clear distinction between the two approaches in the early layers (semantic representation) and the later layers (answer encoding). Few-shot learning creates more interpretable, semantically organized representations in early layers, whereas fine-tuning produces fuzzier representations until the later layers. The difference in representation structure is highlighted by comparing the probability density peaks in the different model scenarios.

This figure compares the representation landscape of LLMs trained with three different methods: zero-shot, few-shot, and fine-tuned. It visualizes the probability modes in the hidden layers of the network using density plots, showing how these modes evolve from the input to the output layers. The differences in the probability landscapes highlight the different internal strategies LLMs employ to solve the same question-answering task with different training paradigms.
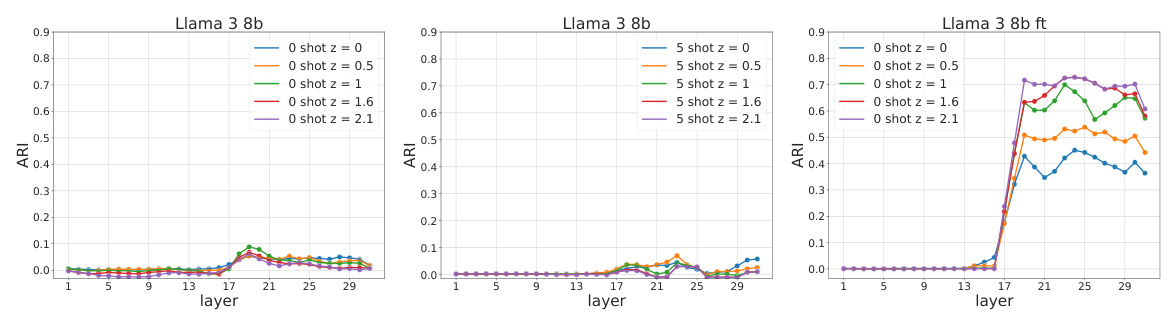
This figure shows the probability landscape of hidden representations in LLMs for three different learning paradigms: zero-shot, few-shot, and fine-tuned. It visualizes how the probability density changes across layers, comparing the distributions of subject and answer representations. It highlights a transition point in the middle layers where the representation structure shifts.
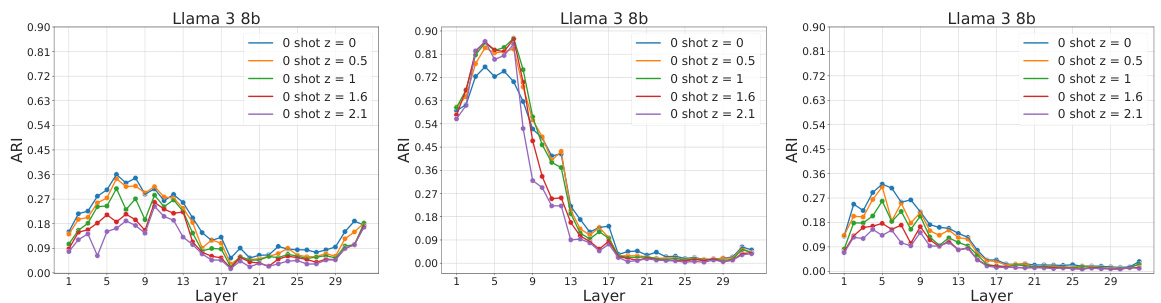
This figure shows the representation landscape of LLMs in few-shot learning and fine-tuning. It compares zero-shot, 5-shot in-context learning, and fine-tuned models on a question-answering task. The top row displays the representations from layers closer to the input, and the bottom row displays the representations from layers closer to the output. The visualizations highlight how different learning paradigms structure internal representations. In 5-shot learning, early layers represent subjects better, while fine-tuned models better encode answers in later layers.

This figure shows how the internal representations of LLMs differ when using few-shot learning vs. fine-tuning for a question-answering task. The top row displays the representations closer to the input layer, and the bottom row shows representations closer to the output layer. It compares zero-shot, few-shot (5-shot), and fine-tuned models. Few-shot learning develops semantically organized representations, while fine-tuning produces fuzzier and more semantically mixed representations in the early layers. In the later layers, fine-tuned representations better encode the answers, while few-shot learning has less defined probability modes.

This figure shows the visualization of probability modes in LLMs for three different learning scenarios: zero-shot, few-shot, and fine-tuned. It compares how the internal representations of LLMs differ when solving a question-answering task using these three methods, showing distinct patterns in the probability landscape at different network layers.
This figure shows the visualization of probability modes in LLMs for three scenarios: zero-shot, few-shot learning, and fine-tuning. The top row displays the representations from the beginning layers (near input), while the bottom displays the end layers (near output). It shows how different learning paradigms organize internal representations, with few-shot showing interpretable, semantically organized clusters early on, and fine-tuning developing answer-specific clusters in later layers.

This figure compares the representation landscape of three different learning scenarios (zero-shot, few-shot, and fine-tuned) in large language models while solving the same question-answering task. It shows the probability distributions in early and late layers of the model, revealing how the different learning strategies shape the internal representations in the model.
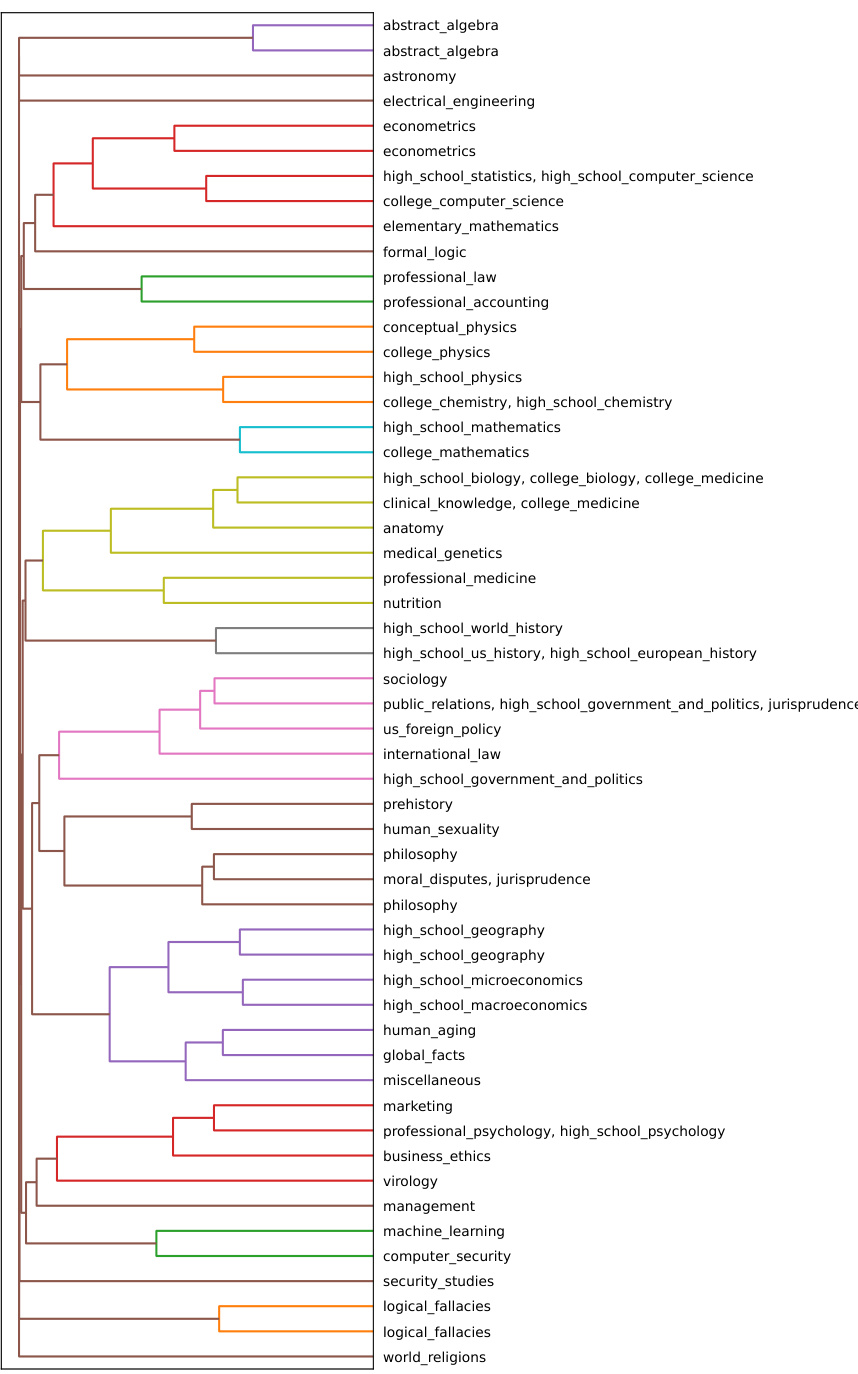
This figure shows how in-context learning and fine-tuning affect the representation space of LLMs, comparing their probability landscape at different layers (near input vs. near output) for a question-answering task. It reveals distinct internal structures for each learning paradigm, with ICL forming hierarchically organized representations based on semantic content in the early layers and SFT generating fuzzier, semantically mixed representations. In later layers, fine-tuning shows clearer probability modes that better encode the answers, while ICL representations are less defined.

This figure shows how the representation landscape of LLMs differs between few-shot learning and fine-tuning for a question answering task. The top row displays the representations from layers closer to the input, while the bottom row shows those closer to the output. Three scenarios are compared: zero-shot, few-shot (in-context learning), and fine-tuned. The results demonstrate that these two learning paradigms create significantly different internal structures within the model. Few-shot learning leads to semantically organized representations in the first half of the network while fine-tuning generates fuzzier, semantically mixed representations. In contrast, the second half of the model shows fine-tuning developing clear probability modes associated with answers while few-shot learning displays less defined peaks.

This figure shows how the internal representations of large language models differ when using few-shot learning vs. fine-tuning. The top row shows early layers of the network, while the bottom shows later layers. Three conditions are compared: zero-shot, 5-shot (few-shot learning), and fine-tuned. Few-shot learning develops better representations of the subjects in the early layers, while fine-tuning better encodes the answers in the later layers.
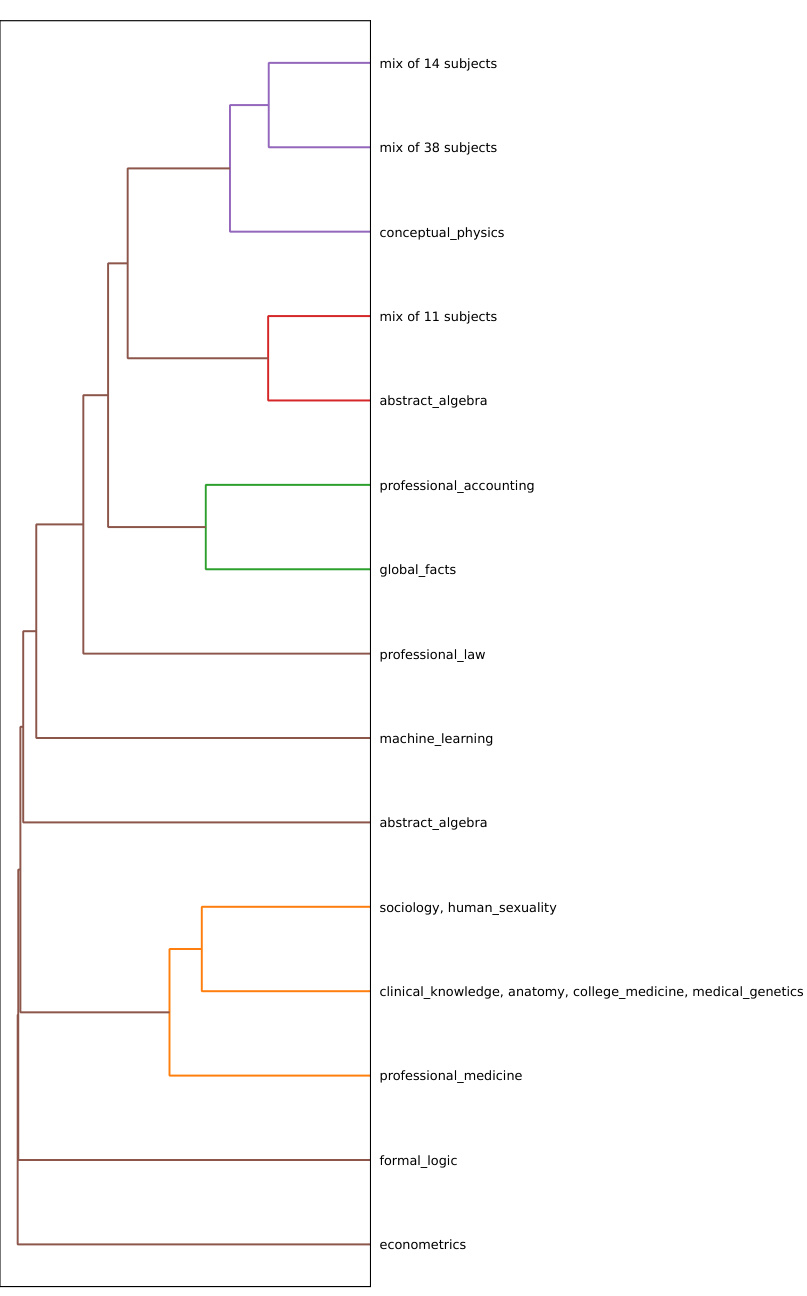
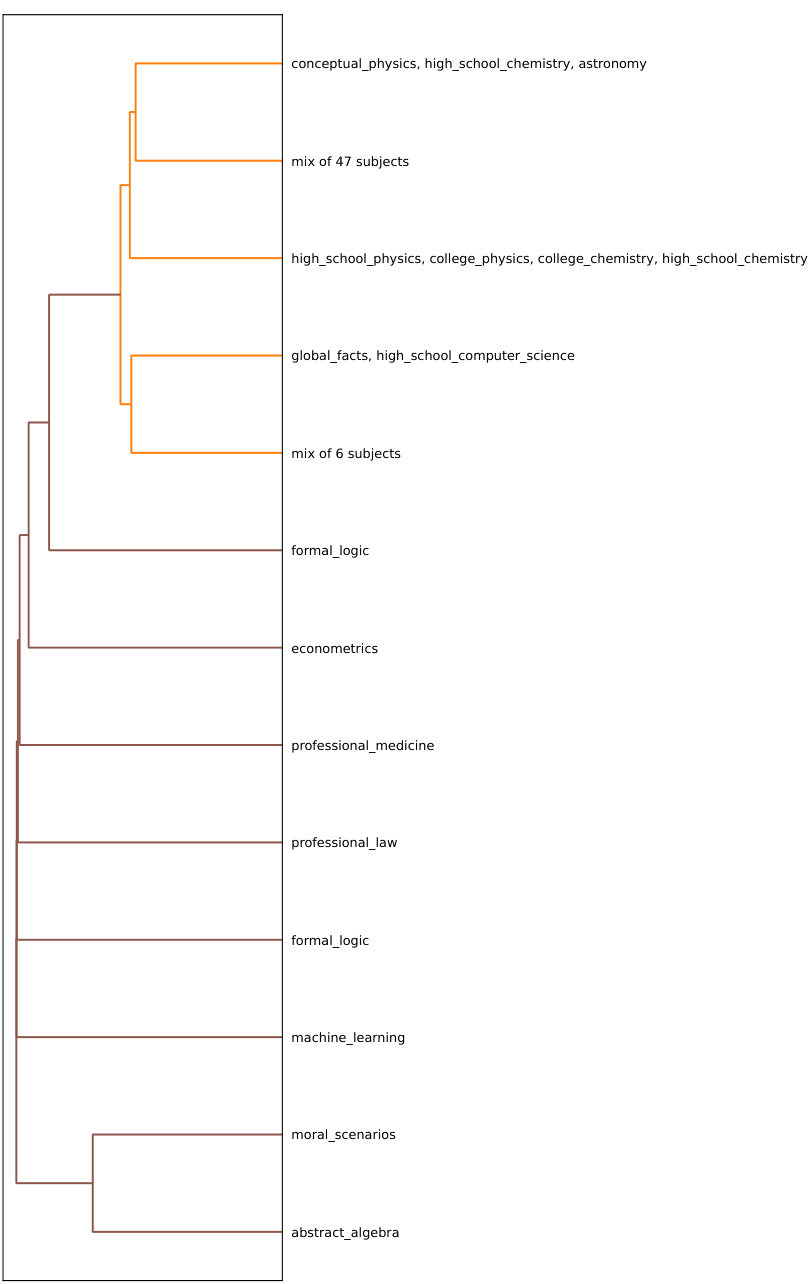
This figure shows dendrograms illustrating the organization of probability density peaks (clusters) in different layers of the Llama3-8b language model. It compares three scenarios: a 5-shot in-context learning (ICL) setup, a 0-shot ICL setup, and a fine-tuned model. The 5-shot ICL setup shows a hierarchical clustering of subjects reflecting semantic relationships. In contrast, the 0-shot ICL and fine-tuned models exhibit less structured, more mixed clusters.
Full paper#