↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Deep neural networks (DNNs) are energy-intensive, and reducing voltage to lower energy consumption often leads to accuracy degradation due to bit flips in memory. This paper addresses this crucial issue in energy-efficient AI. Existing solutions either modify hardware or retrain the model which is often costly and impractical, especially for cloud-based APIs.
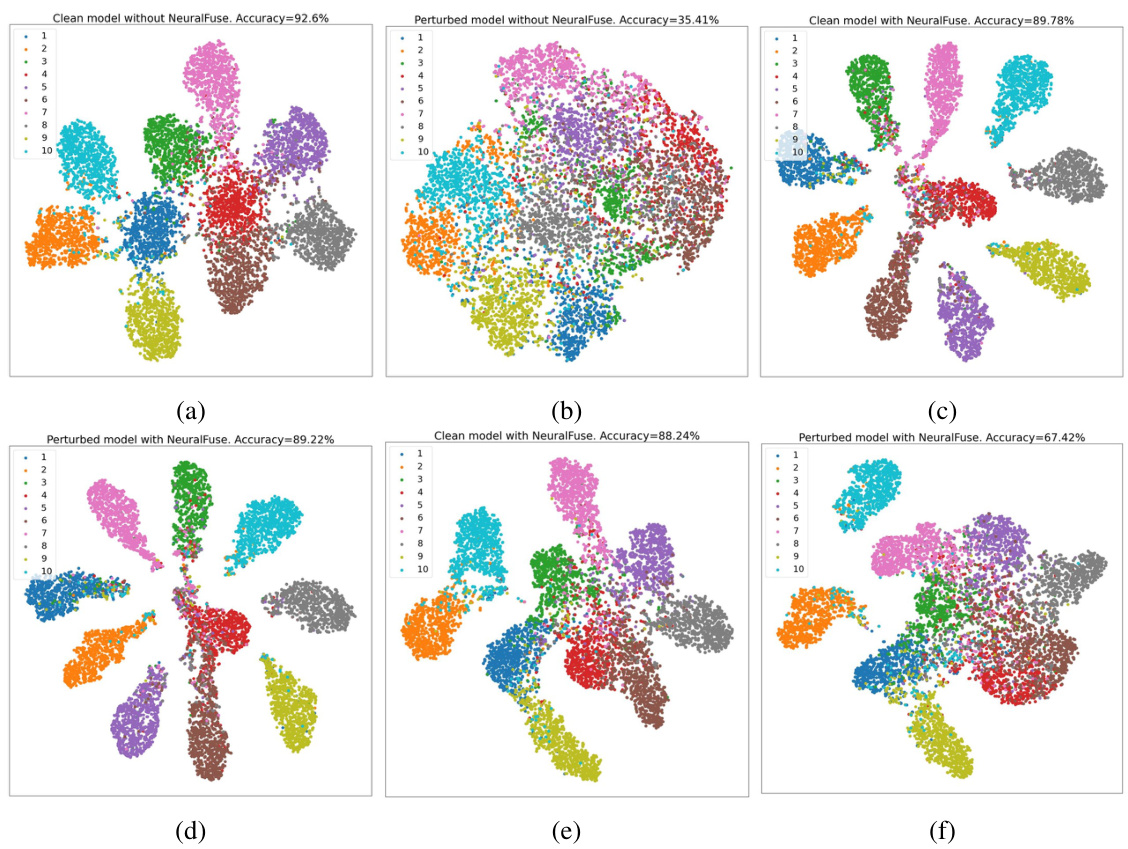
The proposed NeuralFuse module uses a small, trainable DNN to learn input transformations that generate error-resistant data representations. It mitigates low-voltage-induced errors without requiring model retraining, making it highly versatile and applicable to various scenarios with limited access to the models. Experiments show NeuralFuse can improve accuracy by up to 57% and reduce SRAM access energy by up to 24% at a 1% bit-error rate.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel, model-agnostic approach to mitigate accuracy loss in low-voltage deep neural network inference. This is a significant challenge in deploying AI systems in resource-constrained environments, and the proposed method, NeuralFuse, offers a practical solution that doesn’t require model retraining. The results demonstrate significant energy savings and accuracy recovery, opening new avenues for research on energy-efficient AI.
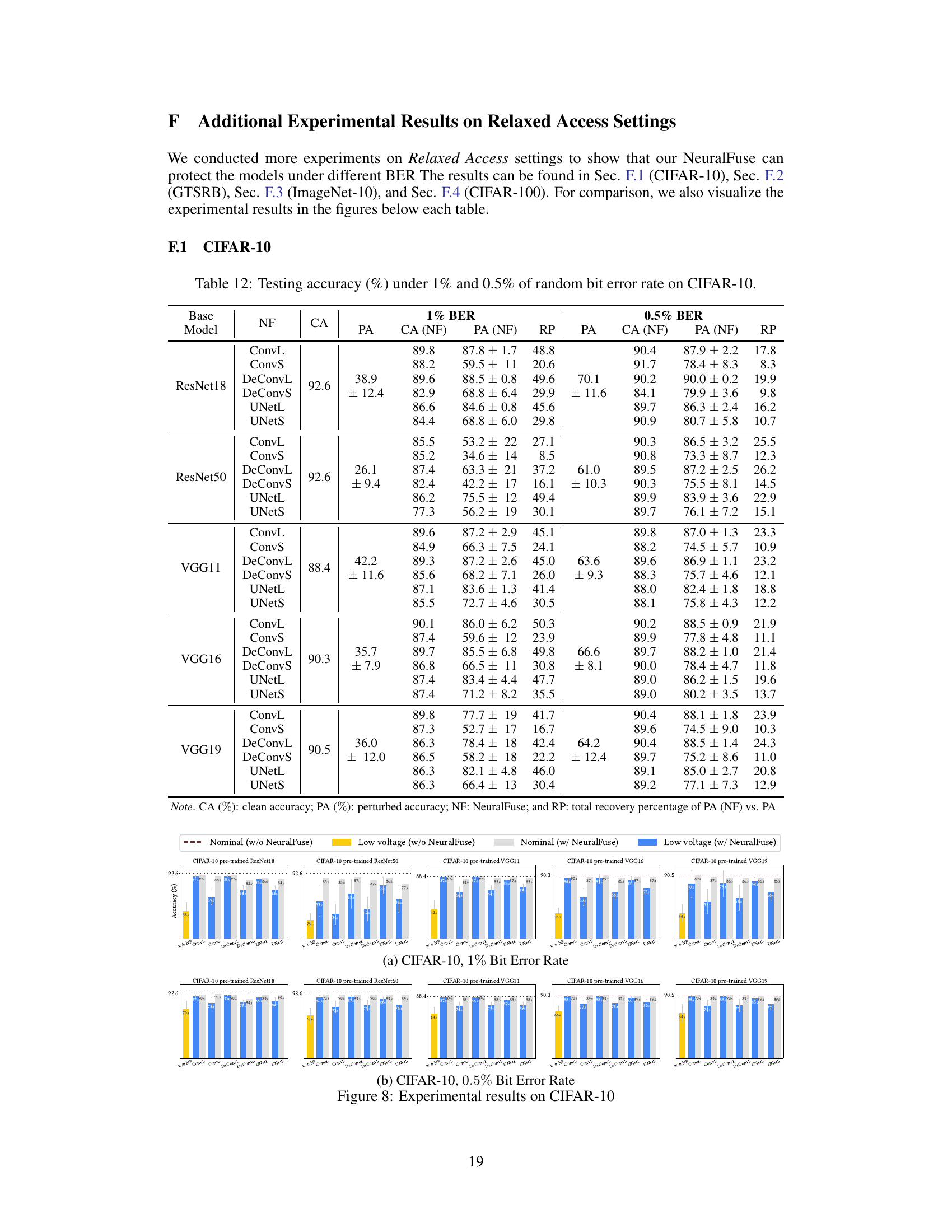
Visual Insights#

This figure illustrates the NeuralFuse framework. (a) shows the pipeline of NeuralFuse at inference, transforming input samples to be robust to bit errors introduced by low voltage. It compares the accuracy at nominal and low voltage with and without NeuralFuse. (b) shows the energy-accuracy tradeoff for six different NeuralFuse implementations, highlighting the energy savings while maintaining accuracy at a 1% bit-error rate.
This table presents the results of the transferability experiment performed under a restricted-access scenario. The experiment evaluated the performance of NeuralFuse trained on a surrogate model and then transferred to various target models (ResNet18, ResNet50, VGG11, VGG16, VGG19). The table shows the clean accuracy (CA), perturbed accuracy (PA), clean accuracy with NeuralFuse (CA (NF)), perturbed accuracy with NeuralFuse (PA (NF)), and the recovery percentage (RP) for each combination of surrogate model, target model, and bit error rate (0.5% and 1%). The results demonstrate the transferability and robustness of NeuralFuse.
In-depth insights#
Low-Voltage DNNs#
Low-voltage DNNs represent a significant challenge and opportunity in deep learning. The primary goal is to reduce energy consumption without sacrificing accuracy. This is difficult because aggressive voltage reduction leads to increased bit-flips in SRAM, where model parameters are stored, causing accuracy degradation. Research in this area focuses on developing hardware and software solutions to mitigate this problem. Hardware solutions might involve specialized memory cells or error correction codes, while software techniques could include model quantization, pruning, or training methods robust to noise. NeuralFuse, as presented in the provided paper, is an example of a software approach that focuses on learning input transformations to create more robust data representations, thereby improving accuracy in low-voltage environments. Future research should explore hybrid approaches combining hardware and software techniques for optimal energy efficiency and accuracy. Benchmarking and standardization are crucial to objectively evaluate the progress and impact of future low-voltage DNN designs.
NeuralFuse Design#
The NeuralFuse design is a model-agnostic, plug-and-play module designed to enhance the accuracy of deep neural networks (DNNs) operating in low-voltage regimes. Its core functionality centers on a trainable input transformation, implemented as a small, efficient DNN. This input transformation learns to generate error-resistant data representations, mitigating the impact of bit errors induced by low-voltage operation on SRAM-based model parameters. The design is particularly innovative because it requires no model retraining, making it applicable to various scenarios with limited access such as cloud-based APIs or non-configurable hardware. A key strength is its model-agnostic nature: NeuralFuse can be seamlessly integrated with various DNN architectures and datasets, demonstrating flexibility and broad applicability. Different architectures (convolutional, deconvolutional, and UNet-based) and sizes of NeuralFuse were investigated to explore optimal performance and efficiency trade-offs.
Energy-Accuracy Tradeoff#
The Energy-Accuracy Tradeoff is a central challenge in low-power deep learning. Reducing energy consumption, often by lowering supply voltage, typically degrades model accuracy due to increased bit errors in SRAM. This tradeoff necessitates strategies that mitigate accuracy loss without significantly impacting energy efficiency. NeuralFuse, as presented in the paper, offers a promising solution by learning input transformations to generate error-resistant data representations. This model-agnostic approach protects DNN accuracy under low-voltage conditions without requiring model retraining, enhancing deployment feasibility in resource-constrained environments. The experimental results demonstrate a substantial improvement, showcasing the effectiveness of NeuralFuse in achieving a balance between energy savings and accuracy recovery. Future work could focus on optimizing NeuralFuse for specific hardware architectures and error characteristics to further refine this critical energy-accuracy balance.
Transfer Learning#
Transfer learning, in the context of the provided research paper, likely focuses on adapting a pre-trained model (NeuralFuse) to new, unseen deep neural networks (DNNs). The core idea revolves around leveraging the knowledge learned by NeuralFuse in one setting to improve performance on other, related tasks. This is particularly relevant when dealing with access-limited scenarios, where retraining is impossible or computationally expensive. Key aspects would include evaluating the model’s ability to generalize across different DNN architectures (e.g., ResNet, VGG), datasets (CIFAR-10, ImageNet), and bit-error rates. Success would be measured by the extent to which NeuralFuse maintains or improves accuracy in low-voltage regimes without requiring retraining on the target DNN. Challenges might stem from domain adaptation issues where the source and target DNNs have significant differences, hindering transferability, or the need for strategies to mitigate the effects of hardware-specific bit errors during the inference stage. The methodology might involve fine-tuning a subset of NeuralFuse’s parameters on a smaller, surrogate model or employing techniques to create a more robust input representation before feeding it to the target DNN. The success of the transfer learning aspect directly relates to the claim of NeuralFuse’s model-agnostic nature and its practical applicability in resource-constrained environments.
Future Works#
Future work could explore several promising avenues. Extending NeuralFuse’s applicability to other neural network architectures and modalities (e.g., transformer-based models) is crucial for broader impact. Optimizing the pre-processing module to better adapt to specific low-voltage SRAM error characteristics and integrating lightweight hardware modifications could further enhance energy efficiency. Investigating the trade-off between runtime latency and energy savings is essential, potentially involving model compression or a more streamlined NeuralFuse architecture. Addressing edge case scenarios, such as those involving exceptionally noisy or corrupted input data, warrants exploration. Finally, a comprehensive investigation into the generalization capabilities of NeuralFuse and its robustness to different hardware platforms and memory technologies is needed for real-world deployment.
More visual insights#
More on figures

This figure shows the NeuralFuse framework. (a) illustrates the pipeline at inference, highlighting input transformation for robustness to bit errors at low voltage. (b) presents an energy-accuracy tradeoff example for different NeuralFuse implementations on a ResNet18 model, demonstrating the balance achieved between energy savings and accuracy recovery at a 1% bit error rate.
This figure shows the NeuralFuse framework’s pipeline during inference and its energy-accuracy tradeoff example. (a) illustrates how NeuralFuse processes input samples and generates robust representations to mitigate bit errors induced by low voltage. The accuracy of a pre-trained ResNet18 model is compared with and without NeuralFuse at nominal and low voltages. (b) presents the energy-accuracy tradeoff for different NeuralFuse implementations on the same ResNet18 model, showing the balance between energy saving (x-axis) and accuracy at low voltage (y-axis).

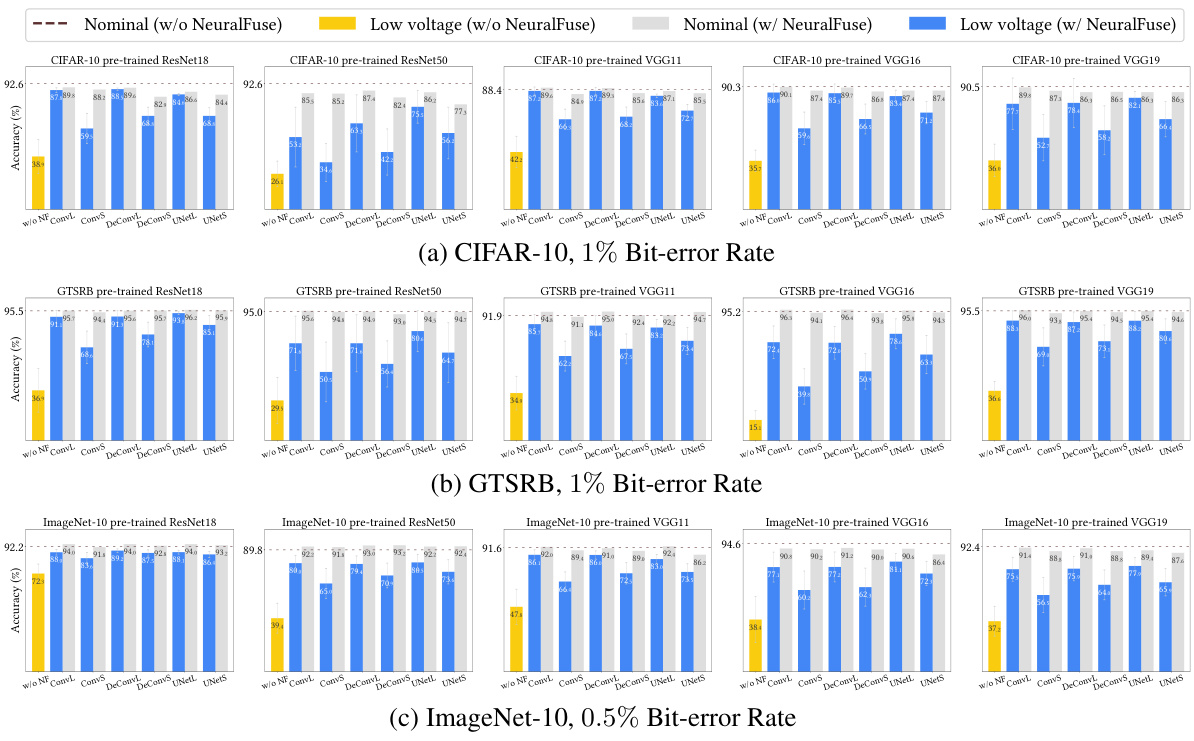
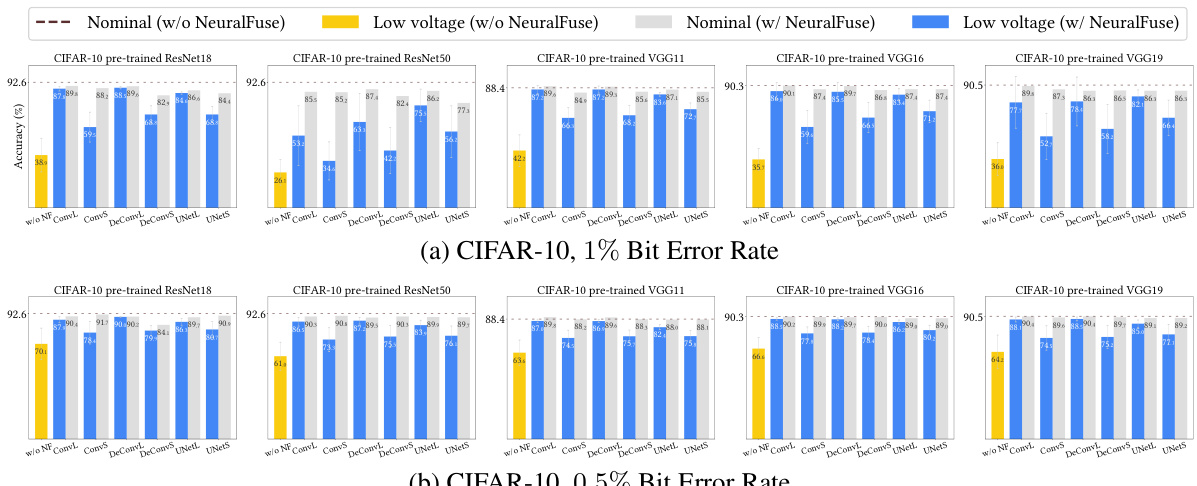
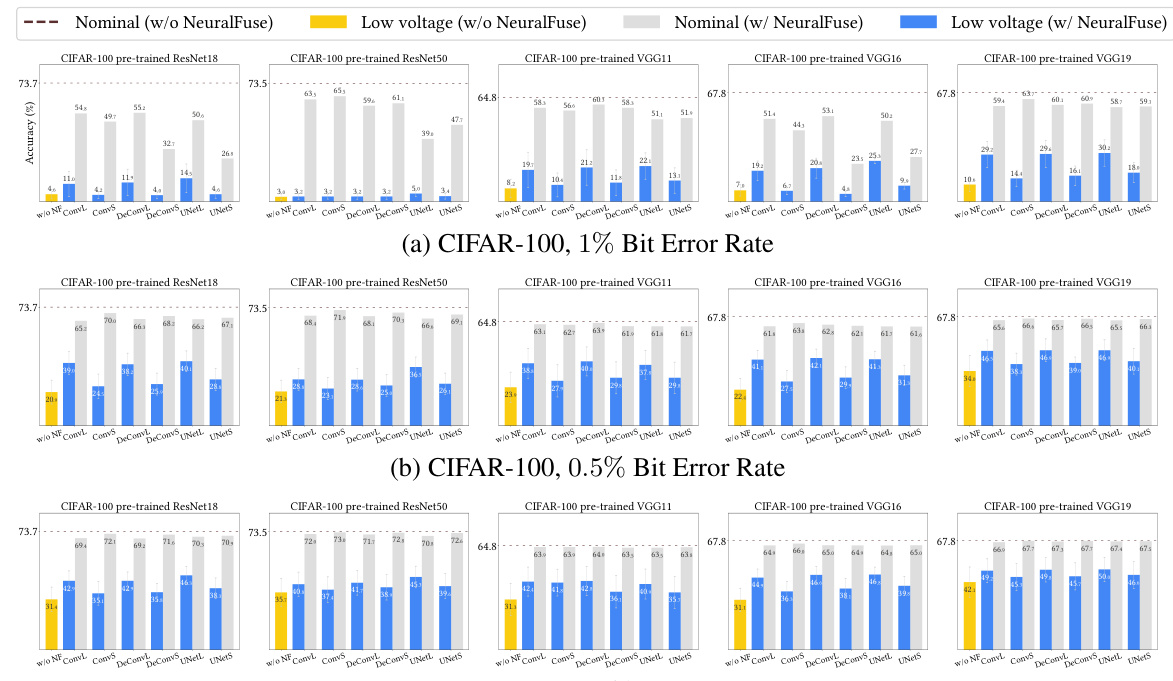
This figure shows the results of the relaxed-access scenario experiments. It compares the test accuracies of various pre-trained models (ResNet18, ResNet50, VGG11, VGG16, VGG19) with and without NeuralFuse under nominal voltage (0% bit-error rate) and low voltage conditions (with specified bit-error rates of 0.5% and 1%). The results show NeuralFuse consistently improves the accuracy when bit errors are present, demonstrating its effectiveness in mitigating the impact of low voltage on model performance.

This figure shows the results of experiments conducted under the relaxed-access scenario. It compares the test accuracies of various pre-trained models (ResNet18, ResNet50, VGG11, VGG16, VGG19) with and without NeuralFuse enabled, at both nominal voltage (no bit errors) and low voltage (with specified bit error rates of 0.5% and 1%). The results visually demonstrate NeuralFuse’s effectiveness in recovering accuracy lost due to low voltage-induced bit errors.
This figure shows the results of experiments conducted in the relaxed-access scenario, where the base model information is not fully transparent but backpropagation through the model is possible. The experiments evaluated various pre-trained models (ResNet18, ResNet50, VGG11, VGG16, VGG19) on three datasets (CIFAR-10, GTSRB, ImageNet-10) with and without NeuralFuse enabled. The x-axis represents the nominal voltage (0% bit-error rate) and different low-voltage settings with specified bit-error rates (BER). The y-axis represents the test accuracy. For each model and voltage setting, the accuracy is displayed with and without NeuralFuse. The figure demonstrates NeuralFuse’s effectiveness in recovering accuracy at low voltages by consistently improving the perturbed accuracy.

The figure shows the performance of NeuralFuse in a relaxed-access scenario where the model details are known, but not the internal workings. The experiment is performed with three different datasets (CIFAR-10, GTSRB, and ImageNet-10) and various pre-trained models. The figure compares the test accuracies at nominal voltage (without bit errors) and low voltage (with specified bit-error rates) with and without NeuralFuse enabled. The results demonstrate NeuralFuse’s effectiveness in recovering accuracy losses caused by low-voltage induced bit errors.
This figure shows two parts: (a) illustrates how NeuralFuse works during inference. It transforms input data to make it robust to bit errors at low voltage. The example shows the accuracy of a CIFAR-10 pre-trained ResNet18 model with and without NeuralFuse at normal and low voltages. (b) Presents energy/accuracy tradeoffs of different NeuralFuse architectures. The X-axis shows energy savings and Y-axis shows accuracy at a 1% bit error rate. It demonstrates how NeuralFuse can recover accuracy while reducing energy consumption at low voltage.

This figure shows the pipeline of NeuralFuse and its impact on energy-accuracy tradeoff. (a) illustrates how NeuralFuse processes input data to generate robust representations that are resistant to bit errors induced by low voltage. It compares the accuracy of a ResNet18 model with and without NeuralFuse at nominal and low voltages. (b) presents the energy-accuracy tradeoff curves for six different NeuralFuse architectures, highlighting the energy savings achieved while maintaining accuracy at a 1% bit error rate.

This figure shows the results of experiments conducted under the relaxed-access scenario. It compares the accuracy of various pre-trained models (ResNet18, ResNet50, VGG11, VGG16, VGG19) with and without the NeuralFuse module applied. The accuracy is evaluated at both nominal voltage (0% bit error rate) and low voltage (with specified bit-error rates of 0.5% and 1%). The results highlight the ability of NeuralFuse to significantly improve the accuracy of the base models when operating under low-voltage conditions that introduce bit errors.
This figure presents the results of experiments conducted in a relaxed-access scenario where the base models’ details were not entirely transparent but backpropagation was possible. It compares the test accuracies of various pre-trained models with and without NeuralFuse under different bit-error rates (BERs) at both nominal and low voltages. The results show the consistent accuracy recovery offered by NeuralFuse, showcasing its effectiveness in mitigating the negative impact of low voltage on model accuracy.
This figure shows the pipeline of the NeuralFuse framework during inference and an example of the energy/accuracy tradeoff. (a) illustrates how NeuralFuse transforms inputs to create robust representations that are resilient to bit errors introduced at low voltage. It compares the accuracy of a ResNet18 model with and without NeuralFuse under nominal and low-voltage conditions, highlighting the accuracy loss due to bit errors. (b) displays the energy-accuracy tradeoff for different NeuralFuse implementations on the same ResNet18 model, showing the potential for energy savings while maintaining high accuracy. The x-axis represents the energy savings, and the y-axis represents the accuracy under a 1% bit error rate.
This figure shows the test accuracies of various pre-trained models (ResNet18, ResNet50, VGG11, VGG16, VGG19) on three datasets (CIFAR-10, GTSRB, ImageNet-10) under different bit error rates (0%, 0.5%, 1%). The results are displayed for both scenarios: without NeuralFuse and with NeuralFuse. The figure demonstrates how NeuralFuse consistently improves the accuracy of models under low voltage conditions by mitigating bit-flip errors caused by undervoltage.

This figure shows the results of the experiments conducted in the relaxed-access scenario. The experiment evaluated various pre-trained models (ResNet18, ResNet50, VGG11, VGG16, VGG19) on CIFAR-10, GTSRB, and ImageNet-10 datasets. Each model was tested under nominal voltage (0% bit error rate) and low voltage conditions (with 0.5% or 1% bit error rates). The accuracy was measured with and without the NeuralFuse module enabled. The figure illustrates that NeuralFuse consistently increased the perturbed accuracy (accuracy under bit errors) across various models and datasets, highlighting the effectiveness of the proposed method in mitigating bit errors caused by low voltage.

This figure shows the results of experiments conducted under the relaxed-access scenario. It compares the test accuracies of various pre-trained models (ResNet18, ResNet50, VGG11, VGG16, and VGG19) with and without NeuralFuse enabled. The accuracies are measured at both nominal voltage (0% bit-error rate) and low voltage (with specified bit error rates of 0.5% and 1%). The results presented illustrate that NeuralFuse consistently improves accuracy, particularly under low-voltage conditions where bit errors occur.
This figure shows the results of the relaxed-access scenario experiments, where the accuracy of various pre-trained models (ResNet18, ResNet50, VGG11, VGG16, and VGG19) is evaluated under both nominal voltage (no bit errors) and low-voltage conditions (with 0.5% or 1% bit error rate). It compares the accuracy with and without the NeuralFuse module. The results demonstrate NeuralFuse’s effectiveness in improving the accuracy of these models, especially under low-voltage conditions with bit errors.

This figure shows the accuracy of various pre-trained models (ResNet18, ResNet50, VGG11, VGG16, VGG19) on three datasets (CIFAR-10, GTSRB, ImageNet-10) under both nominal voltage (no bit errors) and low voltage (with 0.5% or 1% bit error rates). It compares the performance of the models with and without NeuralFuse enabled. The results show that NeuralFuse consistently improves the accuracy of the models under low voltage conditions.
This figure shows the pipeline of NeuralFuse framework during inference, and the energy/accuracy tradeoff example using CIFAR-10 pre-trained ResNet18 model at different voltage settings and NeuralFuse implementations. The left panel shows how NeuralFuse improves the robustness of the model to bit errors induced by low voltage. The right panel shows the energy savings and accuracy recovery achieved by different NeuralFuse implementations at 1% bit-error rate.

This figure shows NeuralFuse’s framework and its energy/accuracy tradeoff. (a) illustrates how NeuralFuse processes inputs to generate robust representations, protecting against bit errors introduced at low voltage. The example uses a pre-trained ResNet18 on CIFAR-10, showing accuracy improvements with NeuralFuse enabled under both nominal and low-voltage conditions. (b) displays the energy-accuracy trade-off achieved using six different NeuralFuse implementations; the graph showcases the balance between reduced memory access energy and maintained accuracy at a 1% bit error rate.

This figure shows two subfigures. Subfigure (a) illustrates the NeuralFuse framework pipeline during inference, highlighting the input transformation to create robust representations and the impact of bit errors at low voltage on model accuracy. Subfigure (b) presents the energy-accuracy trade-off achieved by six different NeuralFuse implementations, demonstrating the ability of NeuralFuse to reduce energy consumption at low voltage while maintaining accuracy.
More on tables

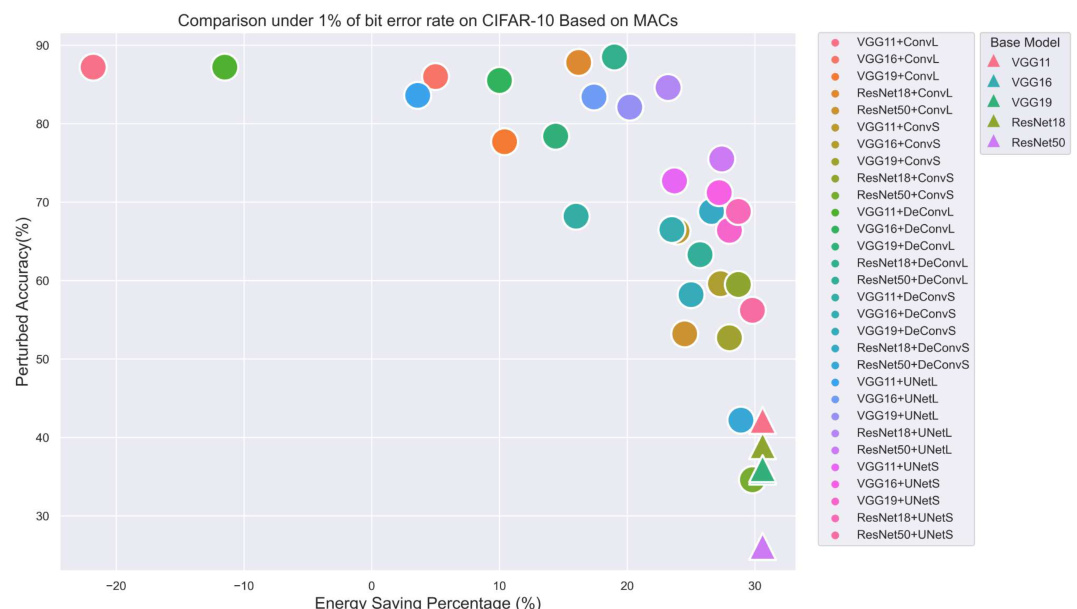
This table shows the energy savings achieved by using NeuralFuse with various base models (ResNet18, ResNet50, VGG11, VGG16, and VGG19) and NeuralFuse generators (ConvL, ConvS, DeConvL, DeConvS, UNetL, and UNetS). The energy savings are calculated at a 1% bit-error rate. The values represent the percentage reduction in dynamic memory access energy when using NeuralFuse compared to the bit-error-free (nominal) voltage.

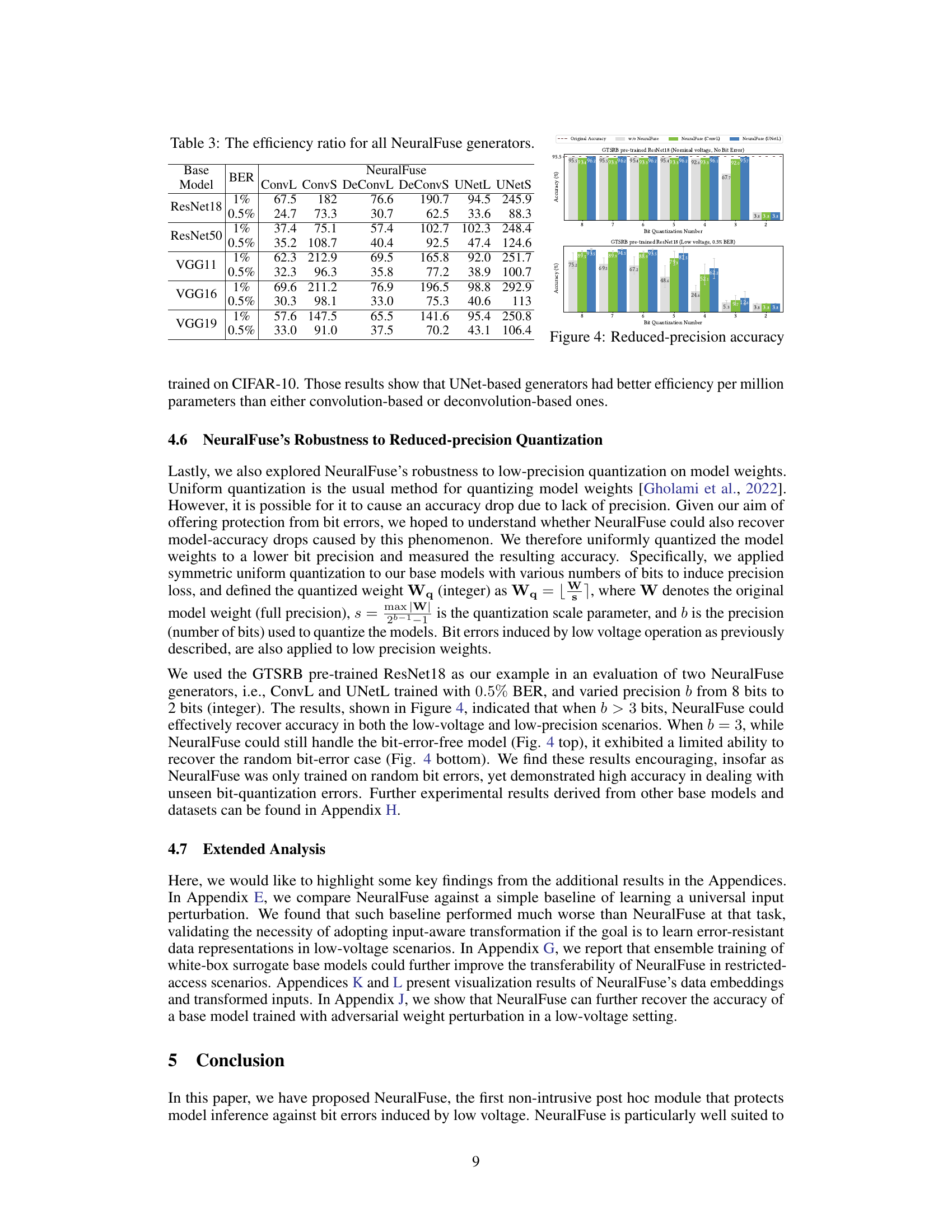
This table presents the efficiency ratio for different NeuralFuse generators. The efficiency ratio is calculated as the recovery percentage in perturbed accuracy divided by the NeuralFuse’s parameter count. It compares the efficiency ratios of all NeuralFuse generators trained on CIFAR-10, considering different base models (ResNet18, ResNet50, VGG11, VGG16, and VGG19) and bit error rates (0.5% and 1%). This allows for a comparison of the effectiveness of different generator architectures in terms of accuracy recovery per parameter.

This table details the architecture of the Convolution-based and Deconvolution-based NeuralFuse generators. It specifies the layers, including ConvBlocks (Convolution, Batch Normalization, ReLU), MaxPool, UpSample, and DeConvBlocks (Deconvolution, Batch Normalization, ReLU) layers for both large (L) and small (S) versions of each generator type. The #CHs column indicates the number of channels for each layer. The table helps in understanding the structural differences and complexities of the different generator designs.

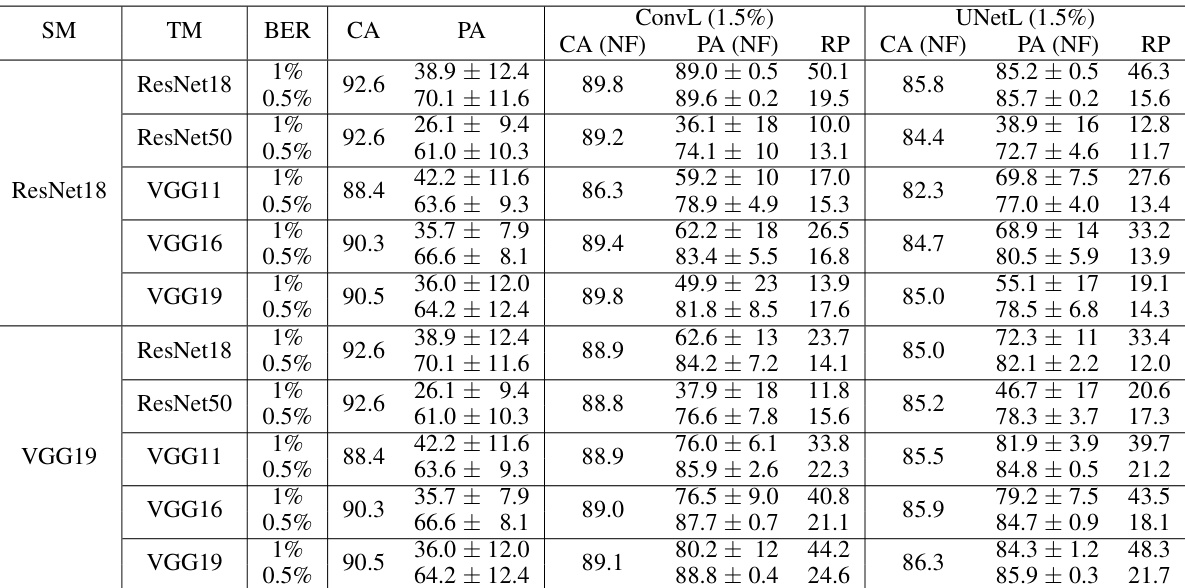
This table presents the results of transfer learning experiments conducted on the CIFAR-10 dataset using the NeuralFuse framework in a restricted access scenario. The experiments involved training NeuralFuse generators (ConvL and UNetL) on a source model (SM) with a 1.5% bit error rate (BER) and then transferring them to various target models (TM) with different bit error rates (0.5% and 1%). The table shows the clean accuracy (CA), perturbed accuracy (PA), clean accuracy with NeuralFuse (CA(NF)), perturbed accuracy with NeuralFuse (PA(NF)), and the recovery percentage (RP) for each combination of source and target models and bit error rates. The RP indicates the percentage improvement in perturbed accuracy achieved by NeuralFuse.

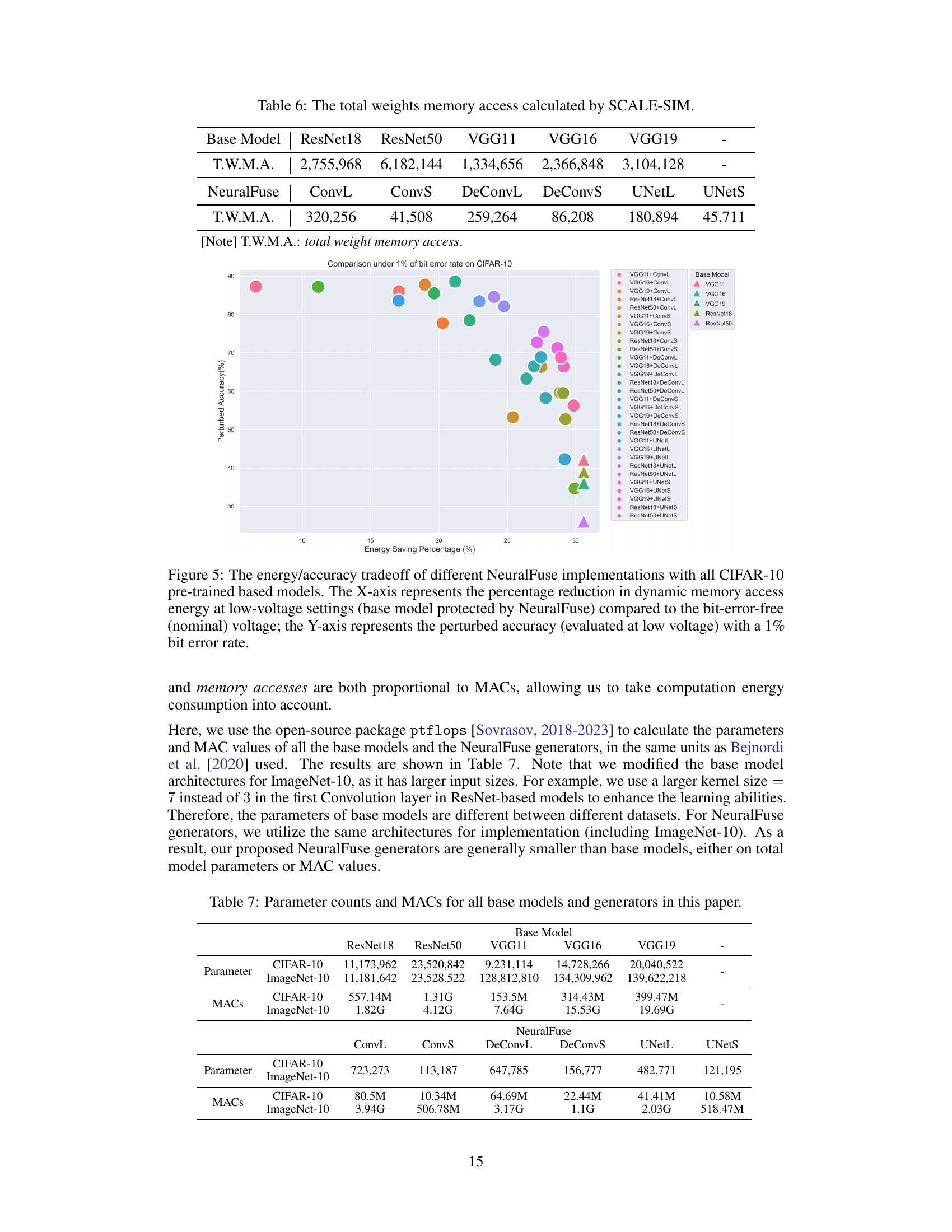
This table presents the total number of weight memory accesses for different base models (ResNet18, ResNet50, VGG11, VGG16, VGG19) and NeuralFuse generators (ConvL, ConvS, DeConvL, DeConvS, UNetL, UNetS). The values are calculated using the SCALE-SIM simulator. The total weight memory access (T.W.M.A) for each model is shown, providing a quantitative measure of memory usage related to model weights.

This table presents the total number of weight memory accesses (T.W.M.A.) for different base models (ResNet18, ResNet50, VGG11, VGG16, VGG19) and NeuralFuse generators (ConvL, ConvS, DeConvL, DeConvS, UNetL, UNetS) calculated using the SCALE-SIM simulator. The T.W.M.A. values are crucial for determining the overall energy consumption of the models in the context of SRAM access energy.
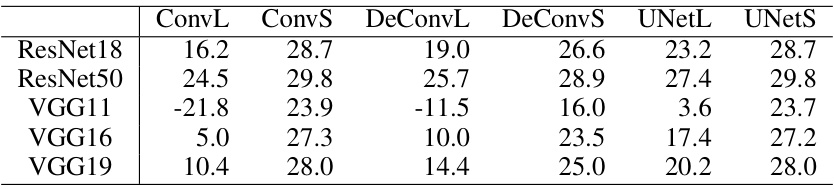
This table presents the energy savings achieved by using NeuralFuse with various base models (ResNet18, ResNet50, VGG11, VGG16, and VGG19) and generators (ConvL, ConvS, DeConvL, DeConvS, UNetL, and UNetS). The energy savings are calculated as the percentage reduction in dynamic memory access energy at low voltage with a 1% bit error rate, compared to the nominal voltage without bit errors. The table shows the effectiveness of NeuralFuse in reducing energy consumption while maintaining accuracy.

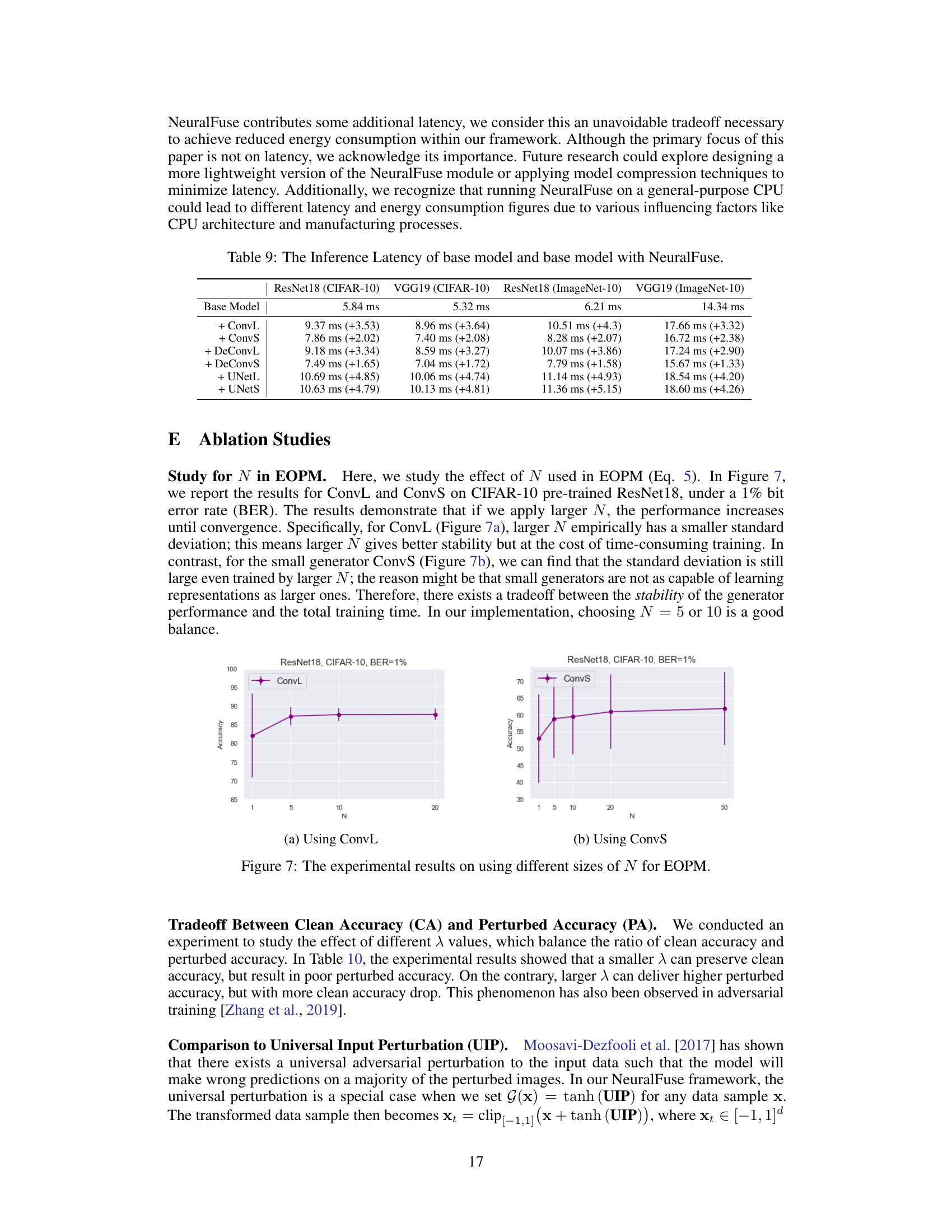
This table shows the inference latency of base models and base models with NeuralFuse in milliseconds (ms). The latency is measured for different models (ResNet18 and VGG19) on two datasets (CIFAR-10 and ImageNet-10) and with different NeuralFuse generators (ConvL, ConvS, DeConvL, DeConvS, UNetL, and UNetS). The numbers in parentheses indicate the increase in latency compared to the base model for each generator.
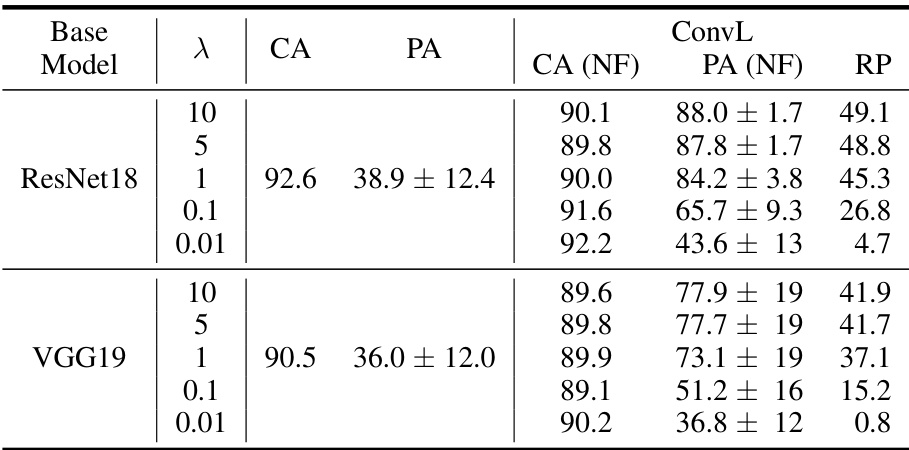
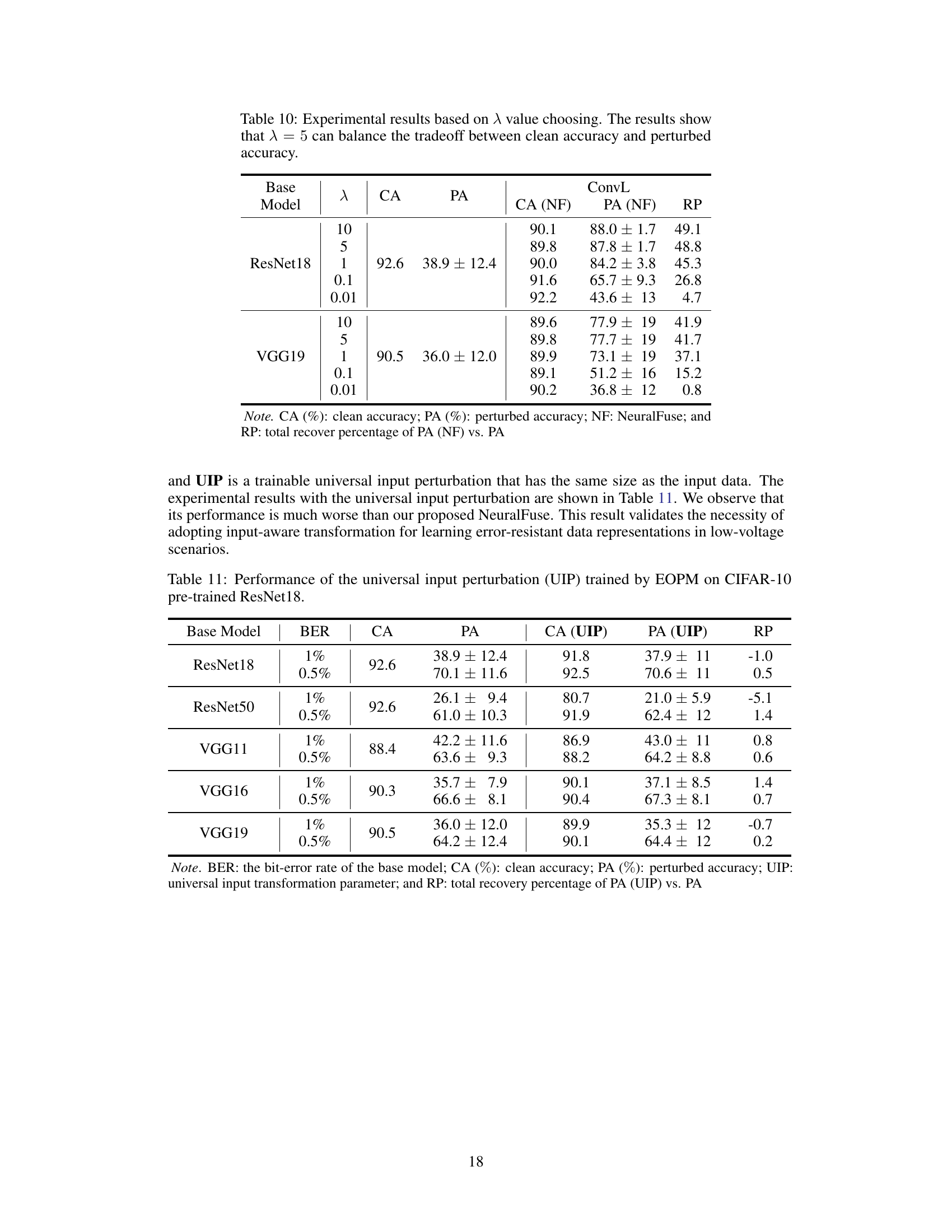
This table presents the results of experiments conducted to determine the optimal value of the hyperparameter λ in the NeuralFuse training objective function. The objective function balances the importance of maintaining accuracy on clean (unperturbed) inputs versus accuracy on inputs perturbed by simulated bit errors due to low voltage. Different values of λ were tested on ResNet18 and VGG19 models, and the clean accuracy (CA), perturbed accuracy (PA), and the percentage accuracy recovery (RP) provided by NeuralFuse are reported. The results show that λ = 5 provides a good balance between clean and perturbed accuracy.

This table presents the results of an experiment comparing the performance of NeuralFuse against a simple baseline method called Universal Input Perturbation (UIP). The experiment uses a CIFAR-10 pre-trained ResNet18 model and evaluates performance under different bit error rates (BER). The table shows the clean accuracy (CA), perturbed accuracy (PA), and the recovery percentage (RP) for both NeuralFuse and UIP. The RP metric indicates the improvement in perturbed accuracy achieved by each method relative to the baseline.

This table presents the results of the transferability experiment conducted under the restricted access scenario on the CIFAR-10 dataset with a 1.5% bit error rate. It shows the performance of different base models (ResNet18, ResNet50, VGG11, VGG16, VGG19) when using NeuralFuse generators trained on a surrogate model (ResNet18 or VGG19) at 1.5% bit-error rate. The results are compared with and without NeuralFuse at 0.5% and 1% bit-error rates. The table includes clean accuracy (CA), perturbed accuracy (PA), clean accuracy with NeuralFuse (CA(NF)), perturbed accuracy with NeuralFuse (PA(NF)), and recovery percentage (RP) for each model and generator combination.

This table presents the results of transfer learning experiments on CIFAR-10, where NeuralFuse models were trained on a source model with a 1.5% bit error rate and then tested on various target models with different bit error rates (0.5% and 1%). The table shows the clean accuracy (CA), perturbed accuracy (PA), and the recovery percentage (RP) for each combination. It demonstrates NeuralFuse’s ability to transfer knowledge learned from a high bit-error-rate setting to achieve accuracy improvements in lower bit-error-rate scenarios. Different source (SM) and target (TM) models (ResNet18, ResNet50, VGG11, VGG16, VGG19) and generator types (ConvL, UNetL) are evaluated.
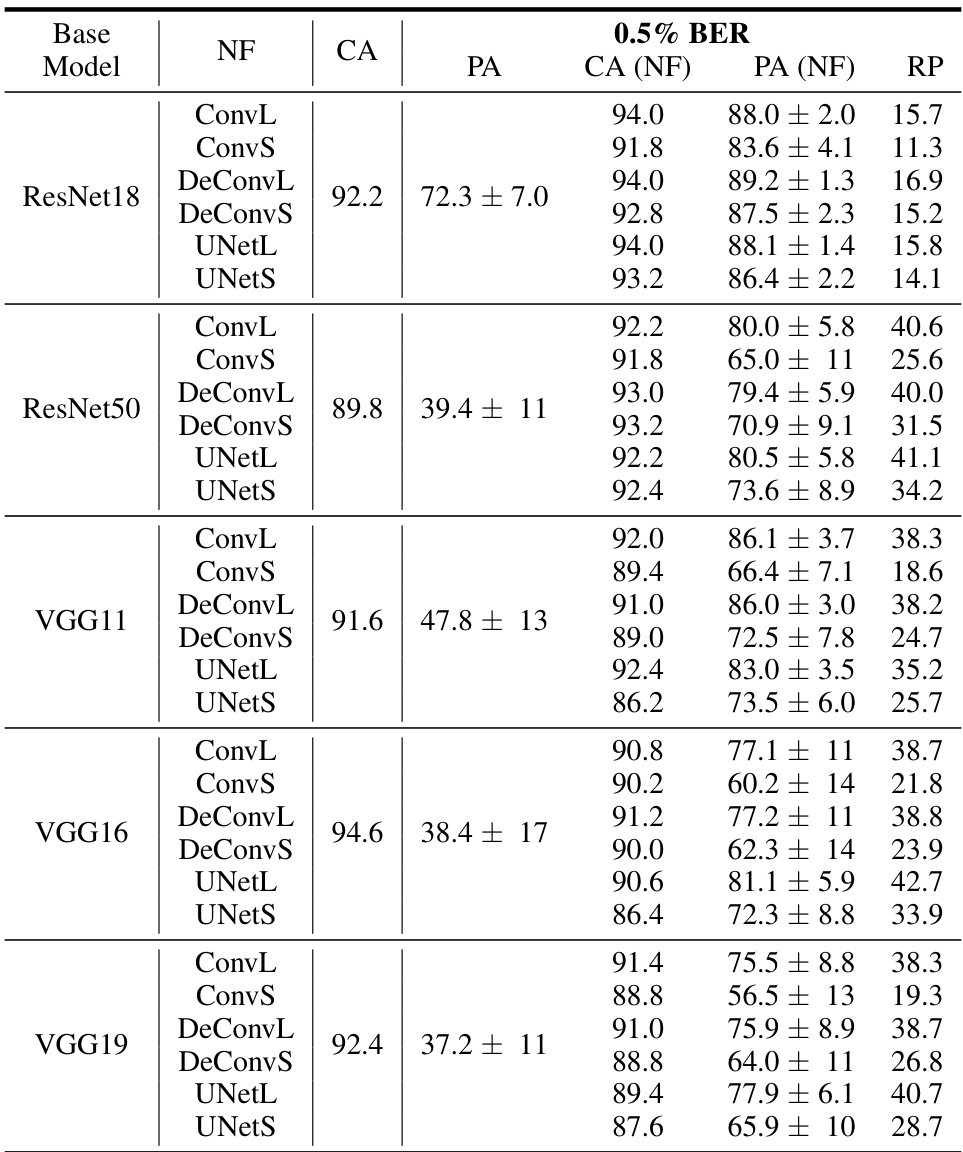
This table presents the results of testing the accuracy of various pre-trained models (ResNet18, ResNet50, VGG11, VGG16, VGG19) on the ImageNet-10 dataset under a 0.5% random bit error rate. The models were tested both with and without NeuralFuse, and for each model, several different NeuralFuse generator architectures were applied (ConvL, ConvS, DeConvL, DeConvS, UNetL, UNetS). The table shows the clean accuracy (CA), the perturbed accuracy (PA), the accuracy with NeuralFuse (CA (NF)), the perturbed accuracy with NeuralFuse (PA (NF)), and the recovery percentage (RP). The RP metric indicates the improvement in accuracy achieved by NeuralFuse in mitigating the impact of bit errors.
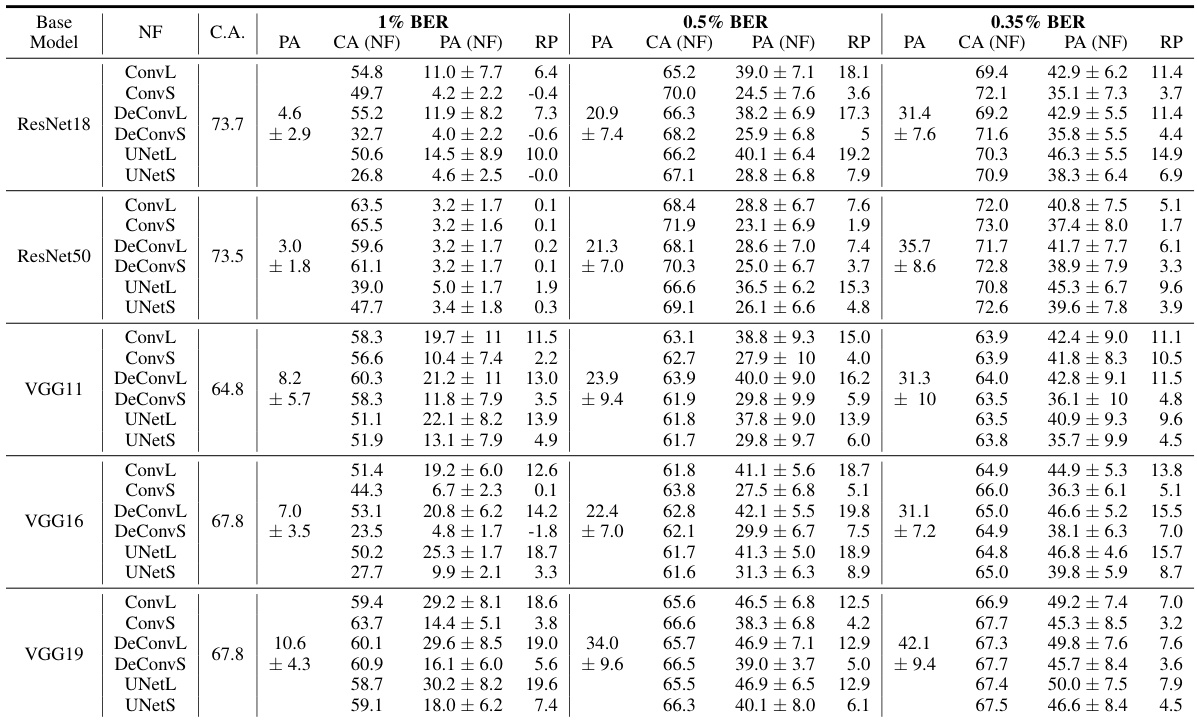
This table presents the results of testing the accuracy of various models (ResNet18, ResNet50, VGG11, VGG16, VGG19) on the CIFAR-100 dataset under different bit error rates (1%, 0.5%, 0.35%). For each model and bit error rate, the table shows the clean accuracy (CA), the perturbed accuracy (PA), the accuracy after applying NeuralFuse (CA (NF), PA (NF)), and the percentage recovery (RP). The results demonstrate the effectiveness of NeuralFuse in improving model accuracy under various bit error conditions.
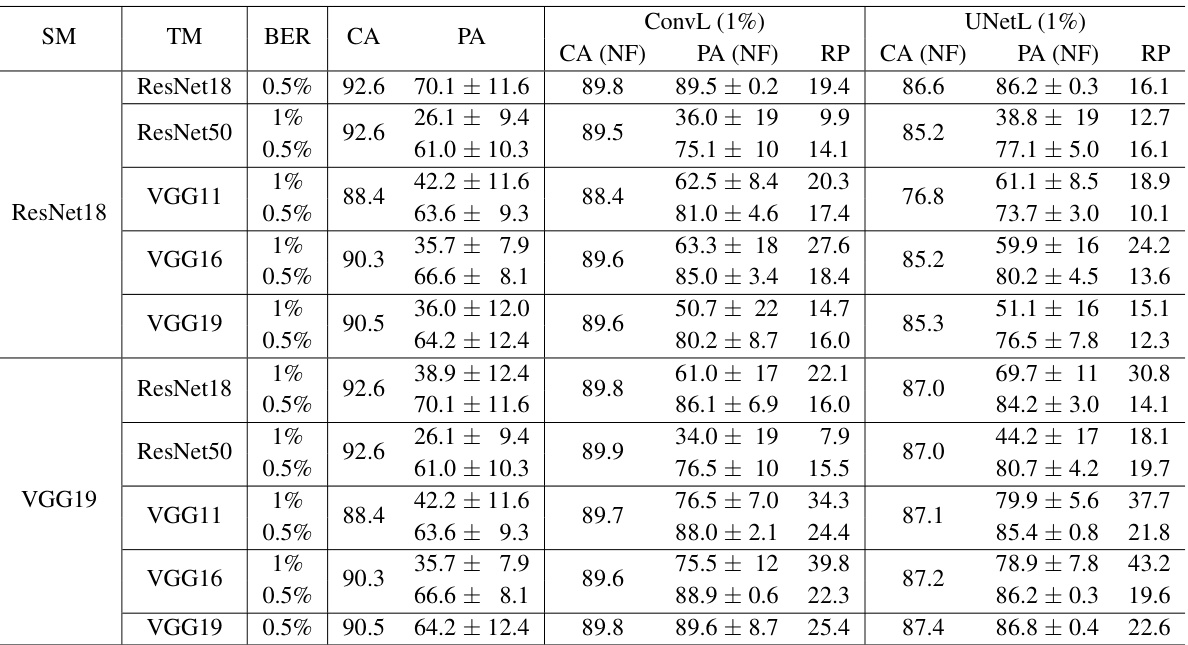
This table presents the results of the transferability experiment in the restricted access scenario on the CIFAR-10 dataset using a 1.5% bit error rate. It shows the clean accuracy (CA), perturbed accuracy (PA), and the recovery percentage (RP) achieved by NeuralFuse with various combinations of source models (SM) used for training the generators, target models (TM) used for testing, and the bit error rate (BER). The table aims to evaluate the performance of NeuralFuse in situations where access to the base model is restricted.

This table presents the results of transfer learning experiments on the GTSRB dataset using NeuralFuse. The model was trained on a source model (SM) with a 1.5% bit error rate (BER). The table shows the clean accuracy (CA), perturbed accuracy (PA), and the recovery percentage (RP) for different target models (TM) and bit error rates (0.5% and 1%). The results are shown separately for two different NeuralFuse generators: ConvL and UNetL. It demonstrates the transferability of NeuralFuse trained at one bit error rate to other models and BERs.

This table presents the results of transfer learning experiments on the CIFAR-10 dataset. The NeuralFuse model was initially trained on a source model (SM) with a 1% bit error rate (BER). The table shows the performance of the trained NeuralFuse model when applied to various target models (TM) at different BERs (0.5% and 1%). The columns show the source model, target model, BER, clean accuracy (CA), perturbed accuracy (PA), NeuralFuse clean accuracy (CA (NF)), NeuralFuse perturbed accuracy (PA (NF)), and the recovery percentage (RP). The RP indicates the improvement in accuracy achieved by applying the NeuralFuse model, relative to the perturbed accuracy without NeuralFuse.

This table presents the results of transfer learning experiments on the CIFAR-10 dataset. The experiment uses NeuralFuse, a model-agnostic module, trained on a source model (SM) with a 1% bit-error rate (BER). The table shows how well NeuralFuse, trained in this way, transfers to different target models (TM) operating under 0.5% and 1% BER. The results are shown in terms of clean accuracy (CA), perturbed accuracy (PA), clean accuracy with NeuralFuse (CA (NF)), perturbed accuracy with NeuralFuse (PA (NF)), and the recovery percentage (RP) of PA (NF) compared to PA. This demonstrates the transferability of NeuralFuse trained on a single model and BER to other models and BERs.
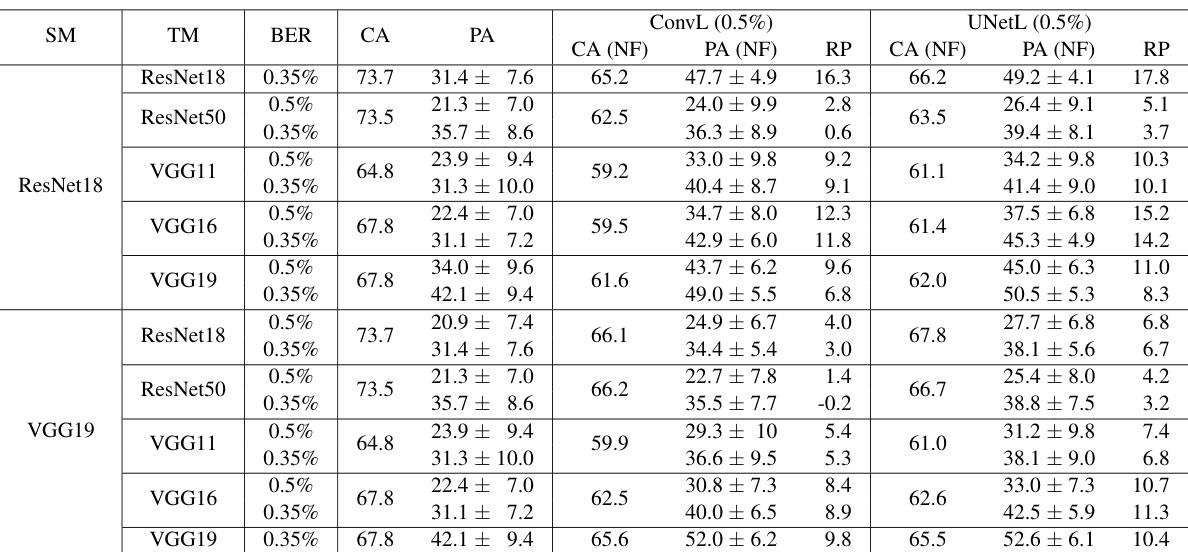
This table presents the results of transfer learning experiments conducted in a restricted-access scenario. NeuralFuse, a model-agnostic module, was trained on a surrogate model (SM) with a 1.5% bit-error rate (BER) and then transferred to various target models (TM) for testing. The table shows the clean accuracy (CA), perturbed accuracy (PA) before and after applying NeuralFuse (CA(NF), PA(NF)), and the recovery percentage (RP) for different target models under 0.5% and 1% BER. The results demonstrate the transferability and effectiveness of NeuralFuse in access-limited settings.

This table presents the results of transfer learning experiments conducted in a restricted-access scenario on the CIFAR-10 dataset with a 1.5% bit error rate. It shows the performance of NeuralFuse generators trained on different source models (SM) applied to various target models (TM) under different bit error rates (BER). The table includes the clean accuracy (CA), perturbed accuracy (PA), clean accuracy with NeuralFuse (CA (NF)), perturbed accuracy with NeuralFuse (PA (NF)), and the recovery percentage (RP) which quantifies the improvement in accuracy due to NeuralFuse. The goal is to evaluate the transferability of NeuralFuse trained in one setting to other models and bit error rates.

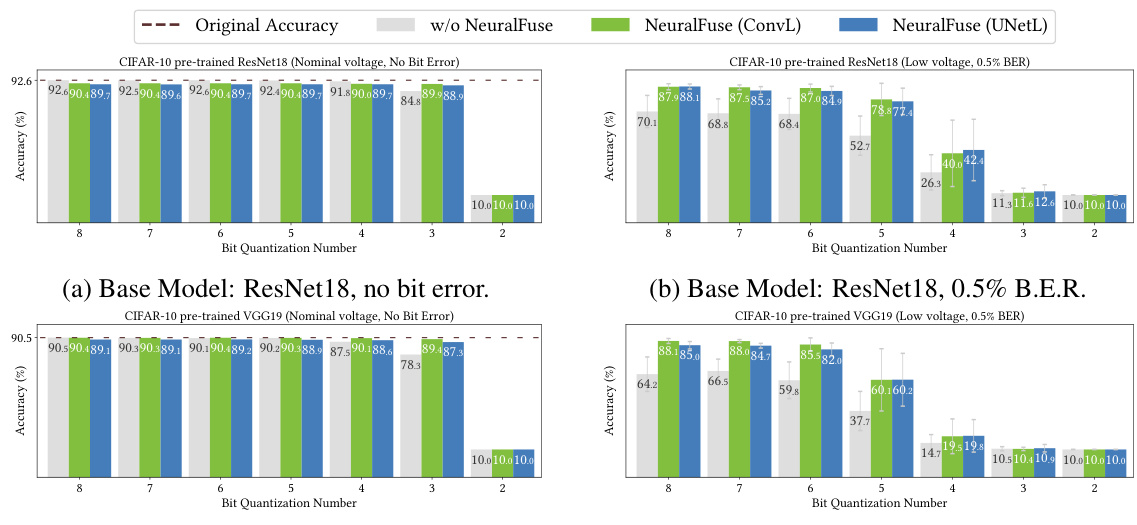
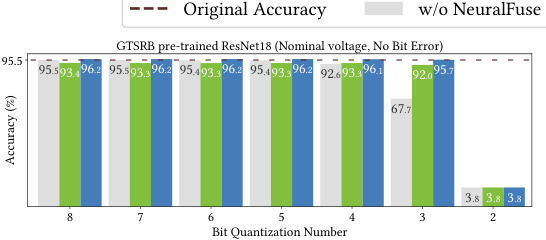
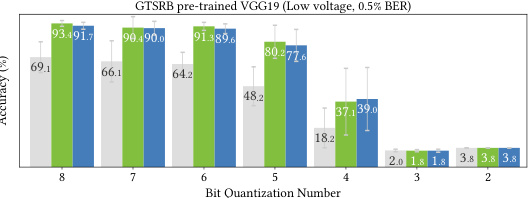
This table presents the results of an experiment evaluating the impact of reduced-precision quantization on model accuracy, in the presence of a 0.5% bit error rate (BER) due to low voltage. It compares the clean accuracy (CA), perturbed accuracy (PA), and the accuracy recovery percentage (RP) achieved by NeuralFuse using different numbers of bits for quantization (from 8 bits down to 2 bits). The table shows the performance of two NeuralFuse generator architectures (ConvL and UNetL, both trained with a 1% BER) on two different base models (ResNet18 and VGG19).

This table presents the results of an experiment evaluating the performance of NeuralFuse on CIFAR-10 pre-trained models under reduced-precision quantization and a 0.5% bit error rate. It shows the clean accuracy (CA), perturbed accuracy (PA), and the accuracy recovery percentage (RP) achieved by NeuralFuse (ConvL and UNetL) for different bit quantization levels (8-2 bits). The data demonstrates NeuralFuse’s resilience to both low-precision and bit errors.
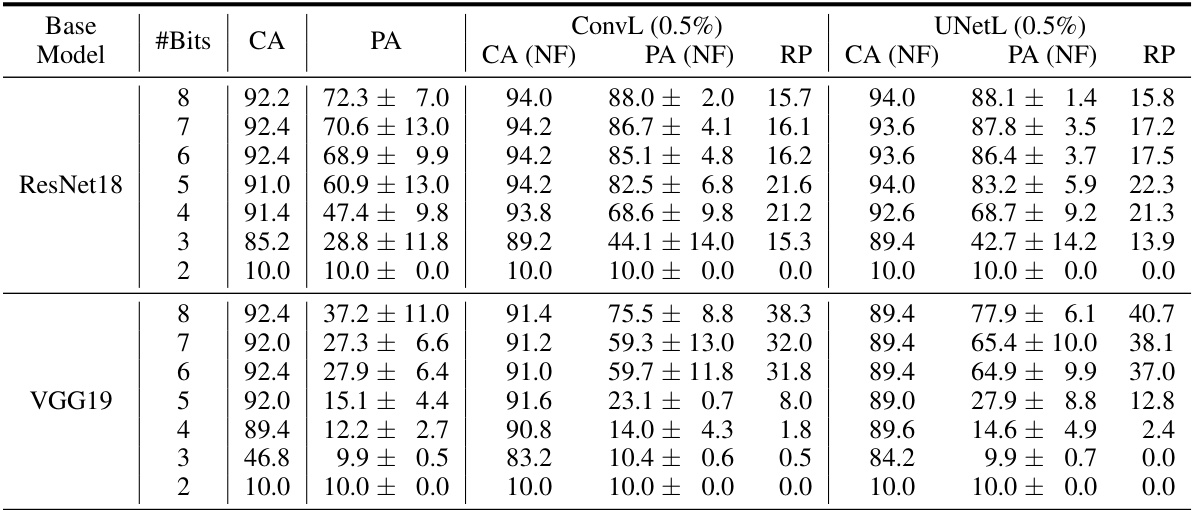
This table presents the results of an experiment evaluating the impact of reduced-precision quantization on model accuracy, in the presence of a 0.5% bit error rate due to low voltage. It shows clean accuracy (CA), perturbed accuracy (PA), and the accuracy recovered by NeuralFuse (CA(NF), PA(NF)) for different numbers of bits used for quantization. The recovery percentage (RP) is also provided, indicating the effectiveness of NeuralFuse in mitigating the negative impact of both reduced precision and bit errors. Two different NeuralFuse generator architectures, ConvL and UNetL, are compared.
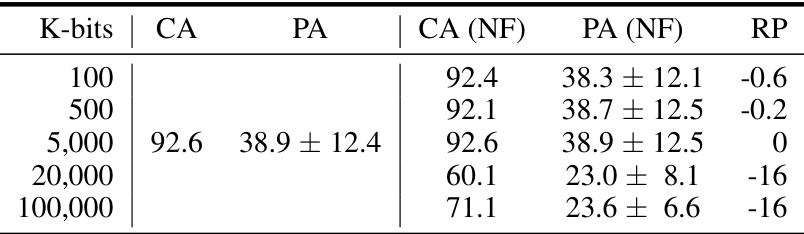
This table presents the results of an experiment evaluating the performance of a generator trained using adversarial training. The experiment used ResNet18 on the CIFAR-10 dataset. The goal was to assess the generator’s ability to maintain high accuracy when facing bit errors (simulated by flipping bits in the model’s weights). The table shows that the adversarial training approach was not successful in achieving this, demonstrating a limitation in the method for addressing the impact of random bit errors.

This table presents the results of applying NeuralFuse to a robust model (PreAct ResNet18) pre-trained on CIFAR-10. It evaluates the performance of different NeuralFuse generator architectures (ConvL, ConvS, DeConvL, DeConvS, UNetL, UNetS) at both 1% and 0.5% bit error rates (BER). The table shows the clean accuracy (CA), perturbed accuracy (PA), and the percentage recovery (RP) achieved by NeuralFuse for each generator architecture and BER. The RP values indicate how much accuracy was recovered by NeuralFuse compared to the PA without NeuralFuse.
Full paper#