TL;DR#
Current diverse human motion prediction (HMP) models struggle with real-world scenarios, often producing unrealistic movements due to neglecting environmental factors. This paper tackles this problem by introducing a new task: predicting diverse human motion within real-world 3D scenes. This requires harmonizing the deterministic constraints imposed by the environment with the stochastic nature of human motion.
The paper proposes DiMoP3D, a novel framework that addresses this challenge by leveraging 3D scene awareness. DiMoP3D analyzes the 3D scene and observed motion to determine probable target objects, plan obstacle-free trajectories, and generate diverse and physically consistent predictions. Experimental results on real-world benchmarks demonstrate DiMoP3D’s superior performance compared to existing state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and challenging task of predicting diverse human motions within real-world 3D scenes, advancing beyond the traditional scope of diverse HMP. It proposes DiMoP3D, a novel framework that harmonizes the deterministic constraints of 3D scenes with the stochastic nature of human motion. This work opens new avenues for research in areas like autonomous driving, human-robot interaction, and virtual/augmented reality applications. DiMoP3D’s superior performance on benchmark datasets demonstrates its effectiveness and sets a new state-of-the-art.
Visual Insights#
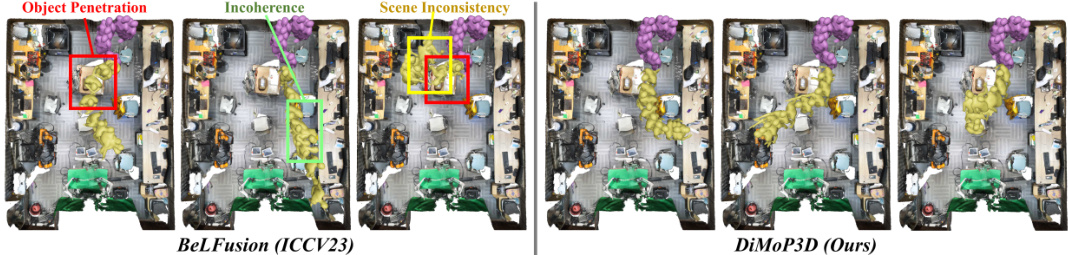
🔼 This figure compares the performance of the proposed DiMoP3D model against a state-of-the-art baseline (BeLFusion) for diverse human motion prediction in 3D scenes. The purple meshes represent the observed human motion, while the yellow meshes show the predicted motion from each model. DiMoP3D generates predictions that are more realistic, diverse and consistent with the surrounding environment, as opposed to BeLFusion, which suffers from issues such as object penetration, incoherent motion, and inconsistencies with the scene.
read the caption
Figure 1: Comparison of our DiMoP3D with the SoTA baseline [5]. Purple meshes represent observations, and yellow meshes denote predictions. DiMoP3D produces high-fidelity, diverse sequences tailored to real-world 3D scenes, while BeLFusion's inadequate scene context integration leads to issues such as object penetration, motion incoherence, and scene inconsistency.
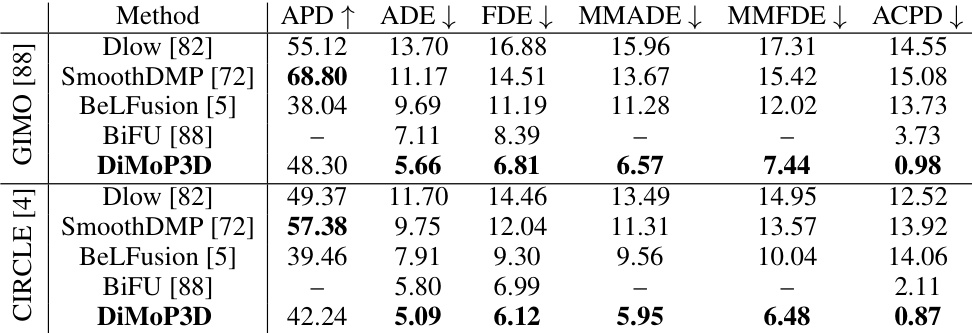
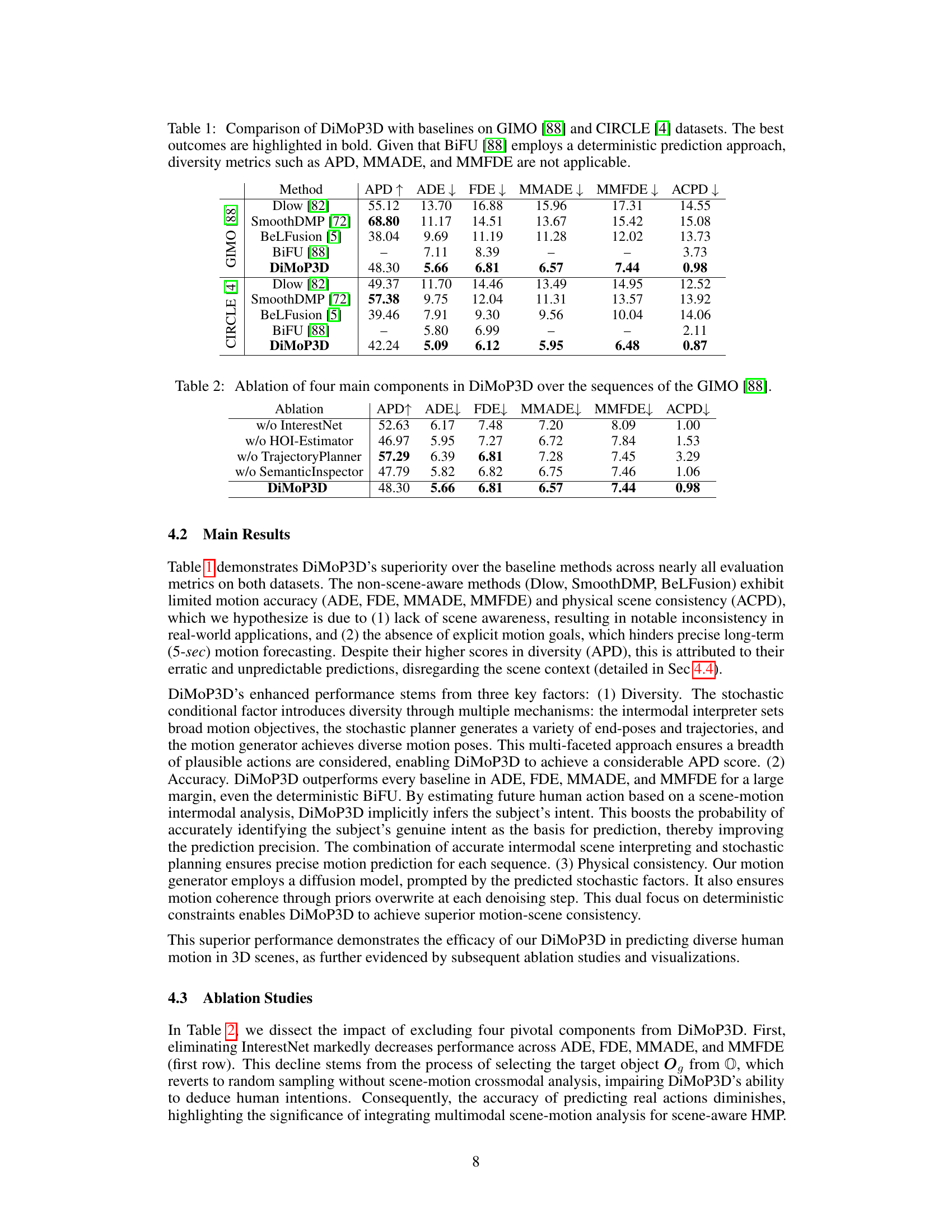
🔼 This table presents a comparison of the proposed DiMoP3D model’s performance against several baseline methods on two benchmark datasets, GIMO and CIRCLE. The evaluation metrics include accuracy (ADE, FDE, MMADE, MMFDE) and diversity (APD). The ACPD metric assesses the physical consistency of predictions in 3D scenes. Note that the diversity metrics are not applicable for BiFU, which is a deterministic model.
read the caption
Table 1: Comparison of DiMoP3D with baselines on GIMO [88] and CIRCLE [4] datasets. The best outcomes are highlighted in bold. Given that BiFU [88] employs a deterministic prediction approach, diversity metrics such as APD, MMADE, and MMFDE are not applicable.
In-depth insights#
Diverse HMP in 3D#
The concept of “Diverse HMP in 3D” signifies a significant advancement in human motion prediction. It moves beyond the limitations of traditional methods by acknowledging the stochastic nature of human movement while simultaneously considering the deterministic constraints imposed by the 3D environment. This necessitates a framework that can seamlessly integrate scene understanding, intermodal coordination (scene and motion data), and behavioral modeling to generate multiple plausible future motion trajectories. Success in this area would require overcoming several significant challenges. These include accurately interpreting human intentions from observed actions within a complex 3D scene, resolving intermodal ambiguities, and ensuring physical consistency (avoiding collisions, respecting object interactions) in generated predictions. Ultimately, a robust solution will be crucial for applications like autonomous vehicles, human-robot interaction, and virtual reality, where realistic and diverse human motion prediction is paramount.
DiMoP3D Framework#
The DiMoP3D framework, designed for diverse human motion prediction in 3D scenes, presents a novel approach by harmonizing stochasticity and determinism. Its core innovation lies in integrating 3D scene context (point clouds) with historical motion data to predict future movements. DiMoP3D cleverly addresses the challenges of diverse HMP by first using a context-aware intermodal interpreter to identify human intentions and potential interaction targets within the scene. A behaviorally-consistent stochastic planner then generates obstacle-free trajectories toward these targets, producing diverse and physically plausible results. Finally, a self-prompted motion generator, leveraging a diffusion model, produces the final motion predictions, conditioned on the planned trajectories and intended interaction. This unique combination of scene understanding, trajectory planning, and diffusion-based generation results in significantly improved accuracy, diversity, and physical consistency compared to state-of-the-art methods. The framework’s ability to learn and integrate deterministic scene constraints with stochastic motion patterns makes it particularly effective in real-world scenarios.
Scene-Aware HMP#
Scene-aware Human Motion Prediction (HMP) represents a significant advancement in the field, addressing limitations of previous methods. Traditional HMP models often fail to accurately predict human motion in complex, real-world environments because they neglect the influence of the surrounding scene. Scene-aware HMP seeks to rectify this by integrating scene context into the prediction process. This integration can involve various techniques, such as incorporating 3D scene representations (e.g., point clouds, RGB-D data) and object detection to understand the environment and its interaction with the human. By considering scene constraints, scene-aware HMP can generate more realistic and physically plausible predictions, avoiding unrealistic scenarios like humans passing through walls or objects. This approach improves the accuracy and robustness of motion predictions, enabling a wide range of applications in robotics, VR/AR, and autonomous driving. However, challenges remain in efficiently and effectively incorporating complex scene information into motion models and handling the inherent stochasticity and variability of human movement within diverse scenes. Future research is needed to develop robust and scalable methods for real-time scene-aware HMP.
Ablation Experiments#
Ablation experiments systematically remove components of a model to assess their individual contributions. Thoughtful design is crucial; removing too many parts at once obscures the impact of individual elements. Results should be carefully analyzed, considering not just performance metrics but also qualitative aspects, like the type of errors produced. For example, removing a specific module might improve accuracy on a certain type of data while harming performance on others, highlighting that module’s specific role. A good ablation study rigorously isolates and evaluates each component and explains the results’ implications for the overall model’s architecture and functionality. It helps understand which parts are crucial to the model’s success, paving the way for improved designs and a deeper understanding of the model itself. The insights gained inform decisions about model simplification or enhancement. Ultimately, well-executed ablation experiments provide invaluable insights into model architecture, enabling researchers to refine designs for enhanced performance and efficiency.
Future of DiMoP3D#
The future of DiMoP3D lies in addressing its current limitations and expanding its capabilities. Improving the accuracy and robustness of 3D scene understanding is crucial, especially in complex and cluttered environments. This could involve incorporating more sophisticated scene parsing techniques or leveraging advanced sensor modalities. Enhancing the model’s ability to handle longer temporal horizons and incorporate more diverse human behaviours will be essential to improve prediction realism. Furthermore, investigating the potential of integrating language models could unlock more nuanced scene comprehension, leading to more context-aware and believable human motion predictions. Finally, exploring applications in areas such as human-robot interaction, virtual reality, and autonomous driving will be critical to demonstrating DiMoP3D’s real-world impact.
More visual insights#
More on figures
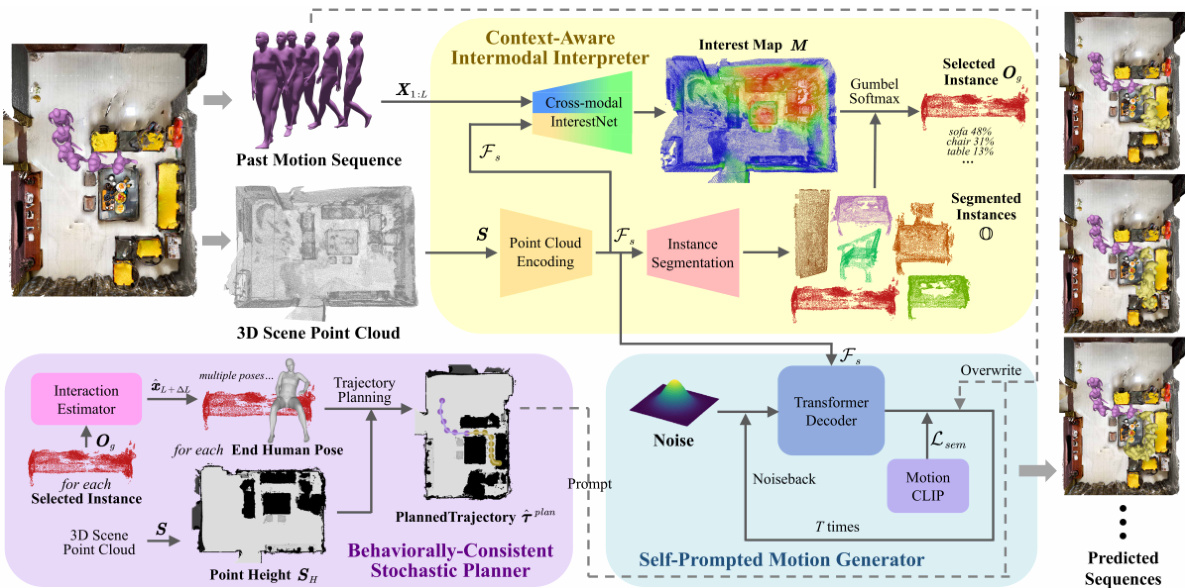
🔼 This figure illustrates the architecture of the DiMoP3D model, which takes past human motion and a 3D scene point cloud as input. It shows how the model processes this information through three main components: Context-aware Intermodal Interpreter, Behaviorally-Consistent Stochastic Planner, and Self-Prompted Motion Generator. The first component identifies potential interaction targets within the scene. The second component plans obstacle-free trajectories to those targets. Finally, the third component generates diverse and physically consistent future motion predictions conditioned on the planned trajectory and target.
read the caption
Figure 2: The architecture of DiMoP3D. DiMoP3D incorporates two modalities of input, the past motion and the 3D scene point cloud. Initially, the Context-aware Intermodal Interpreter encodes the point cloud to features Fs, identifies interactive objects O, and uses a cross-modal InterestNet to pinpoint potential interest areas, sampling a target instance Og according to interest map M. Following this, the Behaviorally-consistent Stochastic Planner forecasts the interactive human end-pose L+∆L, and devises an obstacle-free trajectory plan towards this pose. The sampled end-pose and trajectory are incorporated as a stochastic conditional factor to prompt the Self-prompted Motion Generator to generate physically consistent future motions.
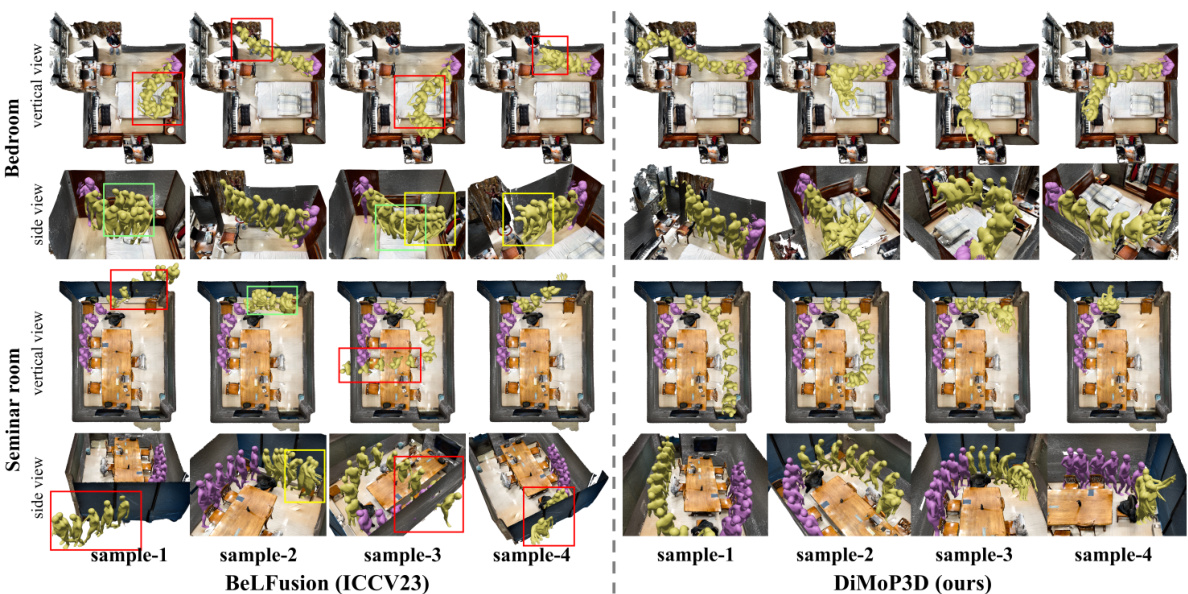
🔼 This figure compares the motion prediction results of DiMoP3D and BeLFusion, a state-of-the-art method. The left side shows BeLFusion’s predictions, highlighting issues like object penetration, motion incoherence, and scene inconsistency because it doesn’t consider the 3D scene context. The right side displays DiMoP3D’s results, demonstrating accurate and physically plausible motion predictions with obstacle avoidance and consideration for interactive goals within the 3D scene.
read the caption
Figure 3: Visual comparisons between DiMoP3D and SoTA BeLFusion in bedroom and seminar room scenarios. BeLFusion's predictions, which rely solely on past human motion without considering 3D scene context, are shown on the left. In contrast, DiMoP3D, displayed on the right, incorporates interactive goals and designs obstacle-free trajectories for each sequence. Purple meshes depict observed motions, while yellow ones signify predicted future motions. For clarity, distortions in BeLFusion's predictions are marked: red boxes for object penetration, green boxes for motion incoherence, and yellow boxes for scene inconsistency.
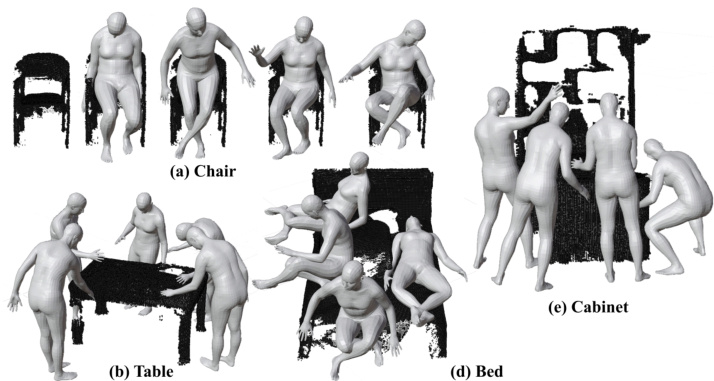
🔼 This figure visualizes the diverse end poses generated by the HOI-Estimator for five different object types: chair, table, bed, cabinet, and another object. It shows how the model predicts various plausible interactions between humans and objects in 3D scenes, illustrating the model’s ability to produce diverse and contextually appropriate human poses in different scenarios.
read the caption
Figure 4: Visualizations of diverse predicted end-poses across five object point clouds. The HOI-Estimator can generate a variety of human-object interactive poses tailored to specific scenarios.

🔼 This figure visualizes the paths generated by the modified A* trajectory planner. It shows three examples of trajectories planned from a starting point to a destination point in a 3D environment. The black lines represent the observed trajectory while the colored lines represent the planned trajectories. The planner is designed to generate diverse and obstacle-free paths between the points. The figure highlights the ability of the modified A* algorithm to find multiple valid paths that avoid obstacles in complex environments.
read the caption
Figure 5: Visualization samples of the modified A* trajectory planner. Black lines denote the observed trajectory, while colored lines represent the generated paths.

🔼 This figure shows the results of 3D scene instance segmentation and interest map prediction. The upper part shows the instance segmentation results for three different scenes (bedroom, living room, and laboratory), color-coded for different objects. The lower part shows the predicted interest map for each scene. The color intensity represents the level of human interest in that area, with red indicating high interest and blue indicating low interest. This method helps identify the probable target object for motion prediction.
read the caption
Figure 6: Visualization of 3D scene instance segmentation (upper) and the corresponding interest map (lower). Red points in the interest map denote higher interest, while blue points denote lower interest. Leveraging the insight provided by the predicted interest map enables the exclusion of improbable or illogical targets, thereby enhancing the reliability and scene congruency of predictions.

🔼 This figure compares the motion predictions of DiMoP3D and BeLFusion in two different scenarios: a bedroom and a seminar room. DiMoP3D uses 3D scene context to generate diverse and physically realistic motion predictions, while BeLFusion, which only uses past motion data, produces unrealistic predictions with issues such as object penetration, motion incoherence, and scene inconsistency. The figure highlights the advantages of incorporating 3D scene information into motion prediction.
read the caption
Figure 3: Visual comparisons between DiMoP3D and SoTA BeLFusion in bedroom and seminar room scenarios. BeLFusion's predictions, which rely solely on past human motion without considering 3D scene context, are shown on the left. In contrast, DiMoP3D, displayed on the right, incorporates interactive goals and designs obstacle-free trajectories for each sequence. Purple meshes depict observed motions, while yellow ones signify predicted future motions. For clarity, distortions in BeLFusion's predictions are marked: red boxes for object penetration, green boxes for motion incoherence, and yellow boxes for scene inconsistency.

🔼 This figure compares the motion predictions of DiMoP3D and BeLFusion in two different scenarios: a bedroom and a seminar room. BeLFusion, a state-of-the-art method that doesn’t consider the 3D scene context, produces predictions with artifacts such as object penetration, motion incoherence, and scene inconsistency. In contrast, DiMoP3D generates high-fidelity predictions with diverse and physically consistent motion trajectories that avoid obstacles and interact naturally with the scene.
read the caption
Figure 3: Visual comparisons between DiMoP3D and SoTA BeLFusion in bedroom and seminar room scenarios. BeLFusion's predictions, which rely solely on past human motion without considering 3D scene context, are shown on the left. In contrast, DiMoP3D, displayed on the right, incorporates interactive goals and designs obstacle-free trajectories for each sequence. Purple meshes depict observed motions, while yellow ones signify predicted future motions. For clarity, distortions in BeLFusion's predictions are marked: red boxes for object penetration, green boxes for motion incoherence, and yellow boxes for scene inconsistency.
More on tables
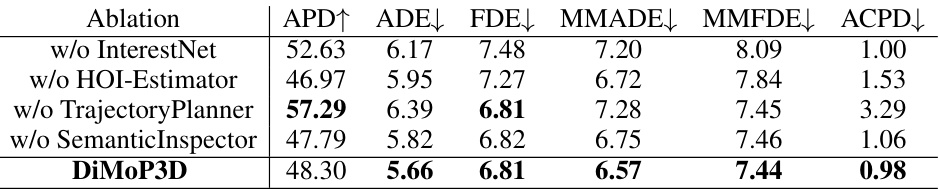
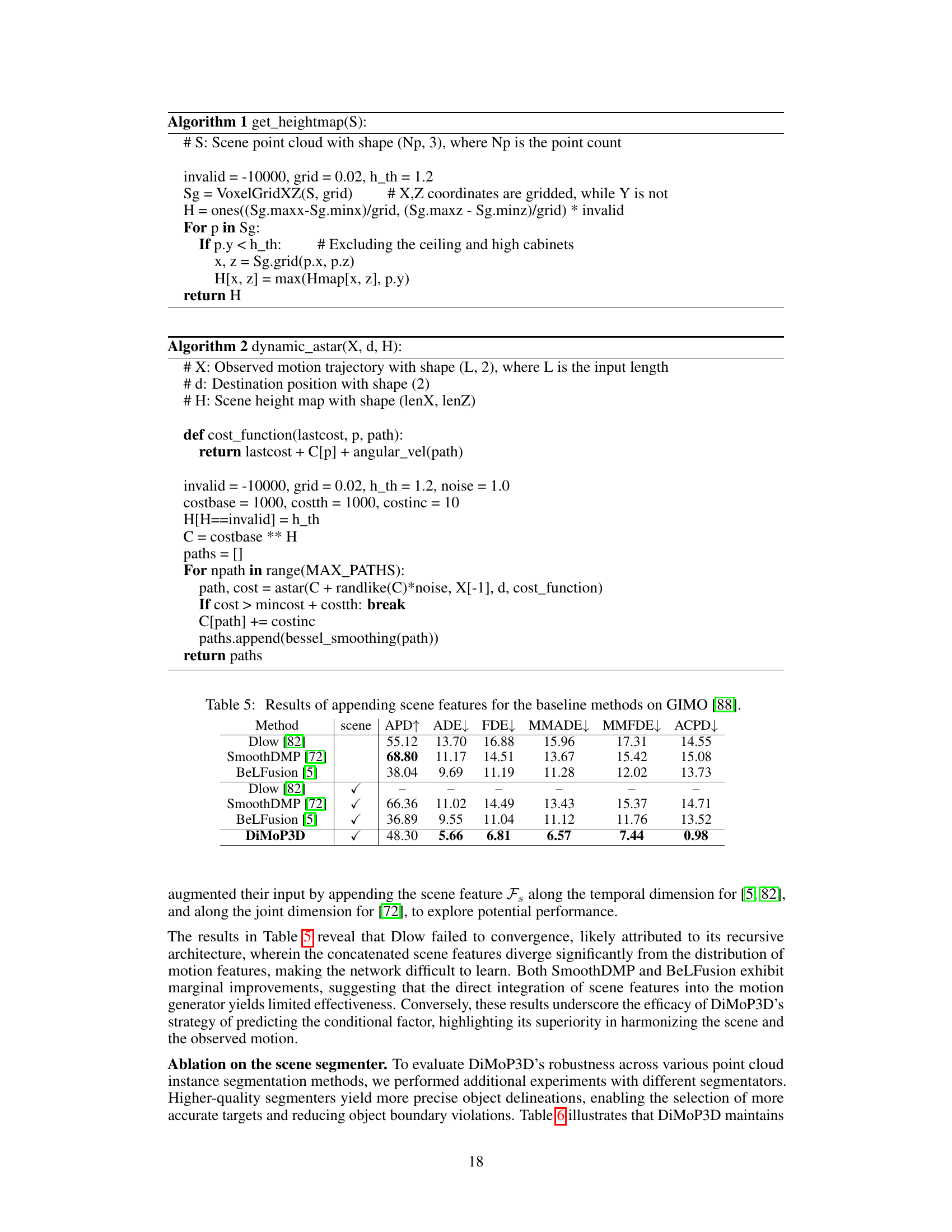
🔼 This table presents the ablation study results for the DiMoP3D model on the GIMO dataset. It shows the impact of removing each of the four main components: InterestNet, HOI-Estimator, TrajectoryPlanner, and SemanticInspector on the performance metrics: APD (Average Pairwise Distance), ADE (Average Displacement Error), FDE (Final Displacement Error), MMADE (Multimodal Average Displacement Error), MMFDE (Multimodal Final Displacement Error), and ACPD (Average Cumulated Penetration Depth). The results demonstrate the contribution of each component to the overall performance of the DiMoP3D model in terms of diversity, accuracy, and physical consistency.
read the caption
Table 2: Ablation of four main components in DiMoP3D over the sequences of the GIMO [88].

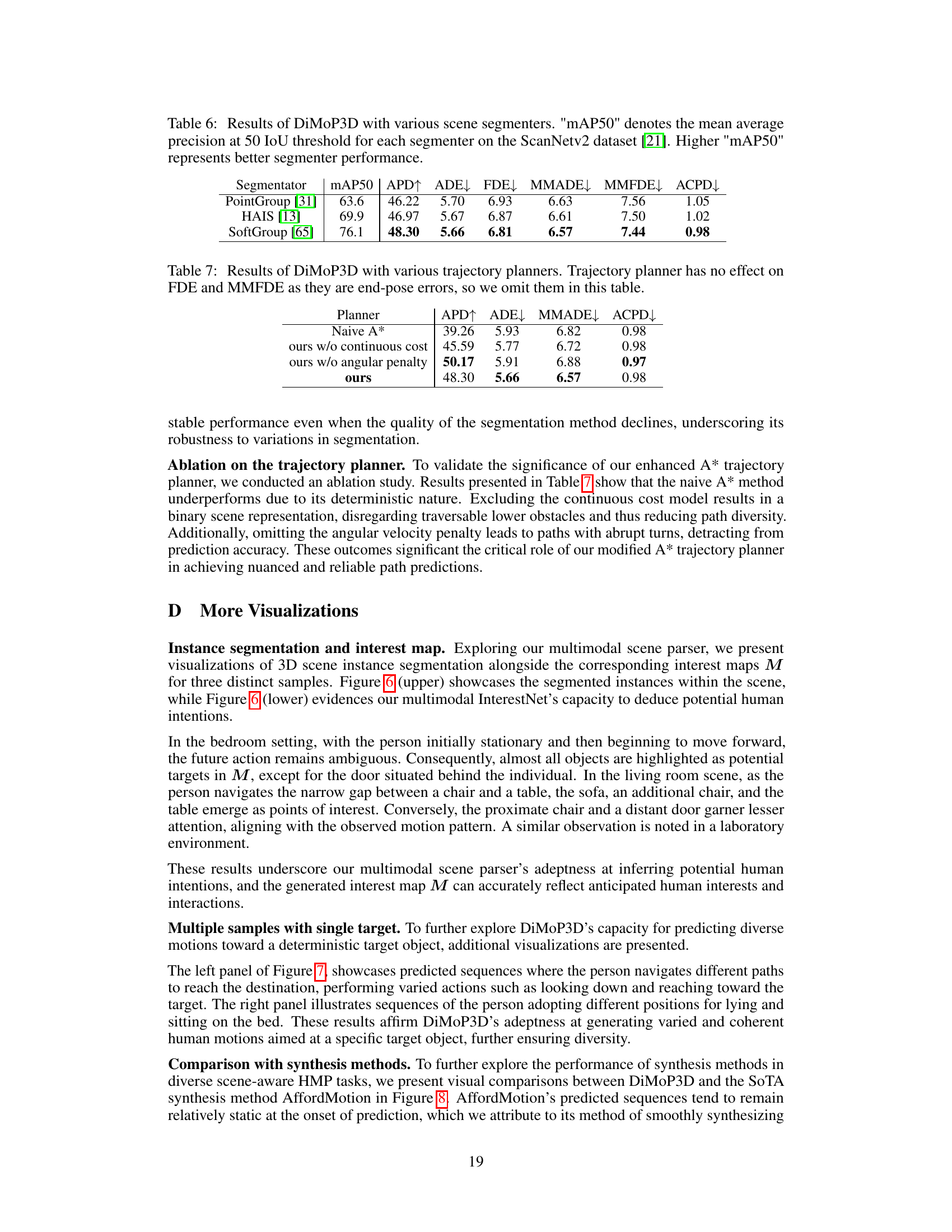
🔼 This table compares the performance of DiMoP3D against three other scene-aware motion synthesis methods: SAMP, DN-Synt, and AffordMotion. The comparison uses several metrics to evaluate both the diversity and accuracy of the motion prediction, including Average Pairwise Distance (APD), Average Displacement Error (ADE), Final Displacement Error (FDE), Multimodal Average Displacement Error (MMADE), Multimodal Final Displacement Error (MMFDE), Fréchet Inception Distance (FID), and Average Cumulated Penetration Depth (ACPD). Lower values for ADE, FDE, MMADE, MMFDE, and ACPD indicate better performance, while higher APD indicates greater diversity. Lower FID suggests the generated motion is closer to the real motion in terms of distribution.
read the caption
Table 3: Comparison of DiMoP3D with scene-aware motion synthesis methods.
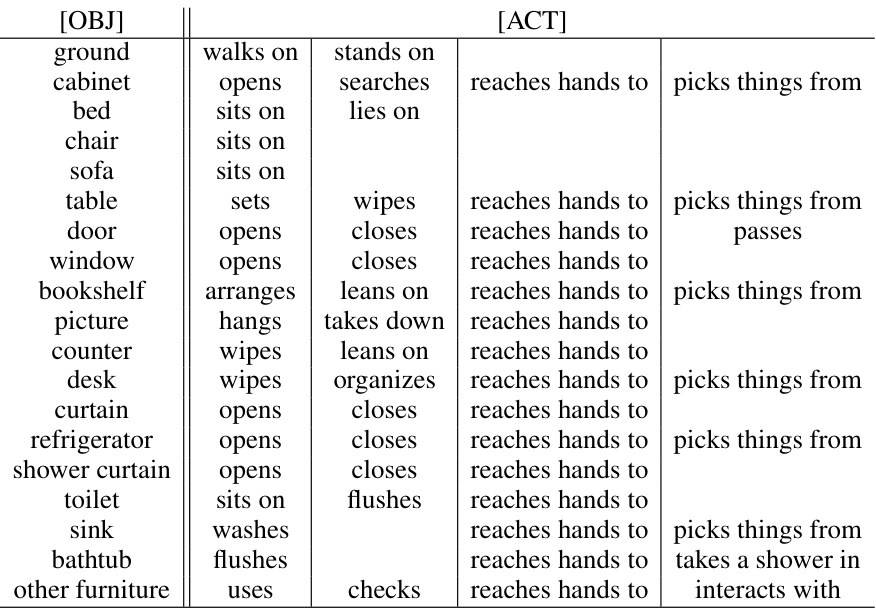
🔼 This table presents a template for describing the semantic interaction between a human and various objects in the ScanNet dataset, aiming to enhance the accuracy and diversity of human motion prediction. Each row represents an object (e.g., ground, cabinet, bed, etc.), and multiple action verbs are listed for each object, indicating possible actions or interactions that a human might perform with that specific object. This template is used in the DiMoP3D model to generate more contextually relevant and diverse human motion predictions.
read the caption
Table 4: Description template of semantic inspector among 18 objects in the ScanNet dataset [21].
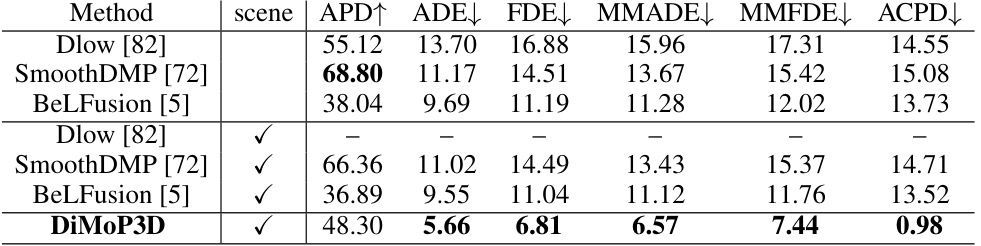
🔼 This table presents a comparison of the proposed DiMoP3D model with several baseline methods on two datasets, GIMO and CIRCLE. The metrics used evaluate prediction accuracy (ADE, FDE, MMADE, MMFDE), diversity (APD), and physical consistency (ACPD). DiMoP3D demonstrates superior performance across most metrics, particularly in accuracy and physical consistency. The diversity metrics are not applicable to BiFU due to its deterministic nature.
read the caption
Table 1: Comparison of DiMoP3D with baselines on GIMO [88] and CIRCLE [4] datasets. The best outcomes are highlighted in bold. Given that BiFU [88] employs a deterministic prediction approach, diversity metrics such as APD, MMADE, and MMFDE are not applicable.

🔼 This table presents the ablation study of different scene segmenters used in DiMoP3D. It shows the impact of the segmenter’s performance (measured by mean average precision at 50% Intersection over Union or mAP50 on the ScanNetv2 dataset) on DiMoP3D’s overall performance. The metrics used to evaluate the performance include Average Pairwise Distance (APD), Average Displacement Error (ADE), Final Displacement Error (FDE), Multimodal Average Displacement Error (MMADE), Multimodal Final Displacement Error (MMFDE), and Average Cumulated Penetration Depth (ACPD).
read the caption
Table 6: Results of DiMoP3D with various scene segmenters. 'mAP50' denotes the mean average precision at 50 IoU threshold for each segmenter on the ScanNetv2 dataset [21]. Higher 'mAP50' represents better segmenter performance.
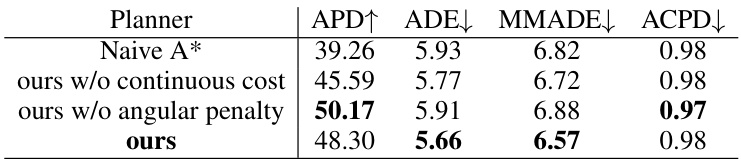
🔼 This table presents the ablation study of four main components of the DiMoP3D model on the GIMO dataset. It shows the impact of removing each component on the model’s performance in terms of APD, ADE, MMADE, and ACPD. The results demonstrate the importance of each component for achieving high accuracy and diversity in motion prediction.
read the caption
Table 7: Ablation of four main components in DiMoP3D over the sequences of the GIMO [88].
Full paper#