↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Multimodal Large Language Models (MLLMs) are increasingly used but suffer from a critical problem: ’text-only forgetting’. Existing MLLMs, trained initially on text-only instructions, lose this capability after incorporating visual information. This significantly limits their application in real-world scenarios requiring mixed-modality interactions, like conversational AI that can handle image and text. This is a significant challenge, demanding more research efforts to maintain the performance of LLMs in various modalities.
The paper introduces WINGS, a novel MLLM architecture to solve the ’text-only forgetting’ issue. WINGS uses an additional low-rank residual attention (LoRRA) block that acts as a ‘modality learner’, effectively expanding the learning space and compensating for attention shifts that cause forgetting. Experimental results demonstrate that WINGS outperforms other MLLMs in text-only and visual question answering tasks. A new benchmark, Interleaved Image-Text (IIT), was also created for better evaluation of MLLMs in multi-turn, mixed-modality scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multimodal large language models (MLLMs). It addresses the significant issue of text-only forgetting, where MLLMs lose their ability to handle text-only instructions after visual data integration. The proposed solution, WINGS, offers a novel architectural approach that can be widely applied to improve MLLMs’ robustness and versatility, impacting research on efficient training and multimodal learning. The Interleaved Image-Text (IIT) benchmark introduced also contributes to the field by offering a more realistic evaluation setting.
Visual Insights#

This figure shows examples of interactions with a multimodal large language model (MLLM) using text-only, interleaved image-text, and multimodal instructions. It also includes a comparison chart showcasing the performance of WINGS against LLaVA-Next and DeepSeek-VL across various text-only and multimodal question answering benchmarks. The dark green color highlights the superior performance of WINGS in both text-only and multimodal settings.
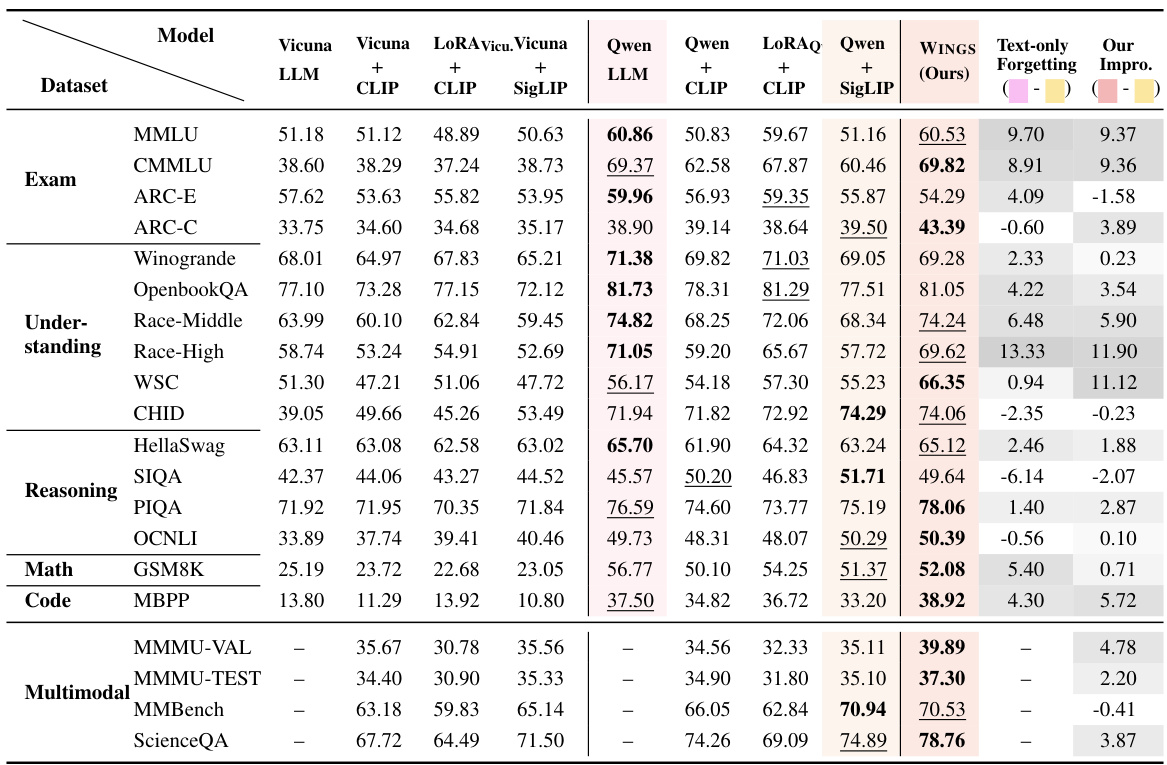
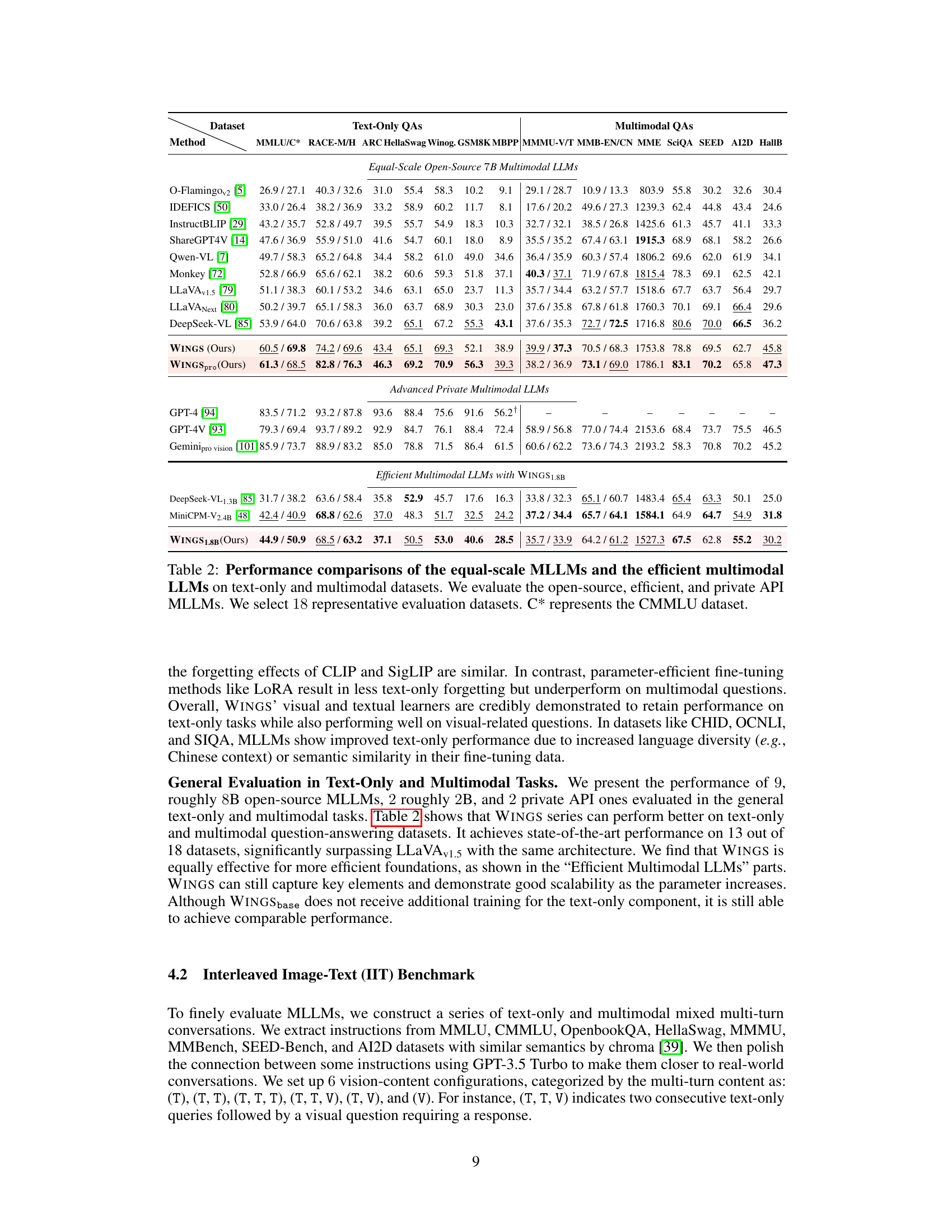
This table presents a comparison of WINGS’ performance against eight baseline multimodal large language models (MLLMs). The baselines vary in their underlying LLM (Vicuna or Qwen), visual encoder (CLIP or SigLIP), and fine-tuning method (full parameter or LoRA). The table evaluates performance across 20 datasets spanning six domains (Exam, Understanding, Reasoning, Math, Code, and Multimodal). The ‘Our Improvement’ column shows how much WINGS outperforms its corresponding baseline MLLM using the same underlying LLM and visual encoder.
In-depth insights#
Multimodal LLM woes#
Multimodal LLMs, while demonstrating impressive capabilities, suffer from significant drawbacks. A primary concern is catastrophic forgetting, where the model loses its proficiency in text-only tasks after being fine-tuned on multimodal data. This is a critical limitation as many real-world applications require seamless transitions between text-only and multimodal inputs. Furthermore, the computational cost of training and deploying these models is substantial, often exceeding the resources of many researchers and institutions. Data scarcity for multimodal tasks remains a challenge, limiting the potential for robust and generalizable performance. Another issue lies in the evaluation methodologies, which can be inconsistent across different benchmarks, making comparisons difficult and hindering the development of truly robust models. Finally, the problem of attention shift, where the model disproportionately focuses on visual information at the expense of textual context, impacts the accuracy and reliability of the model’s overall reasoning capabilities. Addressing these multimodal LLM woes requires further research into robust training methodologies, efficient architectures, and standardized evaluation practices.
WINGS Architecture#
The WINGS architecture is designed to address the issue of text-only forgetting in multimodal LLMs. It achieves this by introducing parallel modality-specific learners: visual learners that focus on visual features and textual learners that attend to textual information. These learners, operating alongside the main attention mechanism, prevent the catastrophic forgetting that occurs when visual information overshadows text. Low-Rank Residual Attention (LoRRA) blocks form the core of these learners, ensuring computational efficiency. A crucial element is the token-wise routing mechanism, which dynamically weights the outputs of the visual and textual learners, blending them collaboratively based on attention shifts in the main branch. This collaborative approach ensures that the model effectively processes both text-only and multimodal instructions, preserving the text-only knowledge learned from the pre-trained LLM while expanding the model’s capacity for handling visual information. The overall architecture resembles a bird with wings (hence ‘WINGS’), emphasizing the parallel and complementary nature of the visual and textual learners to enhance multimodal understanding.
Attention Shift Analysis#
The analysis of attention shifts in multimodal large language models (MLLMs) is crucial for understanding the phenomenon of “text-only forgetting.” Attention shift analysis would involve examining how the model’s attention mechanism changes across different layers as it processes both textual and visual information. A key aspect would be comparing attention weights on text tokens before and after the insertion of visual tokens. A significant shift away from pre-image text towards post-image text suggests a potential cause for the model’s impaired performance on text-only tasks after multimodal training. Quantifying this attention shift might involve calculating metrics such as the difference or ratio of attention weights before and after the visual input at each layer, potentially comparing these shifts across models of different architectures and training data. Beyond simple metrics, a qualitative analysis of the attention patterns could reveal insightful relationships between attention focus and performance degradation. By identifying the specific layers and attention heads most affected by visual input, we can pinpoint areas needing architectural modification to mitigate the issue, leading to more robust models handling both text-only and multimodal instructions effectively. This deep dive would thus reveal crucial insights into MLLM behavior and guide strategies for improving their capabilities.
IIT Benchmark Results#
The IIT (Interleaved Image-Text) benchmark results are crucial for evaluating the model’s ability to handle real-world, multi-modal conversations. The benchmark’s design, incorporating multi-turn interactions with varying image relevance, allows for a more nuanced assessment than traditional benchmarks which often focus on single-turn question-answering. The performance on IIT likely reveals the model’s strength in integrating visual and textual information dynamically, demonstrating its ability to maintain context across multiple turns. Strong performance suggests a robust attention mechanism capable of shifting focus between visual and textual cues as needed, while poor performance may indicate limitations in context maintenance, visual reasoning, or cross-modal alignment. A detailed analysis of these results, broken down by the type and number of visual inputs and the complexity of the conversation, would offer valuable insights into the model’s capabilities and potential limitations. Comparing performance on IIT to other benchmarks will help contextualize the model’s overall strengths and weaknesses. The IIT results, therefore, are pivotal in showcasing the real-world applicability of the multimodal large language model.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending WINGS to encompass diverse modalities beyond vision and text, such as audio or other sensor data, would significantly broaden its applicability. Investigating alternative attention mechanisms or router designs could improve efficiency and address potential limitations in current design choices. Developing a more comprehensive benchmark that accounts for nuanced aspects of real-world interaction would enhance future MLLM evaluation. A focus on making WINGS more robust to noisy or incomplete data, and exploring techniques to mitigate catastrophic forgetting in more complex scenarios, is needed. Finally, thorough investigation into potential ethical implications of multimodal LLMs and the development of safeguards against misuse is crucial for responsible deployment.
More visual insights#
More on figures
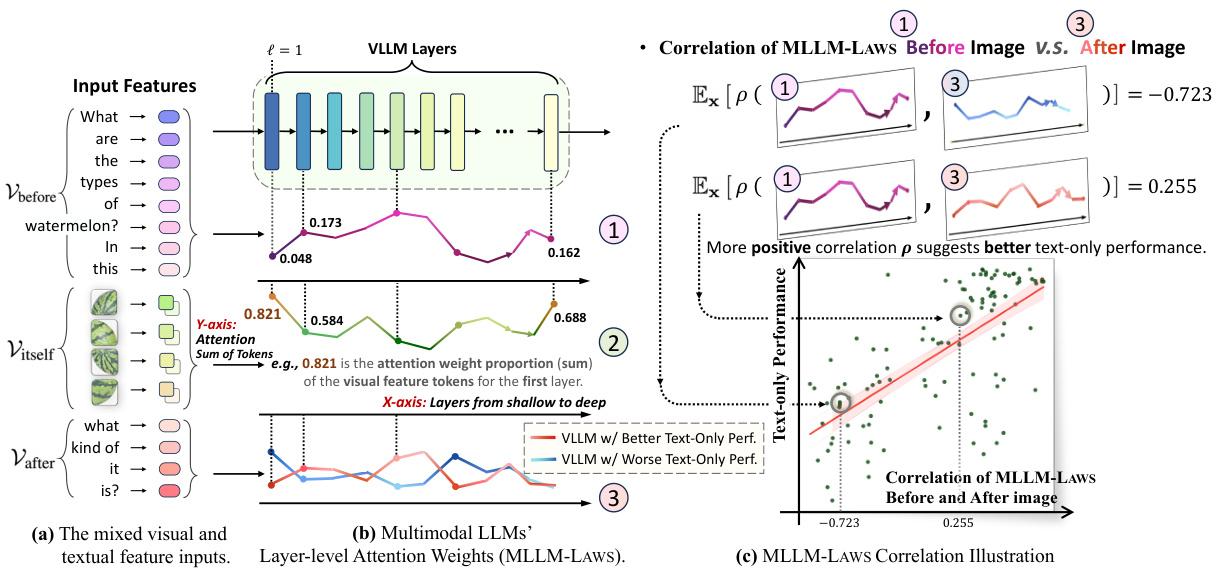
This figure illustrates how visual input tokens are inserted into a sequence of textual tokens in a multimodal large language model (MLLM). It shows the attention weight distribution across layers for both high-performing and low-performing models, revealing a correlation between attention shifts and text-only performance degradation. Panel (a) shows the input structure; (b) compares the attention weights (MLLM-LAWS) across layers for models with good vs. poor text-only performance; (c) shows a positive correlation between the attention shift and performance degradation.

The figure shows the architecture of the WINGS model. It illustrates how visual and textual learners are added in parallel to the main attention blocks of each layer in the model. These learners are designed to compensate for the attention shift observed when visual information is introduced, preventing the model from forgetting its ability to handle text-only instructions. The visual learners operate first, focusing on visual features and aligning them with textual features. Then, textual learners are incorporated, with a router distributing the outputs of both visual and textual learners based on their attention weights, enabling collaborative learning. The Low-Rank Residual Attention (LoRRA) architecture is used for both the visual and textual learners to ensure efficiency.

This figure illustrates the architecture of the WINGS model and its training process. Panel (a) shows a detailed breakdown of the Low-Rank Residual Attention (LoRRA) module, which is a core component of WINGS. It explains how the visual and textual features interact with the hidden states through a multi-head self-attention mechanism, ultimately leading to a balanced output. Panel (b) outlines the two-stage training paradigm. The first stage focuses on aligning the projector and learning visual features, while the second stage fine-tunes the LLM by incorporating visual and textual learners, which dynamically route attention based on the importance of the various feature inputs.
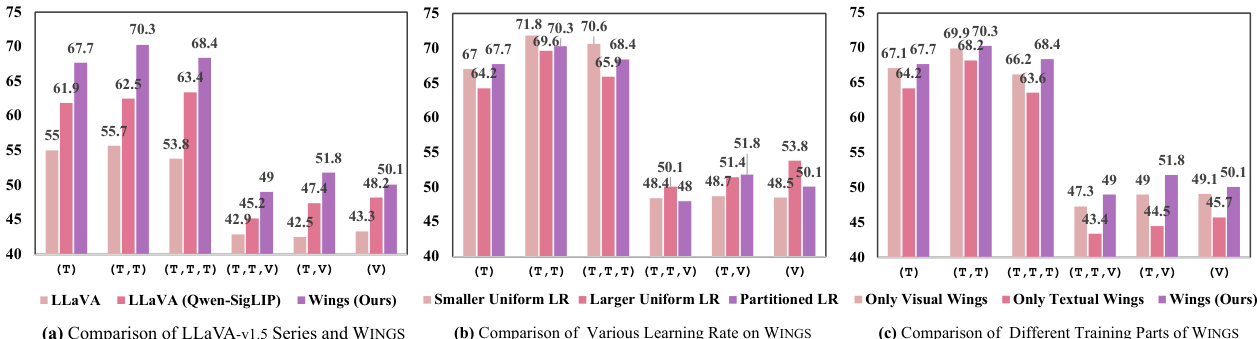
This figure presents a comparative analysis of the performance of different models and training approaches on the newly created Interleaved Image-Text (IIT) benchmark. The IIT benchmark consists of multi-turn conversations combining both text-only and multimodal instructions, testing the models’ ability to handle various combinations of textual and visual information. The figure showcases performance across different multimodal question settings, comparing the WINGS model to the LLaVA series. Further, it demonstrates the impact of different learning rate strategies and training configurations (such as using only visual learners, only textual learners, or both) on WINGS’s performance. The violet bars consistently highlight the WINGS model’s superior performance across the different settings.
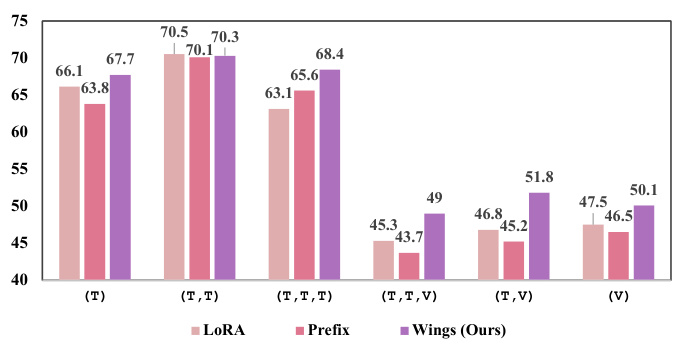
This figure compares the performance of WINGS against other models (LLaVA, LoRA, Prefix) on a new benchmark called IIT (Interleaved Image-Text). The IIT benchmark tests the models’ ability to handle conversations that interleave text-only questions with multimodal questions (i.e., those including images). The three subplots show ablation studies: (a) compares WINGS to variants of LLaVA; (b) compares WINGS trained with different learning rates; (c) compares WINGS trained with different combinations of visual and textual learners. The results demonstrate that WINGS achieves superior performance in handling mixed modality conversations, especially when compared to simpler approaches like LoRA and Prefix-tuning.
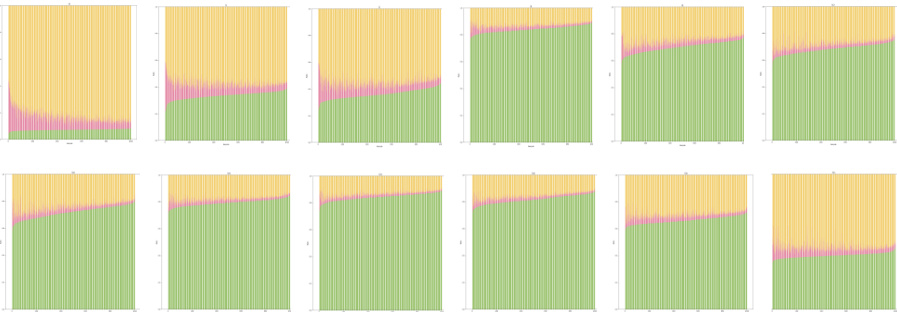
This figure illustrates how visual input tokens are integrated into textual sequences and the resulting attention weight distribution across different layers of a Multimodal Large Language Model (MLLM). Panel (a) shows the integration of visual features into the text sequence. Panel (b) presents the dynamic change of attention weights across layers for both high and low performing models on text-only tasks before and after visual token insertions. The red line corresponds to high performing models, while blue is for lower performing models. Finally, panel (c) shows the correlation between the attention shift, measured by the difference in attention weights before and after visual tokens, and the performance on text-only tasks for over 100 models, demonstrating the correlation between attention shift and text-only forgetting in MLLMs.

This figure illustrates how visual input tokens are integrated into textual sequences in MLLMs and analyzes the impact on attention weights. Part (a) shows the structure of mixed visual and textual input features. Part (b) displays the attention weight distribution across layers for two different MLLMs (one with good text-only performance and one with poor text-only performance), highlighting the attention shift after image insertion. Part (c) shows the positive correlation between the attention shift (measured by Layer-level Attention Weights or MLLM-LAWS) and the decline in text-only performance across numerous MLLMs.
Full paper#