↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep learning models heavily rely on tensor multiplication, which becomes computationally expensive for large models. Existing methods to address this either compromise accuracy or lack hardware efficiency. This paper introduces Sketch Structured Transform (SS1), an operator that enhances both expressivity and GPU efficiency.
SS1 achieves this by implementing random yet structured parameter sharing. This method, coupled with quantization, allows for significant speed-ups while maintaining or even improving model accuracy. Experiments show that the approach works well when training models from scratch and also when fine-tuning existing models, resulting in faster inference without significant performance loss. SS1 showcases better quality-efficiency tradeoffs than existing methods, providing a practical solution to the challenges of efficient inference in deep learning.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient deep learning. It directly addresses the critical need for faster inference, a major bottleneck in deploying large models. The proposed method, SS1, offers a novel approach to improving quality-efficiency trade-offs, opening avenues for further research into efficient model compression techniques and hardware-aware optimization.
Visual Insights#

This figure illustrates the weight tying mechanism used in the Sketch Structured Transform (SS1) method. The left panel shows how weights within a group are tied together using a hash function, resulting in a rotation of the weights. The right panel demonstrates the K-coalescing (sharing parameter chunks) and N-coalescing (sharing the same hash function) techniques used in SS1 to enhance GPU-friendliness. This structured parameter sharing allows SS1 to reduce computations while maintaining expressiveness. Same-colored weights indicate that they are shared and point to the same parameter location in memory.
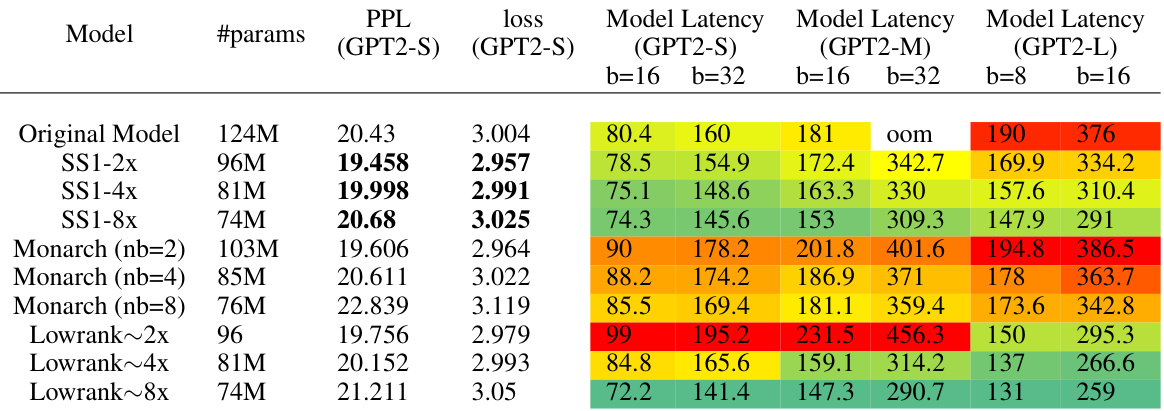
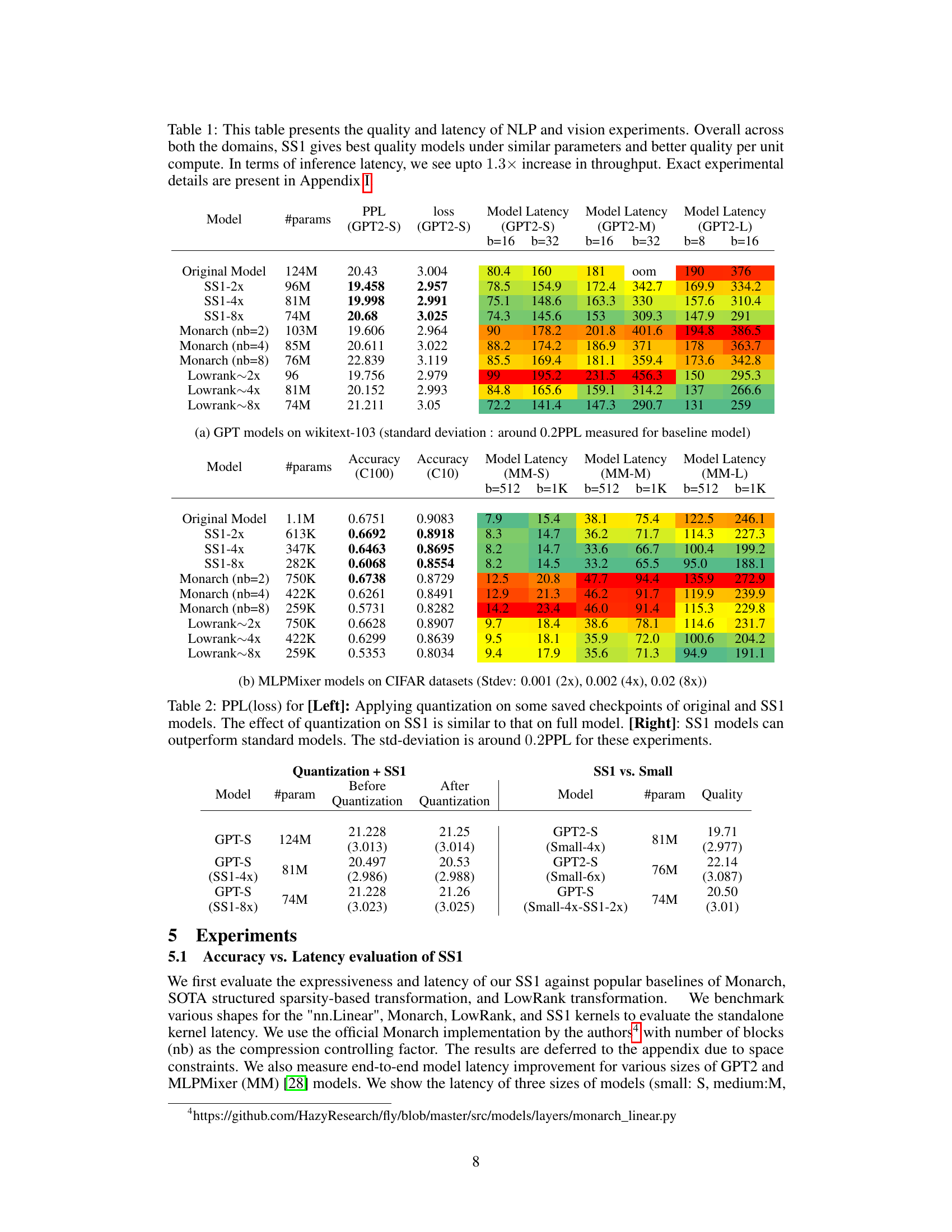
This table presents the results of NLP and vision experiments comparing the quality and latency of different models: original, SS1 (with different compression rates), Monarch (with different numbers of blocks), and LowRank (with different compression rates). It shows that across different model sizes and tasks, SS1 generally offers better quality-efficiency tradeoffs than the compared methods, and achieves significantly faster inference throughput. Detailed experiment setups are available in the Appendix I.
In-depth insights#
SS1: Quality-Efficiency#
The heading “SS1: Quality-Efficiency” suggests an analysis of the trade-off between model performance (quality) and computational resources (efficiency) for the proposed Sketch Structured Transform (SS1). A comprehensive exploration would involve comparing SS1’s performance metrics (e.g., accuracy, perplexity, inference speed) against other methods across various model architectures and datasets. Key aspects to consider are parameter count, FLOPs, and latency. The analysis should delve into whether SS1 achieves superior quality-efficiency trade-offs compared to unstructured sparsity, structured sparsity, and low-rank methods. A strong analysis would quantify these trade-offs, potentially using Pareto efficiency curves or similar visualization techniques. Furthermore, it should address if the gains are consistent across different model sizes, datasets, and tasks, and discuss the potential limitations or areas where SS1 may not provide substantial benefits. Finally, the exploration needs to justify the claims made with both empirical evidence and a theoretical understanding of the method’s underlying mechanisms.
SS1 Projection#
SS1 Projection, as a method, presents a powerful technique for efficient model deployment. It leverages a projection function to map the weights of a pre-trained model onto a lower-dimensional SS1-structured space. This projection drastically reduces computational costs during inference, making it highly suitable for resource-constrained environments. The process cleverly combines random yet structured weight-tying to maintain model expressiveness. A key advantage is that pre-trained models can be directly projected, sometimes performing reasonably well without further finetuning. This eliminates the need for retraining the entire model from scratch, saving time and resources. The success of SS1 Projection rests on carefully balancing expressivity and efficiency, where random parameter sharing helps reduce the computational complexity, while the structured approach ensures compatibility with hardware acceleration. This combination of methods, therefore, results in a faster inference model with negligible loss in accuracy.
SS1 and Quantization#
The combination of SS1 and quantization presents a compelling approach to model optimization. SS1, a novel structured random parameter sharing method, already offers improvements in quality-efficiency tradeoffs by reducing computation. Combining SS1 with quantization further enhances efficiency gains, exceeding the performance attainable by either method alone. This synergy is supported by theoretical analysis, demonstrating that the variance of the combined approach is less than the sum of individual variances, particularly effective in low to medium compression regimes. SS1’s structured sparsity complements quantization’s precision reduction, resulting in a powerful combination for accelerating inference without substantial accuracy loss. This is validated by empirical results showing improved quality-efficiency trade-offs, with significant latency reductions in various deep learning models and promising results in large language models. The integration of SS1 and quantization is particularly impactful for computationally intensive layers, yielding noticeable speedups and potentially alleviating computational bottlenecks in resource-constrained environments.
SS1: GPU-Friendly#
The heading ‘SS1: GPU-Friendly’ suggests a focus on the efficiency and performance of the Sketch Structured Transform (SS1) algorithm on Graphics Processing Units (GPUs). A thoughtful analysis would explore how SS1’s design facilitates GPU acceleration. This likely involves techniques like data parallelism and memory optimization, exploiting the massively parallel architecture of GPUs. The discussion would delve into the specific implementation details to highlight how SS1 leverages GPU features to minimize computational overhead and maximize throughput. A key aspect would be comparing SS1’s GPU performance against existing methods, demonstrating its superiority in terms of speed and energy efficiency. This would involve presenting benchmarks and discussing scalability for large models. Finally, a critical analysis would examine limitations and potential improvements, considering aspects like memory bandwidth constraints and algorithm complexity. The overall goal is to show not just that SS1 is GPU-friendly but why it is and how this advantage contributes to the overall goals of efficient deep learning inference.
SS1 Limitations#
The Sketch Structured Transform (SS1) demonstrates promising results in accelerating inference, but several limitations warrant consideration. Computational gains are marginal beyond 8x compression, suggesting limited scalability for extremely large models. The theoretical analysis, while insightful, primarily focuses on linear models and may not fully generalize to the complexities of deep learning architectures. GPU-friendliness is achieved through specific hash functions and coalescing strategies, potentially limiting flexibility and adaptability to diverse hardware. While SS1 combines effectively with quantization, the theoretical analysis of this combination lacks robustness beyond specific parameter settings. Furthermore, the projection method from pre-trained models isn’t perfect, potentially resulting in accuracy loss even with fine-tuning. Finally, the empirical evaluations, while extensive, might benefit from a broader range of models and datasets to establish broader applicability.
More visual insights#
More on figures

This figure shows the upper bound on the variance of inner products between unit norm vectors under three different scenarios: projection alone, quantization alone, and a combination of both. The x-axis represents the compression ratio, and the y-axis represents the variance. The graph demonstrates that combining projection and quantization can yield better results (lower variance) than using either technique alone, particularly in the high-compression regime. This supports a key finding in the paper regarding the synergistic benefits of using both methods together.
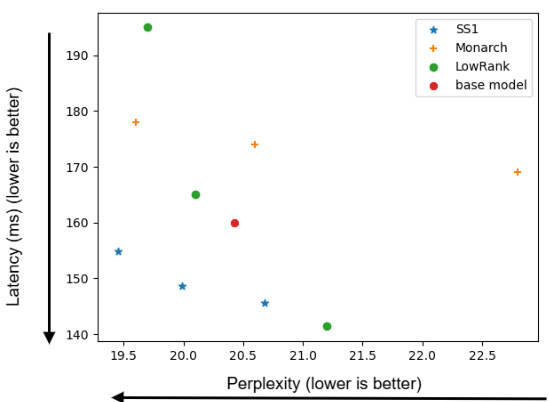
This figure shows the trade-off between latency (in milliseconds) and perplexity for GPT-S models using different linear transformation methods: SS1, Monarch, LowRank, and a baseline model. Lower latency and lower perplexity are both desirable; the ideal point would be in the lower-left corner. The plot helps visualize the quality-efficiency tradeoffs of each method.
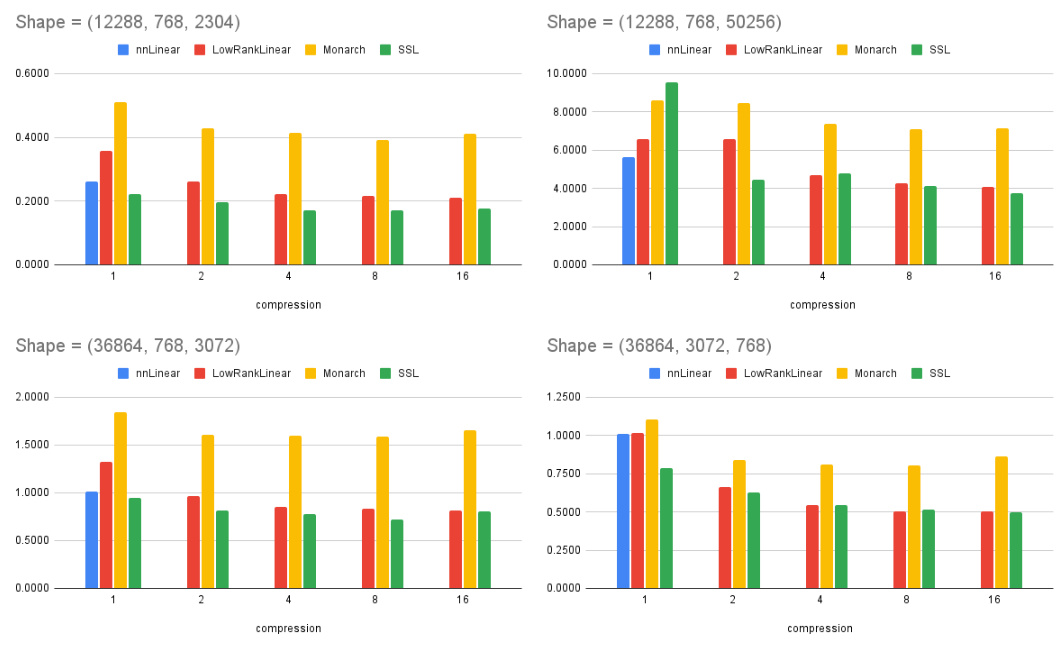
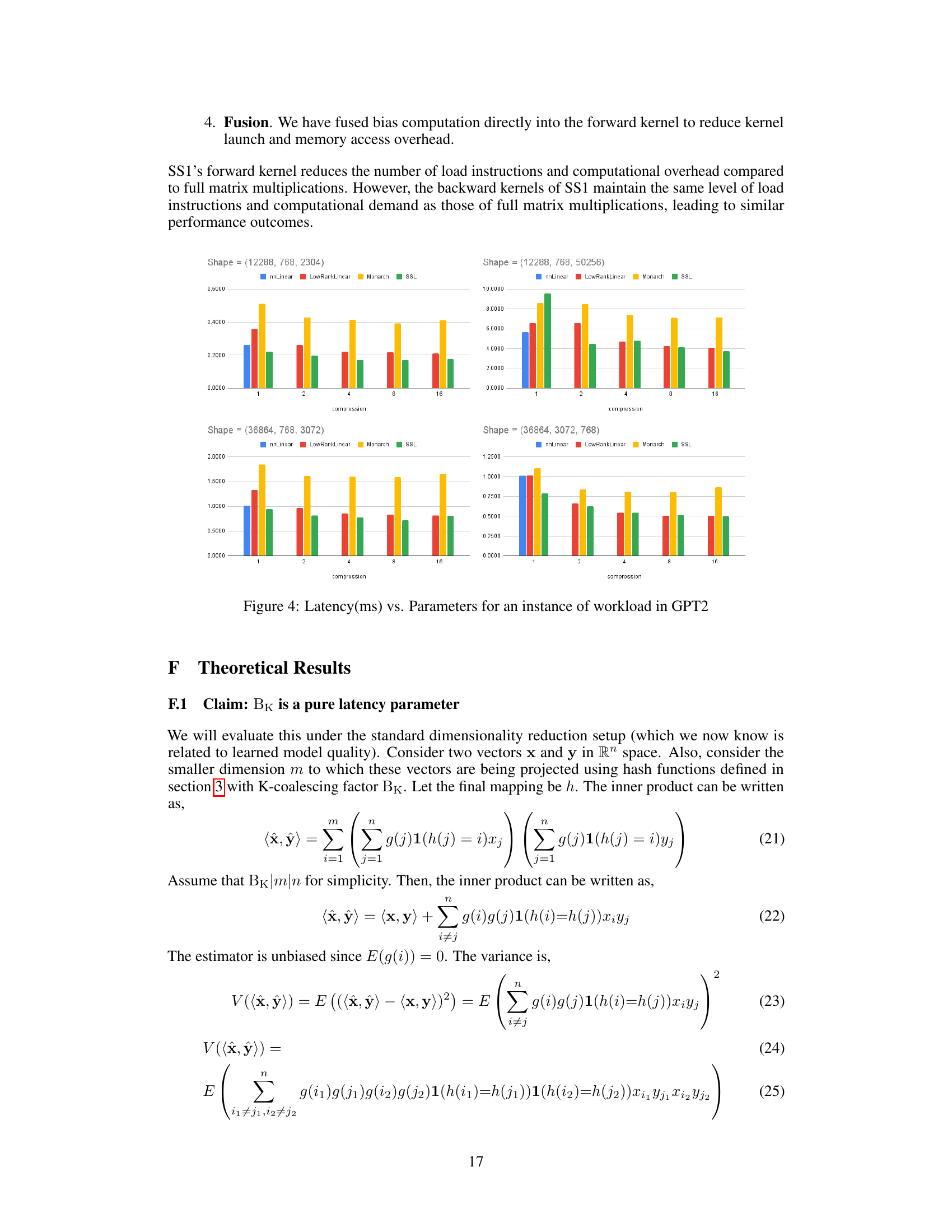
This figure shows the latency in milliseconds (ms) for different model sizes of GPT2 against the number of parameters and compression ratios. Four different matrix multiplication methods are compared: nnLinear (standard linear layer), LowRankLinear (low-rank linear layer), Monarch (structured matrix), and SS1 (Sketch Structured Transform). The x-axis represents the compression factor (1x, 2x, 4x, 8x, 16x), and the y-axis represents latency in milliseconds. Each subplot represents a different input size.
More on tables
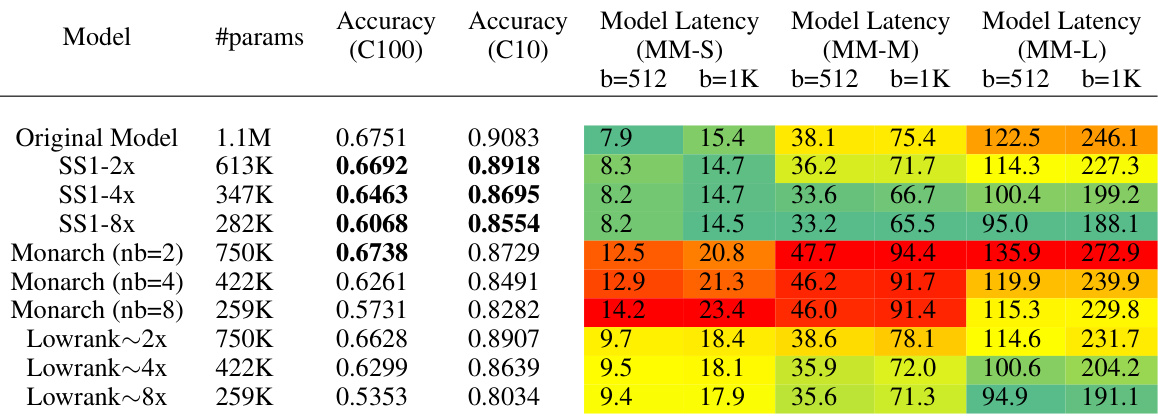
This table presents the results of NLP and Vision experiments, comparing the quality and latency of models using SS1 against baselines like Monarch and LowRank. It shows that SS1 achieves better quality-efficiency tradeoffs, and up to 1.3x faster inference throughput.
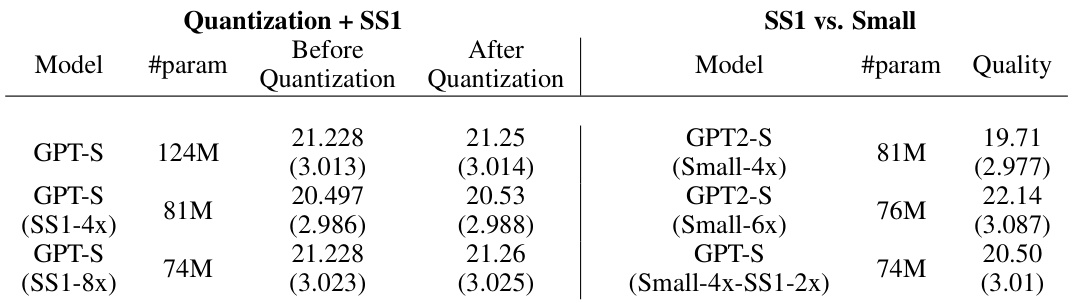
This table presents the results of applying post-training quantization to both the original GPT2 and the SS1-compressed models. The left side shows that the impact of quantization on the SS1 models is similar to its effect on the full-sized models; the quality remains largely unaffected. The right side demonstrates that SS1 models can achieve higher quality (lower perplexity) than smaller, less-parameterized versions of the original GPT2 model.
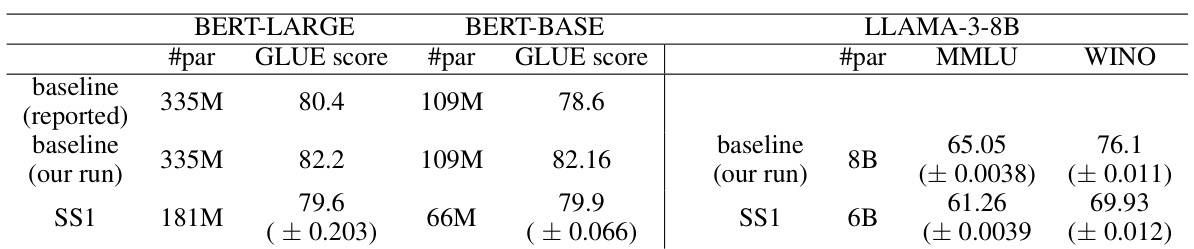
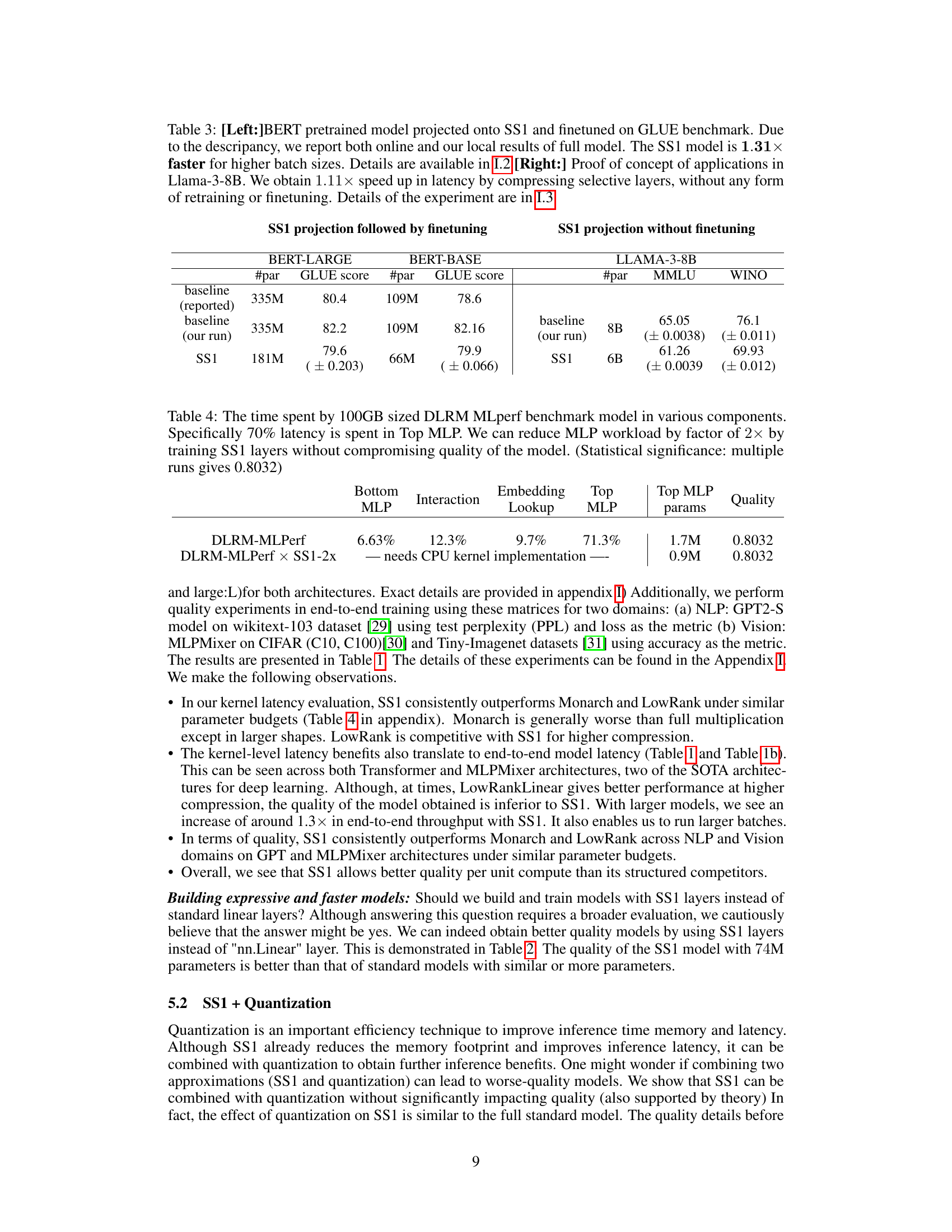
This table presents the results of applying Sketch Structured Transform (SST) to BERT and Llama models. The left side shows the results of finetuning a BERT model projected onto SST on the GLUE benchmark, demonstrating a 1.31x speedup in inference. The right side shows a proof-of-concept for Llama-3-8B, achieving a 1.11x speedup by compressing selective layers without finetuning.

This table shows the breakdown of time spent in different components of the DLRM model. The majority (70%) of the latency is in the Top MLP. By using SS1, the MLP workload is reduced by half while maintaining the same level of accuracy. This demonstrates the performance improvement offered by SS1, specifically for CPU-bound tasks where matrix multiplications dominate the computational workload.

This table compares the performance of SS1 against Monarch and LowRank baselines across various NLP and vision tasks. It shows that SS1 achieves better quality-efficiency tradeoffs (quality per parameter and FLOPs) and faster inference latency (up to 1.3x speedup) compared to baselines. The Appendix I contains more detailed experimental results.

This table shows the results of NLP and vision experiments using different models. It compares the quality (measured by PPL for NLP and accuracy for vision) and latency of models using the proposed SS1 method against baselines (Monarch, LowRank). The table highlights that SS1 consistently achieves better quality-efficiency tradeoffs than baselines, with up to a 1.3x increase in inference throughput. Detailed experimental settings are provided in Appendix I.
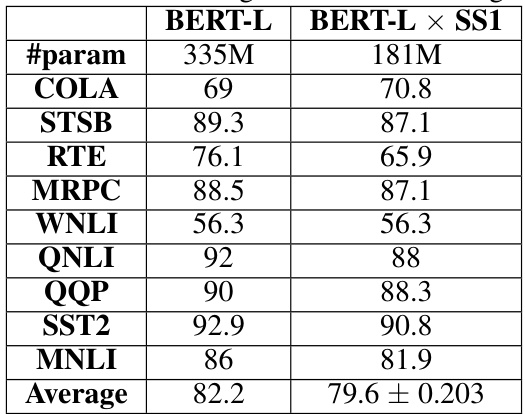
This table presents the results of fine-tuning experiments on the GLUE benchmark using the BERT-Large model and its SS1 compressed variant. The table shows the performance on various subtasks of the GLUE benchmark, including the number of parameters used and average accuracy for both models. The SS1 model demonstrates a significant reduction in the number of parameters while maintaining a relatively high level of accuracy compared to the original BERT-Large model.
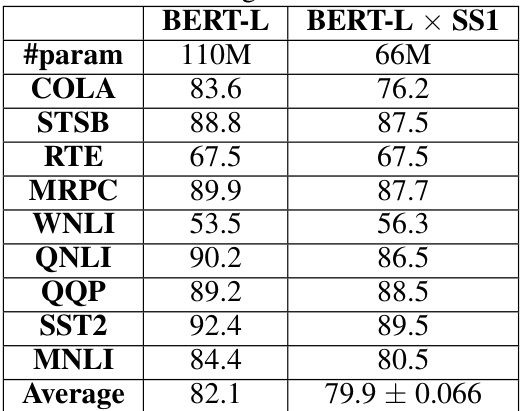
This table presents the results of fine-tuning BERT-base and a compressed version of BERT-base (using SS1) on the GLUE benchmark. The table shows the performance (accuracy) on several sub-tasks of GLUE, including COLA, STSB, RTE, MRPC, WNLI, QNLI, QQP, SST2, and MNLI, as well as the average accuracy across all tasks. It demonstrates that using SS1 to compress BERT-base resulted in only a minimal drop in accuracy compared to the original model.
This table compares the performance of the proposed Sketch Structured Transform (SS1) method against other state-of-the-art methods (Monarch and LowRank) on various NLP and vision tasks. It shows the number of parameters, accuracy/perplexity, and inference latency for different model sizes and compression levels for GPT and MLPMixer models. The results demonstrate that SS1 achieves better quality-efficiency trade-offs and faster inference compared to the baselines.
This table compares the performance of SS1 against other methods (Monarch, LowRank) on NLP and vision tasks. It shows that SS1 achieves better quality-efficiency trade-offs across various model sizes and benchmarks, offering improvements in both accuracy and inference speed.

This table compares the performance of SS1 against Monarch and LowRank methods on NLP and vision tasks. It shows that SS1 achieves better quality-efficiency tradeoffs (quality per parameter and FLOP) and faster inference latency (up to 1.3x speedup). The table presents metrics such as perplexity, accuracy, and latency for various model sizes and configurations.

This table shows the median latency (in milliseconds) for BERT-Large and BERT-Large with SS1 compression across different batch sizes (8, 16, 32, 64, 128). It also calculates the throughput increase achieved by using SS1 compression compared to the original BERT-Large model for each batch size. The results demonstrate the significant latency reduction and throughput improvement obtained by using SS1, especially at larger batch sizes.

This table presents the evaluation results of the compressed Llama model on the full MMLU and Winogrande datasets. It shows the number of parameters (#param), accuracy on the MMLU and Winogrande benchmarks, and the speedup achieved by using SS1 compression. The results demonstrate that SS1 compression achieves a significant reduction in model size while maintaining comparable performance, showing a 1.1x speedup.
This table compares the performance of SS1 against Monarch and LowRank across various NLP and vision tasks. It shows that SS1 achieves better quality-efficiency tradeoffs in terms of both accuracy/perplexity and inference latency, often significantly outperforming the baselines while using fewer parameters. Appendix I contains more detailed experimental results.
Full paper#