↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current Large Vision-Language Models (LVLMs) struggle with high-resolution images, limiting their applicability to real-world scenarios with fine-grained visual details. Previous attempts to enhance high-resolution understanding have been limited in their resolution range and scope.
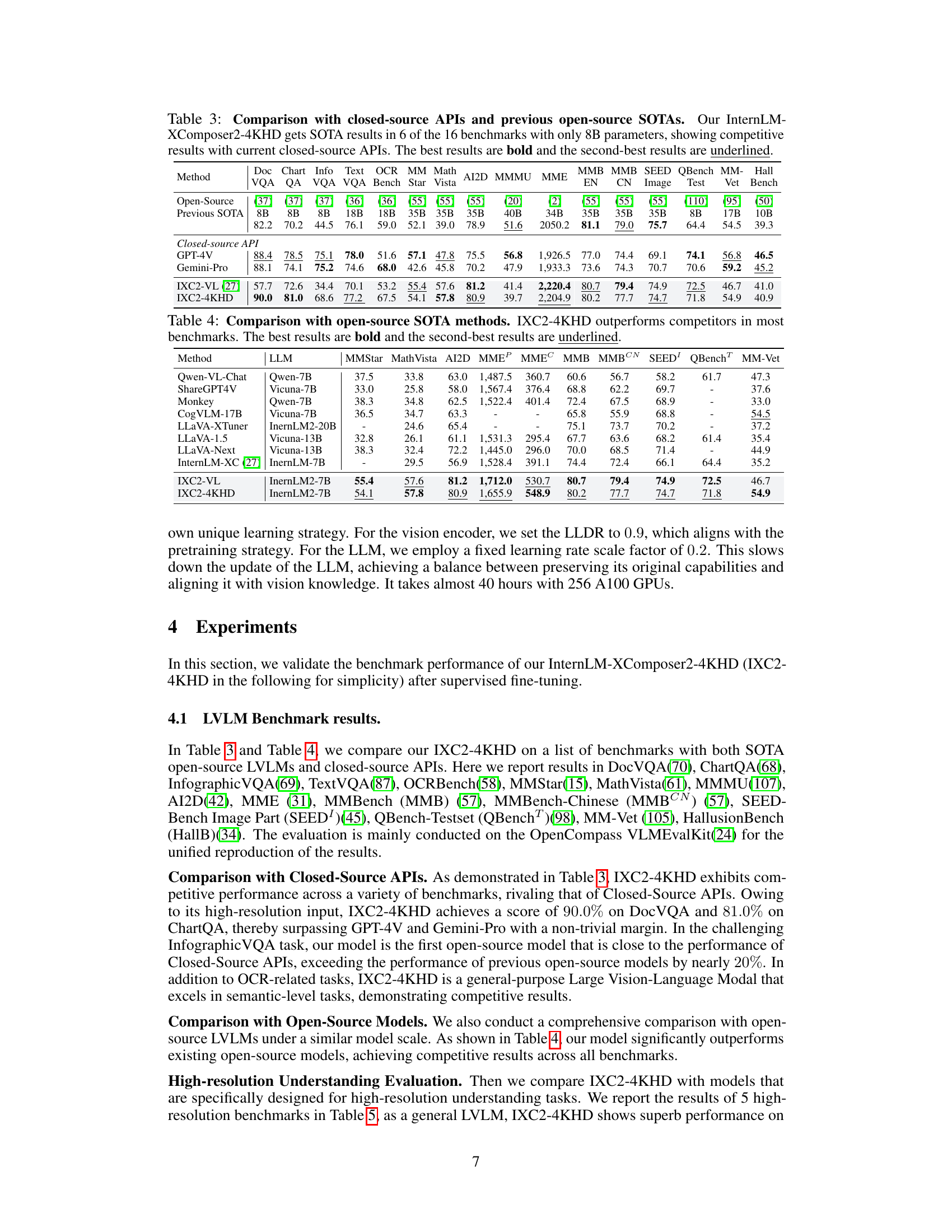
This research introduces InternLM-XComposer2-4KHD, a groundbreaking model that addresses these issues. It uses a novel ‘dynamic resolution with automatic patch configuration’ approach, allowing it to process a much wider range of resolutions (336 pixels to 4K HD). The model demonstrates superior performance compared to existing models on several benchmarks, showcasing its improved ability to handle high-resolution images and achieve state-of-the-art results.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large vision-language models (LVLMs) and high-resolution image processing. It presents a novel approach to significantly enhance LVLM capabilities for handling high-resolution images, surpassing existing models on several benchmarks. This opens exciting new avenues for research, including improving the performance of LVLMs on complex tasks and exploring high-resolution image understanding in diverse domains.
Visual Insights#

This figure presents a comparison of the InternLM-XComposer2-4KHD model’s performance against GPT-4V and Gemini Pro across 16 benchmarks, showcasing its superior performance in 10 out of the 16 benchmarks. The figure also shows the image resolutions used in each benchmark, demonstrating a wide range of resolutions handled by the InternLM-XComposer2-4KHD model.
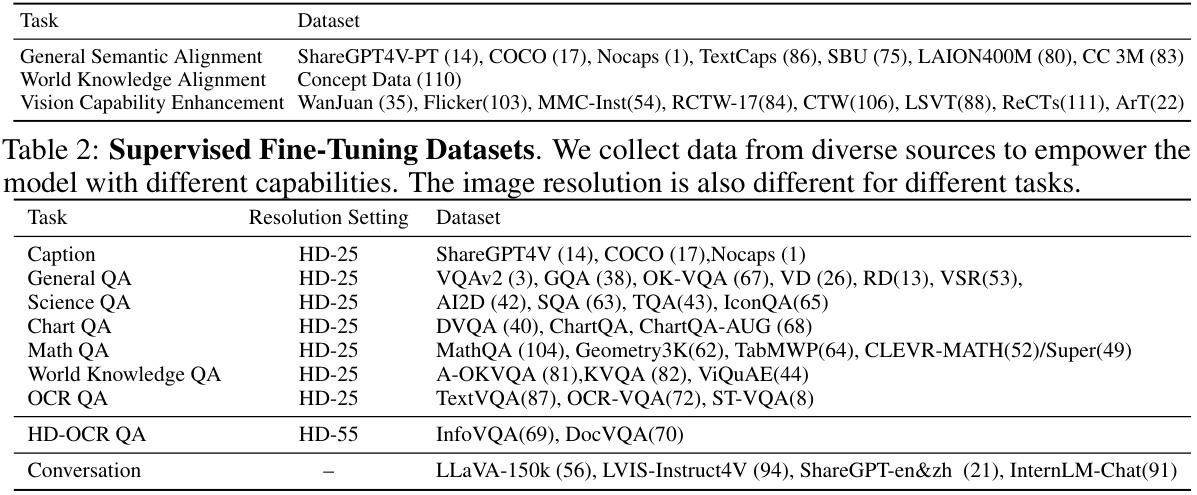
This table lists the datasets used for supervised fine-tuning of the InternLM-XComposer2-4KHD model. It breaks down the datasets by task (e.g., Captioning, General QA, Science QA, etc.) and shows the resolution setting used for each task’s training data. The table highlights the model’s versatility and ability to handle different types of visual and textual information.
In-depth insights#
4K HD LVLM#
The concept of a “4K HD LVLM” points towards a significant advancement in large vision-language models (LVLMs). High-resolution image processing is a major challenge in LVLMs, limiting their ability to understand fine-grained details crucial for complex tasks. A 4K HD LVLM would overcome this limitation, enabling the model to process images at significantly higher resolutions, thus improving the accuracy and detail in its understanding. This has important implications for tasks like document understanding, image captioning, and visual question answering, where fine details are essential. The development of such a model likely involves innovative solutions in image processing, such as dynamic resolution adjustment and efficient patch management, to handle the increased computational demands. The benefits could be substantial, but challenges remain, including the availability of large high-resolution datasets for training and the computational costs associated with processing such data. This new capability could fundamentally change the interaction between humans and machines. It would improve applications ranging from medical diagnosis to enhanced accessibility solutions. However, considerations regarding ethical implications and potential misuse (such as generating high-quality deepfakes) should also be addressed. Ultimately, 4K HD LVLMs represent a substantial step towards more robust and capable AI systems.
Dynamic Patching#
Dynamic Patching, in the context of large vision-language models (LVLMs), addresses the challenge of processing images with varying resolutions and aspect ratios. Instead of using a fixed patch size, as in traditional methods, dynamic patching adjusts the number and configuration of patches automatically based on the input image’s dimensions. This adaptability is crucial for handling high-resolution images (like 4K) and diverse image content without compromising performance. By maintaining the original aspect ratio and dynamically adjusting patch counts, dynamic patching improves efficiency and enables the model to focus on relevant details regardless of the image size. Automatic patch configuration eliminates the need for pre-defined resolution settings, thus expanding the model’s applicability to a wider range of real-world scenarios. The introduction of a newline token in the patch layout further enhances the model’s ability to understand the two-dimensional structure of high-resolution inputs, leading to improved accuracy and performance. This approach significantly broadens the potential of LVLMs in handling diverse image data.
High-Res Training#
The concept of “High-Res Training” in the context of large vision-language models (LVLMs) centers on enhancing model capabilities by training them on images with significantly higher resolutions than traditionally used. This approach directly addresses the limitations of previous LVLMs, which often struggled with fine-grained visual details due to lower resolution inputs. Training with higher-resolution images exposes the model to richer visual information, leading to improved understanding of complex scenes and better performance on tasks involving fine detail analysis such as object recognition and optical character recognition (OCR). However, high-resolution training presents challenges. Obtaining sufficient high-resolution training data can be expensive and time-consuming. Furthermore, computational demands increase significantly, potentially requiring more powerful hardware and longer training times. Therefore, strategies like dynamic resolution and automatic patch configuration become crucial to mitigate these challenges, allowing for efficient training across a wide range of resolutions while preserving the benefits of higher-resolution learning.
Benchmark Results#
The benchmark results section of a research paper is crucial for evaluating the performance of a proposed model or technique. A thoughtful analysis should go beyond simply stating the numerical results. It should explore the selection of benchmarks, highlighting their relevance to the problem domain and the extent to which they cover diverse aspects. The comparison with existing state-of-the-art methods is vital, ensuring clarity in demonstrating improvements, either absolute or relative. Error analysis is equally important, providing insights into potential weaknesses or limitations of the proposed approach. It’s also critical to understand the methodological details underlying the benchmarks to assess the fairness and robustness of the evaluation process. A high-quality benchmark results section will not just report numbers but offer a nuanced, detailed analysis that fosters confidence in the claims made by the researchers. The clarity and completeness of the presentation are key to providing the reader with a thorough understanding of the methodology’s capabilities and limitations.
Future Directions#
Future research directions for InternLM-XComposer2-4KHD could explore scaling to even higher resolutions beyond 4K, potentially investigating whether performance gains continue or reach a plateau. Improving inference efficiency is crucial, especially given the large model size. This could involve exploring more efficient architectures or optimization techniques. A significant area for improvement lies in handling variability in patch layouts more effectively, aiming for a more robust and less computationally expensive approach. Further investigation into optimizing the balance between global and local views could lead to more accurate and nuanced image understanding. Finally, research should focus on expanding the diversity of datasets used for training to enhance the model’s generalizability and robustness across a broader range of visual content and language tasks.
More visual insights#
More on figures

This figure presents a comparison of InternLM-XComposer2-4KHD’s performance against state-of-the-art models on 16 benchmark datasets. Subfigure (a) is a radar chart visualizing the model’s performance across these benchmarks, showing that it surpasses or matches GPT-4V and Gemini Pro on 10 out of 16 tasks. Subfigure (b) provides a statistical overview of the image resolutions within these benchmarks, indicating a wide range of resolutions used in the datasets, emphasizing the model’s capability to handle diverse input image resolutions.
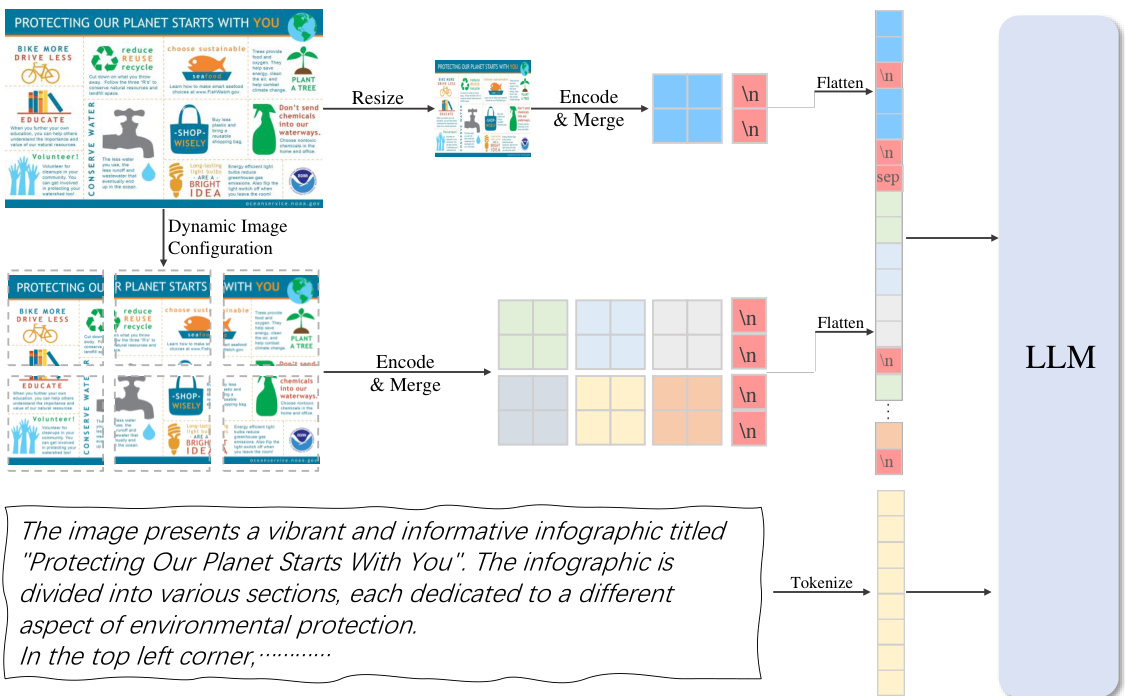
The figure illustrates the architecture of InternLM-XComposer2-4KHD, a large vision-language model designed to handle high-resolution images. It shows how the model processes high-resolution images by dynamically partitioning them into smaller patches. These patches are then encoded and merged with text tokens before being fed into a large language model (LLM) for processing. The diagram highlights the ‘Dynamic Image Configuration’ step which automatically adjusts the number and layout of patches based on the input image’s aspect ratio and resolution, maintaining training image aspect ratios and varying patch counts and layouts.

This figure shows a comparison of InternLM-XComposer2-4KHD’s performance against other models (GPT-4V and Gemini Pro) across 16 benchmarks with varying resolutions. The left panel (a) is a radar chart illustrating the model’s performance relative to the others; the right panel (b) shows the distribution of image resolutions across the benchmarks, categorized by minimum, median, and maximum values.

This figure shows two example interactions with the InternLM-XComposer2-4KHD model. The first example shows a question about contact tracing, with the model providing a detailed explanation based on an infographic image showing the contact tracing process. The second example shows the model describing a Venn diagram on the topic of healthy eating habits.

This figure illustrates the InternLM-XComposer2-4KHD model’s architecture. It showcases how high-resolution images are processed using a dynamic image partition strategy. The image is divided into patches, and features are extracted from each patch. These features are then merged with text tokens and fed into a large language model (LLM) for processing. A key aspect shown is the dynamic configuration of patches based on the input image’s resolution and aspect ratio. The global view, which provides a macro-level image understanding, is also included in the input.

This figure shows a comparison of the InternLM-XComposer2-4KHD model’s performance against other models (GPT-4V and Gemini Pro) across 16 benchmarks with varying image resolutions. Part (a) is a radar chart illustrating the model’s performance relative to others. Part (b) provides a table summarizing the minimum, median, and maximum image resolutions across these benchmarks, highlighting the wide range of image sizes handled by InternLM-XComposer2-4KHD and the other models. The results demonstrate InternLM-XComposer2-4KHD’s competitive performance and ability to handle a broad range of high resolutions.

This figure illustrates the architecture of InternLM-XComposer2-4KHD, a large vision-language model designed to handle high-resolution images. The model uses a dynamic image partition strategy, dividing high-resolution images into smaller patches based on their aspect ratio, before processing them with a vision transformer (ViT). These image tokens are then concatenated with text tokens and fed into a large language model (LLM) for processing. This approach enables the model to understand fine details in high-resolution images. The dynamic patch configuration ensures efficient handling of various image sizes and aspect ratios.
More on tables
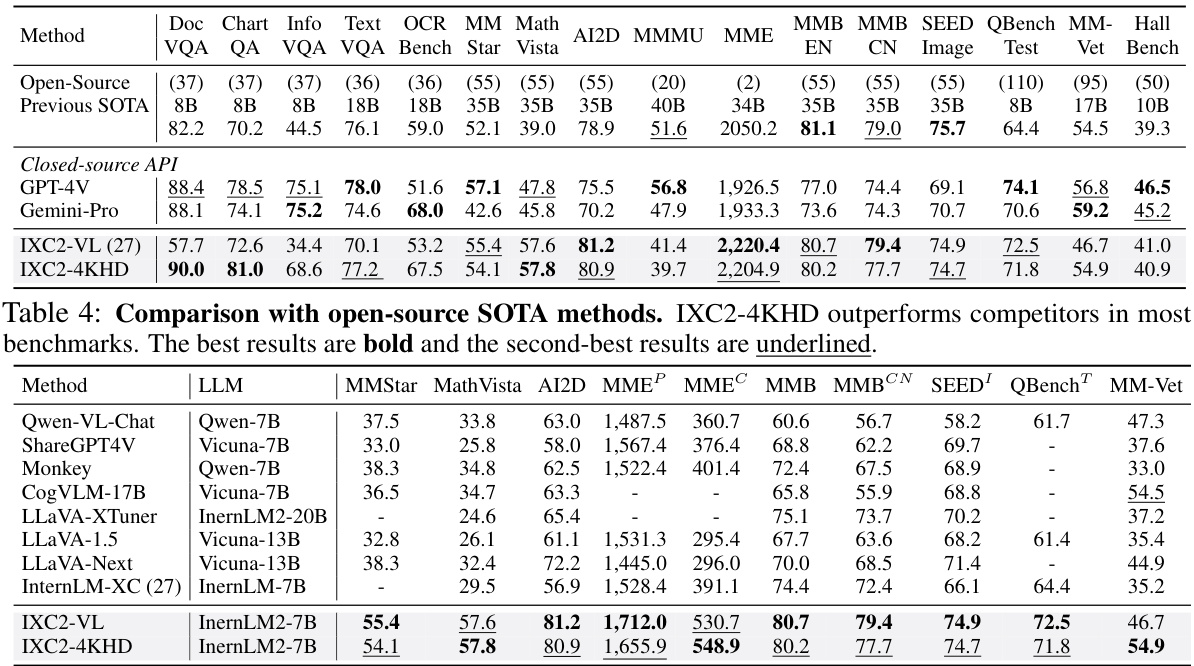
This table compares the performance of InternLM-XComposer2-4KHD (IXC2-4KHD) against other state-of-the-art (SOTA) open-source Large Vision-Language Models (LVLMs) across sixteen benchmark datasets. The benchmarks cover diverse tasks, including document visual question answering, chart question answering, and image-based reasoning. The table highlights IXC2-4KHD’s superior performance by showing that it achieves the best scores (in bold) on most benchmarks and second-best scores (underlined) on the others. The model sizes are also compared to showcase the efficiency of IXC2-4KHD.

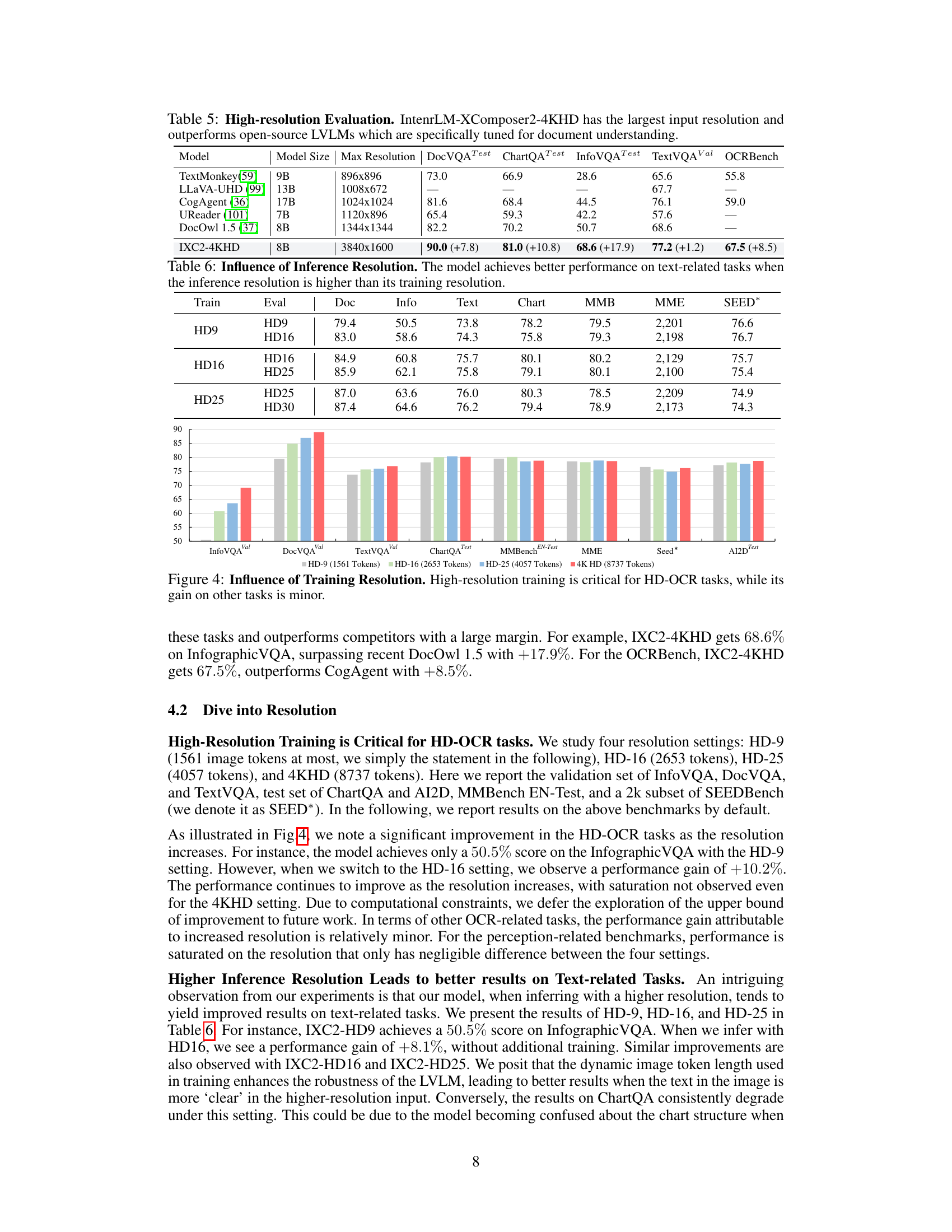
This table presents a comparison of InternLM-XComposer2-4KHD against other open-source Large Vision-Language Models (LVLMs) on high-resolution benchmarks focusing on document understanding tasks. It shows that InternLM-XComposer2-4KHD achieves superior performance with the largest input resolution (3840x1600 pixels) compared to other models, highlighting its ability to handle high-resolution images effectively.

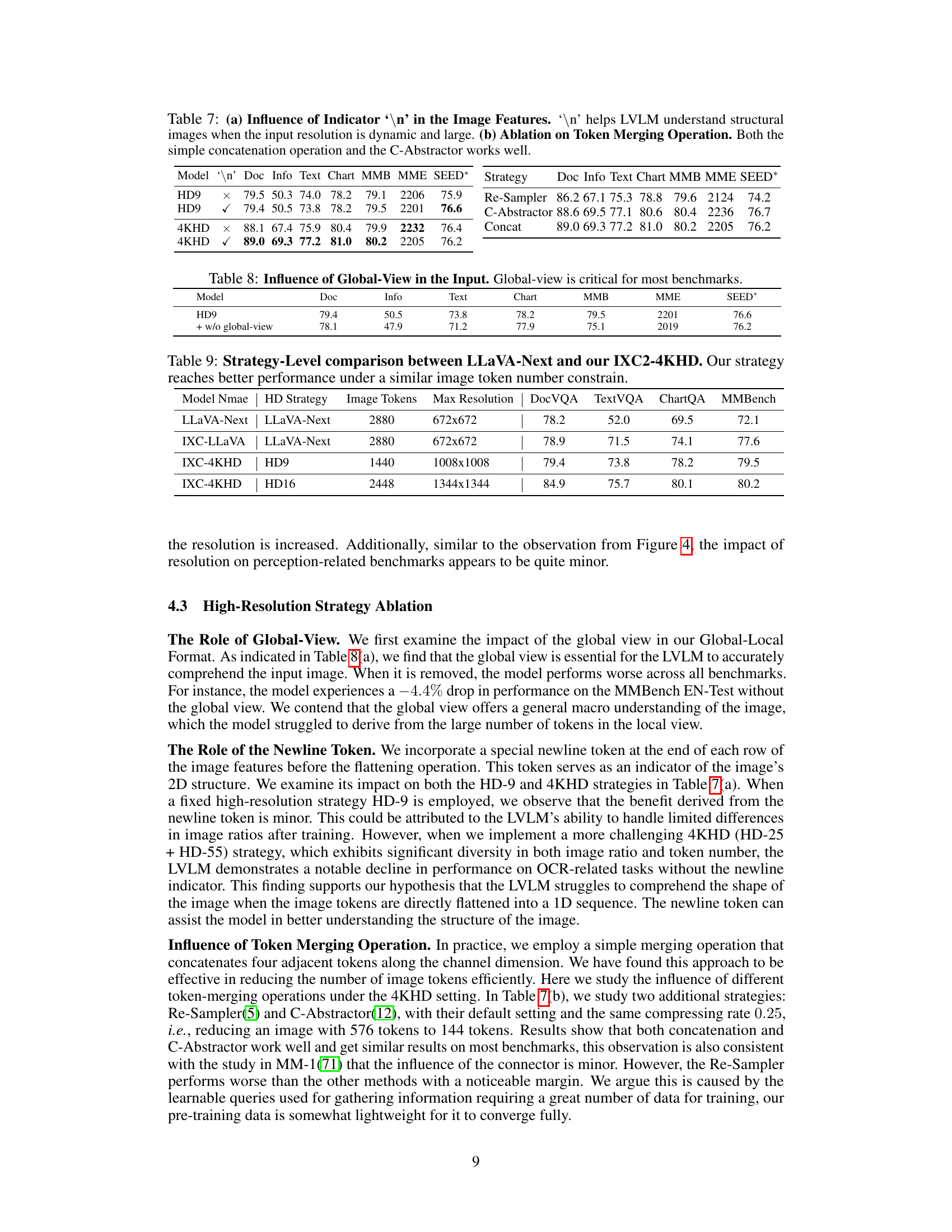
This table presents the ablation study of two key components in InternLM-XComposer2-4KHD: the newline token (’\n’) as an indicator for image features and the token merging operation. Part (a) compares the performance of the model with and without the newline token for different image resolutions (HD9 and 4KHD). The results show that the newline token significantly improves performance when dealing with high resolutions, suggesting its crucial role in helping the model understand the 2D structure of images with dynamic and large patch layouts. Part (b) evaluates three different token merging strategies: Re-Sampler, C-Abstractor, and Concat. The results indicate that both the concatenation and C-Abstractor methods achieve comparable performance, demonstrating the effectiveness of these approaches in balancing efficiency and performance.

This table presents the ablation study on the global view’s impact. It compares the performance of the model with and without the global view across several benchmarks. The results demonstrate the importance of the global view for overall performance, particularly highlighting its contribution to the accuracy on most benchmarks.

This table compares the performance of the InternLM-XComposer2-4KHD model (IXC-4KHD) with LLaVA-Next, another state-of-the-art model, across multiple benchmarks. It highlights the superior performance of IXC-4KHD while maintaining a similar number of image tokens as LLaVA-Next. This demonstrates the effectiveness of the IXC-4KHD model’s high-resolution strategy.

This table presents an efficiency analysis of the InternLM-XComposer2-4KHD model’s inference process, focusing on the time required for prefix encoding and per-token decoding. The results show that the prefix encoding time scales linearly with the number of image tokens, while the per-token decoding speed remains relatively constant regardless of the input size. The overall inference time for generating 2048 new tokens is nearly identical across different input resolutions (HD9, HD16, HD25), indicating that the model’s efficiency is acceptable even with high-resolution images.
Full paper#