↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current neuroscience models often struggle with the complexity of neural activity, being limited to small circuits of neurons and specific brain regions. This limits their ability to generalize across multiple brain areas and provides a fragmented understanding of brain function. This lack of generalization makes it difficult to build a comprehensive model of the brain that is capable of translating neural activity into behavior or other cognitive functions.
The researchers address these issues with a novel self-supervised learning approach called Multi-task Masking (MtM). MtM excels by incorporating information from multiple brain regions simultaneously. It’s particularly effective at handling various prediction tasks such as decoding behavior and single-neuron activity. The model’s flexibility and improved accuracy make it a valuable contribution for building robust, generalizable models of neural computation. MtM’s effectiveness across multiple animals and its ability to improve generalization to new animals highlights its potential as a foundational model for understanding brain activity.
Key Takeaways#
Why does it matter?#
This paper is crucial for neuroscience research because it introduces a novel self-supervised learning approach that significantly improves the performance of existing population models. This advancement will likely accelerate the development of more accurate and comprehensive models of neural activity and their application in understanding brain function.
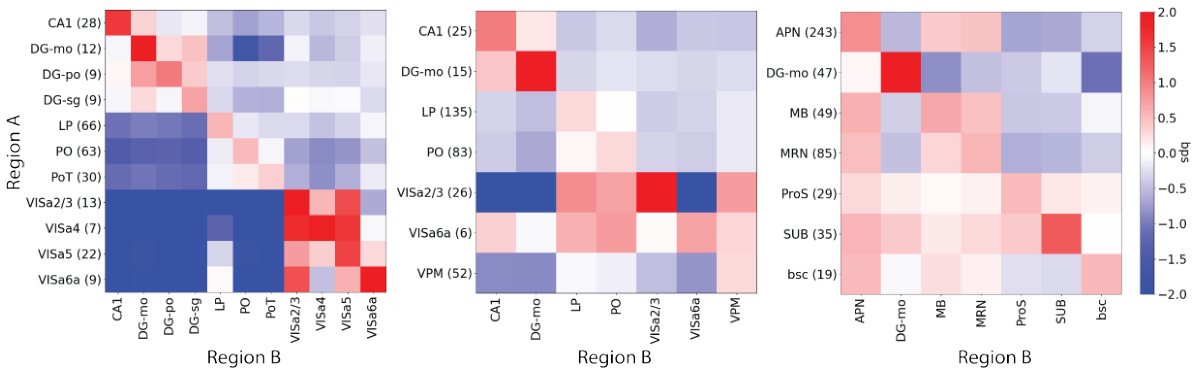
Visual Insights#

This figure schematically illustrates the multi-task masking (MtM) approach. Panel A shows four metrics used to evaluate foundation models: co-smoothing, causal prediction, inter-region prediction, and intra-region prediction. Different colored areas represent masked regions that are later reconstructed. Panel B details the MtM training process, highlighting the alternation between masking schemes and the use of a learnable ‘prompt’ token to provide context to the model. This token allows for seamless switching between masking objectives during training and test-time adaptation for downstream tasks.
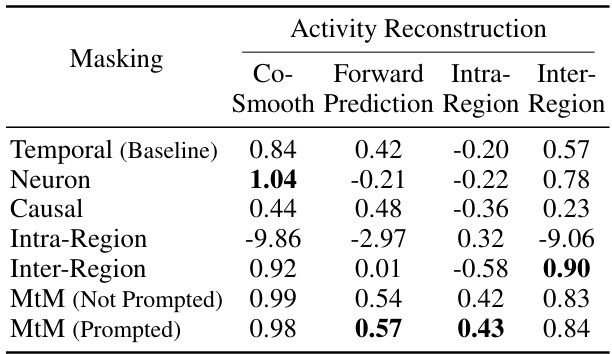
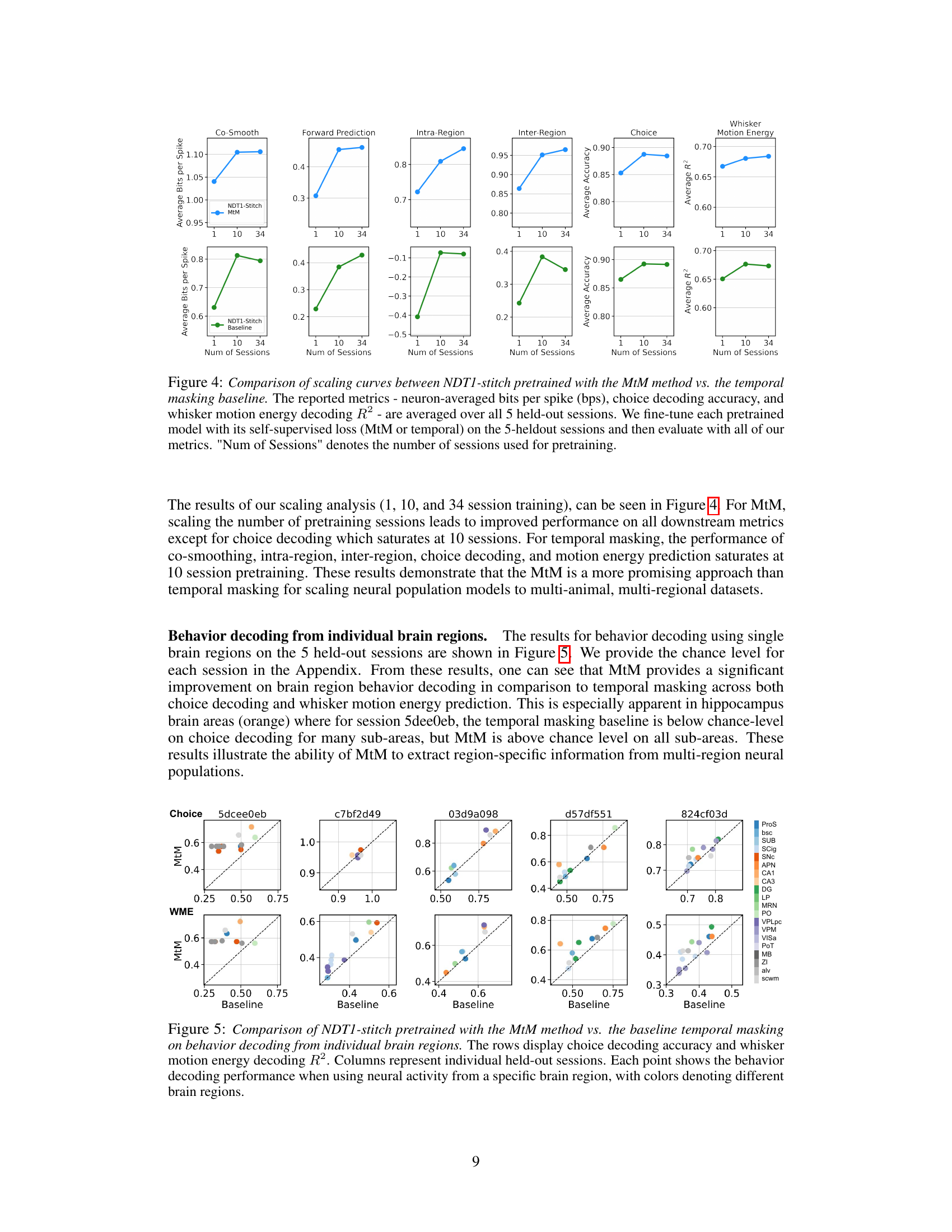
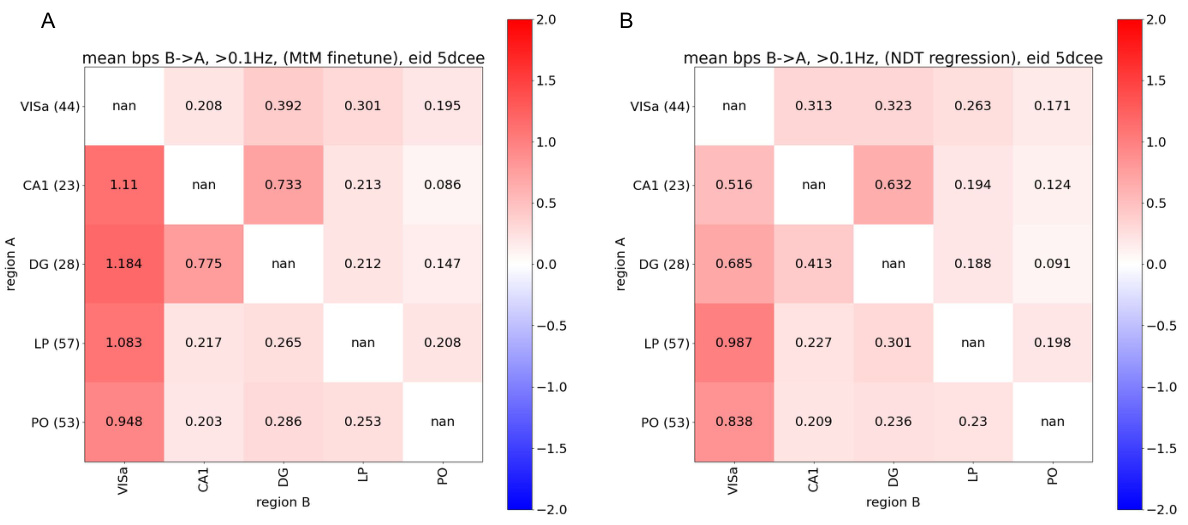
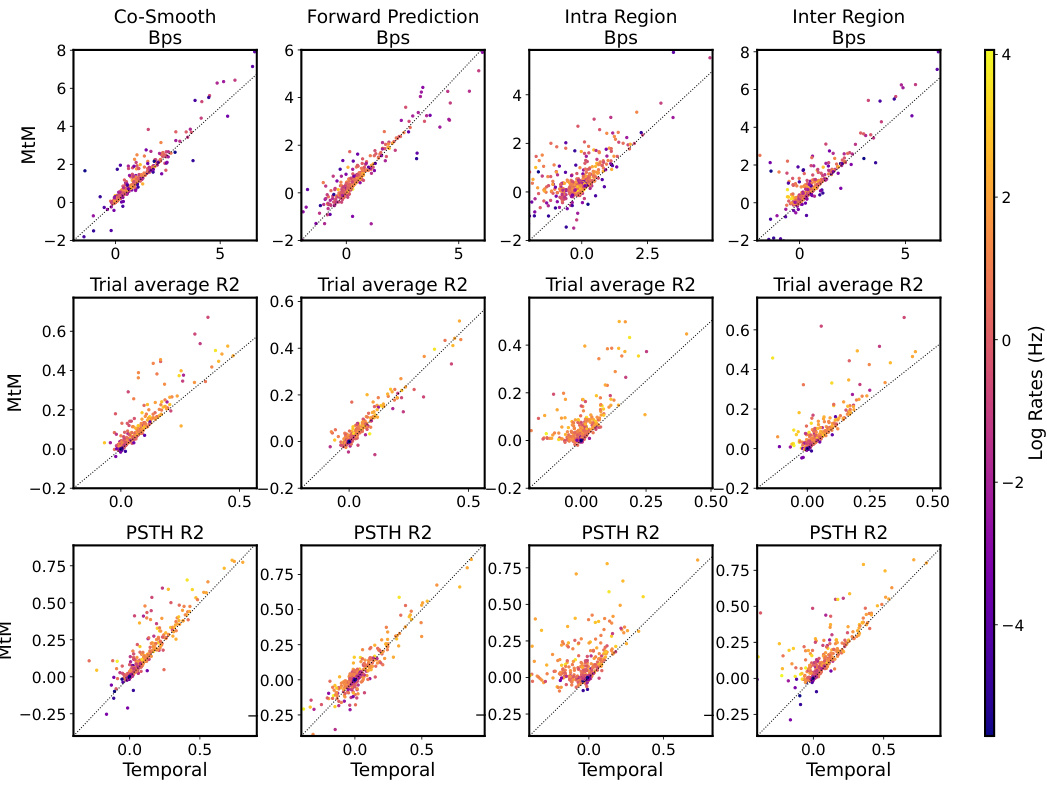
This table presents the performance of the single-session Neural Data Transformer 1 (NDT1) model trained with different masking schemes for neural activity reconstruction. The performance is measured in bits per spike (bps), which is averaged across all neurons in a single session. A higher bps value signifies better performance. The masking schemes are: Temporal (baseline), Neuron, Causal, Intra-Region, Inter-Region, MtM (Not Prompted), and MtM (Prompted). The table provides a quantitative comparison of these masking schemes on four metrics: Co-smoothing, Forward Prediction, Intra-Region, and Inter-Region. This is an ablation study to show the effect of various masking techniques.
In-depth insights#
Universal Translator#
The concept of a ‘Universal Translator’ for neural dynamics, as explored in the research paper, presents a compelling vision. The core idea is to create a model capable of understanding and interpreting neural activity across diverse brain regions and species, moving beyond region-specific models. This necessitates a model robust enough to handle the variability inherent in neural data while generalizing effectively to new tasks and datasets. The paper likely proposes a novel approach, potentially self-supervised learning or a multi-task learning framework, to achieve this ambitious goal. Success would represent a major advance, enabling broader understanding of brain function and facilitating advancements in brain-computer interfaces and other neurotechnologies. However, challenges abound. Creating a truly universal model requires vast amounts of high-quality, diverse neural data, which may be difficult to acquire and process. Furthermore, the computational demands of such a model could be substantial. Despite these hurdles, the pursuit of a ‘Universal Translator’ is a significant endeavor with the potential to revolutionize neuroscience.
Multi-task Masking#
The core idea behind “Multi-task Masking” is to enhance the learning process of a neural network model by exposing it to diverse, yet related, tasks simultaneously. Instead of training on a single objective, such as predicting future neural activity, this approach incorporates multiple masking schemes, each focusing on different aspects of the data. This multi-faceted training strategy forces the network to learn more robust and generalizable representations. For example, masking neurons compels the model to understand inter-neuron dependencies, while masking temporal segments improves its comprehension of temporal dynamics. The key innovation lies in the simultaneous training on these diverse masking objectives, forcing the model to learn a more holistic understanding of the underlying data structure. This approach ultimately improves the model’s generalization capabilities across a wider range of downstream tasks, paving the way for a more powerful and versatile foundation model for neural dynamics.
Scaling & Generalization#
The concept of “Scaling & Generalization” in the context of a neuroscience foundation model is crucial. The ability of a model to successfully train on larger datasets (scaling), encompassing more animals and brain regions, directly relates to its capacity to generalize to unseen data and tasks (generalization). This is especially relevant given the heterogeneity of neural data across animals and the sparsity of comprehensively annotated datasets. A model’s success depends on how well it learns underlying patterns of neural activity rather than memorizing specific instances. The paper’s findings suggest that a multi-task masking (MtM) approach is more successful in achieving both scaling and generalization compared to standard temporal masking methods. This superiority likely arises from MtM’s capacity to capture diverse patterns and relationships within neural data across different spatial and temporal scales. Ultimately, achieving robust scaling and generalization is paramount for creating truly universal models for understanding neural dynamics.
Benchmarking Models#
Benchmarking models in neuroscience is crucial for evaluating their generalizability and performance. A robust benchmark should include diverse tasks, reflecting the complexity of neural systems, such as predicting neural activity, decoding behavior, and generalizing across different brain regions and animals. The International Brain Laboratory (IBL) dataset, with its multi-animal, multi-session recordings across multiple brain regions, offers a rich platform for such benchmarking. Key metrics for evaluation might include bits-per-spike for activity prediction, accuracy for behavioral decoding, and the ability to generalize to unseen animals or sessions. Self-supervised learning approaches, like those utilizing masked modeling, are increasingly important, as they allow for pre-training on large datasets before fine-tuning on specific tasks. Careful consideration of the various masking strategies and the chosen model architecture is vital to ensure accurate and reliable results. Ultimately, a comprehensive benchmark promotes transparency, reproducibility, and facilitates a more rigorous evaluation of novel neural population models. The MtM approach described in the paper offers a multi-task framework potentially well-suited to such a comprehensive benchmark.
Future Directions#
Future directions for this research could involve exploring the scalability of the model to larger datasets, encompassing diverse brain regions and species. Investigating the model’s robustness to noise and incomplete data would be crucial for real-world applicability. Furthermore, research could focus on developing more interpretable methods to understand the model’s internal representations and gain deeper insights into neural dynamics. A comparative analysis of the MtM approach with other state-of-the-art methods, including different transformer architectures, would enhance the field’s understanding. The incorporation of behavioral context and task demands within the model is also a promising avenue to better reflect the complex nature of neural computation. Finally, exploring the potential of this model for clinical applications, such as brain-computer interfaces and diagnostics, warrants future investigation.
More visual insights#
More on figures
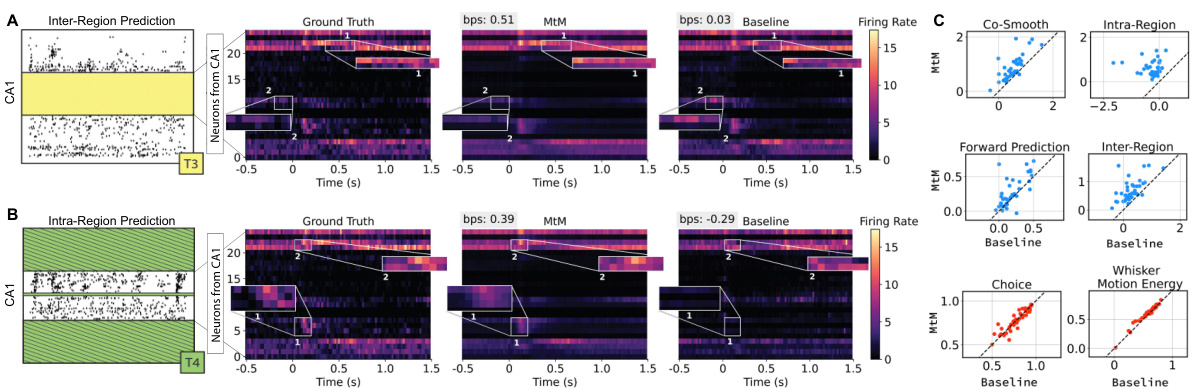
This figure compares the performance of the proposed multi-task masking (MtM) method against a temporal masking baseline for single-session neural data. Panels A and B show raster plots illustrating the superior performance of MtM in reconstructing neural activity in the CA1 region under both inter-region and intra-region masking schemes. Panel C presents a comparison of the overall performance of MtM and the baseline across multiple performance metrics (activity reconstruction and behavioral decoding) and across 39 experimental sessions.
This figure compares the performance of the proposed multi-task masking (MtM) method against a temporal masking baseline on single-session neural data. It shows trial-averaged raster maps for CA1, highlighting regions where MtM provides better predictions than the baseline for both inter-region and intra-region masking. Additionally, it presents a comparison of activity reconstruction and behavioral decoding performance across multiple sessions, illustrating the superior performance of MtM.

This figure compares the performance of the proposed multi-task masking (MtM) method against a temporal masking baseline on single-session neural data. It shows trial-averaged raster plots for CA1, highlighting regions where MtM provides better predictions compared to the baseline for both inter-region and intra-region masking schemes. Additionally, it presents a comparison of the activity reconstruction and behavior decoding performance across 39 sessions using different metrics, indicating MtM’s superior performance.
This figure compares the performance of the proposed multi-task masking (MtM) approach against a temporal masking baseline for single-session neural data. Panel A and B show raster plots illustrating improved activity prediction by MtM in CA1 for both inter-region and intra-region masking scenarios. Panel C summarizes the performance across all 39 sessions for both activity reconstruction and behavioral decoding tasks, indicating that MtM significantly outperforms the temporal masking baseline.
This figure compares the performance of the proposed multi-task masking (MtM) method against a temporal masking baseline for single-session neural data. Panel A and B show raster plots visualizing the model’s ability to reconstruct neural activity after inter- and intra-region masking, respectively, highlighting MtM’s superior performance. Panel C presents a comparison across multiple sessions, evaluating activity reconstruction (bps) and behavior decoding (accuracy and R-squared) for both methods. The NDT1 architecture was used for all comparisons.
This figure compares the performance of the multi-task masking (MtM) approach with a temporal masking baseline on single-session data. Panel A and B show raster plots illustrating that MtM better reconstructs neural activity in CA1, both when using information from other brain regions (inter-region) and from within CA1 itself (intra-region). Panel C summarizes the results across all 39 sessions, showing MtM’s improved performance on activity reconstruction and behavior decoding.
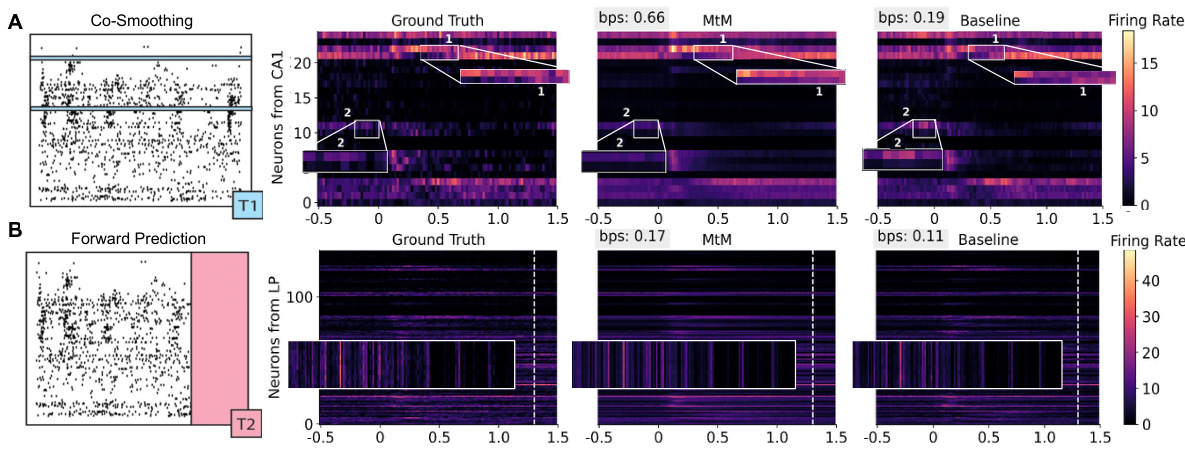
This figure compares the performance of the Multi-task Masking (MtM) approach against a temporal masking baseline on single-session data from 39 mice. It shows trial-averaged raster maps for two brain regions (CA1 and LP), highlighting areas where MtM produces qualitatively better predictions. It also presents a comparison of activity reconstruction and behavior decoding across all sessions, using various metrics like bits per spike (bps), accuracy, and R-squared (R²).

This figure compares the performance of the proposed multi-task masking (MtM) method against a temporal masking baseline on single-session neural data. Panel A and B show raster plots illustrating the superior ability of MtM to predict neural activity in the CA1 region, both from other brain regions (inter-region) and from within the CA1 region itself (intra-region). Panel C provides a summary of the performance across 39 sessions for both methods, demonstrating that MtM outperforms the baseline in activity reconstruction and behavior decoding metrics.
This figure schematically illustrates the Multi-task-Masking (MtM) approach. Panel A shows four metrics for evaluating neural population activity models: co-smoothing, causal prediction, inter-region prediction, and intra-region prediction. Different colored areas represent masked and reconstructed regions for each metric. Panel B depicts the training process, showing how the model alternates between masking schemes using a learnable ‘prompt’ token to provide context.

This figure compares the performance of the proposed multi-task masking (MtM) method against a temporal masking baseline for single-session neural data. Panels A and B show raster plots visualizing the activity predictions of MtM and the baseline for two different masking schemes (inter-region and intra-region). Panel C provides a summary of activity reconstruction and behavioral decoding performance across 39 sessions, demonstrating the superior performance of MtM.

This figure compares the performance of the proposed multi-task masking (MtM) method against a temporal masking baseline on single-session data from 39 mice. Panels A and B show raster plots illustrating MtM’s improved prediction accuracy for inter-region and intra-region activity, respectively. Panel C provides a summary comparing the overall performance of MtM and the baseline across different tasks.

This figure schematically illustrates the Multi-task Masking (MtM) approach. Panel A shows the four metrics used to evaluate the model: co-smoothing, causal prediction, inter-region prediction, and intra-region prediction. The colored areas represent masked sections of the input data. Panel B demonstrates the training process, showing how the model alternates between different masking schemes guided by a learnable ‘prompt’ token. This token allows for seamless switching between tasks during both training and evaluation, making the approach flexible and adaptable.
More on tables

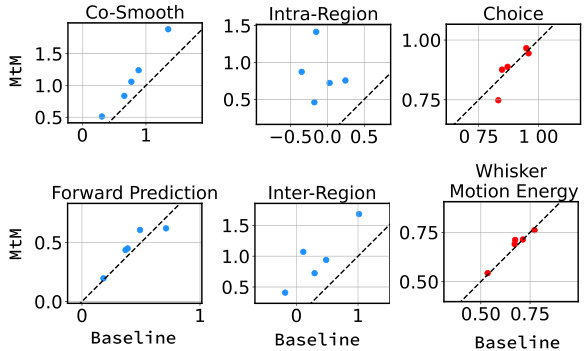
This table presents the results of fine-tuning two different NDT1-stitch models (one pretrained with MtM and the other with temporal masking) on 5 held-out sessions. It compares their performance across multiple metrics related to activity reconstruction (bits per spike for co-smoothing, forward prediction, intra-region and inter-region prediction) and behavior decoding (accuracy for choice and R-squared for whisker motion energy). The higher the value, the better the model performance. The table shows that the MtM model outperforms the temporal masking model across most metrics, demonstrating that MtM is a more effective training approach.

This table compares the performance of two different neural network architectures (NDT1 and LFADS) trained with two different masking approaches (temporal masking baseline and MtM) across several tasks involving activity reconstruction and behavior decoding. The results show the average performance across all neurons in one session. It aims to demonstrate the effectiveness of the MtM approach across different architectures.

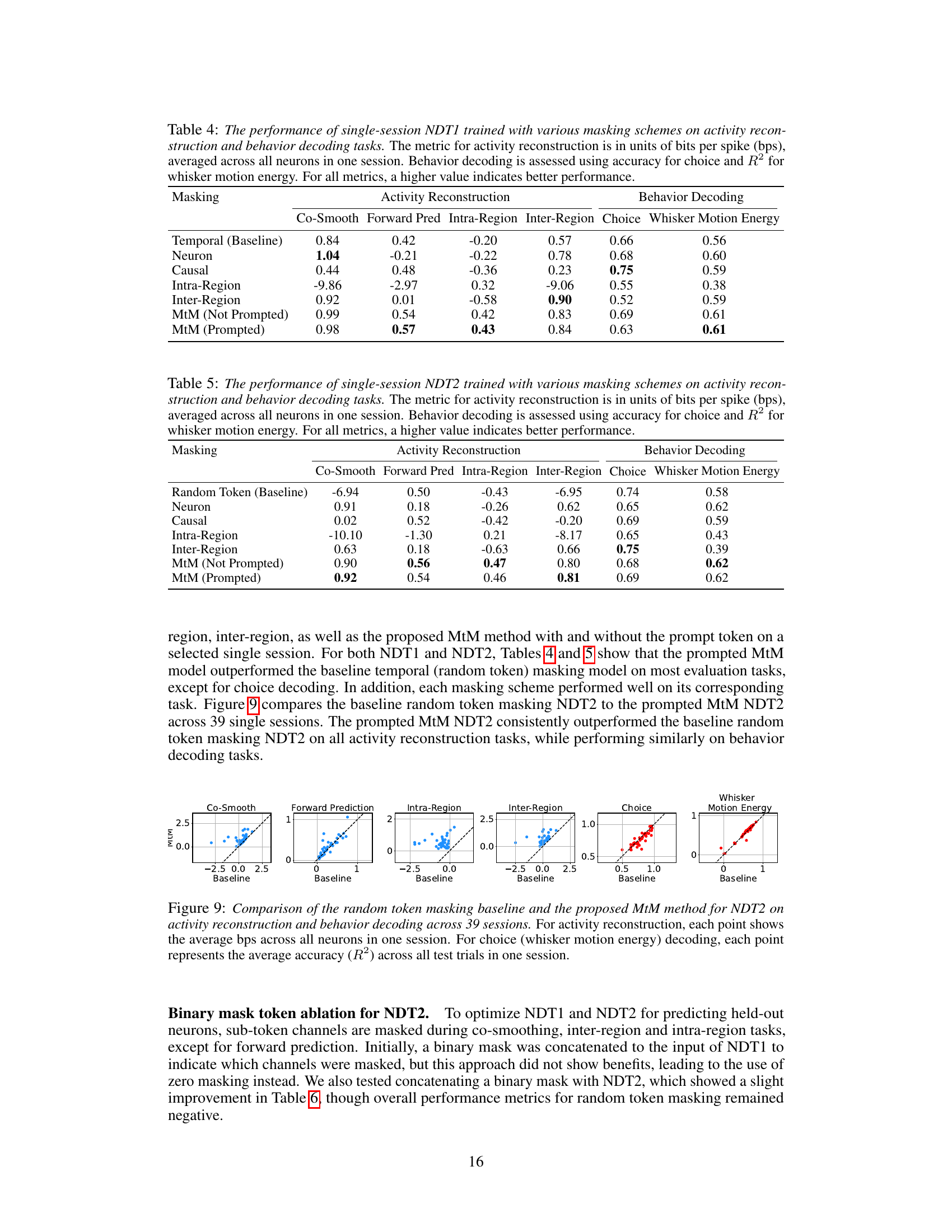
This table presents the results of an ablation study evaluating the performance of single-session Neural Data Transformer 1 (NDT1) when trained using different masking schemes on neural activity reconstruction tasks. The metrics used to evaluate the model’s performance are presented in bits per spike (bps), averaged across all neurons within a single session. Higher bps values indicate better reconstruction performance. The table compares the performance of the baseline temporal masking scheme with neuron, causal, intra-region, inter-region, and multi-task masking (MtM) methods, both with and without prompting. This allows for an assessment of how each masking scheme contributes to the overall performance and whether the multi-task approach improves generalization across different aspects of neural activity.
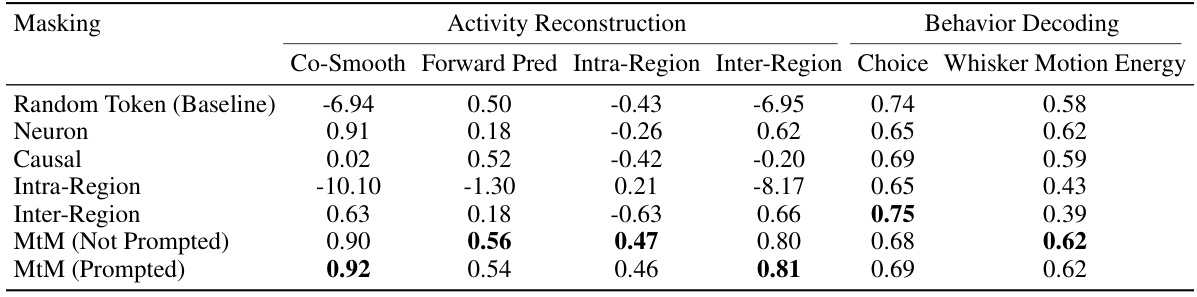
This table presents the results of single-session experiments using the Neural Data Transformer 2 (NDT2) architecture with different masking schemes. It compares the performance of various masking approaches (random token, neuron, causal, intra-region, inter-region, and multi-task masking (MtM) with and without prompting) on activity reconstruction (measured in bits per spike) and behavior decoding tasks (choice accuracy and whisker motion energy R-squared). Higher values indicate better performance for all metrics.

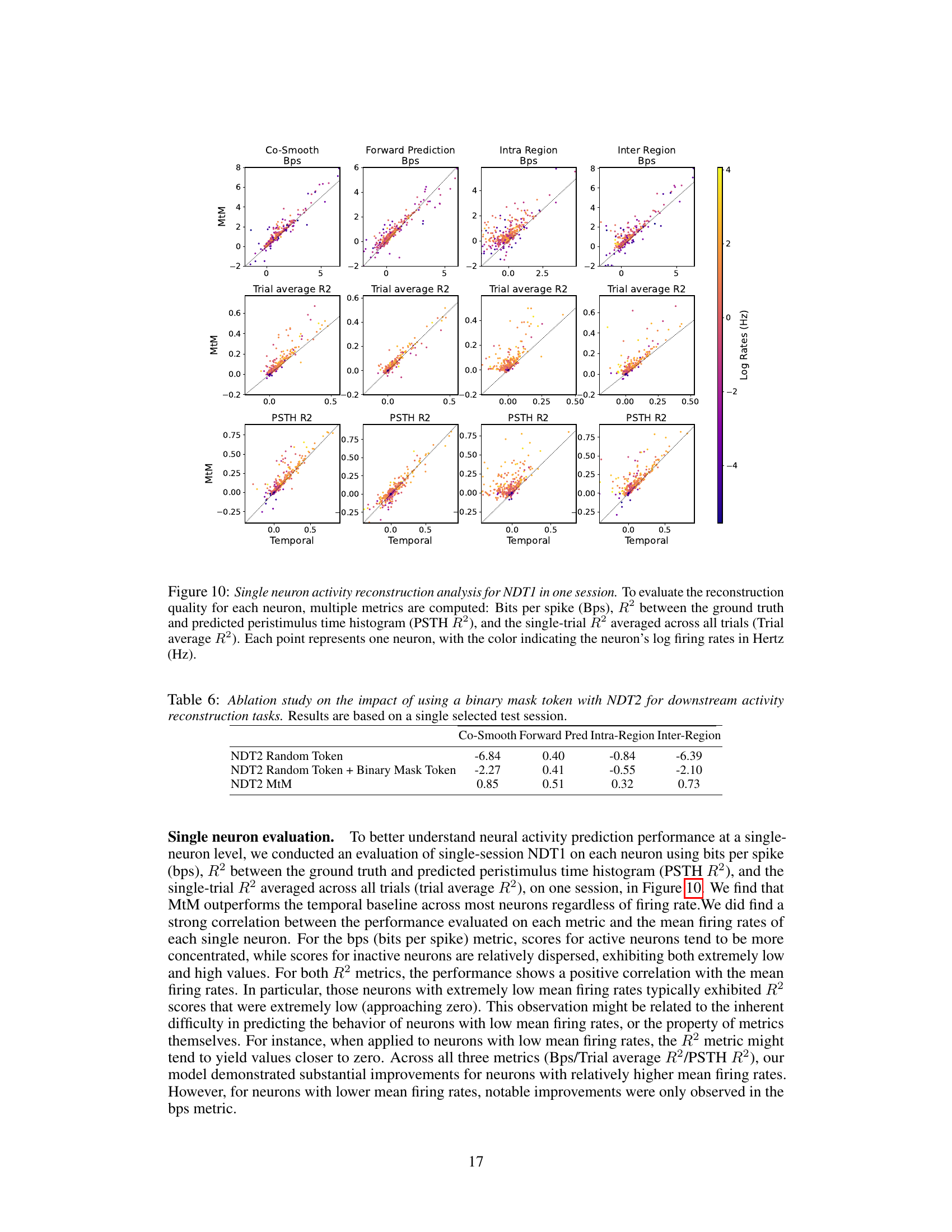
This table shows the ablation study on the impact of adding a binary mask token to NDT2 model for activity reconstruction tasks. It compares the performance of the NDT2 model with random token masking, random token masking plus binary mask token, and MtM (multi-task masking) approach. The results show that MtM significantly improves the performance compared to the baseline, indicating the effectiveness of the multi-task masking approach.

This table presents the results of fine-tuning two different NDT2 models (one pretrained with MtM and the other with random token masking) on five held-out sessions. It compares their performance across multiple metrics, including activity reconstruction (measured in bits per spike) and behavior decoding (measured by accuracy for choice and R-squared for whisker motion energy). The purpose is to show the effectiveness of MtM pre-training on the NDT2 architecture.
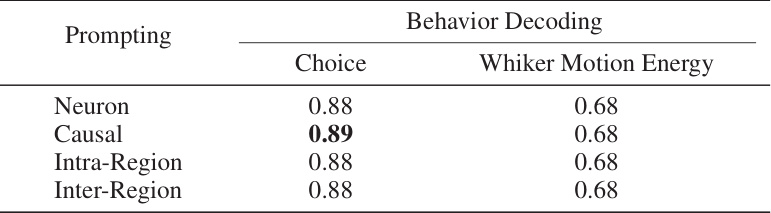
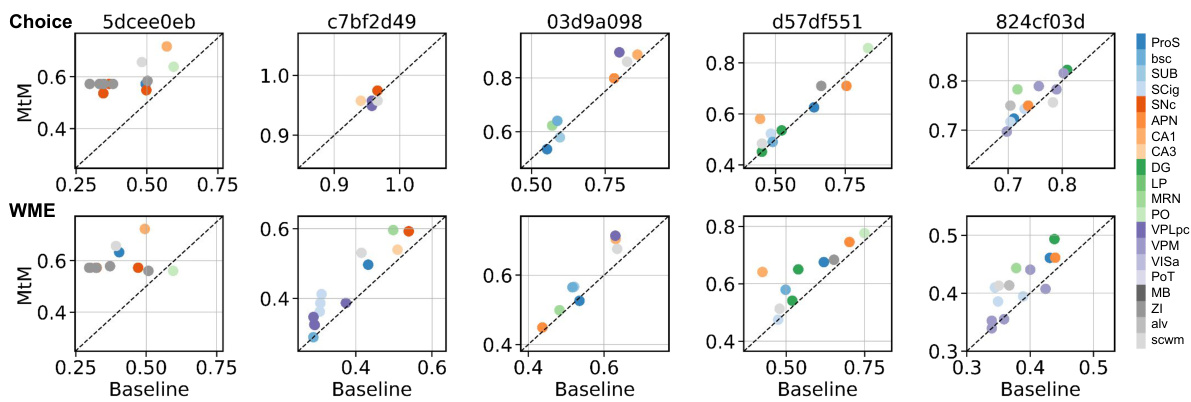
This table shows the result of ablating different prompt tokens used during the inference stage of the NDT1 model. The model was pretrained and fine-tuned using the multi-task masking (MtM) approach. The table compares the performance across four different prompt tokens: ‘Neuron’, ‘Causal’, ‘Intra-Region’, and ‘Inter-Region’ for two downstream tasks: choice decoding (accuracy) and whisker motion energy decoding (R-squared). The metrics are averaged across five held-out sessions.

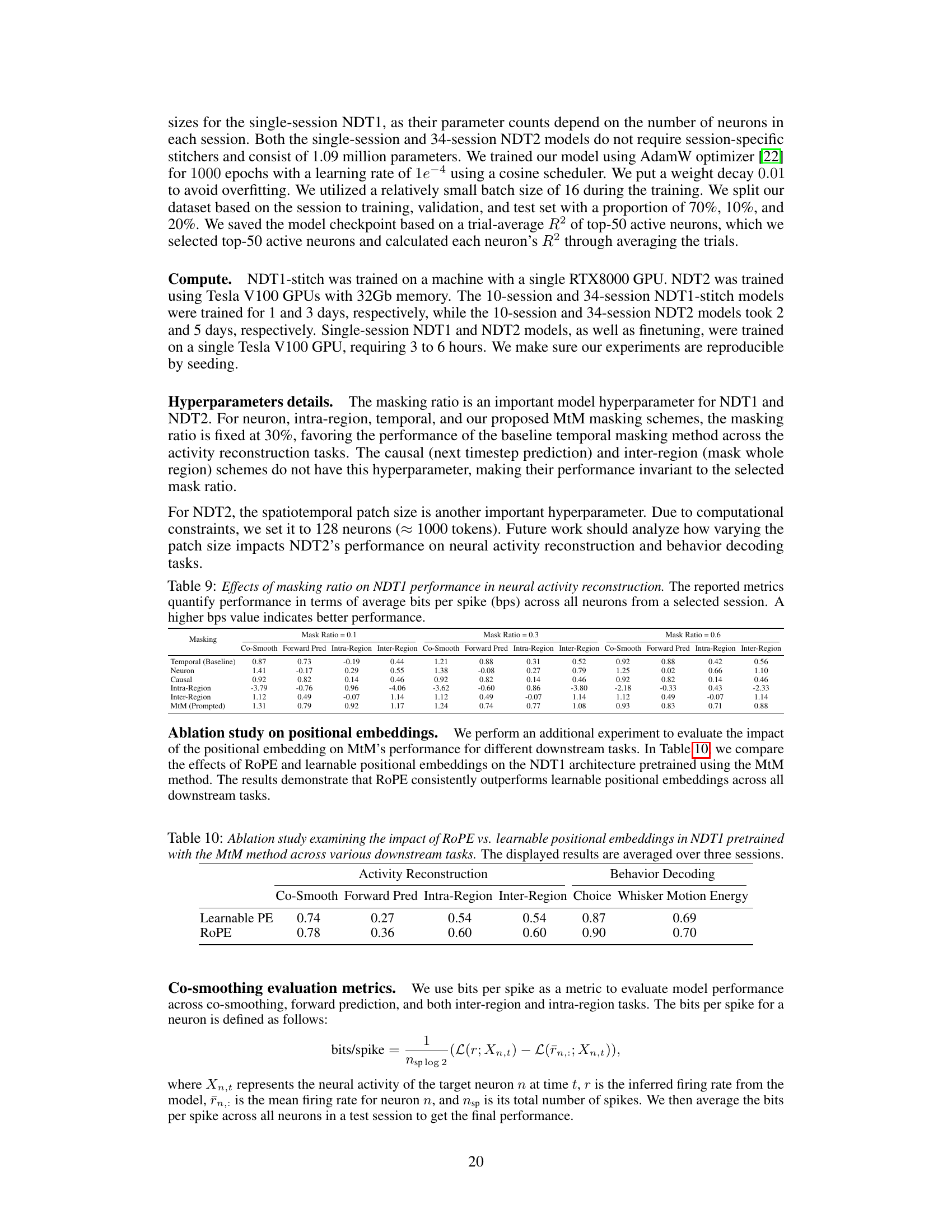
This table shows the impact of different masking ratios (0.1, 0.3, and 0.6) on the performance of the NDT1 model in neural activity reconstruction. The performance is measured using the average bits per spike (bps) metric across all neurons in a single session. Different masking schemes (Temporal (Baseline), Neuron, Causal, Intra-Region, Inter-Region, and MtM (Prompted)) are evaluated under each masking ratio.

This table presents the ablation study on positional embeddings by comparing RoPE (Rotary Positional Embeddings) and learnable positional embeddings. The experiment is performed on the NDT1 architecture pretrained with the MtM (Multi-task Masking) method. The results are averaged over three sessions and show the performance across different downstream tasks (Co-Smooth, Forward Prediction, Intra-Region, Inter-Region, Choice, and Whisker Motion Energy). RoPE consistently outperforms learnable positional embeddings in all downstream tasks.

This table shows the chance level for choice decoding and whisker motion energy decoding for each of the five held-out sessions used in the experiments. The chance level represents the accuracy that would be achieved by randomly guessing the correct choice or whisker motion energy for each trial. The table provides a baseline for comparing the actual decoding performance achieved by the models. The values illustrate that higher-than-chance performance demonstrates meaningful behavioral decoding ability.
Full paper#