TL;DR#
Large Language Models (LLMs) are prone to hallucinations—generating plausible-sounding but factually incorrect information. This significantly limits their applicability. Current datasets for detecting and mitigating these hallucinations are small and unreliable due to the high cost and difficulty of accurate human annotation. This makes it hard to properly study and solve this issue at scale.
The paper introduces ANAH-v2, an iterative self-training framework addressing these issues. It uses an Expectation-Maximization approach, initially training a weak annotator on existing data. Then it iteratively scales the dataset (more data, more models, more topics) and trains increasingly better annotators. The final annotator surpasses GPT-4 in accuracy on several benchmark datasets, providing both a better way to evaluate LLMs and a method for improving them. This approach greatly reduces the reliance on expensive and time-consuming manual annotation.
Key Takeaways#
Why does it matter?#
This paper is crucial because hallucination in LLMs is a significant problem hindering real-world applications. The proposed iterative self-training framework offers a scalable solution for creating high-quality datasets and improving annotation accuracy which is currently very expensive and time-consuming. This opens new avenues for research into hallucination mitigation and LLM evaluation, significantly impacting the field.
Visual Insights#
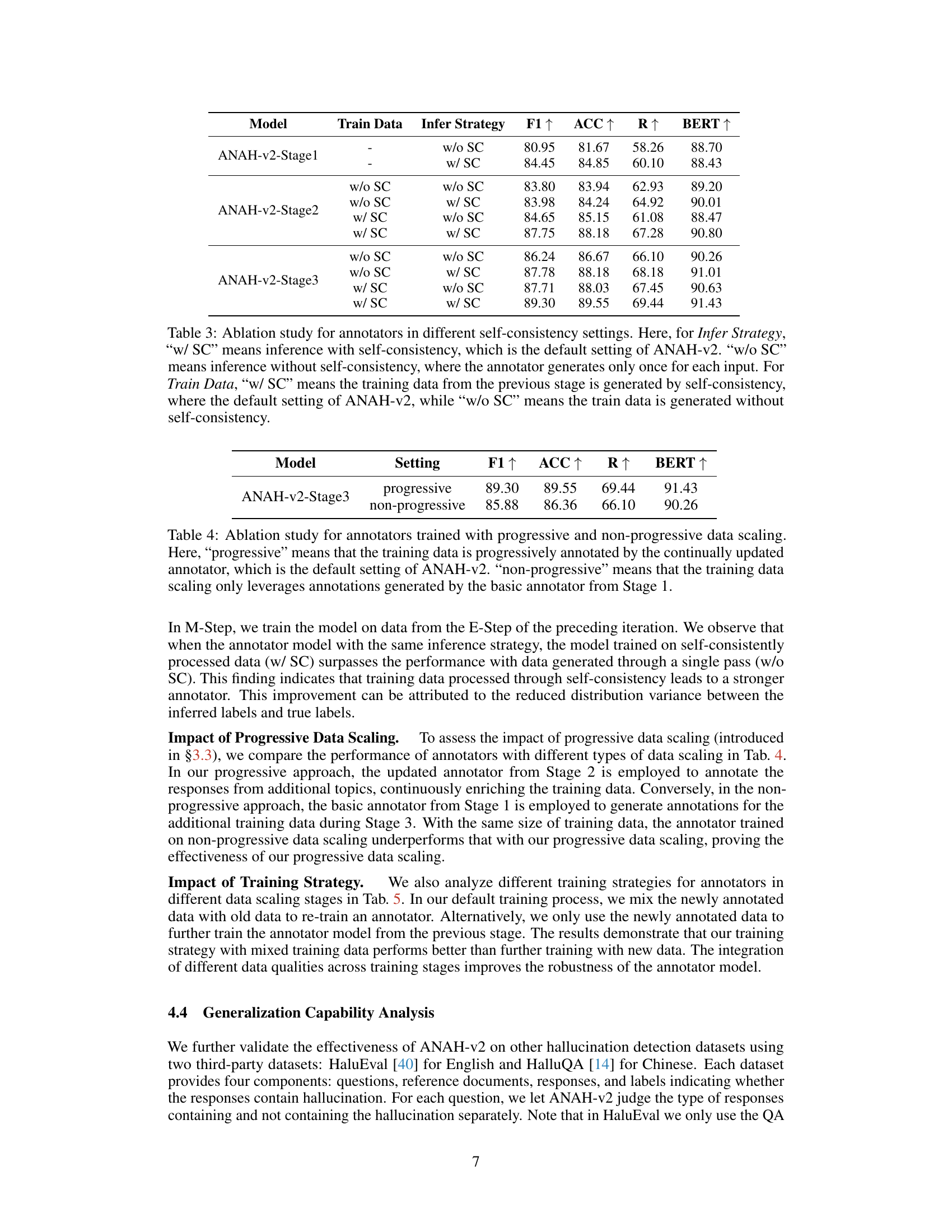
🔼 This figure illustrates the iterative self-training framework used in the paper. It shows how the dataset size and annotator accuracy improve over three stages. Stage 1 starts with a small dataset and a weak annotator. Stage 2 increases the dataset size by adding more responses and trains a stronger annotator. Stage 3 further expands the dataset by adding more topics and results in an ultra annotator that surpasses GPT-4 in accuracy. The figure visually represents the framework’s iterative process of scaling up both the data and the model’s performance.
read the caption
Figure 1: Our iterative self-training framework progressively scales up the hallucination annotation dataset size (left) and simultaneously increases the annotator's accuracy (right) in three stages.
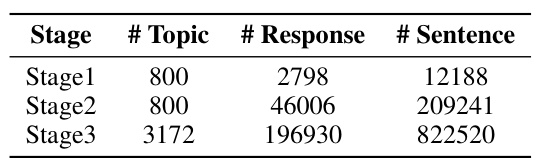
🔼 This table shows the dataset size used in each of the three stages of the ANAH-v2 iterative self-training framework. It details the number of topics, model responses (answers from LLMs), and the total number of sentences annotated for each stage. This illustrates the growth of the dataset throughout the iterative process.
read the caption
Table 1: The dataset size for ANAH-v2 in different stages, including the number of topics, model responses, and annotated sentences.
In-depth insights#
Iterative Self-Training#
Iterative self-training, as a method, presents a powerful approach to scaling data annotation and enhancing model performance. By iteratively refining annotations through an automated pipeline and using improved models for subsequent annotation, the process transcends limitations of manual approaches. The EM algorithm provides a robust framework, ensuring gradual improvements in annotation quality and model accuracy. This is crucial because high-quality datasets are vital for successful training, and iterative self-training addresses the prohibitive costs and challenges of creating large-scale datasets manually. However, the approach’s success hinges on the initial annotator’s quality and the iterative process’s stability. Challenges may include achieving convergence and addressing biases present in initial datasets. Despite these potential challenges, the multi-dimensional scaling strategy employed enhances the generalizability and robustness of the trained models, addressing a key limitation of existing hallucination mitigation approaches. This iterative method provides a compelling, cost-effective alternative for tasks such as hallucination annotation in LLMs, impacting research in NLP significantly.
Hallucination Annotation#
Hallucination annotation in large language models (LLMs) is a crucial yet challenging task. It involves identifying and classifying instances where the LLM generates factually incorrect or nonsensical information. This process is complex because hallucinations can be subtle, plausible, and context-dependent, making manual annotation expensive and time-consuming. To address this, researchers are exploring automated methods, which often leverage external knowledge bases or other LLMs to verify the LLM’s outputs. However, these automated methods can be prone to errors and may not capture the nuances of human judgment. The reliability of annotators, whether human or automated, is a critical issue impacting the accuracy and effectiveness of any downstream applications such as hallucination detection and mitigation. Consequently, developing robust and scalable hallucination annotation methods is vital for ensuring the responsible development and deployment of LLMs.
Multi-Dimensional Scaling#
Multi-dimensional scaling, in the context of a research paper focusing on large language model (LLM) hallucination annotation, likely refers to a strategy for expanding the dataset used to train and evaluate hallucination detection models. Instead of simply increasing the number of examples, a multi-dimensional approach would involve scaling across various dimensions to enhance the dataset’s richness and diversity. This could include increasing the number of questions, the number of LLMs used to generate answers, the number of topics covered, and the number of languages included. Such a multi-faceted approach is crucial because LLMs exhibit hallucinations across a wide spectrum of domains and contexts. Therefore, a robust dataset should represent this diversity to create a more generalizable and effective hallucination detection model. The iterative nature of many such frameworks often sees the initial stage start with a relatively small dataset, which is then progressively augmented in multiple dimensions across several stages, improving both the size and quality of the data that trains the annotator model, ultimately leading to more reliable and precise annotation of LLM hallucinations.
Hallucination Mitigation#
The research explores various strategies for mitigating hallucinations in large language models (LLMs). One primary challenge is the high cost and labor intensity of creating comprehensive datasets for accurate assessment of hallucinations. The paper proposes an iterative self-training framework to simultaneously address both data scaling and annotator accuracy. Hallucination mitigation is approached as a re-ranking problem: The LLM generates multiple candidate responses, and the annotator selects the response with the lowest hallucination rate, demonstrating a practical, efficient method for improving factual accuracy. While existing methods focused on model editing or additional training are mentioned, the re-ranking approach offers a less computationally expensive alternative. The study’s focus on zero-shot performance on benchmark datasets further highlights the potential for broad application and ease of integration into existing LLM workflows. The improvement of Natural Language Inference metrics from 25% to 37% showcases a notable impact. Although computational costs for training the annotator are acknowledged, the overall approach represents a promising, efficient solution to the ongoing challenge of LLM hallucination.
Future Work#
The authors propose several avenues for future research, focusing on scalability and generalizability. Extending the dataset to encompass diverse languages and tasks is crucial, acknowledging the current limitations of English-centric datasets. A key area of improvement is enhancing the robustness of the hallucination annotator across various domains and models, potentially by exploring architectural improvements or training techniques. Improving the integration of the proposed annotator with existing hallucination mitigation strategies such as RLHF is highlighted, suggesting this is a fruitful area of interdisciplinary research. Investigating the applicability of the self-training framework to other NLG tasks like dialogue generation is also suggested, reflecting a broader ambition to enhance the overall quality of language model outputs. Finally, the potential of this work for mitigating the negative societal impacts of large language models is implicitly mentioned, offering a direction toward responsible AI development.
More visual insights#
More on figures
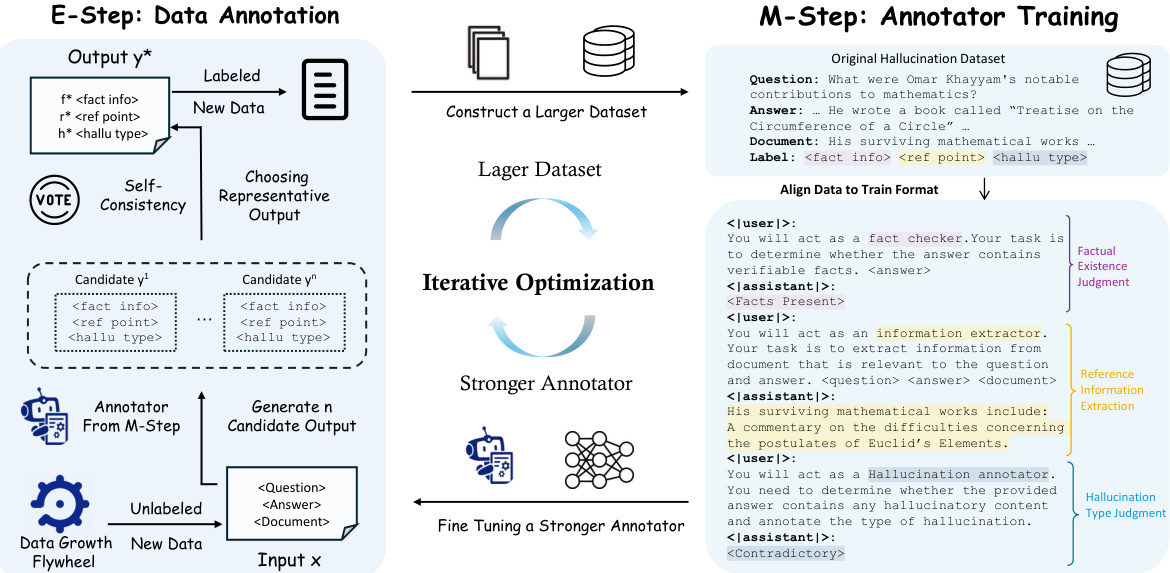
🔼 This figure illustrates the Expectation-Maximization (EM) based iterative self-training framework used in the paper. The E-step focuses on automatically annotating a larger dataset using the current best annotator and a self-consistency strategy to select the most reliable annotation for each data point. This produces a larger, improved dataset. The M-step uses this larger dataset to train a more accurate annotator. This process iterates, progressively scaling the dataset and improving annotation accuracy. The annotation process itself is broken down into three phases: Factual Existence Judgment, Reference Information Extraction, and Hallucination Type Judgment.
read the caption
Figure 2: The schema of EM-based interactive self-training framework. In the E-step, given unlabeled new data from the Data Growth Flywheel, the annotator predicts N candidate outputs y. Then the representative annotation y* is chosen via self-consistency. As a result, we construct a larger dataset by collecting the new annotations. In the M-step, we train an annotator on the larger dataset aligned to our training format. This annotation process consists of three phases: Factual Existence Judgment, Reference Information Extraction, and Hallucination Type Judgment. As a result, we gain a stronger annotator with higher accuracy.
🔼 The figure illustrates the iterative self-training framework used in the paper. It shows how the dataset size increases through three stages, leading to improved annotator accuracy. The left side depicts the growth of the dataset size, starting small and increasing to a massive dataset. The right side shows the corresponding increase in annotator accuracy, starting with a weak annotator and progressing to a strong annotator. This framework is based on the Expectation Maximization algorithm, where each iteration involves an expectation step (annotating a scaled dataset) and a maximization step (training a new, more accurate annotator).
read the caption
Figure 1: Our iterative self-training framework progressively scales up the hallucination annotation dataset size (left) and simultaneously increases the annotator's accuracy (right) in three stages.
More on tables
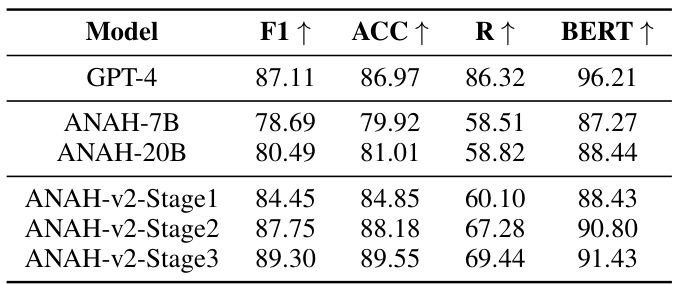
🔼 This table presents the performance comparison of three different models: GPT-4, ANAH, and ANAH-v2 across three stages of development. The metrics used are F1 score, Accuracy, RougeL (R), and BERTScore (BERT). Higher scores in F1, Accuracy, R, and BERT indicate better performance. The table shows that the performance of ANAH-v2 improves significantly across stages, eventually surpassing GPT-4 in F1 score and Accuracy.
read the caption
Table 2: Evaluation results for GPT4, ANAH, and ANAH-v2 at each stage, where “R” and “BERT”, refer to 'RougeL' and 'BERTScore', respectively.
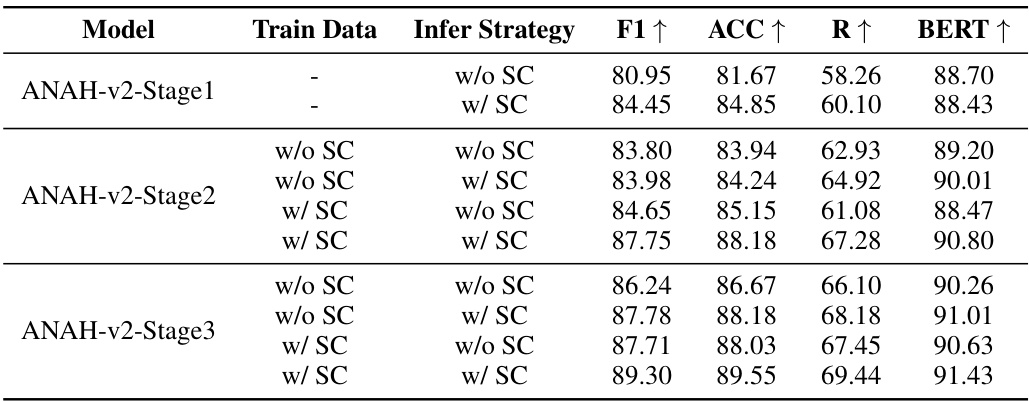
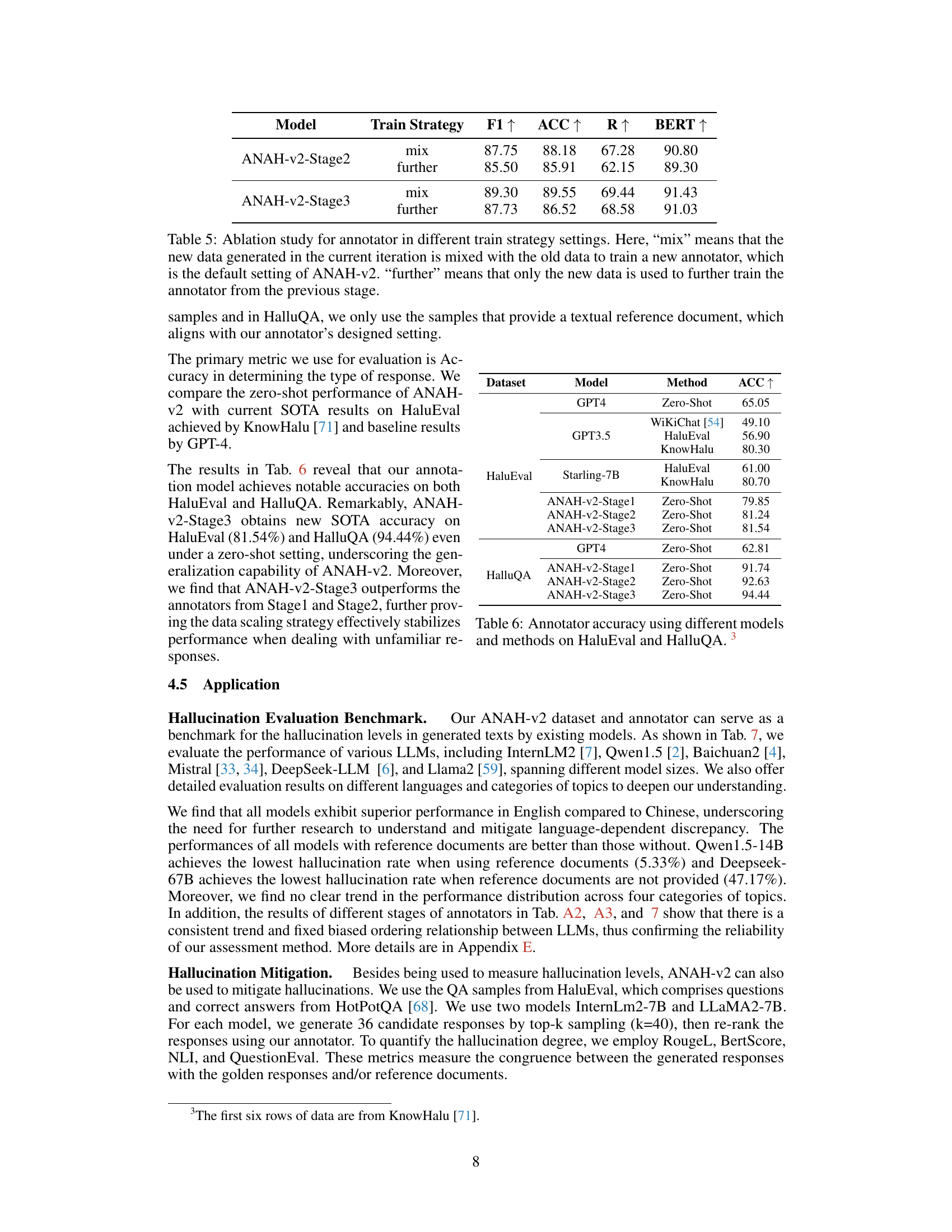
🔼 This table presents the ablation study on the impact of self-consistency in both inference and training phases of the ANAH-v2 model across three stages. It compares the performance metrics (F1, ACC, R, BERT) when self-consistency is used versus when it is not, showing its effect on the accuracy and stability of hallucination annotation.
read the caption
Table 3: Ablation study for annotators in different self-consistency settings. Here, for Infer Strategy, 'w/ SC' means inference with self-consistency, which is the default setting of ANAH-v2. 'w/o SC' means inference without self-consistency, where the annotator generates only once for each input. For Train Data, 'w/ SC' means the training data from the previous stage is generated by self-consistency, where the default setting of ANAH-v2, while 'w/o SC' means the train data is generated without self-consistency.

🔼 This table presents the ablation study comparing the performance of annotators trained with two different data scaling strategies: progressive and non-progressive. The progressive strategy uses a continually updated annotator to annotate the training data, while the non-progressive strategy uses only the basic annotator from the first stage. The results show that the progressive approach leads to better performance.
read the caption
Table 4: Ablation study for annotators trained with progressive and non-progressive data scaling. Here, 'progressive' means that the training data is progressively annotated by the continually updated annotator, which is the default setting of ANAH-v2. “non-progressive” means that the training data scaling only leverages annotations generated by the basic annotator from Stage 1.
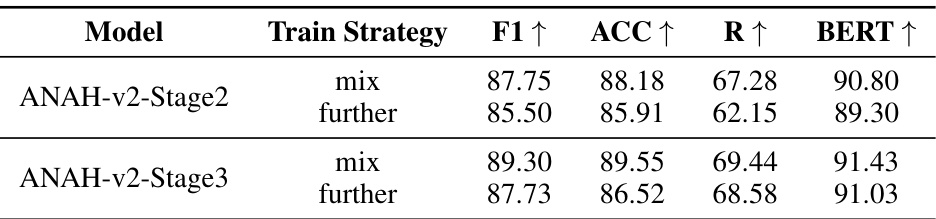
🔼 This table presents the ablation study on different training strategies for the hallucination annotator. The table compares two training strategies: ‘mix’, where new and old data are mixed for training, and ‘further’, where only new data is used for further training of the annotator from the previous stage. The results for each stage (Stage 2 and Stage 3) are presented separately and demonstrate that the ‘mix’ strategy consistently outperforms the ‘further’ strategy in terms of F1 score, accuracy, RougeL score, and BERTScore.
read the caption
Table 5: Ablation study for annotator in different train strategy settings. Here, “mix” means that the new data generated in the current iteration is mixed with the old data to train a new annotator, which is the default setting of ANAH-v2. “further” means that only the new data is used to further train the annotator from the previous stage.
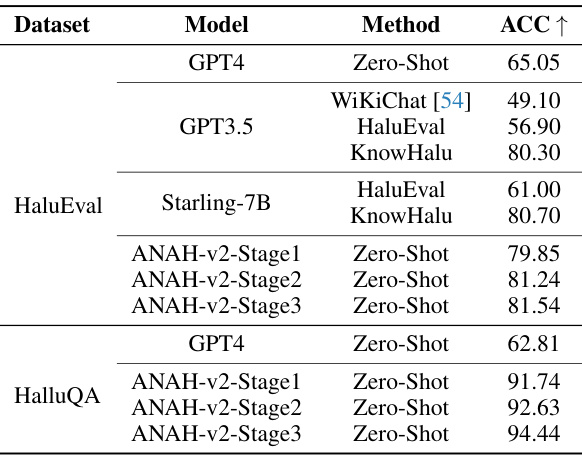
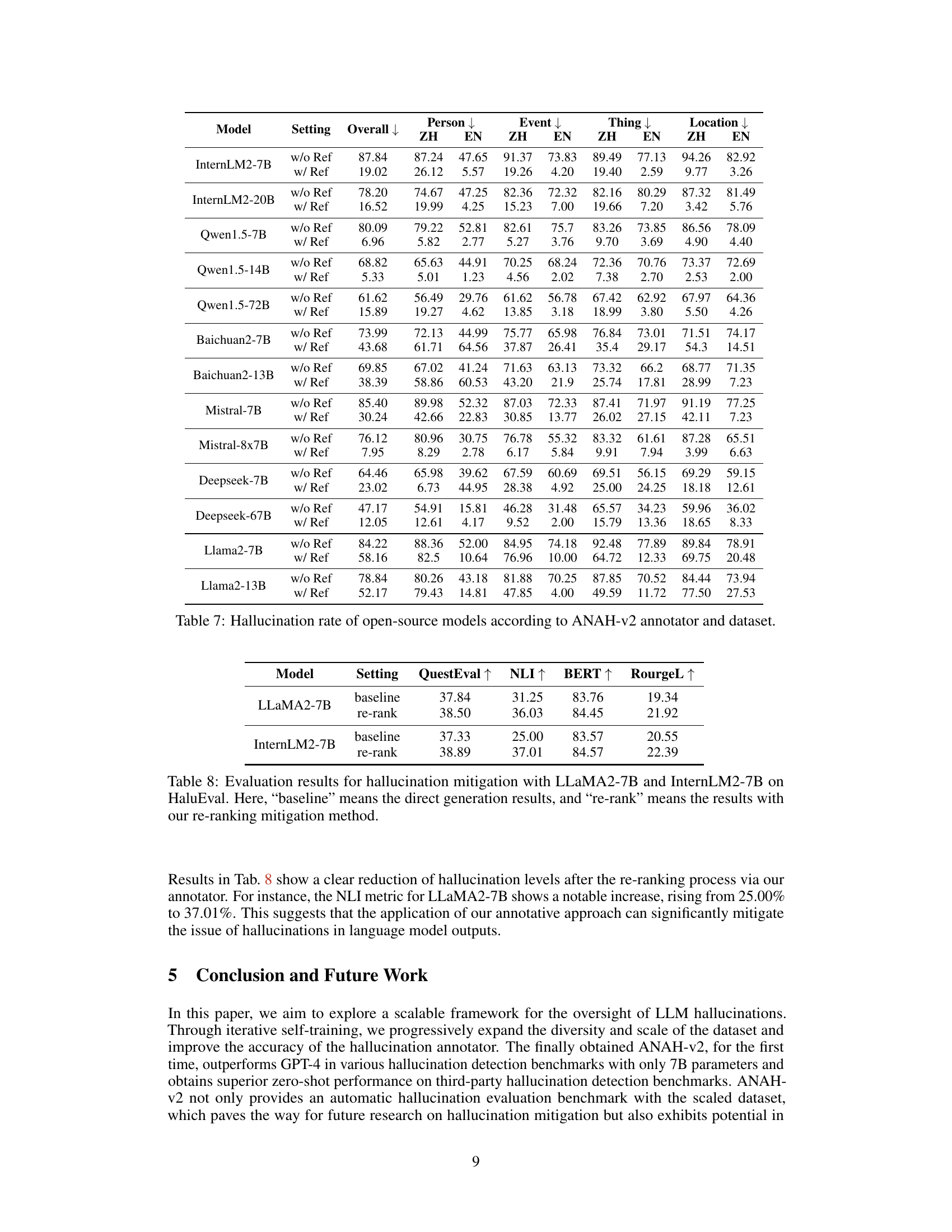
🔼 This table presents the zero-shot accuracy results of different models on two benchmark datasets: HaluEval and HalluQA. The models include GPT4, GPT3.5, Starling-7B, and the ANAH-v2 annotator at different stages of training. The methods used are zero-shot inference and WiKiChat for comparison, showcasing the performance of ANAH-v2 compared to existing state-of-the-art methods. The ACC↑ column indicates the accuracy of the models. Higher accuracy signifies better performance in identifying hallucinations.
read the caption
Table 6: Annotator accuracy using different models and methods on HaluEval and HalluQA.
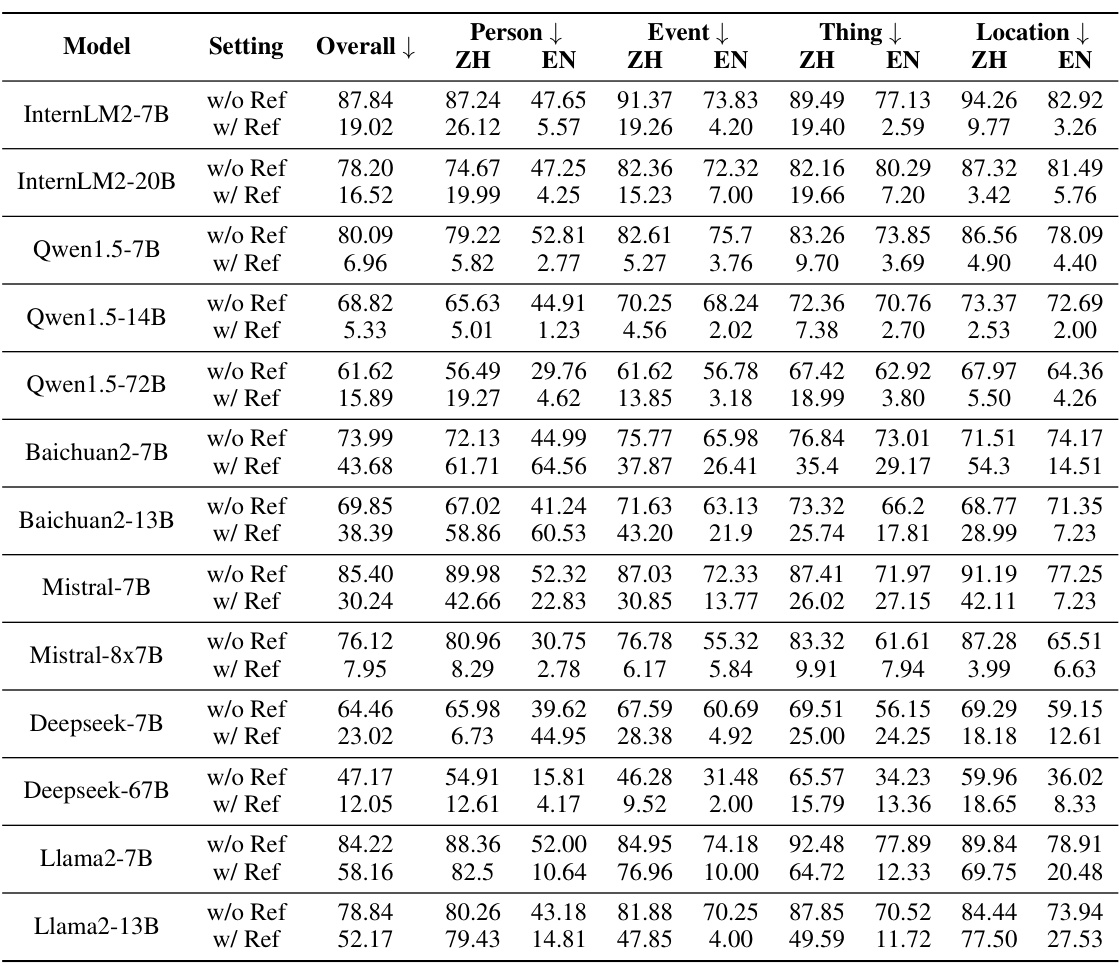
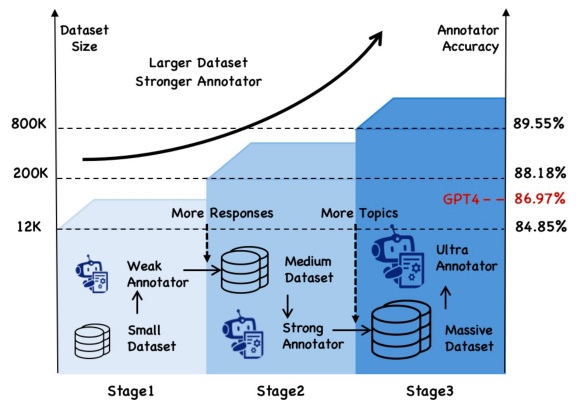
🔼 This table presents the hallucination rates of various open-source large language models (LLMs) evaluated using the ANAH-v2 annotator and dataset. The results are categorized by model, setting (with or without reference documents), and domain (overall, person, event, thing, location), further broken down by language (Chinese and English). It shows the performance of each model in different scenarios and aspects, highlighting variations based on the access to reference material and the type of topic.
read the caption
Table 7: Hallucination rate of open-source models according to ANAH-v2 annotator and dataset.
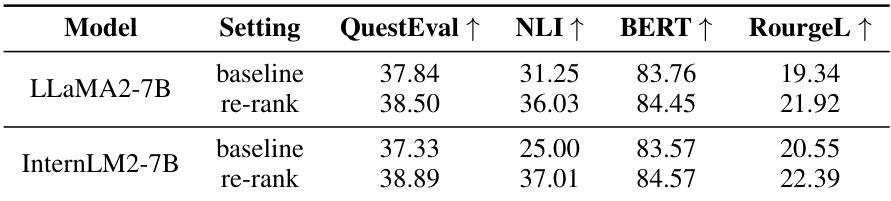
🔼 This table presents the results of a hallucination mitigation experiment using two different language models, LLaMA2-7B and InternLM2-7B. The experiment compares the performance of the models before and after applying a re-ranking mitigation strategy. The metrics used for evaluation include QuestEval, NLI, BERTScore, and RougeL, all of which measure different aspects of language model quality and relevance to the reference content. Higher scores generally indicate better performance. The results show that the re-ranking method leads to improvements in all four metrics for both models, suggesting its effectiveness in reducing hallucinations.
read the caption
Table 8: Evaluation results for hallucination mitigation with LLaMA2-7B and InternLM2-7B on HaluEval. Here, 'baseline' means the direct generation results, and “re-rank” means the results with our re-ranking mitigation method.
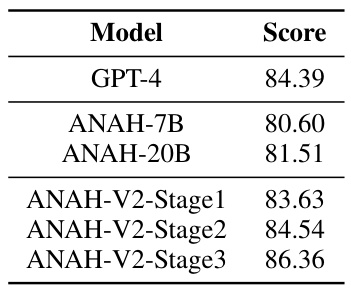
🔼 This table presents the results of an LLM-based evaluation designed to assess the consistency of generated reference points with the source documents. The evaluation aims to determine whether the reference points produced by the model accurately reflect the information present in the source document, rather than simply relying on metrics like ROUGE-L or BERTScore which measure similarity without necessarily validating factual accuracy. The table shows that the reliability of the generated reference points progressively improves with each stage of the iterative self-training framework.
read the caption
Table A1: The score assessing the consistency of generated reference points with the source documents.
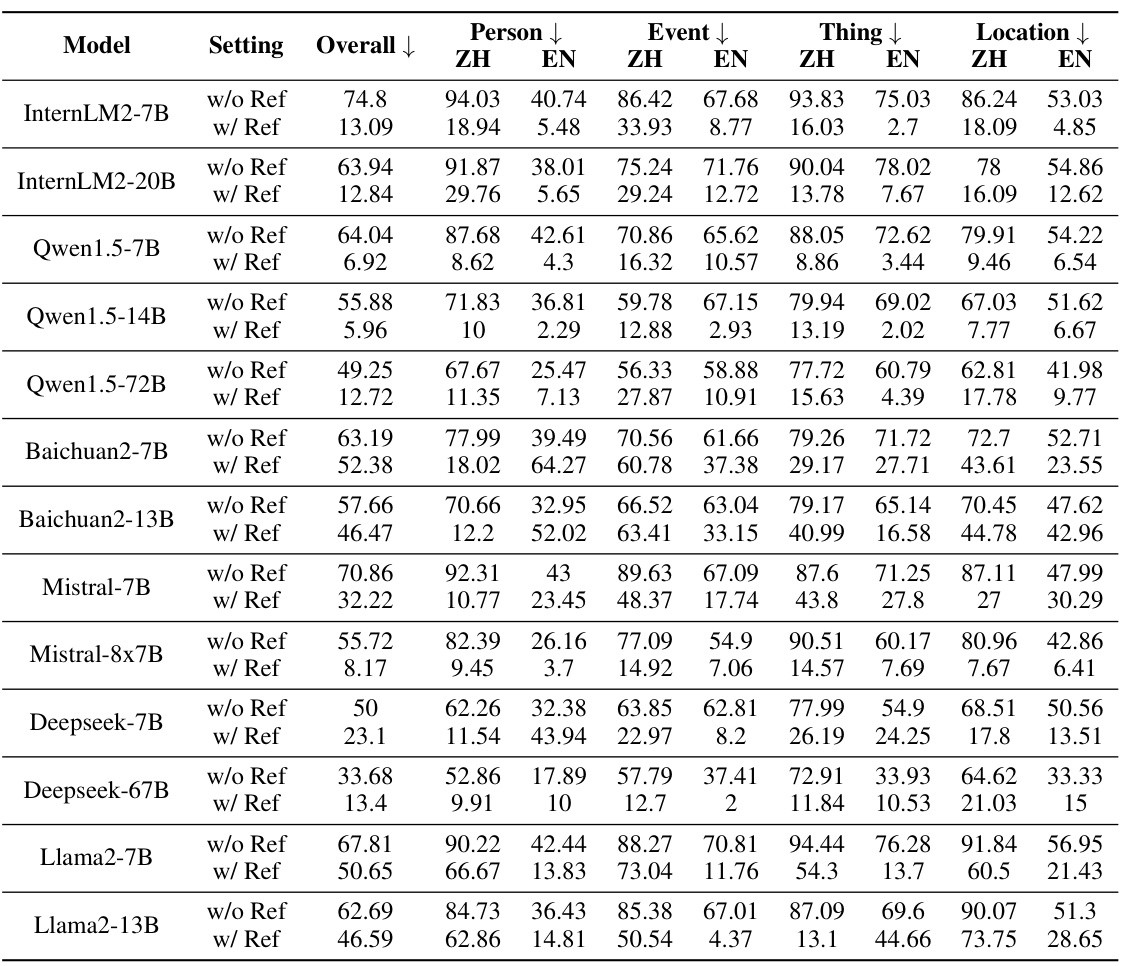
🔼 This table presents the hallucination rates of various open-source LLMs evaluated using the ANAH-v2 annotator and dataset. The results are broken down by model, setting (with or without reference documents), overall hallucination rate, and hallucination rates for four specific categories (Person, Event, Thing, Location). Both English (EN) and Chinese (ZH) language results are included for each category, providing a comprehensive view of LLM performance across different languages and topic domains.
read the caption
Table 7: Hallucination rate of open-source models according to ANAH-v2 annotator and dataset.
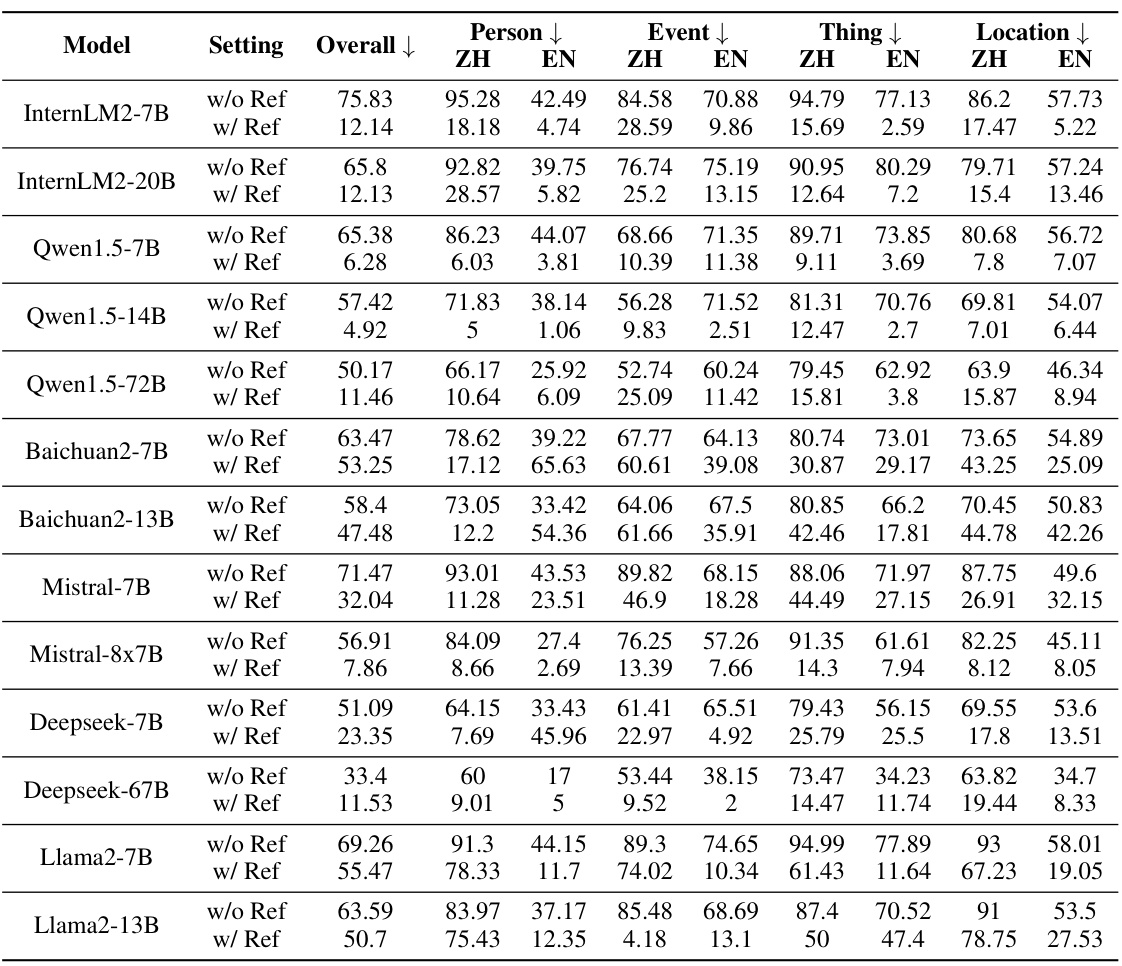
🔼 This table presents the hallucination rates of various open-source large language models (LLMs) evaluated using the ANAH-v2 annotator. The results are broken down by language (ZH for Chinese, EN for English), model, whether a reference document was used during generation (w/ Ref or w/o Ref), and four topic categories (Person, Event, Thing, Location). Higher percentages indicate higher hallucination rates.
read the caption
Table 7: Hallucination rate of open-source models according to ANAH-v2 annotator and dataset.
Full paper#