TL;DR#
Current video diffusion models suffer from slow sampling and poor frame quality due to limitations in training data. Applying image diffusion distillation techniques directly often results in unsatisfactory results. There is a need for a method that efficiently distills knowledge from high-quality image data to improve both the speed and the visual quality of video diffusion models.
The proposed Motion Consistency Model (MCM) tackles this challenge via a single-stage approach that disentangles motion and appearance learning. This is achieved using two key techniques: disentangled motion distillation, which focuses on motion representation, and mixed trajectory distillation that mitigates training-inference discrepancies by using a mix of low- and high-quality trajectories. Extensive experiments demonstrate that MCM achieves state-of-the-art performance in video diffusion distillation, producing high-quality videos with significantly fewer sampling steps. The results demonstrate the effectiveness of MCM in enhancing both speed and quality of video generation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to video diffusion distillation, a critical area in AI research. It addresses the limitations of existing methods by enhancing frame quality and accelerating video generation, leading to improved efficiency and visual results. Researchers can leverage the proposed motion consistency model (MCM) and its techniques (disentangled motion distillation and mixed trajectory distillation) to develop more efficient and visually appealing video generation models. This work opens new avenues for research in video generation and other related areas such as style transfer and video editing.
Visual Insights#

🔼 This figure compares the qualitative results of video generation using three different models: the teacher model (ModelScopeT2V), the Latent Consistency Model (LCM), and the proposed Motion Consistency Model (MCM). The teacher model generated high-quality videos, but required 50 sampling steps. LCM produced improved results with fewer sampling steps, however, still exhibiting some artifacts. MCM outperforms both, producing even higher-quality videos with very few sampling steps and demonstrates style adaptation capabilities by training with additional image datasets.
read the caption
Figure 1: Qualitative result comparisons with latent consistency model (LCM) [38] using ModelScopeT2V [62] as teacher. Our MCM outputs clearer video frames using few-step sampling, and can also adapt to different image styles using additional image datasets. Corresponding video results are in supplementary materials.
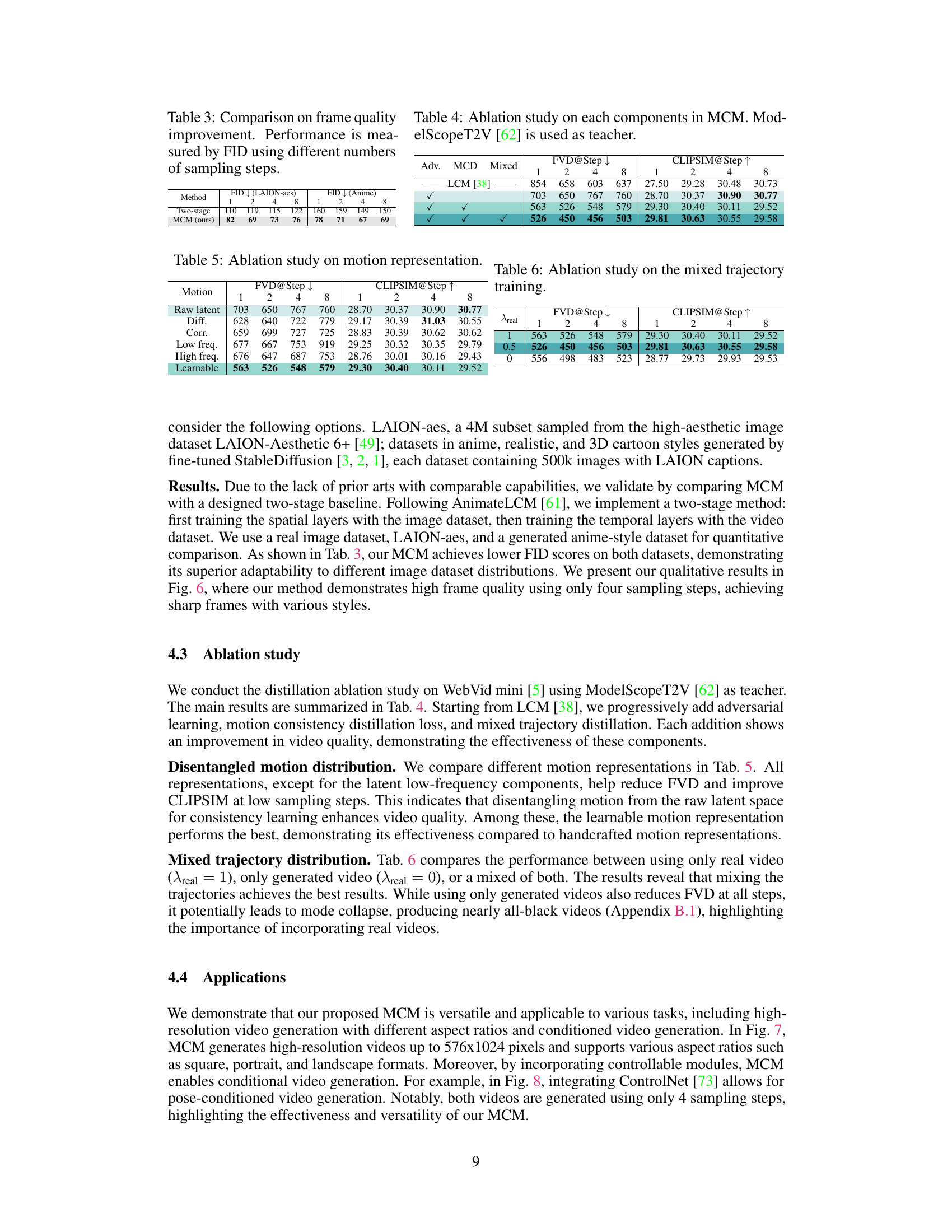
🔼 This table presents a comparison of different video diffusion distillation methods on the WebVid mini validation dataset. It shows the Fréchet Video Distance (FVD) and CLIP similarity (CLIPSIM) scores for various methods at different sampling steps (1, 2, 4, 8). Lower FVD indicates better video quality, while higher CLIPSIM signifies better alignment between generated videos and text prompts. The results are categorized by the teacher model used (AnimateDiff and ModelScopeT2V) and include baselines (DDIM, DPM++) and other distillation methods (LCM, AnimateLCM, AnimateDiff-Lightning) for comparison with the proposed MCM method.
read the caption
Table 1: Video diffusion distillation comparison on the WebVid mini validation set.
In-depth insights#
Motion Distillation#
Motion distillation, in the context of video diffusion models, presents a unique challenge: effectively transferring temporal dynamics from a teacher model to a student model. A naive approach might struggle due to the complexity of motion representation and the potential for inconsistencies between training and inference. Disentangling motion from appearance is crucial, allowing for separate optimization of these distinct aspects. This enables focusing the distillation process on the temporal information, improving efficiency and mitigating the risk of overfitting to low-quality training data. Addressing discrepancies between training and inference is key. Techniques like mixed trajectory distillation, which combines low and high-quality trajectories, aim to reduce this gap, resulting in more robust and effective student models. The choice of motion representation is also vital; effective choices would accurately capture temporal dynamics without excessive computational overhead. This approach ultimately accelerates video generation while maintaining or enhancing the quality of the generated frames.
Adversarial Learning#
Adversarial learning, in the context of the provided research paper, likely plays a crucial role in enhancing the quality of generated video frames. By pitting a generator network against a discriminator network, the adversarial process pushes the generator to produce increasingly realistic and high-quality outputs. The discriminator acts as a critic, identifying flaws and inconsistencies in the generated videos, driving the generator to improve. This approach is particularly valuable in video diffusion models, which often struggle with generating visually compelling frames. The use of adversarial learning in video generation models is likely coupled with a dataset of high-quality images. This allows the discriminator to learn the characteristics of realistic visuals, providing a more robust benchmark for the generator. The effectiveness of this method may also depend heavily on the architecture and training strategies implemented for both the generator and discriminator. Ultimately, adversarial learning represents a powerful technique to improve the realism and aesthetic quality of video generated via diffusion processes, especially when combined with high-quality training data and a carefully designed architecture.
Mixed Trajectory#
The concept of “Mixed Trajectory” in video diffusion distillation addresses the discrepancy between training and inference phases. During training, the model learns from low-quality video data, while inference uses higher-quality generated samples. This mismatch leads to performance degradation. To mitigate this, mixed trajectory distillation simulates high-quality trajectories during training. This simulation involves generating high-quality samples and then adding noise, mimicking the inference process. By mixing these simulated high-quality trajectories with real low-quality ones, the model better bridges the gap between training and inference. This approach is crucial because it enhances the model’s ability to generalize and produce high-quality results during inference. The key benefit is that it leads to a more robust and accurate model that performs well even when encountering data different from its training set. By blending trajectories, the mixed approach prevents overfitting to the limited low-quality training data, resulting in improved video generation.
Frame Quality#
The concept of ‘Frame Quality’ in video generation models is paramount, directly impacting user experience and the overall success of the application. The authors highlight a critical challenge: existing public video datasets often suffer from inferior frame quality, including low resolution, motion blur, and watermarks. This directly affects the performance of both teacher and student models in distillation processes. The paper proposes several novel methods to tackle this problem, including disentangling motion and appearance learning to mitigate conflicts in training objectives. Furthermore, the paper introduces mixed trajectory distillation to address inconsistencies between training and inference, thereby ensuring high-quality frame generation even with limited training data. Leveraging high-quality image datasets as an auxiliary training source is also explored as a means of enhancing the visual appeal of the generated frames. This multi-pronged approach represents a significant advancement in achieving improved frame quality within video diffusion models. The overall success hinges on effectively addressing the limitations imposed by low-quality training data.
Video Diffusion#
Video diffusion models represent a significant advancement in video generation, building upon the successes of image diffusion models. They offer the potential for high-fidelity video synthesis, but face challenges like high computational cost and the need for substantial training data. The core idea revolves around progressively adding noise to a video until it becomes pure noise, and then learning a reverse process to reconstruct the video from this noise. Disentangling motion and appearance is a key area of research to improve generation quality and efficiency, as is the use of distillation techniques to create faster, lighter models. However, publicly available video datasets are often of lower quality than image datasets, which impacts model performance. Therefore, data augmentation and other methods for improving the quality and quantity of training data are crucial for further progress. Successfully addressing these challenges will unlock the potential of video diffusion models for applications across various domains.
More visual insights#
More on figures

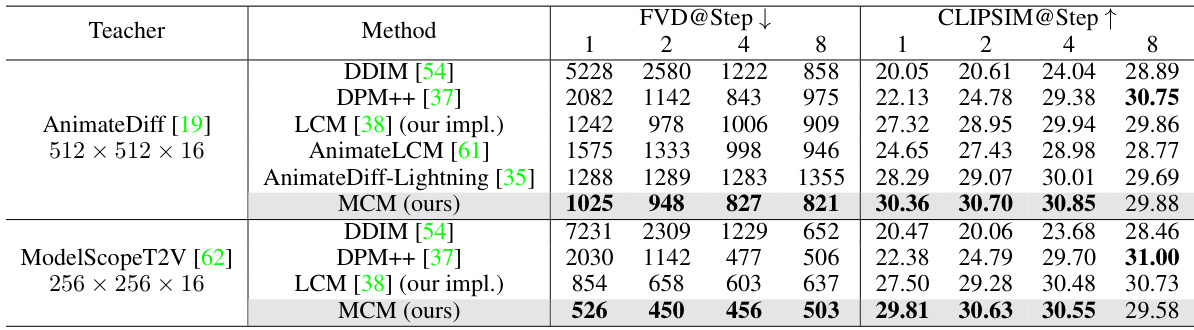
🔼 This figure illustrates the motion consistency model (MCM) distillation process. It shows how a teacher model (T2V Teacher) generates low-quality video frames with slow sampling due to its reliance on low-quality video data. The MCM then takes this low-quality output and high-quality image data as input and distills both the motion and appearance information. This results in a student model (T2V Student) which generates high-quality video frames at a much faster sampling speed.
read the caption
Figure 2: Illustration of our motion consistency model distillation process, which not only distills the motion prior from teacher to accelerate sampling, but also can benefit from an additional high-quality image dataset to improve the frame quality of generated videos.
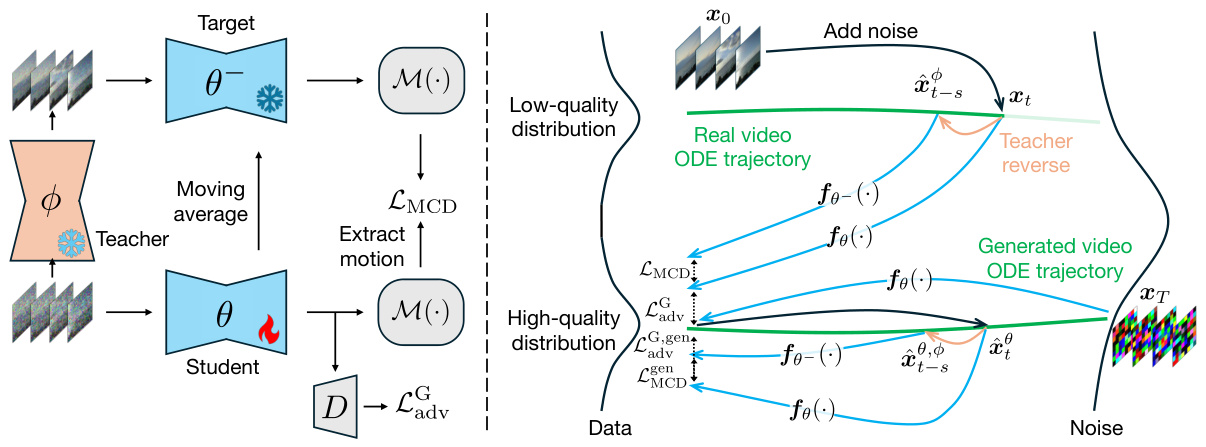
🔼 This figure illustrates the architecture of the Motion Consistency Model (MCM). The left panel shows the disentangled motion-appearance distillation process. The motion component is distilled from the teacher model using the motion consistency distillation loss (LMCD), while the appearance is learned using the frame adversarial loss (Ladv). The right panel depicts the mixed trajectory distillation. Here, both real video ODE trajectories and simulated trajectories (generated by the student model) are used for training to reduce training-inference discrepancy.
read the caption
Figure 3: Left: framework overview. Our MCM features disentangled motion-appearance distillation, where motion is learned via the motion consistency distillation loss LMCD, and the appearance is learned with the frame adversarial objective Lady. Right: mixed trajectory distillation. We simulate the inference-time ODE trajectory using student-generated video (bottom green line), which is mixed with the real video ODE trajectory (top green line) for consistency distillation training.
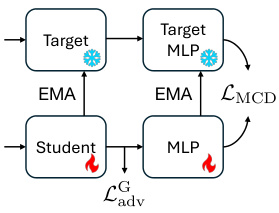
🔼 The figure illustrates the framework of the Motion Consistency Model (MCM) for video diffusion distillation. The left side shows the disentangled motion-appearance distillation process. Motion is distilled using the motion consistency distillation loss (LMCD) applied to the motion representation extracted from the video latent. Appearance is refined using a frame adversarial loss (Ladv) that compares the generated video frames to high-quality image data. The right side illustrates the mixed trajectory distillation, where trajectories from both low-quality training video and high-quality generated video are used in the distillation process to reduce the training-inference discrepancy.
read the caption
Figure 3: Left: framework overview. Our MCM features disentangled motion-appearance distillation, where motion is learned via the motion consistency distillation loss LMCD, and the appearance is learned with the frame adversarial objective L adv. Right: mixed trajectory distillation. We simulate the inference-time ODE trajectory using student-generated video (bottom green line), which is mixed with the real video ODE trajectory (top green line) for consistency distillation training.

🔼 This figure compares the video generated by different video diffusion distillation methods using AnimateDiff as the teacher model. It shows that the proposed Motion Consistency Model (MCM) generates clearer and more detailed videos with better alignment to the text prompt, even when using a small number of sampling steps (2 and 4). The teacher model used 50 sampling steps, highlighting the efficiency of the MCM approach.
read the caption
Figure 5: Qualitative comparison of video diffusion distillation with AnimateDiff [19] as the teacher model. The first and last frames are sampled for visualization. Our MCM produces cleaner frames using only 2 and 4 sampling steps, with better prompt alignment and improved frame details. Corresponding video results are in supplementary materials.

🔼 This figure demonstrates the ability of the Motion Consistency Model (MCM) to improve the quality of generated video frames by leveraging different image datasets. Three example prompts are used: an aerial view of a river, a woman near a creek, and an autumn scene. For each prompt, the results from a standard 50-step video diffusion model are compared against MCM results at only 4 steps using different image datasets (WebVid, LAION-aes, Anime, Realistic, and 3D Cartoon). The visual results show that MCM produces clearer and more aesthetically pleasing frames compared to the standard model across all datasets and prompts, demonstrating its ability to adapt to a variety of visual styles and enhance frame quality.
read the caption
Figure 6: MCM frame quality improvement results using different image datasets with ModelScopeT2V [62] teacher. The first and last frames are sampled for visualization. Our MCM effectively adapts to different distributions with 4 steps. Corresponding video results are in supplementary materials.

🔼 This figure compares the qualitative results of the proposed Motion Consistency Model (MCM) against the Latent Consistency Model (LCM). MCM uses ModelScopeT2V as a teacher model and generates clearer video frames, even with fewer sampling steps. The figure demonstrates MCM’s ability to adapt to various image styles by using additional image datasets, showing its improved visual fidelity.
read the caption
Figure 1: Qualitative result comparisons with latent consistency model (LCM) [38] using ModelScopeT2V [62] as teacher. Our MCM outputs clearer video frames using few-step sampling, and can also adapt to different image styles using additional image datasets. Corresponding video results are in supplementary materials.

🔼 This figure shows the results of applying the Motion Consistency Model (MCM) to generate pose-conditioned videos using ControlNet. The left side displays example human pose keypoints that serve as input to the model, and the right side showcases the resulting videos. The model successfully generates videos where the subject’s pose aligns with the given keypoints. This demonstrates the model’s ability to incorporate external control signals, enhancing its capability for generating diverse and controlled video content. Only 4 sampling steps were used to produce these videos.
read the caption
Figure 8: Our MCM can incorporate ControlNet [73] to enable pose-conditioned video generation. The videos are generated using 4 sampling steps.

🔼 This figure shows a failure case that occurred during the mixed trajectory distillation process when only generated videos were used for Ordinary Differential Equation (ODE) trajectory sampling. The parameter λreal was set to 0, meaning no real-world video data was used in the training. The figure displays several video frames at different sampling steps (1, 2, 4, and 8 steps) for three different video generation prompts: stage lighting, flag of Cape Verde, and air conditioning elements. The results show artifacts and failures in video generation across all prompts when only synthetic videos were used in the training data. This demonstrates the importance of incorporating real video data in the distillation process to achieve high-quality video generation.
read the caption
Figure 9: Failure case in mixed trajectory distillation when only generated videos are used for ODE trajectories sampling, i.e., λreal = 0.
More on tables
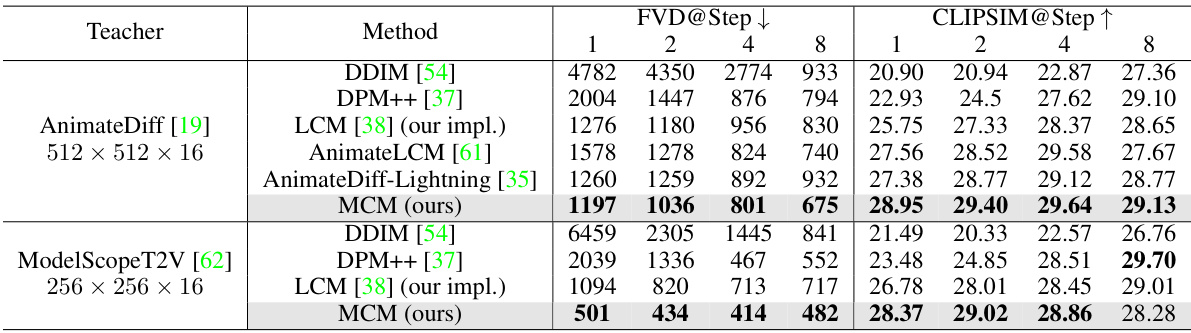
🔼 This table presents a comparison of different video diffusion distillation methods on the WebVid mini validation dataset. It shows the performance of various methods (DDIM, DPM++, LCM, AnimateLCM, AnimateDiff-Lightning, and MCM) using two different teacher models (AnimateDiff and ModelScopeT2V). The evaluation metrics are FVD (Fréchet Video Distance) at different sampling steps (1, 2, 4, and 8) and CLIPSIM (CLIP Similarity) at the same steps. Lower FVD scores indicate better video quality, while higher CLIPSIM scores suggest better alignment between generated videos and prompts. The table allows for a direct comparison of the effectiveness of various video diffusion distillation approaches in terms of both quality and fidelity.
read the caption
Table 1: Video diffusion distillation comparison on the WebVid mini validation set.

🔼 This table presents a comparison of frame quality improvement achieved by different methods, specifically focusing on the impact of varying the number of sampling steps. The evaluation metric is the Fréchet Inception Distance (FID), which measures the discrepancy between generated frames and real images. Lower FID values indicate better frame quality. The table compares the performance of the proposed Motion Consistency Model (MCM) against a two-stage baseline. The results highlight the effect of adjusting the number of sampling steps on frame quality for both MCM and the baseline, providing insights into the efficiency of the proposed method.
read the caption
Table 3: Comparison on frame quality improvement. Performance is measured by FID using different numbers of sampling steps.

🔼 This ablation study demonstrates the effectiveness of each component of the Motion Consistency Model (MCM). Starting with the Latent Consistency Model (LCM) baseline, the impact of adding an adversarial objective, disentangled motion distillation, and mixed trajectory distillation is evaluated. The results, measured by FVD (Fréchet Video Distance) and CLIPSIM (CLIP similarity), show improvements in video quality and prompt alignment with each added component.
read the caption
Table 4: Ablation study on each components in MCM. ModelScopeT2V [62] is used as teacher.

🔼 This table presents the ablation study results on different motion representation methods used in the Motion Consistency Model (MCM). It shows the impact of using different representations (raw latent, latent difference, latent correlation, low-frequency components, high-frequency components, and learnable representation) on the video generation quality, measured by FVD and CLIPSim scores at different sampling steps (1, 2, 4, 8). The results demonstrate that using a learnable motion representation achieves the best performance in terms of reducing FVD and improving CLIPSim scores.
read the caption
Table 5: Ablation study on motion representation.
Full paper#