TL;DR#
Vision-language models (VLMs) currently struggle with suboptimal image-text alignment due to equally weighting all text tokens during training, leading to overemphasis on less relevant or contradictory tokens. This hinders the model’s ability to capture the true visual information. Existing methods focus on increasing image resolution or training data quality, overlooking this fundamental alignment issue.
The paper introduces Contrastive Alignment (CAL), a novel re-weighting strategy that addresses this limitation. CAL uses the difference in prediction logits (with and without image input) to determine each token’s visual correlation. This simple, efficient method prioritizes visually relevant tokens during training, improving cross-modal alignment without significant computational burden. Experiments show CAL consistently enhances various VLMs across different benchmarks, demonstrating its effectiveness in improving image-text understanding.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in existing vision-language models (VLMs): the equal weighting of all text tokens during training. By showing that contrasting image inputs reveals the visual correlation of each token, this work introduces a simple yet effective method (CAL) for re-weighting tokens, leading to consistent improvements across various VLMs and benchmarks. This highlights the importance of a more nuanced approach to image-text alignment in VLMs and opens up new avenues for improving their performance. This research is highly relevant to the current trends in multimodal learning and large language models.
Visual Insights#
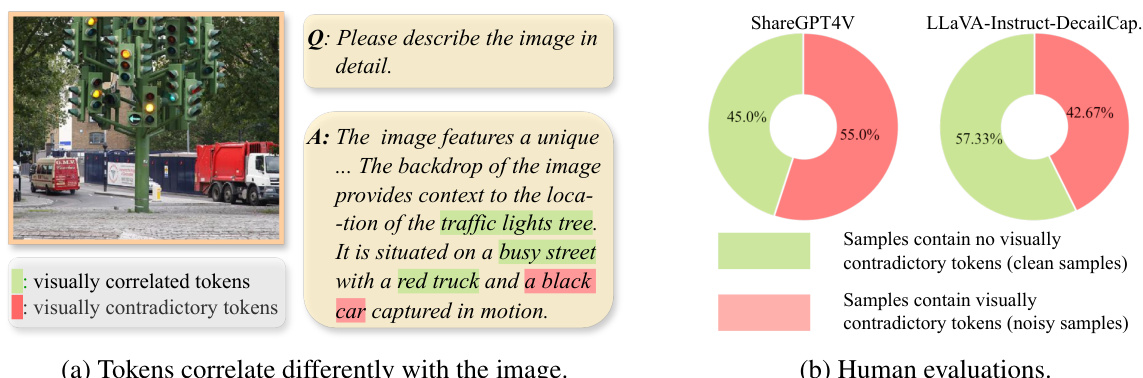
🔼 Figure 1(a) shows an example from the ShareGPT4V dataset illustrating how some tokens in the caption are not visually correlated or even contradict the image content. Figure 1(b) presents the results of a human evaluation assessing the percentage of samples in ShareGPT4V and LLaVA-Instruct-DetailCap datasets that contain visually contradictory tokens, demonstrating a significant proportion of such noisy samples.
read the caption
Figure 1: Figure 1a is one sample drawn from the ShareGPT4V dataset, which contains text tokens that are even contradictory with the given image. Figure 1b further presents our human evaluation results on the proportion of noisy samples that contain contradictory tokens.

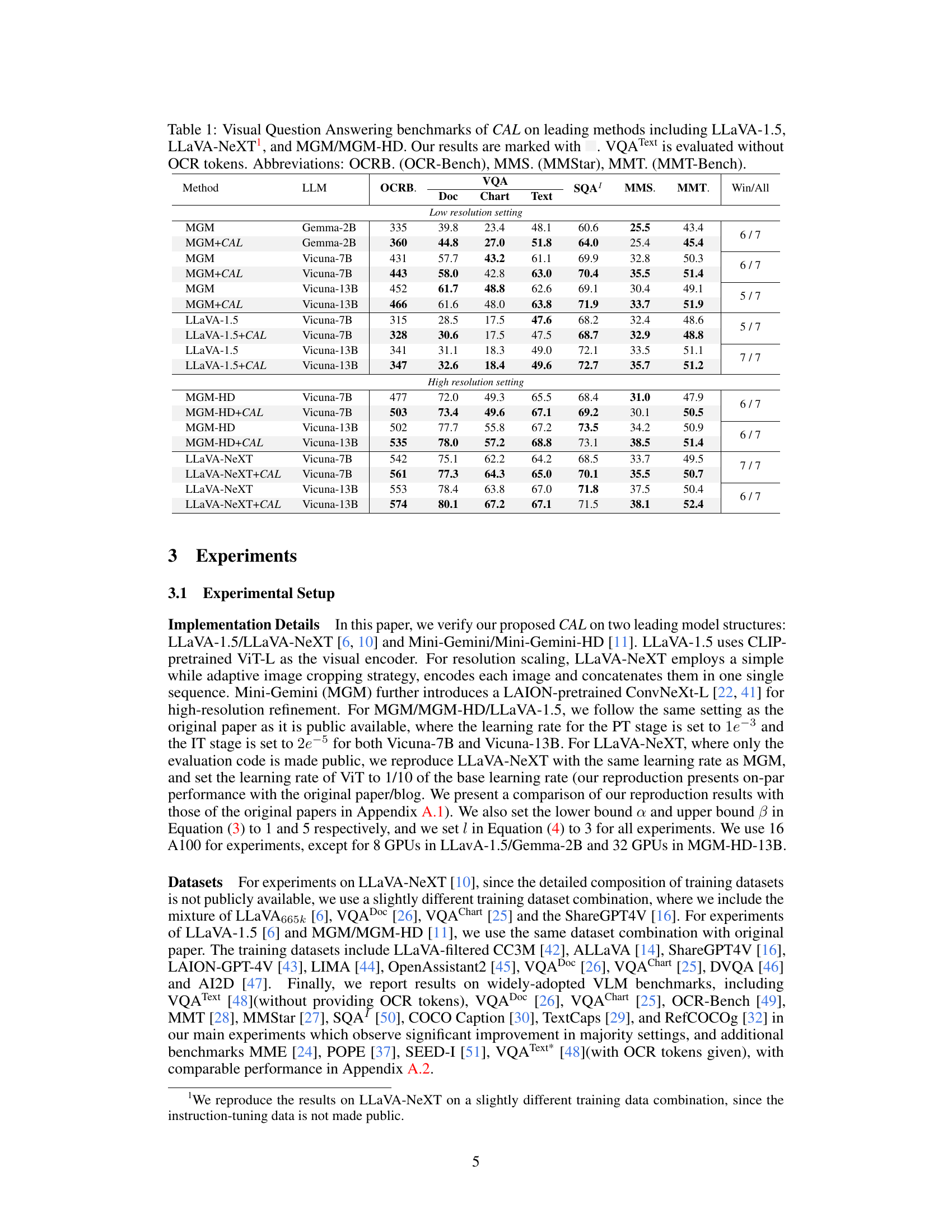
🔼 This table presents the results of Visual Question Answering experiments using three different Vision Language Models (VLMs): LLaVA-1.5, LLaVA-NeXT, and MGM/MGM-HD. The experiments are conducted with and without the Contrastive Alignment (CAL) method proposed in the paper. The table shows the performance on various benchmarks, including Doc, Chart, and Text, with and without OCR tokens, across different resolutions and model sizes. Abbreviations for the benchmarks are provided. The authors’ results are clearly marked.
read the caption
Table 1: Visual Question Answering benchmarks of CAL on leading methods including LLaVA-1.5, LLaVA-NeXT¹, and MGM/MGM-HD. Our results are marked with VQA Text is evaluated without OCR tokens. Abbreviations: OCRB. (OCR-Bench), MMS. (MMStar), MMT. (MMT-Bench).
In-depth insights#
Visual Correlation Focus#
The concept of “Visual Correlation Focus” in a research paper likely centers on how well a model (e.g., a vision-language model) connects visual and textual information. A strong visual correlation focus would imply the model prioritizes aligning text tokens that are semantically relevant to the visual content of an image. This contrasts with approaches that treat all text tokens equally, potentially leading to the model focusing on less relevant or even contradictory descriptions. The significance lies in improved accuracy and reduced hallucination. By emphasizing true visual-textual relationships, the model produces more accurate and coherent outputs. A key aspect would be the method of determining visual correlation, whether through explicit feature comparison, attention mechanisms, or some other approach. The research would ideally demonstrate that a strong visual correlation focus leads to improved performance on various tasks such as image captioning, visual question answering, and visual grounding, outperforming methods that lack this focused alignment.
Contrastive Alignment#
Contrastive alignment, in the context of Vision Language Models (VLMs), addresses the suboptimal alignment arising from treating all text tokens equally during training. The core idea is to prioritize tokens strongly correlated with the visual input, thereby improving the model’s understanding of the image-text relationship. This is achieved by contrasting the prediction logits of text tokens with and without the image input; the difference reveals the visual correlation of each token. A re-weighting strategy is implemented, emphasizing visually correlated tokens during training and minimizing the influence of irrelevant or contradictory ones. This approach offers a computationally efficient solution for enhancing image-text alignment without requiring extensive data scaling, leading to consistent improvements across various VLMs and benchmarks. The method’s simplicity and effectiveness make it a valuable technique for enhancing multimodal understanding in VLMs.
CAL’s Efficiency#
The efficiency of CAL (Contrastive ALignment) is a crucial aspect of its practicality. The paper highlights minimal computational overhead, achieved through a simple re-weighting strategy that avoids complex model modifications or data augmentation. This efficiency is a significant advantage over alternative data scaling methods that often demand substantially increased computational resources. CAL’s low overhead is primarily due to its reliance on contrasting prediction logits with and without image inputs, requiring only one gradient-free forward operation per training step. This makes CAL highly suitable for deployment in resource-constrained environments, and compatible with various VLMs of different scales and architectures, further enhancing its practical value and wide applicability.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper would ideally present a comprehensive evaluation of the proposed method against existing state-of-the-art techniques. It should go beyond simply reporting numerical scores; a thoughtful analysis is crucial. Clear visualizations (tables, charts, graphs) comparing performance across different benchmarks are essential, highlighting both strengths and weaknesses. Statistical significance should be explicitly addressed, demonstrating whether performance differences are statistically meaningful or due to chance. The choice of benchmarks themselves is critical; a diverse and relevant set showcasing the method’s capabilities across various scenarios and datasets provides stronger evidence of its effectiveness. Detailed explanations of benchmark metrics should be included to ensure reproducibility and facilitate understanding of the results. Finally, a discussion of the limitations and potential biases in the benchmarks, alongside implications for the generalizability of the findings, will add significant value to the results analysis and contribute to a more robust and impactful contribution.
Future Research#
Future research directions stemming from this contrastive alignment work could explore several promising avenues. Extending CAL to other multimodal tasks beyond the ones evaluated (e.g., visual question generation, image retrieval) would demonstrate its broader applicability and effectiveness. A key area for improvement is developing more sophisticated weighting strategies, potentially incorporating additional factors such as token importance or contextual information, to further refine the prioritization of visually correlated tokens. Investigating the impact of different contrastive learning approaches and architectures on CAL’s performance would offer valuable insights into optimal implementation. Furthermore, research could focus on adapting CAL for different model architectures and training paradigms, including more efficient implementations suitable for large-scale models. Finally, a thorough analysis of CAL’s robustness to noisy or biased data is needed to better understand its limitations and guide future development efforts toward more reliable and resilient multimodal models.
More visual insights#
More on figures
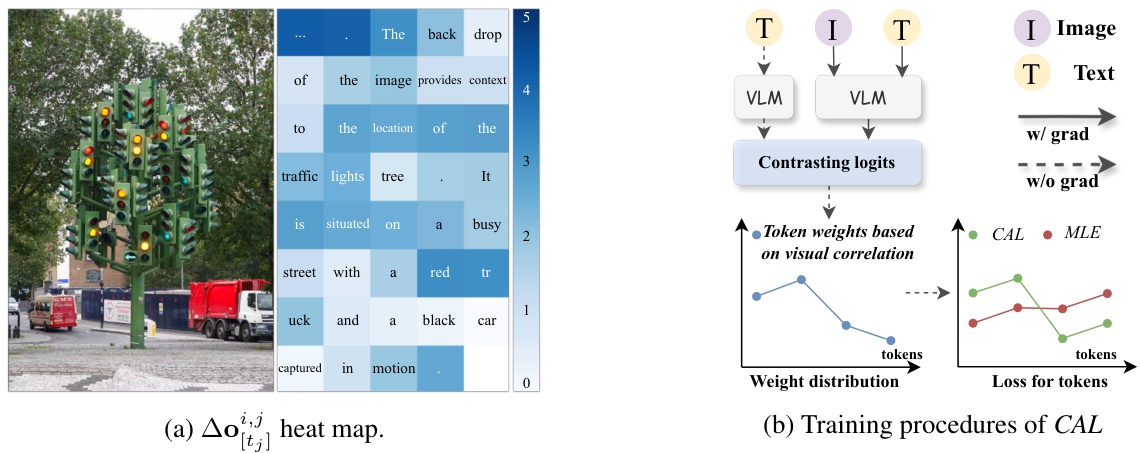
🔼 This figure illustrates the Contrastive Alignment (CAL) method. Figure 2a shows a heatmap visualizing the difference in prediction logits for each text token with and without image input. Tokens with higher logit differences (stronger visual correlation) are highlighted. Figure 2b depicts the CAL training process, which uses these logit differences to re-weight the importance of each text token, prioritizing visually correlated tokens during training.
read the caption
Figure 2: Overview of CAL. Figure 2a presents a sample drawn from the ShareGPT4V dataset. We calculate the logit difference w/ or w/o image inputs and plot the heat map on partial text tokens. Figure 2b presents the training procedure of CAL, which re-weights the importance of label tokens based on the contrasting logits.

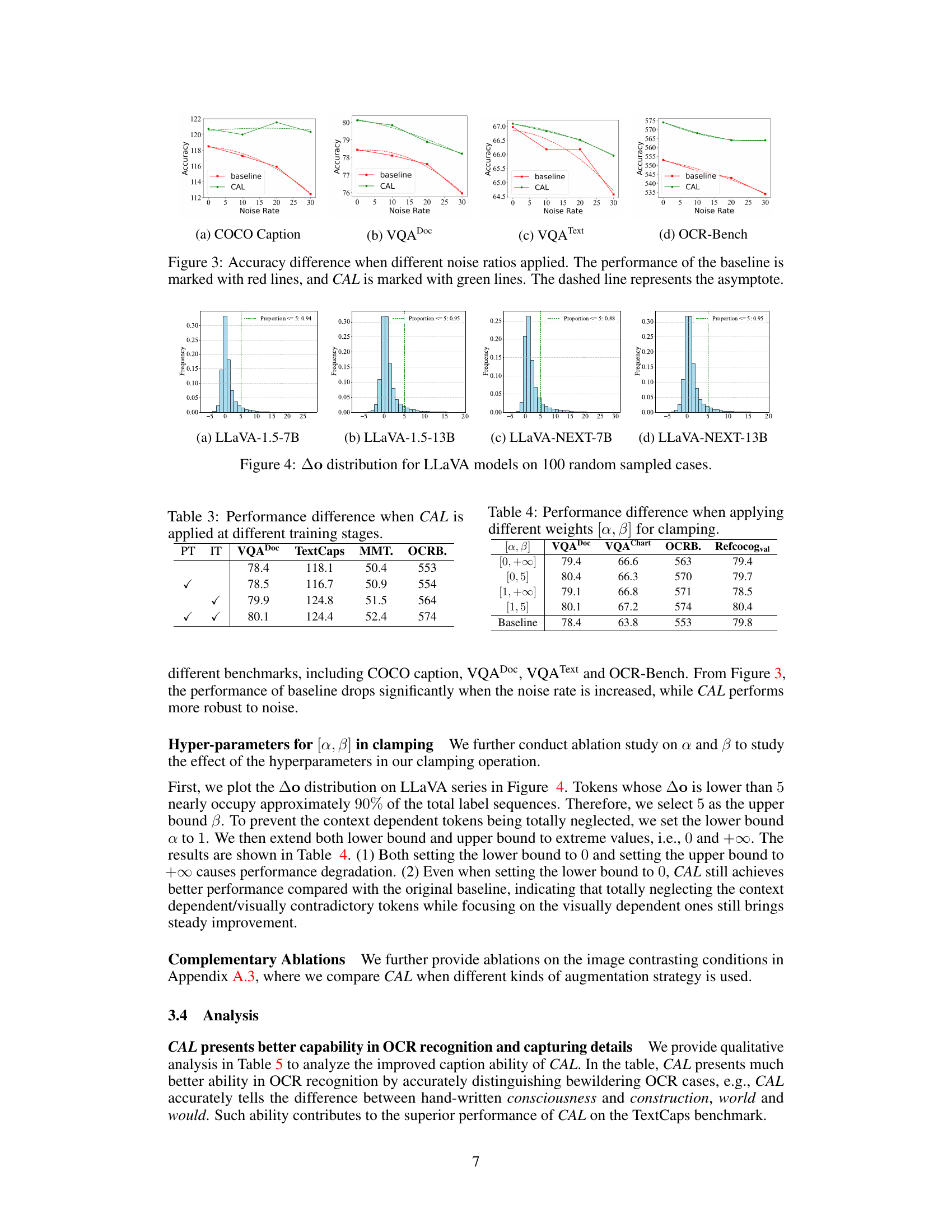
🔼 This figure shows the impact of noisy labels in the training dataset on the performance of the baseline model and the proposed CAL method. The x-axis represents the noise rate (percentage of noisy labels), while the y-axis represents the accuracy on four different benchmarks (COCO Caption, VQA Doc, VQA Text, and OCR-Bench). As the noise rate increases, the accuracy of the baseline model decreases significantly, while the accuracy of CAL model decreases at a much slower rate, demonstrating its robustness to noisy labels.
read the caption
Figure 3: Accuracy difference when different noise ratios applied. The performance of the baseline is marked with red lines, and CAL is marked with green lines. The dashed line represents the asymptote.

🔼 The figure shows the distribution of the difference in prediction logits (Δo) for various text tokens in four different LLaVA models (LLaVA-1.5-7B, LLaVA-1.5-13B, LLaVA-NeXT-7B, and LLaVA-NeXT-13B). The x-axis represents the Δo value, and the y-axis shows the frequency. The vertical dashed line indicates the threshold where Δo is less than or equal to 5, showing the proportion of tokens with low Δo values. This distribution visualization is used to support the argument that contrasting image inputs helps distinguish between visually correlated, irrelevant, and contradictory text tokens.
read the caption
Figure 4: Δo distribution for LLaVA models on 100 random sampled cases.

🔼 The figure shows an example from the ShareGPT4V dataset illustrating how some text tokens are contradictory to the image content (Figure 1a). It also presents a human evaluation demonstrating that approximately half of the samples in ShareGPT4V and LLaVA-Instruct contain visually contradictory tokens (Figure 1b), highlighting the problem of existing image-text alignment strategies.
read the caption
Figure 1: Figure 1a is one sample drawn from the ShareGPT4V dataset, which contains text tokens that are even contradictory with the given image. Figure 1b further presents our human evaluation results on the proportion of noisy samples that contain contradictory tokens.

🔼 This figure shows an example from the ShareGPT4V dataset illustrating how some tokens in the caption are not visually correlated with the image, and even contradict it. It also presents results from a human evaluation, showing the proportion of samples with visually contradictory tokens in ShareGPT4V and LLaVA-Instruct datasets.
read the caption
Figure 1: Figure 1a is one sample drawn from the ShareGPT4V dataset, which contains text tokens that are even contradictory with the given image. Figure 1b further presents our human evaluation results on the proportion of noisy samples that contain contradictory tokens.

🔼 The figure shows an example from the ShareGPT4V dataset illustrating how some text tokens are not visually correlated with the image, and even contradict it. It also includes the results of a human evaluation showing a significant percentage of samples containing contradictory tokens.
read the caption
Figure 1: Figure 1a is one sample drawn from the ShareGPT4V dataset, which contains text tokens that are even contradictory with the given image. Figure 1b further presents our human evaluation results on the proportion of noisy samples that contain contradictory tokens.

🔼 The figure shows an example from the ShareGPT4V dataset illustrating how some tokens in the caption are not visually correlated with the image (Figure 1a). It also presents a bar chart summarizing the results of human evaluation, which demonstrates that a significant portion of samples in both ShareGPT4V and LLaVA-Instruct-DetailCap datasets contain visually contradictory tokens (Figure 1b). This highlights the issue of existing image-text alignment strategies in VLMs that treat all text tokens equally, leading to sub-optimal cross-modal alignment.
read the caption
Figure 1: Figure 1a is one sample drawn from the ShareGPT4V dataset, which contains text tokens that are even contradictory with the given image. Figure 1b further presents our human evaluation results on the proportion of noisy samples that contain contradictory tokens.

🔼 The figure demonstrates the attention maps generated by the baseline model and the proposed model with contrastive alignment (CAL). The attention weights are calculated by accumulating the attention score between image tokens and text tokens across all layers. The figure shows that the model with CAL produces clearer attention maps with less noisy points in the background, which indicates that CAL helps the model focus on the relevant regions of the image.
read the caption
Figure 5: Comparison of attention maps with and without CAL on LLaVA-NeXT-13B. The left side of each sub-figure shows LLaVA-NeXT-13B without CAL, while the right side shows LLaVA-NeXT-13B with CAL.

🔼 The figure visualizes the image-text modality alignment by finding the nearest text words to each image patch feature from the LLM vocabulary. The top shows a sample image patch with identified text. The bottom shows the results for baseline and CAL methods, comparing the nearest text words (from the LLM vocabulary) found for each image patch. CAL shows improved alignment by more accurately identifying relevant OCR information from the language vocabulary.
read the caption
Figure 6: Visualization of image-text modality alignment for each image patch. We filtered out some nonsensical patches for better visualization.
More on tables
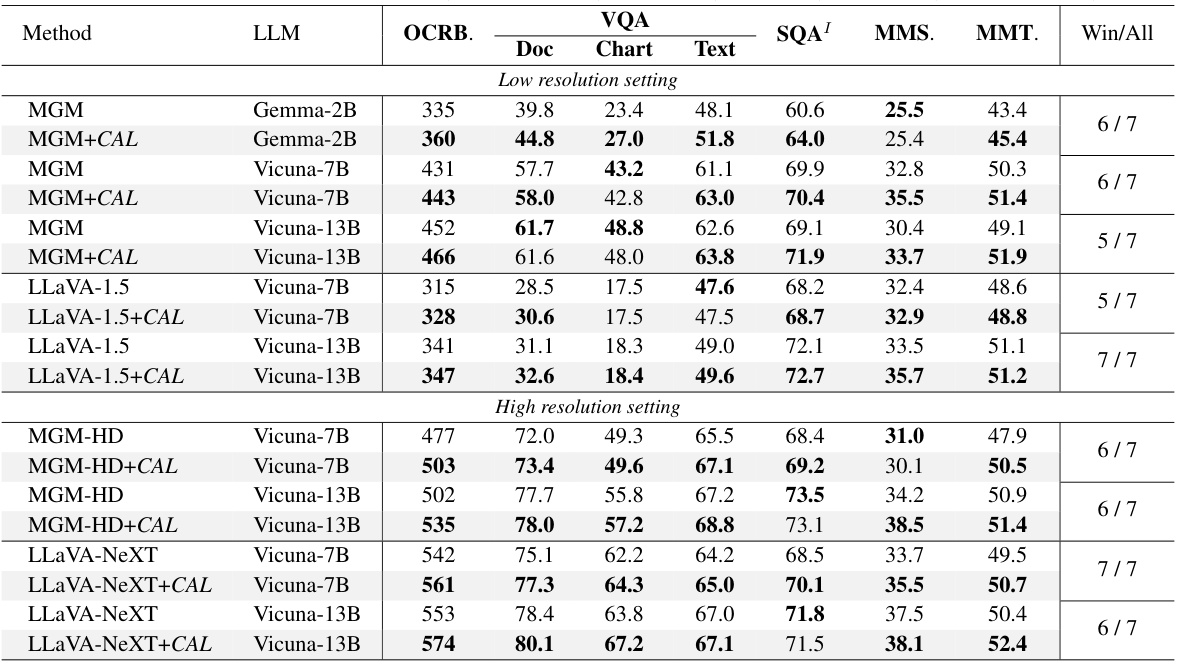
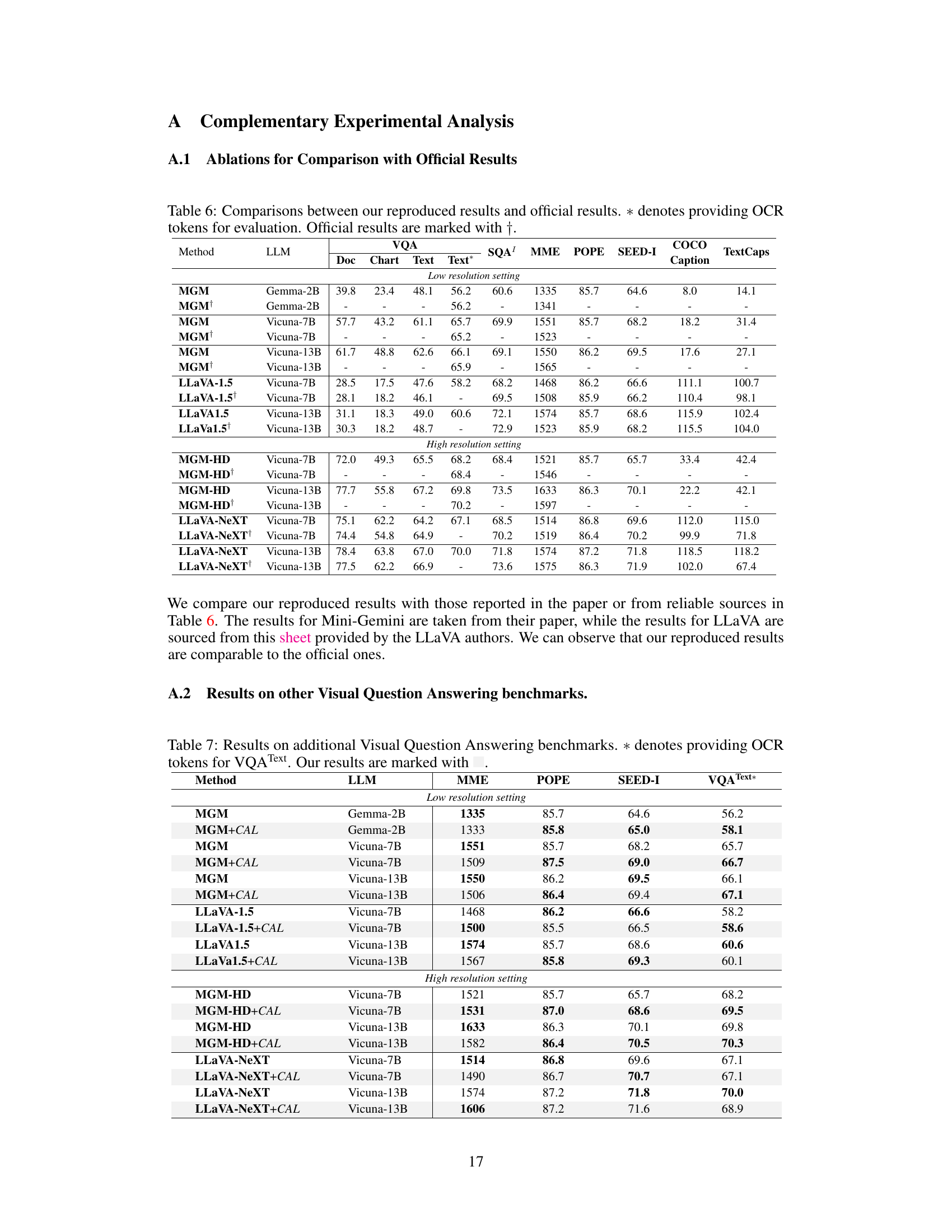
🔼 This table presents the performance comparison of different Vision Language Models (VLMs) on various Visual Question Answering (VQA) benchmark datasets. It showcases the impact of Contrastive Alignment (CAL), a method proposed in the paper, on improving the performance of these models. The table shows results for different LLMs (Large Language Models) at different resolutions (low and high) and with/without CAL. Various metrics are used for evaluation across different VQA tasks.
read the caption
Table 1: Visual Question Answering benchmarks of CAL on leading methods including LLaVA-1.5, LLaVA-NeXT¹, and MGM/MGM-HD. Our results are marked with VQA Text is evaluated without OCR tokens. Abbreviations: OCRB. (OCR-Bench), MMS. (MMStar), MMT. (MMT-Bench).
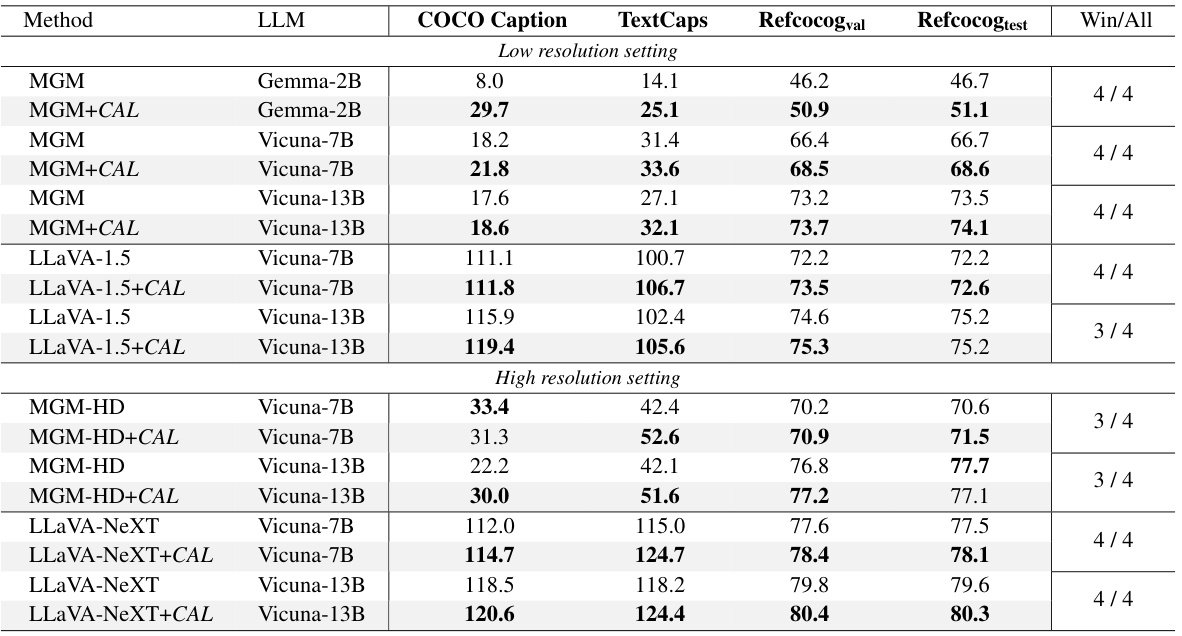
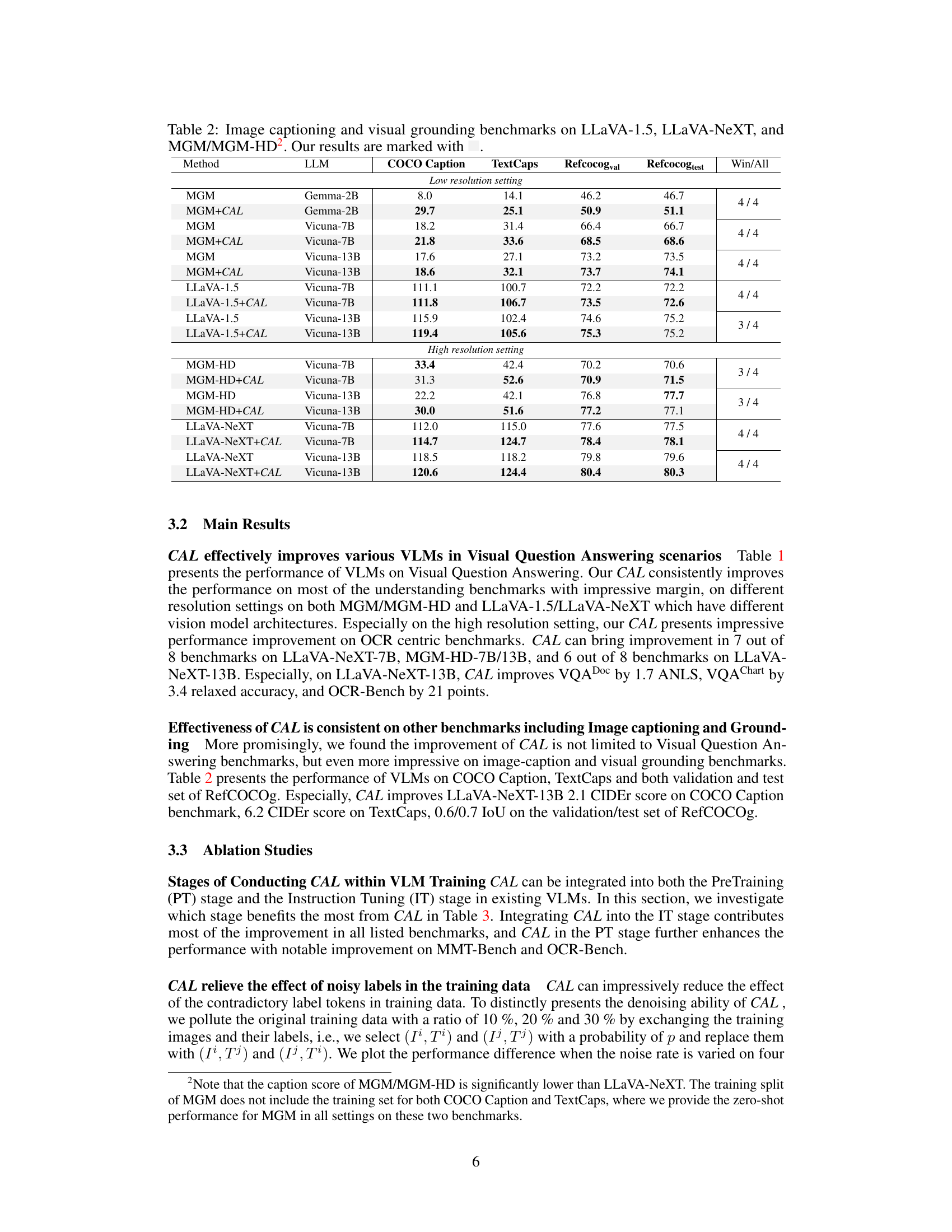
🔼 This table presents the performance comparison of different Vision Language Models (VLMs) on image captioning and visual grounding benchmarks. The VLMs are tested on COCO Caption, TextCaps, and RefCOCOg datasets. The results show the performance improvement achieved by using Contrastive Alignment (CAL). The table is split into two sections: low-resolution and high-resolution settings. Each row shows the performance of a specific VLM with and without CAL, along with the model size (LLM) and dataset used.
read the caption
Table 2: Image captioning and visual grounding benchmarks on LLaVA-1.5, LLaVA-NeXT, and MGM/MGM-HD2. Our results are marked with
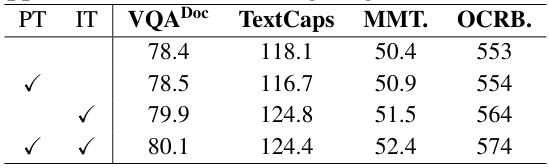
🔼 This table presents the performance difference observed when Contrastive Alignment (CAL) is applied at various stages during the training process of a Vision Language Model (VLM). Specifically, it shows the results for different benchmarks (VQADoc, TextCaps, MMT, OCRB) when CAL is integrated only in the instruction tuning (IT) stage, only in the pre-training (PT) stage, and when it’s included in both stages. It demonstrates the relative contribution of each training stage and the cumulative impact when CAL is applied to both.
read the caption
Table 3: Performance difference when CAL is applied at different training stages.

🔼 This table presents the performance difference in various benchmarks (VQA Doc, VQA Chart, OCRB, Refcocogval) when different clamping weight ranges ([α, β]) are applied during the Contrastive Alignment (CAL) process. It shows how the choice of clamping weights affects the final results, with [1,5] showing the best overall performance compared to the baseline and other weight configurations. The results highlight the sensitivity of CAL to the choice of hyperparameters and the importance of finding appropriate values for optimal performance.
read the caption
Table 4: Performance difference when applying different weights [α, β] for clamping.

🔼 This table presents the performance comparison of different Vision Language Models (VLMs) on various Visual Question Answering (VQA) benchmarks. The VLMs tested include LLaVA-1.5, LLaVA-NeXT, and MGM/MGM-HD, both with and without the Contrastive Alignment (CAL) method. The results are categorized by resolution (low and high) and LLM used (Gemma-2B, Vicuna-7B, Vicuna-13B). The table shows the performance improvements achieved by CAL on these benchmarks, using several metrics.
read the caption
Table 1: Visual Question Answering benchmarks of CAL on leading methods including LLaVA-1.5, LLaVA-NeXT¹, and MGM/MGM-HD. Our results are marked with VQA Text is evaluated without OCR tokens. Abbreviations: OCRB. (OCR-Bench), MMS. (MMStar), MMT. (MMT-Bench).

🔼 This table presents the performance of different Vision Language Models (VLMs) on various Visual Question Answering (VQA) benchmarks. It compares the performance of several state-of-the-art models (MGM, LLaVA-1.5, LLaVA-NeXT) both with and without the Contrastive Alignment (CAL) method proposed in the paper. The results are broken down by model size (Vicuna-7B, Vicuna-13B), resolution (low and high), and specific VQA sub-tasks (Doc, Chart, Text, etc.). The table highlights the consistent improvements achieved by CAL across different model types and sizes.
read the caption
Table 1: Visual Question Answering benchmarks of CAL on leading methods including LLaVA-1.5, LLaVA-NeXT¹, and MGM/MGM-HD. Our results are marked with VQA Text is evaluated without OCR tokens. Abbreviations: OCRB. (OCR-Bench), MMS. (MMStar), MMT. (MMT-Bench).

🔼 This table presents the performance of several vision-language models (VLMs) on various visual question answering benchmarks. It compares the baseline performance of three leading VLMs (LLaVA-1.5, LLaVA-NeXT, and MGM/MGM-HD) against their performance after applying the Contrastive Alignment (CAL) method. The results are broken down by different LLM backbones (Gemma-2B, Vicuna-7B, Vicuna-13B), resolution settings (low and high), and benchmark types (Doc, Chart, Text, Text*, SQA, MMS, MMT, OCRB). The ‘Text*’ column indicates results where OCR tokens were not used in evaluation. The table demonstrates the consistent improvement in performance across various VLMs and benchmarks after incorporating CAL.
read the caption
Table 1: Visual Question Answering benchmarks of CAL on leading methods including LLaVA-1.5, LLaVA-NeXT¹, and MGM/MGM-HD. Our results are marked with VQA Text is evaluated without OCR tokens. Abbreviations: OCRB. (OCR-Bench), MMS. (MMStar), MMT. (MMT-Bench).
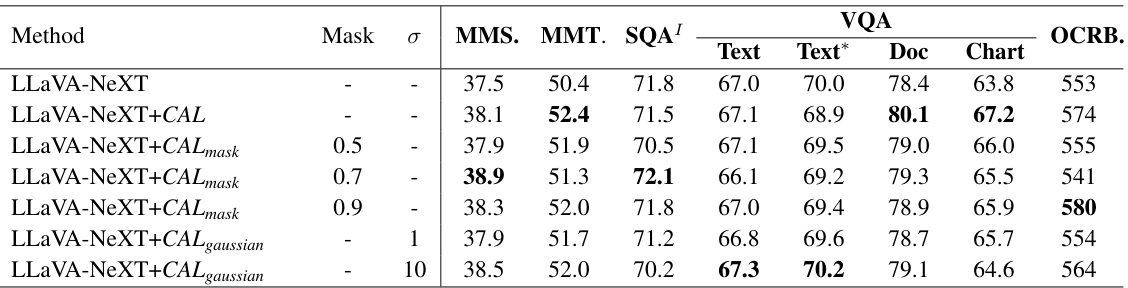
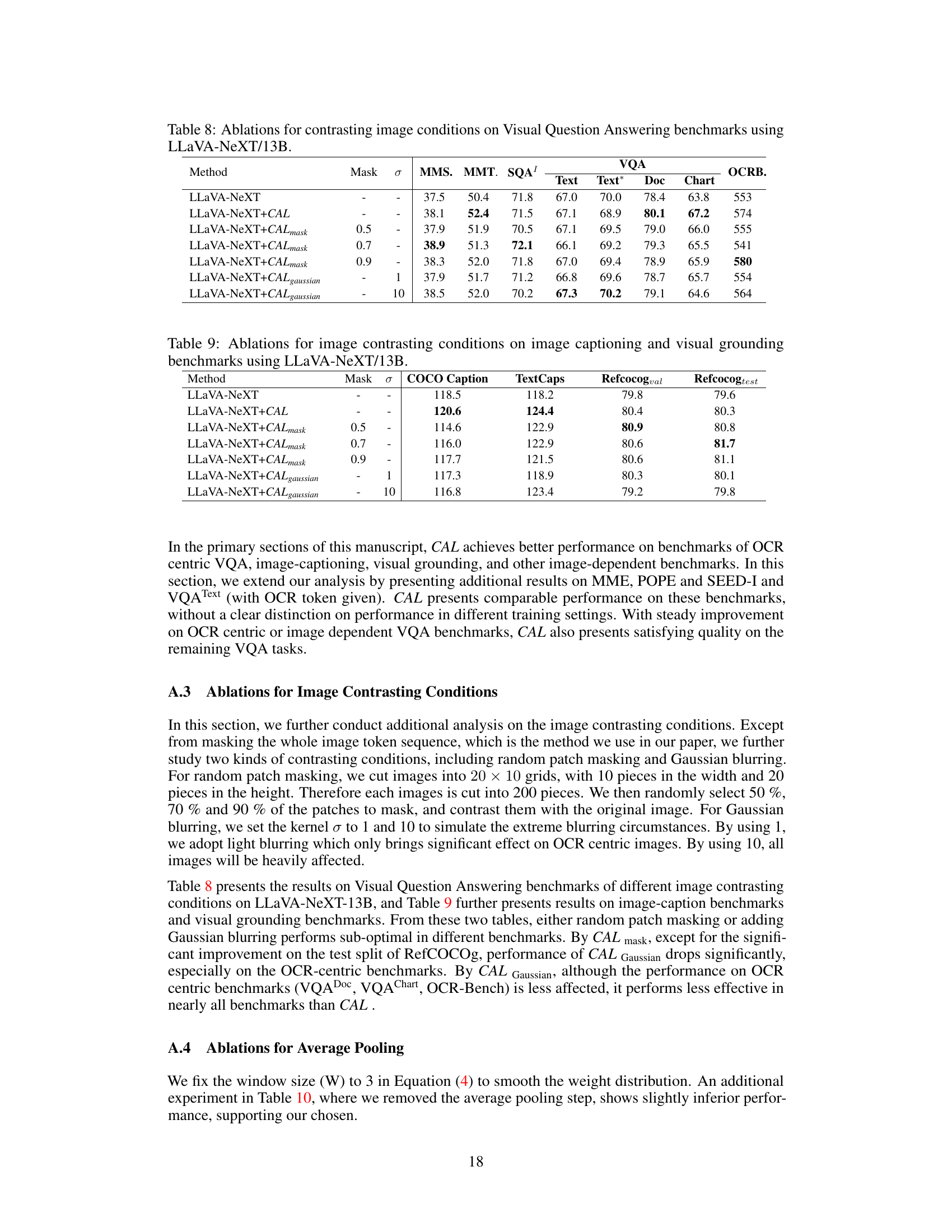
🔼 This table presents the ablation study on different image contrasting methods for visual question answering tasks using the LLaVA-NeXT/13B model. It shows the performance variations of the model with and without CAL (Contrastive Alignment) under different image masking techniques (random patch masking and Gaussian blurring) and different masking ratios. The results are presented in terms of various metrics for different visual question answering benchmarks, including MMS, MMT, SQA, Text, Text*, Doc, Chart, and OCRB.
read the caption
Table 8: Ablations for contrasting image conditions on Visual Question Answering benchmarks using LLaVA-NeXT/13B.

🔼 This table presents ablation studies on the impact of different image contrasting methods on the performance of LLaVA-NeXT-13B for image captioning and visual grounding tasks. It shows how the model’s performance varies when using different masking ratios (0.5, 0.7, 0.9) and Gaussian blurring (σ=1 and σ=10) during the contrasting process. The results are evaluated using COCO Caption, TextCaps, Refcocogval, and Refcocogtest metrics.
read the caption
Table 9: Ablations for image contrasting conditions on image captioning and visual grounding benchmarks using LLaVA-NeXT/13B.

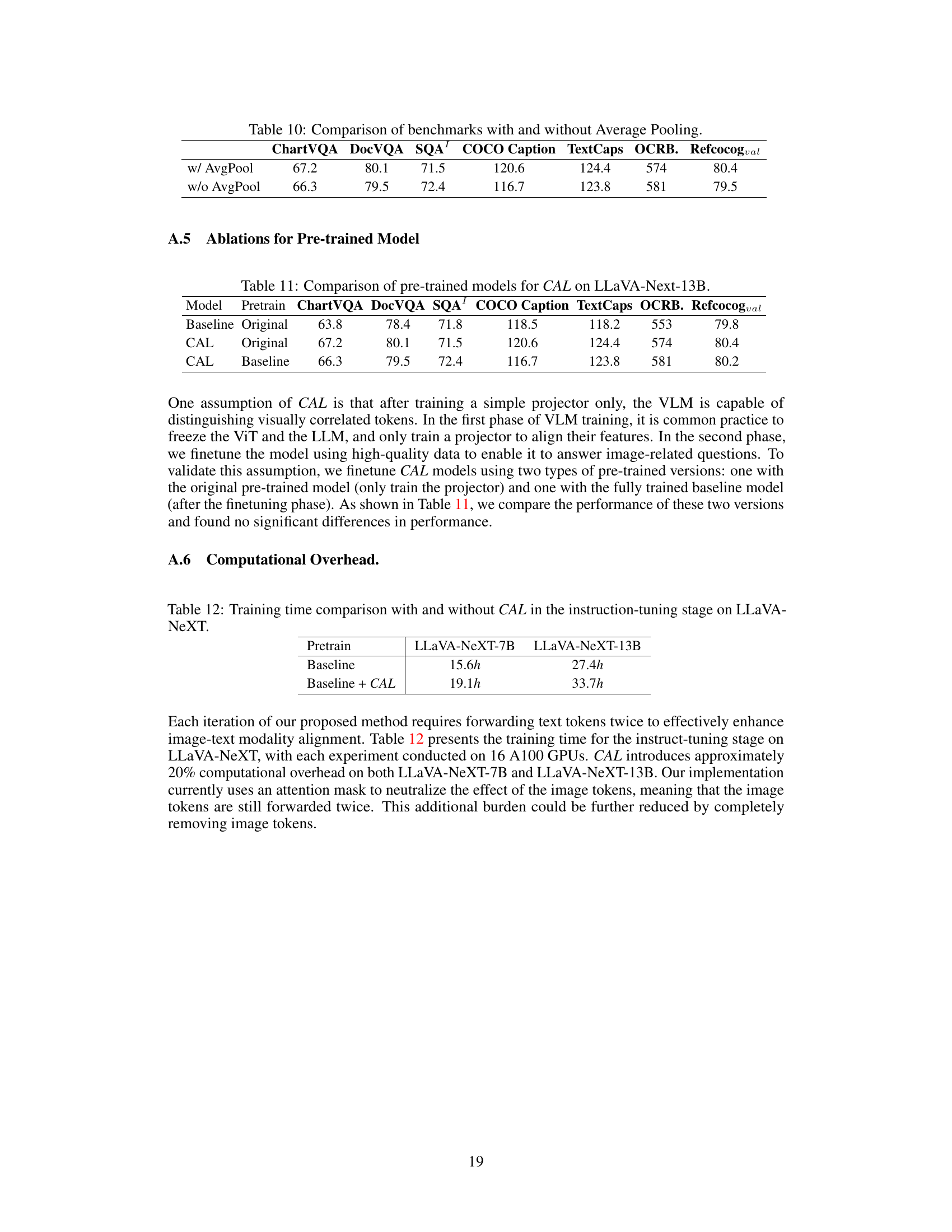
🔼 This table presents ablation study results on the impact of average pooling in the proposed CAL method. It compares the performance of CAL with and without average pooling on various benchmarks, including ChartVQA, DocVQA, SQA, COCO Caption, TextCaps, OCRB, and Refcocog_val. The results demonstrate that average pooling slightly improves performance across these benchmarks.
read the caption
Table 10: Comparison of benchmarks with and without Average Pooling.

🔼 This table compares the performance of CAL using different pre-trained models on the LLaVA-Next-13B architecture. It shows the results for three model variations: a baseline with original pre-training, CAL with original pre-training, and CAL with a baseline pre-trained model. Results are presented across various benchmark tasks including visual question answering (ChartVQA, DocVQA, SQA), image captioning (COCO Caption, TextCaps), and OCR-based tasks (OCRB, Refcocog). This helps to analyze the impact of pre-training on the effectiveness of CAL.
read the caption
Table 11: Comparison of pre-trained models for CAL on LLaVA-Next-13B.

🔼 This table presents the results of the Contrastive Alignment (CAL) method on various Visual Question Answering (VQA) benchmarks. It compares the performance of several leading Vision Language Models (VLMs), including LLaVA-1.5, LLaVA-NeXT, and MGM/MGM-HD, both with and without the CAL method applied. The table shows improvements in VQA scores across different model sizes and resolutions, highlighting the effectiveness of CAL in enhancing VQA performance. Note that ‘VQA Text*’ indicates results were evaluated without OCR tokens.
read the caption
Table 1: Visual Question Answering benchmarks of CAL on leading methods including LLaVA-1.5, LLaVA-NeXT¹, and MGM/MGM-HD. Our results are marked with VQA Text is evaluated without OCR tokens. Abbreviations: OCRB. (OCR-Bench), MMS. (MMStar), MMT. (MMT-Bench).
Full paper#