↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current vision models primarily focus on accuracy, neglecting the dynamic nature of human decision-making. This leads to incomplete models of human visual perception, lacking a critical integration of vision and decision-making processes. Existing attempts to model reaction times (RTs) have limitations, either requiring extensive searches for optimal thresholds or relying on surrogates like uncertainty, which don’t fully capture the relationship between RTs and the decision process.
The proposed RTify framework addresses these limitations by learning to align a recurrent neural network’s (RNN) dynamics with human RTs, using an approximation to constrain the number of time steps an RNN takes to solve a task. RTify can be trained using direct human RT supervision, or via self-penalty, achieving optimal speed-accuracy tradeoffs without human data. The resulting model accurately predicts human RTs and achieves superior performance to existing methods. This framework is extended to integrate with existing CNN models, advancing our understanding of visual decision-making.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on bridging the gap between computer vision and cognitive science. It provides a novel framework for aligning deep learning models with human behavior, opening new avenues for creating more realistic and human-like AI systems. The integration of vision and decision-making models is a major step towards understanding human visual perception and building more robust AI.
Visual Insights#

This figure illustrates the RTify method, showing how a pre-trained recurrent neural network (RNN) processes visual stimuli to generate a decision and reaction time (RT). The RNN’s activity is transformed into an evidence measure using a trainable function, which is then accumulated over time. When the accumulated evidence surpasses a threshold, the process stops, and the RT is determined by the number of steps taken to reach the threshold. The figure uses random dot motion stimuli as an example, but indicates the system can handle other inputs.
In-depth insights#
RTify Framework#
The RTify framework presents a novel approach to bridge the gap between deep learning models of visual processing and human behavioral responses, specifically focusing on reaction times (RTs). It introduces a trainable module that aligns the temporal dynamics of a recurrent neural network (RNN) to human RTs, enabling the model to not only predict behavioral choices but also the time it takes to make those choices. This is achieved by learning a function that transforms RNN activations into a real-valued evidence measure integrated over time until a threshold is met, with the time to reach the threshold representing the model’s RT. RTify’s strength lies in its ability to be applied both with and without human RT data, allowing for optimization to fit human data directly or to optimize for an ideal trade-off between speed and accuracy via self-penalty. The framework’s flexibility extends to different neural network architectures, demonstrating its ability to work with convolutional neural networks (CNNs) and other models by integrating them with an RTified RNN module. This comprehensive approach offers a significant advance in building more realistic and human-like computational vision models.
RNN-Human Alignment#
Aligning Recurrent Neural Networks (RNNs) with human behavior, especially concerning decision-making processes, is crucial for creating more biologically plausible and robust AI models. The core challenge lies in bridging the gap between the abstract mathematical operations of RNNs and the complex, dynamic nature of human choices. This involves moving beyond simply matching overall accuracy metrics and focusing on finer-grained aspects, such as reaction time (RT) distributions and the temporal dynamics of evidence accumulation. This alignment requires innovative computational frameworks that can learn to optimize RNN parameters not just for accuracy, but also to replicate the timing of human decisions. This is achieved by introducing techniques such as direct RT supervision during training or through self-penalized learning, where RNNs learn to optimize the trade-off between speed and accuracy without explicit human RT data. A key aspect of this alignment involves developing differentiable modules that can integrate with existing feedforward networks (like CNNs) to incorporate temporal dynamics. Ultimately, this research aims to advance our understanding of human visual perception and decision-making, by constructing AI models that truly reflect the intricate interplay between speed, accuracy, and the inherent time constraints of cognitive processing.
WW Model Extension#
The Wong-Wang (WW) model, a biologically plausible neural circuit model for decision-making, is extended to enhance its applicability and address limitations. The original WW model’s limitations included handling only binary classification tasks using simplified stimuli and requiring manual parameter tuning. This extension tackles these issues by: 1) integrating a CNN, enabling the processing of complex natural images; 2) generalizing to multi-class classification, accommodating more complex decision scenarios; and 3) incorporating the RTify module, allowing for the training of all parameters via backpropagation to achieve optimal alignment with human reaction times (RTs). This comprehensive extension increases the model’s biological realism and expands its applicability to various cognitive tasks and complex stimuli. Direct training on human RT data alongside a ‘self-penalty’ mechanism further enhances its performance in capturing human-like responses.
Ideal Observer RNN#
An ‘Ideal Observer RNN’ model would represent a significant advance in computational modeling of human visual perception. It would integrate the strengths of ideal observer models—which optimize performance given inherent limitations in sensory information—with the temporal dynamics and learning capabilities of recurrent neural networks (RNNs). This combination could lead to more accurate predictions of human behavior in visual tasks, particularly in terms of reaction times and decision-making processes. Crucially, such a model could move beyond typical simplified stimuli used in traditional psychophysics to model human performance with more complex, natural images. A key challenge in developing this model would be to balance speed and accuracy. While ideal observer models are optimized for accuracy, human visual processing must also be efficient, making it crucial to constrain computational cost and processing time. The success of this model hinges on carefully defining and implementing realistic constraints reflecting biological limitations.
Future Directions#
Future research could explore extensions to more complex and naturalistic stimuli, moving beyond simple artificial patterns. Investigating the generalizability of RTify to diverse visual tasks and populations is crucial. A deeper integration of RTify with biologically-inspired neural models would enhance the framework’s explanatory power. Further exploration of the trade-off between speed and accuracy is needed for a more complete understanding of human decision-making. Finally, examining the influence of factors such as attention, motivation, and cognitive load on model performance and RTs will reveal valuable insights into human perception and decision-making processes.
More visual insights#
More on figures
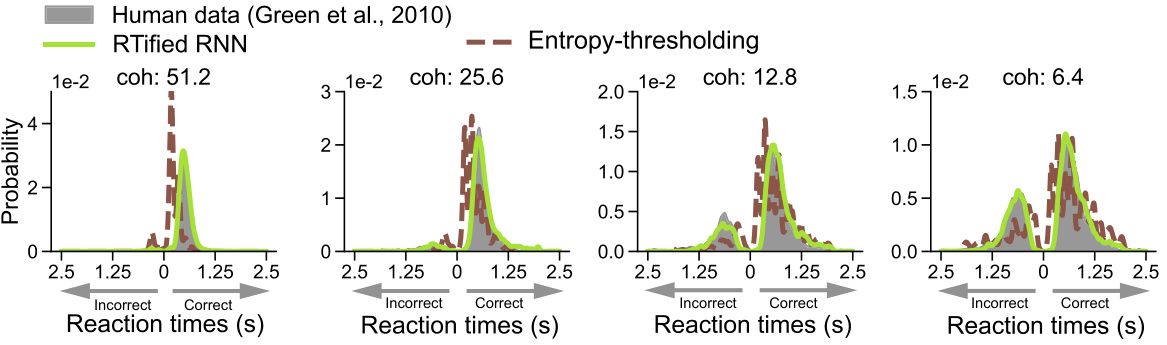
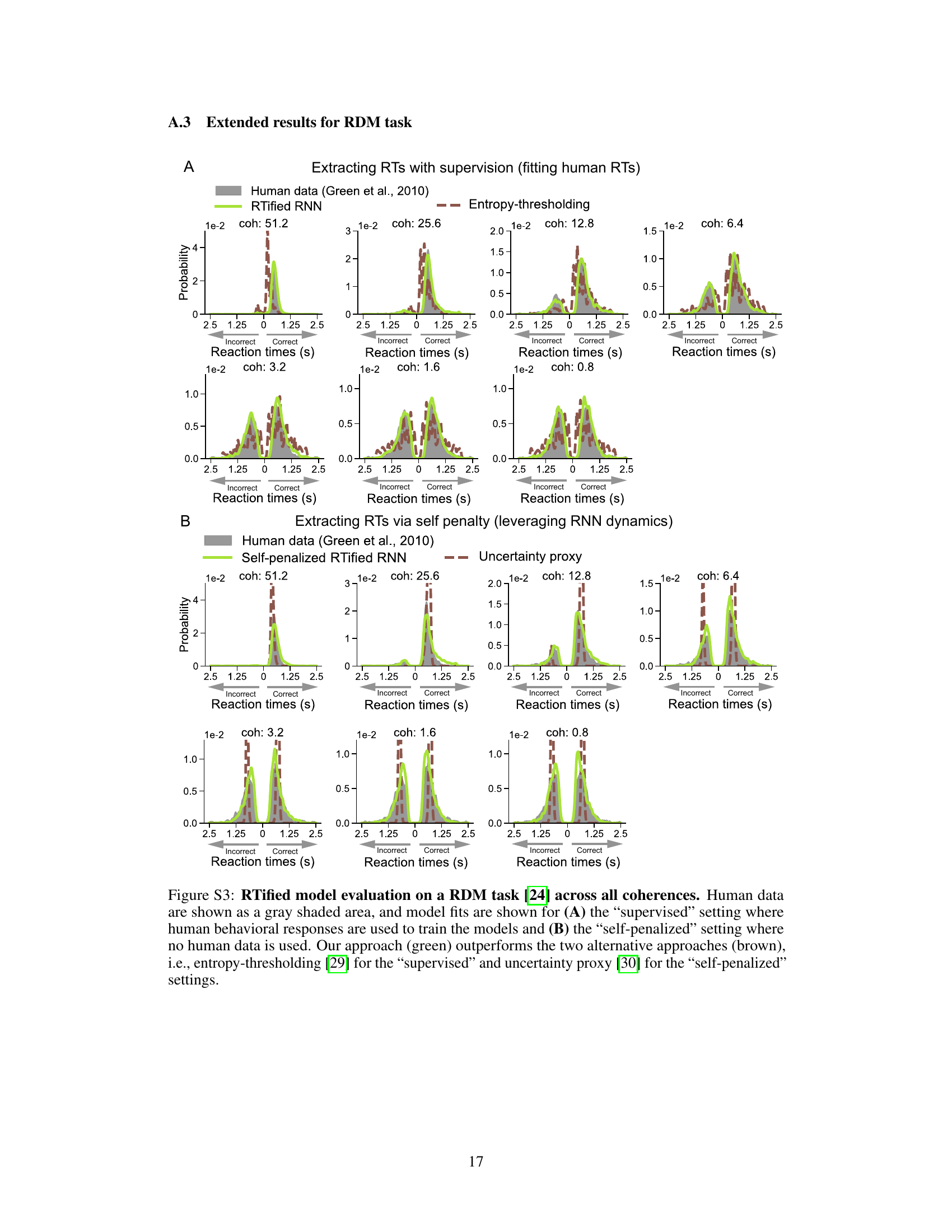
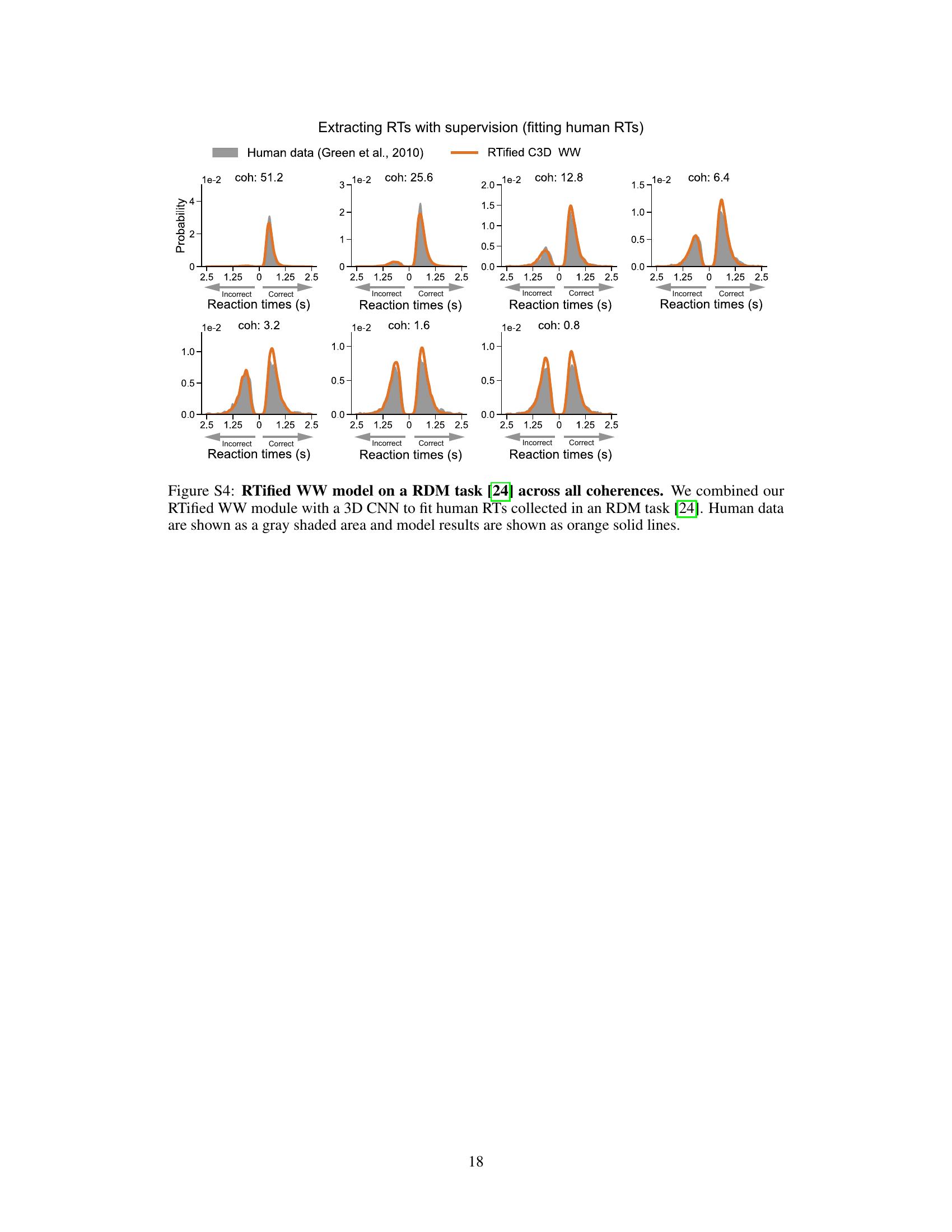
This figure compares the performance of the RTified model with two other methods (entropy-thresholding and uncertainty proxy) on a random dot motion (RDM) task. The RTified model is evaluated under two training conditions: supervised (using human behavioral data) and self-penalized (without human data). The results show the distribution of reaction times (RTs) for correct and incorrect responses, demonstrating that the RTified model provides superior results to both comparison methods.
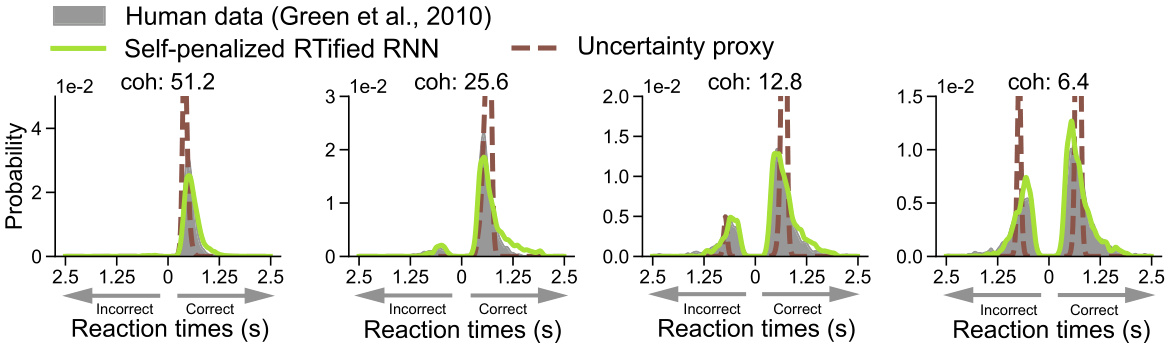
This figure displays the results of the RTified model applied to a random dot motion (RDM) task. It compares the RTified model’s performance against two other methods (entropy-thresholding and uncertainty proxy) under two training conditions: supervised (using human RT data) and self-penalized (optimizing speed and accuracy without human data). Histograms illustrate the distribution of reaction times for correct and incorrect trials at different coherence levels, demonstrating the superior performance of the RTified model in both supervised and self-penalized settings.

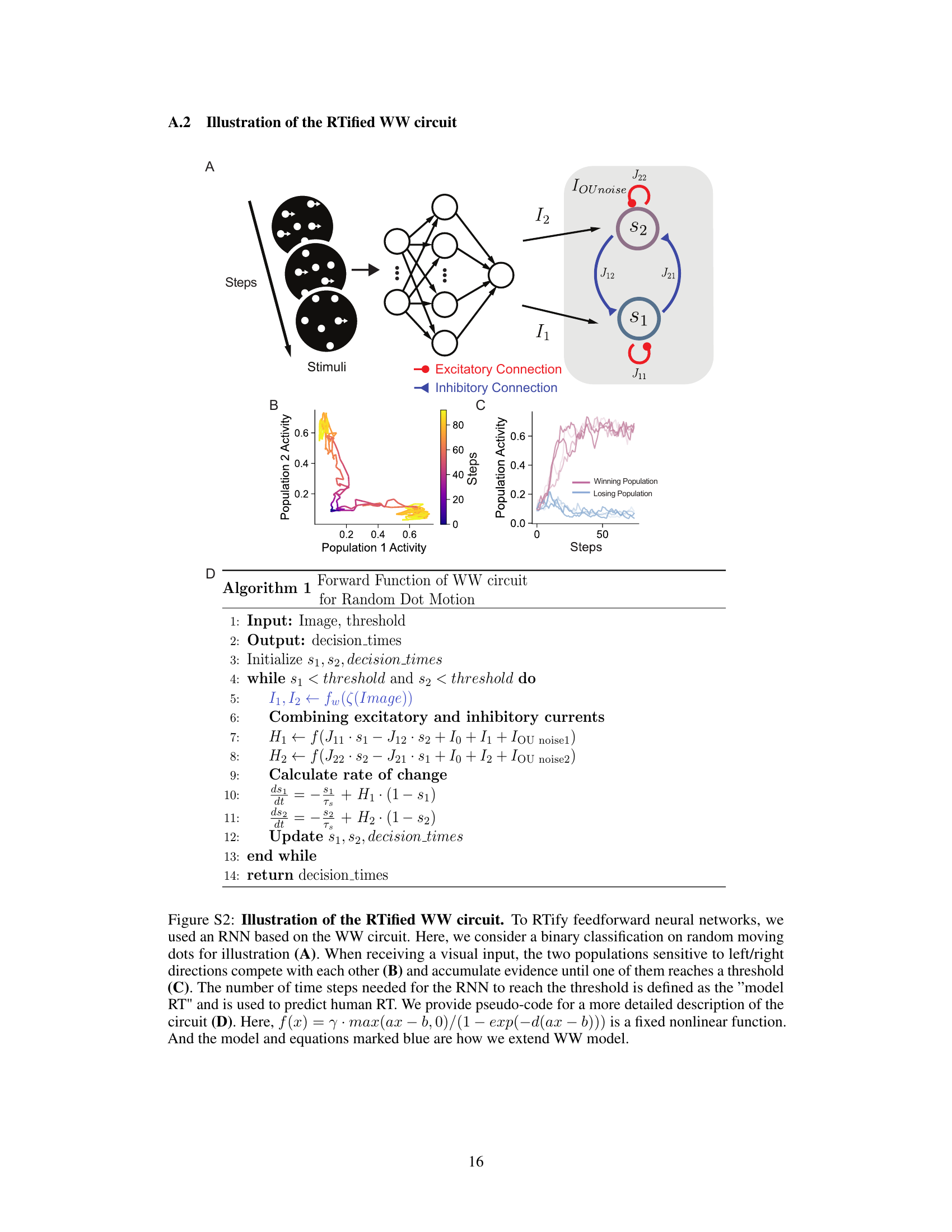
This figure illustrates how the authors integrate a recurrent neural network (RNN) module into a feedforward neural network to model reaction times (RTs). The RNN, based on the Wong-Wang model, allows for dynamic evidence accumulation across multiple neural populations representing different categories. The process culminates in a decision once a population’s activity surpasses a threshold, with the number of steps to reach this threshold serving as a prediction for human RTs. The figure depicts the architecture (A), population activity dynamics (B), and the overall evidence accumulation and decision process (C).

This figure compares the performance of different models on the Random Dot Motion (RDM) task. Panel A shows the Mean Squared Error (MSE) for different coherence levels, demonstrating that the RTified models outperform alternative methods. Panel B shows the classification accuracy, illustrating that RTified models achieve human-like accuracy.

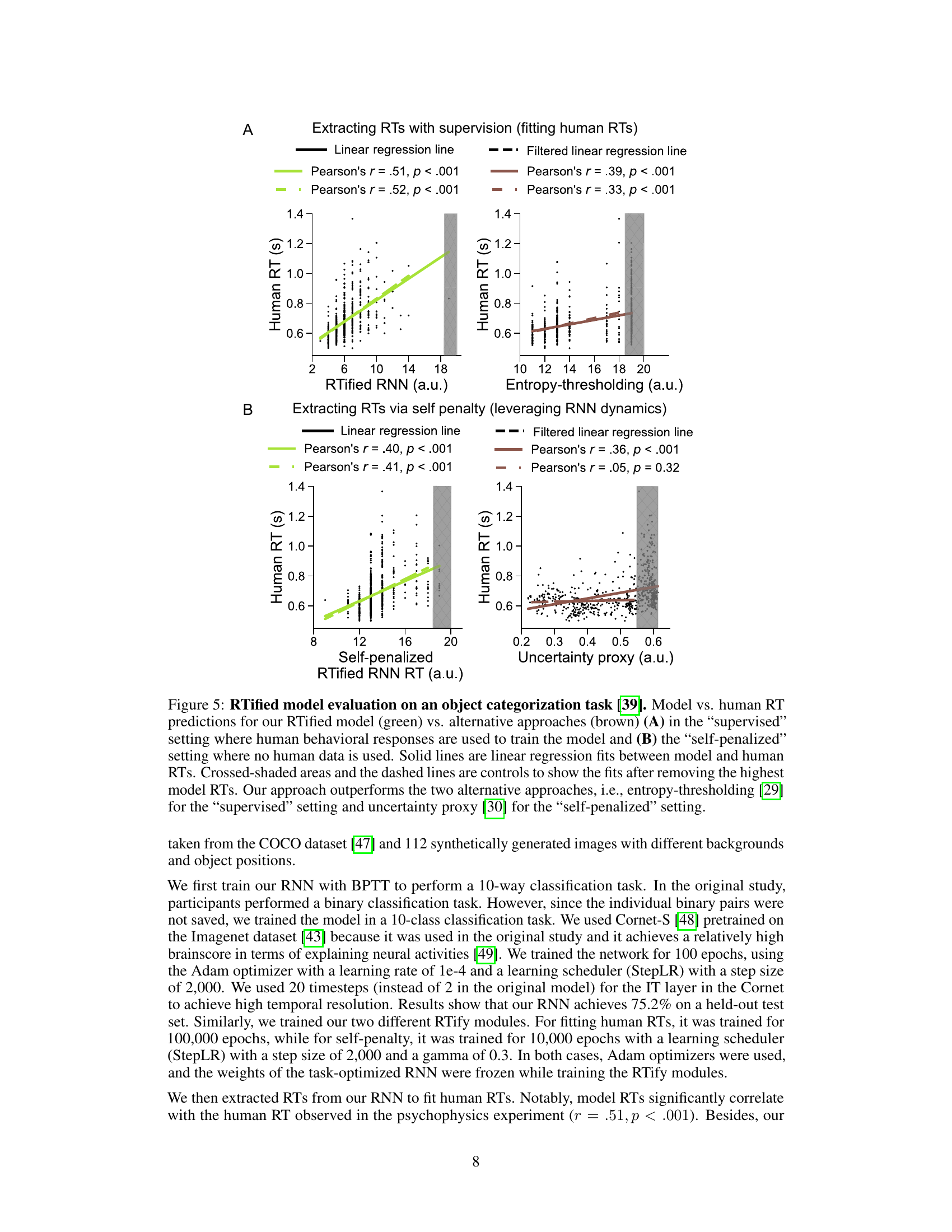
This figure displays the results of evaluating the RTify model on an object categorization task. It compares the RTify model’s performance with two alternative methods in both supervised (using human data) and self-penalized (without human data) settings. The plots show the correlation between model-predicted reaction times and human reaction times, demonstrating the superiority of the RTify method in accurately capturing human reaction time distributions.
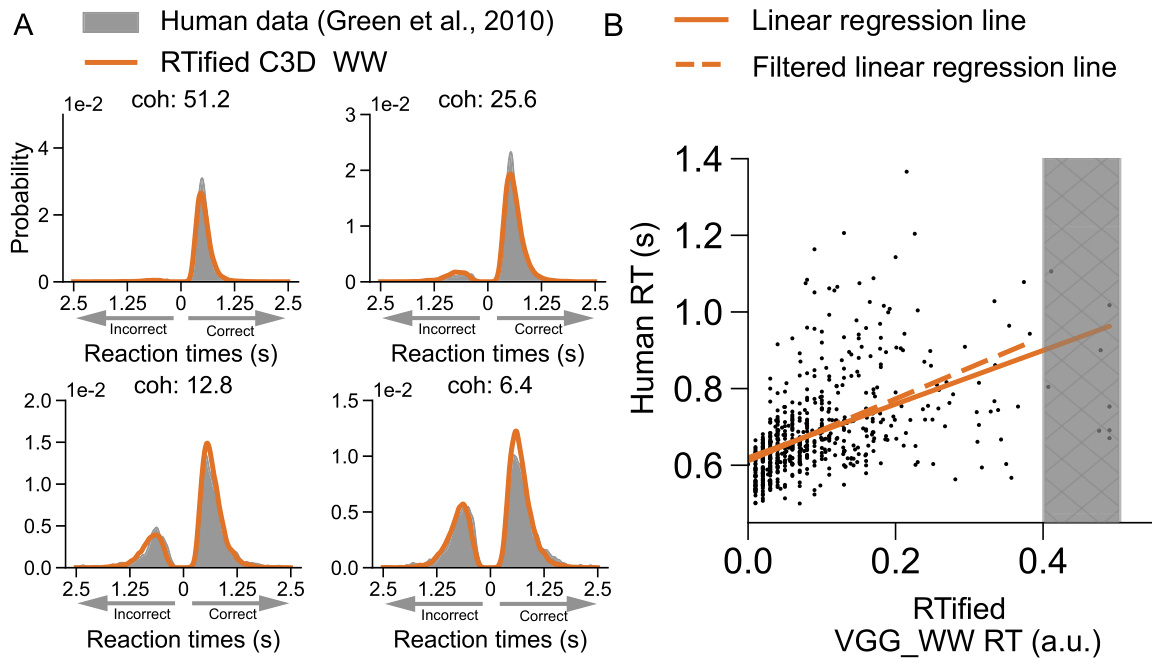
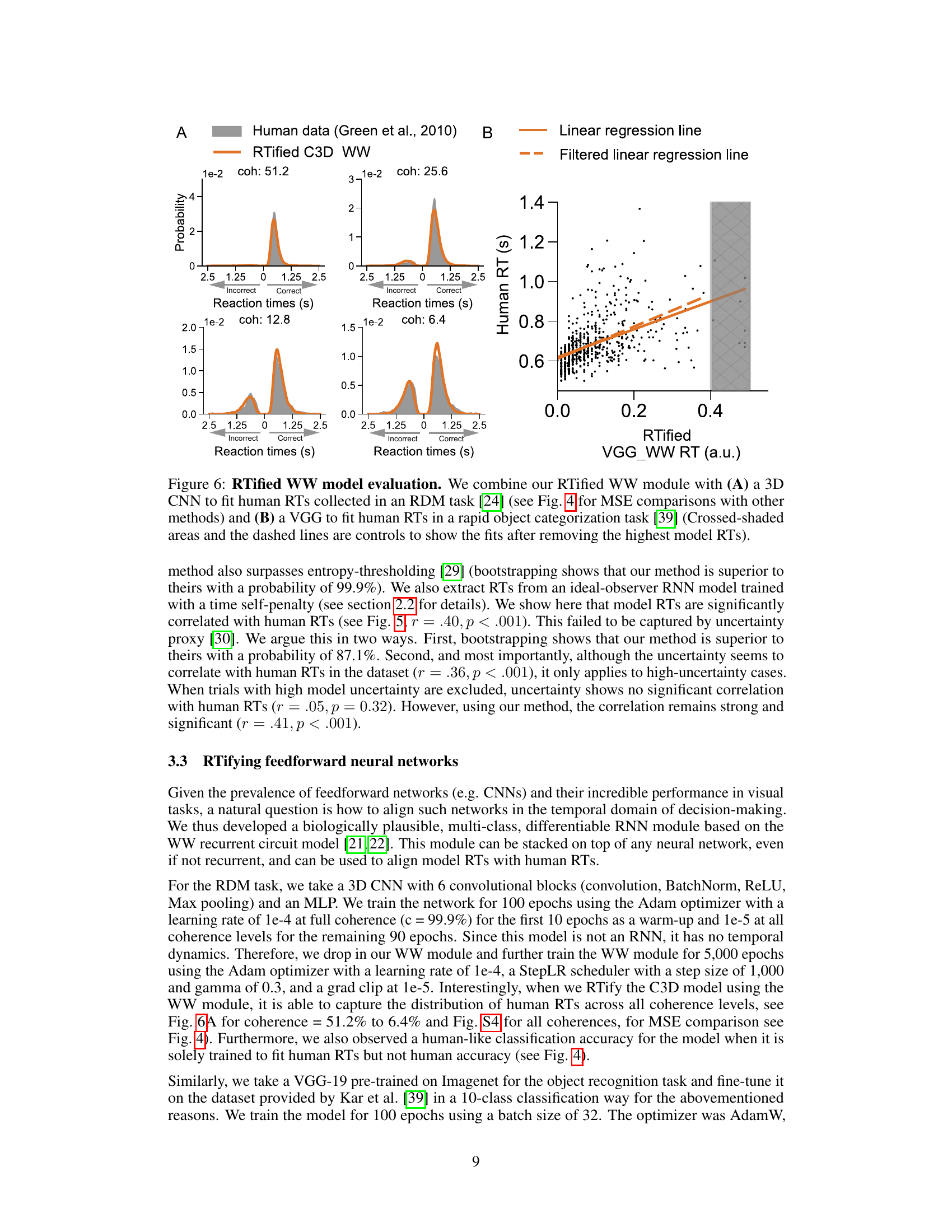
This figure shows the results of applying the RTified WW model to two different tasks: a random dot motion (RDM) task and a rapid object categorization task. Panel A displays the distribution of reaction times for both the model and human participants, comparing their fit across multiple levels of coherence in the RDM task. Panel B shows a scatter plot comparing model reaction times (RTs) to human RTs for the object categorization task, demonstrating a positive correlation. The dashed line represents a filtered regression line, and the shaded area indicates the fit after the removal of extreme values.
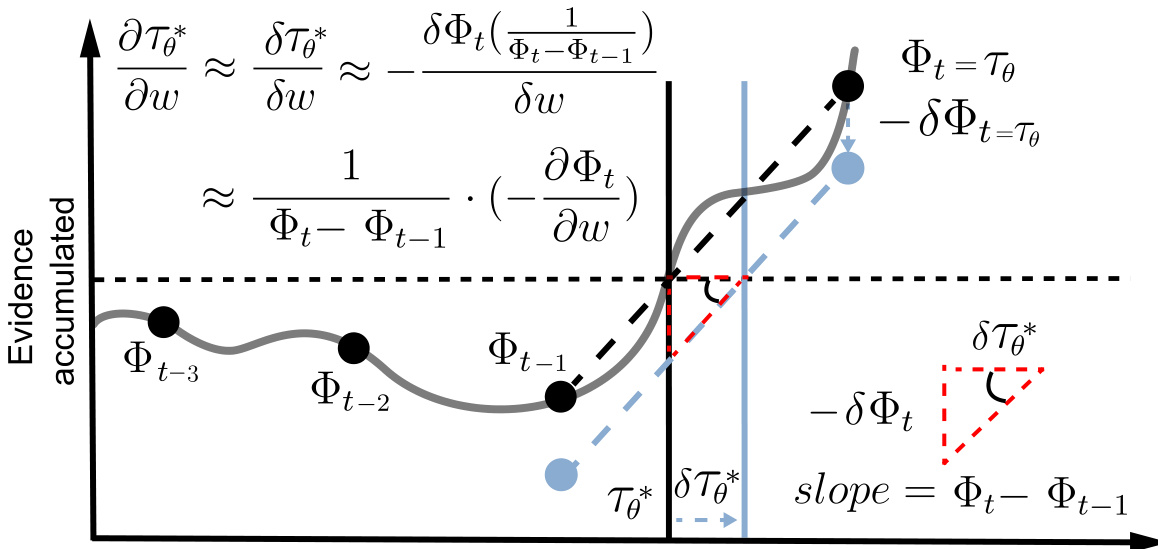
This figure provides a visual illustration of the mathematical proof used in the paper to approximate the gradient of the non-differentiable function τθ(Φ). It demonstrates how a small change in the accumulated evidence (Φt) leads to a proportional change in the time it takes to reach the threshold (τθ(Φ)). The piecewise linear approximation allows for the calculation of the gradient.

This figure illustrates how the authors’ method, RTify, is applied to feedforward neural networks. The RTified WW module, a multi-class RNN based on the Wong-Wang model, is added on top of a CNN. The CNN processes the image, and the output is then fed into the RTified WW module. This module simulates the activity of multiple neural populations competing to reach a threshold. The time it takes for one population to reach the threshold represents the predicted reaction time (RT). Subfigures A, B, and C show, respectively, the architecture of the combined model, the activity of the neural populations over time, and the predicted RT.

This figure displays the results of the RTified model evaluation on a Random Dot Motion (RDM) task, comparing it to two other methods: entropy-thresholding and uncertainty proxy. It shows the distribution of reaction times (RTs) for both correct and incorrect responses at different coherence levels for both the supervised (trained on human data) and self-penalized (trained without human data) versions of the RTified model. The graphs illustrate that the RTified model better fits the human RT data than the other two methods.
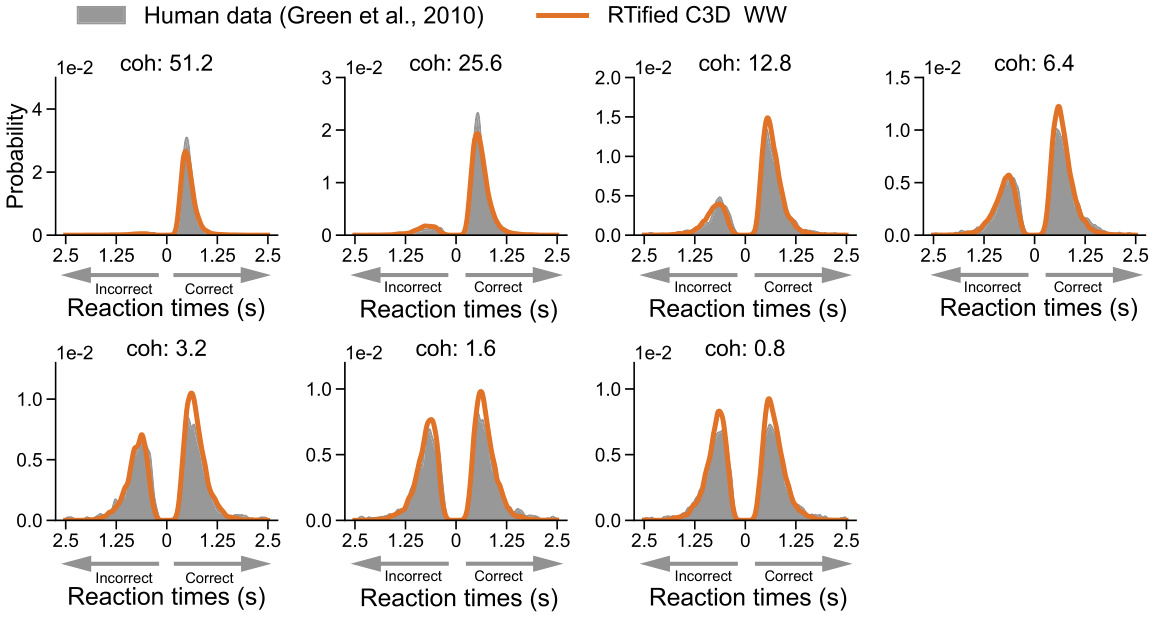
This figure compares the performance of the RTified model with two other methods (entropy-thresholding and uncertainty proxy) in predicting reaction times (RTs) in a random dot motion (RDM) task. The RTified model is tested in two scenarios: with human RT supervision and without human data (self-penalized). The results show that the RTified model significantly outperforms the two other methods across different coherence levels, demonstrating its ability to accurately model human RTs.
Full paper#