TL;DR#
Current query-based black-box attacks often rely on patches or randomness, limiting their effectiveness and efficiency, especially in object detection. This paper addresses these limitations by proposing RFPAR.
RFPAR uses a reinforcement learning approach with ‘Remember’ and ‘Forget’ processes to strategically perturb a minimal number of pixels. This effectively reduces confidence scores in image classification and avoids object detection. Experimental results on ImageNet and MS-COCO demonstrate that RFPAR outperforms existing methods, achieving higher success rates while significantly reducing the number of queries and the size of the perturbation. The extension to the larger Argoverse dataset further validates RFPAR’s effectiveness.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in adversarial machine learning and computer vision. It introduces a novel, efficient black-box pixel attack (RFPAR) that significantly outperforms existing methods in both image classification and object detection. Its focus on pixel-level attacks with limited queries addresses a key challenge in the field, opening avenues for stronger defenses and more realistic attack models. The extension to object detection is particularly significant, pushing the boundaries of current research.
Visual Insights#

🔼 This figure displays example results of the RFPAR attack on three different datasets: ImageNet, MS-COCO, and Argoverse. Each dataset is represented by a column. Each row shows clean images, the adversarial examples generated by RFPAR, and the percentage of pixels modified. The results illustrate that RFPAR can effectively perturb images to cause misclassifications in image classification and object removal in object detection, with only a small percentage of pixels altered.
read the caption
Figure 1: Adversarial examples generated by RFPAR. The first column represents images from ImageNet (image classification), the second column from MS-COCO (object detection), and the third column from Argoverse (object detection). Each row represents a different condition: the first row shows clean images, the second row shows adversarially perturbed images, and the third row shows the perturbation levels with the ratio of attacked pixels to total pixels. Labels in the images indicate detected objects or classifications, such as 'Cock' in ImageNet, '2 Objects' in MS-COCO, and '5 Objects' in Argoverse. In the adversarial row, labels are altered due to perturbations, resulting in misclassifications or undetected objects, such as 'Coil' instead of 'Cock' in ImageNet and no objects detected in MS-COCO and Argoverse. The perturbation row indicates the percentage of pixels attacked in the image. The percentages were 0.004% for ImageNet, 0.027% for MS-COCO, and 0.114% for Argoverse.
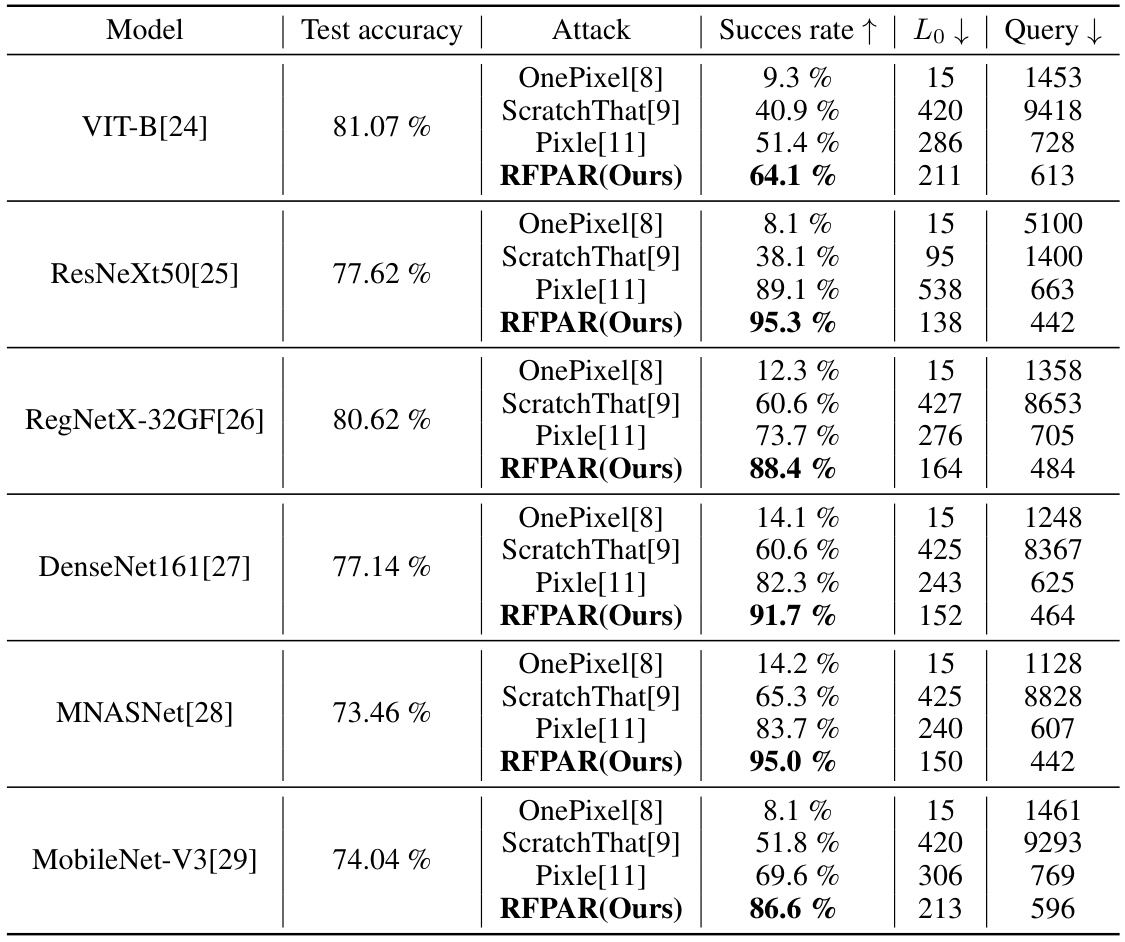
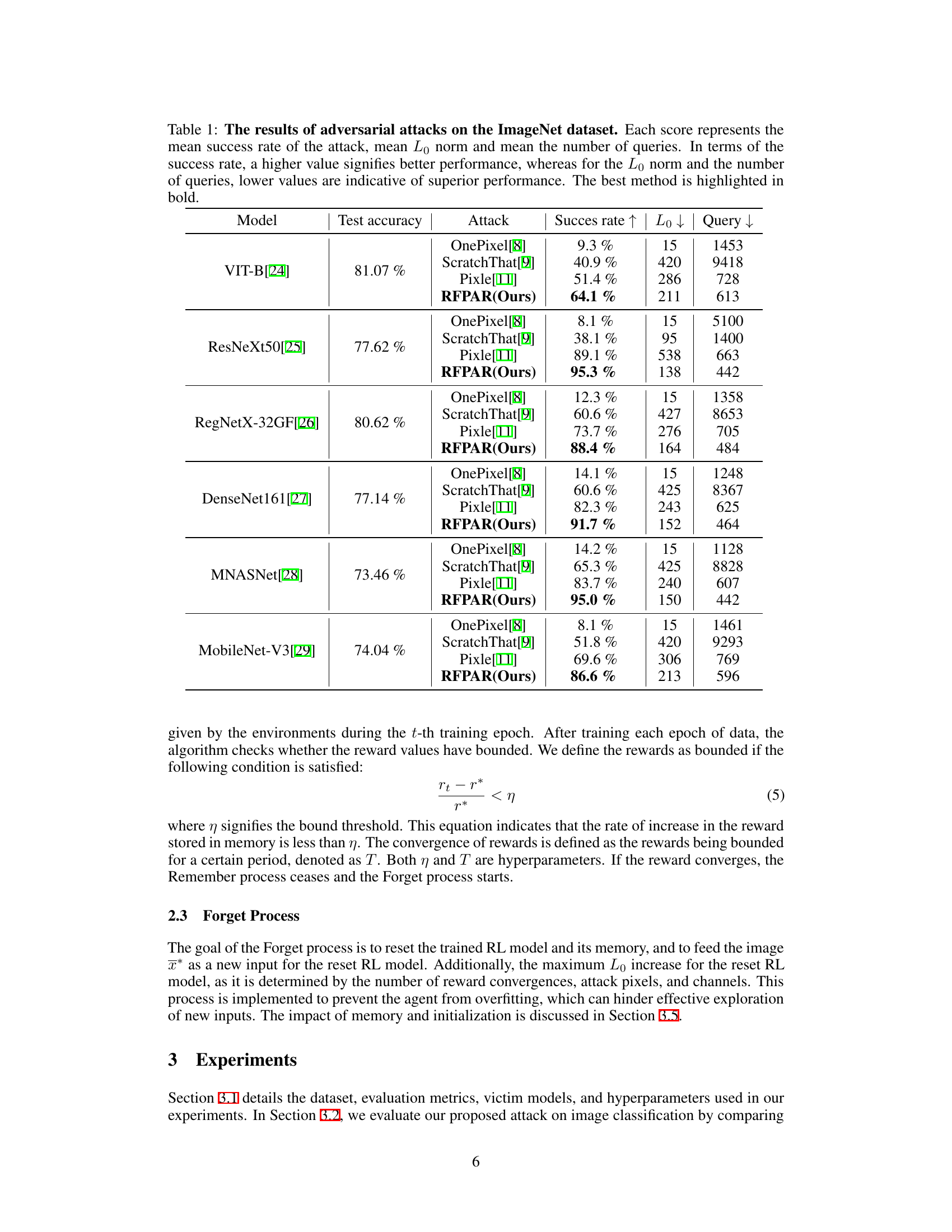
🔼 This table presents a comparison of different adversarial attack methods (OnePixel, ScratchThat, Pixle, and RFPAR) on various ImageNet classification models. For each model and attack method, it shows the mean success rate (higher is better), the mean L0 norm (lower is better, indicating fewer pixel modifications), and the mean number of queries (lower is better, indicating higher efficiency). The best-performing method for each model is highlighted in bold.
read the caption
Table 1: The results of adversarial attacks on the ImageNet dataset. Each score represents the mean success rate of the attack, mean L0 norm and mean the number of queries. In terms of the success rate, a higher value signifies better performance, whereas for the L0 norm and the number of queries, lower values are indicative of superior performance. The best method is highlighted in bold.
In-depth insights#
Amnesia-based Attacks#
Amnesia-based attacks represent a significant advancement in adversarial machine learning, focusing on the manipulation of a limited number of pixels within an image to cause misclassification or object detection failure. The core principle is to leverage ‘forgetting’ mechanisms, where the attack strategically perturbs pixels, forcing the model to disregard previously learned features and thus decreasing the model’s accuracy. This approach contrasts with traditional methods that rely on holistic image modifications, offering a more subtle and effective attack vector. The amnesia-based strategy enhances query efficiency and reduces the number of queries required for successful attacks. Furthermore, its application extends beyond image classification to object detection, demonstrating its versatility and potential impact on diverse applications relying on image-based AI. However, the robustness of these attacks to various defenses, as well as their real-world implications, requires further investigation. The subtle nature of amnesia-based attacks also presents a challenge for detection and mitigation, necessitating the development of robust countermeasures to safeguard AI systems from malicious exploitation.
RFPAR Algorithm#
The RFPAR algorithm, a novel query-based black-box pixel attack, is a two-stage process leveraging reinforcement learning. The Remember stage uses a one-step RL algorithm to iteratively perturb pixels, maximizing reward (reduction in confidence scores). The Forget stage resets the RL agent and memory, restarting the process with the best-performing perturbed image from the Remember stage. This cyclical process mitigates randomness inherent in previous methods and reduces query dependence. RFPAR’s effectiveness stems from its ability to efficiently target a limited number of pixels, significantly outperforming existing pixel attacks in image classification while demonstrating comparable results in object detection. The algorithm’s two-stage structure is key to its efficiency and accuracy, as the iterative refinement process avoids unnecessary queries and improves targeted pixel selection. While further research may explore its limitations on diverse datasets or with varying model architectures, the results highlight RFPAR as a powerful tool for evaluating model robustness against adversarial attacks.
Object Detection#
The research paper explores query-based black-box pixel attacks, focusing significantly on object detection. The authors introduce RFPAR, a novel method leveraging reinforcement learning to enhance the effectiveness of such attacks. RFPAR’s core innovation is in its ability to target scattered pixels rather than relying on patches, which is particularly relevant for object detection where localized perturbations are more likely to evade detection. The paper demonstrates RFPAR’s superior performance against existing state-of-the-art query-based attacks in terms of achieving comparable mAP reduction while requiring fewer queries. This is particularly important for black-box settings where queries are limited. The method’s application extends beyond typical ImageNet datasets to larger scale datasets like Argoverse, further highlighting its potential and robustness. This work contributes to the understanding of vulnerabilities in object detection systems, and suggests promising directions for future research in both attack methods and defensive countermeasures.
Query Efficiency#
Query efficiency in adversarial attacks focuses on minimizing the number of queries to a target model needed to generate a successful attack. Reducing queries is crucial for practical attacks, as excessive queries can be easily detected or blocked, especially in black-box settings where model information is limited. This paper’s proposed RFPAR method addresses this by intelligently selecting pixels to perturb. RFPAR uses a reinforcement learning approach to manage the trade-off between attack effectiveness and query count. The ‘Remember and Forget’ mechanism helps RFPAR focus the attack, improving efficiency compared to previous methods that heavily rely on randomness or extensive patch exploration. The reduction in queries demonstrates a significant improvement in stealth and practicality, making it a valuable contribution to the field of adversarial attacks.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency of the Remember and Forget processes within RFPAR is crucial. This might involve investigating more advanced RL algorithms or exploring alternative memory management strategies to reduce the number of queries required while maintaining attack effectiveness. Another critical area is extending RFPAR to a broader range of object detection models and datasets. Evaluating its performance against diverse architectures and in various real-world scenarios is necessary to assess its generalizability and robustness. Furthermore, research should focus on developing defenses against RFPAR. This necessitates exploring novel training methods or architectural modifications that enhance the resilience of deep learning models to pixel-based attacks. Finally, investigating the potential for transfer learning in the context of RFPAR could lead to more efficient attack strategies, reducing the computational cost and number of queries needed to generate effective adversarial examples.
More visual insights#
More on figures

🔼 This figure illustrates the workflow of the RFPAR attack, which consists of two main processes: Remember and Forget. The Remember process uses reinforcement learning to iteratively generate and refine adversarial images by maximizing rewards. The Forget process resets the model and memory, leveraging the best-performing adversarial image from the Remember process to start a new iteration. This cycle repeats until convergence or a maximum number of iterations is reached.
read the caption
Figure 2: The model architecture of RFPAR: the Remember and Forget process. During the Remember process, the RL model generates perturbed images and corresponding rewards. Memory compares these with previously stored values and retains only the highest reward and its associated image. Once the rewards converge to a certain value, the Forget process starts and resets the RL agent and memory, then reintroduces the perturbed images that gained the highest reward to the Remember process. The process continues until an adversarial image is generated or a predefined number of cycles is reached, at which point it terminates.

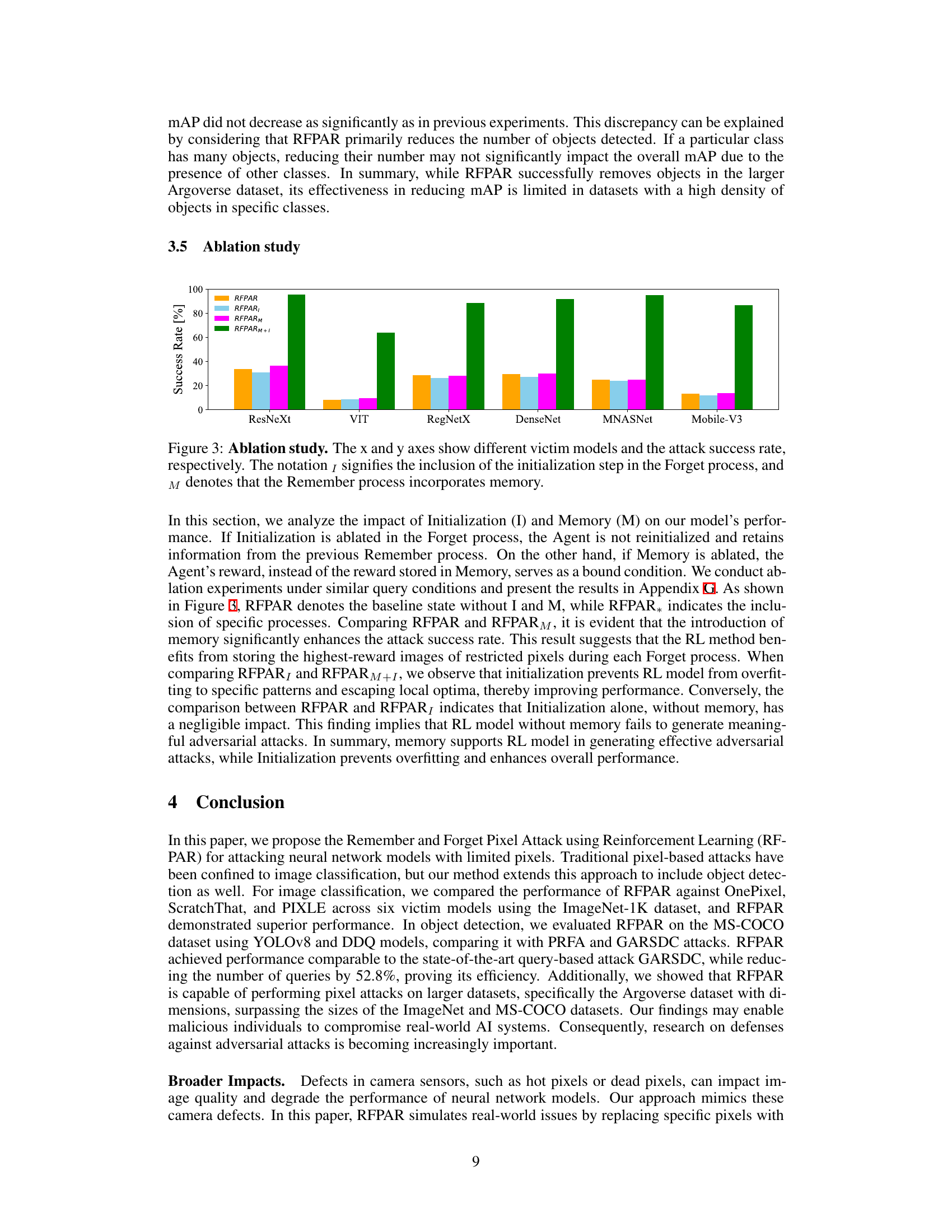
🔼 This ablation study analyzes the impact of Initialization (I) and Memory (M) on the RFPAR model’s performance. The four bars for each model represent: the baseline RFPAR; RFPAR without initialization (I); RFPAR without memory (M); and RFPAR with both initialization and memory. The results show that both Initialization and Memory significantly improve the attack success rate, indicating that the RL agent benefits from both resetting and storing high-reward image information.
read the caption
Figure 3: Ablation study. The x and y axes show different victim models and the attack success rate, respectively. The notation 1 signifies the inclusion of the initialization step in the Forget process, and M denotes that the Remember process incorporates memory.

🔼 This figure shows several examples of adversarial attacks generated by the RFPAR method on the ImageNet dataset. Each row presents a clean image, the difference between the clean image and the adversarial image (delta), and the resulting adversarial image. The labels predicted by the model are shown below each image, demonstrating the impact of the adversarial attacks.
read the caption
Figure 4: Adversarial examples generated by RFPAR on the ImageNet dataset. The 'Original Image' is the original unaltered image, the 'Delta' represents the difference between the Original Image and the Adversarial Image, and the 'Adversarial Image' is the image with the altered prediction. The predicted labels are shown below the Original Image and the Adversarial Image.

🔼 This figure shows the results of applying the RFPAR attack on the MS-COCO dataset for object detection. It demonstrates the impact of varying the attack intensity (controlled by parameter α) on both the generated perturbations (Delta Images) and the resulting adversarial images. The figure shows that as α increases, more pixels are modified, leading to more significant changes in the detected objects.
read the caption
Figure 5: Adversarial examples generated by RFPAR on the MS-COCO dataset. The Original Image represents the unaltered image, and the Delta shows the difference between the Original Image and the Adversarial Image. The parameter α is a hyperparameter that determines the attack level; a higher value of α attacks more pixels. We conducted experiments with α ranging from 0.01 to 0.05. The Delta Image resulting from α values of 0.01 to 0.05 is presented in columns 2 to 6, and the Adversarial Image generated from the same α values is shown in columns 7 to 11. The Adversarial Image typically indicates an image with a changed prediction, but in this context, it also includes unsuccessful attacks. We present the results of Delta and Adversarial Images according to different values of α.
More on tables

🔼 This table presents the results of the RFPAR attack on two object detection models, YOLOv8 and DDQ. It shows the average percentage of removed objects (RM), the mean average precision drop (mAP), the average L0 norm (Lo - number of pixels changed), and the average number of queries needed for the attack at different pixel attack rates (α). Lower mAP and Lo values, as well as higher RM values, represent better attack performance.
read the caption
Table 2: Attack Results on Object Detection Models. The subscripts after RFPAR denote a pixel attack rate, a. RM indicates the average percentage of objects removed from the clean image. Lo represents the average ||δ||0. Query denotes the average number of queries made to the victim model. Higher RM, lower mAP, lower Lo, and lower Query values indicate better performance.

🔼 This table compares the performance of three query-based black-box attacks (PRFA, GARSDC, and RFPAR) on the YOLO object detection model. The results show the reduction in mean Average Precision (mAP) and the number of queries required for each attack. RFPAR demonstrates comparable performance to GARSDC in terms of mAP reduction while significantly reducing the number of queries needed.
read the caption
Table 3: Comparison to other methods. RD means reduction in mAP.
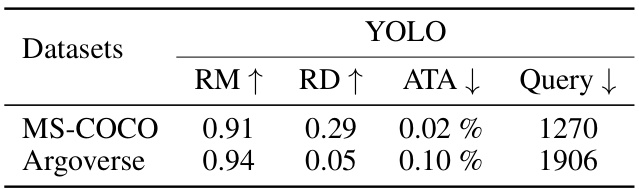
🔼 This table compares the performance of the RFPAR attack on the MS-COCO and Argoverse datasets. It shows the average percentage of objects removed (RM), the reduction in mean Average Precision (mAP), the percentage of the image area attacked (ATA), and the average number of queries made to the victim model. The results demonstrate that RFPAR is effective in removing objects across different datasets, although its effectiveness in reducing mAP is limited in datasets with a high density of objects. Specifically, on Argoverse with higher image resolution, RFPAR achieved a high object removal rate while attacking a small portion of the image.
read the caption
Table 4: Comparison on dataset. ATA means the ratio of altered pixels to the image size.

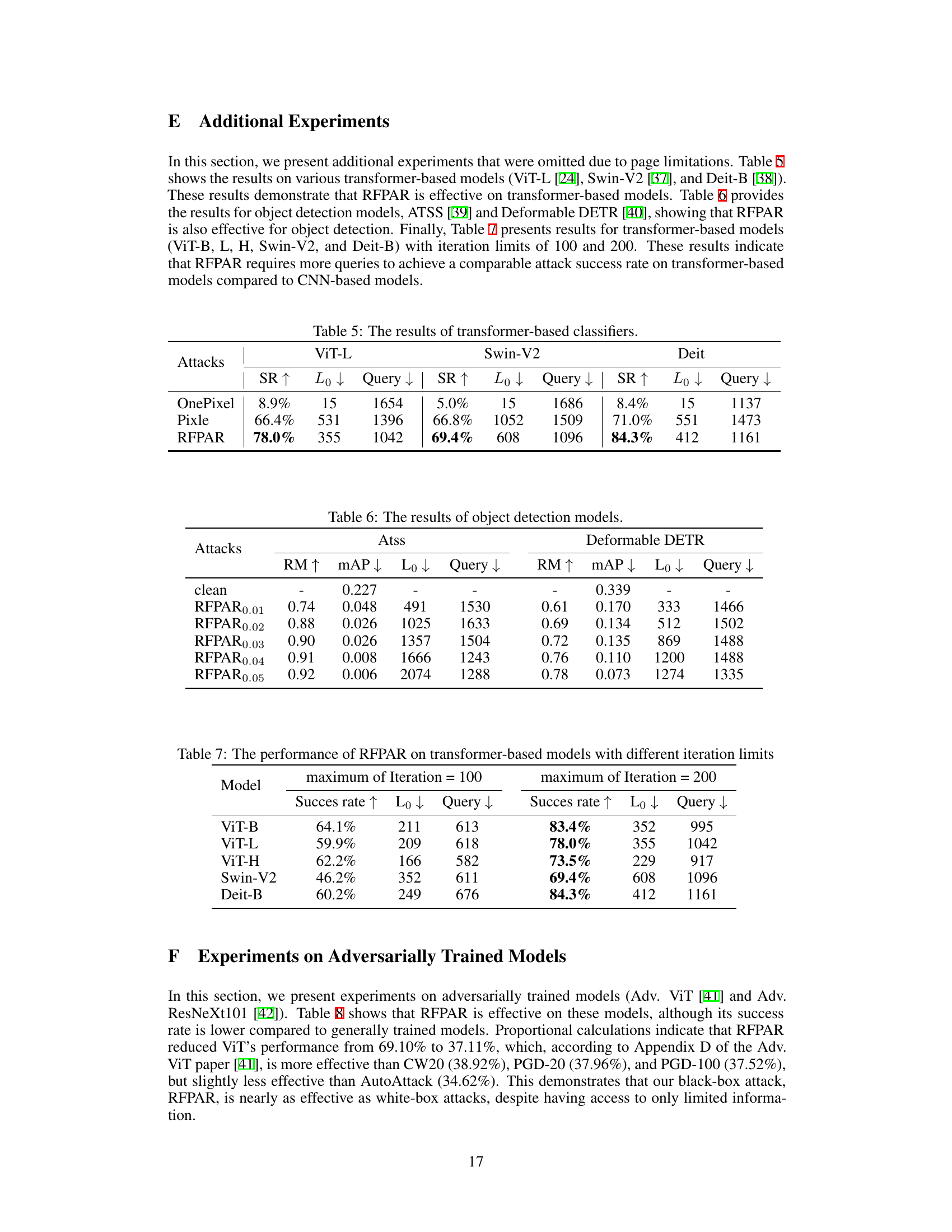
🔼 This table presents the results of adversarial attacks on different transformer-based image classification models: ViT-L, Swin-V2, and Deit. For each model, it shows the success rate (SR), the average L0 norm (representing the number of pixels modified), and the average number of queries needed to generate an adversarial example. Higher success rates and lower L0 norms and query counts indicate better attack performance. The table compares the performance of three different attack methods: OnePixel, Pixle, and RFPAR (the proposed method).
read the caption
Table 5: The results of transformer-based classifiers.

🔼 This table compares the performance of the RFPAR attack with different pixel attack rates (from 0.01 to 0.05) on two object detection models: YOLOv8 and DDQ. The metrics used are RM (the average percentage of objects removed), mAP (mean Average Precision), Lo (the average number of perturbed pixels), and Query (the average number of queries made to the model). Higher RM and lower mAP values indicate better attack performance, while lower Lo and Query values indicate greater efficiency.
read the caption
Table 6: The results of object detection models.

🔼 This table presents the results of applying the RFPAR attack to various transformer-based models (ViT-B, ViT-L, ViT-H, Swin-V2, and DeiT-B) with two different maximum iteration limits: 100 and 200. It shows the success rate of the attacks (higher is better), the L0 norm (lower is better, representing the sparsity of the attack), and the number of queries required (lower is better). Comparing the results across different models and iteration limits helps to understand the impact of these factors on RFPAR’s effectiveness.
read the caption
Table 7: The performance of RFPAR on transformer-based models with different iteration limits
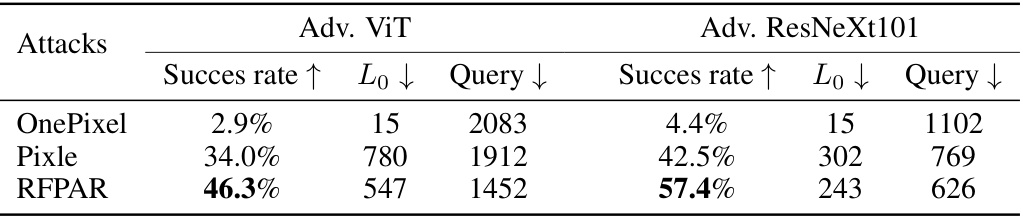
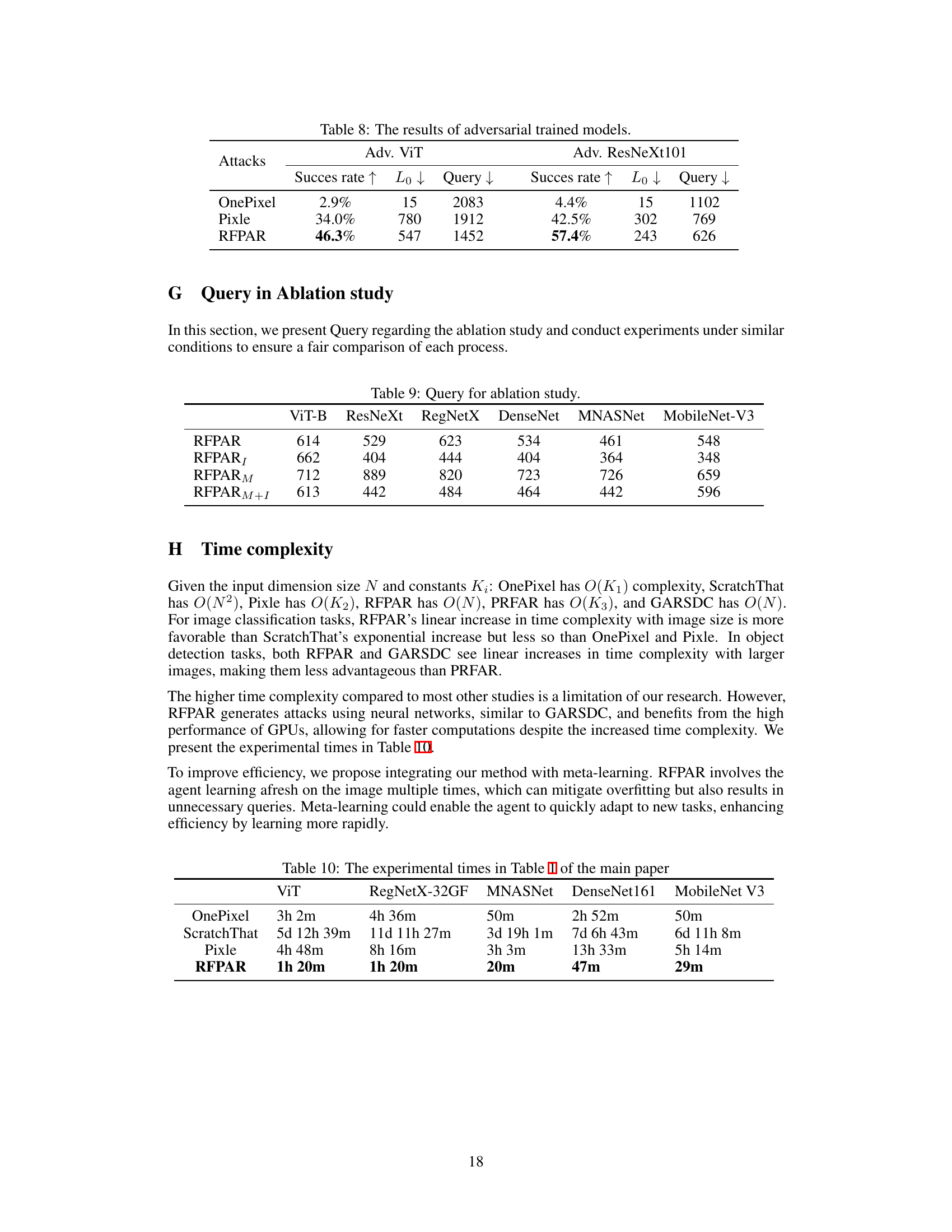
🔼 This table presents the results of adversarial attacks against adversarially trained models (Adv. ViT and Adv. ResNeXt101). It compares the performance of OnePixel, Pixle, and RFPAR in terms of success rate (higher is better), L0 norm (lower is better, representing the number of pixels changed), and the number of queries (lower is better). The results show that RFPAR outperforms the other methods on both models, demonstrating its effectiveness even against adversarially trained models.
read the caption
Table 8: The results of adversarial trained models.

🔼 This table presents the number of queries required for different attack methods in an ablation study. The ablation study focuses on evaluating the impact of Initialization (I) and Memory (M) on the model’s performance. RFPAR represents the baseline attack method without I and M, while RFPARI, RFPARM, and RFPARM+I represent variations of the method with different combinations of I and M. The table shows that the inclusion of memory significantly increases the number of queries required, while the addition of initialization does not significantly affect the query count.
read the caption
Table 9: Query for ablation study.

🔼 This table presents a comparison of different adversarial attack methods (OnePixel, ScratchThat, Pixle, and RFPAR) on various image classification models (VIT-B, ResNeXt50, RegNetX-32GF, DenseNet161, MNASNet, and MobileNet-V3) using the ImageNet dataset. The metrics used for comparison are success rate (higher is better), L∞ norm (lower is better, indicating fewer pixels modified), and the number of queries (lower is better, indicating higher efficiency). RFPAR’s performance is highlighted in bold, showing its superior performance compared to other methods.
read the caption
Table 1: The results of adversarial attacks on the ImageNet dataset. Each score represents the mean success rate of the attack, mean L∞ norm and mean the number of queries. In terms of the success rate, a higher value signifies better performance, whereas for the L∞ norm and the number of queries, lower values are indicative of superior performance. The best method is highlighted in bold.
Full paper#