↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Creating realistic video backgrounds that seamlessly integrate with moving foreground subjects is a tedious and expensive process, traditionally requiring extensive manual effort in the movie and visual effects industries. This problem hinders the rapid iteration of creative ideas during filmmaking. Existing video editing and inpainting methods are limited because they either perform holistic changes to the entire video or cannot precisely follow artistic creative intentions. They often fail to adapt the background to the subject’s movement and may not work well with complex scenes.
ActAnywhere, a novel video diffusion model, addresses these issues by taking a foreground segmentation sequence and a condition image (either background-only or a composite) as input, and generating a video of the subject interacting naturally within the new background. The model uses a self-supervised training procedure and conditions the generation process on both the foreground segmentation and the condition image, resulting in improved realism and adherence to the background’s characteristics. Extensive evaluation shows ActAnywhere significantly outperforms existing methods, producing videos with realistic foreground-background interactions and high generalization capabilities. This greatly improves efficiency and expands creative possibilities for video content creation.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles a crucial problem in filmmaking and visual effects: automatically generating realistic video backgrounds that adapt to foreground subject motion. Its novel approach using a video diffusion model opens new avenues for creative storytelling and efficient visual effects production, saving time and resources for artists and filmmakers. The findings also have implications for other fields dealing with video generation and manipulation.
Visual Insights#

This figure shows the results of ActAnywhere, a video generation model. Given a sequence of foreground segmentations (top) and a background condition image (left), the model generates a video of the subject interacting realistically with the background. The examples demonstrate the model’s ability to handle diverse scenarios and subjects, including humans and ducks, and to generate realistic details like water splashes and shadows.

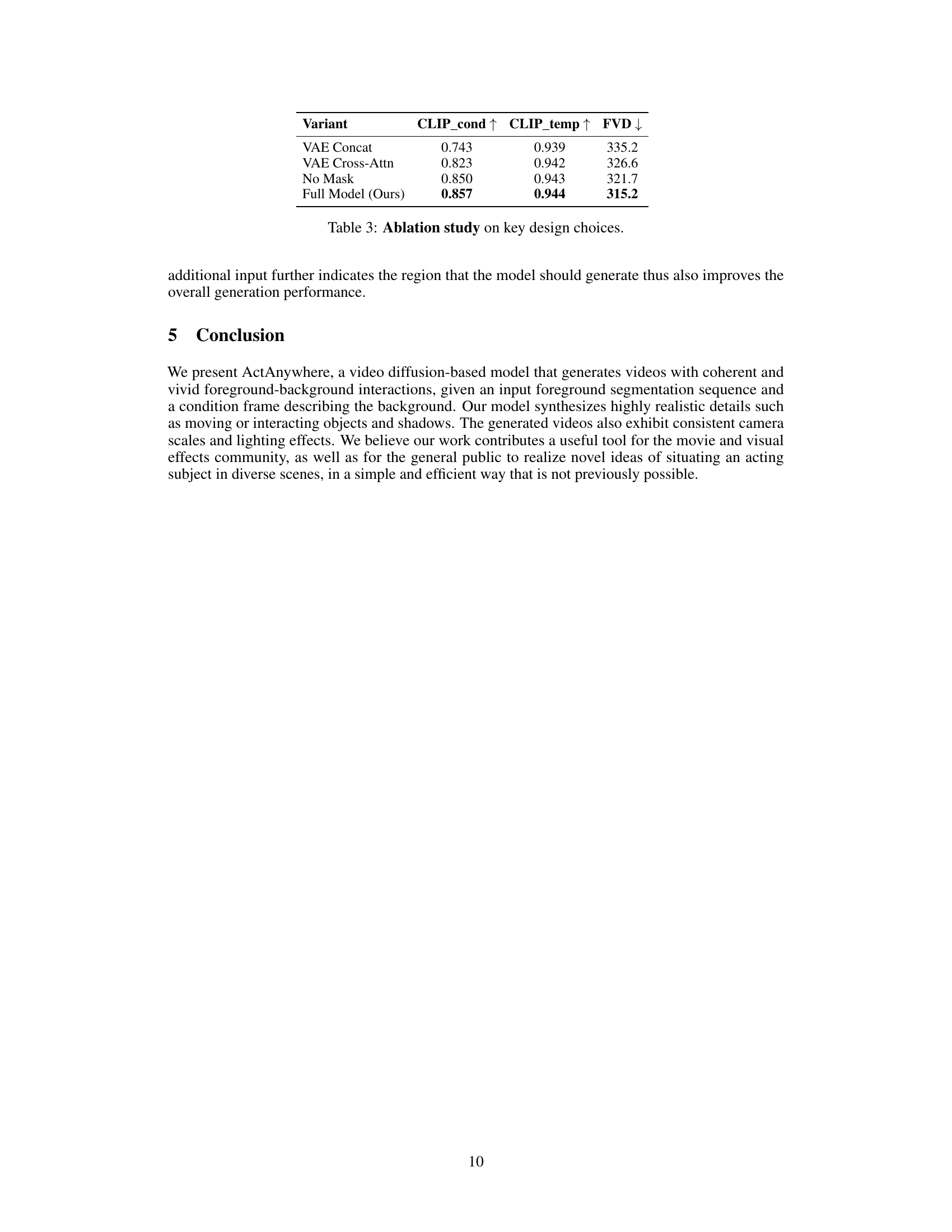
This table presents a quantitative comparison of the proposed ActAnywhere model against several baseline methods. Three metrics are used for evaluation: CLIP_cond (measuring the consistency of generated videos with the condition image), CLIP_temp (measuring the temporal consistency within the generated videos), and FVD (measuring the overall quality and realism of the generated videos). Lower FVD scores indicate better visual quality. The results show ActAnywhere outperforms the baselines across all three metrics, demonstrating its superiority in generating coherent and realistic videos.
In-depth insights#
Subject-Aware Video#
The concept of ‘Subject-Aware Video’ represents a significant advancement in video processing and generation. It moves beyond generic video manipulation techniques by explicitly considering the foreground subject’s motion and interaction with the background. This allows for the creation of more realistic and believable videos, critical for applications like filmmaking and visual effects. Seamless integration of the subject into novel backgrounds is a key challenge addressed by this approach, requiring sophisticated algorithms to handle lighting, shadows, and camera movement coherently. The success of ‘Subject-Aware Video’ depends heavily on accurate foreground segmentation, providing the system with precise information about the subject’s location and shape in each frame. The ability to generalize to diverse scenarios, including varied subject types and background settings, further demonstrates the robustness and potential of the technology. Future research could explore enhancing the realism of interactions by incorporating physics-based simulations and improving the handling of occlusions and complex lighting scenarios. Ultimately, ‘Subject-Aware Video’ points towards an exciting future where realistic video manipulation becomes increasingly accessible and efficient.
Diffusion Model#
Diffusion models, a class of generative models, are prominent in the research paper for their ability to generate high-quality video backgrounds. The core idea involves a diffusion process that gradually adds noise to an image until it becomes pure noise, then reverses this process using a neural network to learn to remove noise step-by-step. This approach allows for high-resolution and detailed video generation by carefully controlling the noise levels at each stage. The paper leverages diffusion models’ capability to handle complex temporal dependencies in video data, creating realistic foreground-background interactions. Furthermore, the success of the approach highlights the power of diffusion models in handling conditional inputs, allowing the model to adhere to the user-specified background image and foreground subject motion while generating a novel video. The research paper demonstrates the effectiveness of diffusion models in generating realistic and high-quality video content, showcasing their growing potential in diverse video processing and generation tasks.
Video Backgrounds#
Generating realistic video backgrounds that seamlessly integrate with foreground subjects presents a significant challenge. Traditional methods are tedious and expensive, often requiring extensive manual effort. This paper tackles this problem by introducing a novel approach to automatically generate video backgrounds tailored to the motion of the foreground subject, significantly improving efficiency and reducing the manual workload. The method uses a video diffusion model, enabling dynamic adaptation to subject movement. A key component is the use of a condition frame, either a background-only image or a composite frame, which guides the generation process, ensuring coherence and realism. The model demonstrates strong generalization capabilities across various subject types (human, animal, animated) and video styles, marking a significant advancement in the field of visual effects and video generation. The results highlight the potential of automated video background generation for creative applications and movie production.
Ablation Experiments#
Ablation experiments systematically remove components of a model to assess their individual contributions. In a video background generation model, this might involve removing the temporal attention mechanism, the CLIP image encoder for background conditioning, or different input modalities. The goal is to isolate each part’s effect on the final output quality, such as visual realism, temporal consistency, or adherence to the condition frame. By comparing the results with and without each component, researchers determine which features are essential and which may be redundant or detrimental. This helps optimize model architecture, leading to improved performance, efficiency, and better understanding of the underlying model workings. Identifying crucial components allows for targeted improvements in future model iterations. A successful ablation study shows a clear hierarchy of importance among model elements, demonstrating the key drivers of performance and guiding future model development.
Future Directions#
Future research could explore enhancing ActAnywhere’s capabilities by addressing several key areas. Improving the robustness to noisy or incomplete foreground segmentations is crucial for real-world applicability. Current methods rely on relatively clean segmentations; handling occlusions, motion blur, or inaccuracies would significantly expand its use. Secondly, research into more efficient models is needed, as current approaches are computationally expensive. Reducing inference time would enable real-time applications and broaden accessibility. Further exploration is required to improve the quality and diversity of generated backgrounds. While the current model produces realistic results, enhancing the level of detail, variation, and consistency across different scenes and conditions is key. Finally, expanding the range of supported foreground subjects and scenarios would further increase the system’s utility. Addressing these limitations will enable ActAnywhere to seamlessly transition from a research project to a practical and versatile tool for filmmakers and visual effects artists alike.
More visual insights#
More on figures
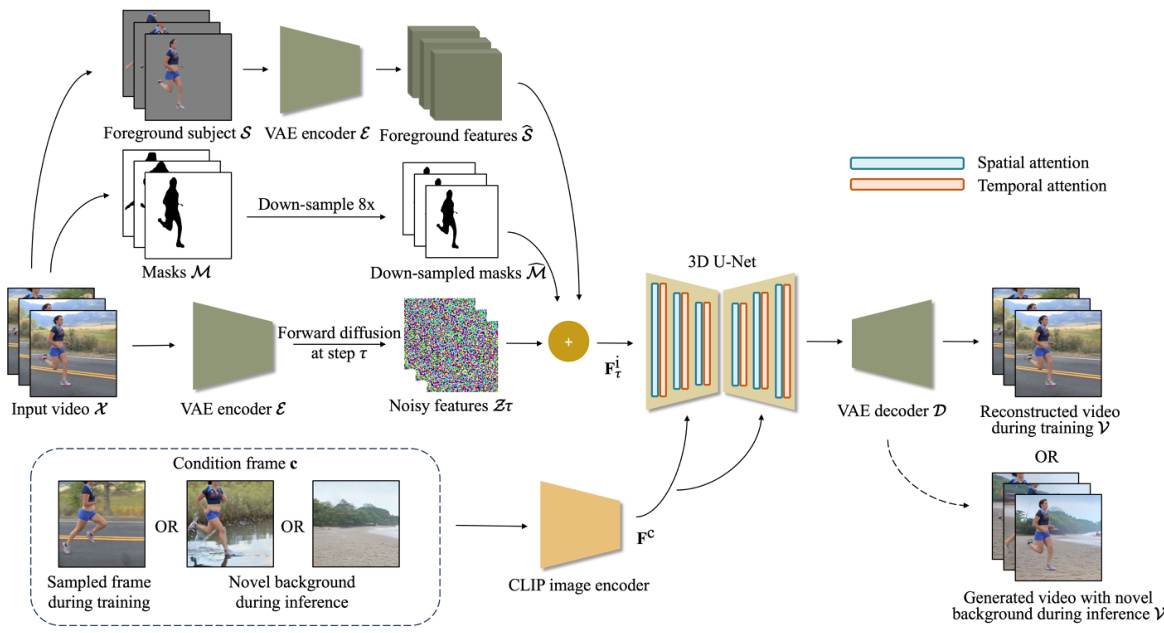
This figure illustrates the architecture of the ActAnywhere model. During training, the model takes a video, its corresponding foreground segmentation masks, and a randomly sampled frame from the video as input. The foreground segmentation and masks are encoded into latent features using a VAE, and then concatenated with noisy latent features of the input video. These features are passed through a 3D U-Net with spatial and temporal attention layers, conditioned on the CLIP features of the sampled frame. The output is a reconstructed video. At test time, the model takes a video, its corresponding foreground segmentation masks, and a novel background image as input. The features are processed similarly to training, except that the condition is provided by the CLIP features of the background image instead of a sampled frame from the video. The output is a generated video with the subject interacting with the novel background.

This figure shows several examples of video background generation results using the ActAnywhere model. The top half shows results where the input included a composite image of the subject with a partially generated background, while the bottom half shows results from using a background-only image as input. The input videos, in all cases, are from the held-out subset of the HiC+ dataset.

This figure compares the results of ActAnywhere with other state-of-the-art video generation and editing methods. Two video examples from the DAVIS dataset are used for comparison. For each example, the figure shows the input video, the condition frame (as a signal for the generation process), and the generated videos from ActAnywhere and other baselines. This visualization helps to understand the differences in the generated results and evaluate the performance of ActAnywhere in comparison to existing techniques.

This figure shows several examples of video background generation results using the proposed ActAnywhere model. The top half shows results where the model was conditioned on an image with the foreground subject already composited into a new background. The bottom half demonstrates results from using a background-only image as a condition. In both cases, the model successfully adapts the background to match the movement of the foreground subject, creating realistic and coherent videos. The foreground subject sequences are taken from the held-out set of the HiC+ dataset.

This figure shows the results of ActAnywhere on various videos from the HiC+ dataset’s held-out set. The top row shows examples where the model was conditioned on an inpainted frame (a frame where the background was filled in using an image editing tool). The bottom row shows examples where the model was conditioned on a background-only image. In both cases, the model generates coherent videos that adapt the foreground subject’s motion to the background. The diverse examples demonstrate the model’s ability to generalize to various scenes and subjects.

This figure shows the model’s generalization ability to various domains such as gaming, animation, and videos with multiple moving subjects. It demonstrates that the model can successfully generate realistic video backgrounds that adapt to the foreground subject’s motion, even across significantly different visual styles and subject types.

This figure demonstrates the robustness of the ActAnywhere model to inaccurate masks. It shows a video sequence from the HiC+ dataset with two different background condition frames (top row). The middle and bottom rows display six generated frames for each condition, showcasing the model’s ability to generate realistic results even when the input foreground segmentation masks are imperfect. Despite the inaccuracies in the masks, the model successfully generates videos with coherent foreground-background interactions.

This figure illustrates the architecture of the ActAnywhere model. The model takes as input a sequence of foreground segmentations and a condition frame (either a composited image or background-only image). It uses a VAE to encode the foreground segmentation and the condition frame into latent features. These features are then concatenated with noisy latent features of the video frames and fed into a 3D U-Net that denoises the features and generates the video. During training, a randomly selected frame from the training video is used as the condition. During inference, a novel background image can be used as the condition.

This figure showcases the diverse results obtained using the ActAnywhere model. The top row displays examples where a composite image (including both subject and background) was used as the condition input, demonstrating the model’s ability to seamlessly integrate the subject into the provided scene. The bottom row shows examples where only a background image was used as input. Despite the differing input types, ActAnywhere successfully generates coherent video backgrounds in all cases that realistically adapt to the foreground subject’s motion. The foreground sequences are taken from the held-out subset of the HiC+ dataset.
Full paper#