TL;DR#
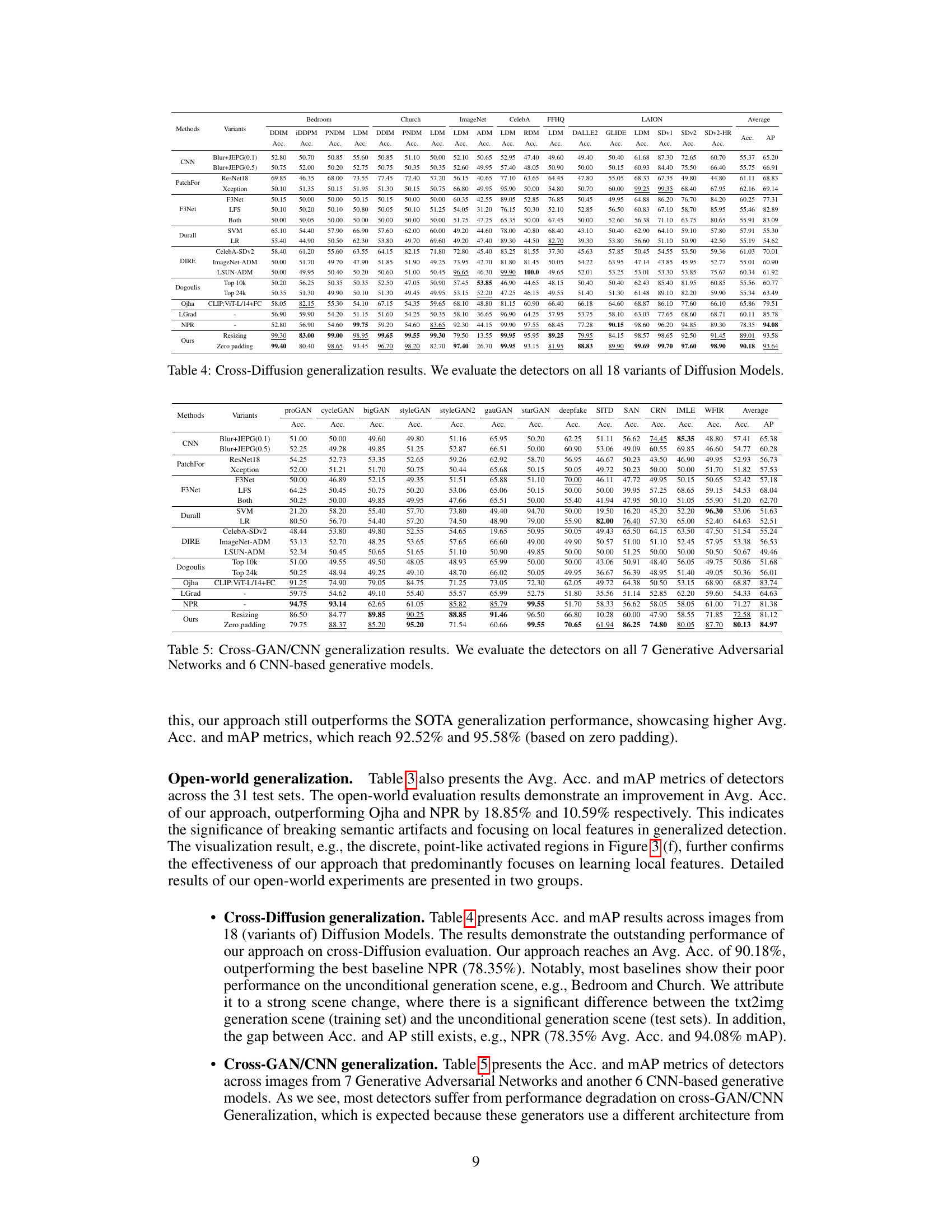
The proliferation of AI-generated images necessitates robust detection methods. Existing detectors, however, often fail to generalize across diverse image scenes, a problem attributed to ‘semantic artifacts’ present in both real and synthetic images, causing overfitting in the detection models. These artifacts are image features that the models learn to associate with either real or fake images, but these vary across different datasets and scenes. This limits the generalizability of the models to new scenes and unseen data.
To tackle this, the paper introduces a novel approach that addresses this challenge by shuffling image patches before training a patch-based classifier. This method aims to disrupt the global semantic information that contributes to overfitting, allowing the model to learn more localized features and improve its ability to generalize across different scenes. The extensive experimental results demonstrate that this new method significantly outperforms previous approaches in both cross-scene and open-world generalization, highlighting its potential for enhancing AI-generated image detection.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI security researchers due to the rise of AI-generated images. It identifies a critical limitation of existing detectors—their inability to generalize across different image scenes—and proposes a novel solution. The findings open new avenues for research into robust AI-generated image detection and more generally, the mitigation of “semantic artifacts” in various machine learning applications. Its comprehensive evaluation across numerous generative models and datasets makes it particularly valuable for benchmarking and developing future detectors.
Visual Insights#
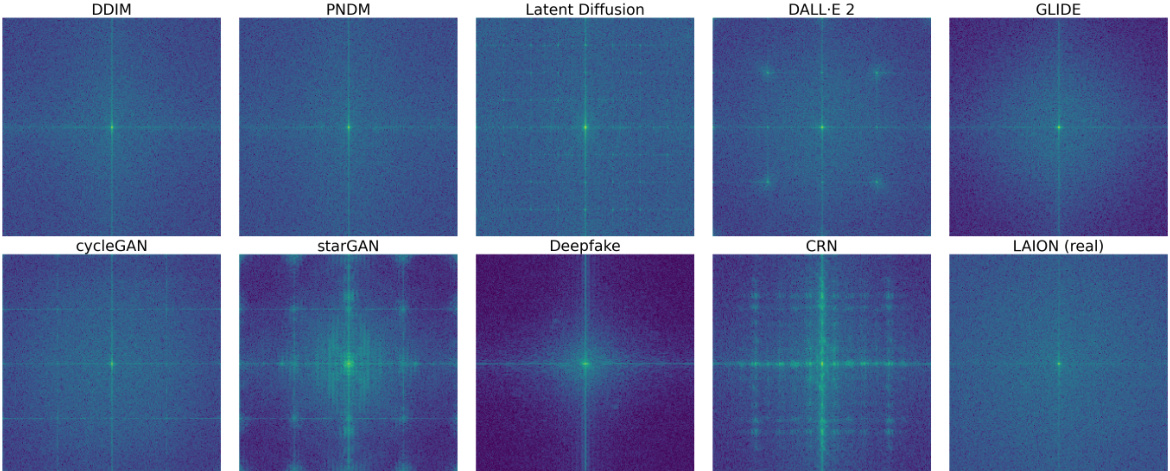
🔼 This figure visualizes the noise residuals power spectrum of images generated by various generative models and a real dataset (LAION). It aims to highlight the differences in artifacts produced by different generative architectures (Diffusion Models and GANs) and CNN-based generators. The spectral patterns are unique for each generator, showcasing distinct artifacts that could be exploited for detection. The figure shows how different generative models create images with various artifacts. These artifacts are visible in the frequency spectrum and differ significantly between GANs, Diffusion Models, and CNN-based generators. The figure’s purpose is to show the uniqueness of artifacts for different generators and to lay the groundwork for a proposed method.
read the caption
Figure 1: Generator artifacts: noise residuals power spectrum of images from 9 generative models and 1 real dataset. Top row: 5 Diffusion Models. Bottom row: 2 GANs, cycleGAN and starGAN, 2 CNN-based generators, Deepfake and CRN, and 1 real dataset, LAION.
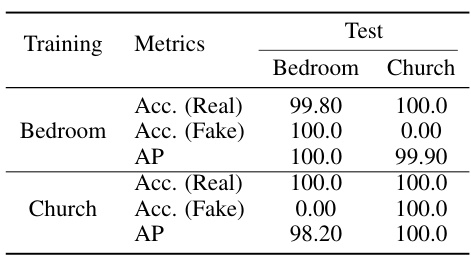
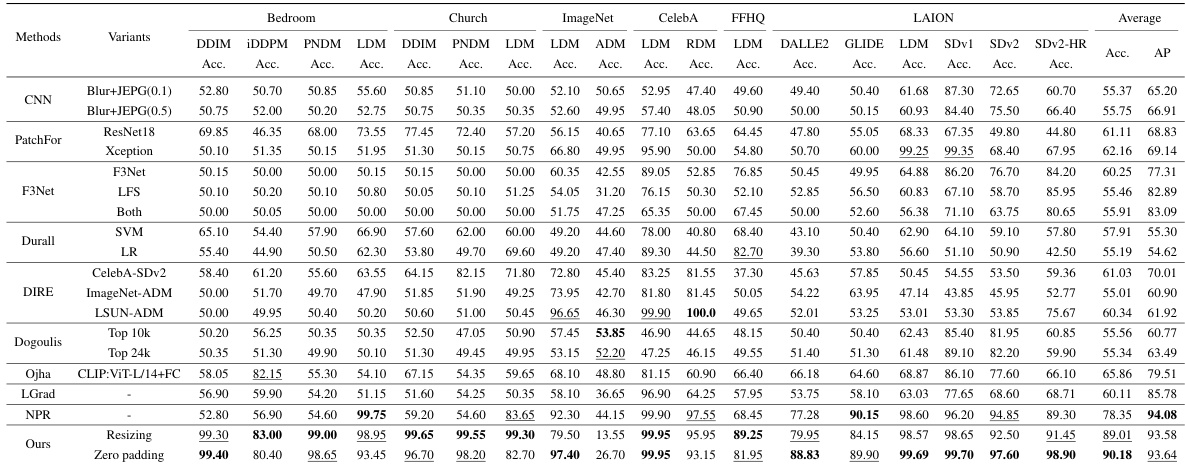
🔼 This table presents the results of cross-scene detection experiments using ResNet-50 models. Two different scene datasets (Bedroom and Church) were used to train the model separately. The table shows the accuracy (at 50% threshold) and Average Precision (AP) for real and fake images within the same scene and across different scenes, highlighting the impact of semantic artifacts on cross-scene generalization.
read the caption
Table 1: Cross-scene detection experiments on ResNet-50 models from ForenSynths [4]. We use 2 sets of training images on different scenes, Bedroom and Church, to retrain the detectors. Detection accuracy (Acc.) (at a threshold of 50%) and Average Precision (AP) are reported.
In-depth insights#
Semantic Artifacts#
The concept of “Semantic Artifacts” introduced in the paper offers a novel perspective on the limitations of existing AI-generated image detectors. These artifacts, inherent in both real and synthetic images, represent scene-specific visual patterns that detectors inadvertently learn during training, leading to poor generalization across different datasets. Unlike previously studied “generator artifacts,” which are specific to the algorithms used, semantic artifacts are deeply rooted in the image content itself. The authors highlight that existing detectors often overfit to these semantic artifacts, resulting in significant performance degradation when exposed to unseen image scenes. This is a crucial observation that challenges the generalizability of current detection methods, pushing research towards novel approaches that explicitly address this scene-dependency. The paper’s proposed solution, using patch shuffling, attempts to mitigate this overfitting by breaking down the global image patterns and focusing on local features.
Patch Shuffle#
The proposed ‘Patch Shuffle’ technique is a novel data augmentation method for improving the generalization of AI-generated image detectors. It addresses the issue of semantic artifacts, which cause detectors to overfit on specific image scenes, hindering cross-scene generalization. By randomly shuffling image patches before training, Patch Shuffle disrupts the global semantic information that detectors tend to rely on, forcing them to focus on local features and thus making them more robust to variations across different datasets. This approach is particularly effective in mitigating the negative impact of scene-specific artifacts, thus enhancing the universality of the detectors. The effectiveness of Patch Shuffle highlights the significance of considering local feature learning in AI-generated image detection, paving the way for improved generalization capabilities and more robust AI security measures.
Cross-Scene Generalization#
The concept of ‘Cross-Scene Generalization’ in AI-generated image detection focuses on a critical limitation of existing detectors: their inability to generalize across different image scenes or datasets, even if trained on multiple generators. This limitation arises from ‘semantic artifacts’, which are scene-specific features present in both real and synthetic images. These artifacts, unlike generator-specific artifacts, are not directly tied to the generation method itself, but rather to the inherent visual characteristics of a specific dataset or scene. This means that a detector performing well on one dataset may fail dramatically when presented with images from a different scene, even if the generative models are the same. Overfitting to these semantic artifacts during training is a major contributor to poor cross-scene generalization, as the model learns to identify scene-specific features rather than truly generalizable characteristics of synthetic images. Therefore, effective strategies must be developed to mitigate the impact of semantic artifacts, promoting robustness and true generalization across diverse, real-world scenarios.
Open-World Testing#
Open-world testing in AI-generated image detection is crucial because real-world scenarios present a vast diversity of unseen images. Standard benchmarks often fail to capture this complexity, focusing instead on limited datasets and specific generator types. Open-world evaluation needs to assess generalization across numerous generators (GANs, diffusion models, etc.), diverse image sources, and various image characteristics (resolution, styles, artifacts, etc.). Robust detectors must maintain high accuracy under these challenging conditions. A key aspect is how well the model adapts to unknown distributions and avoids overfitting to specific training data artifacts. Therefore, metrics beyond simple accuracy are essential, possibly incorporating measures that reflect uncertainty and confidence in predictions. Open-world testing also highlights the limitations of current approaches, showcasing the ongoing need for more robust and adaptable detection methods that address the continual evolution of AI image generation technology.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In the context of AI-generated image detection, ablation studies might involve removing different parts of the detection pipeline (e.g., specific layers in a convolutional neural network, preprocessing steps, or the patch shuffling technique) to evaluate their impact on the model’s performance. Such experiments reveal the relative importance of each component, helping researchers understand which aspects are crucial for successful generalization and which might be redundant or detrimental. By performing ablation studies with varying training set sizes, the researchers can also evaluate the robustness of their model to different amounts of data. The results of ablation studies are essential for optimizing a model, highlighting areas for improvement and providing insights into the underlying mechanisms of the system’s success or failure. They are also crucial for informing future model designs and refining approaches for generalizable AI-generated image detection.
More visual insights#
More on figures

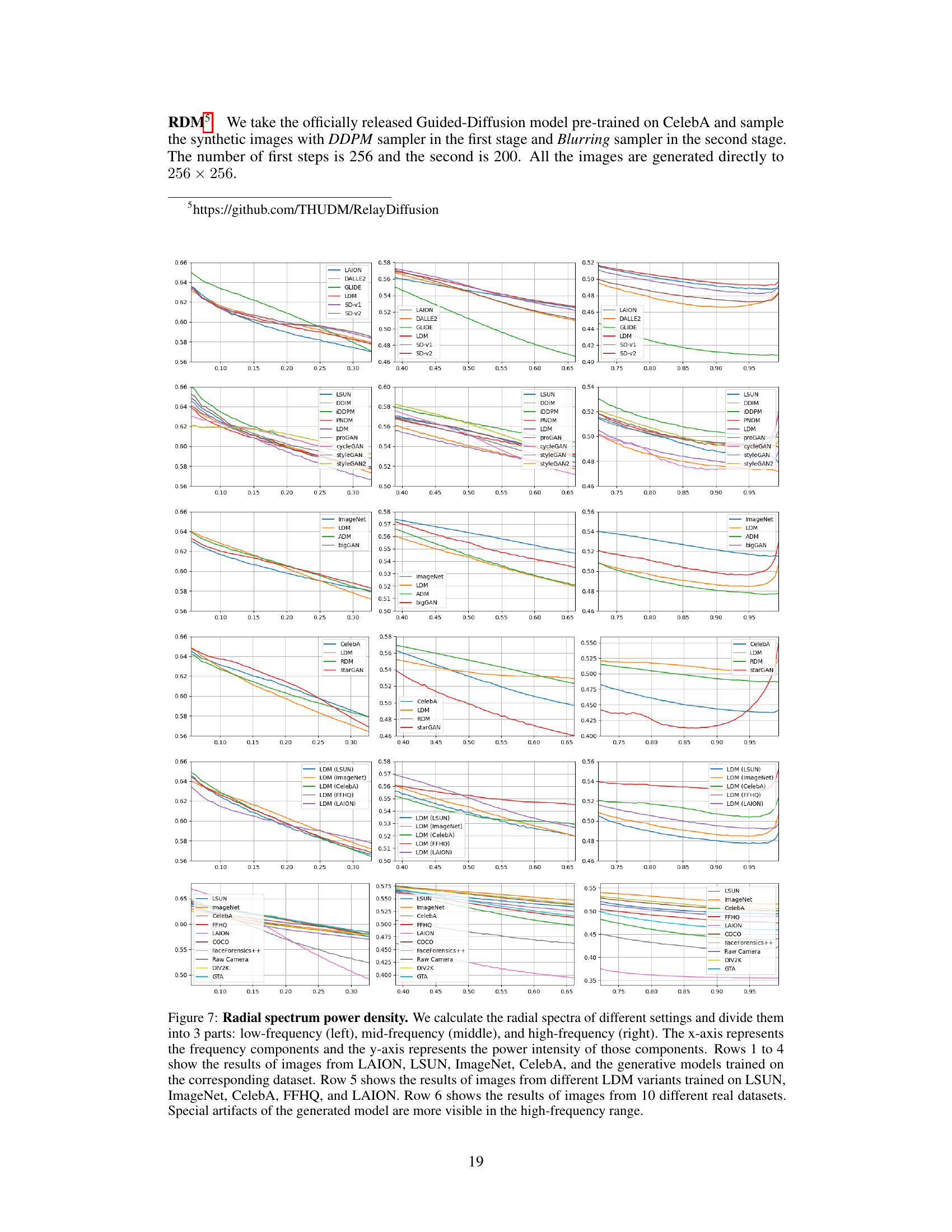
🔼 This figure visualizes the noise residuals power spectrum of images from both real and synthetic datasets. The top row shows the power spectrum of 5 different real-world datasets, demonstrating the unique spectral characteristics associated with each dataset’s content and image processing. The bottom row displays the corresponding power spectrum for synthetic images generated by different models trained on the same datasets. This comparison highlights how generative models inherit and reflect the unique artifacts present in their training data, which are referred to as ‘semantic artifacts.’ The existence of ‘semantic artifacts’ in both real and generated images is a key finding of the paper and a significant challenge to creating generalized AI-generated image detectors.
read the caption
Figure 2: Semantic artifacts: noise residuals power spectrum of images from different scenes. Top row: 5 real datasets. Bottom row: 5 generative models in corresponding scenes, deepfake, SITD, and 3 variants of Latent Diffusion on CelebA, FFHQ, and LAION.
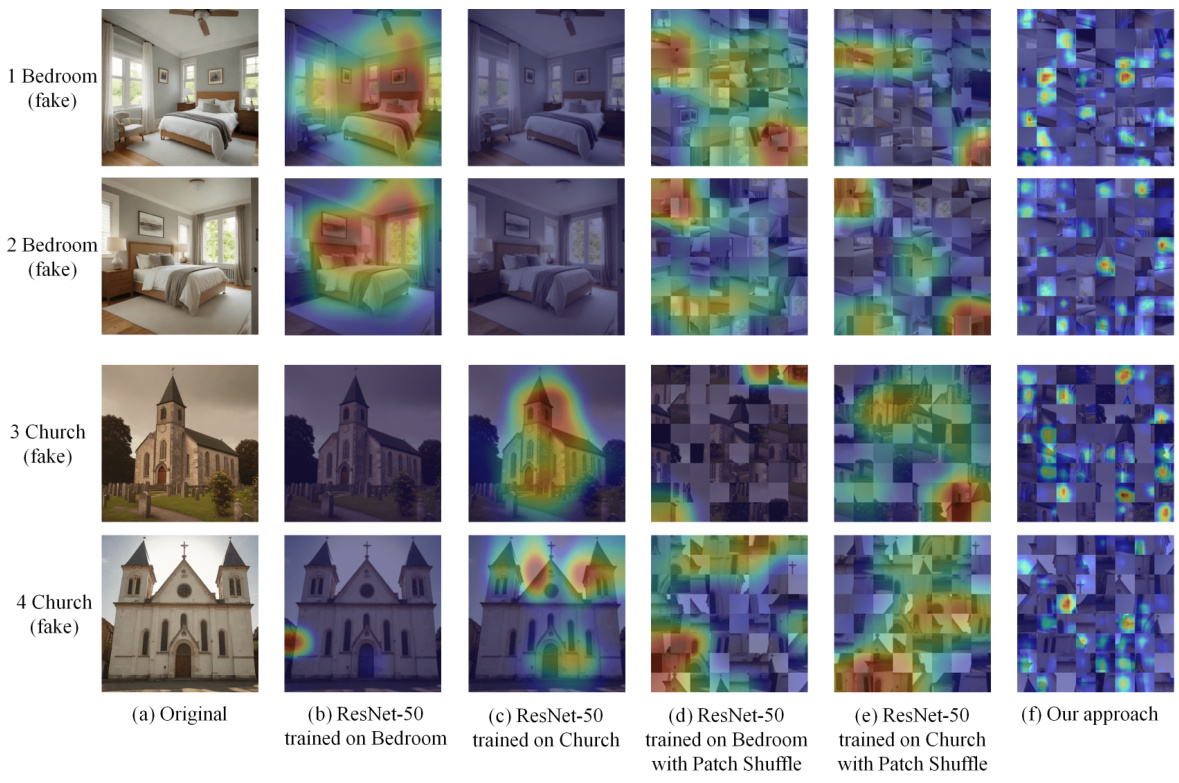
🔼 This figure visualizes Class Activation Maps (CAMs) from different AI-generated image detection models applied to images of bedrooms and churches. The models tested are: a baseline ResNet-50 trained on bedroom images; a baseline ResNet-50 trained on church images; a ResNet-50 trained on bedroom images that uses a patch shuffling technique; a ResNet-50 trained on church images that uses a patch shuffling technique; and the authors’ proposed approach. The warmer colors in the CAMs indicate areas the model deemed more important for its classification decision. The purpose of the figure is to demonstrate how the models utilize different features when classifying images (e.g., the authors’ model focuses on local rather than global features).
read the caption
Figure 3: The visualization of CAM extracted from different detectors on Bedroom or Church images. Warmer color indicates a higher probability.

🔼 This figure illustrates the three main steps of the proposed approach for generalized AI-generated image detection. First, the input image is divided into patches, and these patches are randomly shuffled to mitigate the impact of global semantic artifacts. Second, a patch-based convolutional neural network is used to extract local features from each patch. Finally, the extracted features are concatenated into a vector, and a linear classifier is applied to determine whether the input image is real or fake. This approach aims to break the global semantics while preserving the local generator-specific artifacts, which are more robust to cross-scene generalization.
read the caption
Figure 4: Pipeline of our approach. First, for pre-processing, we divide the input image into patches and shuffle these patches to obtain a randomized sequence. Then, we train a patch-based convolutional network for feature extraction. Finally, we flatten these features into a one-dimensional vector and then apply a linear classifier for classification.

🔼 This figure visualizes the noise residuals power spectrum for images from four real datasets (FaceForensics++, Raw Camera, CelebA, LAION) and four generative models (Deepfake, SITD, LDM-CelebA, LDM-LAION). The figure shows the original images, images after resizing, images after shuffling (Patch Shuffle), and segmented patches of the images. It demonstrates the effectiveness of Patch Shuffle in breaking down global semantic artifacts by comparing the spectral characteristics of the processed images with the original images.
read the caption
Figure 5: Additional noise residuals power spectrum of images from 4 real datasets (Faceforensics++, Raw Camera, CelebA, LAION) and 4 generative models (Deepfake, SITD, LDM-CelebA, LDM-LAION). As suggested by the reviewer, we consider 3 preprocessing operations from rows 2 to 4.

🔼 This figure visualizes Class Activation Maps (CAMs) to show which parts of the input image the different detectors focus on for classification. The top row shows results for bedroom images, while the bottom row shows results for church images. Columns (b) and (c) show the CAMs from ResNet-50 models trained only on bedroom and church images, respectively, demonstrating overfitting to the specific scene. Columns (d) and (e) show results after applying the Patch Shuffle pre-processing method, indicating some improvement. Finally, column (f) shows the CAMs from the proposed ‘Our approach’, demonstrating that the approach effectively focuses on local features instead of overall semantic content.
read the caption
Figure 3: The visualization of CAM extracted from different detectors on Bedroom or Church images. Warmer color indicates a higher probability.

🔼 This figure visualizes the noise residuals power spectrum of images generated by nine different generative models and one real dataset (LAION). The top row shows five diffusion models, while the bottom row displays two GANs (cycleGAN and starGAN), two CNN-based generators (Deepfake and CRN), and the LAION real dataset. Each image shows a distinct spectral pattern, highlighting the unique artifacts produced by different generative architectures.
read the caption
Figure 1: Generator artifacts: noise residuals power spectrum of images from 9 generative models and 1 real dataset. Top row: 5 Diffusion Models. Bottom row: 2 GANs, cycleGAN and starGAN, 2 CNN-based generators, Deepfake and CRN, and 1 real dataset, LAION.
More on tables

🔼 This table presents the results of cross-scene detection experiments using ResNet-50 models. Two different scene datasets (Bedroom and Church) were used to train the models, and each trained model was then tested on both datasets. The table reports both the accuracy (at 50% threshold) and the average precision (AP) for each model/dataset combination, demonstrating the impact of scene changes on the model’s performance.
read the caption
Table 1: Cross-scene detection experiments on ResNet-50 models from ForenSynths [4]. We use 2 sets of training images on different scenes, Bedroom and Church, to retrain the detectors. Detection accuracy (Acc.) (at a threshold of 50%) and Average Precision (AP) are reported.

🔼 This table presents a comparison of the cross-scene and open-world generalization performance of different methods for detecting AI-generated images. The cross-scene results average the performance across six variations of Latent Diffusion models trained on different datasets. The open-world results average performance across all 31 test datasets, encompassing various GANs, diffusion models, and CNN-based generative models. The table highlights the superior performance of the proposed approach.
read the caption
Table 3: Results of cross-scene generalization and open-world generalization. For cross-scene generalization, we average the results on 6 variants of Latent Diffusion (LSUN-Bedroom, LSUN-Church, ImageNet, CelebA, FFHQ, LAION). For open-world generalization, we average the results on all 31 test sets (including 18 DMs, 7 GANs, and 6 CNN-based generators). Bold represents the best and underline represents the second best. More Detailed results are shown in Table 4 and Table 5.
🔼 This table presents a comparison of various methods for detecting AI-generated images. It shows the average accuracy (Acc.) and mean average precision (mAP) across two different evaluation settings: cross-scene generalization (testing on images from different datasets but generated by the same model) and open-world generalization (testing on images from a wide variety of generative models and datasets). The results highlight the performance differences between methods and show which methods are more robust and generalize well.
read the caption
Table 3: Results of cross-scene generalization and open-world generalization. For cross-scene generalization, we average the results on 6 variants of Latent Diffusion (LSUN-Bedroom, LSUN-Church, ImageNet, CelebA, FFHQ, LAION). For open-world generalization, we average the results on all 31 test sets (including 18 DMs, 7 GANs, and 6 CNN-based generators). Bold represents the best and underline represents the second best. More Detailed results are shown in Table 4 and Table 5.
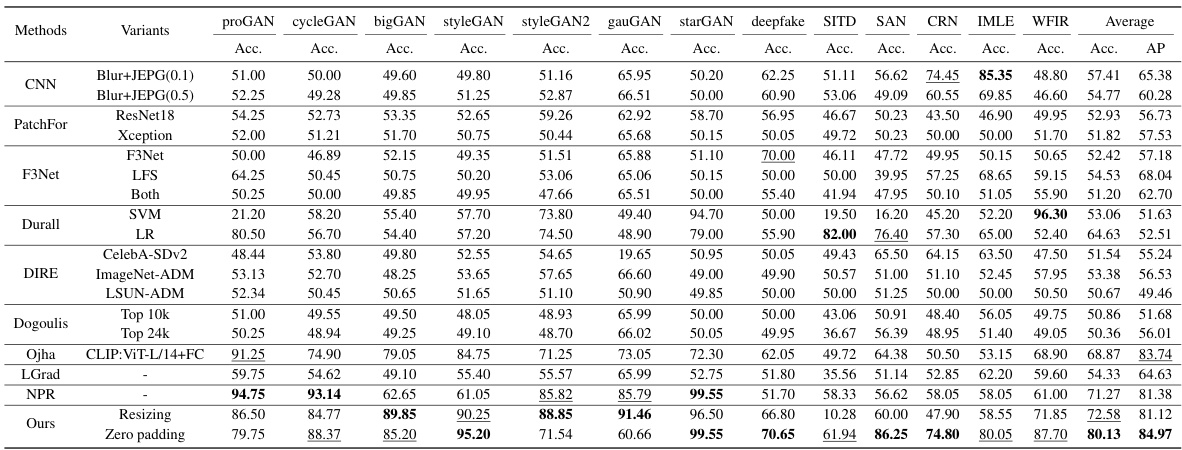
🔼 This table presents the results of a comprehensive evaluation on the proposed approach and other existing methods. The evaluation is conducted on two aspects: cross-scene generalization and open-world generalization. Cross-scene generalization assesses the performance of the methods when the input images are from different scenes but generated using the same generative model. Open-world generalization, on the other hand, evaluates the performance on a much broader range of datasets including diverse generative models and real-world images. The table shows the average accuracy and mean average precision (mAP) achieved by each method on both aspects and indicates the best performing methods.
read the caption
Table 3: Results of cross-scene generalization and open-world generalization. For cross-scene generalization, we average the results on 6 variants of Latent Diffusion (LSUN-Bedroom, LSUN-Church, ImageNet, CelebA, FFHQ, LAION). For open-world generalization, we average the results on all 31 test sets (including 18 DMs, 7 GANs, and 6 CNN-based generators). Bold represents the best and underline represents the second best. More Detailed results are shown in Table 4 and Table 5.

🔼 This ablation study investigates the effect of varying the number of same-convolutional blocks (N) in the patch-based feature extraction network on the model’s performance. Different values of N correspond to varying receptive field sizes and model depths. The table presents the average accuracy (Avg. Acc.) and mean average precision (mAP) across three generalization tasks: cross-diffusion, cross-GAN/CNN, and open-world, for each value of N. The results show that there is an optimal depth that balances the trade-off between underfitting (too few layers) and overfitting (too many layers).
read the caption
Table 6: Ablation study results on model depth.
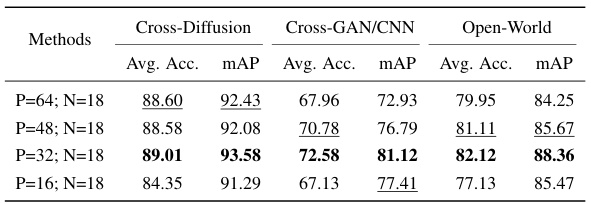
🔼 This table presents the ablation study results focusing on the impact of different patch sizes on the model’s performance. It shows the average accuracy (Avg. Acc.) and mean average precision (mAP) across three different evaluation settings: cross-diffusion, cross-GAN/CNN, and open-world generalization. The results demonstrate the effect of changing patch size (P) while keeping the number of convolutional blocks (N) consistent. The optimal patch size seems to be P=32, indicating a balance between capturing local features and avoiding overfitting to global semantic artifacts.
read the caption
Table 7: Ablation study results on patch size.
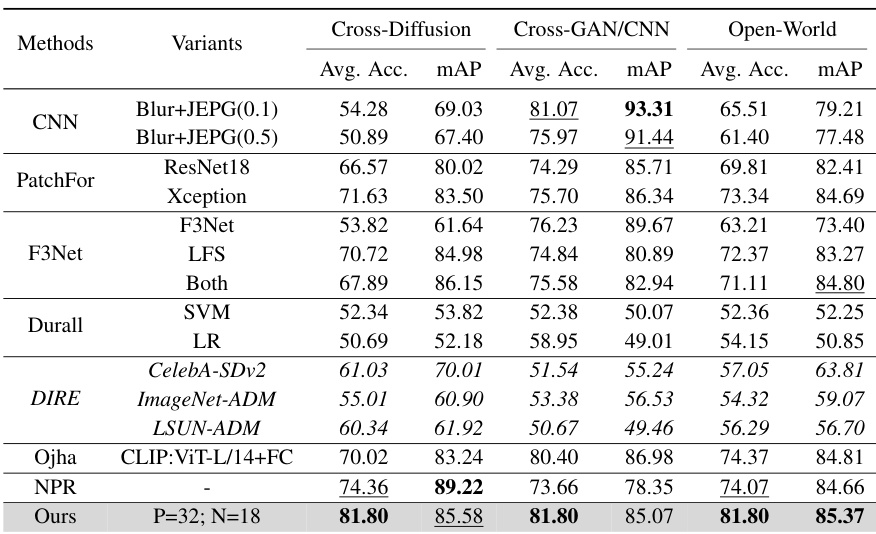
🔼 This table presents the average accuracy and mean average precision (mAP) achieved by various methods on two distinct generalization tasks: cross-scene and open-world. Cross-scene generalization tests the models on Latent Diffusion models trained on six different datasets, while open-world generalization assesses performance across all 31 datasets. The best and second-best results are highlighted.
read the caption
Table 3: Results of cross-scene generalization and open-world generalization. For cross-scene generalization, we average the results on 6 variants of Latent Diffusion (LSUN-Bedroom, LSUN-Church, ImageNet, CelebA, FFHQ, LAION). For open-world generalization, we average the results on all 31 test sets (including 18 DMs, 7 GANs, and 6 CNN-based generators). Bold represents the best and underline represents the second best. More Detailed results are shown in Table 4 and Table 5.

🔼 This table presents the average accuracy (Avg. Acc.) and mean Average Precision (mAP) for cross-scene and open-world generalization. Cross-scene generalization uses 6 variants of the Latent Diffusion model, while open-world includes 31 test sets (7 GANs, 18 Diffusion Models, 6 CNN-based models). The best performing methods are highlighted.
read the caption
Table 3: Results of cross-scene generalization and open-world generalization. For cross-scene generalization, we average the results on 6 variants of Latent Diffusion (LSUN-Bedroom, LSUN-Church, ImageNet, CelebA, FFHQ, LAION). For open-world generalization, we average the results on all 31 test sets (including 18 DMs, 7 GANs, and 6 CNN-based generators). Bold represents the best and underline represents the second best. More Detailed results are shown in Table 4 and Table 5.
Full paper#