TL;DR#
Current sequence-to-sequence (Seq2Seq) diffusion models rely on fixed noise schedules, limiting their performance. They struggle to adapt to the varying complexity of different sentences, often resulting in suboptimal generation. This paper addresses these issues by focusing on the need for a more contextualized approach to noise scheduling.
The proposed solution, Meta-DiffuB, uses meta-exploration to train a separate scheduler model. This model dynamically adjusts the noise level for each sentence based on its characteristics. The results show that Meta-DiffuB significantly outperforms existing methods across various datasets. This improvement stems from the ability to apply the right amount of noise to each sentence; this contextualized approach improves both the overall quality and the diversity of generated text. Furthermore, the trained scheduler can be easily integrated into other diffusion models.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces a novel approach to improve sequence-to-sequence text generation using diffusion models. It presents Meta-DiffuB, a framework that leverages meta-exploration for contextualized noise scheduling, achieving state-of-the-art results and offering a “plug-and-play” enhancement for existing diffusion models. This work is highly relevant to the growing research in diffusion models and generative AI, opening up new avenues for improving both the quality and diversity of generated text.
Visual Insights#

🔼 This figure compares the traditional S2S-Diffusion model (DiffuSeq) with the proposed Meta-DiffuB model. The left side shows DiffuSeq, using a fixed noise schedule, represented by consistent shading. The right side depicts Meta-DiffuB, which introduces a scheduler model to dynamically determine the noise schedule based on the context of the input sentence, resulting in variable shading to represent the contextualized noise.
read the caption
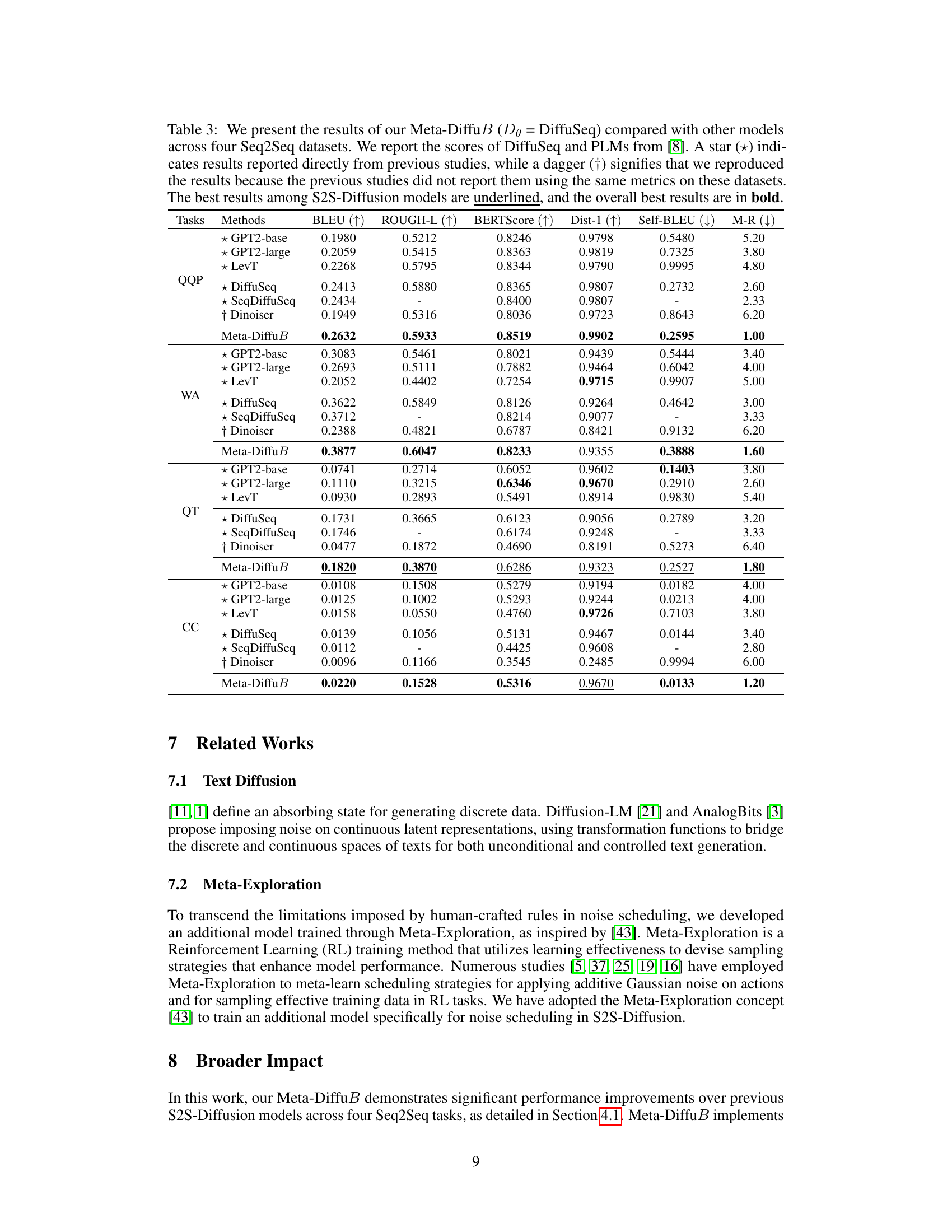
Figure 1: Comparison between S2S-Diffusion model (i.e., DiffuSeq [21]) and the proposed Meta-DiffuB. The shades of color represent different amounts of noise being imposed. Different from prior works that use a fixed noise, we introduce a novel scheduler-exploiter framework, Meta-DiffuB, which achieves trainable noise scheduling inspired by Meta Exploration. Our scheduler model schedules contextualized noise, enhancing the training and generation of the S2S-Diffusion model, resulting in state-of-the-art (SOTA) performance compared to previous S2S-Diffusion models, as detailed in Section 4.

🔼 This table presents the results of applying the Meta-DiffuB framework to enhance three existing S2S-Diffusion models: DiffuSeq, SeqDiffuSeq, and Dinoiser, on two benchmark datasets, QQP and WA. It compares the performance of each original model to the performance after applying Meta-DiffuB. Improved performance after applying Meta-DiffuB is indicated in bold. The table also notes whether the reported results are taken directly from previous studies or reproduced by the authors due to inconsistencies in the original reporting.
read the caption
Table 2: Results of applying our Meta-DiffuB (De = a specific S2S-Diffusion model) to other S2S-Diffusion models [8, 45, 44]. The specific S2S-Diffusion model used in the exploiter model is indicated by the assignment of De. Outcomes where Meta-DiffuB outperforms previous S2S-Diffusion models are highlighted in bold. A star (+) indicates results reported directly from previous studies, while a dagger (†) signifies that we reproduced the results because the original studies did not report them using the same metrics on these datasets.
In-depth insights#
Meta-Exploration in Diffusion#
Meta-Exploration, in the context of diffusion models, presents a powerful paradigm shift. Instead of relying on pre-defined or hand-crafted noise schedules, Meta-Exploration introduces a learned scheduler. This scheduler dynamically adjusts the noise level during the diffusion process, adapting to the specific characteristics of the data and task. This learned approach offers several key advantages. First, it allows for contextualized noise scheduling, meaning the noise level can be tailored to individual data points or sequences, leading to improved generation quality and diversity. Second, it enables greater flexibility and adaptability, allowing the model to handle various data distributions and tasks more effectively. Third, it leads to more robust and efficient training, as the model learns the optimal noise schedule directly from the data. The overall effect is a significant improvement in the performance of diffusion models, particularly in complex sequence-to-sequence generation tasks. The plug-and-play nature of a learned scheduler is also highly valuable, enabling easy integration into existing diffusion models without extensive retraining. However, careful consideration of computational costs and potential overfitting is essential during the implementation of Meta-Exploration within diffusion models.
Contextual Noise Scheduling#
Contextual noise scheduling is a crucial innovation in diffusion models for sequence-to-sequence tasks. Instead of using a fixed or hand-crafted noise schedule, this approach dynamically adjusts the noise level based on the characteristics of each input sentence. This is particularly important for Seq2Seq tasks, as different sentences possess varying semantic complexities and contextual nuances. A contextual scheduler model learns to predict an optimal noise schedule for each sentence, taking into account its specific characteristics. This adaptive strategy allows the model to efficiently handle the diverse challenges presented by different sentences, potentially improving the quality and diversity of generated text. The key advantage is that it overcomes the limitations of non-contextualized methods that fail to account for these sentence-specific variations. By incorporating contextual information, the model becomes more adept at navigating the nuances of sequence generation and may demonstrate a better understanding of the input, leading to improved results.
SOTA Seq2Seq Results#
A hypothetical ‘SOTA Seq2Seq Results’ section would present a comparison of the proposed model’s performance against state-of-the-art (SOTA) sequence-to-sequence models on standard benchmark datasets. This would involve reporting key metrics like BLEU, ROUGE, METEOR, etc., showing that the new model achieves superior results. Crucially, the choice of datasets and metrics must be justified and representative of typical Seq2Seq tasks. The section should also discuss the statistical significance of the improvements, addressing potential biases in the data or evaluation. Visualizations, such as bar charts or tables comparing performance, are essential for clarity. Furthermore, the discussion should consider factors beyond raw metrics, like the model’s efficiency, ability to handle long sequences, and generation quality (e.g., fluency, coherence, and relevance). Finally, a nuanced explanation of any limitations or weaknesses of the SOTA models, and how the proposed approach addresses them is crucial for a comprehensive analysis.
Plug-and-Play Scheduler#
The concept of a “Plug-and-Play Scheduler” within the context of a text diffusion model is intriguing. It suggests a modular design where a pre-trained scheduler module can be seamlessly integrated into various diffusion models without the need for extensive retraining. This offers several potential advantages. First, it significantly reduces the computational cost and time associated with adapting the noise scheduling strategy to different models or datasets. Second, it promotes greater model flexibility and adaptability. Researchers could readily experiment with different diffusion model architectures or task-specific configurations, leveraging the pre-trained scheduler’s expertise without the burden of retraining from scratch. Third, a plug-and-play approach simplifies the overall workflow, making the diffusion modeling pipeline more accessible and user-friendly. However, the effectiveness of such a scheduler depends on its robustness and generalizability. The scheduler must be sufficiently general to handle various architectures and datasets without performance degradation. Careful evaluation is needed to assess how well the plug-and-play scheduler generalizes across different model types and datasets, compared to models with custom-trained schedulers. The potential impact on model performance and the computational savings achieved must also be carefully quantified.
Future Work: RDM#
Future research directions for RDM (Recursive Diffusion Models) in text generation could explore several promising avenues. Improving the efficiency of the diffusion process is crucial; current methods can be computationally expensive, limiting scalability. Investigating more efficient architectures or noise scheduling techniques, perhaps inspired by advancements in other diffusion models, would significantly enhance practicality. Another key area involves enhancing the controllability and interpretability of the generated text. Current RDMs often lack fine-grained control over specific aspects of the output, making it challenging to generate text with precise stylistic choices or factual constraints. Exploring techniques such as guided diffusion or incorporating external knowledge sources could improve controllability. Finally, extending RDM to handle diverse Seq2Seq tasks beyond simple text generation is important. RDMs currently show potential for diverse downstream tasks but require further investigation into their applicability and efficacy for complex tasks involving translation, summarization, or question answering. Addressing these challenges will unlock the full potential of RDMs and solidify their position as a leading generative model for language.
More visual insights#
More on figures

🔼 This figure displays two line graphs, one for the QQP dataset (a) and another for the WA dataset (b). Both graphs show the BLEU scores achieved by three different models (DiffuSeq, GPT2-large, and Meta-DiffuB) as the candidate size |S| increases from 1 to 20. The x-axis represents the candidate size |S|, and the y-axis represents the BLEU score. The graphs illustrate the performance improvement in BLEU score as the candidate size increases for all three models, with Meta-DiffuB consistently outperforming the other two models.
read the caption
Figure 2: Increase in BLEU score with varying candidate sizes |S| on the QQP and WA datasets.

🔼 This figure compares the standard S2S-Diffusion model with the proposed Meta-DiffuB model. It highlights the key difference: Meta-DiffuB uses a scheduler model to determine the amount of noise at each step, resulting in contextualized noise scheduling, whereas the standard model uses a fixed noise schedule. The color intensity visually represents the amount of noise, showing that Meta-DiffuB adapts noise levels dynamically, unlike the fixed approach of the standard S2S-Diffusion model.
read the caption
Figure 1: Comparison between S2S-Diffusion model (i.e., DiffuSeq [21]) and the proposed Meta-DiffuB. The shades of color represent different amounts of noise being imposed. Different from prior works that use a fixed noise, we introduce a novel scheduler-exploiter framework, Meta-DiffuB, which achieves trainable noise scheduling inspired by Meta Exploration. Our scheduler model schedules contextualized noise, enhancing the training and generation of the S2S-Diffusion model, resulting in state-of-the-art (SOTA) performance compared to previous S2S-Diffusion models, as detailed in Section 4.

🔼 This figure visualizes how different S2S diffusion models schedule noise during the diffusion process. It compares Meta-DiffuB with three other models (DiffuSeq, Dinoiser, SeqDiffuSeq) across two datasets (QQP and WA). The key takeaway is that Meta-DiffuB dynamically adjusts the noise level for each sentence, unlike the other methods that apply a fixed or predetermined noise schedule. The graphs show the average noise (βt) applied at each diffusion step (t) over training epochs.
read the caption
Figure 3: Visualization of noise scheduling for each S2S-Diffusion model on the QQP and WA datasets. βt represents the average noise imposed on sentences at diffusion step t. Unlike other models, which impose the same noise on all sentences, our Meta-DiffuB (De = DiffuSeq) varies the noise levels.
More on tables

🔼 This table compares the performance of Meta-DiffuB (with DiffuSeq as the exploiter model) against other state-of-the-art S2S-Diffusion models and fine-tuned pre-trained language models (PLMs) across four benchmark Seq2Seq datasets. The results are presented using standard evaluation metrics including BLEU, ROUGE-L, BERTScore, Distinct-1, Self-BLEU and Mean-Rank. Meta-DiffuB achieves state-of-the-art performance in most cases, demonstrating improved generation quality and diversity.
read the caption
Table 3: We present the results of our Meta-DiffuB (De = DiffuSeq) compared with other models across four Seq2Seq datasets. We report the scores of DiffuSeq and PLMs from [8]. A star (+) indicates results reported directly from previous studies, while a dagger (†) signifies that we reproduced the results because the previous studies did not report them using the same metrics on these datasets. The best results among S2S-Diffusion models are underlined, and the overall best results are in bold.
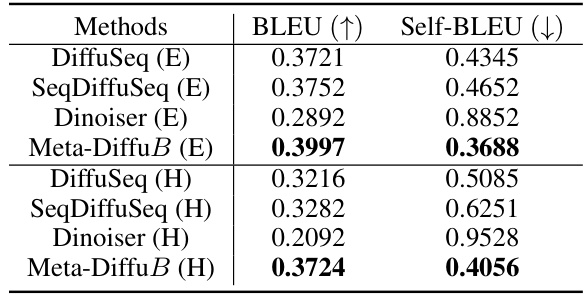
🔼 This table presents a comparison of the performance of Meta-DiffuB (with DiffuSeq as the exploiter model) against other S2S-Diffusion models (DiffuSeq, SeqDiffuSeq, and Dinoiser) on the WA dataset. The results are separated into two groups: (E) representing easier sentences and (H) representing harder sentences. The table shows BLEU scores (higher is better) and Self-BLEU scores (lower is better), indicating the quality and diversity of the generated sentences, respectively. The best-performing model for each metric and sentence difficulty level is highlighted in bold.
read the caption
Table 4: The results of our Meta-DiffuB (De = DiffuSeq) and other S2S-Diffusion models for generating sentences (E) and (H) on the WA dataset. The best result in each group is highlighted in bold.

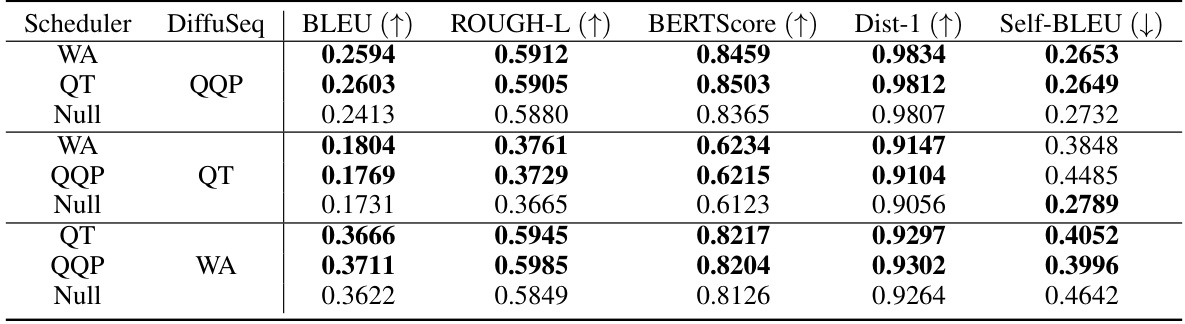
🔼 This table presents the results of a plug-and-play experiment using a pre-trained scheduler model with DiffuSeq on various datasets. The scheduler model’s capability to enhance the DiffuSeq model’s performance without the need for fine-tuning is evaluated across four Seq2Seq benchmark datasets. The results are shown in terms of BLEU, ROUGE-L, BERTScore, Dist-1, and Self-BLEU scores, with bolded values indicating cases where the plug-and-play approach outperforms DiffuSeq using its own noise scheduling.
read the caption
Table 5: Results of the plug-and-play experiment for our scheduler model. The ‘Scheduler’ field indicates the dataset used to train our scheduler model, while the ‘DiffuSeq’ field indicates the dataset used to train DiffuSeq. If the ‘DiffuSeq’ field is ‘Null’, DiffuSeq generates sentences using its own noise. Results that outperform those where DiffuSeq uses its own noise scheduling are highlighted in bold.

🔼 This table compares the performance of Meta-DiffuB when combined with three different S2S-Diffusion models (DiffuSeq, SeqDiffuSeq, and Dinoiser) on two machine translation datasets (IWSLT14 DE-EN and WMT14 DE-EN). The results are presented as SacreBLEU scores, a metric for evaluating machine translation quality. Higher scores indicate better performance. The table highlights cases where using Meta-DiffuB leads to a performance improvement compared to the baseline S2S-Diffusion model alone.
read the caption
Table 6: Results of Meta-DiffuB on Machine Translation datasets (DE-EN). Results where Meta-DiffuB combined with different models show improved performance are indicated in bold.

🔼 This table compares the performance of Meta-DiffuB when used with different S2S diffusion models (DiffuSeq, SeqDiffuSeq, and Dinoiser) on two datasets (QQP and WA). It shows the BLEU, BERTScore, and Dist-1 scores for each model and dataset combination. Bold results highlight cases where Meta-DiffuB outperforms the original S2S diffusion model. The table also notes where results are taken directly from previous studies (*) or were reproduced by the authors (†).
read the caption
Table 2: Results of applying our Meta-DiffuB (De = a specific S2S-Diffusion model) to other S2S-Diffusion models [8, 45, 44]. The specific S2S-Diffusion model used in the exploiter model is indicated by the assignment of De. Outcomes where Meta-DiffuB outperforms previous S2S-Diffusion models are highlighted in bold. A star (+) indicates results reported directly from previous studies, while a dagger (†) signifies that we reproduced the results because the original studies did not report them using the same metrics on these datasets.
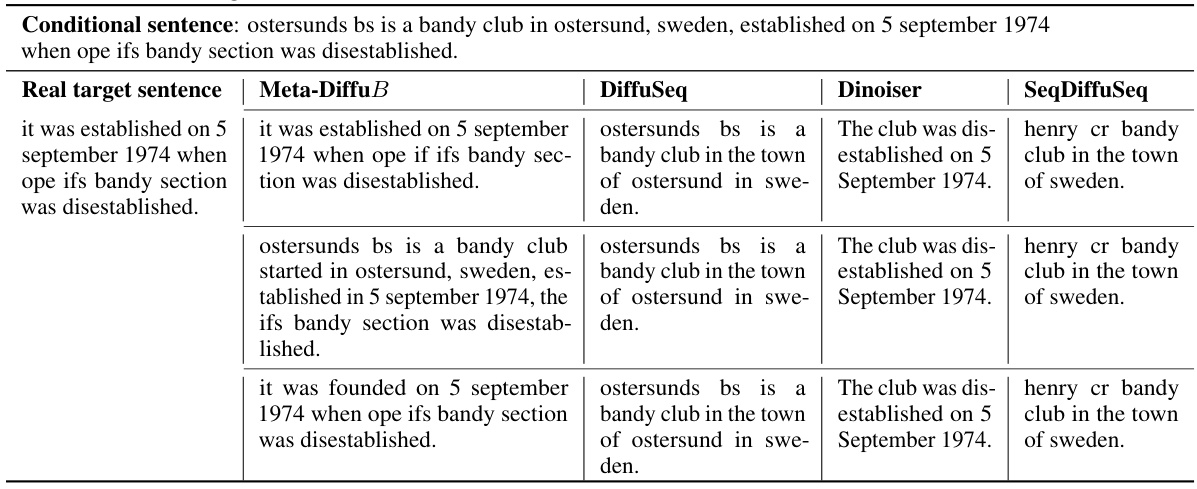
🔼 This table presents a comparison of the text generated by Meta-DiffuB and three other S2S-Diffusion models in response to the same input sentence. The focus is on the hardest sentences to generate (H), highlighting the differences in quality and diversity of the generated text. Meta-DiffuB shows better performance in producing effective and diverse sentences compared to the other models.
read the caption
Table 8: The sample output of our Meta-DiffuB (De = DiffuSeq) and other S2S-Diffusion models [8, 44, 45] on hardest generated sentences (H) of WA dataset. The conditional sentence is the same.

🔼 This table presents example outputs from the Meta-DiffuB model and three other S2S-Diffusion models (DiffuSeq, Dinoiser, and SeqDiffuSeq) for a difficult sentence from the QQP dataset. It demonstrates the differences in the quality and diversity of generated sentences by each model when faced with a challenging input.
read the caption
Table 9: The sample output of Meta-DiffuB (De = DiffuSeq) and other S2S-Diffusion models [8, 44, 45] on hardest generated sentence (H) of QQP dataset. The conditional sentence is the same.

🔼 This table presents the performance comparison of Meta-DiffuB (with DiffuSeq as the exploiter model) against other S2S-Diffusion models (DiffuSeq, SeqDiffuSeq, and Dinoiser) on the WA dataset. The comparison is done for both easy (E) and hard (H) sentences. The ’easy’ and ‘hard’ sentences are determined based on their BLEU scores, where lower scores indicate harder sentences to generate. The table shows the BLEU score, Self-BLEU score, ROUGE-L score, BERTScore, and Dist-1 for each model and sentence type. Higher BLEU, ROUGE-L, and BERTScore indicate better quality, while lower Self-BLEU and higher Dist-1 indicate better diversity. Meta-DiffuB shows consistently superior results compared to the other models, demonstrating effectiveness in generating both easy and hard sentences with higher quality and diversity.
read the caption
Table 4: The results of our Meta-DiffuB (De = DiffuSeq) and other S2S-Diffusion models for generating sentences (E) and (H) on the WA dataset. The best result in each group is highlighted in bold.
🔼 This table presents the results of experiments demonstrating the plug-and-play functionality of the Meta-DiffuB scheduler model. It shows how using a pre-trained scheduler model (trained on a specific dataset) with a separate DiffuSeq model (trained on a different or no dataset) impacts performance. The table reports various metrics (BLEU, ROUGE-L, BERTScore, Dist-1, Self-BLEU) across multiple datasets (WA, QQP, QT), comparing scenarios with and without a pre-trained scheduler. Bold values indicate cases where the scheduler improves performance over the DiffuSeq model operating without a pre-trained scheduler.
read the caption
Table 11: Results of the plug-and-play experiment for our scheduler model. The 'Scheduler' field indicates the dataset used to train our scheduler model, while the 'DiffuSeq' field indicates the dataset used to train DiffuSeq. If the 'DiffuSeq' field is 'Null', DiffuSeq generates sentences using its own noise. Results that outperform those where DiffuSeq uses its own noise scheduling are highlighted in bold.

🔼 This table presents plug-and-play experiment results using the proposed scheduler model with the SeqDiffuSeq model. It shows the performance improvements achieved by integrating the scheduler model trained on different datasets (WA, QQP, QT) with a pre-trained SeqDiffuSeq model on the same datasets. The ‘Null’ entry represents the baseline performance of the SeqDiffuSeq model using its own noise scheduling mechanism. Results are compared using BLEU, BERTScore and Dist-1 metrics.
read the caption
Table 12: Plug-and-play experiments on SeqDiffuSeq integrated with our scheduler. The field ‘SeqDiffuSeq’ indicates which dataset this model is trained on. When the ‘Scheduler’ field is ‘Null’, it indicates the use of the model’s own noise scheduling. Results where the model performs better with its own noise are indicated in bold.

🔼 This table presents the results of plug-and-play experiments using the proposed scheduler model with the Dinoiser model for sequence-to-sequence tasks. It shows the performance improvements when integrating the scheduler trained on different datasets (WA, QQP, QT). The ‘Null’ row indicates the Dinoiser model using its own internal noise scheduling, serving as a baseline for comparison. The metrics used to evaluate performance are BLEU, BERTScore, and Dist-1.
read the caption
Table 13: Plug-and-play experiments on Dinoiser integrated with our scheduler. The field ‘Dinoiser’ indicates which dataset this model is trained on. When the ‘Scheduler’ field is ‘Null’, it indicates the use of the model’s own noise scheduling. Results where the model performs better with its own noise are indicated in bold.
Full paper#