TL;DR#
Current 3D scene reconstruction methods, such as Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS), struggle with real-world data containing occlusions, dynamic objects, and varying illumination. While NeRFs can adapt using per-image embedding vectors, 3DGS faces challenges due to its explicit representation and lack of shared parameters. This necessitates efficient and robust methods for handling such complexities.
WildGaussians introduces a novel approach that leverages robust DINO features and integrates an appearance modeling module within 3DGS. This allows for handling occlusions and appearance changes effectively. The method jointly optimizes a DINO-based uncertainty predictor, enhancing robustness to occlusions. Experimental results demonstrate that WildGaussians achieves state-of-the-art performance while maintaining the real-time rendering speed of 3DGS, outperforming both 3DGS and NeRF baselines in handling in-the-wild data.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances real-time 3D scene reconstruction, a crucial area for various applications like VR/AR, gaming, and robotics. By addressing the limitations of existing methods in handling complex, real-world scenes, this research opens new avenues for creating more realistic and interactive 3D experiences. The improved efficiency and robustness of the proposed approach also has broader implications for research in computer vision and graphics.
Visual Insights#

🔼 This figure showcases the capabilities of WildGaussians in handling complex scenes. The left side demonstrates its ability to extend 3D Gaussian Splatting (3DGS) to manage scenes with variations in appearance and lighting conditions. The right side highlights the joint optimization of a DINO-based uncertainty predictor to effectively address occlusions within the scene, thus producing a more accurate and robust 3D reconstruction.
read the caption
Figure 1: WildGaussians extends 3DGS [14] to scenes with appearance and illumination changes (left). It jointly optimizes a DINO-based [27] uncertainty predictor to handle occlusions (right).
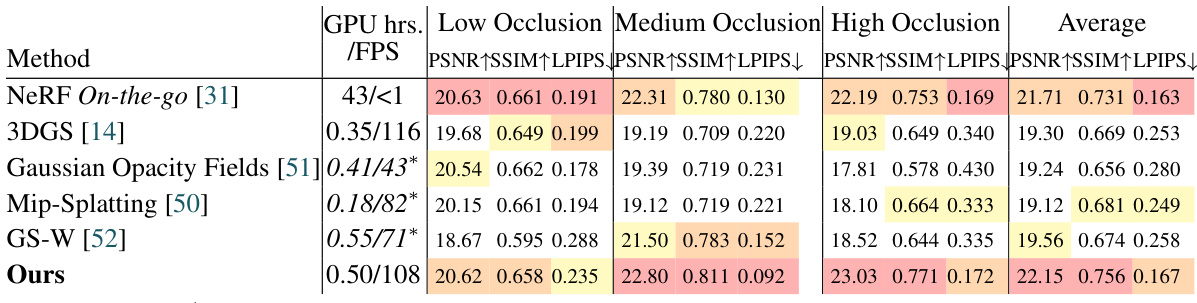
🔼 This table presents a comparison of different methods for novel view synthesis on the NeRF On-the-go dataset. The metrics used are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). The table shows the performance of each method across three occlusion levels (low, medium, high), indicating the ability of each method to handle various degrees of occlusion. The results are also presented in terms of frames per second (FPS) and GPU training hours. The table highlights the superior performance of the proposed method, WildGaussians, compared to existing methods.
read the caption
Table 1: Comparison on NeRF On-the-go Dataset [31]. The first, second, and third values are highlighted. Our method shows overall superior performance over state-of-the-art baseline methods.
In-depth insights#
Wild 3D Gaussian#
The concept of “Wild 3D Gaussian” suggests an extension of 3D Gaussian splatting techniques to handle complex, real-world scenes. Standard 3D Gaussian splatting excels in controlled environments but struggles with the variability inherent in “wild” data (occlusions, dynamic elements, lighting changes). A “Wild 3D Gaussian” approach would likely address this by incorporating robust feature representations (e.g., DINO features), appearance modeling (handling illumination variations), and uncertainty estimation (to manage occlusions). The key challenge lies in efficiently integrating these components within the 3D Gaussian framework while maintaining real-time rendering speeds. This could involve per-Gaussian appearance embeddings, an uncertainty prediction module, and potentially architectural changes to accommodate these additions. The success of such a method would depend on balancing accuracy, efficiency, and robustness to the complexities of uncontrolled settings. A successful implementation would likely lead to significant improvements in the creation of realistic 3D scene reconstructions from challenging datasets.
Appearance Modeling#
Appearance modeling in this context likely addresses the challenge of handling variations in visual appearance within a 3D scene reconstruction system. The core idea is to incorporate trainable parameters to adapt to changes such as illumination, weather, or time of day, which affect how objects appear in images. This differs from methods assuming consistent appearances across all input views. By embedding appearance information, the system can learn to render photorealistic images that accurately reflect scene conditions from various viewpoints. Successful appearance modeling would allow 3D reconstruction systems to handle images taken under different conditions, leading to more robust and versatile representations. The specific implementation might involve learning per-image or per-Gaussian embeddings, then incorporating these representations within a rendering model, often through a neural network. Effectiveness hinges on the ability to disentangle the appearance from the scene geometry. This will lead to improved rendering accuracy and generalization beyond the training conditions. The challenge lies in maintaining efficient rendering and training despite incorporating this added complexity.
Uncertainty Handling#
The paper addresses the challenge of uncertainty in 3D scene reconstruction by introducing an uncertainty modeling module within the 3D Gaussian Splatting (3DGS) framework. This is crucial because real-world scenes, unlike controlled environments, are characterized by occlusions, dynamic objects, and varying lighting conditions. The authors leverage robust DINO features to create an uncertainty mask that effectively removes the influence of occluders during training. This innovative approach contrasts with existing NeRF methods, which generally use per-image embeddings or more computationally expensive methods. The use of DINO features provides robustness to appearance changes and is a key contribution to enabling accurate and efficient 3D reconstruction in challenging scenarios. The integration of the uncertainty prediction mechanism within the 3DGS framework is elegantly implemented, leading to significant improvements in the quality of 3D scene reconstruction. The effectiveness of this strategy is demonstrated through comprehensive experimental results on multiple datasets.
Real-time Rendering#
Real-time rendering in the context of 3D scene reconstruction is a critical advancement, enabling immediate visualization and interaction with the generated models. Speed is paramount, and techniques like Gaussian Splatting (3DGS) have emerged as strong contenders, offering significant performance gains over traditional Neural Radiance Fields (NeRFs). However, real-time rendering often necessitates compromises. Simplifying the scene representation (e.g., using explicit primitives) or employing efficient rendering algorithms (e.g., rasterization) are typical trade-offs. The challenge lies in balancing speed with photorealism and accuracy. Furthermore, real-world scenes present additional difficulties such as occlusions and dynamic elements, requiring robust methods to maintain performance. Addressing these challenges while achieving interactive frame rates is a key focus of ongoing research, driving innovation in both scene representation and rendering techniques.
Future Enhancements#
Future enhancements for WildGaussians could explore several avenues. Improving robustness to extreme weather conditions and highly dynamic scenes remains a challenge; incorporating temporal consistency models or leveraging video data could address this. Expanding the appearance modeling module to handle a wider range of appearance variations, beyond illumination changes, would also be beneficial. This could involve incorporating more sophisticated feature extractors or developing techniques for learning appearance representations from fewer images. Addressing the limitations of the uncertainty model in handling complex occlusions is crucial; exploring alternative uncertainty estimation methods or integrating advanced occlusion reasoning techniques could enhance performance. Finally, optimizing the training process through more efficient loss functions or training strategies, potentially focusing on specific image regions, could reduce training time and improve overall efficiency.
More visual insights#
More on figures

🔼 This figure illustrates the core components of the WildGaussians approach. The left side shows the appearance modeling process, where per-Gaussian and per-image embeddings are fed into an MLP to generate an affine transformation for the Gaussian’s color. The right side depicts the uncertainty modeling, utilizing DINO features from the ground truth and rendered images to estimate uncertainty via cosine similarity, aiding in occlusion handling during training.
read the caption
Figure 2: Overview over the core components of WildGaussians. Left: appearance modeling (Sec. 3.2). Per-Gaussian and per-image embeddings are passed as input to the appearance MLP which outputs the parameters of an affine transformation applied to the Gaussian's view-dependent color. Right: uncertainty modeling (Sec. 3.3). An uncertainty estimate is obtained by a learned transformation of the GT image's DINO features. To train the uncertainty, we use the DINO cosine similarity (dashed lines).

🔼 This figure compares three different uncertainty loss functions: MSE, DSSIM, and DINO Cosine. It uses two example images showcasing significant appearance changes (e.g., lighting, shadows). The heatmaps illustrate how each loss function weights the pixels. MSE and DSSIM incorrectly downplay the importance of the occluded regions (humans), while the DINO Cosine loss effectively focuses on the occluders. The comparison highlights the superior robustness of the DINO Cosine loss to variations in appearance when identifying occluded areas.
read the caption
Figure 3: Uncertainty Losses Under Appearance Changes. We compare MSE and DSSIM uncertainty losses (used by NeRF-W [24] and NeRF On-the-go [31]) to our DINO cosine similarity loss. Under heavy appearance changes (as in Image 1 and 2), both MSE and DSSIM fail to focus on the occluder (humans) and falsely downweight the background, while partly ignoring the occluders.

🔼 This figure compares the performance of 3DGS [14], NeRF On-the-go [31], and WildGaussians (the proposed method) on three scenes from the NeRF On-the-go dataset with varying occlusion levels (5%, 17%, and 26%). The images show that the baseline methods struggle to remove occlusions and produce artifacts, especially in the high-occlusion scene. In contrast, WildGaussians successfully removes occlusions and generates photorealistic renderings, highlighting its improved ability to handle occlusions compared to existing methods.
read the caption
Figure 4: Comparison on NeRF On-the-go Dataset [31]. For both the Fountain and Patio-High scenes, we can see that the baseline methods exhibit different levels of artifacts in the rendering, while our method removes all occluders and shows the best view synthesis results.

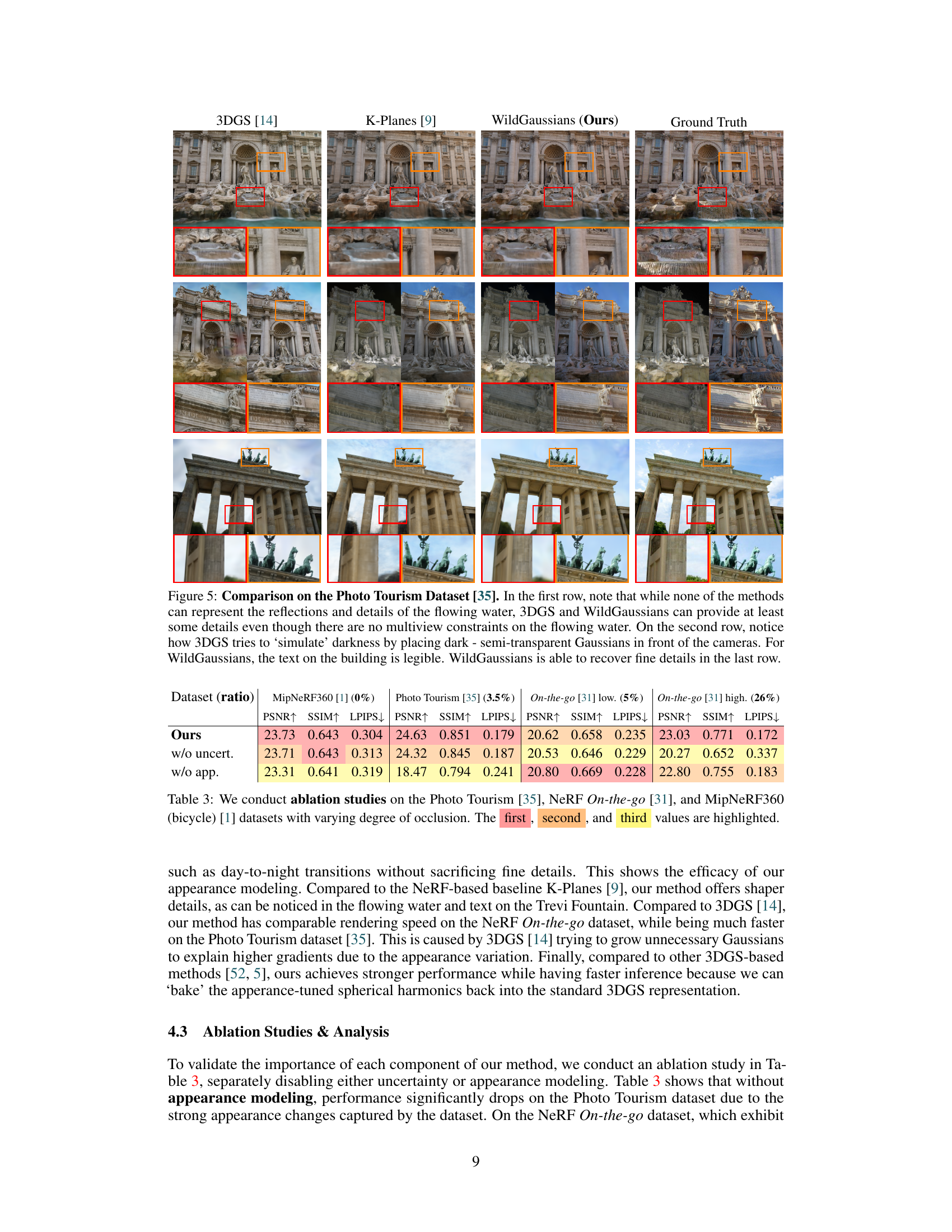
🔼 This figure compares the performance of three different methods (3DGS, K-Planes, and WildGaussians) on the Photo Tourism dataset. The results show WildGaussians’ superior ability to handle challenging scenarios such as reflections, fine details, and occlusions, as seen in the comparison of the Trevi Fountain, Brandenburg Gate, and other scenes. The methods are evaluated based on their visual quality and detail preservation when compared to ground truth images.
read the caption
Figure 5: Comparison on the Photo Tourism Dataset [35]. In the first row, note that while none of the methods can represent the reflections and details of the flowing water, 3DGS and WildGaussians can provide at least some details even though there are no multiview constraints on the flowing water. On the second row, notice how 3DGS tries to 'simulate' darkness by placing dark - semi-transparent Gaussians in front of the cameras. For WildGaussians, the text on the building is legible. WildGaussians is able to recover fine details in the last row.

🔼 This figure demonstrates the smooth transition of appearance changes as the model interpolates between a daytime view and a nighttime view. The gradual appearance of light sources highlights the model’s ability to handle variations in illumination.
read the caption
Figure 6: Appearance interpolation. We show how the appearance changes as we interpolate from a (daytime) view to a (nighttime) view's appearance. Notice the light sources gradually appearing.

🔼 This figure demonstrates the robustness of the proposed appearance modeling. It shows multiple renderings of the Trevi Fountain at night from different viewpoints, all using a single, fixed nighttime appearance embedding. The consistency across views highlights the effectiveness of the approach in handling changes in viewpoint while maintaining a consistent appearance.
read the caption
Figure 7: Fixed appearance multi-view consistency. We shows the multiview consistency of a fixed nighttime appearance embedding as the camera moves around the fountain.
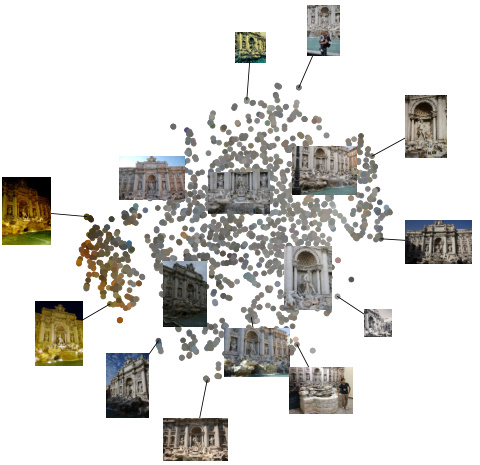
🔼 This figure visualizes the appearance embeddings of training images using t-SNE, a dimensionality reduction technique. The visualization shows that the embeddings are clustered according to image appearance, with day and night images forming distinct groups, demonstrating the effectiveness of the appearance embedding in capturing variations in lighting conditions.
read the caption
Figure 8: t-SNE for Appearance Embedding. We visualize the training images’ appearance embeddings using t-SNE. See the day/night separation.

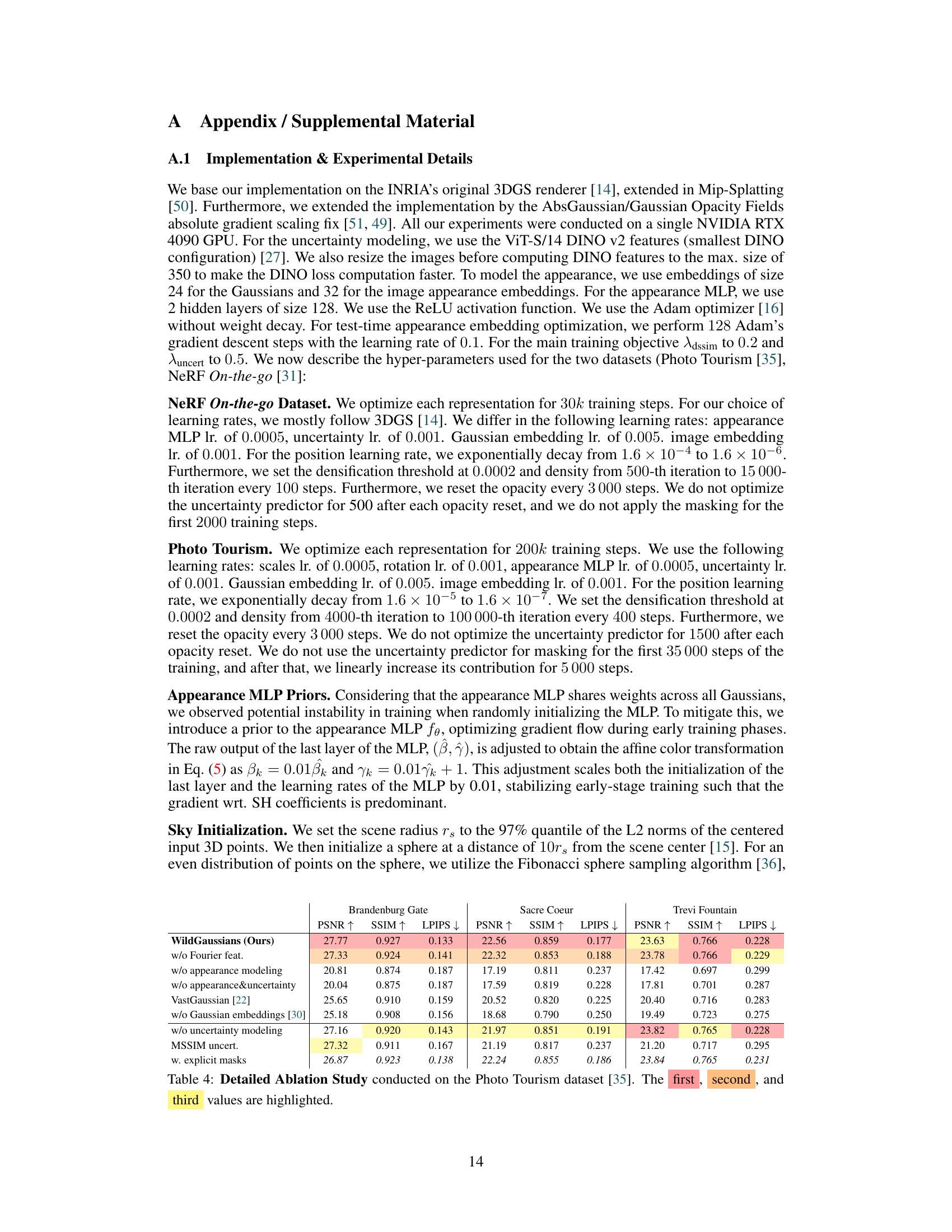
🔼 This figure presents an ablation study on the Photo Tourism dataset, comparing different variations of the WildGaussians model. It shows the results of removing key components of the model: appearance modeling, uncertainty modeling, and per-Gaussian embeddings. By comparing these results to the full WildGaussians model and the ground truth, the figure illustrates the contribution of each component to the overall performance. The results demonstrate the impact of each component on the model’s ability to accurately reconstruct the scene.
read the caption
Figure 9: Photo Tourism ablation study. We show VastGaussian-style appearance modeling, no appearance modeling, no uncertainty modeling, no Gaussian embeddings (only per-image embeddings), and the full method.

🔼 This figure shows example images from the Photo Tourism and NeRF On-the-go datasets to illustrate the types of occlusions present in each dataset. The Photo Tourism dataset contains scenes with approximately 3.5% occlusion, primarily featuring people walking in front of the monuments. The NeRF On-the-go dataset shows examples of low (5%) and high (26%) occlusion scenarios, with the higher occlusion scenes clearly demonstrating people and objects obstructing the main view.
read the caption
Figure 10: Occluders present in the Photo Tourism [35] and NeRF On-the-go [31] datasets.
More on tables
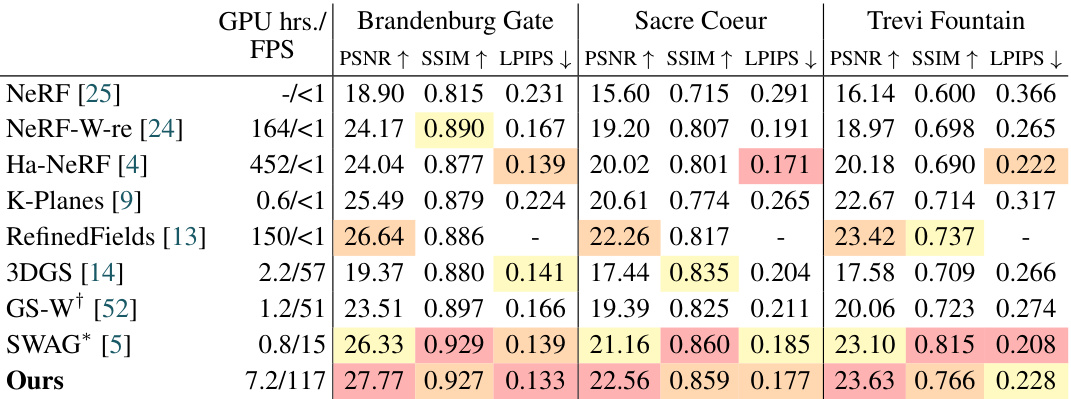
🔼 This table presents a comparison of different novel view synthesis methods on the Photo Tourism dataset. The methods are evaluated based on PSNR, SSIM, and LPIPS metrics across three scenes (Brandenburg Gate, Sacre Coeur, and Trevi Fountain). GPU hours and frames per second (FPS) are also reported to indicate training time and rendering speed. The table highlights the top three performers for each metric in each scene, showcasing the superior performance and speed of the proposed method, WildGaussians.
read the caption
Table 2: Comparison on the Photo Tourism Dataset [35]. The first, second, and third best-performing methods are highlighted. We significantly outperform all baseline methods and offer the fastest rendering times.

🔼 This table compares the proposed WildGaussians method against several state-of-the-art baselines on the NeRF On-the-go dataset [31] in terms of PSNR, SSIM, and LPIPS metrics. The dataset is categorized into three occlusion levels: low, medium, and high. The table highlights the best performing methods for each metric and occlusion level, demonstrating WildGaussians’ superior performance and real-time rendering speed.
read the caption
Table 1: Comparison on NeRF On-the-go Dataset [31]. The first, second, and third values are highlighted. Our method shows overall superior performance over state-of-the-art baseline methods.

🔼 This table presents a comparison of different novel view synthesis methods on the Photo Tourism dataset [35]. The dataset is challenging due to its unstructured nature, encompassing various illuminations and dynamic elements. The table compares the methods based on three metrics: PSNR, SSIM, and LPIPS, across three scenes in the dataset: Brandenburg Gate, Sacre Coeur, and Trevi Fountain. The results highlight the superior performance of WildGaussians, which achieves state-of-the-art results while maintaining real-time rendering speeds. GPU hours and Frames Per Second (FPS) are also provided, further showcasing the computational efficiency of the proposed method.
read the caption
Table 2: Comparison on the Photo Tourism Dataset [35]. The first, second, and third best-performing methods are highlighted. We significantly outperform all baseline methods and offer the fastest rendering times.

🔼 This table presents a quantitative comparison of WildGaussians against other state-of-the-art methods on the NeRF On-the-go dataset [31]. The dataset consists of 6 sequences with varying levels of occlusions (from 5% to 30%). The table shows the PSNR, SSIM, and LPIPS metrics for each method, categorized by occlusion level (low, medium, high). The FPS and GPU hours required for training are also included. WildGaussians outperforms the baselines in terms of image quality metrics, particularly under medium and high occlusion conditions.
read the caption
Table 1: Comparison on NeRF On-the-go Dataset [31]. The first, second, and third values are highlighted. Our method shows overall superior performance over state-of-the-art baseline methods.
Full paper#