↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Ultra image segmentation faces challenges in scalability (dataset-specific models) and architecture (incompatibility with real-world scenarios). Existing methods either use the entire image (computationally expensive) or downsample it (loss of information). The limitations stem from a trade-off between image size and computational resources, leading to instability and poor generalization to diverse datasets.
To address these, the paper proposes a novel framework, SGNet, that incorporates surrounding context information. SGNet refines local patch segmentation using contextual information from larger surrounding areas. This method is easily integrated into existing models, improving performance significantly. Extensive experiments demonstrate consistent improvements and competitive performance across various datasets and segmentation models, overcoming the limitations of prior ultra image segmentation approaches.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the scalability and architectural limitations of existing ultra image segmentation methods by introducing a novel framework, SGNet. This framework enhances generalizability and efficiency, paving the way for more accurate and efficient processing of high-resolution images across various applications. Its impact resonates with researchers working on efficient deep learning models and large-scale image processing.
Visual Insights#

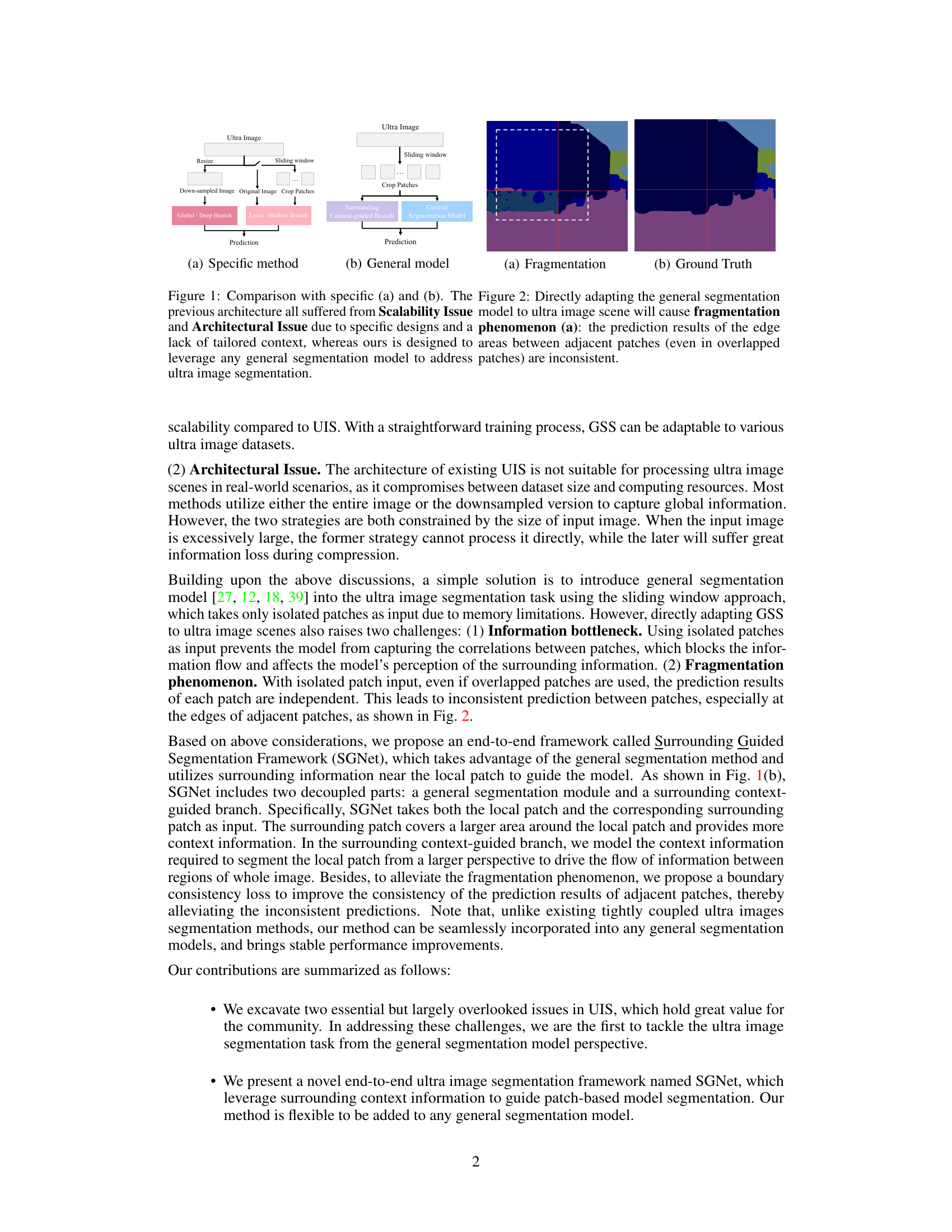
This figure compares two approaches for ultra image segmentation. (a) shows a specific method that uses a combination of global and local branches, while (b) shows a general model which directly adapts a general segmentation model to the ultra-high-resolution image. The figure highlights the fragmentation problem encountered when directly using a general segmentation model with sliding windows on ultra images: inconsistencies in predictions arise at patch boundaries. Figure 2 further illustrates this fragmentation, contrasting the fragmented prediction results with the ground truth.
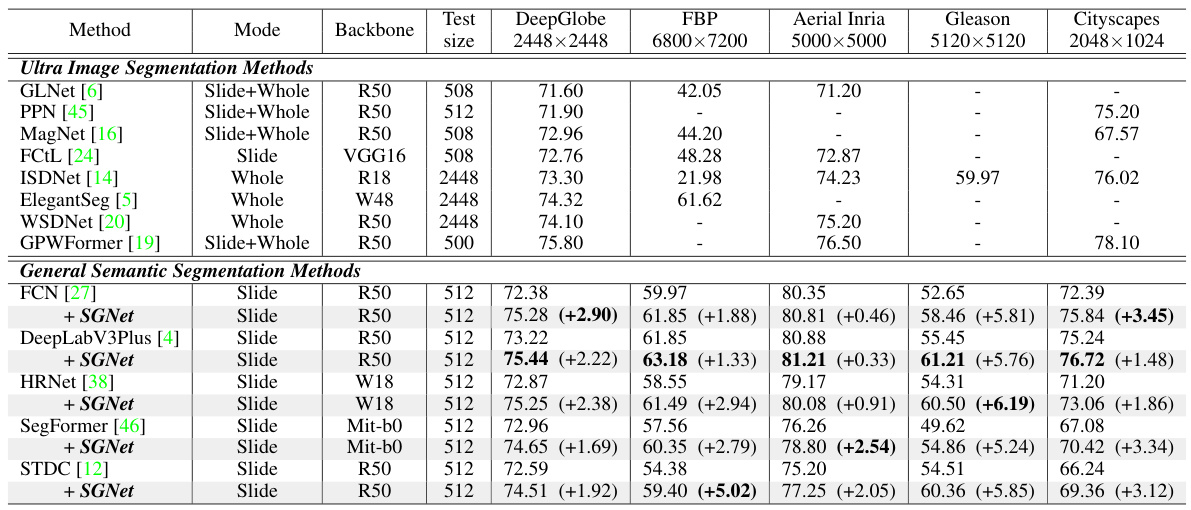
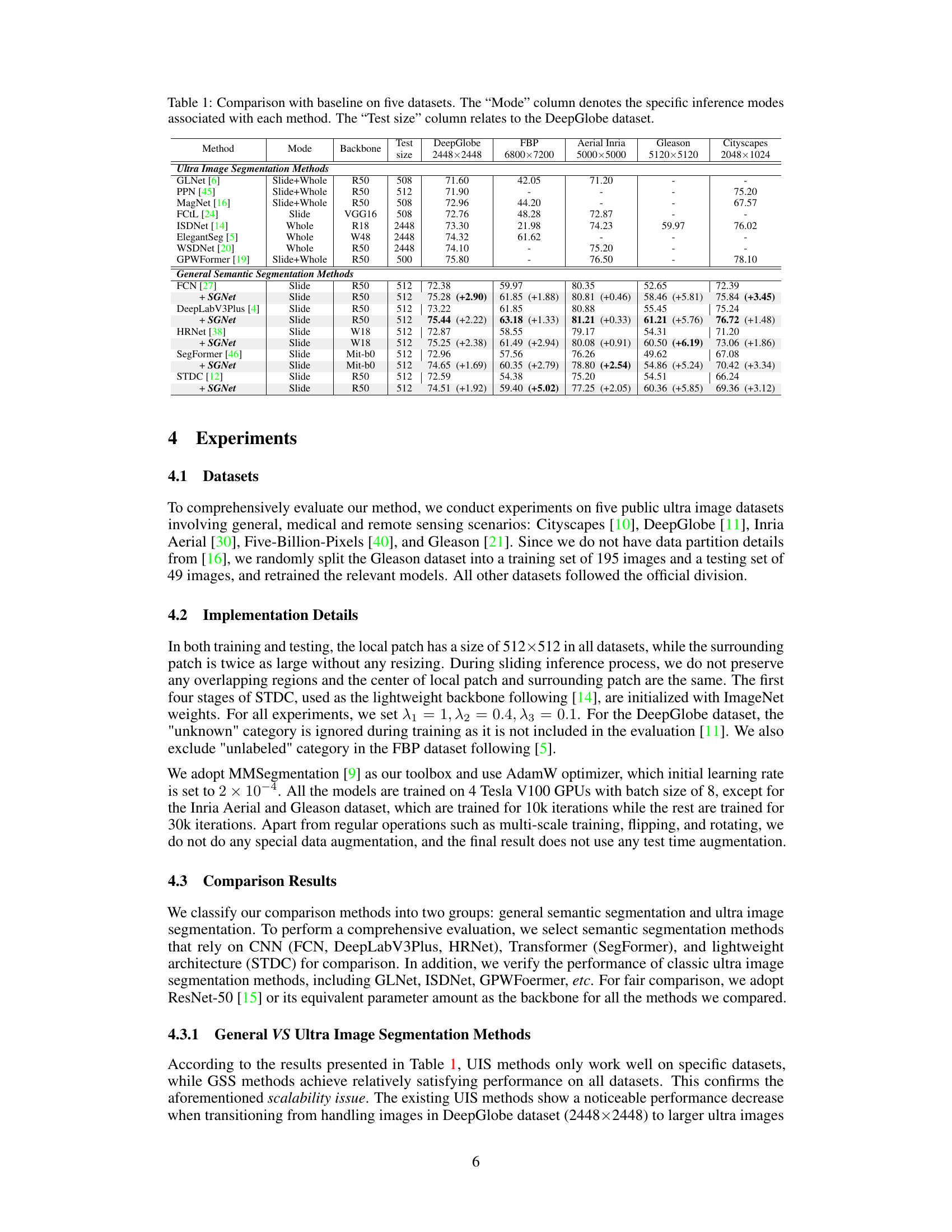
This table compares the performance of the proposed SGNet method with various baseline methods on five different datasets. It shows the mean Intersection over Union (mIoU) scores for each method across the datasets. The ‘Mode’ column indicates the inference strategy used (e.g., slide, whole image). The ‘Backbone’ column specifies the convolutional neural network used as the base architecture. The ‘Test Size’ column refers to the DeepGlobe dataset, highlighting the different image sizes used for testing. The table is split into two sections: ‘Ultra Image Segmentation Methods’ and ‘General Semantic Segmentation Methods,’ showing how SGNet improves upon existing methods. The numbers in parentheses show the improvement gained by adding SGNet to the general segmentation models.
In-depth insights#
UltraSeg: A New Approach#
UltraSeg, as a novel approach, likely presents a significant advancement in ultra-high-resolution image segmentation. Its novelty probably stems from addressing the limitations of existing methods. Scalability and architectural constraints are likely key challenges tackled by UltraSeg, perhaps through a new framework that efficiently handles massive image data while maintaining accuracy. The approach might involve a unique combination of global and local context processing, possibly integrating a deep learning model with a more efficient algorithm for handling large images. Innovative techniques for feature extraction and integration may be employed, potentially involving advanced contextual information processing for enhanced segmentation. The core of UltraSeg’s innovation likely lies in its ability to achieve both high accuracy and computational efficiency on ultra-high resolution images, surpassing existing methods by a considerable margin. Generalizability across different datasets and model architectures is a further point of distinction, showing its practicality in real-world applications.
SGNet Architecture#
The SGNet architecture cleverly integrates a general segmentation model with a surrounding context-guided branch (SCB). This dual-branch design directly addresses the scalability and architectural limitations of traditional ultra-high-resolution image segmentation methods. The general segmentation module acts as a backbone, processing local image patches efficiently. Crucially, the SCB, using a larger surrounding context area, refines these local segmentations, improving accuracy and mitigating the fragmentation issues often associated with patch-based approaches. The SCI within the SCB leverages self-attention mechanisms to effectively integrate contextual information, enhancing the model’s ability to understand spatial relationships and predict boundaries more accurately. This two-pronged design allows SGNet to benefit from the stability and generality of existing models while overcoming their limitations regarding ultra-high-resolution images.
Contextual Integration#
Contextual integration in image segmentation aims to enhance local predictions by incorporating information from surrounding regions. This is crucial for handling complex scenes, as it allows the model to understand the broader context in which individual pixels or patches reside. Effective contextual integration requires mechanisms to selectively gather and fuse relevant contextual information, avoiding the inclusion of irrelevant or distracting details, which can otherwise hinder performance. The integration strategy needs to efficiently combine local and global features, ensuring that both contribute effectively to the final segmentation map. Various techniques, including attention mechanisms and dilated convolutions, have been employed to achieve this. The success of contextual integration hinges on the careful design of these mechanisms to strike a balance between capturing sufficient context and maintaining computational efficiency. Choosing the appropriate integration method depends heavily on the specific dataset and task; a technique that works well for one application may not be suitable for another.
Scalability and Limits#
A crucial aspect of any machine learning model is its scalability and inherent limits. Scalability refers to a model’s capacity to handle increasingly large datasets and complex tasks without significant performance degradation. In research papers, this often involves assessing how computational resources scale with dataset size, and whether the model’s accuracy or efficiency suffers under strain. Limits, on the other hand, represent the boundaries of a model’s capabilities, often dictated by architectural choices, computational constraints, or inherent biases in the data. A thoughtful analysis of scalability and limits involves exploring trade-offs between model complexity, accuracy, and resource requirements. For example, a highly accurate model may be computationally expensive and not scalable to real-world applications, while a faster, more scalable model may sacrifice some level of performance. Understanding these trade-offs is vital for practical deployment and highlights the importance of carefully evaluating a model’s efficacy beyond just its performance on benchmark datasets.
Future of UltraSeg#
The “Future of UltraSeg” (ultra image segmentation) holds immense potential, driven by the increasing availability of ultra-high resolution imagery and the continuous advancements in deep learning. Scalability remains a key challenge; current methods struggle to efficiently process massive datasets and images. Future research should focus on developing more efficient architectures and algorithms, potentially exploring techniques like hierarchical processing or progressive refinement. Contextual information integration will play a crucial role; methods must effectively leverage global context to guide accurate local segmentation. Combining global and local approaches in a principled way, perhaps through novel attention mechanisms or transformer-based models, could yield significant improvements. Dataset biases and limited generalizability across diverse image types are concerns; future work needs to address this by focusing on data augmentation and creating more diverse and representative benchmark datasets. Finally, exploring the potential of weakly-supervised or unsupervised learning could significantly reduce the reliance on large, manually-annotated datasets. Addressing these challenges will pave the way for more accurate, robust, and efficient ultra image segmentation, opening new avenues in diverse applications such as remote sensing, medical imaging, and autonomous driving.
More visual insights#
More on figures

This figure illustrates the architecture of the proposed SGNet framework for ultra image segmentation. It shows how a local patch and its surrounding context are processed by two separate branches: a general segmentation module and a surrounding context-guided branch. The output feature maps from both branches are then concatenated and fed into segmentation heads to generate the final prediction. The surrounding context-guided branch incorporates a surrounding context integration module to leverage information from the broader area around the local patch. The framework also uses loss functions to improve boundary consistency between predictions of adjacent patches and the overall segmentation accuracy.

This figure compares the qualitative segmentation results of different methods on two datasets: DeepGlobe and Inria Aerial. The top row shows results for DeepGlobe images (2448x2448 resolution), while the bottom row presents results for Inria Aerial images (5000x5000 resolution). Each row displays the original image, the ground truth segmentation, and the results obtained using FCtL, ISDNet, and the proposed SGNet method. The visual comparison highlights the differences in accuracy and boundary delineation between the various methods.

This figure compares the performance of adding the Surrounding Context-guided Branch (SCB) to different general segmentation models in the Cityscapes dataset. The images show the ground truth, results from HRNet and DeepLabV3Plus alone, and results from the same models with SCB added. The addition of SCB improves segmentation accuracy for all models, demonstrating its effectiveness in enhancing overall segmentation performance.

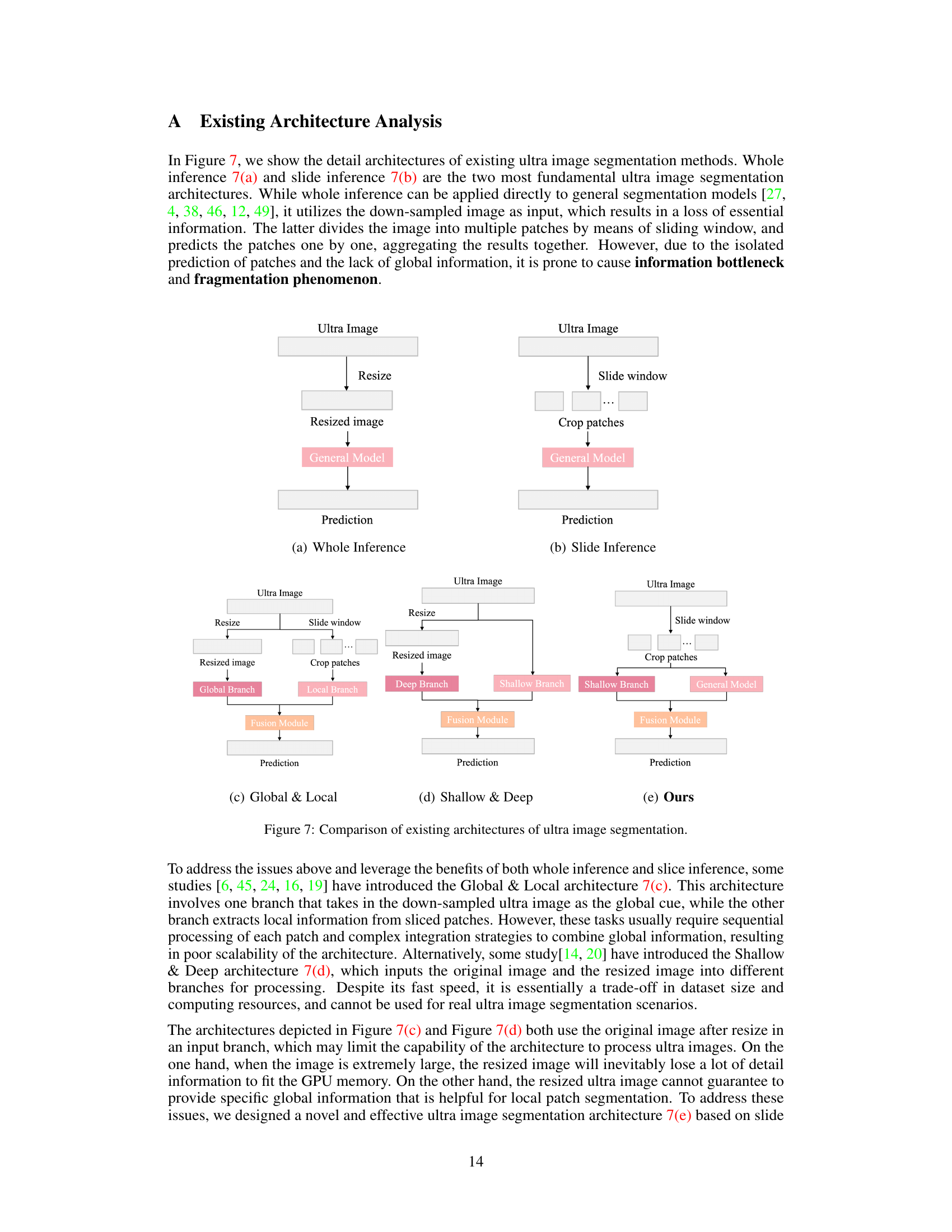
This figure compares five different architectures for ultra image segmentation: (a) Whole Inference, (b) Slide Inference, (c) Global & Local, (d) Shallow & Deep, and (e) Ours (SGNet). Whole inference uses a resized image as input to a general segmentation model, losing detail. Slide inference processes the image in overlapping patches, which can lead to inconsistencies at patch boundaries. Global & Local and Shallow & Deep approaches use both global and local information but may have limitations in scalability or computational cost. The authors’ proposed architecture (SGNet) is designed to leverage surrounding context for enhanced accuracy and scalability.

This figure compares the performance of SGNet and DeepLabV3Plus on the CelebAMask-HQ dataset. To simulate ultra-high resolution images, the images were upscaled from 1024 pixels to 2448 pixels. A sliding window approach with a window size of 512 pixels and no overlap was used for inference. The figure shows that SGNet produces more accurate and detailed segmentations compared to DeepLabV3Plus.
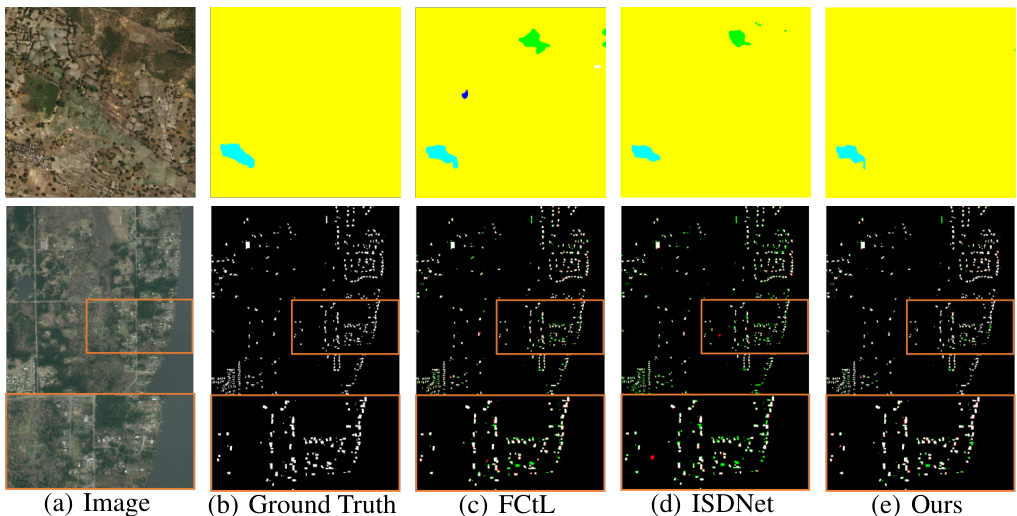
This figure shows a qualitative comparison of the proposed SGNet method against other state-of-the-art ultra image segmentation methods (FCtL and ISDNet) on the DeepGlobe and Inria Aerial datasets. The top row displays results for a DeepGlobe image (2448x2448 resolution), while the bottom row shows results for an Inria Aerial image (5000x5000 resolution). Each row presents the original image, ground truth segmentation, and segmentation results for FCtL, ISDNet, and the proposed SGNet. The visual comparison highlights the improved accuracy and boundary consistency achieved by SGNet.

This figure compares the results of adding the Surrounding Context-guided Branch (SCB) to two different general segmentation models (DeepLab and HRNet) on the Cityscapes dataset. It visually demonstrates the improvement in segmentation accuracy achieved by incorporating the SCB, showcasing its effectiveness in refining the predictions of these models.
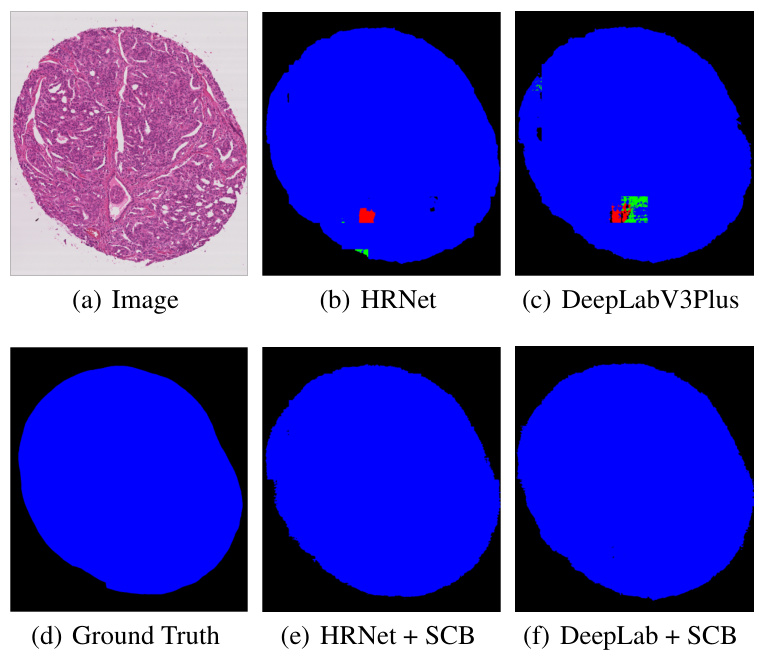
This figure shows a comparison of the Gleason dataset segmentation results using HRNet and DeepLabV3Plus models, both with and without the addition of the Surrounding Context-guided Branch (SCB). The top row displays the original image, the HRNet model prediction, and the DeepLabV3Plus model prediction. The bottom row shows the ground truth, the HRNet model with SCB, and the DeepLabV3Plus model with SCB. This visualization demonstrates the improvement in segmentation accuracy provided by incorporating SCB into the base models.
More on tables

This table compares the performance of the proposed SGNet method with various baseline methods (both general semantic segmentation and ultra image segmentation methods) across five different datasets (DeepGlobe, Aerial Inria, Gleason, Cityscapes, and Five-Billion-Pixels). The table shows the mean Intersection over Union (mIoU) scores achieved by each method, categorized by inference mode (slide, whole, or a combination) and backbone architecture used. The ‘Test size’ column specifies the input image size used for the DeepGlobe dataset.
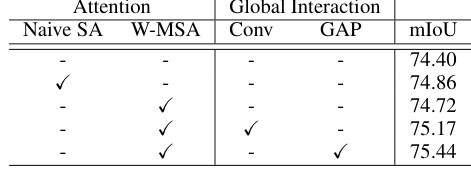
This table presents the ablation study of the surrounding context integration module (SCI) within the SGNet architecture. It shows the impact of different components of SCI on the model’s performance, measured by mean Intersection over Union (mIoU). The components evaluated include: Naive Self-Attention (SA), Window-based Multi-Head Self-Attention (W-MSA), Convolution, and Global Average Pooling (GAP). The results demonstrate how each component contributes to the overall performance, highlighting the effectiveness of the W-MSA and GAP in integrating contextual information for improved segmentation.

This table presents the results of an ablation study comparing different feature fusion schemes (Early Fusion, Late Fusion, ADD, and CONCAT) used in the SGNet architecture. The mIoU (mean Intersection over Union) metric is used to evaluate the performance of each scheme, indicating the effectiveness of each approach in combining local and surrounding contextual information for improved segmentation accuracy.

This table compares the performance of the proposed SGNet method with various baseline methods (both general semantic segmentation and ultra image segmentation methods) across five different datasets. The results are presented in terms of mean Intersection over Union (mIoU) scores and show the consistent improvement achieved by integrating SGNet into different general segmentation models. The table also indicates the inference mode (Whole, Slide or a combination) and backbone architecture used by each method. The DeepGlobe dataset’s test image size is specifically noted.

This table compares the performance of various ultra image segmentation methods and general semantic segmentation methods on five datasets (DeepGlobe, Aerial Inria, Gleason, Cityscapes, and Five-Billion-Pixels). It shows the mean Intersection over Union (mIoU) scores achieved by each method, along with inference mode (slide or whole image), backbone network used, and test image size for the DeepGlobe dataset. The table highlights the performance gains achieved by integrating the proposed SGNet framework with different general segmentation models, demonstrating its effectiveness across various datasets and model architectures.

This table compares the performance of the proposed SGNet method with several baselines on five different datasets. It shows the mean Intersection over Union (mIoU) scores achieved by each method, broken down by dataset and inference mode (Whole, Slide, or a combination). The ‘Mode’ column indicates whether the entire image or individual patches were used for inference. The ‘Backbone’ column indicates the backbone network used for each method. The table also shows the improvements provided by adding SGNet to general semantic segmentation models. This table highlights the consistent improvement achieved by the proposed model across different datasets and baselines.
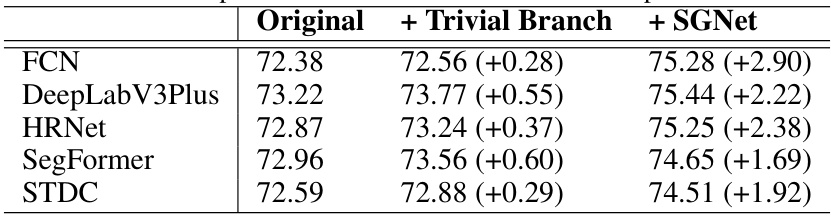
This table compares the performance of the proposed SGNet method with several baseline methods (both general semantic segmentation and ultra image segmentation methods) across five different datasets (DeepGlobe, Aerial Inria, 5000x5000, Gleason, Cityscapes). It shows the mean Intersection over Union (mIoU) scores for each method on each dataset, indicating the accuracy of segmentation. The ‘Mode’ column specifies whether the method uses a sliding window or whole image inference approach, while ‘Test size’ refers to the resolution of images used for testing in the DeepGlobe dataset. The table highlights the consistent improvement achieved by SGNet across various baseline methods and datasets.
Full paper#