↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large vision-language models (VLLMs) are powerful but raise significant data security concerns due to potential inclusion of sensitive information during training. Current methods for detecting misuse of data in VLLMs are inadequate due to the lack of standardized datasets and methodologies. This has resulted in a critical and unresolved issue in securing sensitive data used to train these models.
This paper introduces the first membership inference attack (MIA) benchmark designed for VLLMs, along with a novel MIA pipeline for token-level image detection. A new metric, MaxRényi-K%, is proposed to evaluate MIAs across various VLLMs and modalities (text and image). The results demonstrate the effectiveness of the proposed MIA pipeline and metric, contributing to a deeper understanding of MIAs in the context of VLLMs and offering valuable tools for enhancing data security and privacy in this emerging field.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical data security concerns surrounding large vision-language models (VLLMs). By introducing the first MIA benchmark tailored for VLLMs and a novel MIA pipeline, it significantly advances the understanding and methodology of membership inference attacks in this emerging field. The research directly contributes to the development of more secure and privacy-preserving VLLMs, which is vital in today’s data-driven world. Moreover, the new MaxRényi-K% metric offers a versatile tool for evaluating MIAs across various modalities, opening new avenues for future research and enhancing the robustness of privacy-preserving techniques.
Visual Insights#

This figure illustrates the Membership Inference Attacks (MIA) against large vision-language models (VLLMs). The top half shows the image detection pipeline, detailing the generation and inference stages. In the generation stage, an image and instruction are fed to the VLLM to produce a description. In the inference stage, the image, instruction, and generated description are fed back into the model, and logit slices are extracted for metric calculation. The bottom half details the MaxRényi-K% metric used to quantify the confidence of the model’s output, providing a measure for both text and image data. The metric involves calculating the Rényi entropy for each token position, selecting the largest K% entropies, and averaging them to determine membership. A higher average suggests higher confidence and therefore a higher probability of membership in the training set.
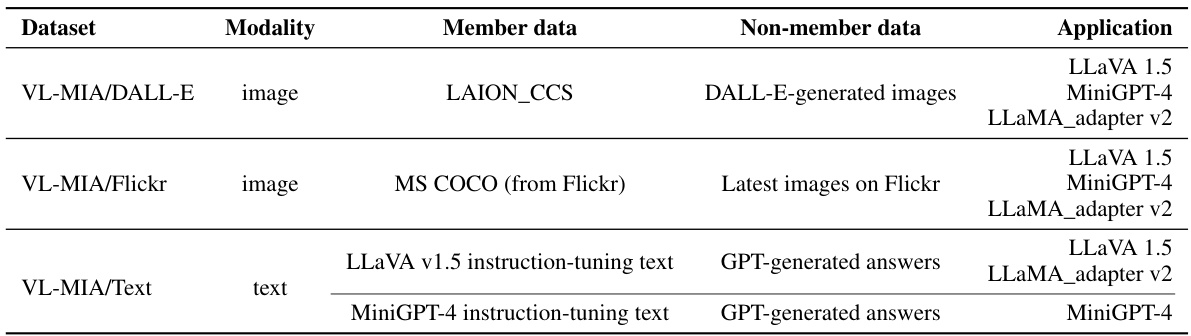
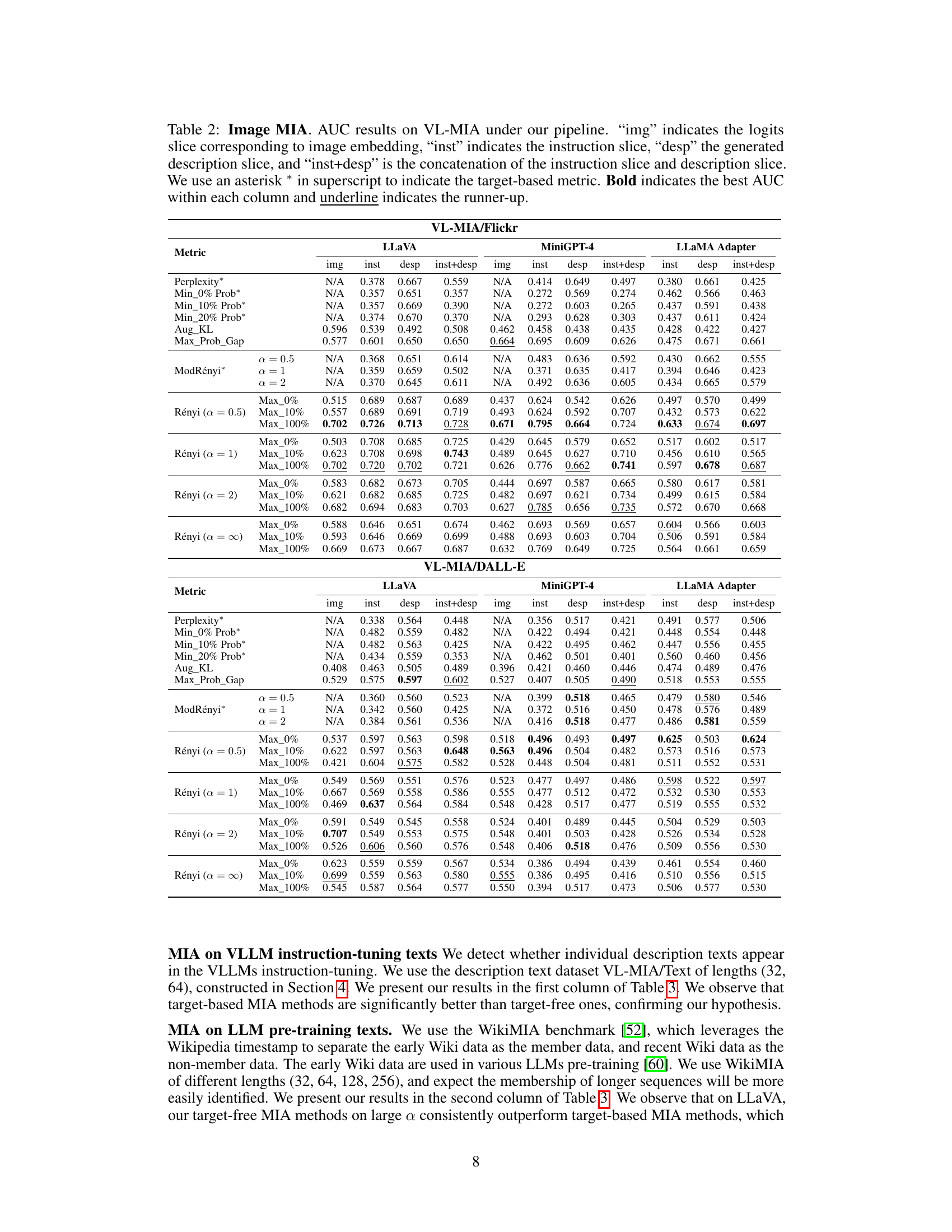
This table summarizes the Vision Language Membership Inference Attack (VL-MIA) dataset. It shows the modality (image or text), the source of the member data (data used to train popular VLLMs), the source of the non-member data (data not used in training), and which VLLMs the dataset is designed to be used with. The goal of VL-MIA is to provide a benchmark for evaluating Membership Inference Attacks against Vision-Language Models.
In-depth insights#
VL-MIA benchmark#
The VL-MIA benchmark represents a significant advancement in evaluating the data security of large vision-language models (VLLMs). Its novelty lies in the first-ever standardized dataset specifically designed for membership inference attacks (MIAs) against VLLMs, addressing the critical lack of such resources in the field. This benchmark enables a more rigorous and systematic evaluation of various MIA techniques, facilitating a deeper understanding of VLLM vulnerabilities and promoting the development of more effective defenses. The inclusion of multiple VLLMs and modalities (image and text) in the benchmark provides a comprehensive evaluation framework, moving beyond single-modality studies and promoting a cross-modal perspective. By providing both open-source and closed-source model evaluations, the benchmark offers unprecedented insight into the real-world implications of data security concerns surrounding VLLMs. The availability of code and data further enhances its value, encouraging wider participation in the ongoing research aimed at improving the security and privacy of VLLMs.
Cross-modal MIA#
Cross-modal membership inference attacks (MIAs) represent a significant advancement in data privacy research within the field of large vision-language models (VLLMs). Unlike traditional MIAs that focus on a single modality (either text or image), cross-modal MIAs leverage the inherent interconnectedness of visual and textual information within VLLMs to enhance attack efficacy. This multi-modal approach allows attackers to exploit the model’s cross-modal reasoning capabilities, making it more challenging to defend against. By analyzing the model’s responses to both image and text inputs, cross-modal MIAs can identify subtle patterns indicative of data membership. A key advantage lies in its increased robustness and accuracy, as it avoids the limitations of single-modality attacks that may fail if one input is obscured or less informative. However, developing effective cross-modal MIAs requires sophisticated techniques to properly combine and analyze multi-modal data representations. Furthermore, the increased complexity adds to the computational cost of these attacks. Future research should investigate effective defense mechanisms specifically tailored to counter cross-modal MIAs, perhaps focusing on differential privacy or data augmentation strategies. The ultimate goal is to create VLLMs that are both powerful and protective of user privacy.
MaxRényi-K% metric#
The proposed MaxR
ényi-K% metric offers a novel approach to membership inference attacks (MIAs) by leveraging the Rényi entropy of token probability distributions. Its key innovation lies in its adaptability to both text and image modalities, addressing a significant challenge in multi-modal MIA. Unlike previous methods, which primarily focus on next-token prediction probabilities (target-based), MaxRényi-K% operates on the entire token sequence. This target-free approach is particularly valuable for image MIAs where individual image tokens aren’t directly accessible. By selecting the top K% tokens with the largest Rényi entropies, the metric effectively captures the model’s confidence in its predictions. The parameter K provides flexibility in balancing sensitivity and robustness, allowing for adjustments based on the specific characteristics of the data and model. Furthermore, the use of Rényi entropy, which generalizes Shannon entropy, offers advantages in scenarios where data distributions deviate from uniformity. The metric’s effectiveness is demonstrated through experiments, outperforming existing MIA methods in various settings, particularly on images. Its cross-modal applicability and ability to incorporate confidence levels make it a valuable tool for enhancing data security and privacy in large vision-language models.
GPT-4 image MIA#
The heading ‘GPT-4 image MIA’ suggests an investigation into Membership Inference Attacks (MIAs) against OpenAI’s GPT-4 model, specifically focusing on its image processing capabilities. This is a significant area of research because VLLMs (Vision-Language Large Models) like GPT-4 are trained on massive datasets that may contain sensitive information. A successful GPT-4 image MIA would demonstrate that an attacker could potentially infer the presence of a specific image within the training data by analyzing the model’s output. This has serious implications for data privacy and security, raising concerns about the potential misuse of sensitive images included in the training datasets of such powerful AI models. The research likely involves developing novel MIA techniques tailored to the unique architecture and functionality of GPT-4’s vision module, potentially comparing its performance against other vision-language models or existing MIA benchmarks. A key aspect would be the evaluation metrics used to assess the success of the attack, and exploring the robustness of the method to various defenses or countermeasures. The findings could have profound implications for future VLLM development, prompting the need for more privacy-preserving training methods and enhanced security measures to protect sensitive data.
Future directions#
The study of membership inference attacks (MIAs) against large vision-language models (VLLMs) is in its early stages, presenting exciting avenues for future research. A key area is developing more sophisticated MIA techniques that can handle the complexities of multi-modal data and diverse VLLM architectures. Current methods often struggle with the intricate interplay between visual and textual information, so improving the accuracy and robustness of MIAs in this context is critical. Further investigation into the effectiveness of different MIA metrics in various VLLM training scenarios is also needed. While existing metrics show promise, their limitations are still apparent and further research could identify better metrics or improve existing ones. Research on more robust defense mechanisms against MIAs for VLLMs would be beneficial. Currently, defenses are limited, and focusing on creating proactive measures to safeguard against data leakage is paramount. Additionally, extending the MIA benchmark to a broader range of VLLMs and datasets would make it more comprehensive and reliable. This includes exploring different VLLM architectures, training data types, and applications to better reflect real-world scenarios. Finally, exploring the potential societal impact of MIAs on VLLMs is crucial. The widespread use of VLLMs raises ethical concerns related to data privacy and security, demanding further investigation into the wider implications of these attacks.
More visual insights#
More on figures
This figure illustrates the proposed membership inference attack (MIA) pipeline against large vision-language models (VLLMs). The top half shows the image detection pipeline, consisting of a generation stage (where an image and instruction are fed to the model to generate a description) and an inference stage (where the image, instruction, and generated description are fed to the model to extract logits for metric calculation). The bottom half details the MaxRényi-K% metric used to quantify the confidence of the model output for both text and image data. This metric calculates the Rényi entropy for each token position, selects the top K% of these positions with highest entropy and averages their entropy to determine membership.
This figure illustrates the proposed membership inference attack (MIA) pipeline against large vision-language models (VLLMs). The top half shows the two-stage pipeline: a generation stage where an image and instruction are fed to the VLLM to produce a description, followed by an inference stage where the image, instruction, and generated description are used to extract logits for metric calculation. The bottom half details the MaxRényi-K% metric used to quantify the confidence of the model’s output for both text and image data, focusing on the Rényi entropy of token positions. This metric helps determine if a specific data point is part of the VLLM’s training data.

This figure illustrates the Membership Inference Attack (MIA) pipeline against large vision-language models (VLLMs). The top half shows the image detection pipeline, which involves a generation stage (feeding the image and an instruction to the model to generate a description) and an inference stage (feeding the generated description, image and instruction to the model to extract logits for metric calculation). The bottom half details the MaxRényi-K% metric, a novel metric for evaluating MIAs. This metric calculates the Rényi entropy for each token position in the model’s output, selects the top K% positions with the highest Rényi entropy, and then averages these entropies to obtain a final score.

This figure illustrates the Membership Inference Attacks (MIA) against large vision-language models (VLLMs). The top part shows the image detection pipeline, which consists of two stages: generation and inference. In the generation stage, an image and instruction are fed into the VLLM to generate a description. The inference stage uses the image, instruction, and generated description to extract logits slices for metric calculations. The bottom part details the MaxRényi-K% metric used to assess the confidence of the model’s output for both text and image data. It involves calculating the Rényi entropy for each token position, selecting the largest k%, and then averaging the Rényi entropy.
This figure illustrates the proposed membership inference attack (MIA) pipeline against large vision-language models (VLLMs). The top half depicts the two-stage process: a generation stage where an image and instruction are fed to the VLLM to produce a description, and an inference stage where the image, instruction, and generated description are used to extract logit slices for metric calculation. The bottom half details the MaxRényi-K% metric, showing how Rényi entropy is calculated for each token position, the top k% positions are selected, and then the average Rényi entropy is computed.

This figure illustrates the proposed membership inference attack (MIA) pipeline against large vision-language models (VLLMs). The top half shows a diagram of the image detection pipeline, detailing the generation and inference stages. The generation stage involves inputting an image and instruction to the VLLM to generate a description. The inference stage uses the image, instruction, and generated description to extract logit slices for metric calculation. The bottom half explains the MaxRényi-K% metric used to quantify the confidence of the model’s output for both text and image data, focusing on Rényi entropy calculations for token positions.
More on tables

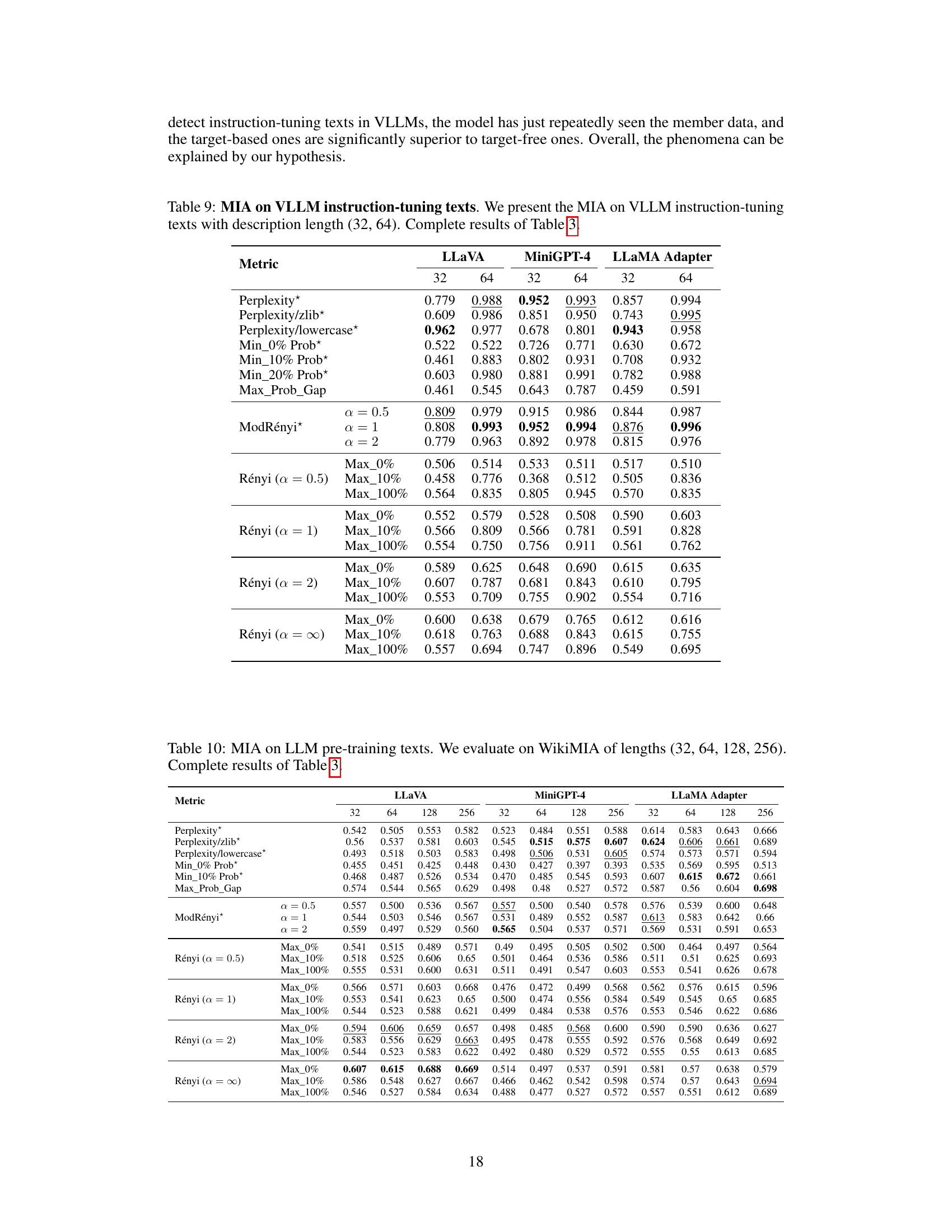
This table presents the Area Under the Curve (AUC) scores for various membership inference attack (MIA) methods on the LLaVA model. It compares different metrics (Perplexity, Min-K% probability, Max-Prob-Gap, and ModRényi) across different text lengths (32 and 64 tokens). It also differentiates between results obtained during Language Model (LLM) pre-training and during VLLM instruction tuning, indicating whether the training data was used in the base LLM’s pre-training or the subsequent instruction tuning phase. This shows the effectiveness of each MIA metric and the influence of the training data’s usage stage.
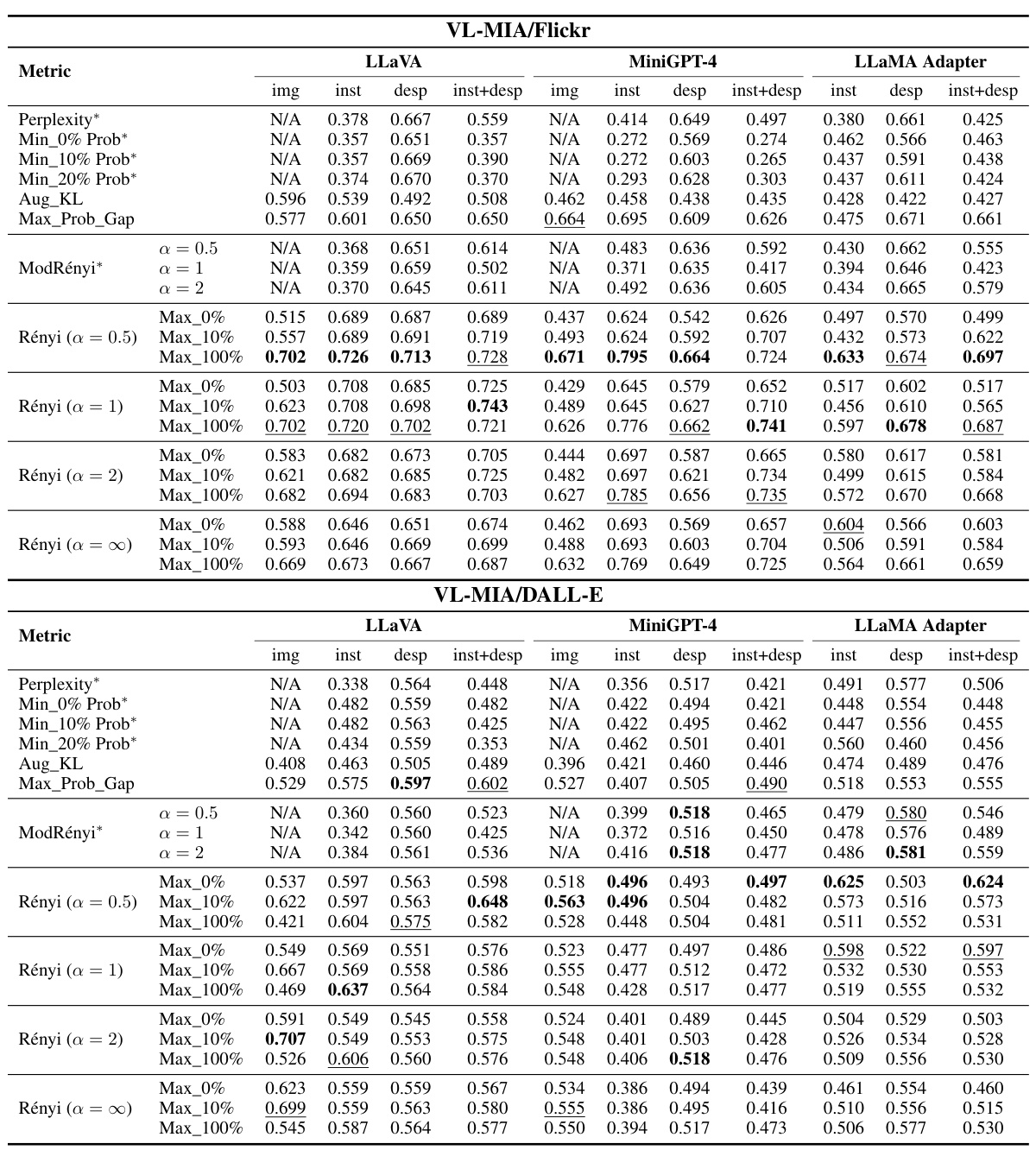
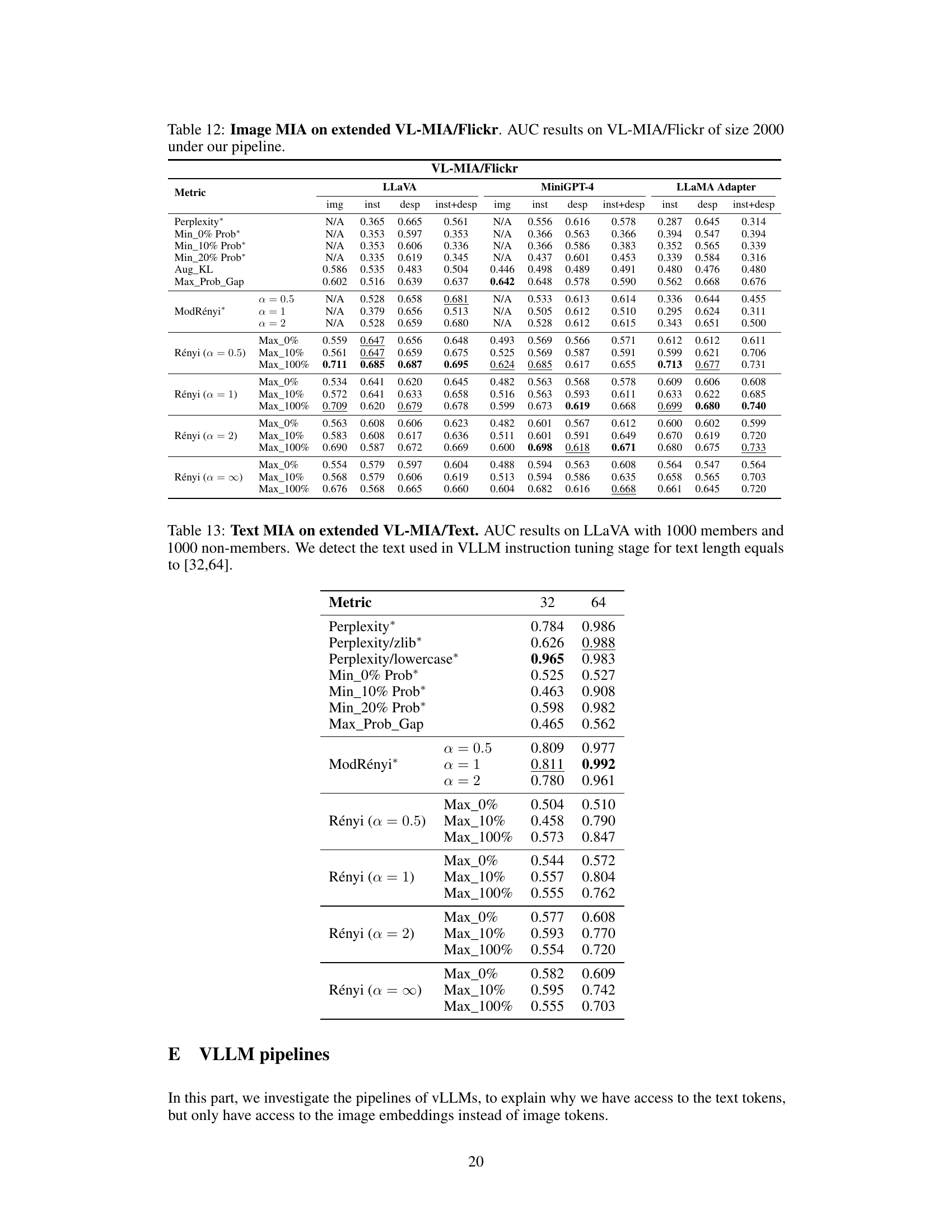
This table presents the results of membership inference attacks (MIAs) on image data using different metrics and VLLMs (MiniGPT-4, LLaMA Adapter v2.1, and LLaVA 1.5). It shows the Area Under the Curve (AUC) scores for various methods, including perplexity, minimum probability, maximum probability gap, and MaxRényi, broken down by the type of logits slice used (image, instruction, description, or combined instruction and description). Target-based metrics are marked with an asterisk. The best and second-best AUC scores are highlighted in bold and underlined, respectively. The results demonstrate the effectiveness of the proposed MaxRényi metric and cross-modal pipeline for image MIAs.
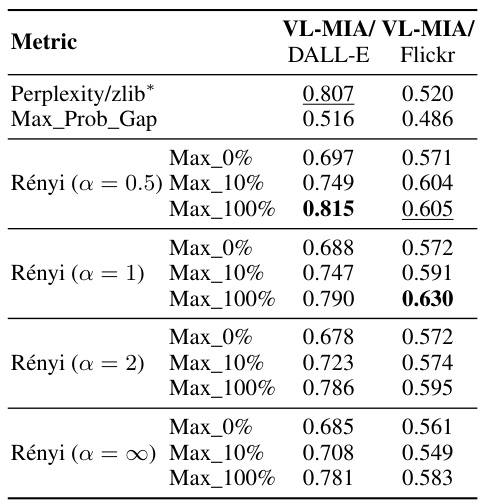
This table presents the results of membership inference attacks (MIAs) performed on the closed-source model GPT-4, using two image datasets: VL-MIA/Flickr and VL-MIA/DALL-E. The table shows AUC scores for various MIA methods, including MaxRényi-K% with different α values and K percentages, as well as baselines such as Perplexity/zlib and Max_Prob_Gap. The results demonstrate the effectiveness of the MIAs on GPT-4, highlighting the potential risks of privacy leakage even with closed-source models.

This table presents the results of Membership Inference Attacks (MIAs) on images, using different metrics and focusing on various logits slices (image, instruction, description). It compares the Area Under the Curve (AUC) scores of different MIA methods for two datasets (VL-MIA/Flickr and VL-MIA/DALL-E) and three vision-language models (LLaVA, MiniGPT-4, and LLAMA Adapter). The asterisk (*) denotes target-based metrics, bold indicates the highest AUC, and underlined values represent the second-highest AUC within each column.

This table shows the prompts used to construct the VL-MIA dataset. Specifically, it details the prompts used for generating images with DALL-E 2 and text with GPT-4-vision-preview, categorized by the dataset (VL-MIA/DALL-E, VL-MIA/Text for MiniGPT-4, VL-MIA/Text for LLaVA 1.5) and model used for generation. The prompts are designed to elicit responses relevant to the training data for each corresponding VLLM.
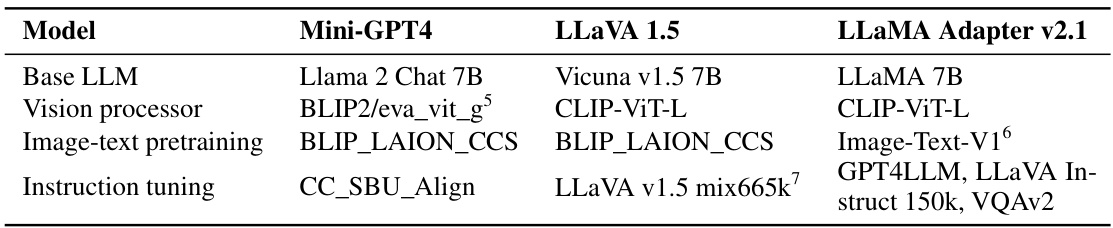
This table lists the versions, base models, and training datasets of the three VLLMs used in the paper’s experiments: MiniGPT-4, LLaVA 1.5, and LLAMA Adapter v2.1. It details the base large language model (LLM), the vision processor used, the datasets used for image-text pre-training, and the datasets used for instruction tuning.

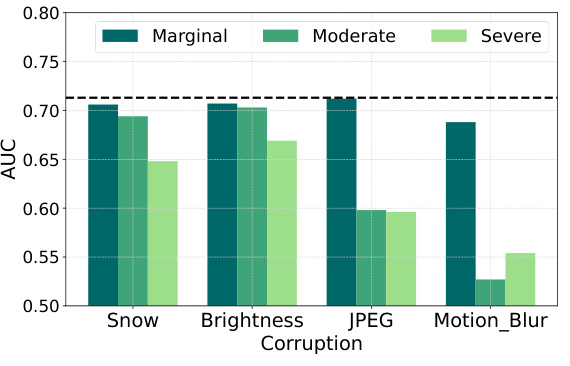
This table shows the values used for the corruption parameter ‘c’ in the ImageNet-C code. The parameter controls the level of corruption applied to images during the experiments. The rows represent the severity levels (Marginal, Moderate, Severe), and the columns represent different types of corruption (Brightness, Motion_Blur, Snow, JPEG). Each cell contains the specific value used for that corruption type and severity level.

This table presents the Area Under the Curve (AUC) scores for various membership inference attack (MIA) methods on the LLaVA model. The methods are evaluated on two different datasets representing pre-training and instruction-tuning stages of the VLLM. Different text lengths (32, 64, 128, and 256 tokens) are used. The table compares various metric-based MIA methods, including perplexity-based methods, minimum probability based methods, and Rényi entropy-based methods (MaxRényi). The results show the effectiveness of each method for detecting whether a given text sequence was part of the model’s training data.
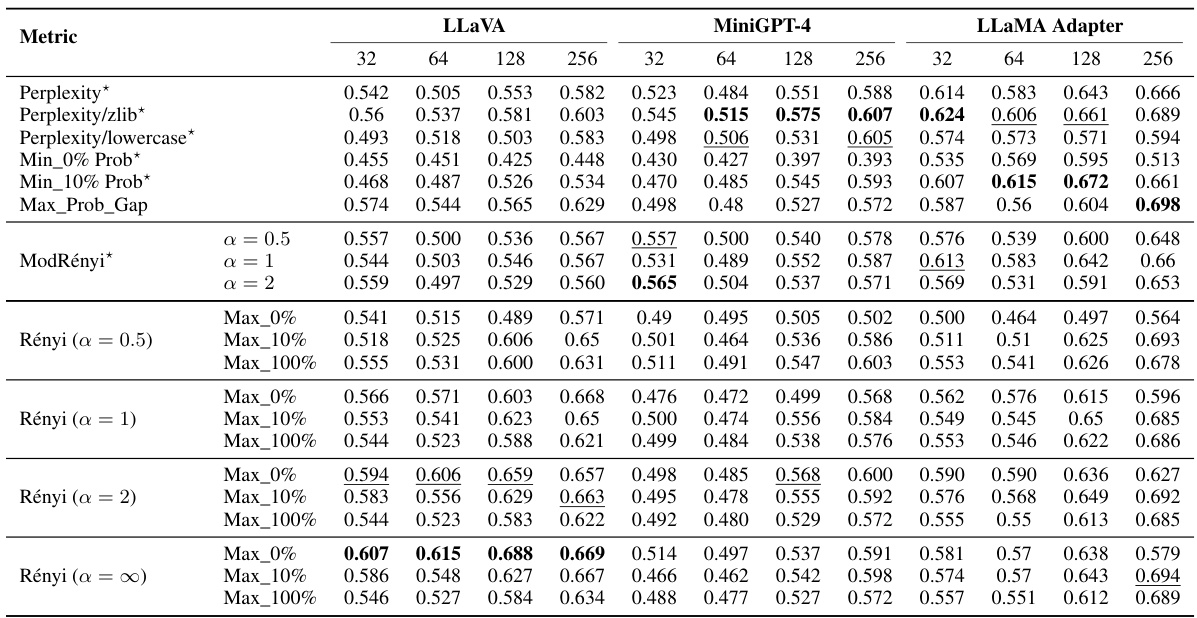
This table presents the Area Under the Curve (AUC) scores for various membership inference attack (MIA) methods on two image datasets (VL-MIA/Flickr and VL-MIA/DALL-E) using three different vision-language models (VLLMs). The AUC scores are broken down by the type of input used for the MIA (image, instruction, description, or a combination of instruction and description) and the specific MIA method employed. Target-based metrics (indicated by an asterisk) are compared against target-free metrics (MaxRényi and Rényi with various α values). The table helps to assess the effectiveness of different MIA methods on images and the influence of various α parameters in MaxRényi on the performance.
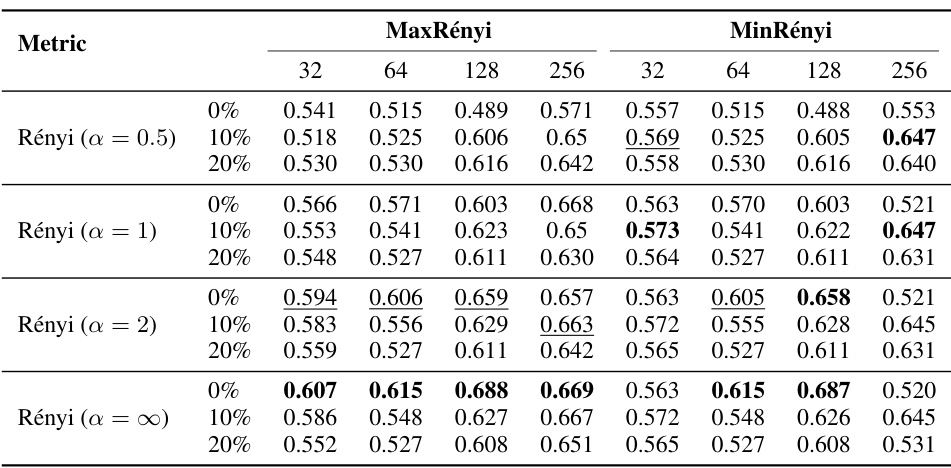
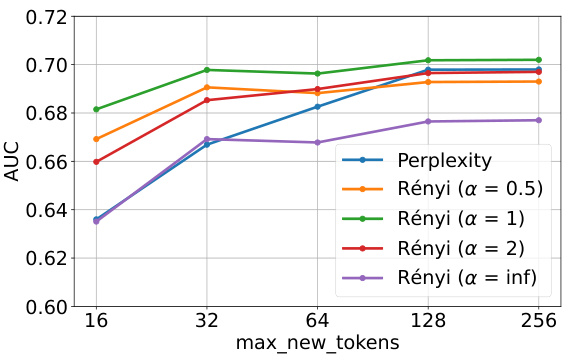
This table presents the results of Membership Inference Attacks (MIAs) on Large Language Model (LLM) pre-training texts using two different metrics: MaxRényi and MinRényi. The WikiMIA benchmark dataset, with text sequences of varying lengths (32, 64, 128, 256), is used. The table shows the Area Under the Curve (AUC) scores for different variations of the MaxRényi and MinRényi metrics (with K values of 0%, 10%, and 20%), and different Rényi entropy orders (α = 0.5, 1, 2, ∞). The results help to compare the performance of these two MIA methods in detecting whether a text sequence was part of the LLM’s pre-training data.

This table presents the Area Under the Curve (AUC) scores for various membership inference attack (MIA) methods applied to image data from the VL-MIA benchmark. Different slices of the model’s output logits (image, instruction, description, and combined instruction+description) are evaluated. Both target-based and target-free MIA metrics are included, and the results are broken down by model (LLaVA, MiniGPT-4, LLAMA Adapter) and metric (MaxRényi, Rényi with different alpha values, etc.). The best performing methods for each scenario are highlighted.

This table presents the results of membership inference attacks (MIAs) on text data using the LLaVA model. It compares the performance of several MIA methods (Perplexity, Max-Prob-Gap, ModRényi, and Rényi with different alpha values and K percentages) in detecting whether a text sequence was part of the model’s instruction-tuning training data. The experiment uses an extended dataset with 1000 member and 1000 non-member data points and text sequences of lengths 32 and 64 tokens.
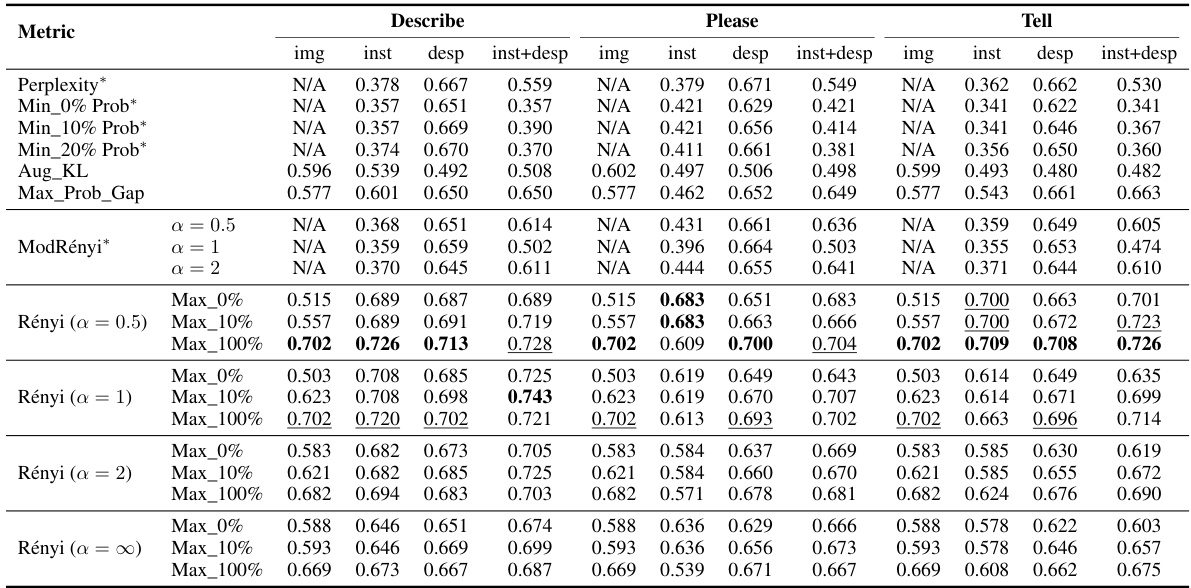
This table presents the Area Under the Curve (AUC) scores for various membership inference attack (MIA) methods on two image datasets (VL-MIA/Flickr and VL-MIA/DALL-E) using three different vision-language models (VLLMs). The methods tested include several baselines and the proposed MaxRényi-K% metric. The table shows the AUC scores for different slices of the model’s output logits (image, instruction, description, and combined instruction and description), demonstrating the performance of each method in detecting whether an image was part of the training data. Target-based methods use the next token as the target for prediction, while target-free methods use all the tokens. The results highlight the superior performance of the MaxRényi-K% metric, especially with a value of α = 0.5, across various scenarios and VLLMs.

This table presents the Area Under the Curve (AUC) scores for various membership inference attack (MIA) methods on two image datasets (VL-MIA/Flickr and VL-MIA/DALL-E) using three different vision-language models (VLLMs). The methods include various target-based and target-free MIA metrics. The table shows performance across different slices of VLLM output logits (image, instruction, description, and combined instruction and description) for each VLLM and metric.

This table provides an overview of the VL-MIA dataset, highlighting its key features. It shows that the dataset includes both image and text modalities, making it suitable for evaluating membership inference attacks (MIAs) on various open-source large vision-language models (VLLMs). The table specifies the modality (image or text), the member data source, the non-member data source, and the intended application (which VLLM the data is designed for). This information is crucial for understanding the scope and design of the VL-MIA benchmark presented in the paper.

This table presents the Area Under the Curve (AUC) scores for various membership inference attack (MIA) methods applied to image data from the VL-MIA benchmark. Different metrics are used, including perplexity and variations of Rényi entropy. The results are broken down by the type of VLLM model, the portion of the model’s output logits used (image, instruction, description, or a combination), and whether the MIA method is target-based or target-free. The table highlights the superior performance of the MaxRényi-K% metric, especially in target-free scenarios, showcasing its effectiveness across different VLLM architectures.
Full paper#