↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are rapidly evolving, but evaluating their performance effectively remains challenging. Existing metrics primarily focus on prediction accuracy, overlooking the internal workings of these complex models. This paper tackles this issue by proposing a novel evaluation method that focuses on how efficiently LLMs eliminate redundancy during training. This method addresses the need for a more intrinsic and comprehensive evaluation of LLMs.
The proposed metric, Diff-eRank, is based on information theory and geometric principles. It quantifies the reduction of uncertainty in a model’s internal representations from an untrained to a trained state. The paper demonstrates Diff-eRank’s effectiveness across various datasets and model sizes, showing a strong correlation with conventional metrics such as loss and accuracy. Further, it introduces a novel alignment evaluation method based on eRank for multi-modal LLMs, providing valuable insights into the quality of modality alignment in these models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers because it introduces a novel metric, Diff-eRank, for evaluating LLMs. This metric offers a new perspective, focusing on internal model representations rather than prediction accuracy. This opens new avenues for understanding how LLMs process information, improving their training, and ultimately leading to better-performing models. Its applicability across uni-modal and multi-modal settings further enhances its value.
Visual Insights#

This figure displays the relationship between Diff-eRank and reduced loss across different model sizes for four different datasets: dolly-15k, wikipedia, openwebtext2, and hh-rlhf. The top row shows the Diff-eRank (difference in effective rank) values plotted against model size (on a logarithmic scale). The bottom row shows the reduced loss (difference between the untrained and trained model losses) also plotted against model size. In each case, both Diff-eRank and reduced loss demonstrate a positive correlation with model size; as the model size increases, so do both metrics. This suggests that larger models are more effective at removing redundant information and achieving better predictive performance.
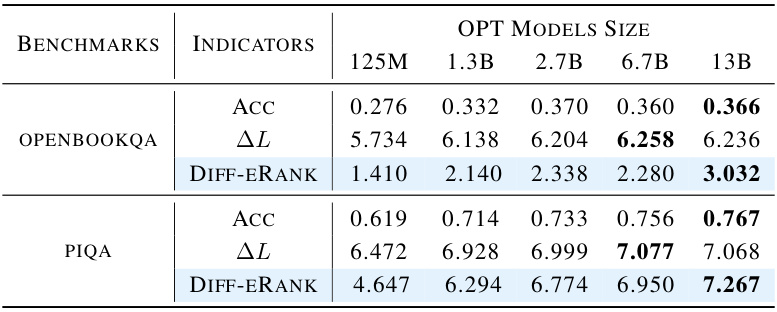
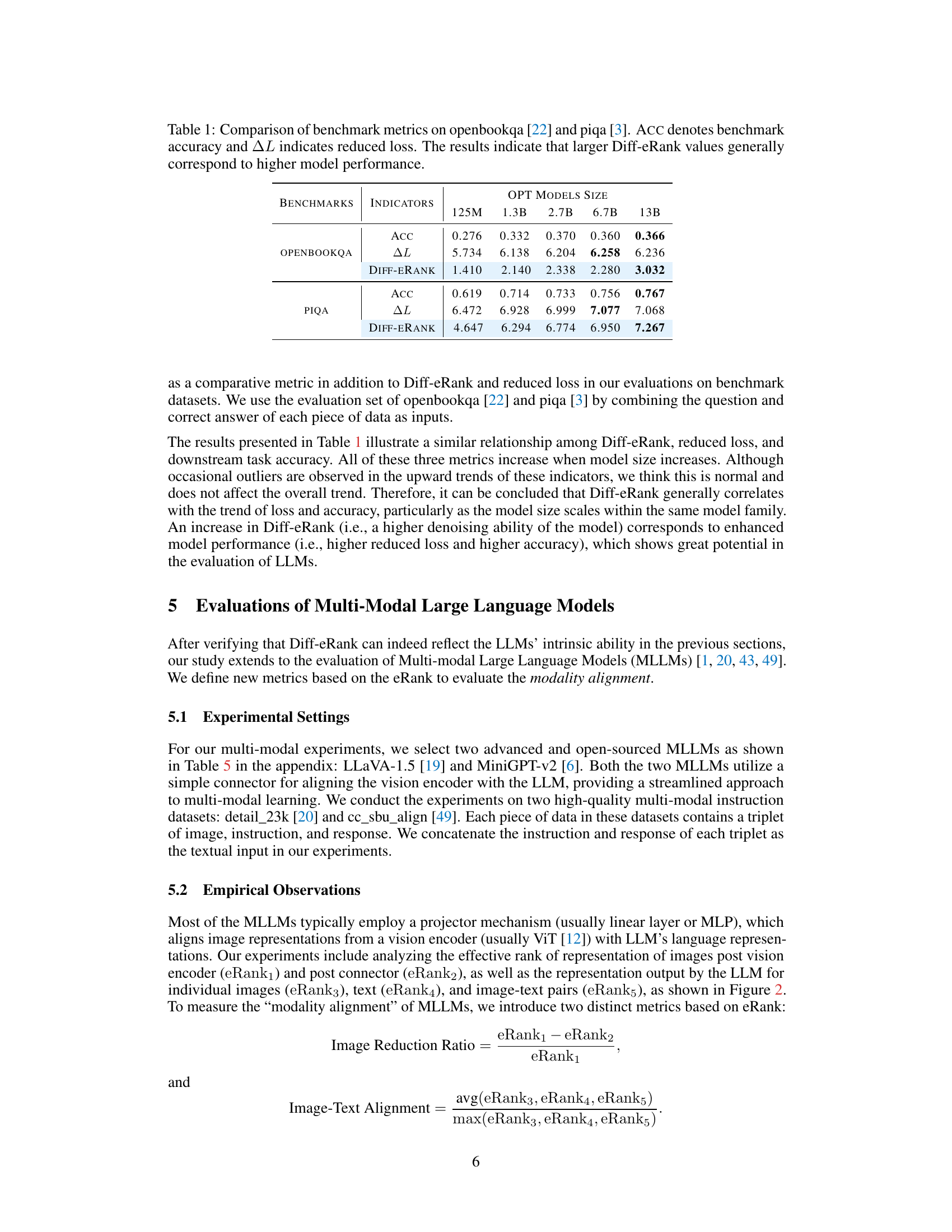
This table presents the results of evaluating the performance of different sized OPT models on two benchmark datasets: openbookqa and piqa. Three metrics are compared: benchmark accuracy (ACC), reduced loss (ΔL), and the novel Diff-eRank metric proposed in the paper. The table shows that as model size increases, all three metrics tend to increase, indicating a positive correlation between Diff-eRank and model performance, as measured by accuracy and loss reduction.
In-depth insights#
Diff-eRank Metric#
The Diff-eRank metric, proposed for evaluating Large Language Models (LLMs), offers a novel approach by focusing on the intrinsic properties of model representations rather than solely on prediction accuracy. It leverages information theory and geometric principles to quantify the efficiency of LLMs in eliminating redundant information during training. The core idea is to track the reduction in the effective rank (eRank) of the model’s internal representations, which is interpreted as a measure of ’noise reduction’. Diff-eRank computes the difference in eRank between an untrained and a trained model, effectively capturing the extent of information compression achieved through training. This makes it an interesting alternative to traditional metrics focusing on extrinsic performance. Importantly, the metric’s applicability extends to both uni-modal and multi-modal LLMs, allowing for a comprehensive evaluation of LLM capabilities.
LLM Evaluation#
The evaluation of Large Language Models (LLMs) is a rapidly evolving field, demanding innovative metrics beyond traditional accuracy measures. Current methods often focus on extrinsic evaluation, assessing performance on downstream tasks, neglecting the models’ internal mechanisms. Intrinsic evaluation, examining the models’ internal representations, offers a valuable complementary perspective. The paper proposes Diff-eRank, a novel rank-based metric for intrinsic evaluation. By analyzing the effective rank of hidden representations, Diff-eRank quantifies the model’s ability to eliminate redundant information, effectively measuring the degree of ’noise reduction’ during training. This approach moves beyond prediction-based metrics, providing insights into the LLM’s behavior and learning process. Diff-eRank’s effectiveness is validated through experiments on both uni-modal and multi-modal LLMs, demonstrating correlations with model size and conventional metrics. Furthermore, the paper introduces alignment evaluation methods for multi-modal models based on eRank. The overall contribution highlights the need for diverse evaluation approaches, with intrinsic metrics like Diff-eRank providing crucial insights into the effectiveness and efficiency of LLMs.
Multi-Modal Alignment#
Multi-modal alignment in large language models (LLMs) focuses on effectively integrating and aligning information from different modalities, such as text and images. A key challenge is ensuring that the model understands the relationships between these modalities and doesn’t treat them as isolated sources of information. Effective alignment is crucial for tasks like visual question answering, where the model needs to connect visual context with a textual question to generate a meaningful response. Approaches to evaluation often involve analyzing the model’s internal representations to assess the degree of alignment between modalities. Metrics might quantify the similarity or correlation between the feature spaces of different modalities after they have been encoded by the respective encoders. Furthermore, a well-aligned model should exhibit improved performance on downstream tasks that require cross-modal understanding. Research in this area explores various techniques, such as joint training of multiple encoders, attention mechanisms that allow interaction between modalities, and specialized architectural designs that promote alignment. The ultimate goal is a model that seamlessly integrates and leverages information from multiple modalities to achieve a more holistic and accurate representation of the world. This will enable LLMs to understand complex, real-world scenarios more effectively and accurately perform multi-modal tasks.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In this context, carefully designed ablation experiments would isolate different aspects of the proposed Diff-eRank metric and its evaluation methodology. For instance, one could examine the impact of using different rank approximation methods or explore the effect of varying dataset size or model architecture choices on the resulting Diff-eRank values. By carefully removing or altering specific parts of the process, researchers can gain a deeper understanding of which elements are essential for the success of the proposed metric. This would provide crucial insights into the robustness of the method and highlight which components significantly contribute to its performance or interpretability. Analyzing the effects of these changes would help determine whether the observed correlations between Diff-eRank and other metrics hold across various scenarios, ultimately strengthening the overall validity and reliability of the findings.
Future Research#
Future research directions stemming from this work on Diff-eRank could explore its application across diverse LLM architectures beyond the OPT family, examining its correlation with other intrinsic evaluation metrics. Investigating Diff-eRank’s behavior during various training phases, from early stages to fine-tuning, would provide crucial insights into its ability to track the learning process. Furthermore, research could focus on developing Diff-eRank variants tailored to specific downstream tasks or modalities, potentially enhancing its precision and interpretability. The strong alignment demonstrated with reduced loss suggests promising avenues for integrating Diff-eRank into training procedures, potentially enabling more efficient optimization. Finally, extending Diff-eRank to encompass a wider range of multi-modal models and datasets is essential to solidify its robustness and generalizability. These investigations will significantly advance our understanding of LLMs and inform the development of more effective evaluation metrics.
More visual insights#
More on figures
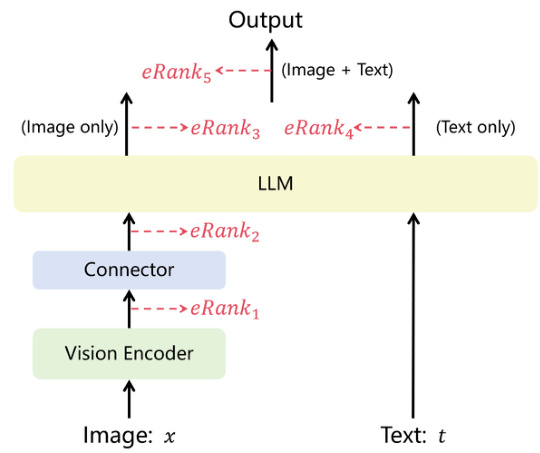
This figure illustrates how eRank is calculated for different stages of multi-modal large language model (MLLM) processing. It shows the flow of image and text data through a vision encoder, a connector, and an LLM. The eRank values (eRank1 to eRank5) represent the effective rank of the representations at each stage, providing a measure of the information contained within them. This allows for evaluation of the efficiency of information processing and modality alignment in MLLMs.

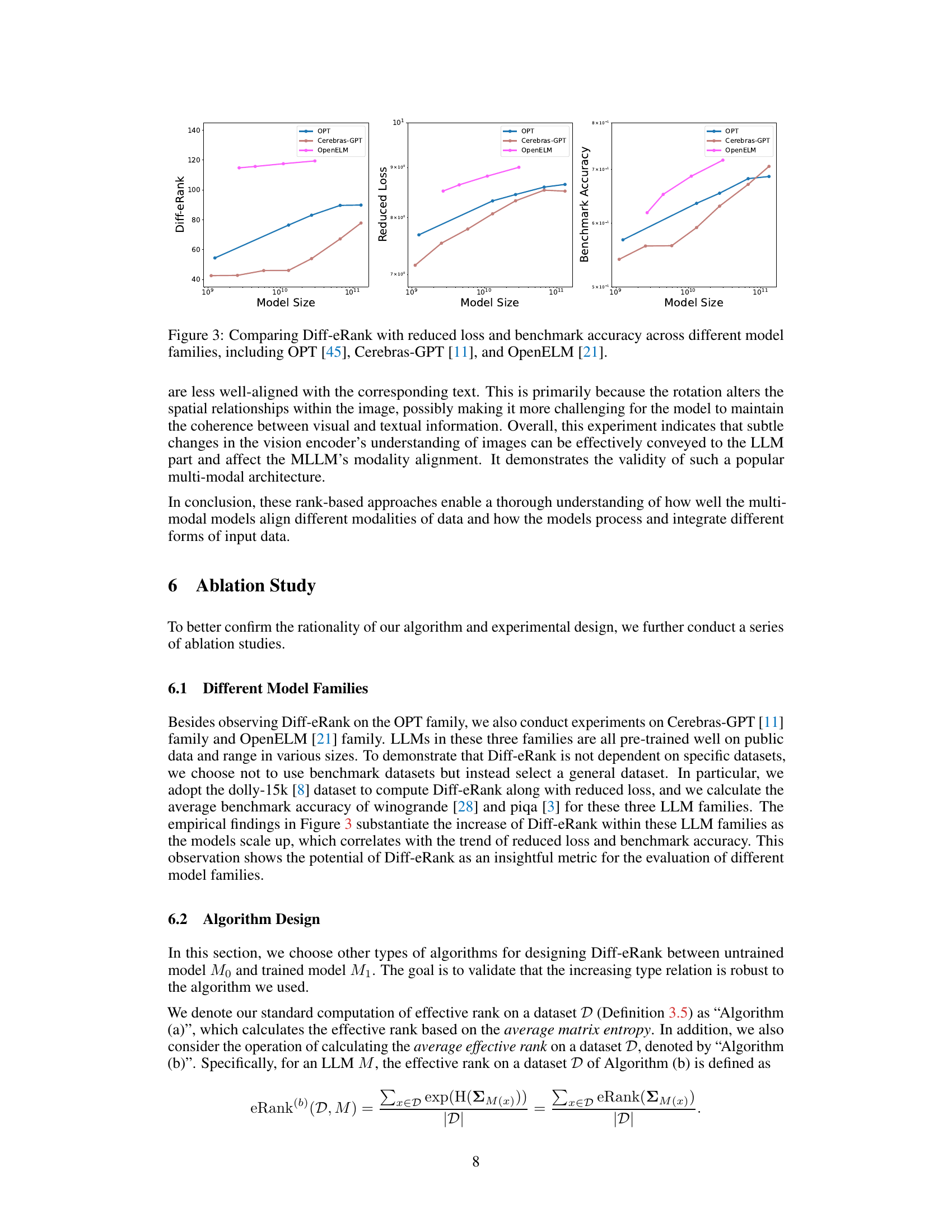
This figure compares the trends of Diff-eRank, reduced loss, and benchmark accuracy across different model sizes for three different language model families: OPT, Cerebras-GPT, and OpenELM. It visually demonstrates the correlation between the proposed Diff-eRank metric and conventional evaluation metrics (loss and accuracy) across various model architectures. The consistent upward trends across all three metrics suggest that Diff-eRank is a robust and meaningful evaluation metric, regardless of the specific model architecture.

This figure compares two different algorithms for calculating Diff-eRank, denoted as Algorithm (a) and Algorithm (b). Algorithm (a) calculates Diff-eRank based on the average matrix entropy across a dataset, while Algorithm (b) uses the average of the effective ranks of individual data samples in the dataset. The x-axis represents the model size and the y-axis represents the calculated Diff-eRank. Both algorithms show a similar trend with the increase in model size, suggesting that the increasing trend of Diff-eRank across different models is robust across various calculation methods. The results validate the reliability of the Diff-eRank metric.
More on tables
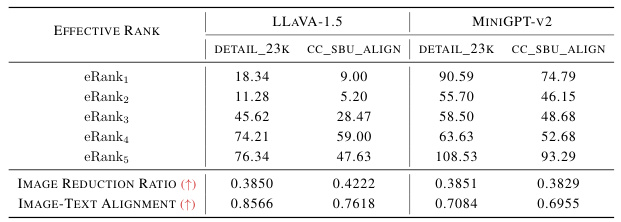
This table presents the results of evaluating two multi-modal large language models (MLLMs), LLaVA-1.5 and MiniGPT-v2, using two metrics based on effective rank (eRank): Image Reduction Ratio and Image-Text Alignment. Image Reduction Ratio quantifies the reduction in effective rank from the vision encoder output to the post-connector stage, indicating the efficiency of the connector network in processing visual information. Image-Text Alignment evaluates the closeness of effective ranks among different modalities (image, text, and image-text pairs) after LLM processing, reflecting the degree of modality alignment. The table shows the eRanks for various stages of image processing (vision encoder output, post-connector, and LLM output for images, text, and combined image-text pairs), along with the calculated Image Reduction Ratio and Image-Text Alignment scores for each model on two datasets: detail_23k and cc_sbu_align.

This table presents the results of an experiment where images were rotated clockwise. The experiment measured the effective rank (eRank) of image representations at different stages of processing in the LLaVA-1.5 model on the DETAIL_23k dataset. The ranks are shown for the vision encoder output (eRank1), post-connector representations (eRank2), and LLM representations of individual images (eRank3), text (eRank4), and image-text pairs (eRank5). Additionally, the Image Reduction Ratio and Image-Text Alignment metrics, which are based on these ranks, are shown to quantify the reduction in dimensionality and alignment between image and text modalities.
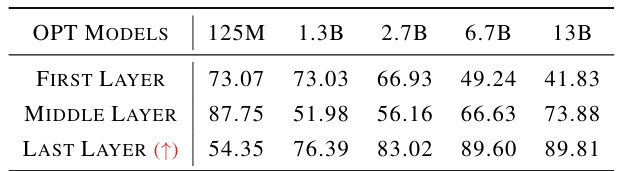
This table presents the Diff-eRank values calculated for different layers (first, middle, and last) of OPT models with varying sizes (125M, 1.3B, 2.7B, 6.7B, and 13B parameters). The results show that only the last layer exhibits a consistent increasing trend in Diff-eRank as the model size increases, suggesting that the last layer is the most informative for evaluating the model’s noise reduction ability using this metric.

This table presents the architectural differences between two prominent multi-modal large language models (MLLMs), LLaVA-1.5 and MiniGPT-v2. It details the specific vision encoder, connector type, and large language model (LLM) used in each architecture. The comparison highlights the variations in how these models integrate visual and textual information.

This table presents the results of evaluating various sized OPT language models across four different datasets: dolly-15k, Wikipedia, OpenWebText2, and HH-RLHF. For each dataset and model size, it shows two key metrics: Diff-eRank (an upward trend indicates stronger noise reduction) and ∆L (reduced cross-entropy loss, where an upward trend suggests better model performance). The table highlights the relationship between model size and these metrics, showing how both generally increase with model size across the different datasets.

This table presents a comparison of three metrics (Diff-eRank, reduced cross-entropy loss, and benchmark accuracy) across different sizes of OpenELM language models. It shows how these metrics change as model size increases, providing insights into the relationship between model size, internal representation efficiency (Diff-eRank), prediction quality (loss), and downstream task performance (accuracy).

This table presents a comparison of three metrics: Diff-eRank, reduced cross-entropy loss (ΔL), and benchmark accuracy (ACC) across different model sizes within the Cerebras-GPT family. It shows how these metrics change as the model size increases, indicating the relationship between model size, noise reduction ability, and performance on benchmark tasks. The upward trend in all three metrics suggests that larger models generally exhibit better performance, improved noise reduction, and lower loss.

This table compares the results of two different algorithms used for calculating Diff-eRank in the OPT model family. Algorithm (a) calculates the effective rank based on the average matrix entropy, while Algorithm (b) calculates the average effective rank. The table shows that Diff-eRank values consistently increase across model sizes irrespective of the algorithm used. This indicates that Diff-eRank is robust across different algorithms, strengthening its reliability as an evaluation metric.

This table presents the values of Diff-eRank, loss, and accuracy at different stages of training for a model. The training stages include a random initialization, initialization from a pre-trained OPT-1.3B model, fully trained model, and an overfitting model. The table demonstrates how these metrics change throughout the training process. These results help to show how Diff-eRank correlates with other standard evaluation metrics.

This table presents the results of an ablation study investigating the robustness of Diff-eRank to variations in sample size. Using the OPT-1.3B model, the study tests different sample sizes (10000, 5000, and 1000 data entries) from the Wikipedia dataset. The results show that Diff-eRank values remain relatively consistent despite the changes in sample size, demonstrating the stability of the metric even with varying sample sizes. The standard deviation highlights that fluctuations in sample size have an insignificant impact on Diff-eRank, underscoring the robustness of the methodology.
Full paper#