↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning (FL) faces challenges with non-IID and imbalanced data, especially when using entire pre-trained models for fine-tuning due to resource constraints. Prompt tuning, which optimizes a small set of input prefixes, offers a more efficient alternative but struggles with the heterogeneity and unalignment of prompts learned across different clients. Existing FL methods often fall short in such challenging scenarios.
This research introduces Probabilistic Federated Prompt Tuning (PFPT), a novel method that tackles these issues. PFPT models each local client’s prompt set as a random sample from a generative model parameterized by global prompts, enabling aligned prompt aggregation. It formulates prompt summarization as a probabilistic set modeling problem, substantially improving the performance over various baselines. Experiments on diverse datasets demonstrate PFPT’s effectiveness in combating extreme data heterogeneity and imbalance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning, particularly those working with heterogeneous and imbalanced datasets. It offers a novel solution to improve the efficiency and effectiveness of prompt-tuning, a technique that is gaining popularity for its ability to leverage pre-trained models without requiring large amounts of data. The proposed probabilistic framework opens new avenues for research in parameter-efficient federated learning and addresses limitations of existing methods. This research directly addresses the challenges of data heterogeneity and imbalance in federated learning, which are critical concerns in practical applications.
Visual Insights#
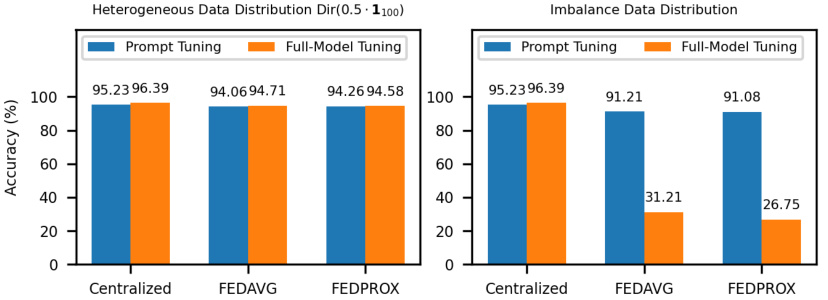
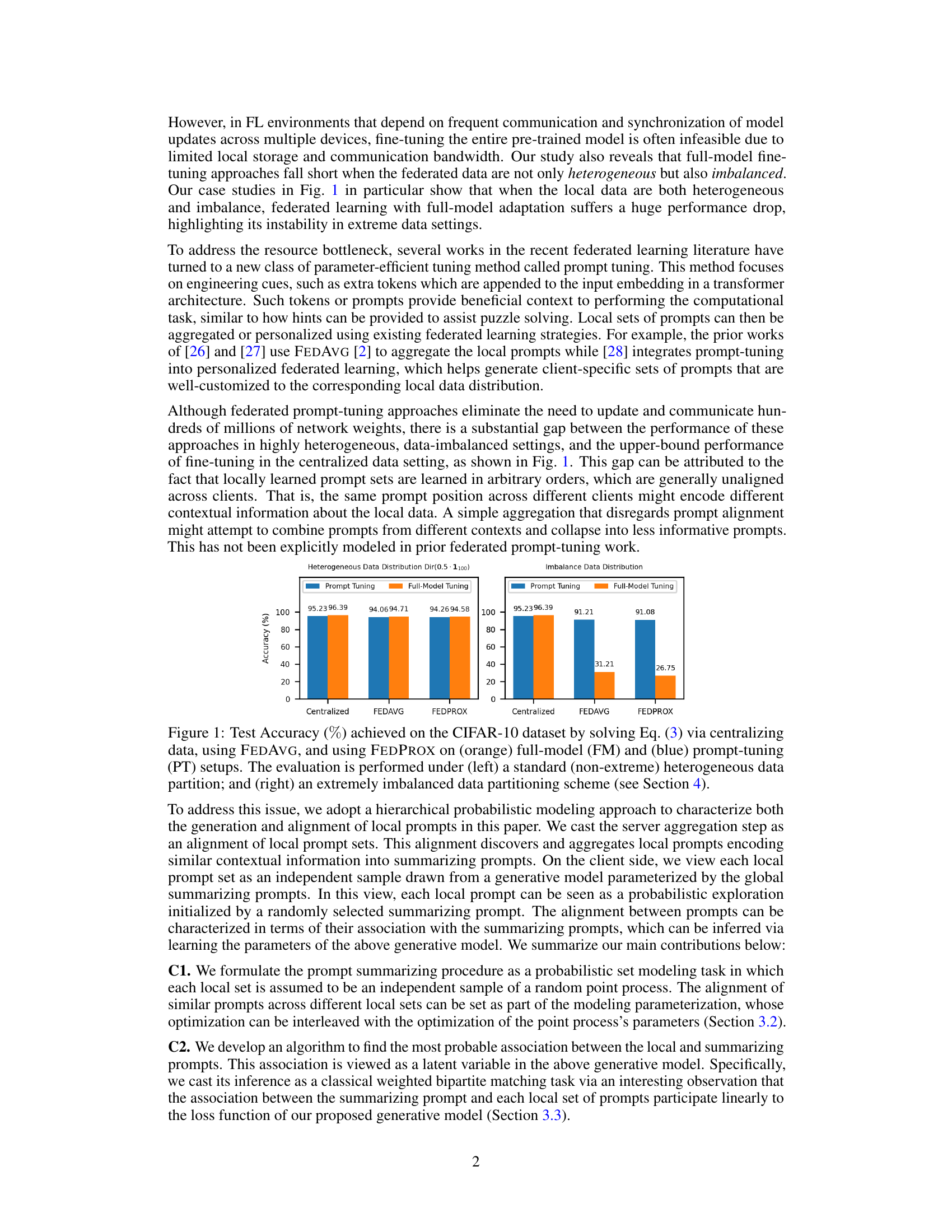
This figure presents the test accuracy achieved on the CIFAR-10 dataset using three different methods: centralized training, FEDAVG, and FEDPROX. Two training approaches are compared: full-model tuning and prompt tuning. The left panel shows results under a standard heterogeneous data partition, while the right panel shows results under an extremely imbalanced data partition. The figure highlights the significant performance drop of full-model tuning in the imbalanced setting, underscoring its instability in extreme data scenarios, while prompt tuning shows more resilience.

This table presents the classification accuracy achieved by different federated prompt-tuning methods on the CIFAR-10 dataset under various data distribution settings. The methods compared include FEDAVG-PT, FEDPROX-PT, SCAFFOLD-PT, FEDOPT-PT, PFEDPG, GMM-PT, and the proposed PFPT. The results are shown for three scenarios: data with Dirichlet distribution (α = 0.5 and α = 0.1) and imbalanced data. The table highlights the superior performance of the proposed PFPT method across all settings.
In-depth insights#
Prompt Tuning FL#
Prompt tuning in Federated Learning (FL) offers a compelling approach to enhance efficiency and privacy. Instead of fine-tuning the entire pre-trained model on each client’s data, prompt tuning optimizes a smaller set of input prompts, effectively reprogramming the model’s behavior. This significantly reduces communication overhead in FL, a crucial factor given the distributed nature of the data. The aggregation of prompts across clients becomes a key challenge, requiring sophisticated techniques to handle non-IID data and potential misalignment of prompt representations across devices. Probabilistic methods show potential for effective aggregation by modeling the diverse prompts as samples from a generative model, thus enabling a more robust and aligned global model. However, prompt tuning’s effectiveness hinges on the careful design of prompt aggregation strategies and their adaptability to diverse data distributions. Further research could explore novel prompt designs, more advanced aggregation techniques, and the interplay between prompt tuning and other FL personalization methods to unlock the full potential of this promising direction in federated learning.
Prob. Prompt Agg.#
The heading ‘Prob. Prompt Agg.’ likely refers to a probabilistic method for aggregating prompts in a federated learning setting. This suggests a departure from simpler averaging techniques by acknowledging the inherent diversity and potential noise in locally generated prompts. A probabilistic approach likely involves modeling the prompts as samples from a probability distribution, allowing for a more nuanced aggregation that considers uncertainty and variations across clients. This could involve sophisticated techniques like Bayesian methods or generative models to estimate a global representation of the prompts, capturing essential information while filtering out noise or inconsistencies. The probabilistic nature might improve robustness, especially given the challenges of non-IID and imbalanced data, by enabling the system to handle conflicting or unreliable prompt updates effectively. The method likely involves a probabilistic model to align the prompts across clients before aggregation, addressing the issue of arbitrary prompt ordering, thus improving the model’s global representation and performance.
Heterog. Data Tests#
In a federated learning setting, where data is distributed across multiple clients, handling heterogeneous data is crucial. Heterogeneous data refers to data that varies significantly in distribution and characteristics across clients. A robust federated learning system must be designed to accommodate this variability to ensure model accuracy and prevent bias. When assessing a federated learning approach, carefully designed tests are vital. These tests would evaluate model performance under diverse data distributions, measuring its robustness and fairness across different client data characteristics. Evaluation metrics might include accuracy, precision, recall, and fairness metrics such as equal opportunity and demographic parity, calculated separately for each client and overall. Experimental design should include various levels of data heterogeneity, such as differences in data size, class distribution imbalance, and feature representation. The analysis should investigate how well the model generalizes to unseen data and identifies any potential biases or limitations. Robustness against outliers and noisy data would also be a key aspect. Ultimately, comprehensive heterogeneous data testing provides valuable insights into a federated learning system’s reliability, fairness, and generalizability in real-world scenarios.
Imbalanced Data#
The concept of “imbalanced data” is critical in evaluating the robustness and generalizability of federated learning models, especially when dealing with diverse data distributions across multiple clients. Federated learning (FL) often struggles when local datasets exhibit significant class imbalances; for example, where one class heavily outweighs others. The paper highlights that this imbalance can severely impact model performance and can be exacerbated in federated settings. Standard model aggregation techniques may fail to effectively address the issue. The authors propose a method to combat this using probabilistic prompt aggregation, showing improved performance compared to other methods. However, the effectiveness of their approach on extremely imbalanced data requires further investigation. The challenge lies in designing techniques that effectively capture diverse and incomplete information from sources with varying levels of class representation. Future work should explore more sophisticated approaches to handling class imbalances within the context of prompt tuning and federated learning. The success of this research relies on the accurate representation and handling of information within highly heterogeneous, imbalanced local datasets to achieve a robust globally trained model.
Future Extensions#
Future research could explore several promising avenues. Extending the probabilistic framework to handle more complex data distributions beyond the Dirichlet and imbalanced scenarios is crucial. Investigating alternative prompt aggregation methods, potentially incorporating techniques from other machine learning fields, could lead to further performance improvements. A deeper analysis of the relationship between prompt diversity and model generalization in federated learning is needed. Exploring different pre-trained models and architectures would expand the applicability of the proposed approach. Finally, empirical evaluation on a wider range of real-world datasets and application domains is essential to demonstrate the robustness and generalizability of probabilistic federated prompt-tuning.
More visual insights#
More on figures
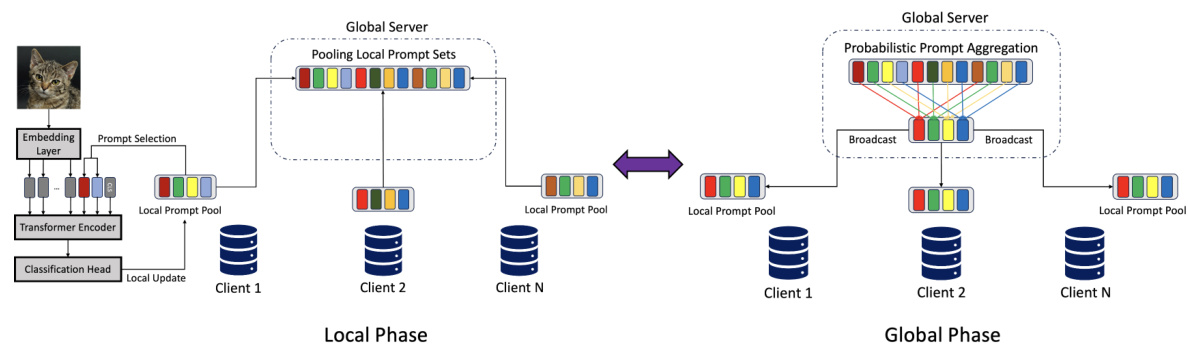
This figure illustrates the workflow of the Probabilistic Federated Prompt Aggregation (PFPT) algorithm. The left side shows the local phase where each client selects a subset of prompts from a global set, fine-tunes them using local data, and then sends the updated prompts to the server. The right side shows the global phase where the server aggregates the local prompt sets and updates the global summarizing prompts by using the PFPT algorithm, which then broadcasts the updated prompts back to the clients. This iterative process helps to combat data heterogeneity in federated learning.

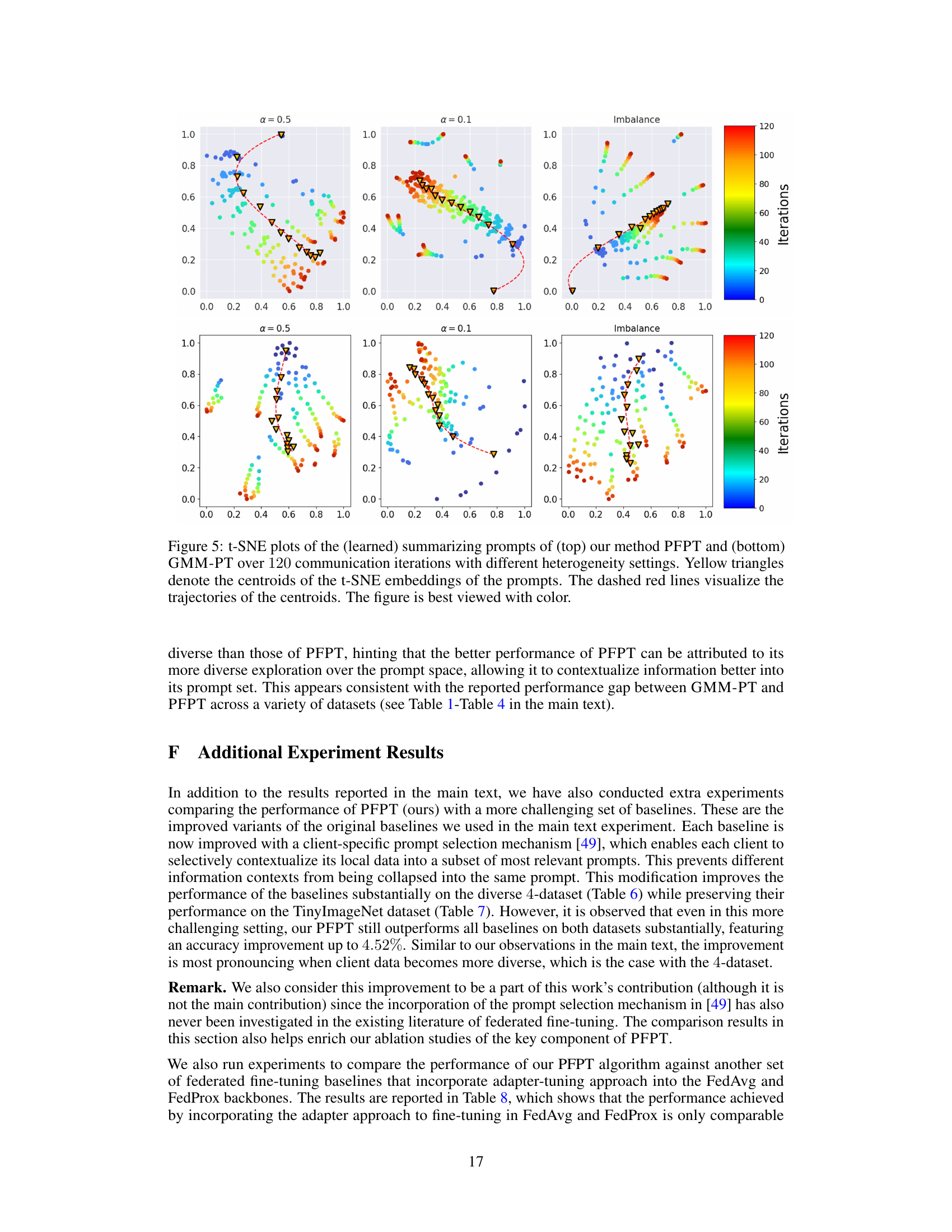
This figure visualizes the learned summarizing prompts’ movement over 120 communication rounds using t-SNE for dimensionality reduction. The plots show the trajectories of the prompts for three different data heterogeneity scenarios (α = 0.5, α = 0.1, and imbalanced data), as well as a centralized learning scenario (for comparison). The yellow triangles indicate the centroids of the prompts at various stages, and the dashed red lines trace their movement over time. The plots illustrate how the prompt distribution evolves as the model trains under different data conditions, offering insights into the prompt convergence and diversity in federated learning.

The figure shows the change in the number of global prompts used in CIFAR-100 experiments across 120 communication rounds under three different data heterogeneity settings (α = 0.5, α = 0.1, and imbalanced data). The shaded area represents the variability in the number of prompts. The plot demonstrates how the prompt pool size evolves over the course of federated learning, offering insights into the algorithm’s adaptation to varying data heterogeneity levels. The plot shows that with more data heterogeneity (lower α value), the prompt pool shrinks slower, which suggests that the heterogeneity requires more prompts to characterize the data.
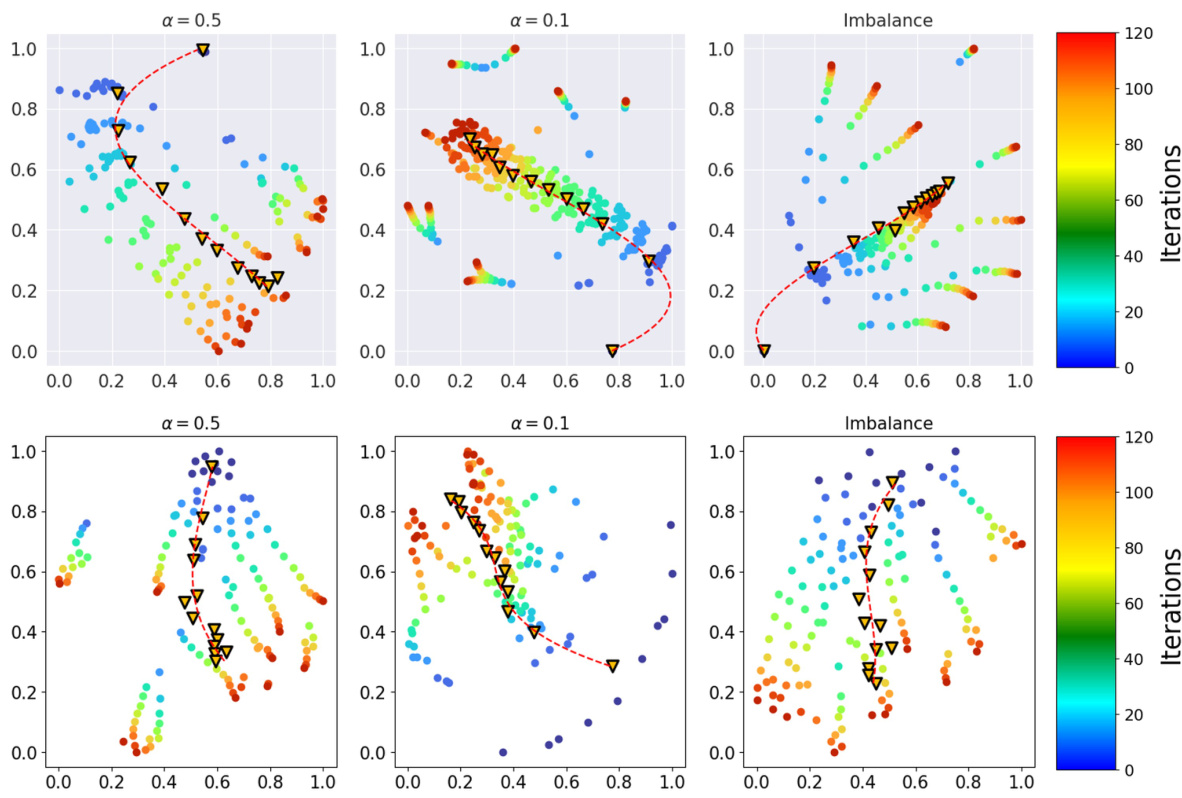
This figure visualizes the learned summarizing prompts’ movement over 120 communication rounds using t-SNE for dimensionality reduction. Three different data heterogeneity settings are shown, along with their centroids and trajectories. The plot helps understand how prompts evolve and diversify during training across various heterogeneity levels.
More on tables

This table presents the classification accuracy on CIFAR-100 dataset for different algorithms under three scenarios: data partition with α = 0.5, data partition with α = 0.1, and imbalanced data partition. The algorithms compared include FEDAVG-PT, FEDPROX-PT, SCAFFOLD-PT, FEDOPT-PT, PFEDPG-PT, GMM-PT, and the proposed PFPT. The results show the effectiveness of PFPT across different data heterogeneity levels.

This table presents the classification accuracy achieved by the proposed Probabilistic Federated Prompt Tuning (PFPT) method and several baseline methods on the TinyImageNet dataset under three different data partition scenarios: a setting with a Dirichlet distribution parameter α = 0.5, another with α = 0.1, and a highly imbalanced data setting. The results show the average accuracy and standard deviation over five independent runs. The table compares PFPT’s performance against baselines such as FEDAVG-PT, FEDPROX-PT, SCAFFOLD-PT, FEDOPT-PT, PFEDPG, and GMM-PT.

This table presents the classification accuracy achieved by different federated prompt-tuning methods on a synthetic dataset combining MNIST-M, Fashion-MNIST, CINIC-10, and MMAFEDB. The results are shown for three different data distributions: Dirichlet distribution with α = 0.5, Dirichlet distribution with α = 0.1, and an imbalanced distribution. The table compares the performance of PFPT (the proposed method) against several baseline methods, including FEDAVG-PT, FEDPROX-PT, SCAFFOLD-PT, FEDOPT-PT, PFEDPG, and GMM-PT.

This table shows the accuracy achieved by PFPT and two other state-of-the-art methods (CREFF and FEDIC) on long-tailed versions of CIFAR-100 and ImageNet datasets. The long-tailed datasets are created using an imbalance factor (IF) which controls the skew in the class distribution. The results demonstrate PFPT’s superiority in handling imbalanced data, especially with high IF values, highlighting its robustness and effectiveness compared to existing approaches.

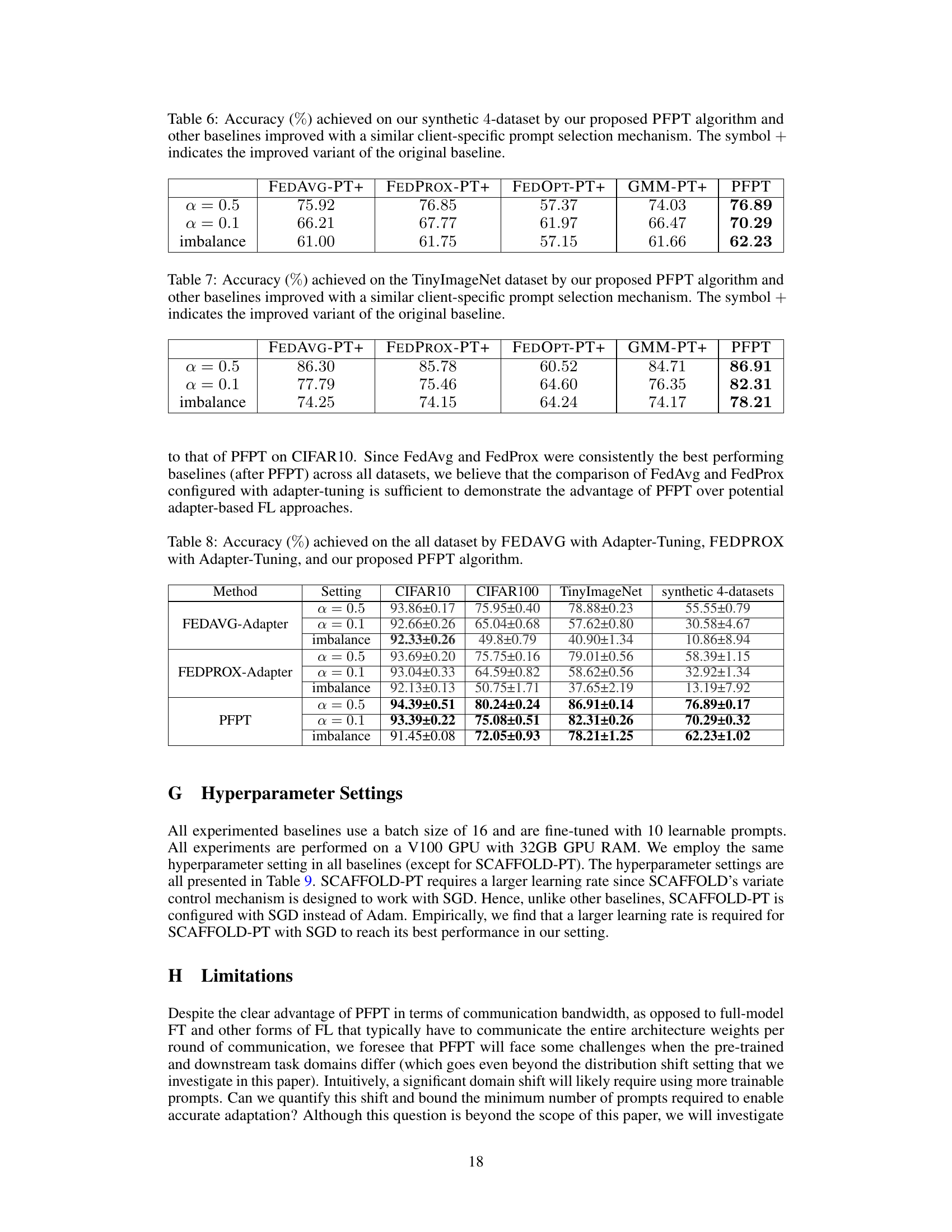
This table compares the performance of the proposed PFPT algorithm against other baseline algorithms on a synthetic 4-dataset. The baselines have been improved by incorporating a client-specific prompt selection mechanism. The table shows the accuracy achieved under different data distribution scenarios (α = 0.5, α = 0.1, and imbalance). The results demonstrate the superior performance of PFPT across all scenarios.

This table shows the accuracy achieved by different federated prompt tuning methods on the TinyImageNet dataset. The baselines (FEDAVG-PT, FEDPROX-PT, FEDOPT-PT, GMM-PT) have been improved by incorporating a client-specific prompt selection mechanism. The results demonstrate the superior performance of the proposed PFPT (Probabilistic Federated Prompt Tuning) algorithm across different data heterogeneity levels (α = 0.5, α = 0.1, and imbalanced).
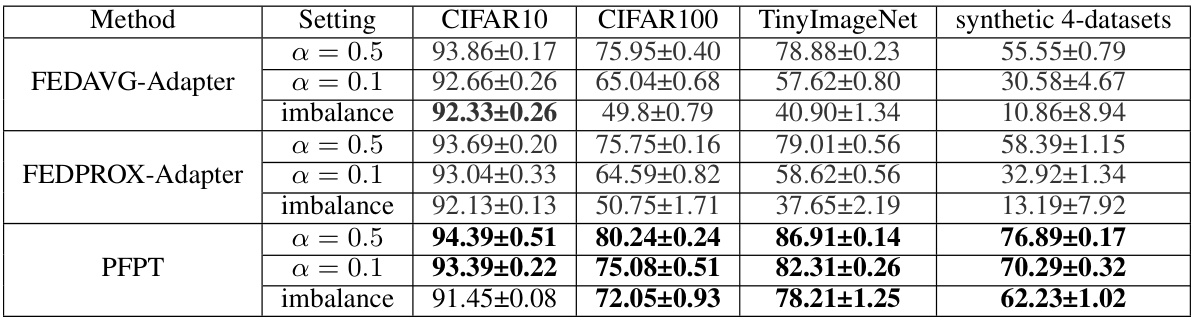
This table compares the performance of PFPT against two other federated learning methods (FEDAVG and FEDPROX) that incorporate adapter-tuning. The results are reported for three different data settings (α = 0.5, α = 0.1, and imbalance) and four datasets (CIFAR10, CIFAR100, TinyImageNet, and a synthetic 4-dataset). The table shows that PFPT consistently outperforms the adapter-tuning methods across all settings and datasets, demonstrating its effectiveness in handling non-IID data and data imbalance.
This table shows the accuracy achieved on the CIFAR-10 dataset using different federated prompt-tuning methods, including the proposed PFPT method and several baselines under different data heterogeneity settings (controlled by the Dirichlet parameter α and data imbalance). The results highlight the superior performance of PFPT, particularly when dealing with extreme data heterogeneity.
Full paper#