↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large vision-language models (LVLMs) often suffer from ‘hallucinations,’ generating outputs that contradict the input image. Existing solutions are resource-intensive, relying on human annotations or extra models to fine-tune LVLMs. These curated preferences can be easily distinguishable by the target LVLM, hence reducing their effectiveness.
This paper introduces Calibrated Self-Rewarding (CSR), a novel iterative approach for enhancing modality alignment in LVLMs. CSR enables self-improvement by iteratively generating candidate responses, evaluating rewards using visual constraints, and refining preferences for fine-tuning. This approach enhances performance, minimizes hallucinations, and demonstrates compatibility across multiple VLM architectures, overcoming the limitations of existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on vision-language models (VLMs) because it directly addresses the prevalent issue of hallucinations, where the model’s output contradicts the input image. The proposed Calibrated Self-Rewarding (CSR) approach offers a novel solution that doesn’t rely on expensive human annotations or external models, enhancing the efficiency and effectiveness of VLM development. The theoretical analysis provides further support for the method’s effectiveness, opening avenues for future improvements in model alignment and reliability. The availability of code and data promotes broader adoption and further research.
Visual Insights#

This radar chart visualizes the performance comparison of CSR against several baseline methods across ten benchmark datasets. Each axis represents a benchmark, and the values indicate the performance scores. The chart effectively shows CSR’s improvement over baseline methods across various tasks and its strength in achieving modality alignment.

This table presents a comparison of the performance of the Calibrated Self-Rewarding (CSR) method on the LLaVA-1.5 model against various baselines across multiple benchmarks. The benchmarks cover a range of tasks, including comprehensive benchmarks assessing various aspects of multimodal reasoning, general VQA (Visual Question Answering) tasks, and hallucination benchmarks evaluating the model’s tendency to generate factually incorrect or hallucinatory outputs. The baselines represent different approaches to improving modality alignment in vision-language models, including methods leveraging human feedback, reinforcement learning, and other self-rewarding techniques. The table allows for a comprehensive comparison of the effectiveness of CSR in improving the overall performance and reducing hallucinations of LLaVA-1.5 compared to existing state-of-the-art methods.
In-depth insights#
CSR: Core Idea#
The core idea behind Calibrated Self-Rewarding (CSR) for vision-language models is to improve modality alignment by enabling the model to iteratively refine its own preferences. Unlike methods relying on external data or models, CSR leverages a self-rewarding paradigm incorporating visual constraints. This involves a step-wise reward modeling process that combines self-generated instruction-following scores with image-response relevance scores, ensuring visual input is prioritized. The iterative nature of CSR allows for continuous improvement, generating preferences and fine-tuning the model to reduce hallucinations and enhance alignment between image and text. This self-improvement, guided by the calibrated reward scores, is a key distinction from other preference optimization approaches. The theoretical analysis supports the effectiveness of this visual constraint integration.
Visual Calibration#
Visual calibration, in the context of vision-language models, is a crucial technique to bridge the gap between visual and textual modalities. It addresses the issue of models prioritizing textual information over visual input, leading to hallucinations where generated text contradicts the image. Effective visual calibration methods would incorporate visual features directly into the reward mechanism during training or inference. This might involve using visual similarity metrics to compare generated descriptions with the input image, or by incorporating visual attention mechanisms to ensure the model focuses on relevant visual details. A well-calibrated model would exhibit improved accuracy, reduced hallucinations, and more faithful representation of the image content in its textual output. The core challenge is finding appropriate visual features and designing effective integration methods that don’t overwhelm the language model’s capabilities. Successful visual calibration will ultimately lead to more robust and reliable vision-language models.
Iterative Tuning#
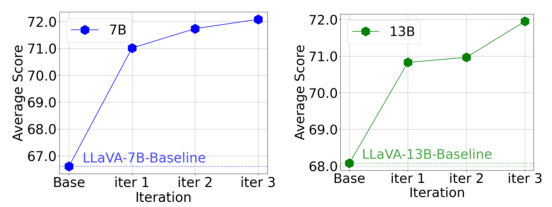
Iterative tuning, in the context of large vision-language models (LVLMs), represents a powerful paradigm shift towards self-improvement. Instead of relying on static datasets or external evaluations, iterative tuning leverages the model’s own internal reward mechanism. The process begins by generating candidate responses, evaluating each against a reward function that incorporates visual constraints, and iteratively refining the model using the generated preferences. Visual constraints are crucial, addressing the inherent modality misalignment challenges in LVLMs. This iterative approach, unlike methods dependent on external preference data, directly reflects the target LVLMs internal preferences, enabling more effective self-calibration and reducing hallucination. The step-wise reward modeling enhances robustness and precision in feedback, making each adjustment refined and informed. The resulting model exhibits continuously enhanced performance over iterations, showcasing the strength of the iterative tuning paradigm in fostering modality alignment and improved factual accuracy in LVLMs.
Benchmark Results#
The benchmark results section of a research paper is crucial for evaluating the performance of a proposed method. A strong benchmark section will present results across a variety of established benchmarks, comparing the proposed model against relevant baselines. Clear visualizations, such as tables and charts, are essential for presenting the results effectively, highlighting improvements and areas where the model excels or underperforms. Statistical significance should be meticulously reported to ensure the reported gains are not merely due to chance. The choice of benchmarks should be carefully justified, selecting tasks that are relevant and challenging. A comprehensive discussion of the results is needed, analyzing strengths and limitations, addressing discrepancies and potential reasons for unexpected results. Furthermore, the authors should reflect on whether the benchmarks appropriately capture all aspects of the model’s capabilities. A thorough analysis of benchmark results significantly enhances the credibility and impact of a research paper.
Future of CSR#
The future of Calibrated Self-Rewarding (CSR) in vision-language models looks promising, given its demonstrated ability to significantly reduce hallucinations and improve modality alignment. Further research should focus on scaling CSR to larger models and datasets, potentially leveraging more efficient training techniques like LoRA. Investigating the theoretical underpinnings of CSR more deeply, particularly regarding the impact of hyperparameters like lambda on performance, is crucial. Exploration into the generalizability of CSR across diverse vision-language model architectures and benchmark tasks is needed to establish its robustness. Finally, research examining the ethical implications and potential biases of self-rewarding mechanisms within CSR is paramount to ensure responsible development and deployment.
More visual insights#
More on figures
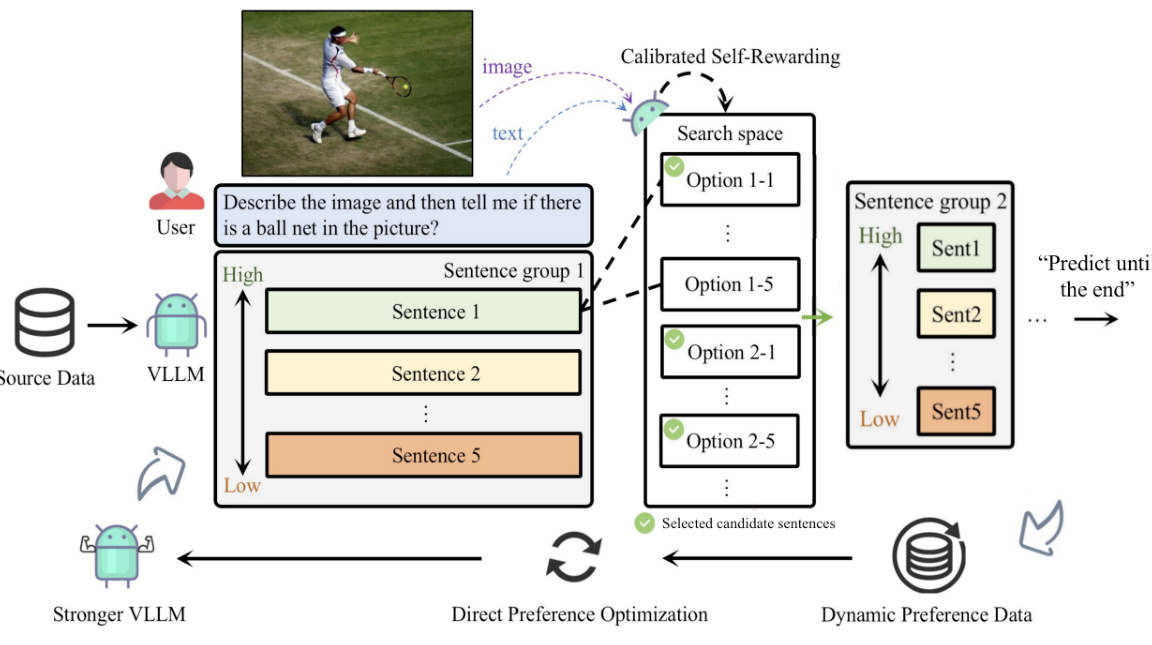
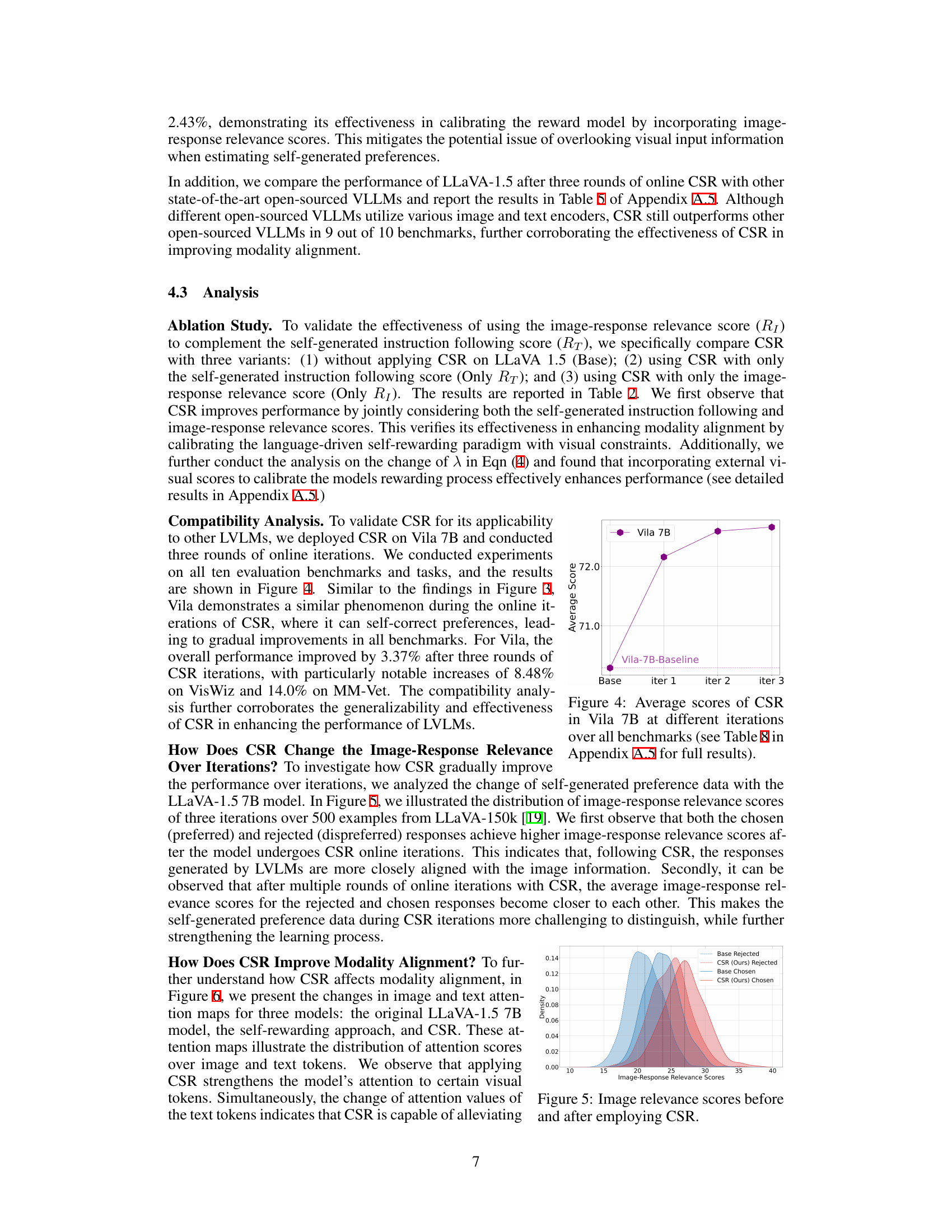
This figure illustrates the iterative process of the Calibrated Self-Rewarding (CSR) framework. It begins with user input (image and text prompt) fed into a Vision-Language Model (VLLM). The VLLM uses sentence-level beam search to generate candidate sentences, each receiving an initial reward score. This score is then calibrated using image-relevance information. The sentences with the highest and lowest cumulative calibrated reward scores are selected as preferred and dispreferred responses, respectively. This preference data is then used to fine-tune the VLLM in the next iteration, improving the model’s performance over time.
This figure compares the performance of the proposed Calibrated Self-Rewarding (CSR) approach with other state-of-the-art methods across various benchmark datasets. The results are presented in a radar chart format, allowing for a visual comparison of the methods’ performance across multiple evaluation metrics. Each axis of the radar chart represents a different benchmark dataset (e.g., MME, SEED, LLaVAW, MMB, MM-Vet, SQA, VisWiz, GQA, POPE, CHAIRS, CHAIR1), and the distance from the center of the chart to each point represents the performance score on that specific dataset. The chart visually demonstrates the improvement achieved by the CSR method over existing methods.

This figure shows a radar chart comparing the performance of the proposed Calibrated Self-Rewarding (CSR) approach with several baseline methods across various benchmark datasets. Each axis represents a different benchmark, and the values show the performance score achieved by each method on that benchmark. CSR outperforms the baselines in most of the benchmarks, demonstrating its effectiveness in improving modality alignment in large vision-language models.

This figure presents a radar chart comparing the performance of the proposed Calibrated Self-Rewarding (CSR) approach with several baseline methods across various vision-language benchmarks. Each axis represents a different benchmark or task (e.g., MME, SEED, LLaVAW, etc.), and the radial distance from the center indicates the performance score achieved by each method on that specific benchmark. The CSR method demonstrates superior performance across most of the benchmarks, highlighting its effectiveness in enhancing modality alignment and reducing hallucinations in vision-language models.
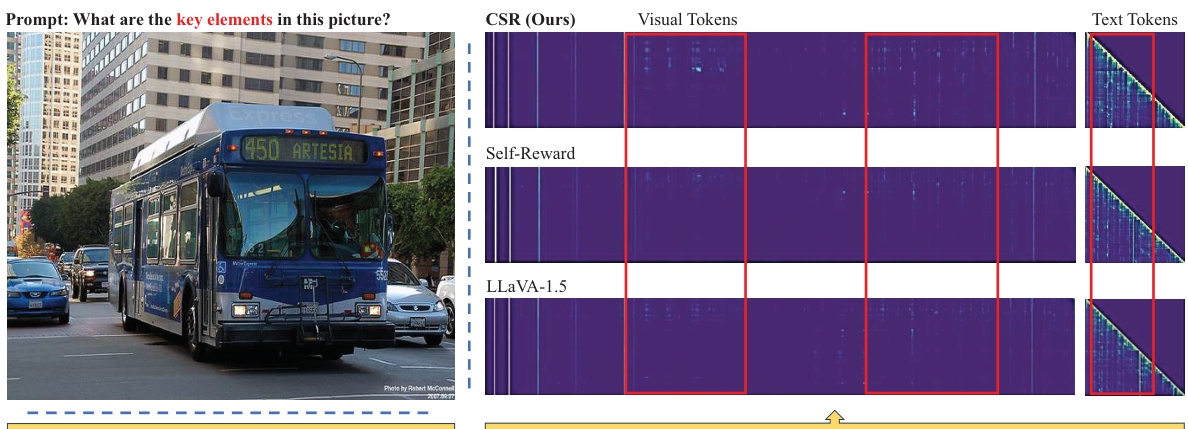
This figure illustrates the iterative process of the Calibrated Self-Rewarding (CSR) framework. It shows how CSR generates candidate responses sentence by sentence using beam search, assigning a calibrated reward (combining self-generated and image-relevance scores) to each sentence. The highest and lowest cumulative reward responses are selected as preferred and dispreferred, respectively, to create preference data for fine-tuning the model in the next iteration. This iterative process leads to continuous model improvement.

This figure compares the performance of the proposed CSR method against several baseline and state-of-the-art methods across various vision-language benchmarks. It visually represents the relative improvements achieved by CSR in terms of accuracy and other relevant metrics. The benchmarks shown include comprehensive benchmarks (MME, SEEDbench, LLaVAW, MMbench, MM-Vet), general VQA (ScienceQA, VisWiz, GQA), and hallucination benchmarks (POPE, CHAIR). The radar chart format allows for a quick comparison of performance across multiple tasks.

This figure presents a radar chart comparing the performance of the proposed Calibrated Self-Rewarding (CSR) approach with several baselines across various vision-language benchmarks. Each axis represents a different benchmark (e.g., MME, SEED, LLaVAW, etc.), and the radial distance from the center indicates the performance score on that benchmark. The chart visually demonstrates the superior performance of CSR compared to other methods, highlighting its effectiveness in improving modality alignment and reducing hallucinations in vision-language models.

This figure shows a radar chart comparing the performance of the proposed Calibrated Self-Rewarding (CSR) approach with several baselines across ten benchmarks. Each benchmark is represented by an axis, and the performance of each method is represented by a point on that axis. The further the point is from the center, the better the performance. The chart visually demonstrates that CSR outperforms the existing state-of-the-art methods, achieving substantial improvements in performance across all benchmarks.
More on tables
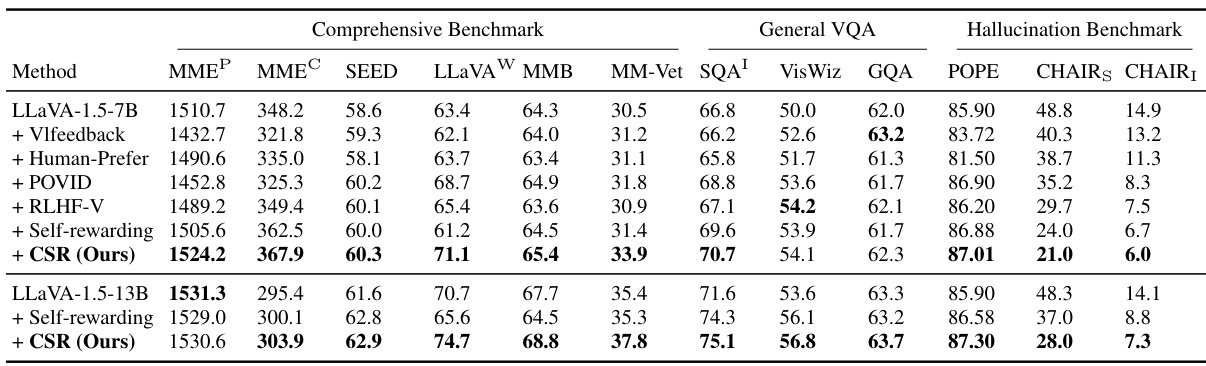
This table presents a comparison of the performance of the Calibrated Self-Rewarding (CSR) method on the LLaVA-1.5 model across various benchmarks. It shows the results for CSR and several baseline methods, including methods using human feedback, additional models, and other self-rewarding approaches. The benchmarks cover several aspects of vision-language model performance, including comprehensive benchmarks (measuring overall capabilities), general VQA (visual question answering), and hallucination benchmarks (assessing the tendency to generate inaccurate or nonsensical responses). The table allows for a quantitative assessment of how CSR improves upon existing methods in terms of accuracy and reducing hallucination.

This table presents the ablation study results, comparing the performance of the proposed CSR method against three variants: the baseline (Base) without CSR, CSR using only the self-generated instruction-following score (Only RT), and CSR using only the image-response relevance score (Only R1). The results show the effectiveness of integrating both scores in CSR for improved model performance, particularly highlighting the contribution of the image-response relevance score.

This table presents a comparison of the performance of the Calibrated Self-Rewarding (CSR) method on the LLaVA-1.5 model across various benchmarks. It compares CSR to several baseline methods, including those using human feedback, preference optimization, and other self-rewarding techniques. The benchmarks cover comprehensive evaluations, general Visual Question Answering (VQA) tasks, and hallucination metrics. The table shows the improvements achieved by CSR in terms of various performance metrics across all benchmark types.

This table presents a comprehensive comparison of the performance of the Calibrated Self-Rewarding (CSR) model against various baseline methods across a range of benchmarks. These benchmarks assess different aspects of vision-language model capabilities, encompassing comprehensive evaluations, general visual question answering (VQA), and hallucination detection. The results demonstrate the improvement achieved by CSR over existing approaches in terms of accuracy and reducing hallucinatory responses.

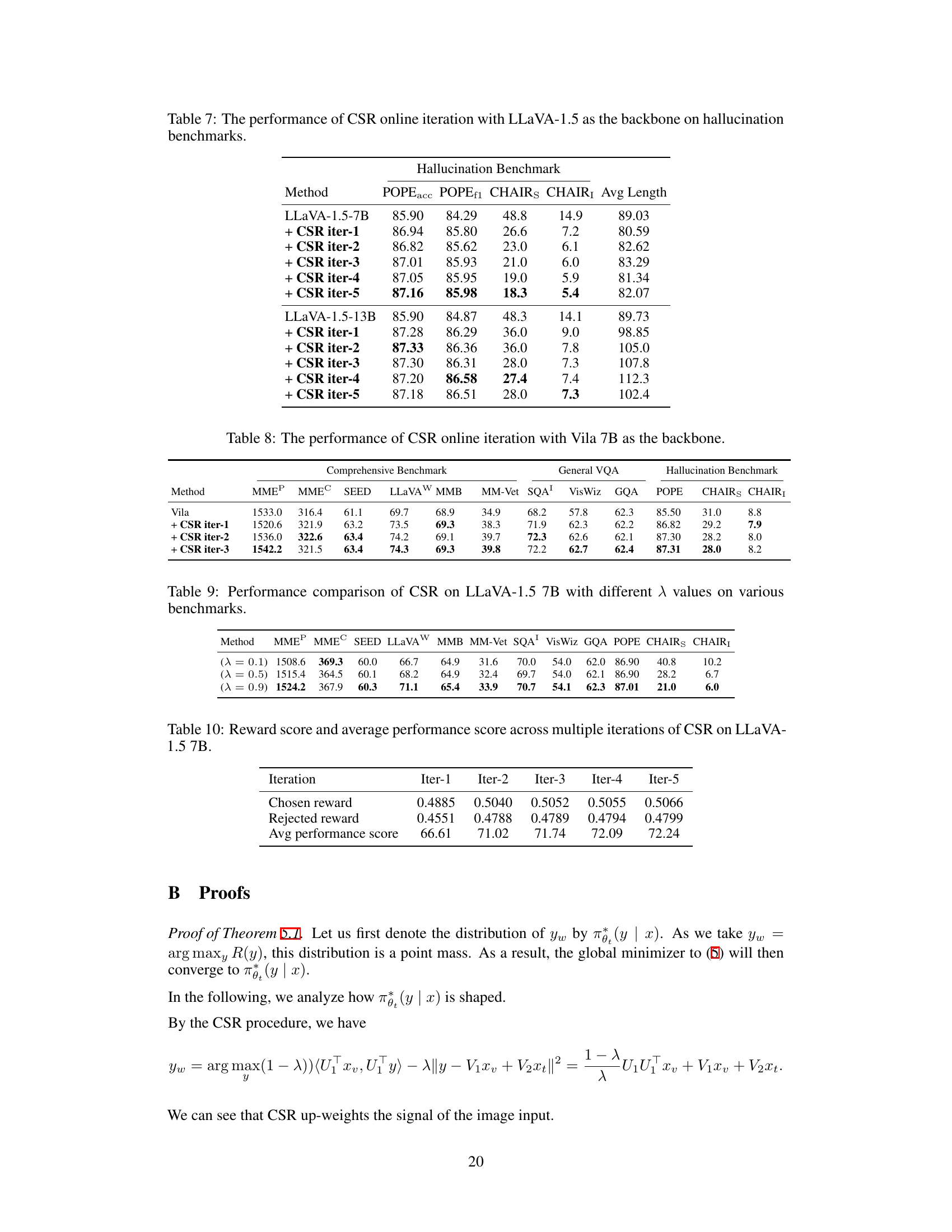
This table presents the results of the Calibrated Self-Rewarding (CSR) approach on hallucination benchmarks, using LLaVA-1.5 as the base model. It shows the performance metrics (POPEacc, POPEf1, CHAIRS, CHAIR1, and Avg Length) across multiple iterations of CSR. The results demonstrate the iterative improvement in reducing hallucinations over several iterations of the CSR process. Each row represents a different stage (iteration) of training.

This table presents the performance of the Calibrated Self-Rewarding (CSR) approach, specifically after three iterations, using the Vila 7B model. It shows the model’s scores across various benchmarks, categorized into Comprehensive Benchmark, General VQA, and Hallucination Benchmark. Each category includes multiple metrics, providing a comprehensive evaluation of the model’s performance after undergoing the iterative CSR process. The table allows for a comparison of the model’s performance before (baseline) and after the CSR iterations, showcasing the impact of the method.

This table presents the results of an ablation study on the hyperparameter λ used in the Calibrated Self-Rewarding (CSR) approach. The study varies the value of λ (which balances the self-generated instruction-following score and image-response relevance score) and evaluates the impact on various LVLMs benchmarks (MMEP, MMEC, SEED, LLAVAW, MMB, MM-Vet, SQA, VisWiz, GQA, POPE, CHAIRS, CHAIR1). The table shows how different values of λ affect the performance on each benchmark, illustrating the importance of calibrating the reward score to improve modality alignment in LVLMs.

This table shows the reward scores for chosen and rejected responses, as well as the average performance score across five iterations of the Calibrated Self-Rewarding (CSR) method. The data demonstrates the iterative improvement in model performance as the CSR process continues.
Full paper#