TL;DR#
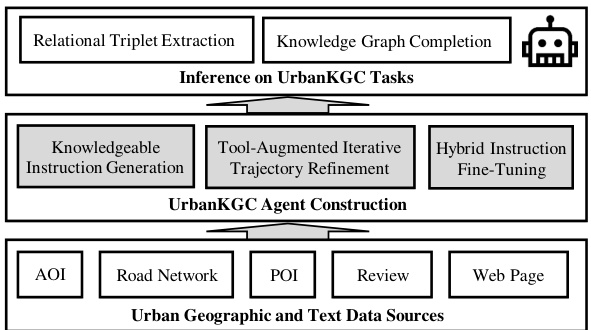
Building comprehensive urban knowledge graphs (UKGs) is challenging due to the heterogeneity of urban data and the limitations of existing manual methods. These UKGs are vital for diverse smart city applications, but their construction is laborious and inefficient. Current approaches often rely heavily on manual efforts, hindering their potential.
UrbanKGent tackles this challenge by introducing a unified large language model (LLM) agent framework. This framework uses a knowledgeable instruction set to guide the LLM, incorporates a tool-augmented iterative trajectory refinement module to enhance geospatial reasoning, and employs hybrid instruction fine-tuning for improved performance. This approach significantly outperforms existing methods in both accuracy and efficiency, enabling the construction of richer and more comprehensive UKGs with drastically reduced data requirements.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on knowledge graph construction, especially within the urban domain. It presents a novel framework that significantly improves the efficiency and scalability of building urban knowledge graphs, which has significant implications for various smart city applications. The unified large language model agent approach and innovative methods for handling heterogeneous urban data offer valuable insights and a new direction for future research.
Visual Insights#

🔼 This figure shows two examples highlighting the limitations of LLMs in UrbanKGC tasks. The first (a) demonstrates how LLMs struggle to understand heterogeneous relationships (e.g., spatial, temporal, and functional) in relational triplet extraction without the injection of prior knowledge. The second (b) illustrates how the limited geospatial reasoning capabilities of LLMs hinder accurate knowledge graph completion, emphasizing the need for integrating external geospatial tools for enhanced performance.
read the caption
Figure 1: Illustrative example of urban relational triplet extraction and knowledge graph completion. (a) The heterogeneous relationship understanding limitation of LLMs can be addressed by injecting prior urban knowledge into instruction. (b) The geospatial computing limitation of LLMs can be alleviated by invoking external geospatial tools.
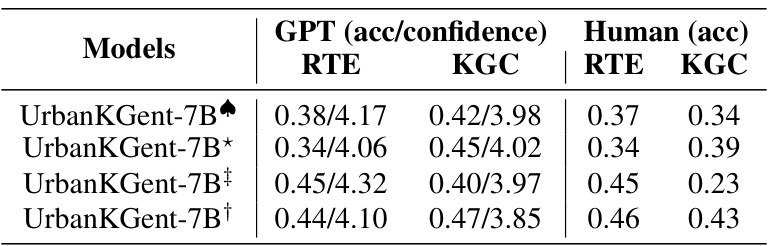
🔼 This table presents the main results of the relational triplet extraction and knowledge graph completion tasks. It compares the performance of the proposed UrbanKGent model against 31 baseline methods across two datasets (NYC and CHI). Both GPT-4-based evaluation and human evaluation are provided for comparison. The accuracy and confidence levels are shown for GPT-4, while accuracy is given for human evaluation. The best-performing baseline model is underlined for each task and dataset.
read the caption
Table 3: The main results of relational triplet extraction (RTE) and knowledge graph completion (KGC). We report the accuracy (acc) and confidence for GPT evaluation on two datasets, and report accuracy (acc) for the Human evaluation approach. The best baseline performance is underlined.
In-depth insights#
UrbanKGent Framework#
The UrbanKGent framework represents a novel approach to constructing urban knowledge graphs (UKGs). Its core innovation lies in leveraging large language models (LLMs) as agents to automate the traditionally manual and labor-intensive UKG creation process. This framework addresses the limitations of existing methods by incorporating heterogeneity-aware instruction generation, which tailors LLM prompts to the nuances of urban data (spatial, temporal, and functional aspects). Furthermore, it utilizes a tool-augmented iterative trajectory refinement module to enhance the LLMs’ reasoning capabilities, particularly in handling geospatial relationships. This involves incorporating external geospatial tools and a self-refinement mechanism to improve accuracy and address the limitations of LLMs in numerical computation. The resulting UrbanKGent family of models demonstrates significant improvements over existing baselines in both relational triplet extraction and knowledge graph completion tasks. Cost-effectiveness is a major advantage, achieving state-of-the-art performance at a fraction of the cost of traditional approaches.
LLM Agent Design#
Designing effective Large Language Model (LLM) agents for knowledge graph construction necessitates a multifaceted approach. Knowledgeable instruction generation is crucial, tailoring prompts to leverage the LLM’s strengths while mitigating its weaknesses in handling heterogeneous urban data. This involves carefully crafting instructions that incorporate spatial, temporal, and functional aspects of urban information. Furthermore, tool augmentation is vital; integrating external geospatial tools enables the agent to perform complex calculations and reasoning beyond the LLM’s inherent capabilities. The iterative process of trajectory refinement is key, allowing for continuous improvement and correction of the agent’s reasoning through self-evaluation and feedback mechanisms. Hybrid instruction fine-tuning offers a powerful method to optimize the agent’s performance on specific Urban Knowledge Graph Construction (UKGC) tasks by leveraging the strengths of both large and smaller LLMs. Ultimately, a successful LLM agent design strikes a balance between leveraging the power of LLMs and addressing their limitations through thoughtful prompting engineering and tool integration, thereby achieving efficient and accurate UKGC.
Hybrid Instruction Tuning#
Hybrid instruction fine-tuning is a crucial technique used to adapt large language models (LLMs) for specific tasks like urban knowledge graph construction. It leverages the strengths of both knowledgeable instructions and refined trajectories to effectively enhance the model’s performance. Knowledgeable instructions, crafted by incorporating heterogeneous urban data and geospatial information, guide the LLM to understand the task’s nuances. Refined trajectories, generated through an iterative process of GPT-4 prompting and tool-augmentation, provide step-by-step reasoning examples. The hybrid approach combines these instructions and trajectories during fine-tuning, enabling efficient learning and overcoming LLMs’ limitations in heterogeneous relationship understanding and geospatial reasoning. This method significantly improves the model’s accuracy and efficiency compared to other approaches, making it a valuable contribution to the field of knowledge graph construction. The hybrid approach represents a powerful strategy for tailoring LLMs to diverse, complex tasks, demonstrating the potential of combining different techniques for optimal performance.
UrbanKG Construction#
The creation of Urban Knowledge Graphs (UrbanKGs) presents a unique set of challenges. Data acquisition is crucial, demanding the integration of diverse sources like geographic data (AOIs, road networks, POIs), textual information (reviews, web pages), and potentially sensor data. Data preprocessing is equally important, requiring careful cleaning, normalization, and standardization to ensure data quality. Knowledge representation is a significant consideration, involving the selection of appropriate ontologies and the formalization of relationships between entities. The core process then involves knowledge extraction from the heterogeneous data sources, often requiring Natural Language Processing (NLP) techniques and potentially geographic information systems (GIS) methods. Finally, the process culminates in the construction of the UrbanKG, typically represented as a graph database, and the subsequent validation and evaluation of the graph’s completeness and accuracy.
Future Work#
The future work section of this research paper presents exciting avenues for enhancing UrbanKGent. Addressing the limitations of relying solely on textual data is crucial; incorporating diverse data modalities like imagery and sensor data would significantly enrich the UrbanKG and improve model performance. Improving the efficiency of the tool-augmented iterative refinement process is another key area. Exploring more efficient tool integration and potentially developing custom tools tailored to specific UrbanKGC tasks could enhance performance and reduce computational costs. Expanding the scope of UrbanKGent to encompass a wider range of urban phenomena beyond the initial focus areas is important. This could involve tasks related to urban planning, sustainability, and social dynamics. Finally, rigorous testing and validation of UrbanKGent’s performance in various real-world scenarios is essential to demonstrate its practical applicability. This requires larger-scale datasets and collaborations with city authorities to evaluate the model’s utility and effectiveness in solving real urban challenges.
More visual insights#
More on figures

🔼 This figure quantitatively analyzes the performance of GPT-4 on two UrbanKGC tasks: Relational Triplet Extraction (RTE) and Knowledge Graph Completion (KGC). It shows that GPT-4 struggles with heterogeneous relationships (spatial, temporal, and functional) in RTE and with geospatial relations (DC, EC, EQ, PO, IN) in KGC, highlighting the limitations of LLMs in these tasks. The results are based on comparing 50 GPT-4 outputs to human annotations.
read the caption
Figure 3: Quantitative performance analysis of prompting GPT-4 for UrbanKGC tasks. The result is obtained by comparing 50 GPT-4's outputs with the human's annotation.
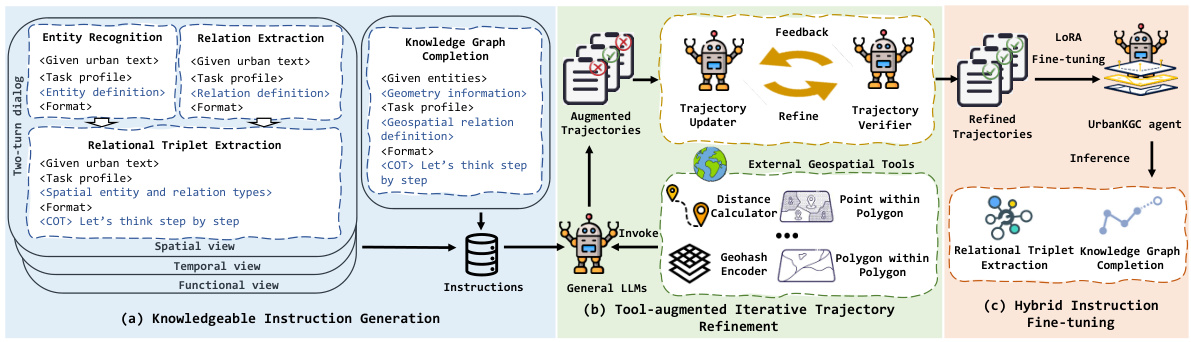
🔼 The figure shows the overall pipeline of the UrbanKGent framework, which consists of three main modules: (1) Knowledgeable Instruction Generation, which generates instructions for aligning LLMs to UrbanKGC tasks; (2) Tool-augmented Iterative Trajectory Refinement, which enhances and refines the trajectories generated by LLMs by invoking external geospatial tools; and (3) Hybrid Instruction Fine-tuning, which fine-tunes LLMs based on the refined trajectories for cost-effectively completing diverse UrbanKGC tasks. Each module is illustrated with detailed diagrams showing the steps and components involved.
read the caption
Figure 4: An overview of UrbanKGent Construction.

🔼 This figure compares the latency (in minutes) and cost (in dollars) of using UrbanKGent-13B and GPT-4 to perform 1000 relational triplet extraction (RTE) and knowledge graph completion (KGC) tasks. It shows that UrbanKGent-13B is significantly more cost-effective than GPT-4 while maintaining comparable performance.
read the caption
Figure 5: The model latency and cost of constructed UrbanKGent-13B and GPT-4 in UrbanKGC. We report the total inference time and cost of 1,000 RTE and KGC tasks.

🔼 This figure visualizes the geographic distribution of head and tail entities in four knowledge graph completion (KGC) datasets. The datasets are represented by different colors and shapes, showing the spatial extent of each entity type. This visualization helps to understand the spatial distribution of data within the datasets and provides context for the KGC task.
read the caption
Figure 7: The geometry range visualization of the head entity and tail entity of four KGC datasets. The horizontal and vertical coordinates are longitude and latitude, respectively. The blue and red polygons stand for entities with the polygon geometry, the purple line string stands for the entities with linestring geometry and the green point is for the coordinate entities.

🔼 This figure shows the overall pipeline of the UrbanKGent framework. It consists of three stages: Knowledgeable Instruction Generation, Tool-augmented Iterative Trajectory Refinement, and Hybrid Instruction Fine-tuning. The Knowledgeable Instruction Generation stage focuses on aligning LLMs to UrbanKGC tasks using heterogeneity-aware and geospatial-infused instruction generation. The Tool-augmented Iterative Trajectory Refinement stage enhances and refines generated trajectories using geospatial tools and self-refinement. Finally, the Hybrid Instruction Fine-tuning stage fine-tunes LLMs on refined trajectories to improve performance on diverse UrbanKGC tasks.
read the caption
Figure 4: An overview of UrbanKGent Construction.

🔼 This figure shows the overall pipeline of the UrbanKGent framework. It includes three main modules: Knowledgeable Instruction Generation, Tool-augmented Iterative Trajectory Refinement, and Hybrid Instruction Fine-tuning. Each module has several steps, demonstrating how UrbanKGent generates instructions for LLMs, refines the trajectories using external geospatial tools, and fine-tunes LLMs for urban knowledge graph construction tasks.
read the caption
Figure 4: An overview of UrbanKGent Construction.

🔼 This figure shows the Spearman correlation coefficients between GPT-4 evaluation results and human evaluation results for different LLMs (Llama-2-7B, Llama-2-13B, Llama-2-70B, GPT-3.5, and GPT-4) on two tasks (RTE and KGC) and two datasets (NYC and CHI). The higher the correlation coefficient, the more consistent the GPT-4 evaluation is with human judgment.
read the caption
Figure 10: The Spearman correlation between the GPT evaluation and human's evaluation under five different LLM backbones (i.e., Llama-2-7B, Llama-2-13B, Llama-2-70B, GPT-3.5 and GPT-4).
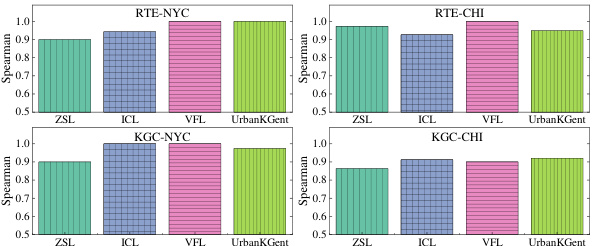
🔼 This figure shows the Spearman correlation coefficients between GPT-4 evaluations and human evaluations for the RTE and KGC tasks. The evaluations were performed using five different LLM backbones: Llama-2-7B, Llama-2-13B, Llama-2-70B, GPT-3.5, and GPT-4. The high correlation coefficients (above 0.8) across all backbones indicate a strong agreement between GPT-4 and human evaluations, suggesting the reliability of using GPT-4 for automated evaluation.
read the caption
Figure 10: The Spearman correlation between the GPT evaluation and human's evaluation under five different LLM backbones (i.e., Llama-2-7B, Llama-2-13B, Llama-2-70B, GPT-3.5 and GPT-4).
More on tables
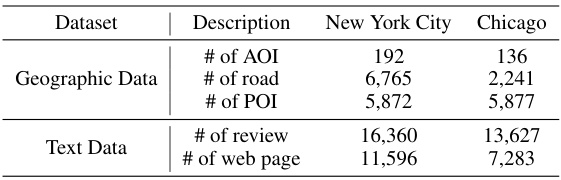
🔼 This table shows the number of Area of Interest (AOI), road, Point of Interest (POI), review, and web page data collected for New York City and Chicago. These data sources are used to construct the Urban Knowledge Graph.
read the caption
Table 1: The statistics of raw datasets.

🔼 This table shows the number of records in different datasets used for the UrbanKGC task. The datasets are categorized by city (New York City or Chicago), task type (RTE or KGC), and dataset size (Instruct, main dataset, or Large). The Instruct datasets are smaller and used for instruction fine-tuning. The main datasets are medium-sized and used for validation, and the Large datasets are much larger and used for real-world testing.
read the caption
Table 2: The statistics of constructed UrbanKGC dataset.

🔼 This table presents the main experimental results of the UrbanKGent model on two tasks: Relational Triplet Extraction (RTE) and Knowledge Graph Completion (KGC). It compares the performance of UrbanKGent against 31 baseline methods across two datasets (NYC and CHI). The accuracy is measured using both GPT-4 and human evaluation. The table highlights the superior performance of UrbanKGent across various models and evaluation methods, with the best performing baseline underlined.
read the caption
Table 3: The main results of relational triplet extraction (RTE) and knowledge graph completion (KGC). We report the accuracy (acc) and confidence for GPT evaluation on two datasets, and report accuracy (acc) for the Human evaluation approach. The best baseline performance is underlined.
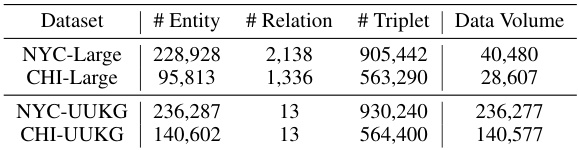
🔼 This table compares the statistics of Urban Knowledge Graphs (UrbanKGs) constructed for New York City and Chicago using the UrbanKGent framework and an existing benchmark (UUKG). It shows the number of entities, relations, and triplets in each UrbanKG, as well as the total volume of data used for construction. The comparison highlights the efficiency of UrbanKGent, which constructs UrbanKGs with a similar scale using significantly less data.
read the caption
Table 4: Statistics comparison of constructed UrbanKGs in New York and Chicago between UrbanKGent and existing benchmark.

🔼 This table presents a statistical overview of six different datasets used for Relational Triple Extraction (RTE) tasks in the UrbanKGent paper. It shows the maximum, minimum, and average lengths of the urban text within each dataset, along with the total number of records in each dataset. The datasets are categorized into instruction tuning datasets and testing datasets, with two datasets each for New York City and Chicago. The large datasets are intended for real-world application. The table helps to understand the characteristics and size of the text data used for training and evaluating the RTE models.
read the caption
Table 5: The detailed statistic of RTE datasets. We report the maximum length, minimum length, and average length of urban text in the RTE dataset.

🔼 This table presents the main experimental results of the paper, comparing the performance of the proposed UrbanKGent model against 31 baseline methods on two tasks: relational triplet extraction (RTE) and knowledge graph completion (KGC). The results are shown for two datasets, and two evaluation methods are used: GPT-4 based evaluation and human evaluation. The accuracy and confidence intervals are reported for the GPT-4 evaluations, and the accuracy is reported for the human evaluation. The best-performing baseline method for each task and dataset is underlined.
read the caption
Table 3: The main results of relational triplet extraction (RTE) and knowledge graph completion (KGC). We report the accuracy (acc) and confidence for GPT evaluation on two datasets, and report accuracy (acc) for the Human evaluation approach. The best baseline performance is underlined.
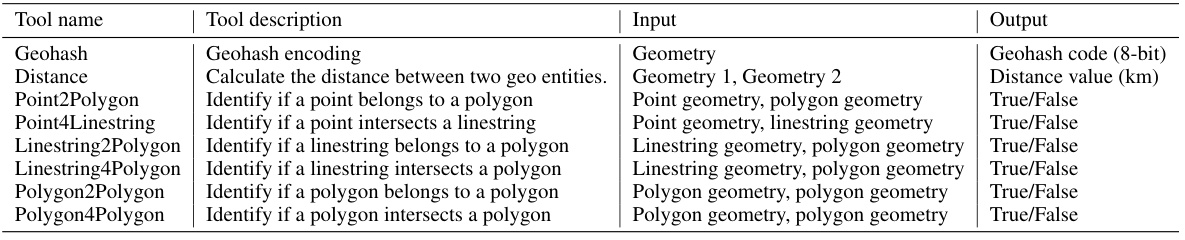
🔼 This table presents the summary statistics of the raw datasets used in the paper, including the number of Areas of Interest (AOI), roads, Points of Interest (POI), reviews, and web pages for both New York City and Chicago.
read the caption
Table 1: The statistics of raw datasets.

🔼 This table shows an example of how the accuracy of relational triplet extraction (RTE) is calculated using both human and GPT-4 evaluation methods. Human evaluators determine the true and false triplets based on a given text and model output. GPT-4 is then used to evaluate the same text and output, providing another accuracy measure. The labels used by GPT-4 are not visible in this specific illustration.
read the caption
Table 7: Illustrative RTE evaluation example when we utilize human evaluation and GPT evaluation method. We calculate the accuracy by counting the proportion of true triplets. The label for GPT evaluation method is invisible.

🔼 This table shows the correlation consistency between human evaluation and GPT-4 evaluation under different repeat times. The Spearman correlation is calculated to measure the consistency, with higher values indicating greater agreement. The results demonstrate the reliability of using GPT-4 for evaluation, even when repeating the evaluation multiple times.
read the caption
Table 8: The average Spearman correlation value between human evaluations and GPT-4 evaluations. 'Repeat X times' refers to instructing GPT-4 to generate judgments X times, and adopting the answer that appears most frequently (e.g., True/False for the KGC task and Number of the true triplet for the RTE task) as the final decision.

🔼 This table presents the main results of the relational triplet extraction (RTE) and knowledge graph completion (KGC) tasks. It compares the performance of various models, including different versions of LLMs (e.g., Llama-2, Llama-3, Vicuna, Alpaca, Mistral) and GPT-3.5/4. Results are shown for two datasets, and include accuracy and confidence scores from GPT-4 based evaluations, as well as human-evaluated accuracy scores. The best-performing baseline model for each task and dataset is underlined.
read the caption
Table 3: The main results of relational triplet extraction (RTE) and knowledge graph completion (KGC). We report the accuracy (acc) and confidence for GPT evaluation on two datasets, and report accuracy (acc) for the Human evaluation approach. The best baseline performance is underlined.
🔼 This table presents the ablation study results of the proposed UrbanKGent framework. By removing different components (knowledgeable instruction generation, multi-view design in RTE, external geospatial tool invocation, and iterative trajectory self-refinement), the impact on the performance of relational triplet extraction (RTE) and knowledge graph completion (KGC) tasks are evaluated. The results are shown in terms of accuracy and confidence using GPT-4 evaluation, and accuracy using human evaluation.
read the caption
Table 10: Effect of different blocks.
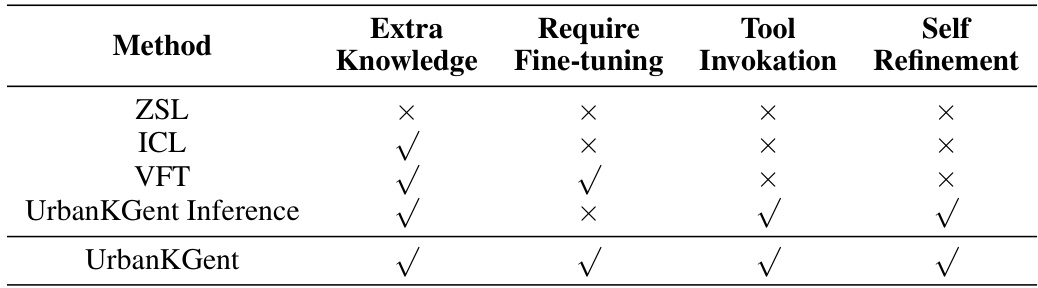
🔼 This table compares four different methods for Urban Knowledge Graph Construction (UrbanKGC) using Large Language Models (LLMs): Zero-shot learning (ZSL), In-context learning (ICL), Vanilla fine-tuning (VFT), and the proposed UrbanKGent inference method. It shows whether each method utilizes extra knowledge, requires fine-tuning, uses tool invocation, and employs self-refinement.
read the caption
Table 11: Comparison among LLM-based UrbanKGC methods in four ways.

🔼 This table shows the inference time in minutes for constructing Urban Knowledge Graphs (UKGs) using three different versions of the UrbanKGent model (7B, 8B, and 13B parameters). The inference time is shown for two medium-sized datasets (NYC and CHI) and two larger datasets (NYC-Large and CHI-Large). The data volume for each dataset is also provided. The bottom row shows the average latency per 1000 records across all datasets.
read the caption
Table 12: The inference latency comparison of UrbanKGC using UrbanKGent family. We use two middle-size dataset (i.e., NYC and CHI) and two large-scale dataset (i.e., NYC-Large and CHI-Large) for UrbanKG construction.

🔼 This table presents the statistics of the entity and relation ontology in the UrbanKGs constructed using the NYC-Large and CHI-Large datasets. It shows the number of coarse-grained and fine-grained entities and relations, as well as the total number of entities and triplets in each UrbanKG. This helps to quantify the richness and complexity of the generated knowledge graphs.
read the caption
Table 13: The statistic of entity and relation ontology of constructed UrbanKGs on NYC-Large and CHI-Large dataset.
Full paper#



















