↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Offline reinforcement learning (RL) aims to learn effective policies from datasets of past experiences. However, current offline RL algorithms often underperform imitation learning, and it is unclear why. This paper investigates the bottlenecks in offline RL by systematically studying value function learning, policy extraction, and policy generalization. It finds that the quality of the value function is not the only factor, and that the choice of policy extraction method greatly influences the final performance and scalability of the algorithm. In addition, the study highlights the significant impact of imperfect policy generalization on test-time states.
To overcome the limitations, the researchers propose two simple test-time policy improvement methods to address the generalization issues. They discover that using either high-coverage data for offline training or test-time policy improvement methods enhances the performance of offline RL. Overall, this study provides actionable advice and new insights into the design of effective offline RL algorithms, emphasizing the importance of policy learning and generalization.
Key Takeaways#
Why does it matter?#
This paper challenges the common belief that poor value function learning is the primary bottleneck in offline RL. By systematically analyzing data scaling properties, it reveals that policy extraction and generalization are often more critical bottlenecks, opening avenues for algorithm improvement and directing future research. This has significant implications for both researchers and practitioners seeking to advance the field of offline RL.
Visual Insights#
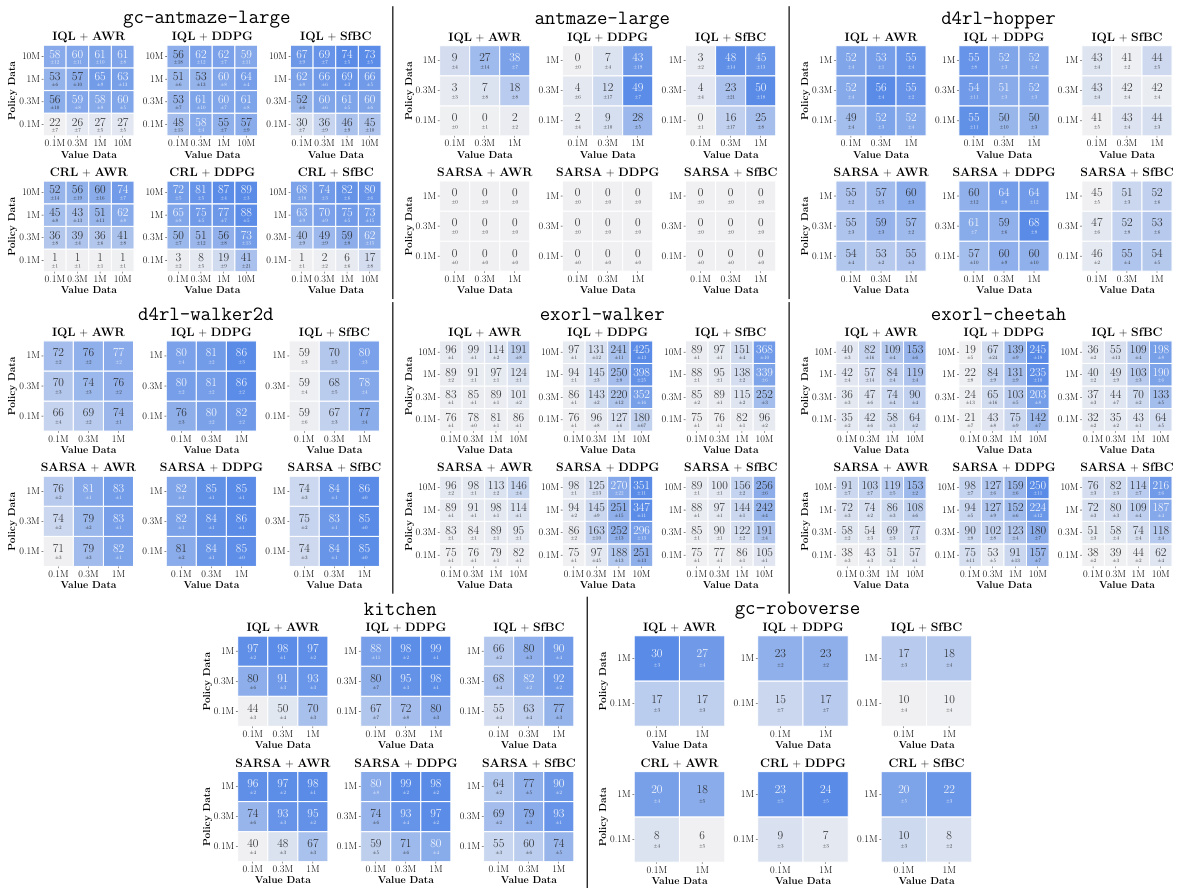
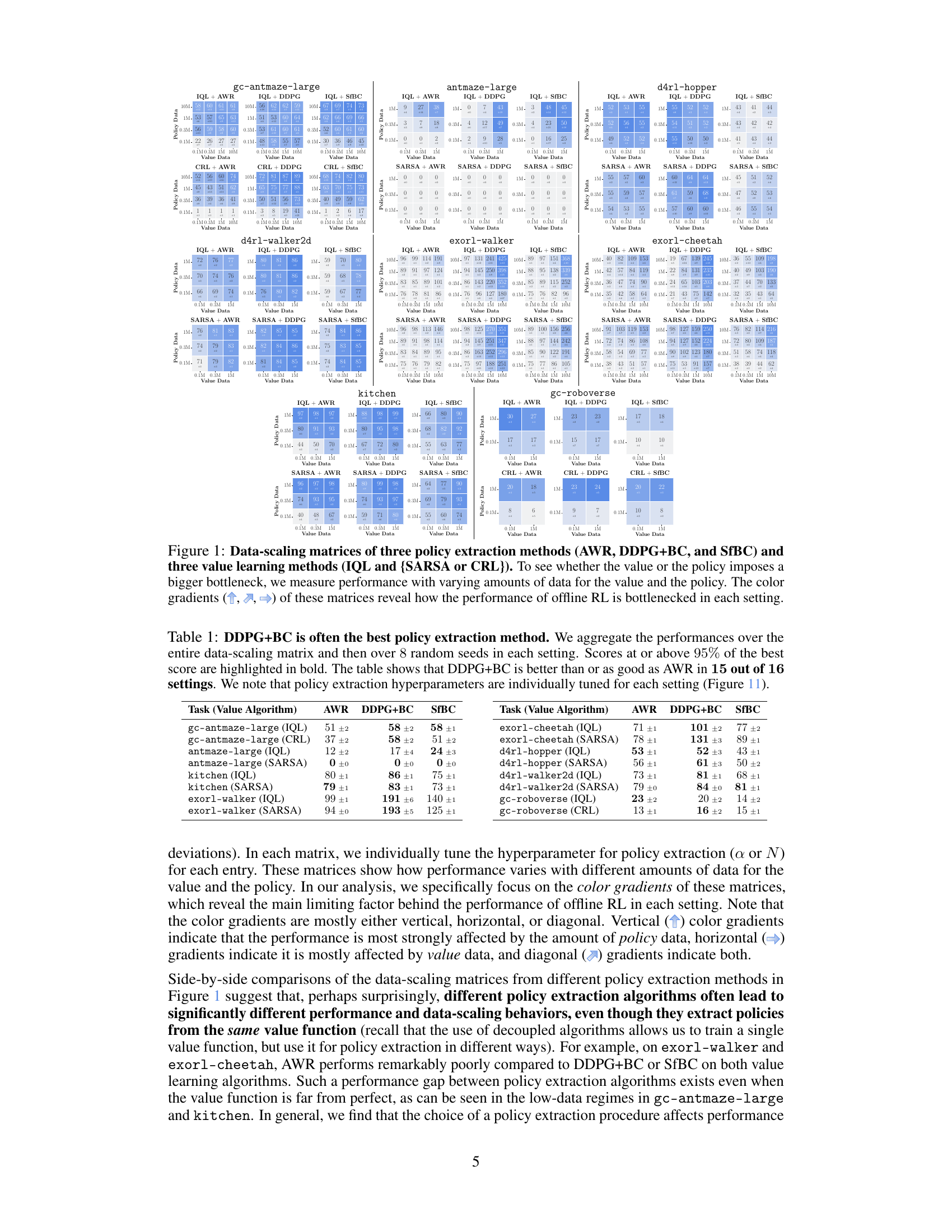
This figure presents data-scaling matrices showing the impact of varying value and policy data amounts on offline RL performance using different value learning (IQL, SARSA, CRL) and policy extraction (AWR, DDPG+BC, SfBC) methods across eight environments. Color gradients in each matrix illustrate how performance bottlenecks arise from either value function accuracy, policy extraction, or policy generalization, revealing insights into offline RL limitations and potential improvements.
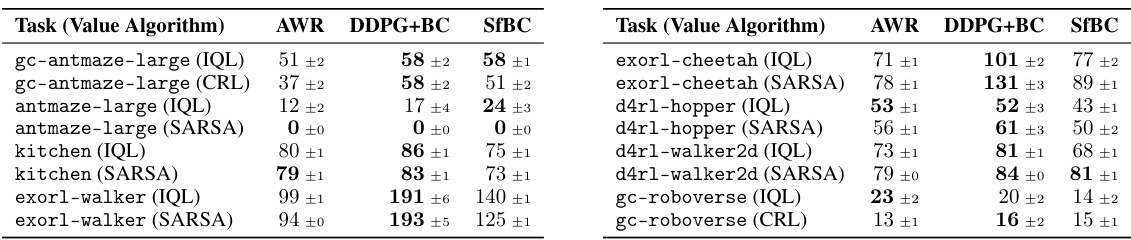
This table presents an aggregated performance comparison of different offline RL algorithms across various environments. It focuses on the impact of policy extraction method (AWR, DDPG+BC, SfBC) on performance, comparing these methods in conjunction with different value learning algorithms (IQL and SARSA or CRL). The results indicate that the behavior-constrained policy gradient method (DDPG+BC) significantly outperforms the other methods in most settings.
In-depth insights#
Offline RL Bottlenecks#
Offline reinforcement learning (RL) aims to learn effective policies from pre-collected data, bypassing the need for online interaction. However, offline RL often underperforms compared to imitation learning, which uses high-quality demonstrations. This paper investigates the main bottlenecks hindering offline RL’s performance. Contrary to the common belief that imperfect value function learning is the primary issue, the study reveals that policy extraction and generalization play a more significant role. Policy extraction methods dramatically impact performance; behavior-constrained policy gradient approaches outperform value-weighted behavioral cloning. Furthermore, generalization to out-of-distribution test-time states is a major bottleneck. The authors propose and evaluate methods to address this, suggesting that high-coverage datasets, even if suboptimal, or on-the-fly policy improvement techniques, are effective strategies for enhancing offline RL’s ability to handle unseen situations.
Policy Extraction#
Policy extraction, a critical step in offline reinforcement learning (RL), focuses on deriving a usable policy from a learned value function. While seemingly straightforward, the choice of policy extraction algorithm significantly impacts performance and scalability. Common approaches like weighted behavioral cloning (e.g., AWR) struggle to fully leverage the value function, often underperforming compared to methods such as behavior-constrained policy gradient (e.g., DDPG+BC). This highlights that policy learning is frequently a more significant bottleneck than value learning in offline RL, contrary to common assumptions. The effectiveness of policy extraction directly relates to how well the resulting policy generalizes to out-of-distribution states during deployment. Therefore, optimizing this stage is crucial for improving offline RL’s overall success and should be given significant consideration beyond the traditional focus on refining value function estimation alone. Innovative techniques such as test-time policy training offer avenues to enhance generalization, indicating a need for future research on this aspect of offline RL algorithms.
Generalization#
The concept of generalization is central to the success of offline reinforcement learning (RL) algorithms. The paper reveals a surprising finding: that current offline RL methods often excel at learning optimal policies within the distribution of their training data, but significantly struggle with generalization to unseen, out-of-distribution test-time states. This bottleneck is highlighted as more impactful than previously assumed limitations in value function learning. The authors propose that future research should focus on improving the policy’s ability to generalize, rather than solely concentrating on refining value function accuracy. Strategies suggested include using high-coverage datasets that encompass a wider range of states and implementing test-time policy improvement techniques to adapt the policy during deployment based on the newly encountered states and the learned value function. This shift in focus towards improving generalization underscores a crucial aspect often overlooked in offline RL methodology.
Data-Scaling Analysis#
A data-scaling analysis in a research paper systematically investigates how the performance of an offline reinforcement learning (RL) algorithm changes with varying amounts of training data. It’s a powerful technique to isolate bottlenecks in the learning process. By incrementally increasing the data size and observing performance changes, researchers can pinpoint whether limitations stem from imperfect value function estimation, suboptimal policy extraction, or poor policy generalization. The results often reveal surprising insights; for example, that policy extraction methods might have a more significant impact than value function learning on overall performance, underscoring the need for careful selection and improvement of these components. This study demonstrates the importance of systematically assessing the scalability of offline RL algorithms to gain a clearer understanding of their strengths and weaknesses, thereby guiding future algorithm development and practical applications.
Future Directions#
Future research should prioritize addressing the limitations uncovered in this study. Improving policy extraction methods beyond behavior-constrained policy gradients is crucial, exploring techniques that more effectively leverage learned value functions. This includes investigating methods that can better handle limited and noisy data, and enhance generalization capabilities to unseen states. Addressing the generalization bottleneck is paramount; future work could focus on developing novel state representations that inherently facilitate generalization, perhaps by incorporating techniques from representation learning. Furthermore, research into offline-to-online policy refinement techniques warrants attention, as this study highlighted the potential for significant performance gains through test-time adaptation. Finally, exploring the interaction between data quality, coverage and quantity, with a focus on designing high-coverage yet still useful datasets is important. This integrated approach would advance the state-of-the-art in offline reinforcement learning.
More visual insights#
More on figures
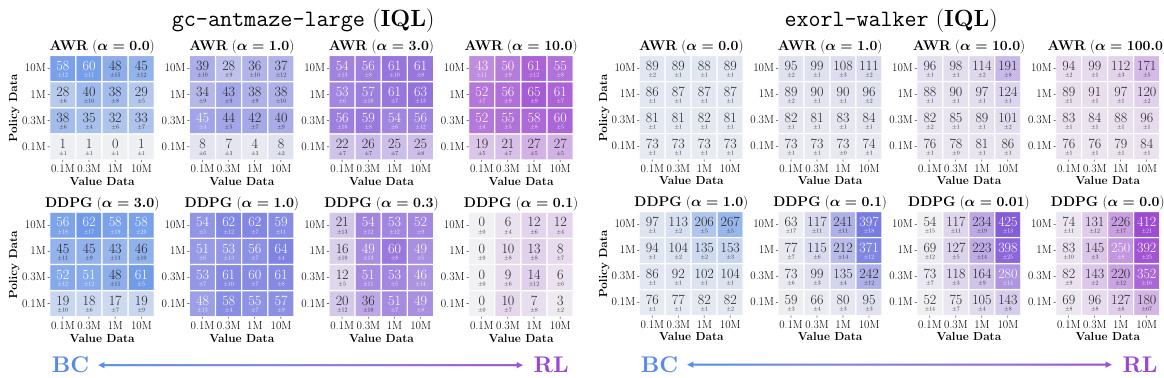
This figure shows data-scaling matrices for different combinations of value learning methods (IQL, SARSA, CRL) and policy extraction methods (AWR, DDPG+BC, SfBC). Each matrix visualizes how performance changes with varying amounts of data used for value function training and policy extraction. The color gradients indicate the main bottleneck in offline RL performance for each scenario (value function, policy, or generalization).
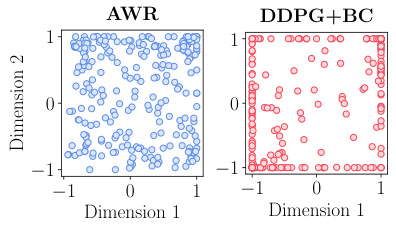
This figure compares the test-time actions sampled from policies learned by AWR and DDPG+BC on exorl-walker. It visually demonstrates that AWR actions are relatively centered around the origin, while DDPG+BC actions are more spread out, suggesting a higher degree of optimality for DDPG+BC.
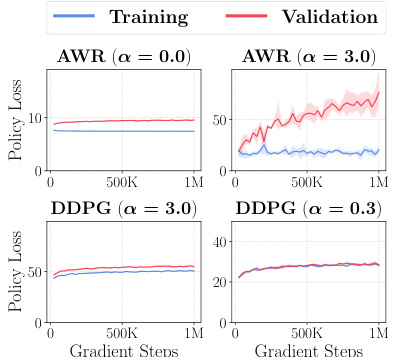
This figure compares the training and validation policy losses of AWR and DDPG+BC on gc-antmaze-large with the smallest 0.1M dataset (8 seeds). The results show that AWR with a large temperature (α = 3.0) causes severe overfitting, while DDPG+BC shows much better performance than AWR in low-data regimes.
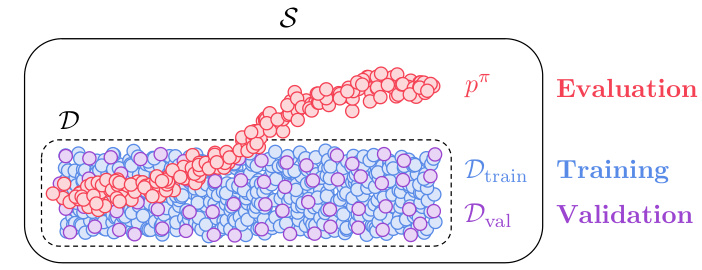
This figure illustrates the three different state distributions used to calculate the Mean Squared Error (MSE) metrics in the paper. The training MSE measures the policy accuracy on states from the training dataset (Dtrain), the validation MSE measures accuracy on a held-out validation set (Dval), and the evaluation MSE measures policy accuracy on states encountered during evaluation (pπ), representing the states the policy visits during deployment. This highlights the key difference between in-distribution (training and validation) and out-of-distribution (evaluation) performance, a central focus of the paper’s analysis.
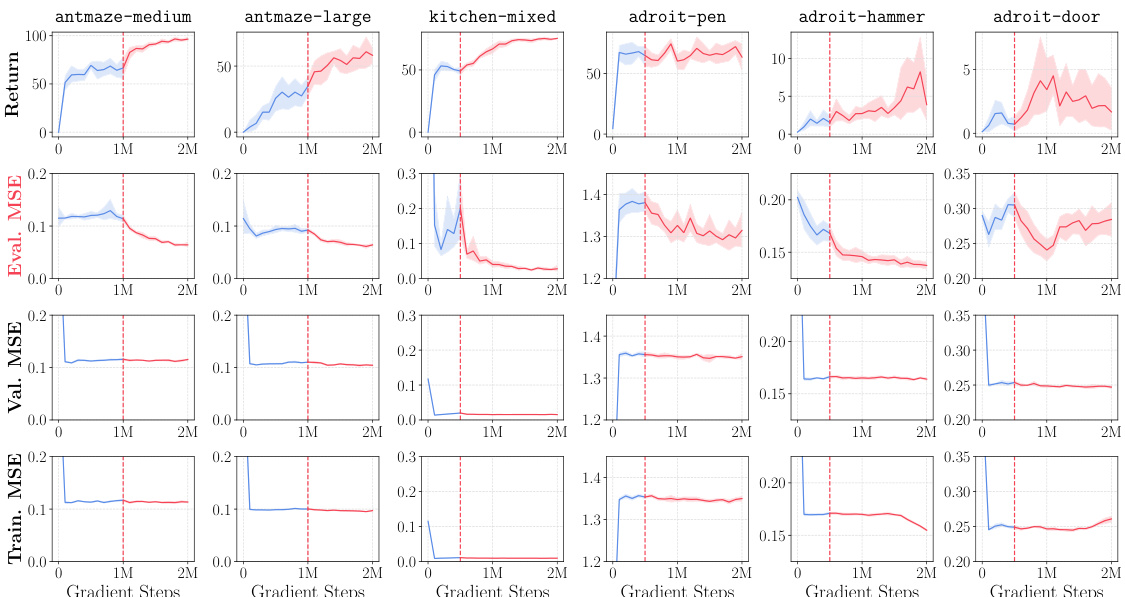
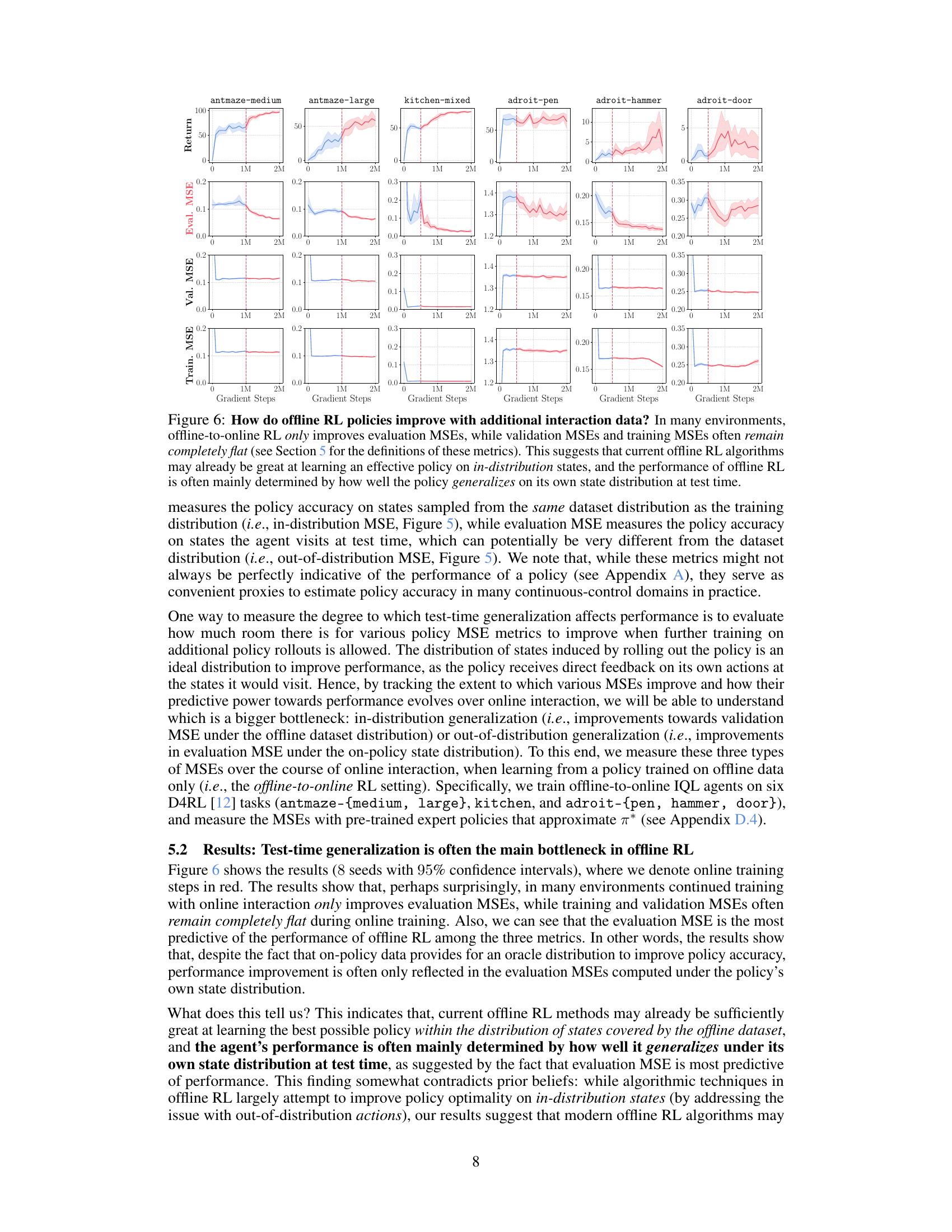
This figure shows the results of an experiment evaluating how offline RL policies improve with additional online interaction data. The results reveal that in many cases, offline-to-online RL primarily improves the evaluation MSE (mean squared error), a metric measuring performance on out-of-distribution test states. In contrast, the training and validation MSEs, representing performance on in-distribution states, often remain unchanged. This suggests the primary limitation of current offline RL algorithms lies not in learning optimal policies within the training data distribution, but rather in the ability of those policies to generalize to novel, out-of-distribution states encountered during deployment.
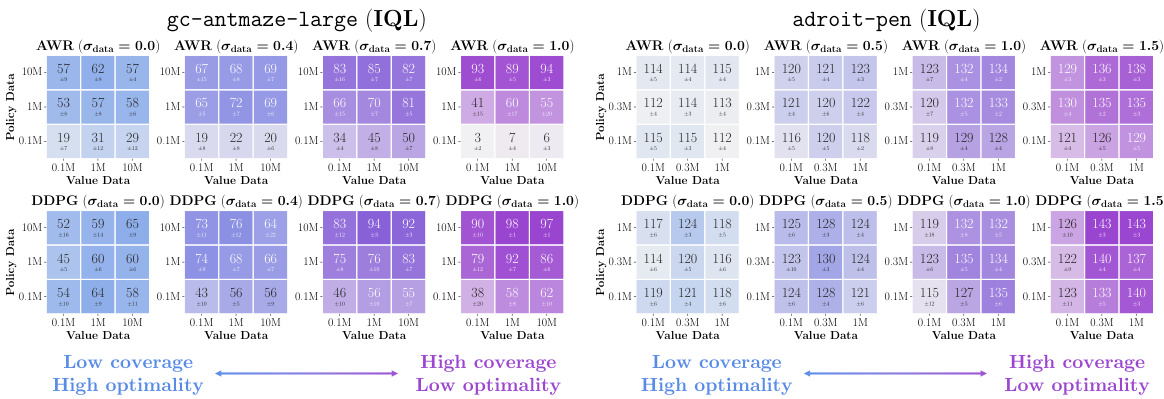
This figure presents data-scaling matrices that visualize how offline RL performance changes with varying amounts of data used for training value functions and policies. It compares three policy extraction methods (AWR, DDPG+BC, and SfBC) and three value learning methods (IQL, SARSA, and CRL) across eight different environments. The color gradients in the matrices indicate which factor—value function learning or policy extraction—is the primary bottleneck in each scenario. Vertical gradients indicate policy is the main bottleneck, horizontal gradients indicate value function learning is the bottleneck, and diagonal gradients indicate both are significant bottlenecks.
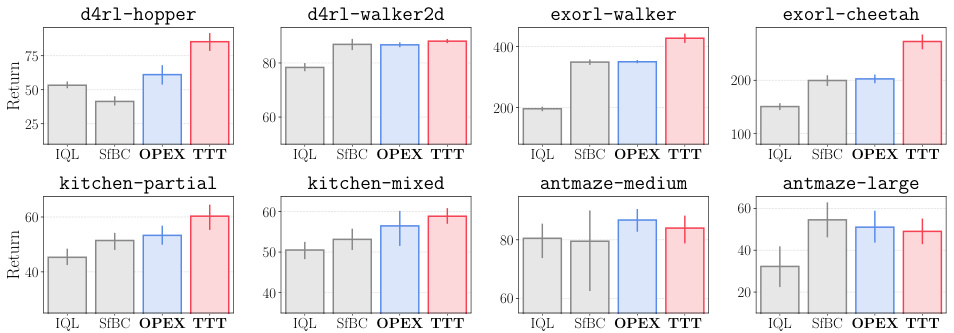
This figure shows the results of applying two test-time policy improvement techniques (OPEX and TTT) to six different offline RL tasks. The results demonstrate that both OPEX and TTT significantly improve performance compared to standard offline RL methods (IQL and SfBC), especially in tasks where generalization to out-of-distribution test-time states is challenging. This supports the paper’s hypothesis that policy generalization is a major bottleneck in offline RL.

This figure compares the performance of goal-conditioned behavioral cloning (BC) with two different state representations on the gc-antmaze-large environment. The first uses the original state representation, while the second uses a transformed representation with a continuous invertible function. Despite being topologically equivalent, the transformed representation leads to significantly better test-time generalization, as measured by Evaluation MSE. This highlights the importance of state representation in achieving good test-time performance in offline RL.

This figure shows data-scaling matrices which illustrate how the performance of offline RL is affected by varying amounts of data used for training the value function and the policy. The three policy extraction methods (AWR, DDPG+BC, SfBC) and three value learning methods (IQL, SARSA, CRL) are tested in eight environments with varying data sizes and qualities. Color gradients in the matrices indicate whether the performance bottleneck is due to insufficient value function data, policy data, or a combination of both.
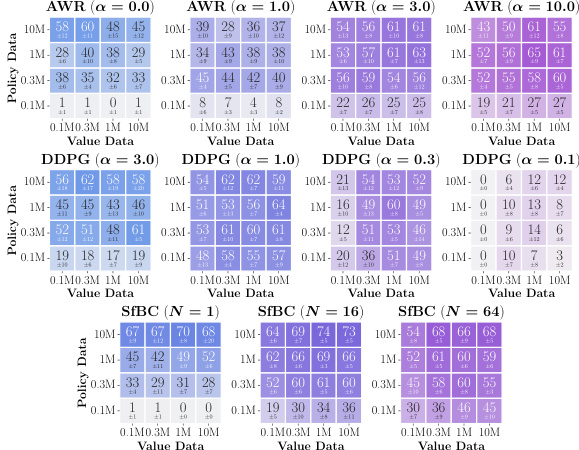
This figure presents data-scaling matrices that visualize the performance of offline RL algorithms with different amounts of data used for training value functions and policies. Each cell in the matrix represents the average performance of an algorithm under specific data amounts for value function training and policy extraction. The color gradient in each cell visually represents the effect of data amount on the performance, showing whether value function or policy learning is the main bottleneck for each algorithm and data setting.
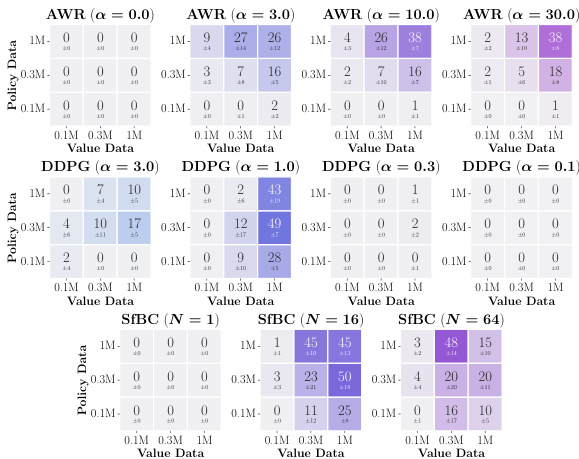
This figure presents data-scaling matrices that analyze how varying the amounts of data used for training the value function and policy affects the performance of offline reinforcement learning algorithms. Different value learning methods (IQL, SARSA, CRL) and policy extraction methods (AWR, DDPG+BC, SfBC) are compared. The color gradients in the matrices show how different aspects (value learning, policy extraction, generalization) contribute to offline RL performance bottlenecks.
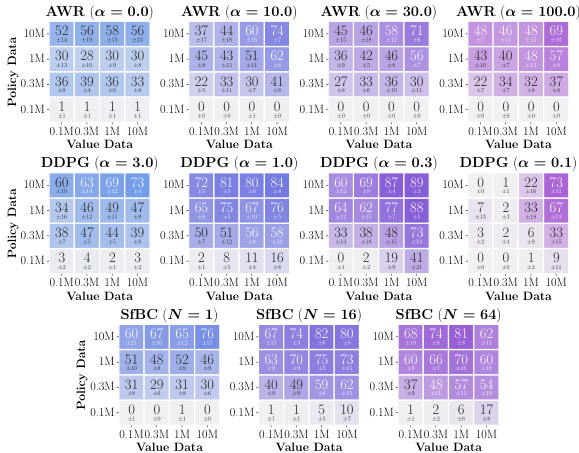
This figure presents data-scaling matrices that analyze how varying the amounts of data used for training value functions and policies affects the performance of offline reinforcement learning algorithms. It compares three policy extraction methods (AWR, DDPG+BC, SfBC) and three value learning methods (IQL, SARSA/CRL) across eight different environments. The color gradients in each matrix indicate which factor (value function quality, policy extraction method, or data amount) is the biggest bottleneck to performance in different data regimes.

This figure presents data-scaling matrices that analyze the bottlenecks in offline reinforcement learning. It compares three policy extraction methods (AWR, DDPG+BC, SfBC) and three value learning methods (IQL, SARSA, CRL) across eight different environments. Varying the amount of data used for value function training and policy extraction reveals which component (value function or policy) presents the bigger performance bottleneck in different data regimes. The color gradients in the matrices indicate whether the bottleneck is primarily due to the policy, value function, or both.
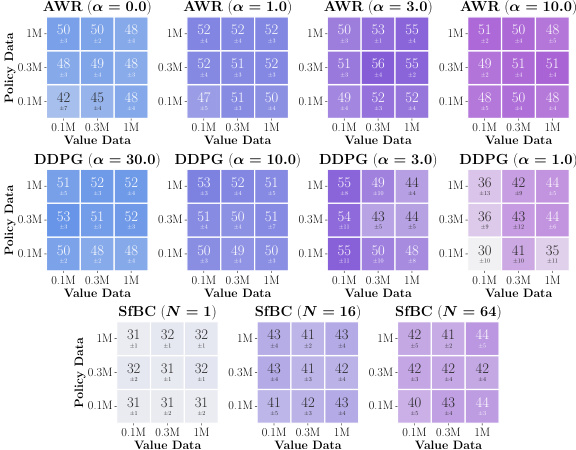
This figure presents data-scaling matrices that visualize how offline RL performance changes with varying amounts of data used for value function training and policy extraction. The matrices compare three policy extraction methods (AWR, DDPG+BC, SfBC) and three value learning methods (IQL, SARSA, CRL) across eight diverse environments. Color gradients in the matrices indicate whether the value function or policy extraction is the main bottleneck in offline RL performance for different data regimes. Arrows indicate the direction of the performance change.
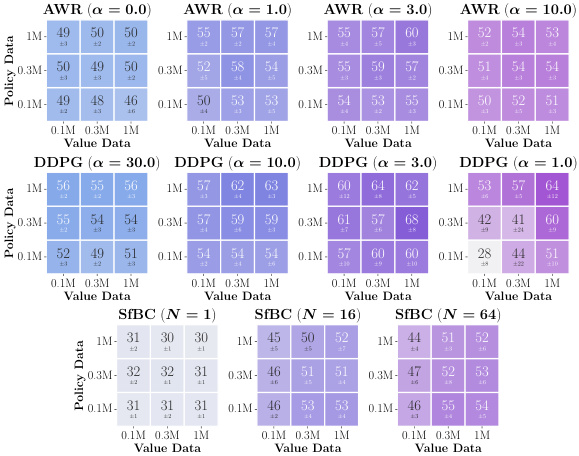
This figure presents data-scaling matrices which show the performance of offline RL algorithms with varying amounts of data used for training value functions and policies. The color gradients in each matrix illustrate how different factors (value function learning, policy extraction, and generalization) influence the overall performance of offline RL in different scenarios. It helps to identify the main bottleneck of offline RL in various settings and algorithms.
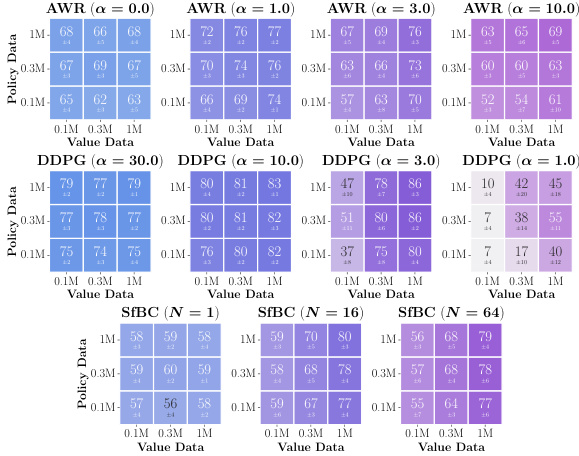
This figure shows data-scaling matrices for different combinations of value learning and policy extraction methods in offline RL. Each matrix represents an environment, and each cell shows the performance with varying amounts of value and policy data. The color gradients indicate which factor (value function learning or policy extraction) is the bigger bottleneck for offline RL performance in each scenario.
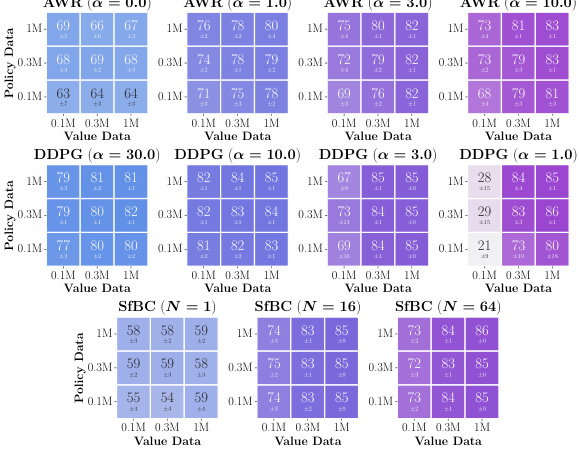
This figure shows data-scaling matrices which analyze how the performance of offline RL is affected by the amount of data used for value function training and policy extraction. It compares three policy extraction methods (AWR, DDPG+BC, and SfBC) and three value learning methods (IQL, SARSA, and CRL) across eight different environments. The color gradients in the matrices indicate whether value learning or policy extraction is the bigger bottleneck to offline RL performance in each scenario. Vertical gradients indicate policy learning is the main bottleneck, horizontal gradients indicate value learning is the bottleneck, and diagonal gradients mean both are bottlenecks.
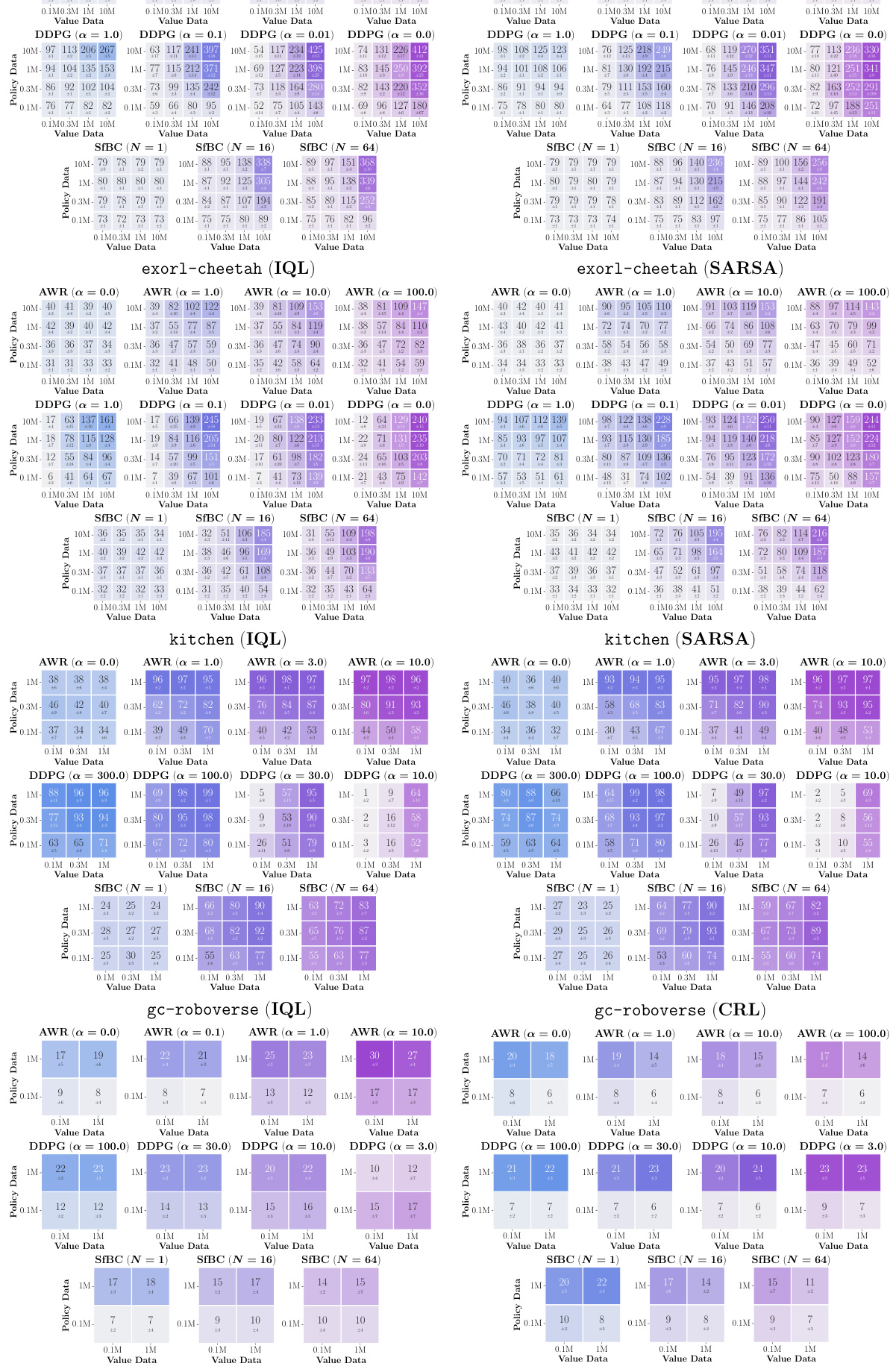
This figure presents data-scaling matrices showing the performance of offline RL algorithms with different amounts of data used for training the value function and the policy. The color gradients in each matrix cell indicate whether value function learning or policy extraction is the main bottleneck in offline RL performance for a given dataset size and algorithm combination. The results suggest that the choice of policy extraction algorithm often has a larger impact on performance than the choice of value learning algorithm.
More on tables

This table presents a comparison of the performance of three policy extraction methods (AWR, DDPG+BC, and SfBC) across various value learning algorithms and environments. The performance is aggregated across the data-scaling matrices, representing the average performance across different data sizes. The results indicate that DDPG+BC consistently outperforms or matches the performance of AWR.
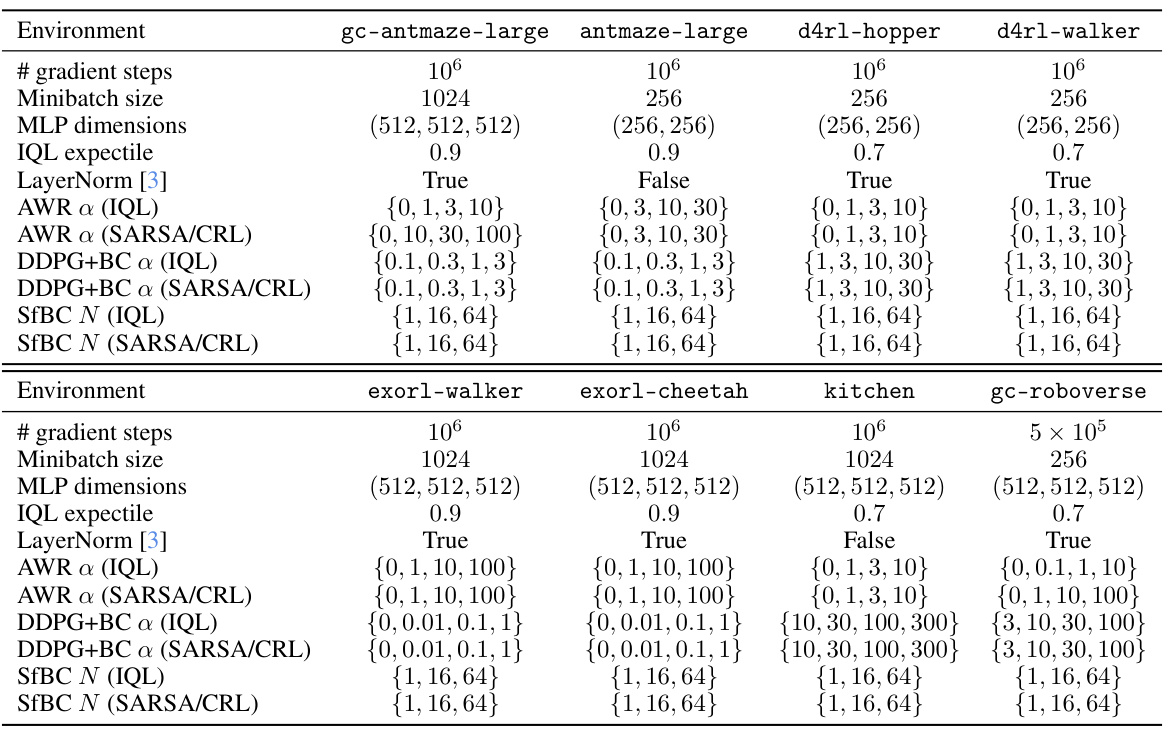
This table summarizes the performance of different policy extraction methods (AWR, DDPG+BC, SfBC) combined with different value learning algorithms (IQL, SARSA/CRL) across various tasks. The results are aggregated across multiple runs and hyperparameter settings. It highlights the superior performance of DDPG+BC in most cases compared to AWR and SfBC.
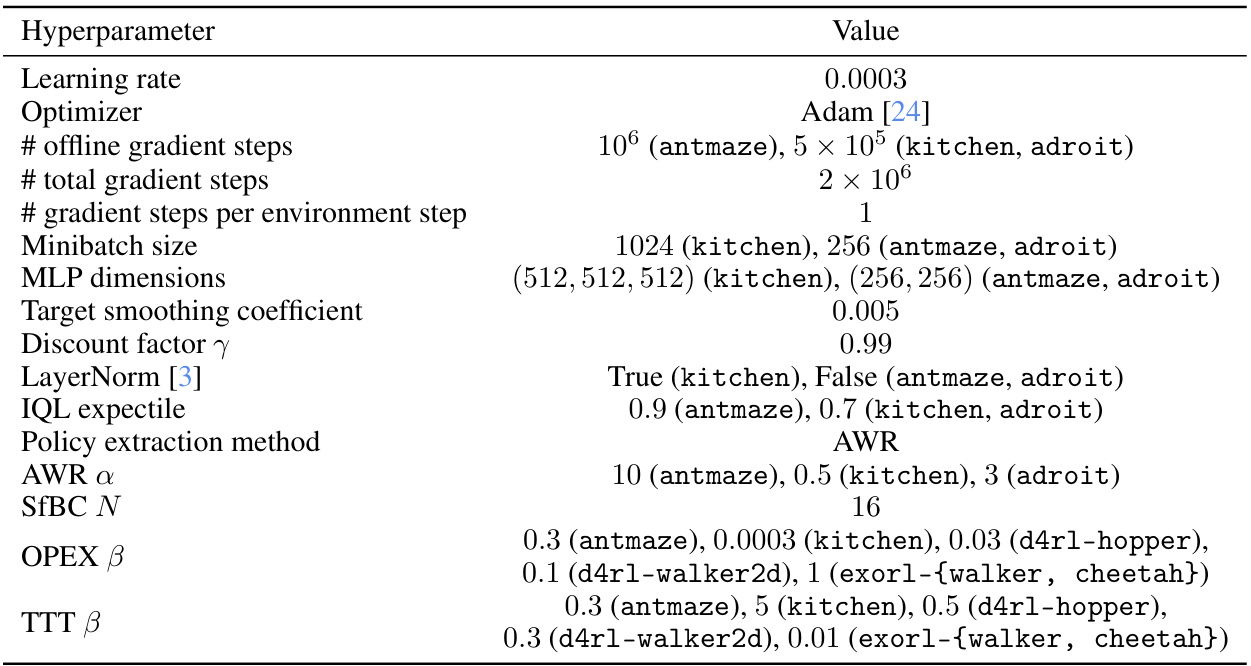
This table summarizes the performance of different policy extraction methods (AWR, DDPG+BC, and SfBC) across various value learning algorithms (IQL and SARSA/CRL) and environments. It highlights the superior performance and scalability of DDPG+BC compared to AWR in most settings, suggesting that the choice of policy extraction significantly impacts offline RL performance.
Full paper#