TL;DR#
Current multi-modal large language models (MLLMs) struggle to effectively function as mobile device operation assistants due to limitations in their training data. Existing MLLM-based agents, while improving capabilities through tool invocation, still face navigation challenges in mobile device operations: managing task progress and identifying relevant information across multiple screens. These difficulties are exacerbated by long token sequences and interleaved text-image data.
Mobile-Agent-v2 overcomes these limitations by employing a multi-agent architecture, including a planning agent to condense task history into a pure-text format, a decision agent to navigate task progress, and a reflection agent to correct errors. A memory unit helps retain focus content from previous screens. This design drastically reduces context length, allowing for easier navigation and improving accuracy. Experiments show that Mobile-Agent-v2 achieves over a 30% improvement in task completion compared to its single-agent predecessor.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel multi-agent architecture for mobile device operation assistance, addressing the limitations of single-agent approaches in handling long, interleaved image-text data. The multi-agent system improves task completion rates, offering a significant advance in automated mobile device operation. Its open-source nature promotes further research and development in this growing field. The work also highlights the challenges of long-context navigation in multi-modal tasks, offering valuable insights for researchers working with similar problems.
Visual Insights#

🔼 This figure illustrates the challenges of single-agent architectures in handling mobile device operation tasks. It shows how a user instruction (search for Lakers game results and create a note) involves navigating through multiple screens and operations. The ‘focus content’ (Lakers game score) is located on a previous screen and needs to be accessed again to complete the task. The length of the image-text input sequence grows with each operation, becoming increasingly difficult for a single agent to manage both task progress and relevant content from past screens. This highlights the need for a more advanced architecture like the multi-agent approach proposed by the authors.
read the caption
Figure 1: Mobile device operation tasks require navigating focus content and task progress from history operation sequences, where the focus content comes from previous screens. As the number of operations increases, the length of the input sequences grows, making it extremely challenging for a single-agent architecture to manage these two types of navigation effectively.

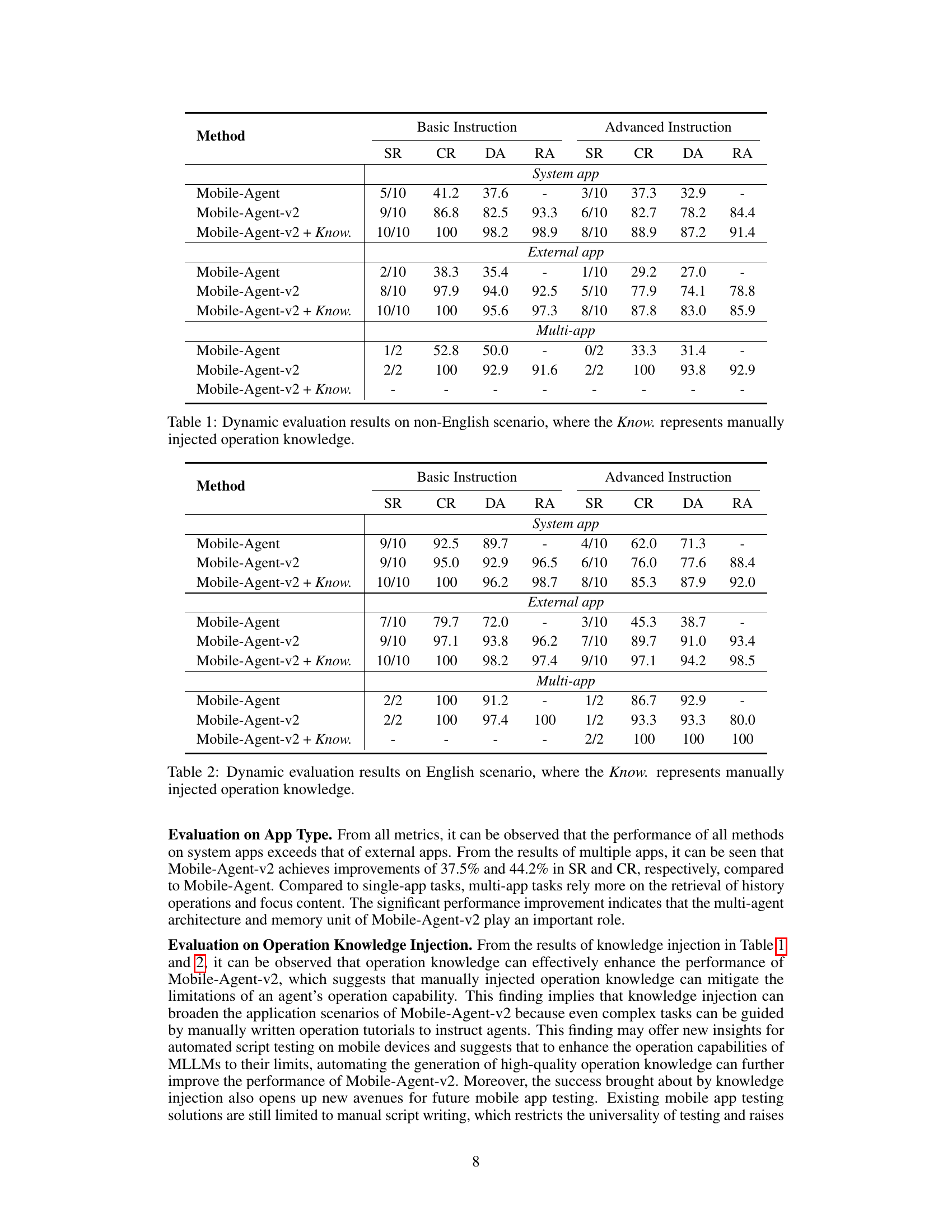
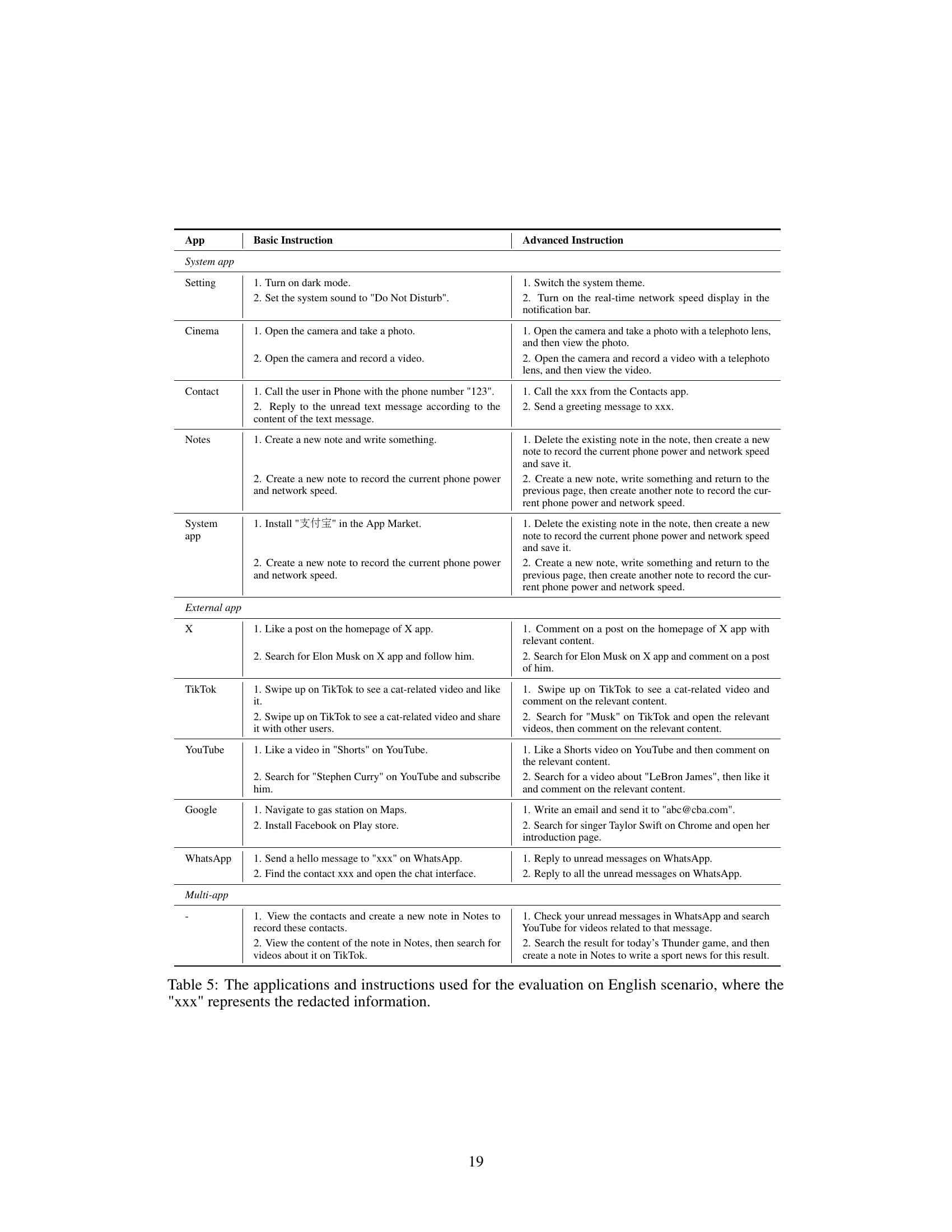
🔼 This table presents the results of a dynamic evaluation of Mobile-Agent, Mobile-Agent-v2, and Mobile-Agent-v2 with injected knowledge on a non-English dataset. It shows the success rate (SR), completion rate (CR), decision accuracy (DA), and reflection accuracy (RA) for basic and advanced instructions across three categories: system apps, external apps, and multi-app operations. The ‘Know.’ column indicates results when manual operational knowledge was injected.
read the caption
Table 1: Dynamic evaluation results on non-English scenario, where the Know. represents manually injected operation knowledge.
In-depth insights#
Multi-Agent Collab#
The concept of “Multi-Agent Collab” in a research paper likely explores the benefits of using multiple agents, each with specialized roles, to collaboratively solve a complex task. This approach is particularly useful when dealing with problems requiring diverse skills or perspectives. A key advantage is the potential for increased efficiency and robustness. By distributing the workload, agents can perform their respective subtasks concurrently, thus speeding up the process compared to a single-agent approach. Failure tolerance is another benefit, as the failure of one agent doesn’t necessarily mean total failure; others can compensate or take over. This is very important for applications where reliability is paramount. However, designing and managing a multi-agent system presents unique challenges. Effective communication and coordination between agents are critical for success, requiring careful consideration of agent architectures, information sharing mechanisms, and conflict resolution strategies. The complexity of managing interactions between agents could also lead to unforeseen performance bottlenecks or emergent behaviors that may be difficult to predict or control. Therefore, a thoughtful analysis of the trade-offs involved is needed before implementing such a system.
Mobile UI Ops#
Mobile UI operations (UI Ops) represent a significant challenge in the realm of mobile application development and user experience. Effective mobile UI Ops hinge on the seamless integration of visual and textual information to drive user interactions. This includes the ability to accurately perceive on-screen elements, interpret user intents, and translate those intents into precise device operations. Multi-agent systems, like the Mobile-Agent-v2 discussed in the paper, present a promising approach to tackle the complexity of mobile UI Ops. By distributing tasks among specialized agents (planning, decision-making, reflection), these systems can improve navigation through long operation sequences and manage focus content more effectively. However, limitations remain in terms of handling diverse UI designs and the robustness of natural language understanding within these agent-based systems. Further research should explore improved visual perception methods, more sophisticated natural language processing techniques, and error handling mechanisms to enhance the efficiency and reliability of automated mobile UI operations. The success of Mobile UI Ops ultimately hinges on the development of resilient and adaptable systems that can successfully interpret user commands and perform desired actions across the multitude of mobile applications and operating systems.
Visual Perception#
A robust visual perception system is crucial for any intelligent agent interacting with the real world, especially in scenarios involving mobile device operation. The ability to accurately interpret visual information from device screens is paramount. Effective visual perception must handle diverse screen layouts, varying resolutions, and different UI elements across diverse applications and operating systems. This necessitates a multi-faceted approach. The system should robustly identify and extract text and visual elements (icons, buttons), even under challenging conditions like low light, screen glare, or partial obstructions. This may involve a combination of techniques such as Optical Character Recognition (OCR) and object detection. Beyond simple recognition, a sophisticated visual perception module should provide contextual understanding. This involves accurately locating interactable elements and establishing their relationships within the user interface. The system’s efficacy hinges on the accuracy and speed of its visual processing. Real-time or near real-time processing is critical for practical mobile device operation assistance. A well-designed system would incorporate error handling and mechanisms for managing uncertainty and ambiguity in visual data, crucial for dependable operation in real-world conditions.
Agent Roles#
The conceptualization of agent roles is crucial in multi-agent systems, particularly for complex tasks such as mobile device operation. Clear delineation of responsibilities among agents is essential for efficient collaboration and avoids redundancy or conflicts. The paper’s design likely involves a hierarchy or collaboration between agents, potentially including a planning agent to define high-level goals and break down complex tasks; a decision agent to execute specific operations based on current screen context and task progress; and a reflection agent to monitor and correct errors. This multi-agent approach addresses the limitations of single-agent systems, particularly when dealing with long sequences of interconnected steps involving both visual and textual information. The division of labor among specialized agents improves efficiency, accuracy, and robustness. The success of this architecture hinges on effective communication and data exchange between the agents, highlighting the need for a well-defined interface and data structures for efficient information flow. The memory unit is also a critical component, preserving essential information that allows decision-making agents to maintain focus and context, improving the overall accuracy of the operations performed.
Future Research#
Future research directions stemming from this multi-agent mobile device operation assistant could explore several key areas. Improving the robustness and adaptability of the agents across diverse mobile environments and user interfaces is crucial. This could involve exploring techniques like transfer learning or meta-learning to enable faster adaptation to new apps or operating systems. Another promising area lies in enhancing the contextual understanding of the agents, potentially by incorporating more sophisticated memory management or integrating external knowledge bases. Investigating how human-in-the-loop learning or reinforcement learning could improve agent performance and efficiency is warranted. Finally, addressing issues like privacy and security in the context of automated mobile device operations and exploring the ethical implications of increasingly autonomous agents is vital for responsible innovation. Ultimately, scaling the system to handle more complex tasks and a broader range of mobile applications will be a key challenge that merits focused attention.
More visual insights#
More on figures
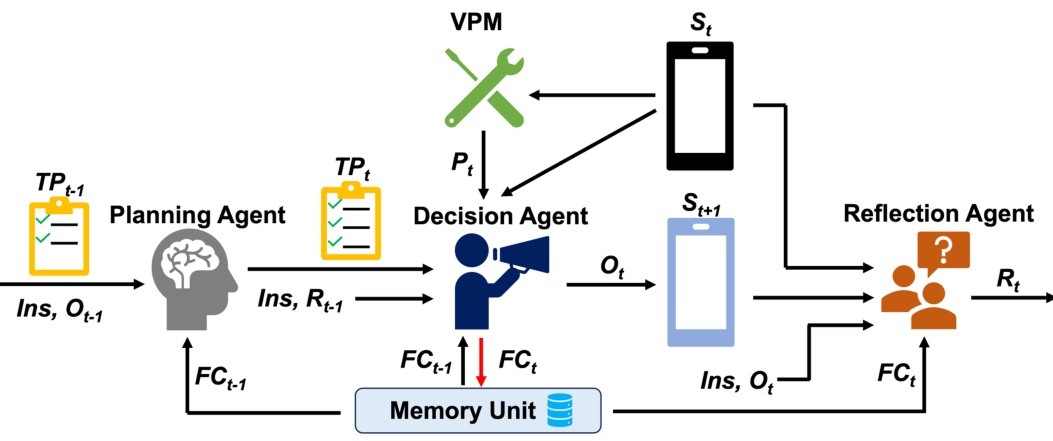
🔼 This figure shows the overall framework of Mobile-Agent-v2, a multi-agent architecture for mobile device operation assistance. It illustrates the interactions between three agents: the planning agent, the decision agent, and the reflection agent. The planning agent processes historical operations to generate task progress. The decision agent, informed by the task progress, the current screen (visual perception module output), and the result of the previous reflection, makes decisions and performs operations. The reflection agent observes the states before and after an operation to evaluate its outcome and provide feedback to the decision agent. The memory unit stores relevant information from previous screens.
read the caption
Figure 2: Illustration of the overall framework of Mobile-Agent-v2.

🔼 This figure illustrates the workflow of Mobile-Agent-v2, a multi-agent system for mobile device operation. It shows the interaction between three agents: the planning agent, decision agent, and reflection agent. The planning agent summarizes past actions and generates a task progress. The decision agent makes decisions based on this progress, current screen content, and feedback from the reflection agent. The reflection agent checks if the decision agent’s actions are successful. The memory unit stores important information for the decision agent. The diagram visually depicts how these components work together in each stage (planning, decision, reflection) to navigate the task effectively.
read the caption
Figure 3: Illustration of the operation process and interaction of agent roles in Mobile-Agent-v2.

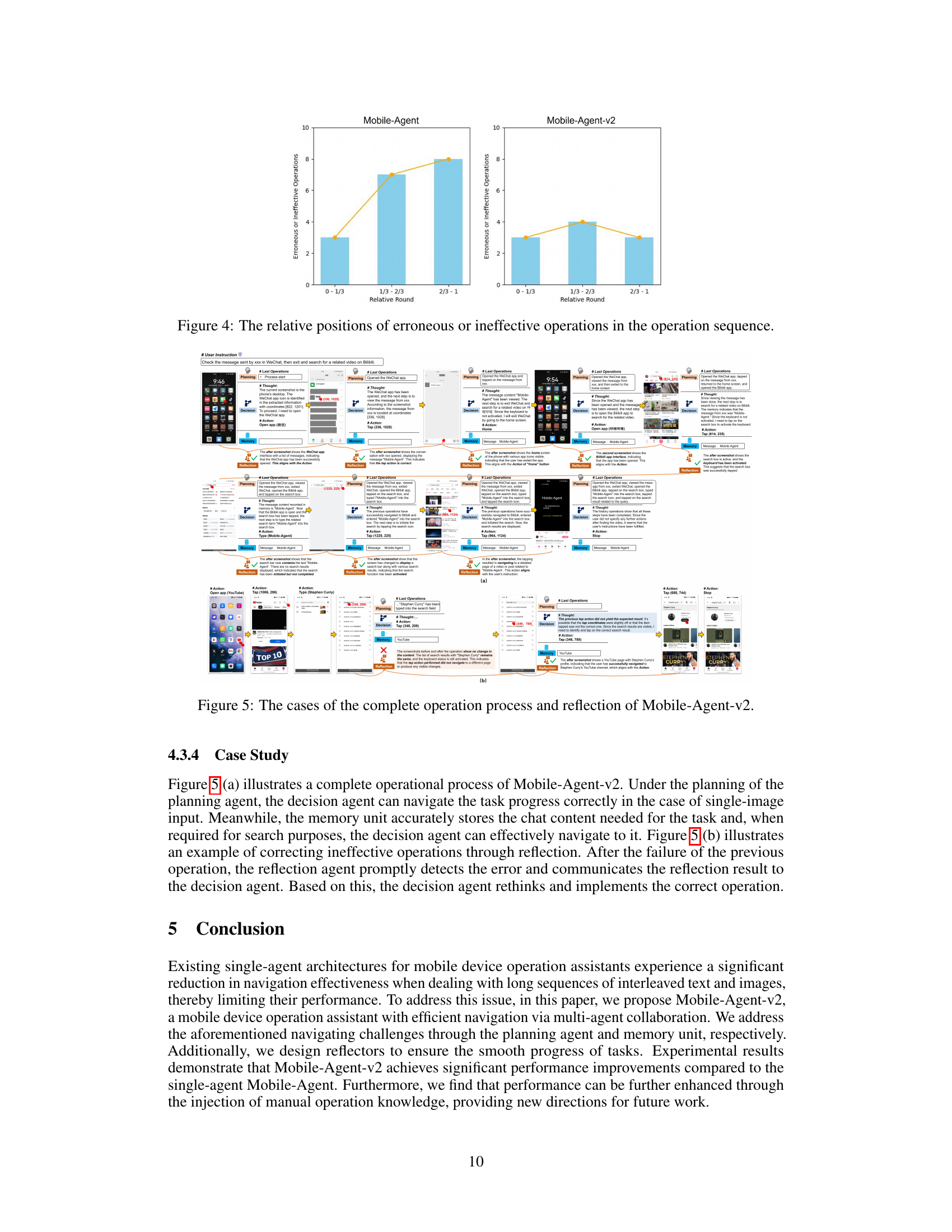
🔼 This figure shows the distribution of erroneous or ineffective operations across different stages of a task’s execution, comparing the single-agent Mobile-Agent and the multi-agent Mobile-Agent-v2. In Mobile-Agent, errors predominantly occur towards the end of the task sequence. However, Mobile-Agent-v2 demonstrates a more even distribution of errors across the task, indicating its improved resilience to the challenges posed by long operation sequences.
read the caption
Figure 4: The relative positions of erroneous or ineffective operations in the operation sequence.

🔼 This figure illustrates the challenges of mobile device operation tasks. It shows that completing a task often involves multiple steps across different screens. The task requires navigating both the overall progress (task progress navigation) and retrieving specific information from previous screens (focus content navigation). The length of the input sequences, which combines images and text from multiple screens, becomes increasingly long and complex as the task proceeds. This complexity makes it difficult for a single-agent system to effectively manage both the task progress and focus content.
read the caption
Figure 1: Mobile device operation tasks require navigating focus content and task progress from history operation sequences, where the focus content comes from previous screens. As the number of operations increases, the length of the input sequences grows, making it extremely challenging for a single-agent architecture to manage these two types of navigation effectively.
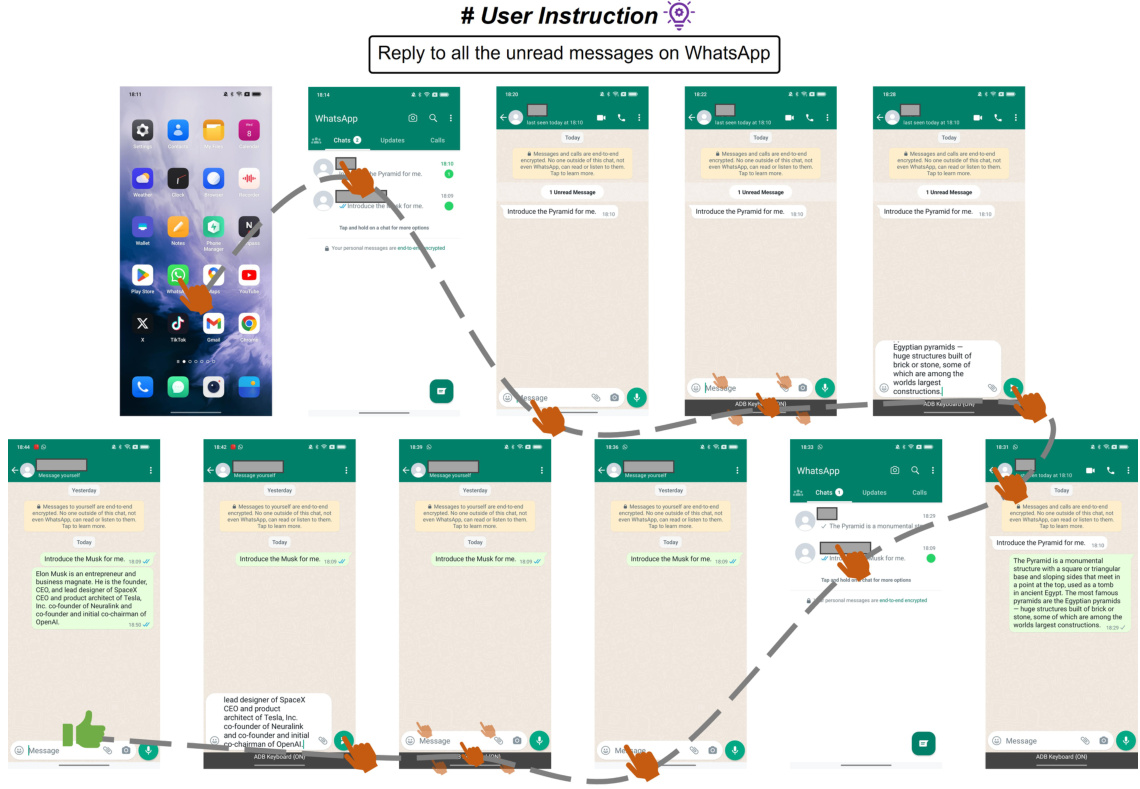
🔼 This figure illustrates the challenges of single-agent architectures in handling mobile device operation tasks. It highlights two key navigation challenges: navigating to the task’s current progress and retrieving relevant information (focus content) from previous screens. As the number of operations increases, the length of the input sequence to the agent grows significantly, making it difficult for a single agent to manage both aspects effectively. The diagram shows a visual representation of an illustrative task, demonstrating the complexity of information input and the task progression across multiple screens.
read the caption
Figure 1: Mobile device operation tasks require navigating focus content and task progress from history operation sequences, where the focus content comes from previous screens. As the number of operations increases, the length of the input sequences grows, making it extremely challenging for a single-agent architecture to manage these two types of navigation effectively.
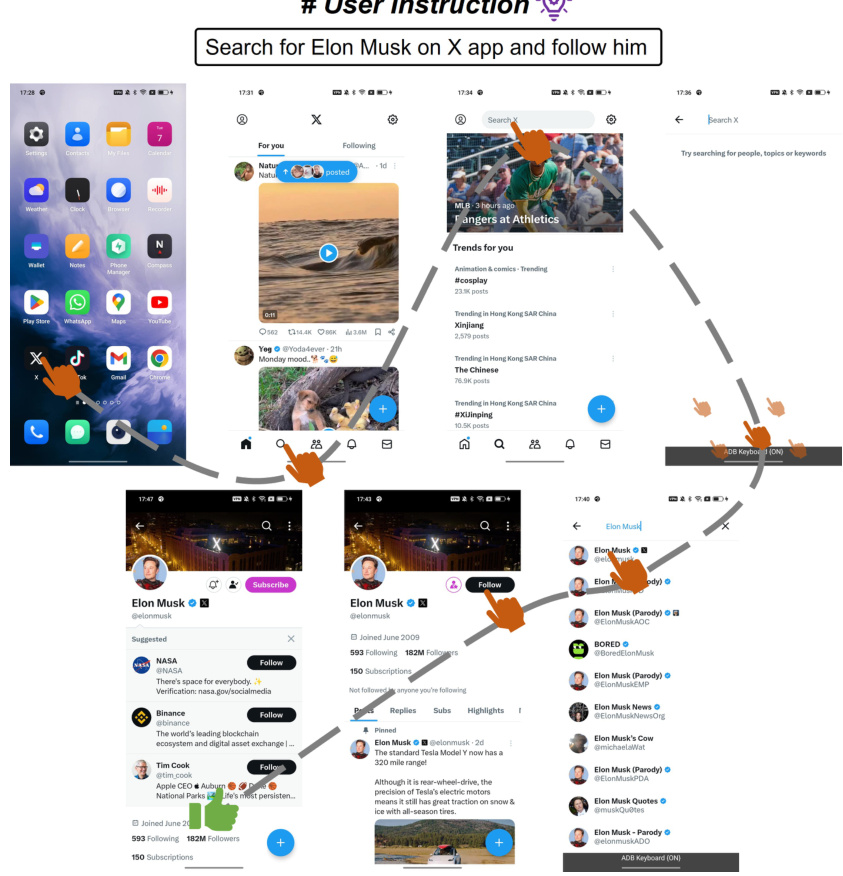
🔼 The figure illustrates the challenges of single-agent approaches in mobile device operation tasks. It highlights the dual navigation challenges: navigating task progress through a sequence of operations, and accessing relevant information (focus content) from previous screens. The complexity increases drastically with the number of steps and the interwoven image-text data format.
read the caption
Figure 1: Mobile device operation tasks require navigating focus content and task progress from history operation sequences, where the focus content comes from previous screens. As the number of operations increases, the length of the input sequences grows, making it extremely challenging for a single-agent architecture to manage these two types of navigation effectively.
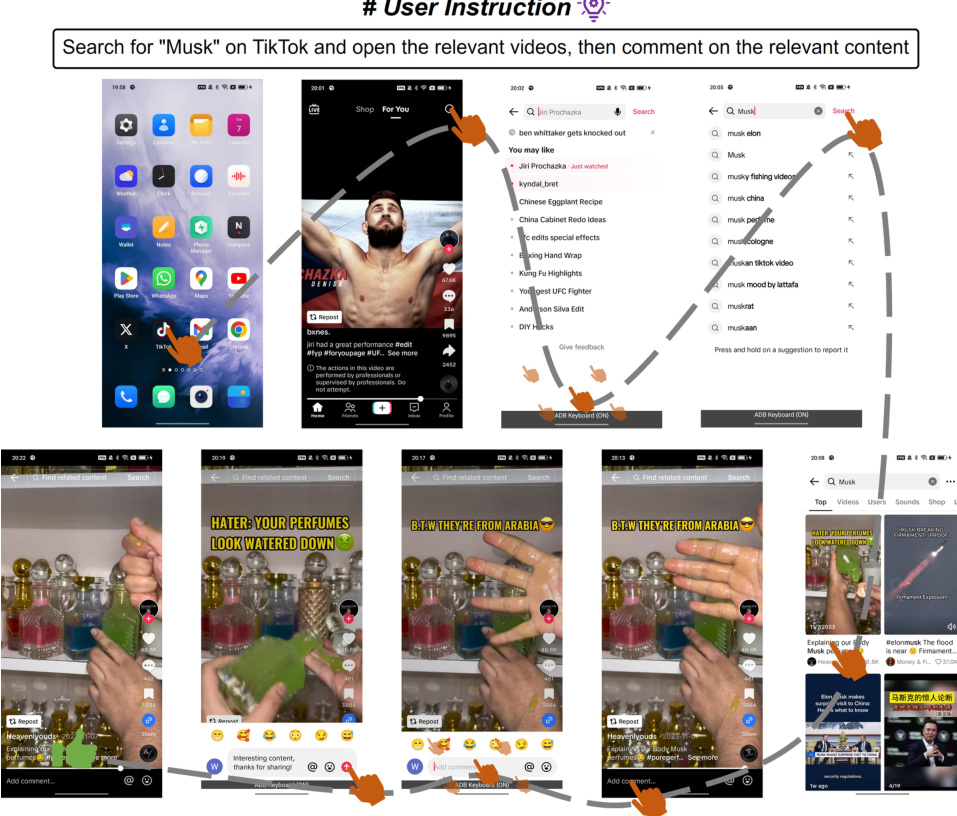
🔼 The figure illustrates the challenges of single-agent architectures in handling mobile device operation tasks. It highlights the complexities of navigating both the task progress (sequence of operations) and the focus content (information needed from previous screens). As the task progresses and the number of operations grows, the length of the input sequence increases dramatically, hindering the effectiveness of a single agent in managing both aspects.
read the caption
Figure 1: Mobile device operation tasks require navigating focus content and task progress from history operation sequences, where the focus content comes from previous screens. As the number of operations increases, the length of the input sequences grows, making it extremely challenging for a single-agent architecture to manage these two types of navigation effectively.
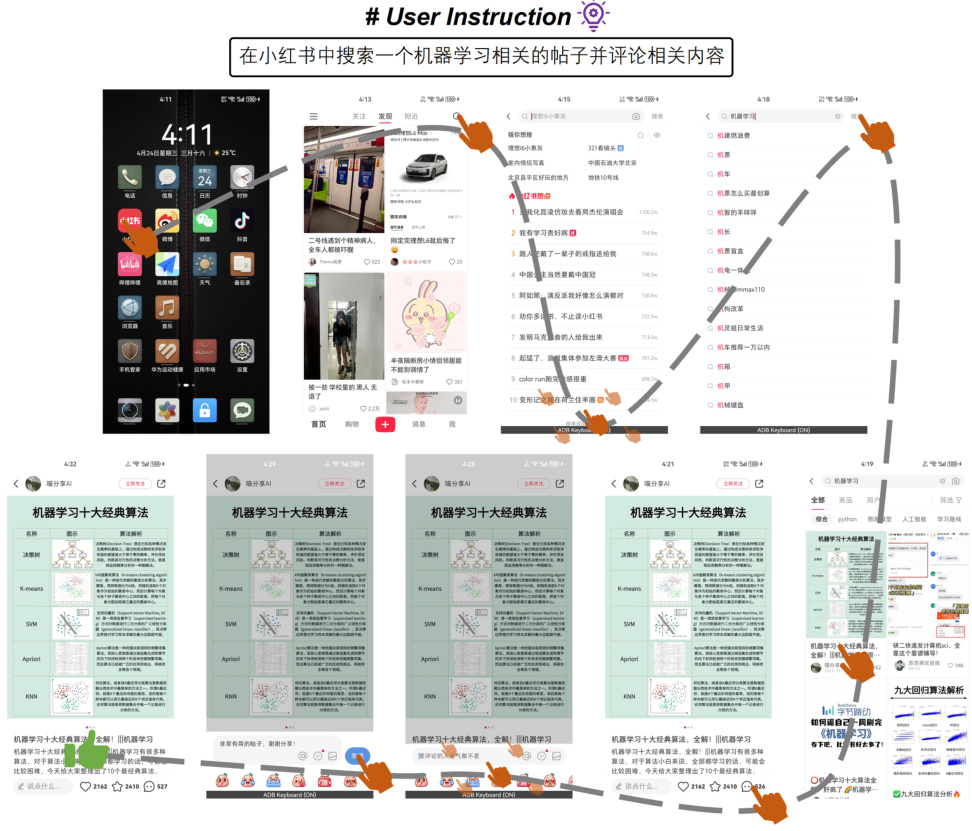
🔼 This figure illustrates the challenges in single-agent mobile device operation assistants. It shows how the task of operating a mobile device involves navigating both the current task progress (a sequence of operations) and retrieving specific information (focus content) from previous screens. As operations accumulate, the context length increases, making it difficult for a single agent to effectively manage both navigation aspects.
read the caption
Figure 1: Mobile device operation tasks require navigating focus content and task progress from history operation sequences, where the focus content comes from previous screens. As the number of operations increases, the length of the input sequences grows, making it extremely challenging for a single-agent architecture to manage these two types of navigation effectively.
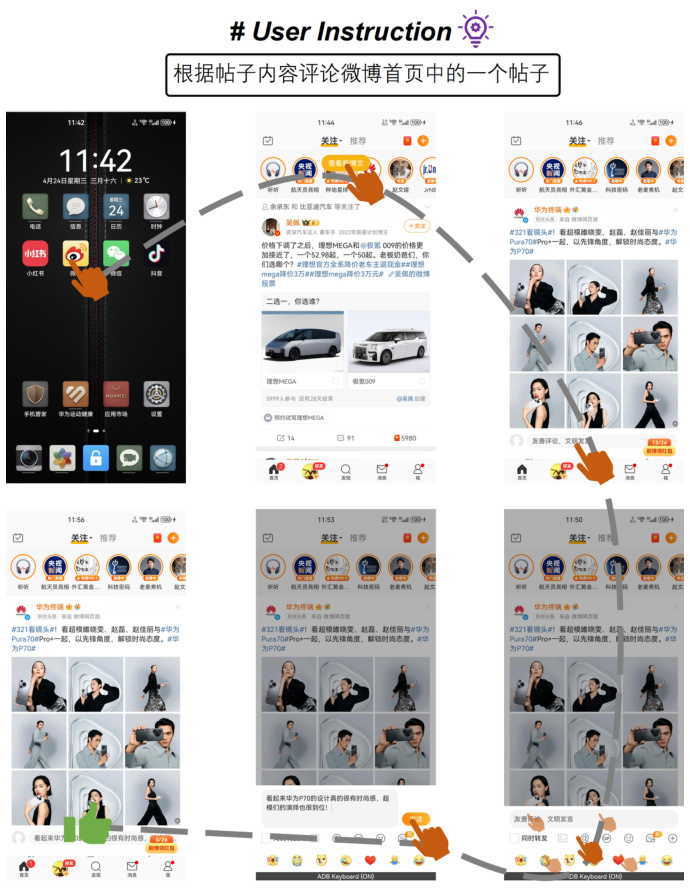
🔼 This figure illustrates the challenges of single-agent architectures in handling mobile device operation tasks. It highlights two key navigation challenges: navigating to the focus content (information needed from previous screens) and navigating the task progress (keeping track of the overall task flow). As the number of operations increases, the length of the input sequence (image and text data) becomes extremely long, making it difficult for a single agent to effectively manage both types of navigation simultaneously.
read the caption
Figure 1: Mobile device operation tasks require navigating focus content and task progress from history operation sequences, where the focus content comes from previous screens. As the number of operations increases, the length of the input sequences grows, making it extremely challenging for a single-agent architecture to manage these two types of navigation effectively.
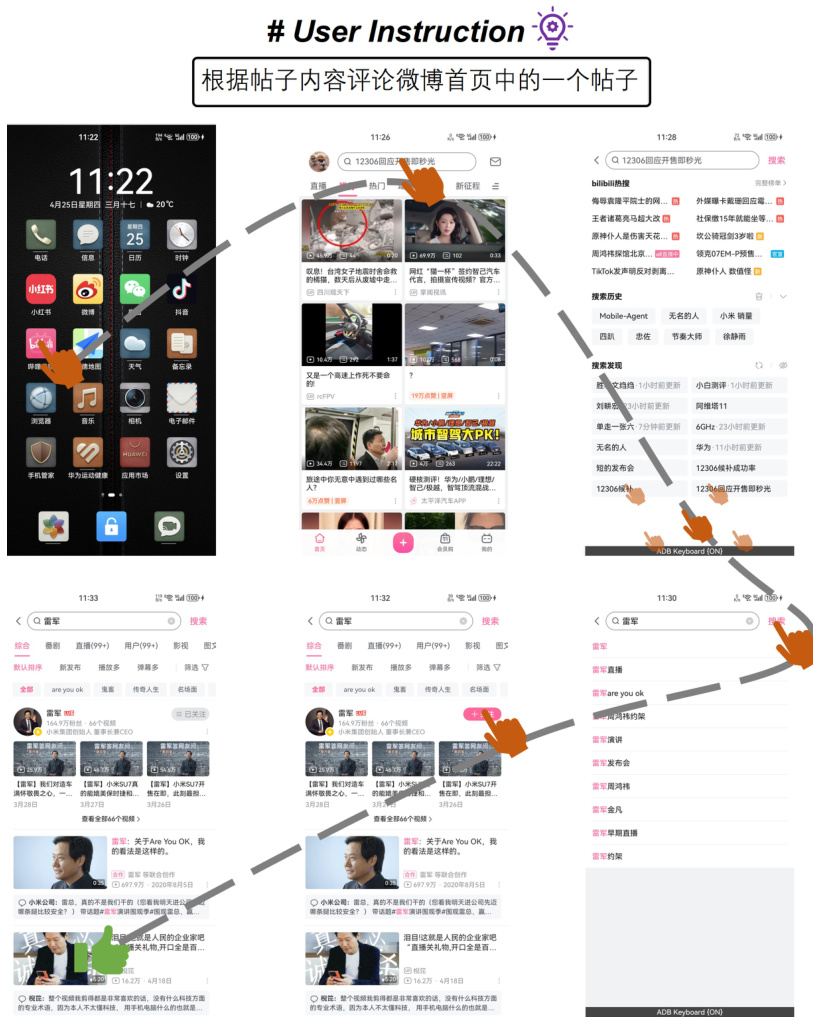
🔼 This figure illustrates the challenges of single-agent architectures in handling mobile device operation tasks. It shows that these tasks involve navigating both the current task’s progress (across multiple screens and operations) and retrieving specific information (focus content) from previous screens. As the number of operations increases, the length of the input sequence becomes excessively long, making it difficult for a single agent to manage both navigation aspects effectively.
read the caption
Figure 1: Mobile device operation tasks require navigating focus content and task progress from history operation sequences, where the focus content comes from previous screens. As the number of operations increases, the length of the input sequences grows, making it extremely challenging for a single-agent architecture to manage these two types of navigation effectively.
More on tables
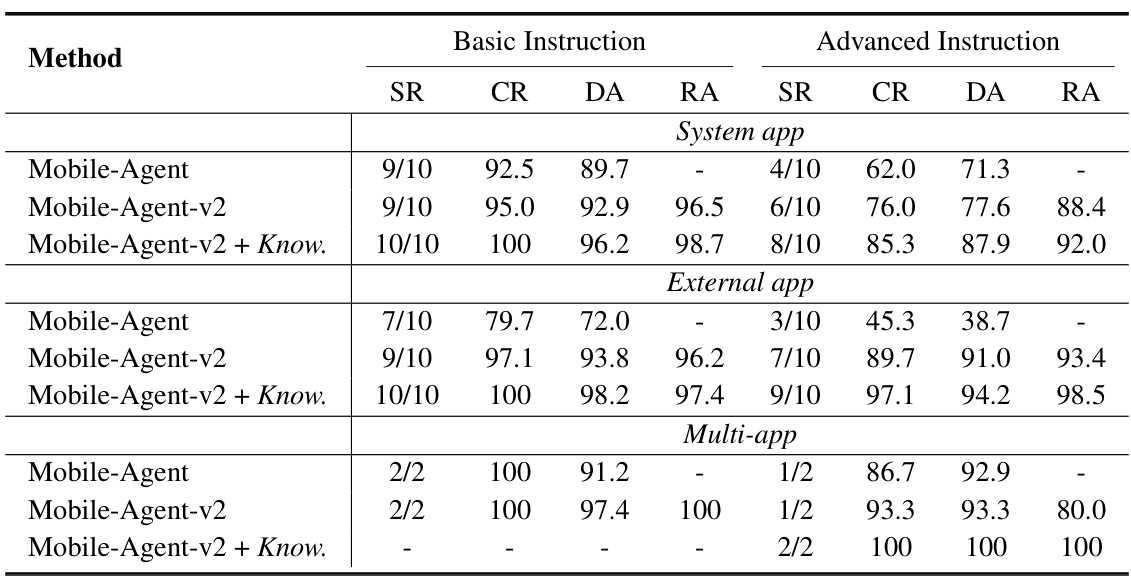
🔼 This table presents a dynamic evaluation of Mobile-Agent, Mobile-Agent-v2, and Mobile-Agent-v2 with injected knowledge on a non-English scenario. It shows the success rate (SR), completion rate (CR), decision accuracy (DA), and reflection accuracy (RA) for basic and advanced instructions, broken down by system apps, external apps, and multi-app tasks. The ‘Know.’ column indicates results when manual operation knowledge was added.
read the caption
Table 1: Dynamic evaluation results on non-English scenario, where the Know. represents manually injected operation knowledge.
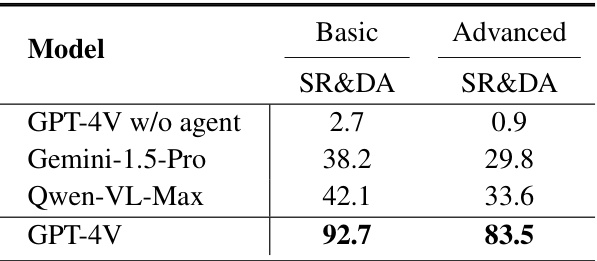
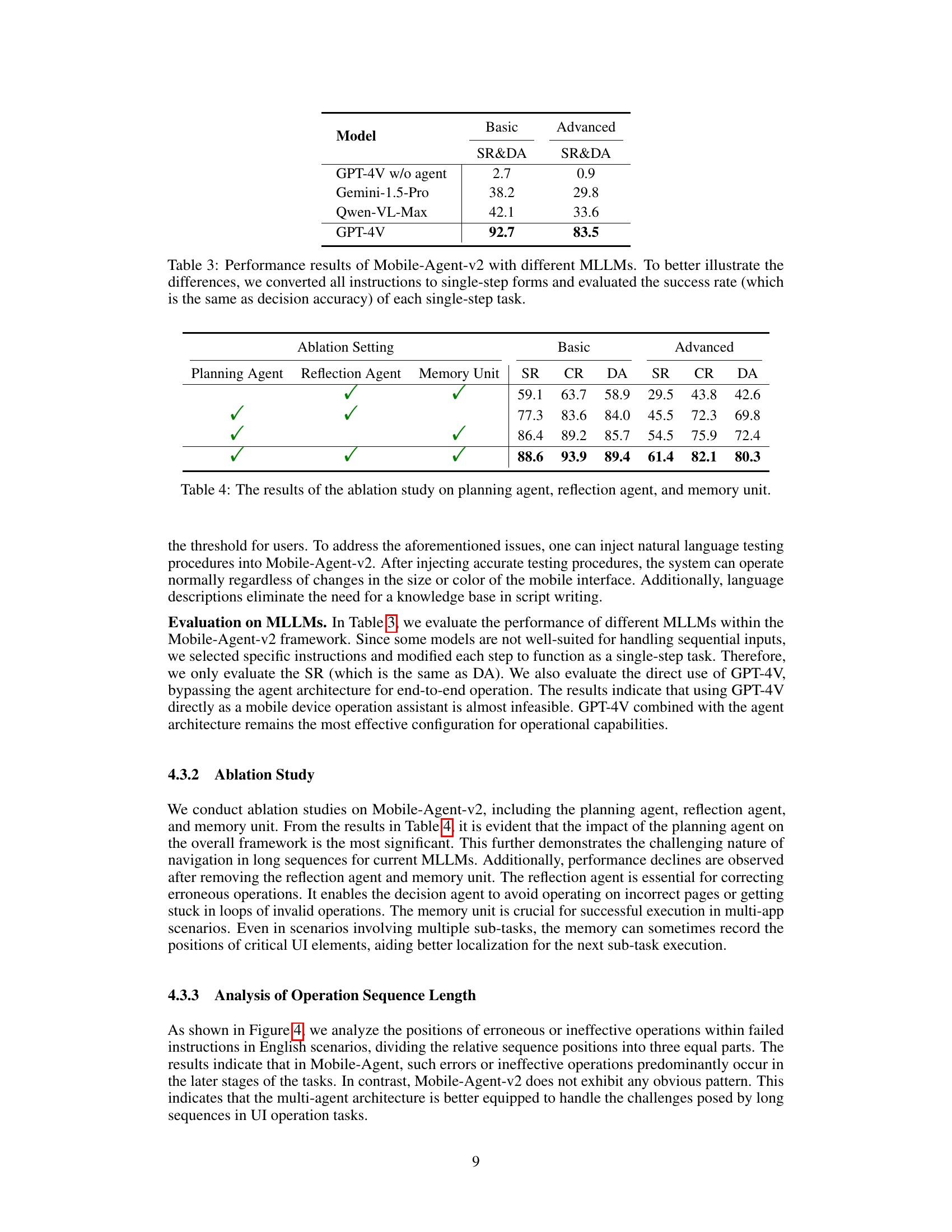
🔼 This table presents a comparison of the performance of Mobile-Agent-v2 using different large language models (LLMs). The models tested include GPT-4V without an agent, Gemini-1.5-Pro, Qwen-VL-Max, and GPT-4V. For better comparability, all instructions were simplified to single steps, and the success rate (equivalent to decision accuracy) for each single-step task was measured.
read the caption
Table 3: Performance results of Mobile-Agent-v2 with different MLLMs. To better illustrate the differences, we converted all instructions to single-step forms and evaluated the success rate (which is the same as decision accuracy) of each single-step task.
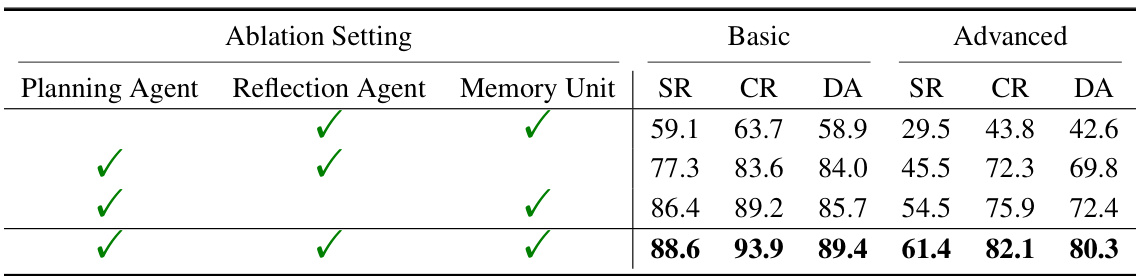
🔼 This ablation study analyzes the impact of each of the three agents (planning, decision, and reflection) and the memory unit on the performance of Mobile-Agent-v2. It shows the success rate (SR), completion rate (CR), decision accuracy (DA) for both basic and advanced instructions under different configurations. Removing any of the agents or the memory unit leads to performance degradation, highlighting their importance for effective mobile device operation assistance.
read the caption
Table 4: The results of the ablation study on planning agent, reflection agent, and memory unit.

🔼 This table presents a dynamic evaluation of Mobile-Agent-v2’s performance on a non-English scenario. It compares the results of three different methods: the original Mobile-Agent, Mobile-Agent-v2 (the proposed multi-agent approach), and Mobile-Agent-v2 with manually injected operational knowledge. The evaluation is broken down by instruction type (basic and advanced) and app type (system apps, external apps, and multi-app operations). Metrics include success rate (SR), completion rate (CR), decision accuracy (DA), and reflection accuracy (RA). The results show a significant improvement in performance for Mobile-Agent-v2, particularly in advanced tasks, which demonstrates the effectiveness of the multi-agent architecture.
read the caption
Table 1: Dynamic evaluation results on non-English scenario, where the Know. represents manually injected operation knowledge.
🔼 This table presents a dynamic evaluation of Mobile-Agent-v2’s performance on a non-English mobile device operating system. It compares the success rate (SR), completion rate (CR), decision accuracy (DA), and reflection accuracy (RA) of Mobile-Agent-v2 against a single-agent baseline (Mobile-Agent) across three types of tasks: basic instructions on system apps, advanced instructions on system apps, basic instructions on external apps, advanced instructions on external apps, and multi-app operations. An additional column shows the results when manual operation knowledge is injected into Mobile-Agent-v2.
read the caption
Table 1: Dynamic evaluation results on non-English scenario, where the Know. represents manually injected operation knowledge.
Full paper#