↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Partially observable environments pose significant challenges for reinforcement learning (RL), as agents only have access to partial information of the environment. However, the use of privileged information, such as access to underlying states from simulators, has led to significant empirical successes in training. This paper aims to understand the benefit of using privileged information. Previous empirical methods, like expert distillation and asymmetric actor-critic, lacked theoretical analysis to confirm the efficiency gains. This paper examines both paradigms and identifies their pitfalls and limitations, particularly in partially observable settings.
This research introduces novel algorithms that offer polynomial sample and quasi-polynomial computational complexities in both paradigms. It formalizes the expert distillation paradigm and demonstrates its potential shortcomings. A crucial contribution is the introduction of a new ‘deterministic filter condition’ under which expert distillation and the asymmetric actor-critic achieve provable efficiency. The study further extends this analysis to multi-agent reinforcement learning with information sharing using the popular CTDE framework (centralized training with decentralized execution), providing provable efficiency guarantees for practically inspired paradigms.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in reinforcement learning (RL) because it bridges the gap between empirical success and theoretical understanding of RL with privileged information. It provides provable guarantees for practically-used algorithms, offering a deeper insight into the efficiency and limitations of current approaches. This opens new avenues for designing efficient algorithms with provable sample and computational complexities, particularly for multi-agent RL. The work will likely stimulate the development of new algorithms and further investigations into the theoretical underpinnings of these methods.
Visual Insights#

This figure presents the results of four different algorithms on four different POMDP problem instances. The algorithms are: Belief-weighted optimistic AAC (ours), Optimistic Asymmetric VI (ours), Asymmetric Q, and Vanilla AAC. The four cases represent four different problem sizes, which vary in the number of states, actions, observations, and the horizon. The figure shows that the Belief-weighted optimistic AAC algorithm (developed by the authors) achieves the highest reward and lowest sample complexity for each problem size.
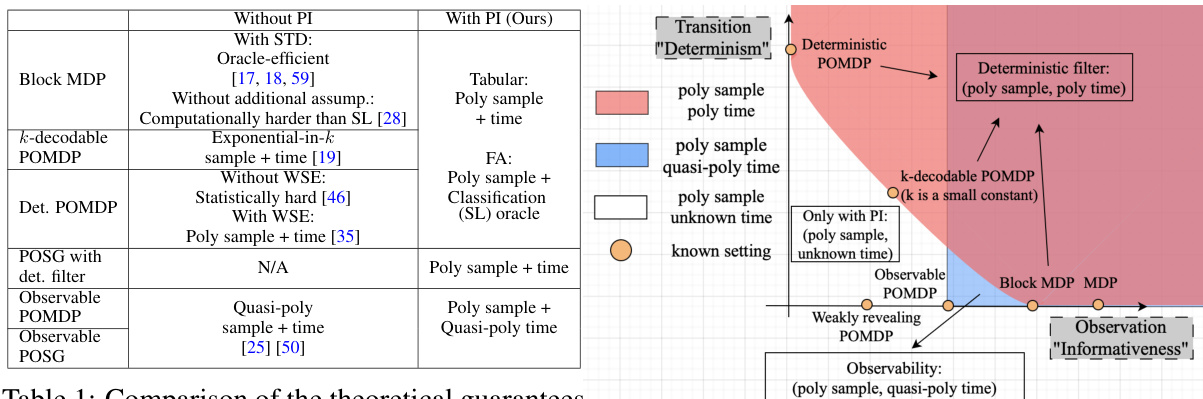
This table compares the theoretical guarantees for Partially Observable Markov Decision Processes (POMDPs) and Partially Observable Stochastic Games (POSGs) with and without privileged information. It shows the sample and time complexities for various algorithms under different model assumptions. The assumptions vary in restrictiveness, ranging from strong structural assumptions (like deterministic transitions) to weaker ones (like well-separated emissions). The table highlights that privileged information can significantly improve the efficiency of algorithms for certain POMDP/POSG classes.
Full paper#



















