TL;DR#
Current custom diffusion models struggle with
catastrophic forgetting (forgetting old concepts when learning new ones) and concept neglect (failing to incorporate all specified concepts during image generation) in continual learning scenarios. This significantly limits their adaptability and real-world applicability. The models usually need to store all old personalized concepts for fine-tuning, leading to high computational cost and privacy concerns.
To address these issues, this paper introduces a novel Concept-Incremental text-to-image Diffusion Model (CIDM). CIDM employs a concept consolidation loss and an elastic weight aggregation module to mitigate catastrophic forgetting. It also incorporates a context-controllable synthesis strategy to prevent concept neglect. Experimental results demonstrate that CIDM outperforms existing models, offering a significant improvement in both single and multi-concept image generation, and in custom image editing and style transfer.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on continual learning and customization of diffusion models. It introduces a novel framework to address the challenge of catastrophic forgetting and concept neglect in a concept-incremental setting, paving the way for more robust and adaptable AI systems. The proposed solutions are valuable for developing practical applications and offer new research directions in improving the efficiency and versatility of AI models.
Visual Insights#
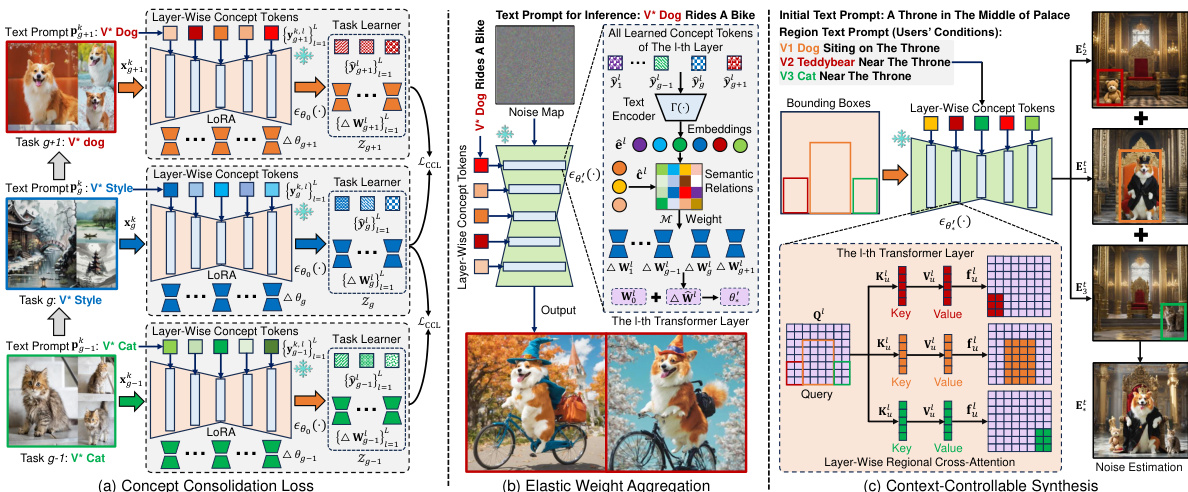
🔼 This figure illustrates the architecture of the proposed Concept-Incremental text-to-image Diffusion Model (CIDM). It highlights three key components: (a) Concept Consolidation Loss which addresses catastrophic forgetting by learning both task-specific and task-shared knowledge; (b) Elastic Weight Aggregation that merges low-rank weights of old concepts during inference to avoid catastrophic forgetting; and (c) Context-Controllable Synthesis to handle concept neglect by leveraging region features and noise estimation to conform to user-specified conditions. Each component is shown as a separate sub-figure to facilitate understanding.
read the caption
Figure 1: Diagram of the proposed CIDM to address the CIFC problem. It consists of (a) a concept consolidation loss, (b) an elastic weight aggregation module to resolve catastrophic forgetting, and (c) a context-controllable synthesis strategy to address the challenge of concept neglect.
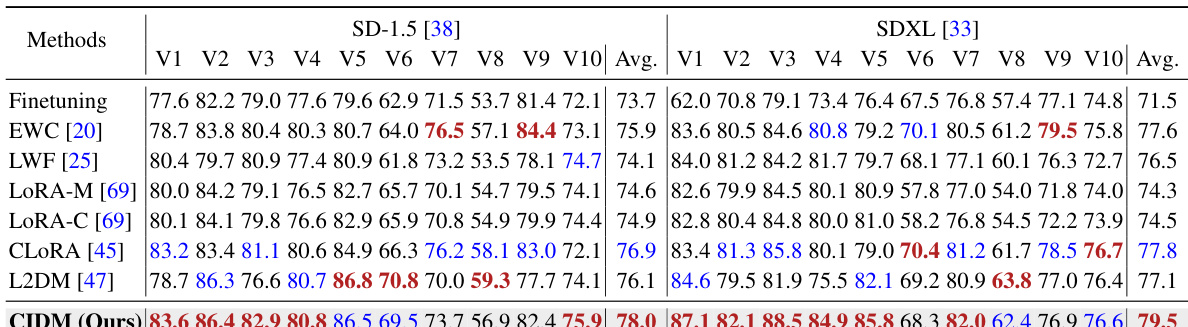
🔼 This table presents a quantitative comparison of the image-alignment (IA) scores achieved by different methods for single-concept customization tasks using two different pretrained diffusion models: Stable Diffusion 1.5 (SD-1.5) and SDXL. The methods compared include various continual learning techniques (Finetuning, EWC, LWF), multi-LoRA approaches (LoRA-M, LoRA-C), and the proposed CIDM. The table shows the IA scores for each method on ten different concepts (V1-V10) for both SD-1.5 and SDXL, along with the average IA score across all concepts.
read the caption
Table 1: Comparisons (IA) of single-concept customization synthesized by SD-1.5 and SDXL.
In-depth insights#
Concept-Incremental Learning#
Concept-Incremental Learning (CIL) tackles the challenge of continuously learning new concepts without forgetting previously acquired ones. This is crucial for real-world applications where knowledge evolves, and systems need to adapt. Catastrophic forgetting, a major hurdle in CIL, is the significant loss of performance on old tasks when learning new ones. Strategies to mitigate this include regularization techniques that penalize changes to previously learned parameters, rehearsal methods that replay past data during training, and dynamic network architectures that expand to accommodate new knowledge. Knowledge distillation transfers knowledge from old models to new ones, promoting better generalization. Memory-based approaches store samples from past tasks, allowing for a form of experience replay. The effectiveness of each approach is context-dependent, with trade-offs between memory efficiency, computational cost, and performance. A key consideration in CIL is the incremental nature of learning, which mandates efficient strategies for updating models and managing memory. The design of effective CIL systems requires careful selection of techniques based on the specific application and constraints.
Catastrophic Forgetting#
Catastrophic forgetting, a significant challenge in continual learning, describes the phenomenon where a model trained on new tasks abruptly forgets previously learned information. This is particularly problematic for complex tasks like text-to-image generation where maintaining a diverse set of learned concepts is crucial. The core issue stems from the model’s parameter updates for new tasks overwriting or interfering with the representations needed for old ones. Approaches to mitigate this often involve techniques to consolidate previous knowledge, like regularization methods that encourage the preservation of older representations, or memory-based methods that replay past training data. Concept-Incremental Flexible Customization (CIFC), as discussed in the provided research paper, directly confronts this challenge. By employing strategies such as elastic weight aggregation and a concept consolidation loss, the model aims to balance learning new concepts with retaining established ones, addressing the limitations of simple parameter fine-tuning which often leads to catastrophic forgetting. The success of these techniques hinges on effectively balancing the exploration of task-specific information and the exploitation of shared knowledge across tasks. Future research will likely focus on more sophisticated memory mechanisms and regularization approaches to even more gracefully handle continual learning across increasingly complex datasets.
Concept Consolidation#
Concept consolidation, in the context of continual learning for text-to-image models, addresses the critical challenge of catastrophic forgetting. As models learn new concepts, they tend to overwrite previously learned information, leading to a loss of performance on older tasks. Effective concept consolidation techniques aim to preserve knowledge acquired across multiple training phases without sacrificing performance on newly introduced concepts. This often involves carefully integrating new learning into existing knowledge representations, possibly through mechanisms such as regularization, weight averaging, or memory replay. The success of concept consolidation hinges on the ability to find a balance between exploiting task-specific information and leveraging shared knowledge among concepts, facilitating efficient and robust continual adaptation of the model.
Elastic Weight Agg#
The heading ‘Elastic Weight Aggregation’ suggests a method for dynamically combining the learned weights of a model across multiple training stages or tasks. This is crucial in scenarios like continual learning where a model must adapt to new information without forgetting previously acquired knowledge. The ’elasticity’ likely refers to a mechanism that allows for flexible weighting of older concepts based on their relevance to the current task. This could involve a weighting scheme that prioritizes recent knowledge but still retains access to past learning, offering a balance between new information and avoiding catastrophic forgetting. The aggregation part implies a process of intelligently merging or combining these weighted knowledge components, possibly through a weighted average or a more sophisticated technique. The key innovation may reside in the specific weighting and merging strategy employed, which is likely tailored to minimize the loss of old knowledge while effectively incorporating new information. A well-designed method would exhibit robustness and efficiently manage the growing size of the model’s knowledge base as it continually learns.
Future Work#
The ‘Future Work’ section of a research paper on continually adapting text-to-image diffusion models for flexible customization could explore several promising avenues. Improving the efficiency of the proposed Concept-Incremental Diffusion Model (CIDM) is crucial, potentially through architectural optimizations or more efficient training strategies. Addressing the concept neglect problem more comprehensively, perhaps by incorporating more sophisticated attention mechanisms or exploring alternative conditioning methods, is another key area. Furthermore, extending CIDM to handle different modalities, such as video generation, or incorporating user feedback directly into the model’s training loop, would significantly broaden its application. Investigating the robustness of CIDM to adversarial attacks would also be valuable. Finally, a thorough empirical analysis comparing CIDM’s performance against a broader range of existing models on more diverse and larger-scale datasets would strengthen the paper’s conclusions and guide future development.
More visual insights#
More on figures

🔼 This figure shows a qualitative comparison of single-concept customization results generated by different models, including EWC, LWF, CLORA, L2DM, LORA-M, LORA-C, and the proposed CIDM. Each row represents a specific concept (V1-V10) and shows the generated images for each model. The purpose is to visually demonstrate the effectiveness of the CIDM in generating high-quality, detailed images with minimal loss of concept identity, especially when compared to the other methods.
read the caption
Figure 2: Some qualitative comparisons of single-concept customization generated by SD-1.5 [38].

🔼 This figure illustrates the architecture of the proposed Concept-Incremental text-to-image Diffusion Model (CIDM). It highlights three key components: (a) a concept consolidation loss to prevent catastrophic forgetting of previously learned concepts, (b) an elastic weight aggregation module to effectively combine the knowledge from previous tasks, and (c) a context-controllable synthesis strategy to address the issue of concept neglect during multi-concept synthesis. The diagram visually explains how these components work together to allow the model to continuously learn new concepts while retaining previous ones and synthesizing images that meet user-specified conditions.
read the caption
Figure 1: Diagram of the proposed CIDM to address the CIFC problem. It consists of (a) a concept consolidation loss, (b) an elastic weight aggregation module to resolve catastrophic forgetting, and (c) a context-controllable synthesis strategy to address the challenge of concept neglect.

🔼 This figure shows a qualitative comparison of custom image editing results for different methods, including CLORA, L2DM, and the proposed CIDM (Ours). Each row represents a different concept and shows the input image along with the results from each method. The results highlight the superior performance of the proposed CIDM in maintaining the integrity and identity of the customized objects within the generated images.
read the caption
Figure 4: Comparisons of custom image editing.

🔼 This figure shows qualitative comparisons of custom style transfer results generated by different methods including CLORA, L2DM, LORA-M, LORA-C, and the proposed CIDM (Ours). Each row represents a different target style, and the input image is shown in the first column. The following columns depict the results produced by each method, allowing for a visual comparison of their effectiveness in transferring the target style to the input image.
read the caption
Figure 5: Comparisons of custom style transfer.

🔼 This figure shows the architecture of the proposed Concept-Incremental text-to-image Diffusion Model (CIDM). It highlights three key components: (a) a concept consolidation loss that helps the model avoid forgetting previously learned concepts; (b) an elastic weight aggregation module that combines the weights of previously learned concepts in a flexible way; and (c) a context-controllable synthesis strategy that allows users to control the content of the generated images based on their preferences. The overall design aims to solve the problem of Concept-Incremental Flexible Customization (CIFC), where the model must continuously learn new concepts without forgetting old ones and accommodate user-specified contextual details.
read the caption
Figure 1: Diagram of the proposed CIDM to address the CIFC problem. It consists of (a) a concept consolidation loss, (b) an elastic weight aggregation module to resolve catastrophic forgetting, and (c) a context-controllable synthesis strategy to address the challenge of concept neglect.

🔼 This figure shows the ablation study results for Task-Specific Knowledge (TSP) and Task-Shared Knowledge (TSH) components in the Concept Consolidation Loss. It demonstrates that both TSP and TSH are crucial for the model’s performance, showing improved image generation quality compared to the baseline, especially when both TSP and TSH are used together. This highlights the effectiveness of the proposed method in exploring task-specific and task-shared knowledge for better concept preservation and generalization.
read the caption
Figure 7: Ablation studies of the TSP and TSH.

🔼 This figure shows the architecture of the proposed Concept-Incremental text-to-image Diffusion Model (CIDM). It illustrates three key components designed to overcome the challenges of the Concept-Incremental Flexible Customization (CIFC) problem: (a) a concept consolidation loss to mitigate catastrophic forgetting, (b) an elastic weight aggregation module for inference to prevent forgetting old concepts, and (c) a context-controllable synthesis strategy to address concept neglect in multi-concept generation. The diagram visually depicts how these components work together to enable continual learning of new customization tasks while maintaining performance on previously learned concepts.
read the caption
Figure 1: Diagram of the proposed CIDM to address the CIFC problem. It consists of (a) a concept consolidation loss, (b) an elastic weight aggregation module to resolve catastrophic forgetting, and (c) a context-controllable synthesis strategy to address the challenge of concept neglect.

🔼 This figure compares the results of single-concept customization across different methods, including EWC, LWF, CLORA, L2DM, LoRA-M, LoRA-C, and the proposed CIDM. Each row represents a different concept (V3 cat, V5 teddy bear, V9 cat, V1 dog, V7 dog, V2 duck toy, V1 dog), and each column represents a different method. The image quality and adherence to the prompt are visually compared across different methods, demonstrating the improved performance of the proposed CIDM in maintaining concept fidelity and detail even after multiple consecutive concept learning tasks.
read the caption
Figure 10: Some qualitative comparisons of single-concept customization generated by SD-1.5 [38].

🔼 This figure displays qualitative results for single-concept customization using the SDXL model. It compares different methods (EWC, LWF, CLORA, L2DM, LoRA-M, and the proposed CIDM) across ten different customization tasks (V1-V10). Each row shows the results for a specific prompt, demonstrating each method’s ability to generate images according to the specified concept. The figure highlights the proposed CIDM’s superior ability to generate high-fidelity images that accurately reflect the intended concepts.
read the caption
Figure 11: Some qualitative comparisons of single-concept customization generated by SDXL [33].

🔼 This figure shows the architecture of the proposed Concept-Incremental text-to-image Diffusion Model (CIDM). It highlights three key components: a concept consolidation loss to prevent catastrophic forgetting, an elastic weight aggregation module to combine information from previous tasks, and a context-controllable synthesis strategy to ensure relevant contexts are generated according to user-provided conditions. The diagram visually explains how these components work together to address the challenges of the Concept-Incremental Flexible Customization (CIFC) problem.
read the caption
Figure 1: Diagram of the proposed CIDM to address the CIFC problem. It consists of (a) a concept consolidation loss, (b) an elastic weight aggregation module to resolve catastrophic forgetting, and (c) a context-controllable synthesis strategy to address the challenge of concept neglect.

🔼 This figure shows a qualitative comparison of custom style transfer results under the Concept-Incremental Flexible Customization (CIFC) setting. Different methods are compared: CLORA, L2DM, LoRA-M, LoRA-C, and the proposed CIDM. Each row shows the target style image, the input image, and the generated images by each method for that style. The results demonstrate the effectiveness of the proposed CIDM in preserving the style consistently even with new concept introductions.
read the caption
Figure 13: Some qualitative comparisons of custom style transfer under the CIFC setting.
More on tables
🔼 This table presents a quantitative comparison of single-concept customization performance using image alignment (IA) as the metric. It compares the performance of several methods, including the proposed CIDM, across ten different concept customization tasks (V1-V10) using two different pretrained diffusion models: SD-1.5 and SDXL. Higher IA scores indicate better performance.
read the caption
Table 1: Comparisons (IA) of single-concept customization synthesized by SD-1.5 and SDXL.
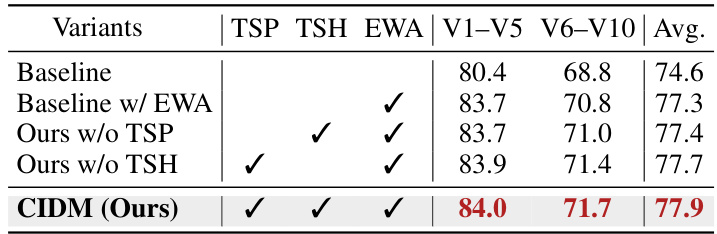
🔼 This table presents the results of ablation studies performed to evaluate the impact of each module (TSP, TSH, EWA) within the proposed CIDM model on single-concept customization tasks. The performance is measured in terms of Image Alignment (IA) scores, separately for tasks involving objects (V1-V5) and styles (V6-V10). The baseline represents the model without any of the ablation modules. Each row shows the IA score averages for the V1-V5 and V6-V10 tasks, and overall average IA score across all tasks. The results demonstrate the individual and combined contributions of each module to the overall performance of the model.
read the caption
Table 3: Ablation studies of single-concept customization.

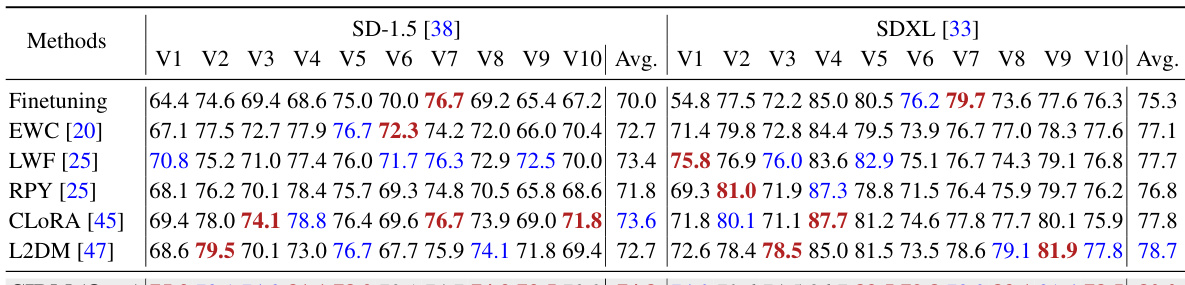
🔼 This table presents a quantitative comparison of image-alignment (IA) scores for single-concept customization results generated using two different diffusion models (SD-1.5 and SDXL). It compares the performance of several methods, including EWC, LWF, LORA-M, LORA-C, CLORA, L2DM, and the proposed CIDM. The results are presented as average IA scores across ten different concept customization tasks (V1-V10), providing a comprehensive evaluation of each method’s ability to maintain the quality and characteristics of individual concepts during synthesis.
read the caption
Table 1: Comparisons (IA) of single-concept customization synthesized by SD-1.5 and SDXL.

🔼 This table presents a quantitative comparison of single-concept customization results achieved using different methods on two distinct datasets (SD-1.5 and SDXL). The Image Alignment (IA) metric is employed to evaluate the similarity between synthesized images and ground truth images for ten different concepts (V1-V10). The table allows for a direct comparison of the performance of the proposed CIDM model against several other state-of-the-art (SOTA) methods, highlighting the improvements in image fidelity achieved by CIDM.
read the caption
Table 1: Comparisons (IA) of single-concept customization synthesized by SD-1.5 and SDXL.
Full paper#



















