TL;DR#
Diffusion models excel in generating high-quality images, but their multi-step inference process is computationally expensive, limiting their applications. Existing distillation methods often struggle to balance preserving the original model’s trajectory and achieving step compression, leading to performance degradation or domain shifts. This necessitates the development of efficient distillation methods that optimize for both speed and quality.
Hyper-SD tackles this challenge with a novel framework that synergistically combines trajectory preservation and reformulation. It introduces Trajectory Segmented Consistency Distillation, progressively distilling the model in pre-defined time-step segments to enhance accuracy and mitigate errors. Human feedback learning is integrated to improve low-step generation performance and overcome limitations of distillation. Finally, the framework employs score distillation and a unified LoRA to further improve one-step generation. Extensive results show that Hyper-SD outperforms state-of-the-art methods across various metrics, demonstrating significant improvements in efficiency and quality for both SDXL and SD1.5.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Hyper-SD, a novel framework that significantly accelerates diffusion models while maintaining high-quality image generation. This addresses a critical limitation of diffusion models, their high computational cost, and opens new avenues for research in efficient generative AI. The proposed trajectory segmented consistency distillation and incorporation of human feedback is highly relevant to current research trends in diffusion model optimization and generative AI. The resulting increase in efficiency makes diffusion models more accessible and applicable for broader real-world applications.
Visual Insights#

🔼 This figure visually compares the image generation results of Hyper-SDXL with three other methods: SDXL-Base, SDXL-Lightning, and SDXL-Turbo. Four different image prompts were used for each model, showcasing the visual differences in output quality and style across the various models, particularly highlighting Hyper-SDXL’s performance.
read the caption
Figure 1. The visual comparison between our Hyper-SDXL and other methods. From the first to the fourth column, the prompts for these images are (1) a dog wearing a white t-shirt, with the word 'hyper' written on it (2) abstract beauty, approaching perfection, pure form, golden ratio, minimalistic, unfinished,... (3) a crystal heart laying on moss in a serene zen garden ... (4) anthropomorphic art of a scientist stag, victorian inspired clothing by krenz cushart ...., respectively.
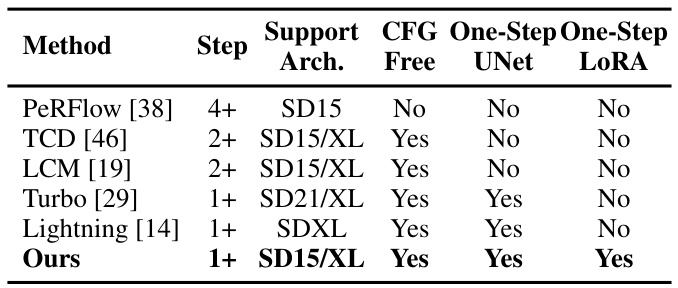
🔼 This table compares the proposed Hyper-SD model with other state-of-the-art (SOTA) acceleration approaches for diffusion models. It shows the number of steps required for inference, the architecture used (SD15 or SDXL), whether classifier-free guidance (CFG) is supported, and whether the acceleration is achieved using a one-step UNet or LoRA. The table highlights that Hyper-SD achieves SOTA performance with support for CFG, one-step UNet and one-step LoRA, demonstrating its efficiency and flexibility.
read the caption
Table 1. Comparison with other acceleration approaches.
In-depth insights#
Segmented Consistency#
The concept of “Segmented Consistency” in the context of diffusion models offers a novel approach to improving efficiency and quality in image generation. It suggests dividing the typical multi-step diffusion process into smaller, manageable segments. By enforcing consistency within each segment, the method aims to mitigate the accumulation of errors that often plague traditional distillation techniques. This segmented approach allows for a more gradual and controlled reduction in inference steps, leading to better preservation of the original ODE trajectory. Progressive training, starting with many segments and gradually decreasing their number, further refines the model’s ability to generate consistent outputs at various inference levels, ultimately achieving efficient yet high-quality results in a low-step regime. The core strength lies in its synergistic combination with other techniques, such as human feedback learning and score distillation, enhancing the overall performance beyond what any single approach could accomplish alone. This strategy represents a significant advance in accelerating diffusion models for efficient high-quality image synthesis.
Human Feedback Boost#
The concept of ‘Human Feedback Boost’ in the context of a research paper on accelerating diffusion models is a crucial aspect. It suggests integrating human preferences to refine the model’s output, which is particularly valuable in the low-step inference regime where automated methods might fall short. This human-in-the-loop approach addresses the limitations of solely relying on algorithmic optimization. By incorporating human feedback, the model can learn to generate images that better align with desired aesthetic qualities and visual perceptual aspects, going beyond objective metrics to capture subjective preferences. This is critical since purely objective metrics often fail to fully capture the nuances of human judgment. The specific implementation could involve a reward model trained on human preferences, guiding the model to improve upon its initial outputs. This process could involve comparing different versions of a generated image, ranking them based on aesthetic appeal, and fine-tuning the model to match those preferences. The combination of human feedback with techniques like Trajectory Segmented Consistency Distillation helps improve both the speed and quality of image generation, enhancing the effectiveness of the approach. Furthermore, using human feedback to guide the model in a low-step setting helps to mitigate any quality loss inherent in the step compression process. This overall strategy balances the efficiency gains of model compression with the quality-boosting effects of human feedback.
Unified LoRA Approach#
The Unified LoRA approach presents a significant advancement in efficient image synthesis. By unifying the various LoRAs trained across different stages of the Trajectory Segmented Consistency Distillation (TSCD) process, it enables consistent, high-quality generation across multiple inference steps (1, 2, 4, 8 steps) using a single, unified LoRA plugin. This eliminates the need for separate LoRAs for each step count, simplifying inference and reducing computational overhead. The effectiveness is demonstrated by achieving comparable image quality and text-to-image alignment with the original model, even in the one-step setting. The unified LoRA promotes the practicality and real-world applicability of the model, making it easier to integrate into diverse applications requiring varied speed-quality trade-offs. It effectively addresses the issue of performance degradation in low-step settings, a common limitation of traditional methods. Furthermore, the unified LoRA approach is shown to be compatible with ControlNet and adaptable to different base models, enhancing its flexibility and usability across various generative image synthesis scenarios. This unified approach represents a significant step towards seamless integration and broader usability of accelerated diffusion models.
Ablation Study Results#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a research paper, ‘Ablation Study Results’ would detail the performance of the model as each component is removed. Key insights would emerge from observing which components significantly impact performance. A drop in accuracy with a specific component’s removal highlights its importance. Conversely, a negligible performance change indicates redundancy or areas for potential simplification. The results section would likely present quantitative metrics (e.g., accuracy, F1-score, precision, recall) showing performance changes across different ablation configurations. Visualizations like bar charts or line graphs could effectively illustrate these changes. A well-written ablation study strengthens the paper by providing evidence for the model’s design choices, demonstrating the necessity of particular components, and suggesting avenues for future optimization. Carefully examining the results helps determine the most crucial parts of the model and assess their relative importance.
Future Directions#
The paper’s core contribution lies in developing Hyper-SD, a novel framework that efficiently accelerates image synthesis in diffusion models. Future research could focus on enhancing Hyper-SD’s capabilities by exploring different architectures and training techniques. For example, integrating advanced techniques like diffusion transformers or exploring alternative distillation methods beyond the current trajectory-segmented consistency model could improve performance and efficiency further. Another promising avenue is investigating the interplay between human feedback and consistency distillation, potentially through reinforcement learning or other advanced optimization strategies. This would allow for a more refined control over the model’s output, ensuring both high-quality visuals and alignment with user preferences. Finally, robustness and generalization capabilities could be enhanced through extensive testing across diverse datasets and prompting strategies. Addressing limitations like compatibility with existing tools and reducing computational costs for high-resolution images remains vital. By addressing these future directions, Hyper-SD’s impact on the broader generative AI field could be significantly expanded.
More visual insights#
More on figures
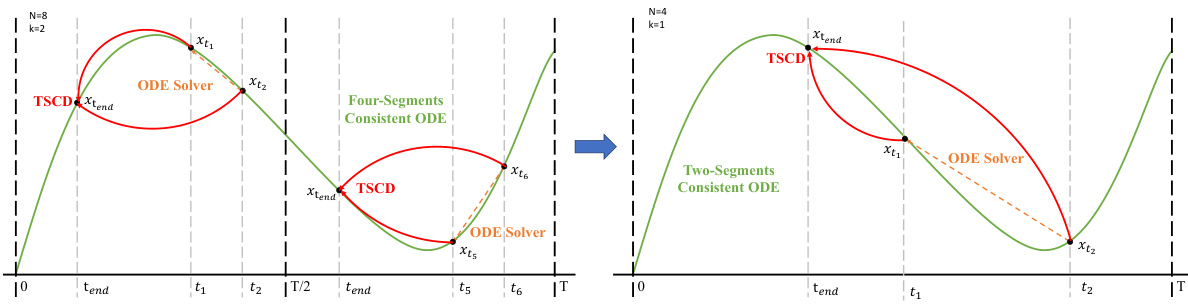
🔼 This figure illustrates the two-stage process of Trajectory Segmented Consistency Distillation (TSCD). The first stage (left panel) divides the time steps into four segments and performs consistency distillation within each segment, resulting in a four-segment consistent ODE trajectory. The second stage (right panel) uses the results from the first stage to train a model that provides a two-segment consistent ODE trajectory, effectively reducing the number of segments and improving efficiency and model fitting. The arrows in the figure show the flow of the process.
read the caption
Figure 2. An illustration of the two-stage Trajectory Segmented Consistency Distillation. The first stage involves consistency distillation in two separate time segments: [0, T] and [1, T] to obtain the two segments consistency ODE. Then, this ODE trajectory is adopted to train a global consistency model in the subsequent stage.
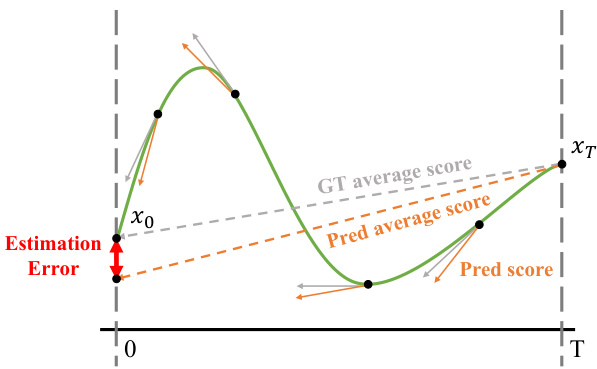
🔼 This figure illustrates the concept of score distillation by comparing the performance of score-based models and consistency models. The x-axis represents the time steps, while the y-axis represents the average score. The green curve shows the ground truth (GT) average score, while the orange dashed line shows the predicted average score of the consistency model. The black dots indicate the predicted scores at specific time steps. The red arrow highlights the estimation error of the score-based model compared to the consistency model. The figure shows that the consistency model is able to produce more accurate predictions closer to the ground truth, while the score-based model has a larger estimation error.
read the caption
Figure 3. Score distillation comparison between score-based model and consistency model. The estimated score produced by the score-based model may exhibit a greater estimation error than the consistency model.
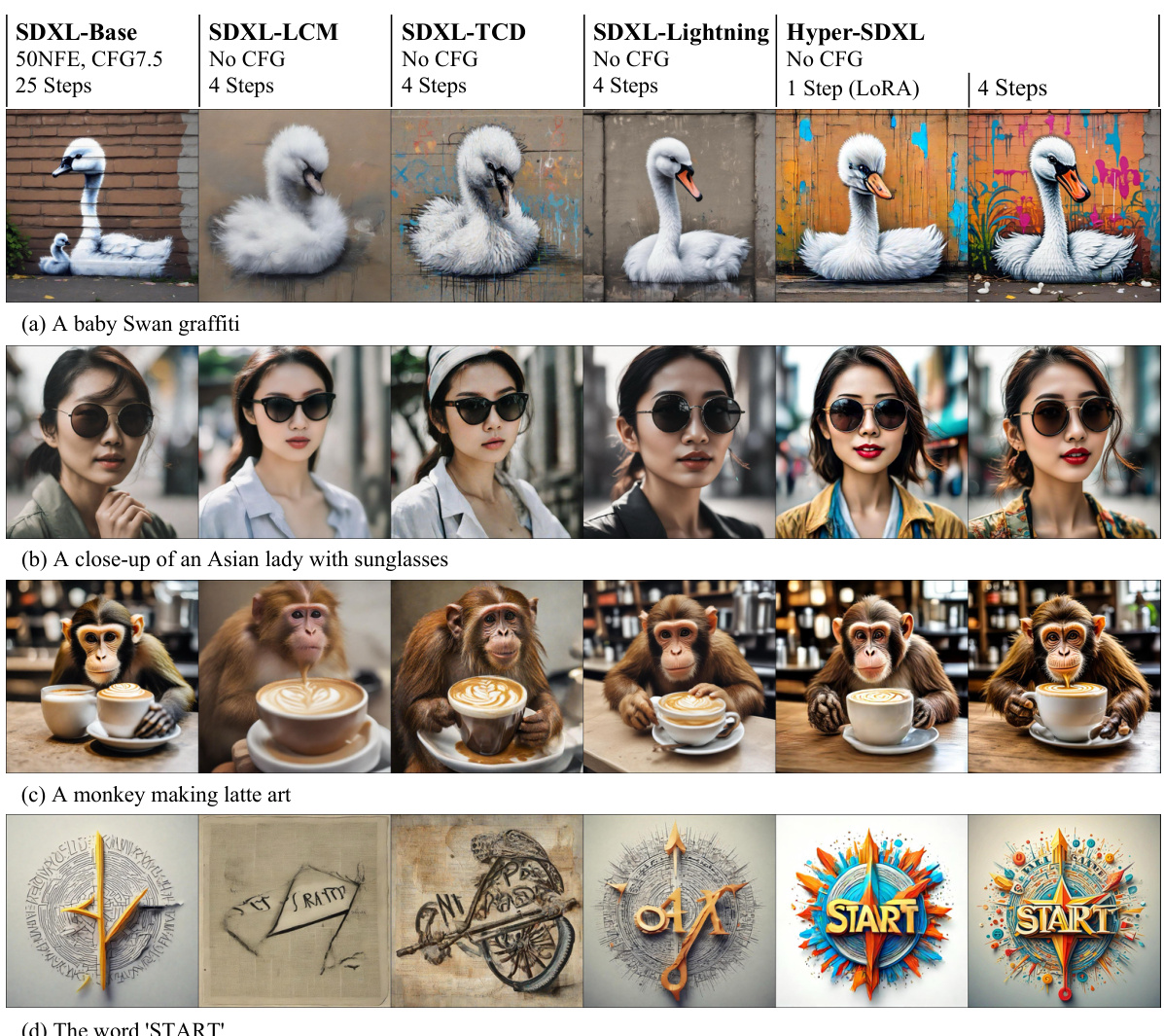
🔼 This figure compares the image generation quality of Hyper-SDXL against other methods (SDXL-Turbo, SDXL-Lightning, and SDXL-Base) using four different prompts. Each column represents a different prompt, showcasing Hyper-SDXL’s performance across various styles and complexities, emphasizing its ability to generate high-quality images even with a small number of inference steps.
read the caption
Figure 1. The visual comparison between our Hyper-SDXL and other methods. From the first to the fourth column, the prompts for these images are (1) a dog wearing a white t-shirt, with the word 'hyper' written on it (2) abstract beauty, approaching perfection, pure form, golden ratio, minimalistic, unfinished,... (3) a crystal heart laying on moss in a serene zen garden ... (4) anthropomorphic art of a scientist stag, victorian inspired clothing by krenz cushart ...., respectively.

🔼 This figure presents the results of a user study comparing the preference rates for images generated by Hyper-SD and other methods. The chart shows the percentage of users who preferred each method’s images, broken down by the number of inference steps and whether LoRA or UNet was used. The results visually demonstrate the superiority of Hyper-SD in terms of user preference across various conditions.
read the caption
Figure 5. The user study about the comparison between our method and other methods.

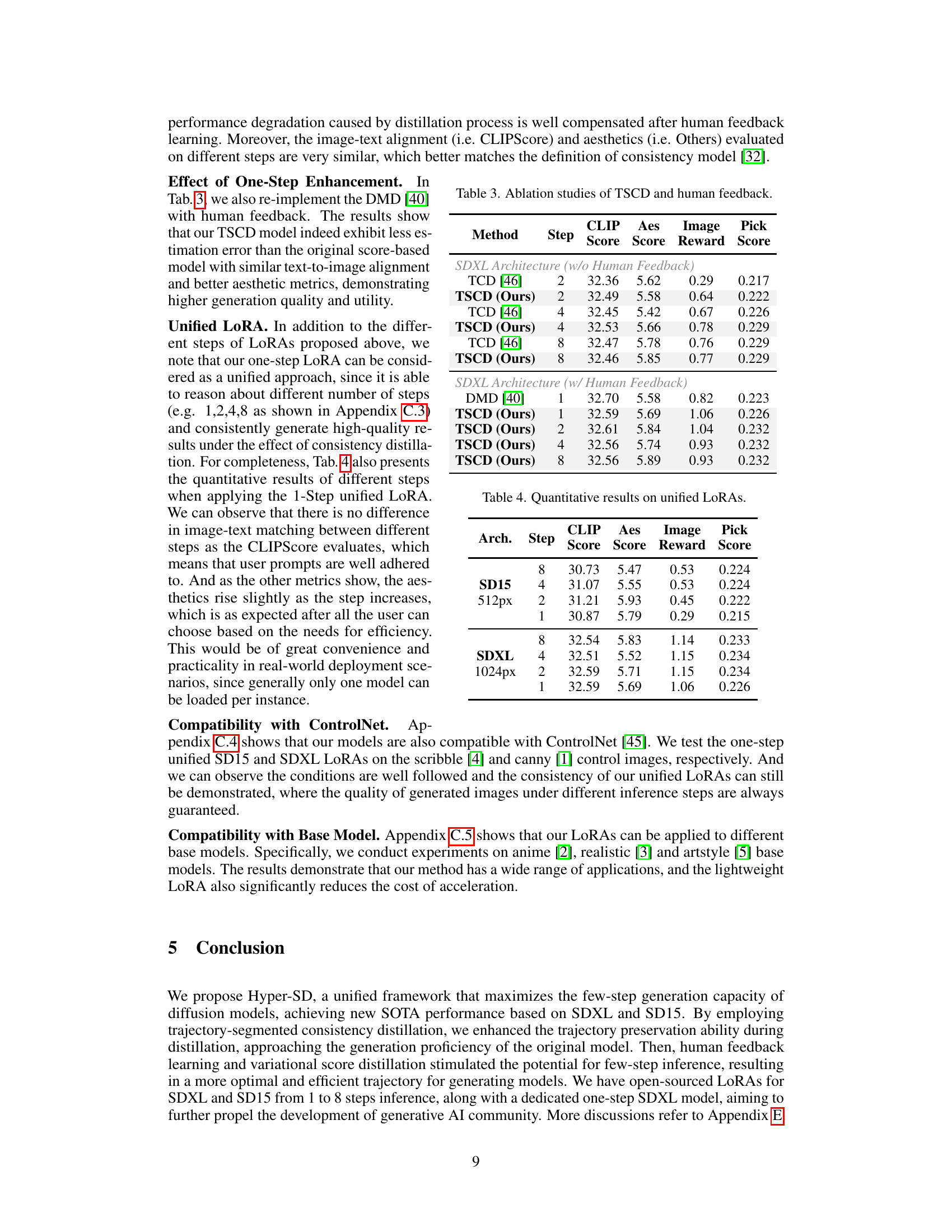
🔼 This figure compares image generation results of different methods on the SD15 architecture using LoRA-based approaches. It shows four different prompts and their generated images by the baseline model (SD15-Base), SD15-LCM, SD15-TCD, SD15-PeRFlow and Hyper-SD15. Hyper-SD15 is the proposed method, and the comparison highlights its superior performance using only 1 step, compared to other methods requiring 4 or 25 steps to achieve similar quality.
read the caption
Figure 6. Qualitative comparisons with LoRA-based approaches on SD15 architecture.

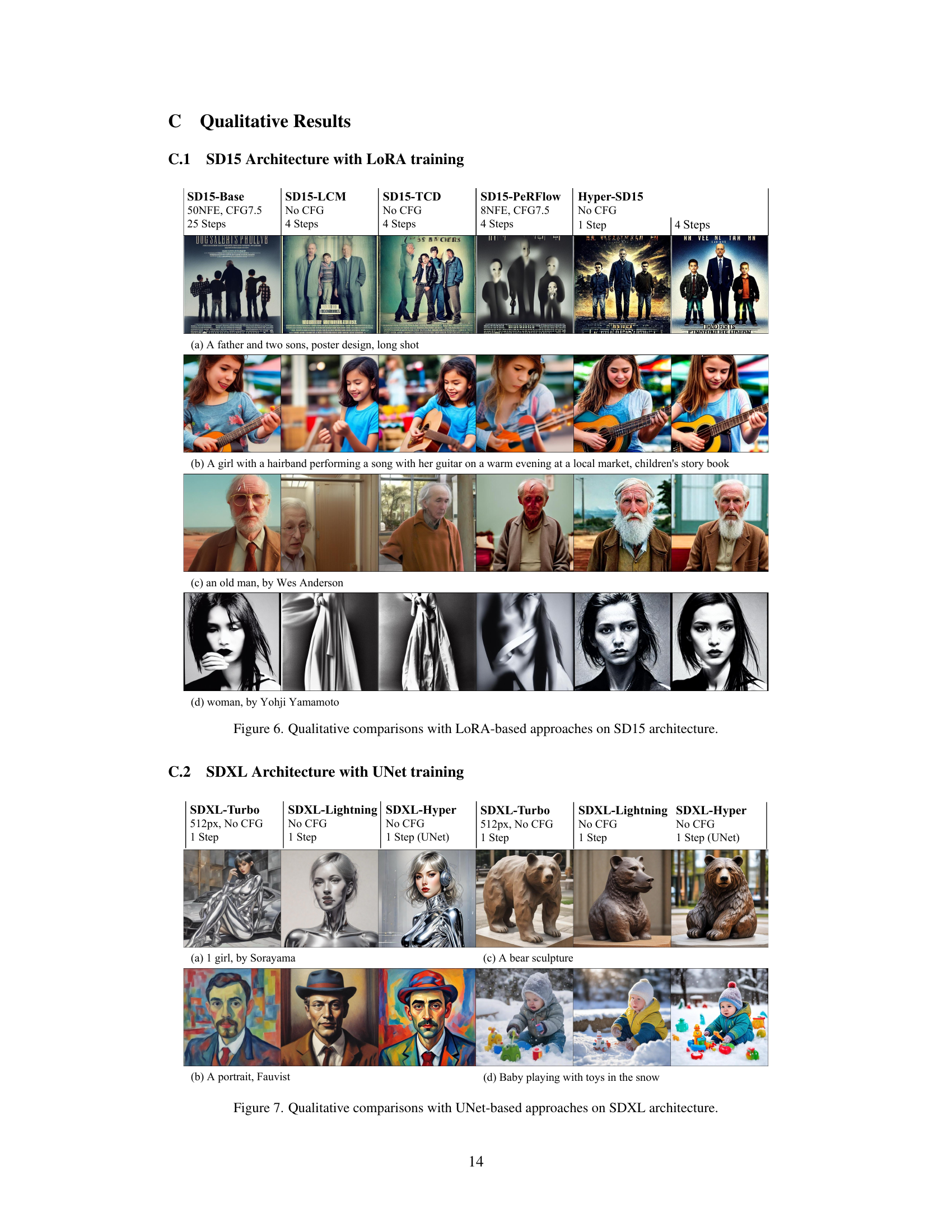
🔼 This figure compares the image generation quality of several models (SDXL-Turbo, SDXL-Lightning, and Hyper-SDXL) using different approaches (UNet-based) on the SDXL architecture. It showcases four different prompts and their respective generated images to illustrate the visual differences between the methods. The figure highlights Hyper-SDXL’s ability to generate high-quality images, even with a single step. This shows the efficacy of the proposed Hyper-SD model in terms of image quality when compared to other approaches.
read the caption
Figure 7. Qualitative comparisons with UNet-based approaches on SDXL architecture.

🔼 This figure demonstrates the results of using a unified LoRA for both Hyper-SD15 and Hyper-SDXL models. The unified LoRA is designed to work effectively across different numbers of inference steps (1, 2, 4, and 8 steps). The images in each row show the output generated from the same prompt at varying step counts, providing a visual comparison of consistency and quality across different inference steps. The prompts used are diverse, ranging from descriptions of nature to more complex scenes like racing cars or parks.
read the caption
Figure 8. Qualitative results on unified LoRAs.

🔼 This figure demonstrates the compatibility of the proposed Hyper-SD model’s unified LoRA with ControlNet. Two examples are shown: one using a scribble control image and the other using a canny edge control image. For each control image, the generated images using the unified LoRA at different inference steps (1, 2, 4, and 8 steps) are displayed, showcasing the model’s consistent performance across various numbers of inference steps, despite using ControlNet’s additional constraints. This highlights the robustness and versatility of Hyper-SD.
read the caption
Figure 9. Our unified LoRAs are compatible with ControlNet. The examples are conditioned on either scribble or canny images.

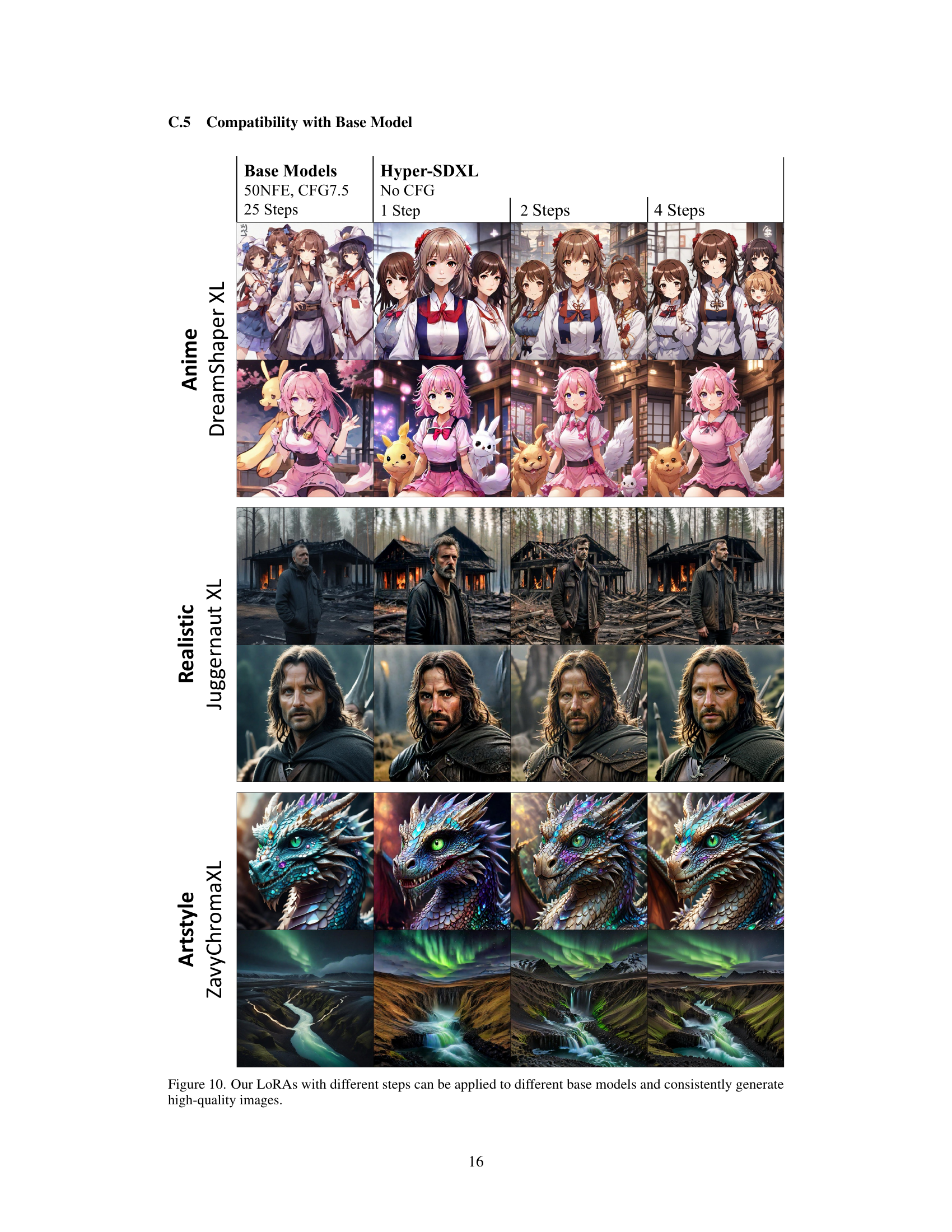
🔼 This figure demonstrates the versatility of the proposed Hyper-SD model. It shows that the same LoRA (Low-Rank Adaptation) models, trained using the Hyper-SD method and with varying numbers of inference steps (1, 2, and 4), can be successfully applied to different base diffusion models. These base models represent various artistic styles and levels of realism, ranging from anime-style images (DreamShaper XL) to photorealistic portraits (Juggernaut XL) and fantasy art (ZavyChromaXL). The consistent high quality of the generated images across all base models and inference steps highlights the effectiveness and generalizability of the Hyper-SD approach.
read the caption
Figure 10. Our LoRAs with different steps can be applied to different base models and consistently generate high-quality images.
More on tables
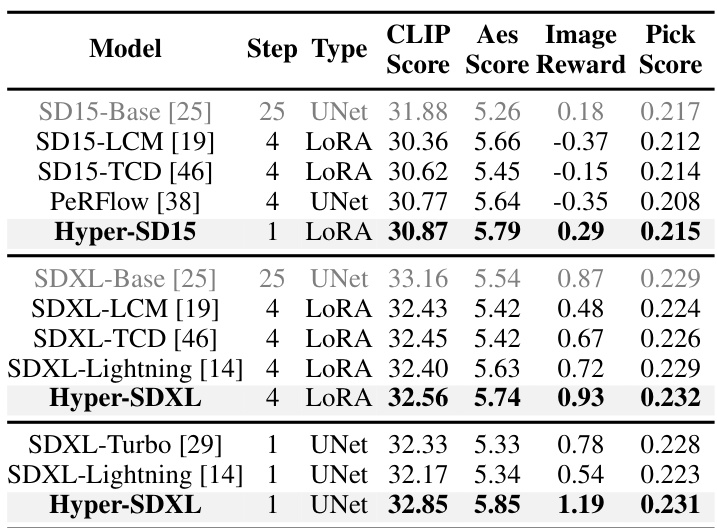
🔼 This table presents a quantitative comparison of Hyper-SD15 and Hyper-SDXL against several state-of-the-art (SOTA) methods for accelerating diffusion models. The comparison uses SD15-Base and SDXL-Base as baselines, and includes other acceleration methods such as LCM, TCD, PerFlow, and Lightning. Evaluation metrics include CLIP Score, Aes Score, ImageReward score, and Pick Score across different numbers of inference steps (1, 4, and 25). The table highlights the best performance achieved by each method for each metric and step, showing Hyper-SD’s improved performance, especially at lower step counts.
read the caption
Table 2. Quantitative comparisons with state-of-the-arts on SD15 and SDXL architectures. The best result is highlighted in bold.

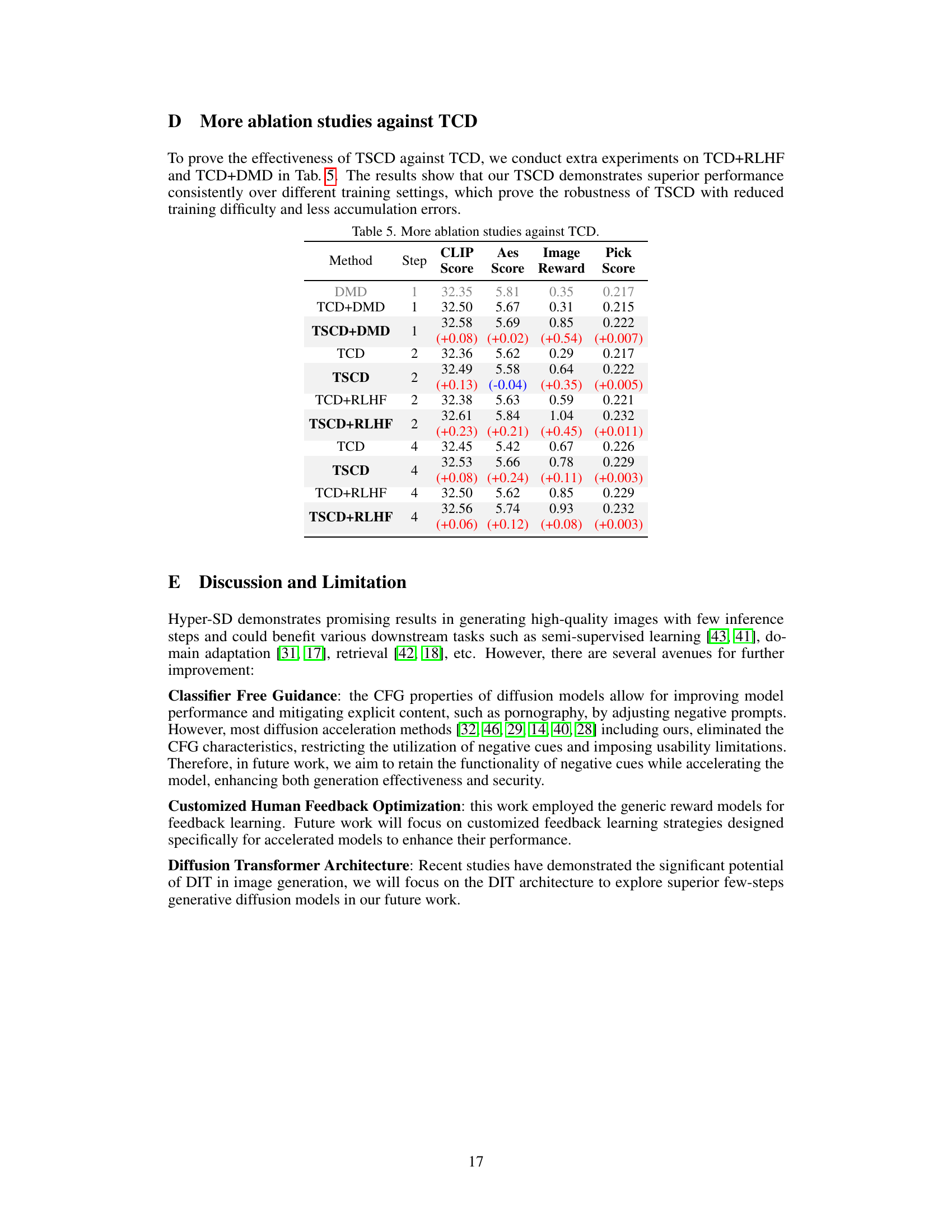
🔼 This table presents the results of ablation studies conducted to evaluate the impact of Trajectory Segmented Consistency Distillation (TSCD) and human feedback on the performance of the proposed model. It compares the performance metrics (CLIP Score, Aes Score, Image Reward, and Pick Score) across different numbers of inference steps (1, 2, 4, and 8) for both the SDXL architecture with and without human feedback. The results show the relative contributions of TSCD and human feedback to the overall performance.
read the caption
Table 3. Ablation studies of TSCD and human feedback.
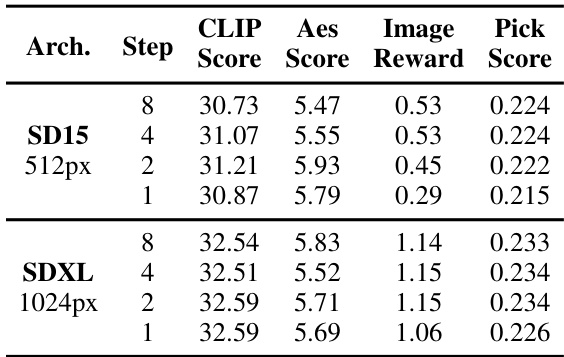
🔼 This table presents a quantitative comparison of the proposed Hyper-SD model with state-of-the-art methods for accelerating image generation using diffusion models. It compares performance on both SD15 (512px) and SDXL (1024px) architectures across multiple metrics, including CLIP Score, Aes Score, ImageReward Score, and Pick Score, for various numbers of inference steps (1, 2, 4, and 8). The best-performing model for each metric and step count is highlighted in bold, showcasing Hyper-SD’s superior performance.
read the caption
Table 2. Quantitative comparisons with state-of-the-arts on SD15 and SDXL architectures. The best result is highlighted in bold.
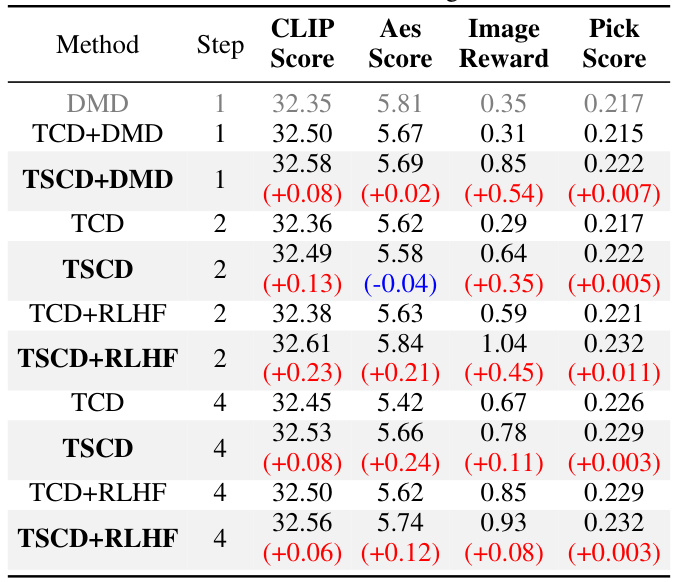
🔼 This table presents the quantitative results of ablation studies conducted on the Trajectory Segmented Consistency Distillation (TSCD) and human feedback components of the proposed Hyper-SD model. It compares the performance of different model configurations across various metrics (CLIP Score, Aes Score, Image Reward, Pick Score) and inference steps (1, 2, 4), demonstrating the individual and combined effects of TSCD and human feedback on the model’s performance.
read the caption
Table 3. Ablation studies of TSCD and human feedback.
Full paper#