↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Vision Transformers (ViTs) are powerful but struggle with high-resolution images, performing poorly when tested on resolutions beyond their training resolution (extrapolation). Current patch position encoding methods create a distribution shift that hinders extrapolation. This is a significant limitation as high-resolution images contain richer information that could improve model accuracy.
LookHere, a novel position encoding method, directly addresses this issue. By using 2D attention masks, LookHere restricts attention heads to specific fields of view, enhancing attention head diversity and translation equivariance. This limits distribution shifts during extrapolation, leading to improved performance on ImageNet classification, adversarial attacks, and calibration, especially when extrapolating to higher resolutions. The paper also introduces a new high-resolution ImageNet dataset to facilitate further research in this area.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of Vision Transformers (ViTs) in handling high-resolution images. It introduces LookHere, a novel method that significantly improves ViT performance on high-resolution images without requiring additional training, advancing the state-of-the-art in image classification and opening avenues for research in high-resolution image understanding. The introduction of a new high-resolution ImageNet dataset further enhances the value and impact of this work.
Visual Insights#
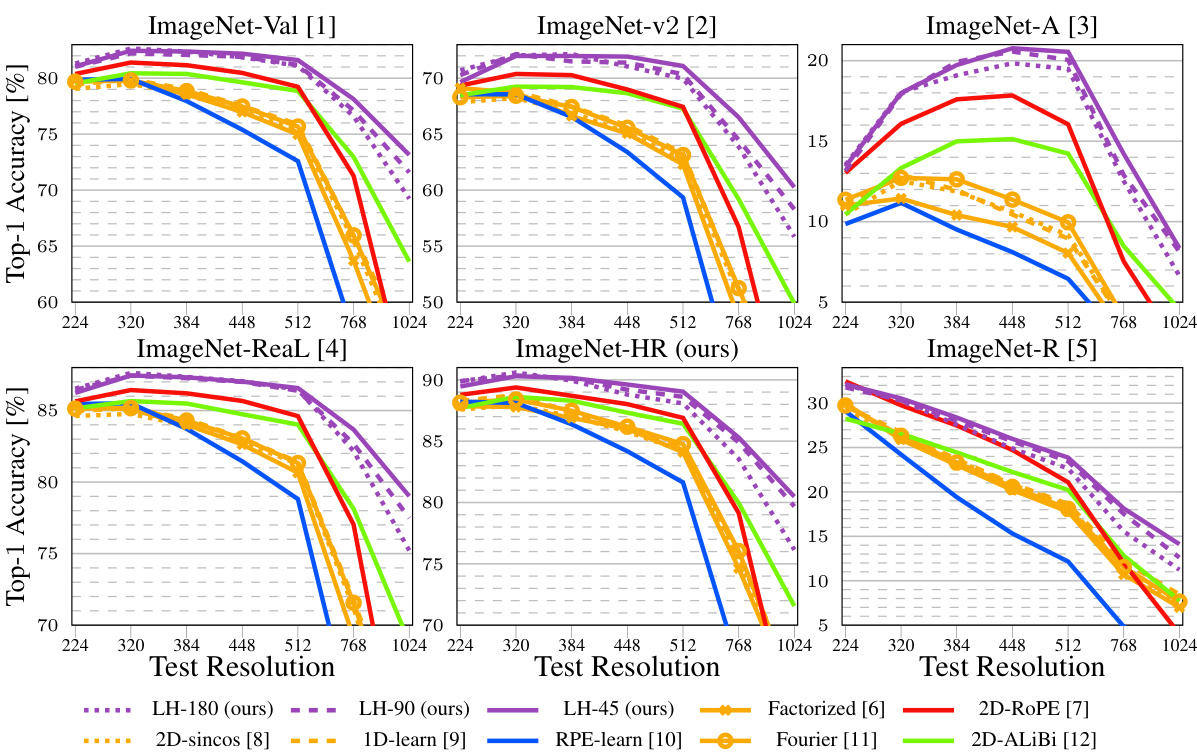
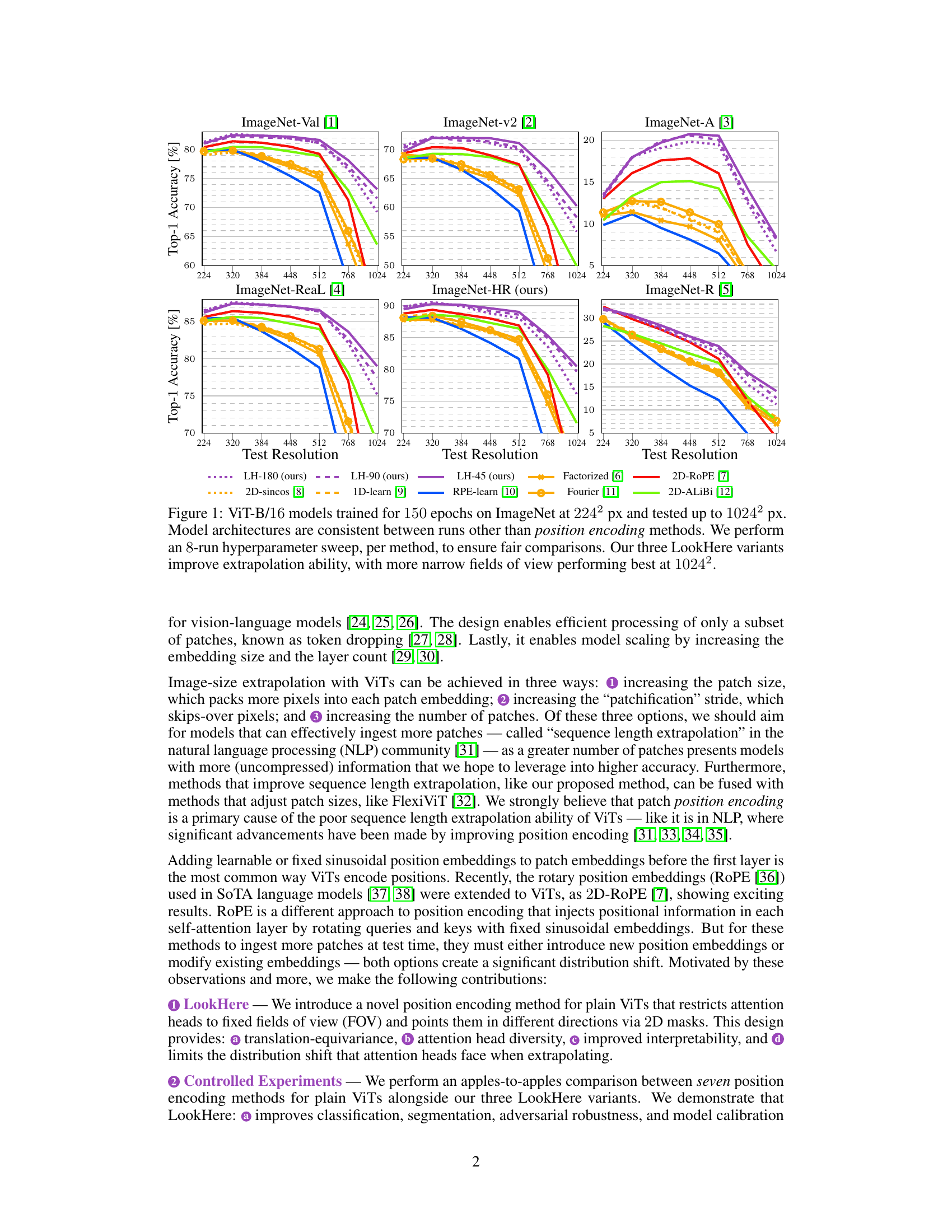
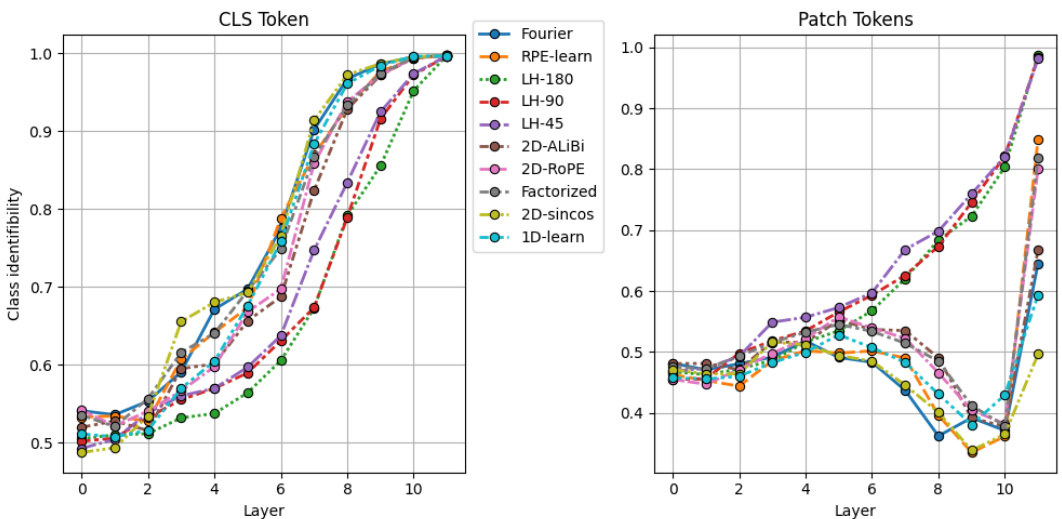
The figure shows the top-1 accuracy of different vision transformer models with various position encoding methods, trained at 224x224 resolution and tested at various resolutions up to 1024x1024. The results highlight the impact of the chosen position encoding method on the model’s ability to generalize to higher resolutions without further training (extrapolation). LookHere, a novel position encoding method proposed in the paper, demonstrates improved extrapolation performance compared to state-of-the-art methods like 2D-RoPE. The three variants of LookHere (LH-180, LH-90, LH-45) represent different field-of-view (FOV) configurations. The results indicate that LookHere models with narrower FOVs perform best at the highest tested resolution.
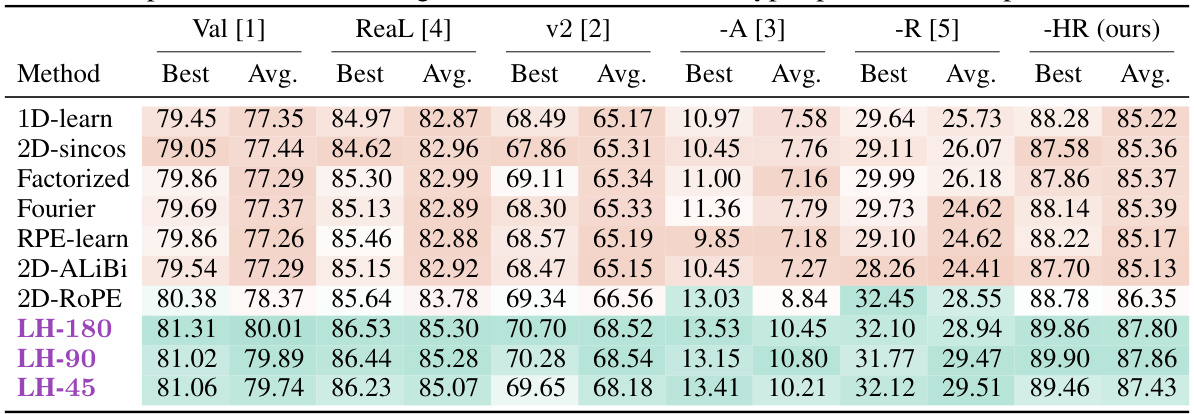
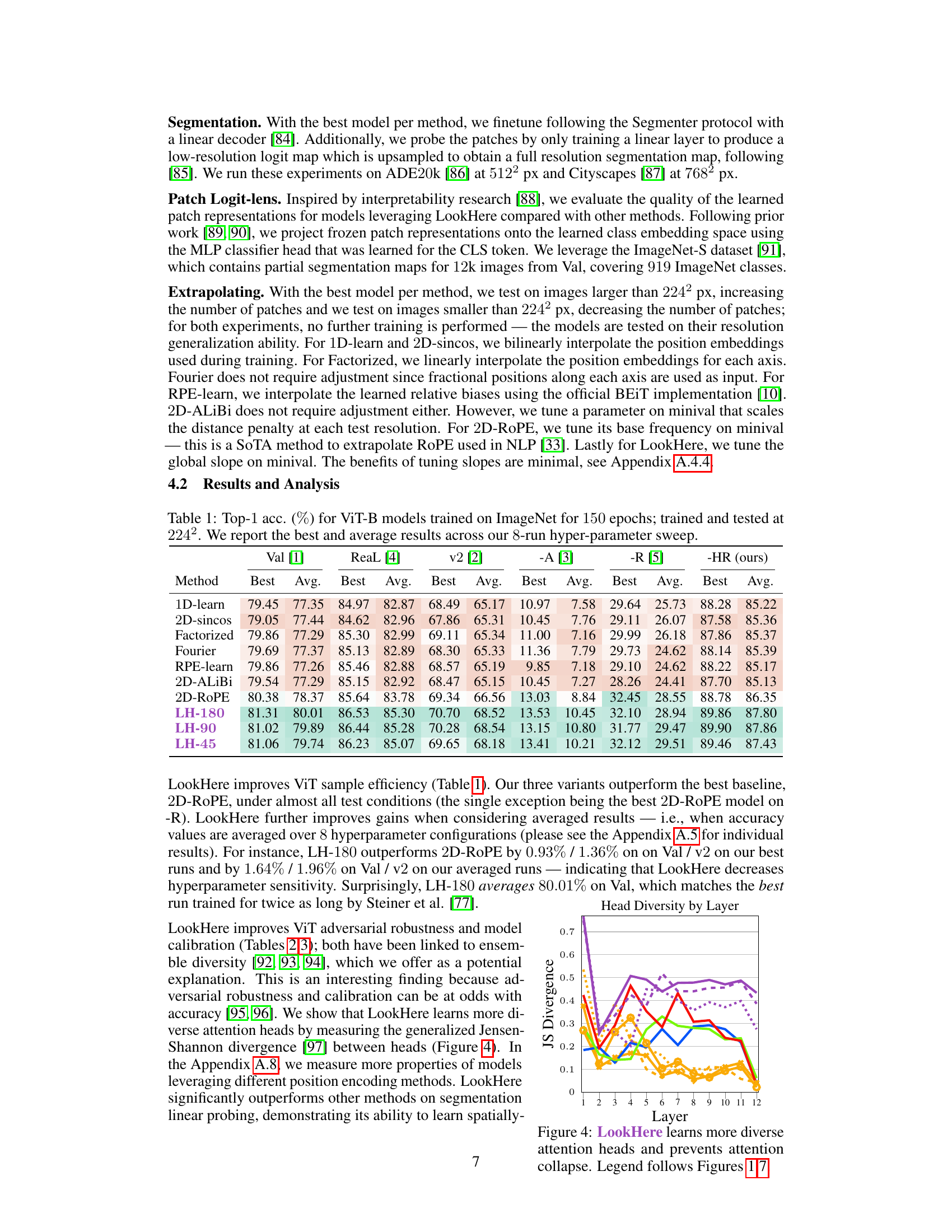
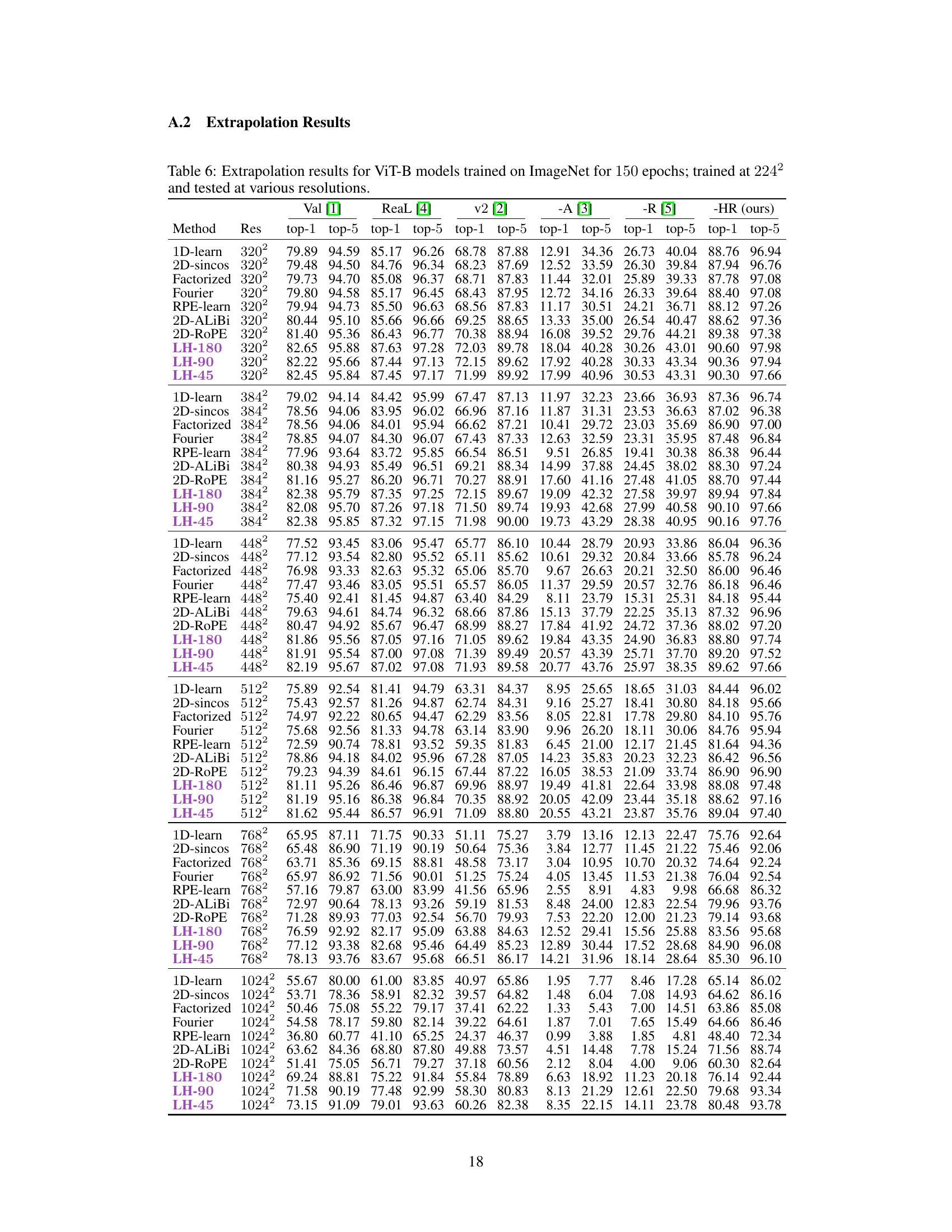
This table presents the Top-1 accuracy results for various Vision Transformer (ViT) models trained on the ImageNet dataset for 150 epochs. The models were trained and evaluated at a resolution of 224x224 pixels. The table shows both the best and average accuracy achieved across eight hyperparameter sweeps for each method. The methods compared include several different position encoding techniques, including LookHere variants and established baselines. The results are presented for ImageNet’s standard validation set and several other benchmark test sets to show overall performance and extrapolation capability.
In-depth insights#
Directed Attention#
The concept of ‘Directed Attention’ in the context of vision transformers is crucial for enhancing model performance, particularly in handling high-resolution images. It addresses the challenge of extrapolation, where a model trained on a specific image size needs to generalize effectively to larger, unseen sizes. Current methods for position encoding in vision transformers often fail to smoothly extrapolate, leading to performance degradation. Directed attention mechanisms, as explored in the paper, aim to improve this situation by restricting the attention heads’ field of view and directing them towards specific regions within the image. This constraint, though seemingly restrictive, offers several advantages. First, it promotes diversity among attention heads, preventing redundancy and encouraging specialization. Second, the approach increases interpretability by making the model’s focus more transparent. Finally, and most significantly, it mitigates the distribution shift often observed when extrapolating; by limiting the attention to localized areas, the model becomes less sensitive to the increased number of patches present in larger images, thus improving overall generalization.
Extrapolation Limits#
Extrapolation, the ability of a model to generalize beyond its training data, is a crucial aspect of high-resolution image classification. Limitations in extrapolation often arise from the distribution shift between training and testing data, especially when dealing with significantly larger images. Current patch position encoding methods in vision transformers struggle to handle this shift effectively, hindering generalization capabilities. High-resolution finetuning, while effective, introduces extra costs. Therefore, the primary goal is to develop models that extrapolate well without the need for costly finetuning at every resolution. A major challenge lies in designing position encoding methods that can effectively encode positional information at different scales and maintain consistent performance across varying input sizes. Overcoming this challenge requires innovations in how models understand spatial relationships in images and how this knowledge is incorporated into the internal representations. Improving extrapolation is essential for efficient high-resolution image classification, avoiding the significant resource requirements associated with finetuning large models on large, high-resolution datasets. Therefore, exploration of the limits of extrapolation should focus on understanding and addressing these distribution shifts and developing more robust spatial encoding techniques.
High-Res ImageNet#
The creation of a ‘High-Res ImageNet’ dataset is a significant contribution to the field of computer vision. The current ImageNet dataset, while impactful, is limited by its relatively low resolution. This limitation hinders the development and evaluation of models capable of effectively processing high-resolution images, which are increasingly prevalent in real-world applications. A high-resolution ImageNet would enable researchers to train and evaluate models on a more realistic and challenging dataset. It would facilitate significant improvements in areas such as object detection and segmentation, where fine details are crucial for accurate results. Furthermore, a high-resolution benchmark dataset would foster the creation of more sophisticated and effective models for a wide range of applications, from medical imaging to autonomous driving.
LookHere Ablations#
The LookHere ablations section is crucial for understanding the model’s robustness and identifying its core components. The authors systematically modify various aspects of LookHere, such as the field of view (FOV) of attention heads, the distance penalty function, and the directional masking scheme. By analyzing the impact of each ablation on the model’s performance, they isolate the key contributions of LookHere. The results likely demonstrate that directional attention masks are essential for achieving translation-equivariance and improved extrapolation. The findings related to the sensitivity of the model to the choices of slope functions or the effect of removing distance penalties would further reinforce the understanding of the model’s behavior and highlight the specific mechanisms responsible for its success. The ablations provide strong evidence for the design choices made in LookHere, validating its architectural decisions and underscoring its effectiveness in addressing the limitations of existing position encoding methods for Vision Transformers.
Future Work#
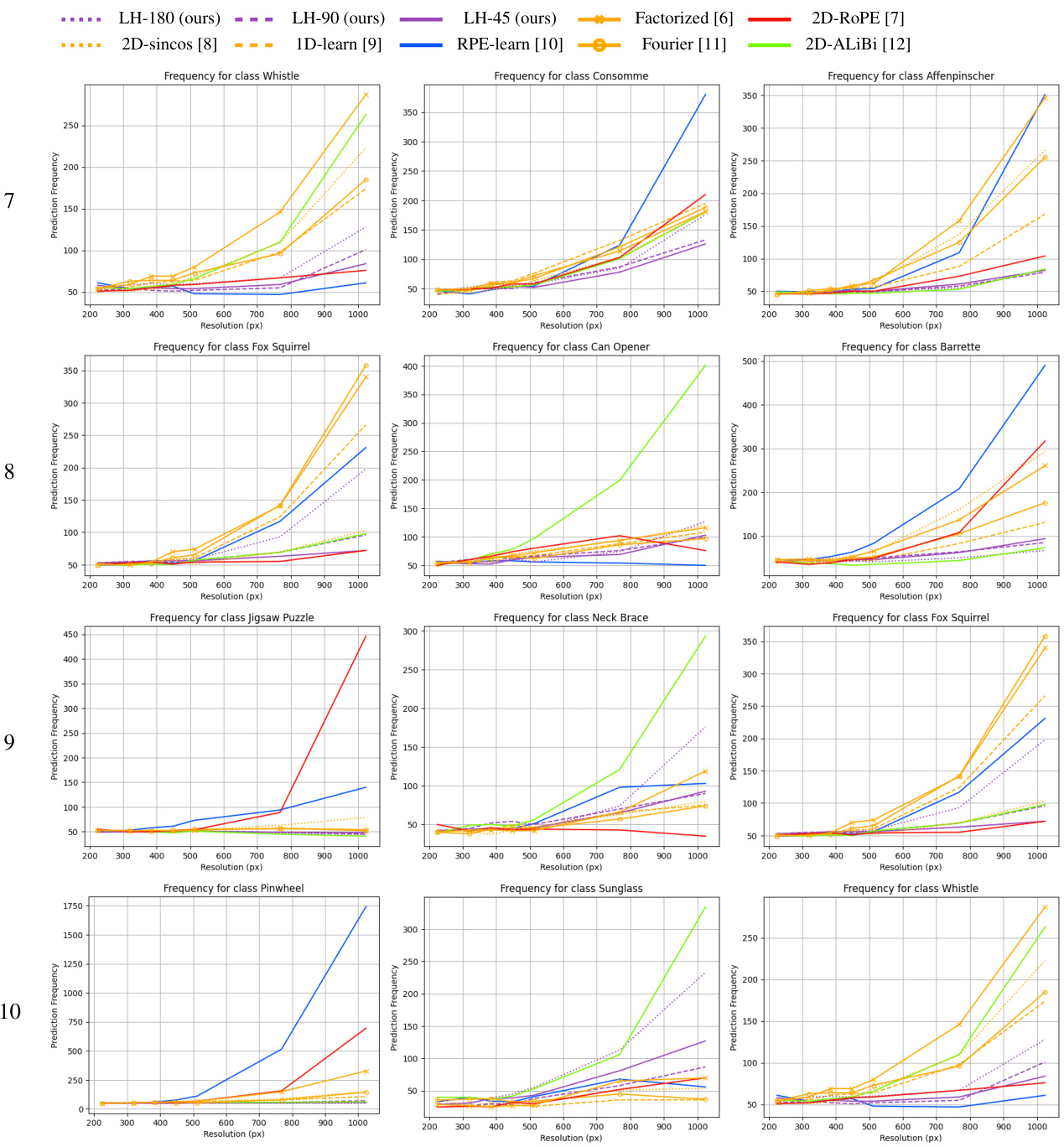
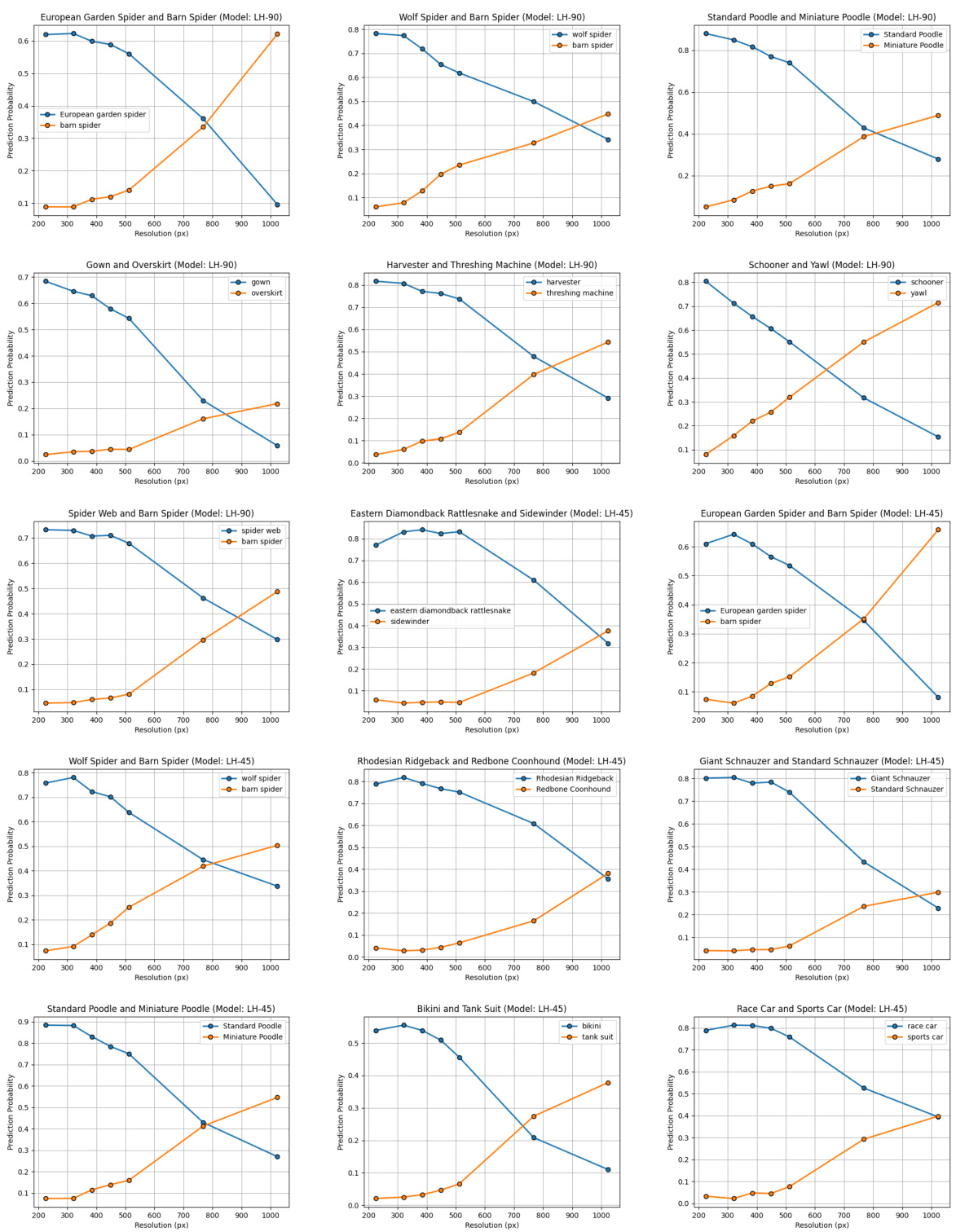
The “Future Work” section of this research paper on LookHere, a novel position encoding method for Vision Transformers, suggests several promising avenues for future research. Extending LookHere to video and 3D point cloud applications is a significant direction, given the increasing importance of these data modalities. This necessitates investigating how the directional attention masks and distance penalties would adapt to the temporal and spatial complexities of these domains. Developing custom kernels to leverage the structured sparsity inherent in the LookHere matrices presents an opportunity for significant computational speedups, crucial for deploying the model on larger-scale datasets. Further investigation into the robustness and generalizability of LookHere across diverse datasets and architectures beyond plain ViTs would strengthen the findings. Additionally, analyzing the impact of LookHere on the inductive biases of ViTs, particularly in the context of learning representations and sample efficiency, would provide deeper insights into its effectiveness. Finally, a detailed exploration of the class-level and dataset-level effects of LookHere’s extrapolation ability, as observed in the results, could provide a more nuanced understanding of its performance characteristics and potential limitations.
More visual insights#
More on figures

This figure illustrates how LookHere modifies the attention mechanism in Vision Transformers. The left panel shows a learned attention matrix, where the colors represent the attention weights. The center panel displays the LookHere mask and bias matrices. The mask (black cells) restricts the attention to a specific field of view (FOV), while the bias (bluish-green shading) encodes the relative patch distances within the FOV. The right panel provides a visual representation of how the FOV affects the attention of the central query patch. Finally, the figure shows that the final attention matrix is calculated by applying a softmax function to the difference between the learned attention matrix and the LookHere matrix.

This figure shows example images from the ImageNet-HR dataset, which is a high-resolution dataset created by the authors. The images are of three different classes: toucan, shovel, and balloon. The caption points out one of the images is of the author’s niece, highlighting the dataset’s diversity and the effort taken to collect realistic, high-resolution images, rather than upscaling lower-resolution images.

This figure presents a comparison of several position encoding methods for vision transformers, focusing on how these methods affect the diversity of attention heads, the average distance between attended patches, and the similarity of representations between patches. The results are shown across twelve transformer layers. Each metric is designed to help assess the inductive biases introduced by different positional encoding methods and their influence on the model’s ability to extrapolate or generalize to input images of varying sizes.
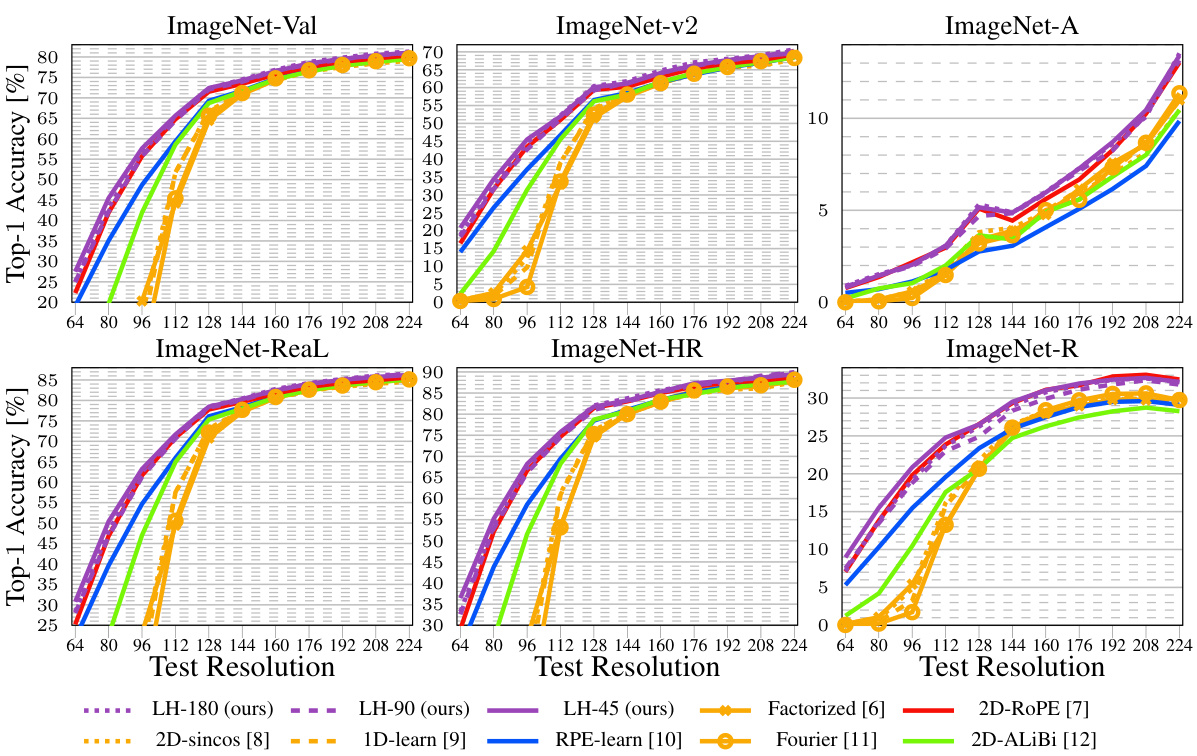
This figure displays the performance of different position encoding methods on ImageNet classification task when tested at various resolutions (from 224x224 to 1024x1024). The models were all trained at 224x224 resolution. The results demonstrate that the LookHere method outperforms other methods, especially at higher resolutions, suggesting it is more effective at extrapolating to unseen image sizes. The figure also shows that using smaller fields of view (FOV) in LookHere yields better results at higher resolutions.

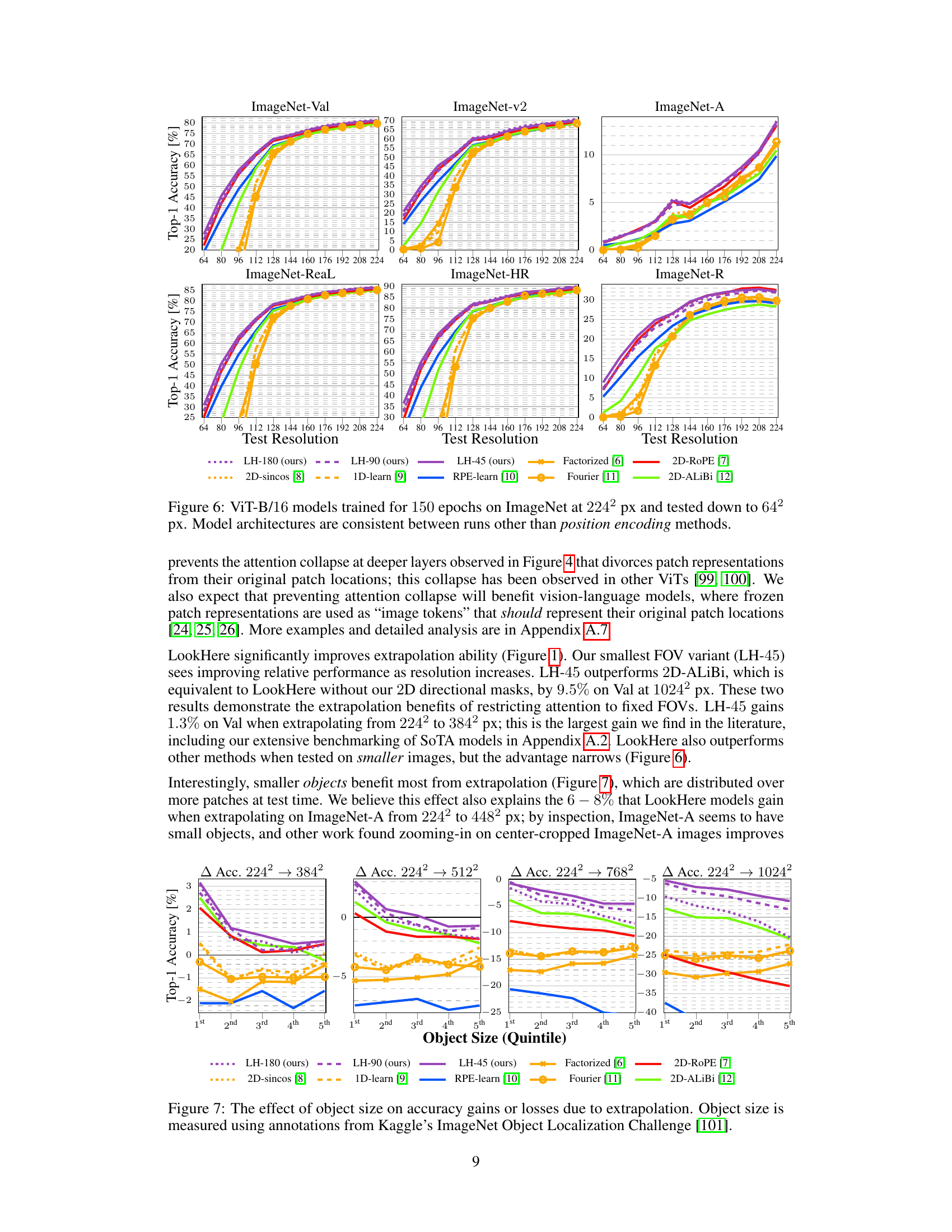
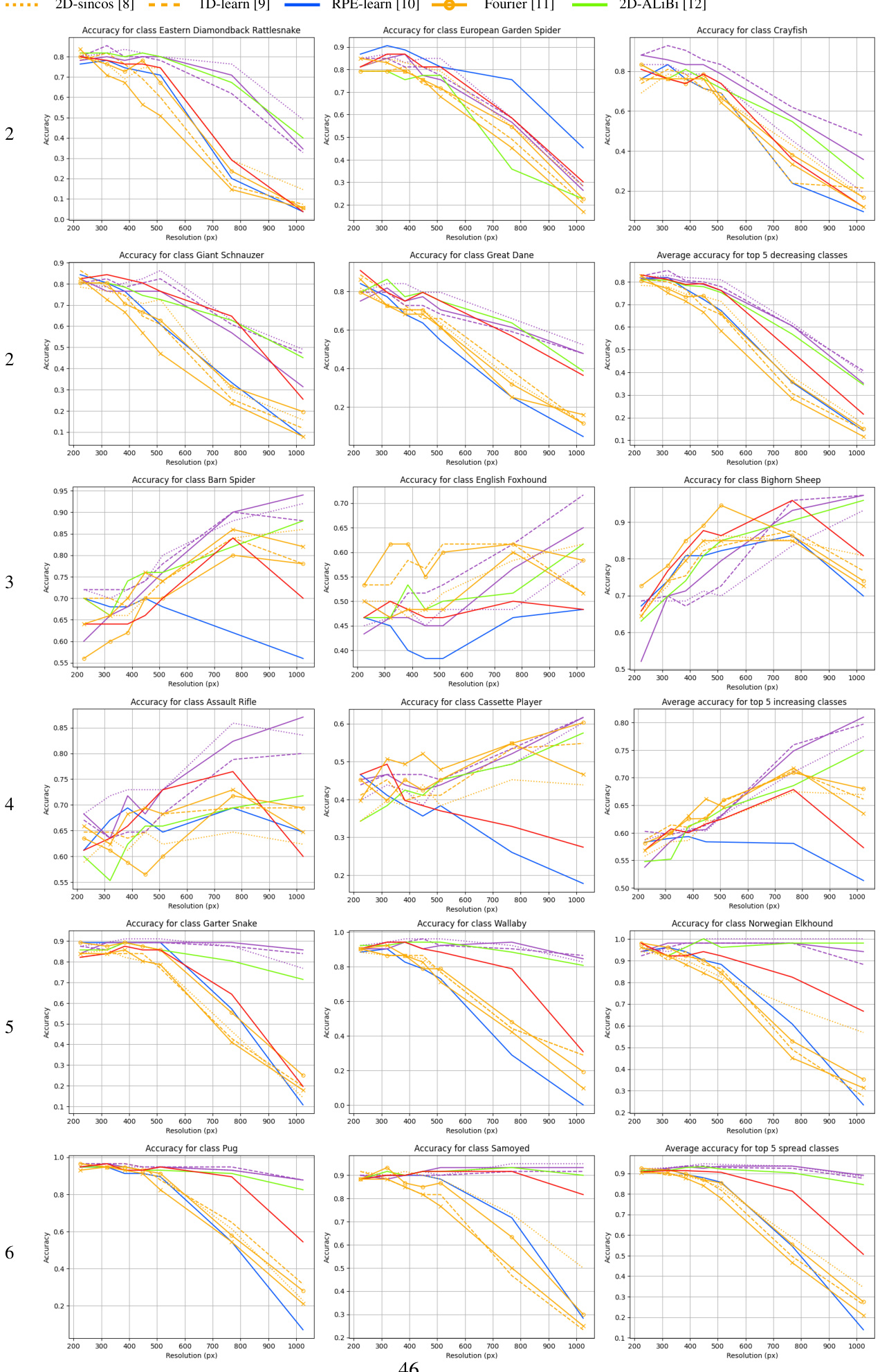
This figure shows the impact of object size on the accuracy improvements or losses observed when extrapolating from a training resolution of 224x224 pixels to higher resolutions (384x384, 512x512, 768x768, and 1024x1024 pixels). The x-axis represents the object size quintile (1st, 2nd, 3rd, 4th, and 5th), and the y-axis represents the change in top-1 accuracy. It demonstrates that models trained with LookHere achieve substantially higher accuracy gains for smaller objects which occupy more patches during the test phase.
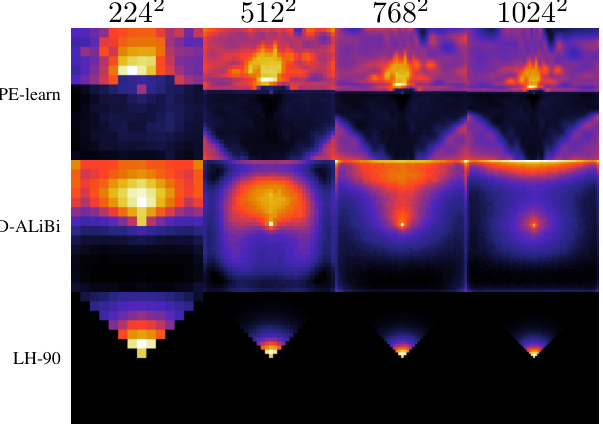
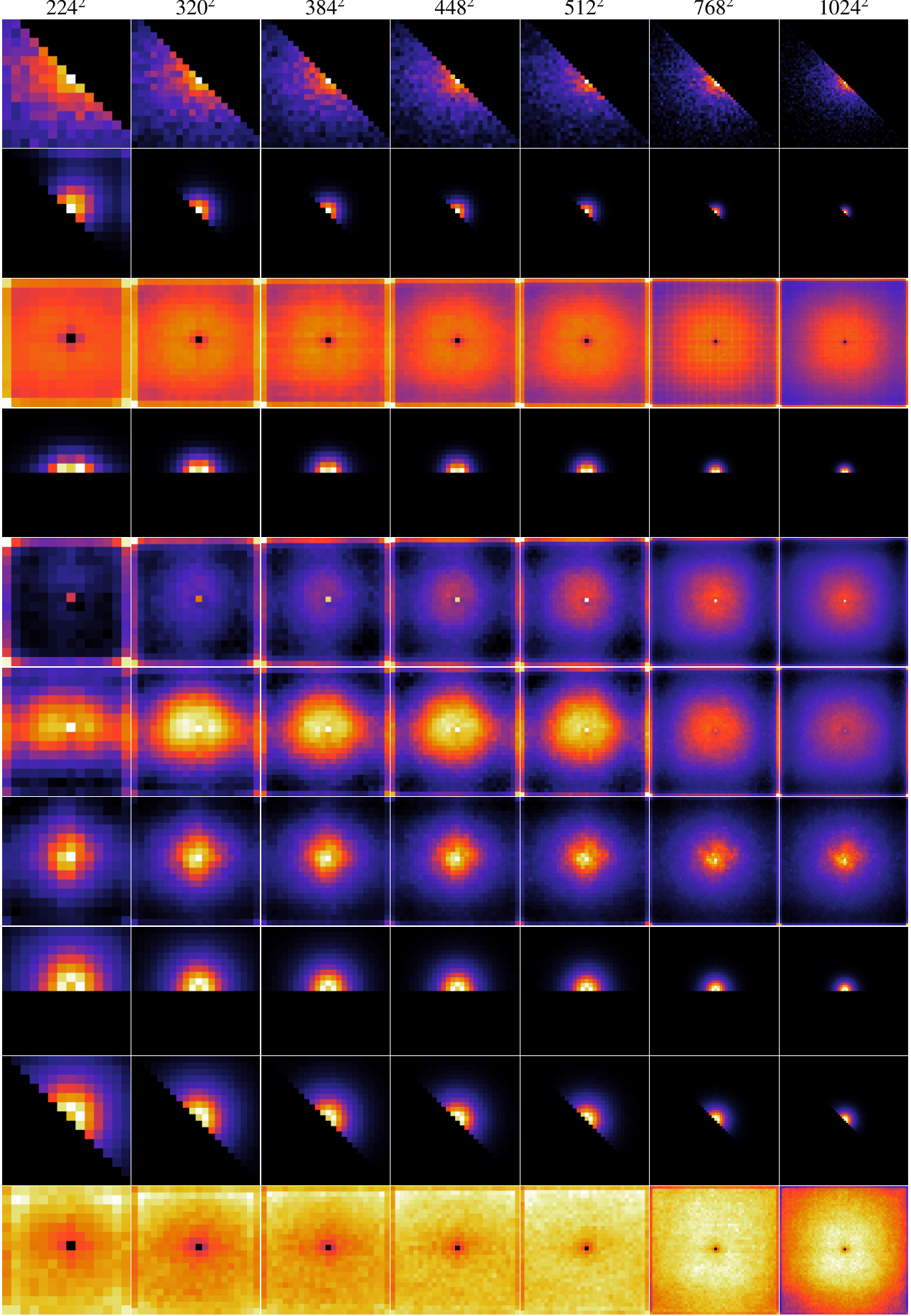
The figure displays attention maps for three different attention heads across four resolutions (224x224, 512x512, 768x768, and 1024x1024). Each head’s attention is visualized as a heatmap, showing the regions of the image that the head attends to. The query is located in the center of each heatmap. This visualization helps to understand how the attention mechanism changes as the resolution of the input image increases. For example, at low resolution, attention may be more diffuse across the entire image, while at higher resolutions attention may be more focused on specific regions. The colormap illustrates the strength of attention, with brighter colors indicating stronger attention.
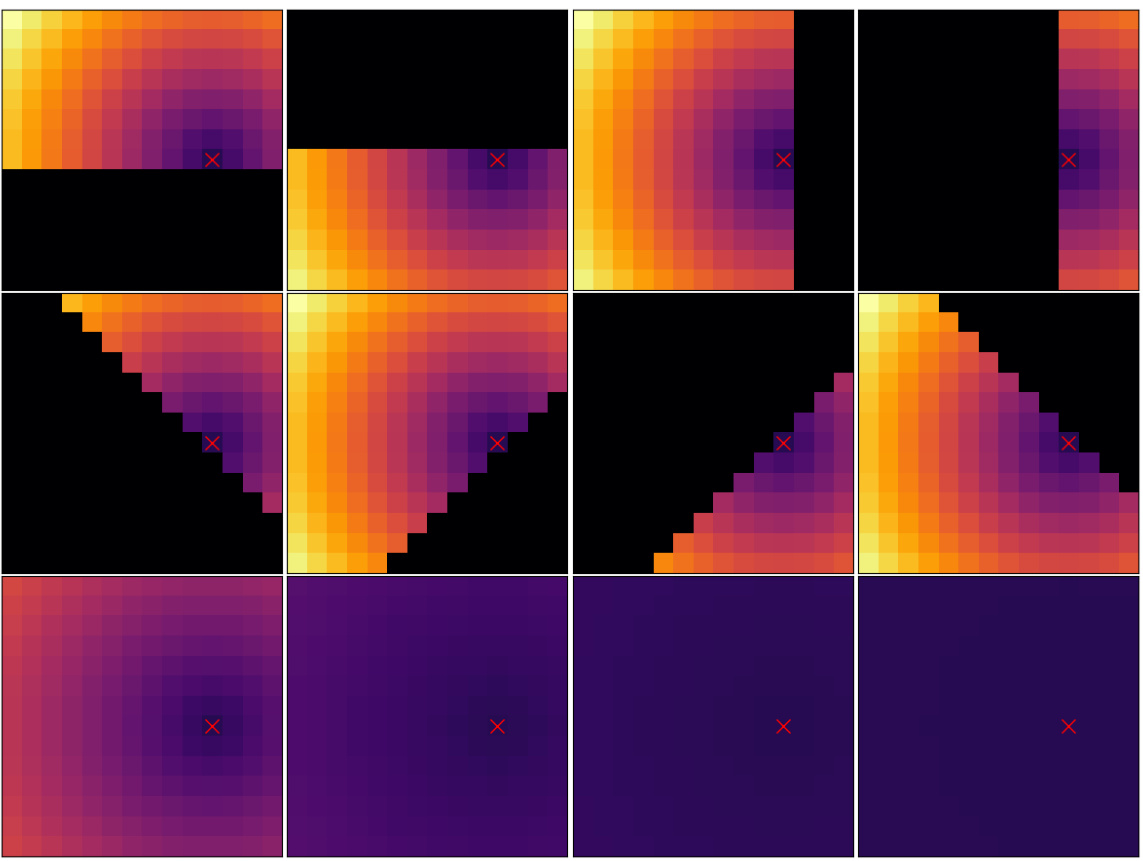
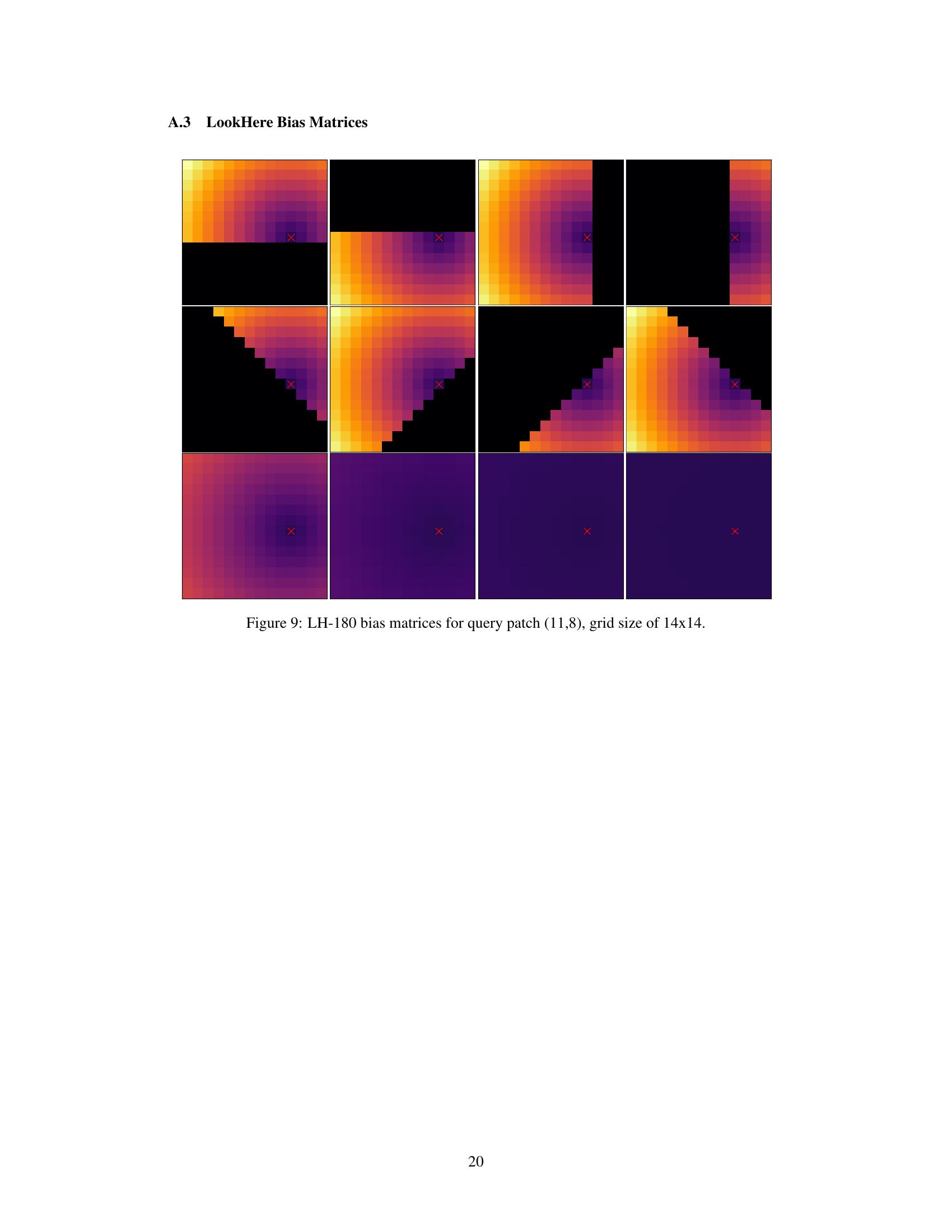
This figure visualizes the bias matrices used in the LookHere model (specifically, the LH-180 variant) for a single query patch within a 14x14 grid. Each matrix represents how the attention mechanism is biased for a different attention head. Darker shades indicate stronger penalties on the attention scores, while lighter shades indicate weaker penalties. The arrangement of these matrices demonstrates how LookHere incorporates positional information and directionality into its attention mechanism. Each bias matrix influences how the attention head weighs different key patches in relation to the query patch.
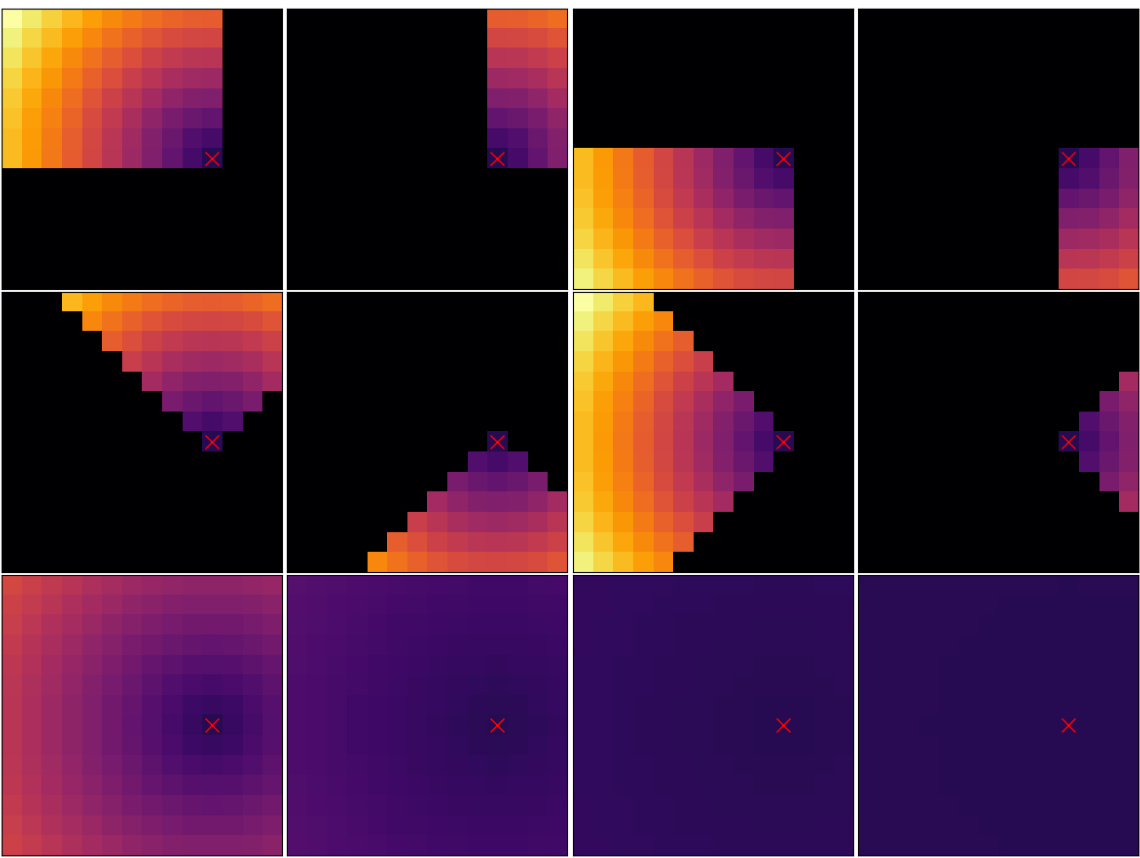
This figure shows the bias matrices used in the LookHere model for a specific query patch. LookHere uses 2D attention masks that restrict attention heads to fixed fields of view (FOV), pointing in different directions. Each matrix represents the bias applied to the attention scores for a given attention head, encoding the relative patch distances within the FOV. The colormap represents the magnitude of the bias. Darker colors indicate stronger penalties, meaning less attention is given to those patches. The ‘X’ marks the location of the query patch.

This figure visualizes the bias matrices used in the LookHere LH-180 model for a specific query patch. The bias matrices are designed to restrict the attention head’s field of view (FOV) and penalize attention scores based on the relative distance between the query patch and other patches. The visualization shows a 14x14 grid representing the patches, with the query patch located at (11,8). The color intensity of each cell indicates the bias value, with warmer colors representing lower bias (stronger attention) and cooler colors representing higher bias (weaker attention). The masks restrict attention to a specific region around the query patch. The figure illustrates how the bias is spatially dependent, influencing attention scores in different directions from the central query patch.

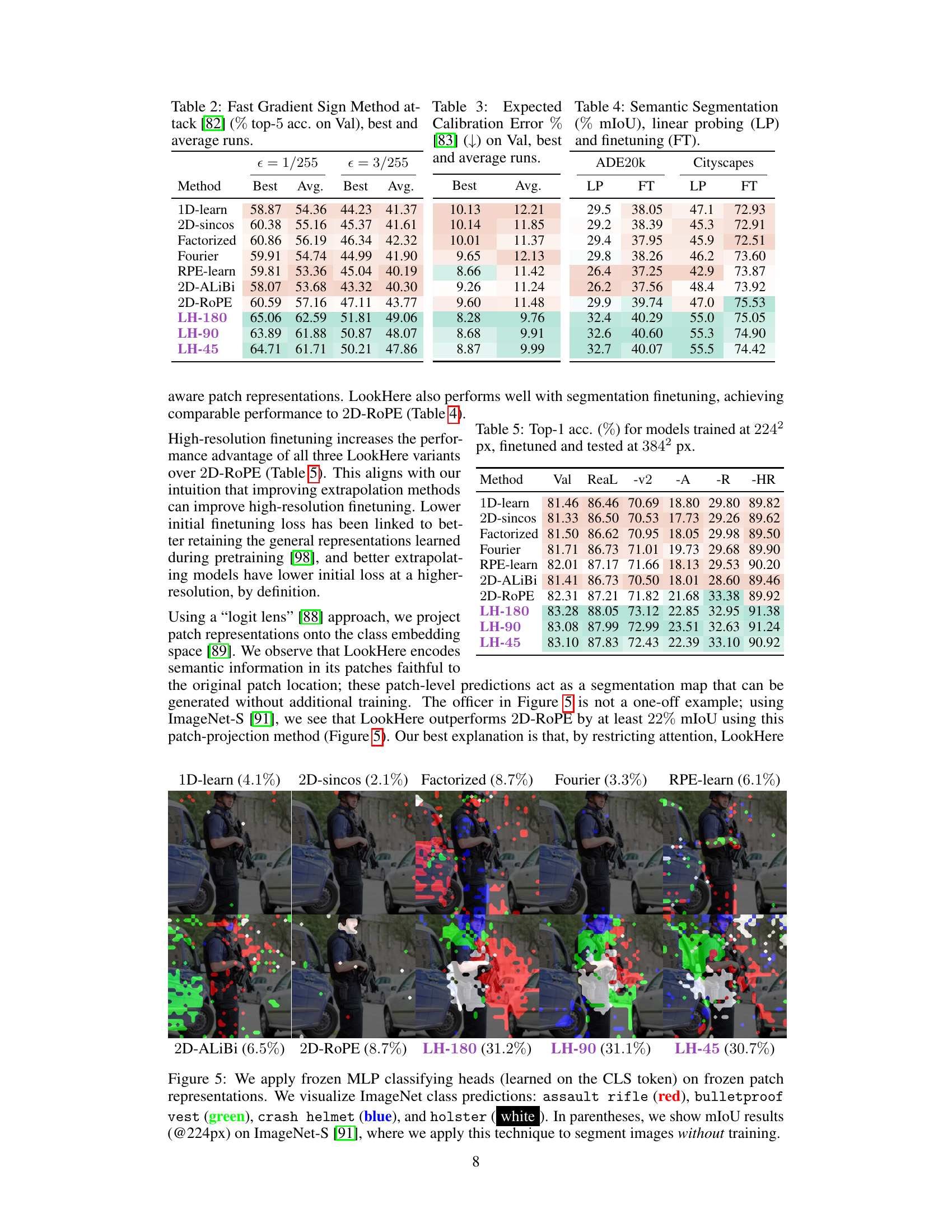
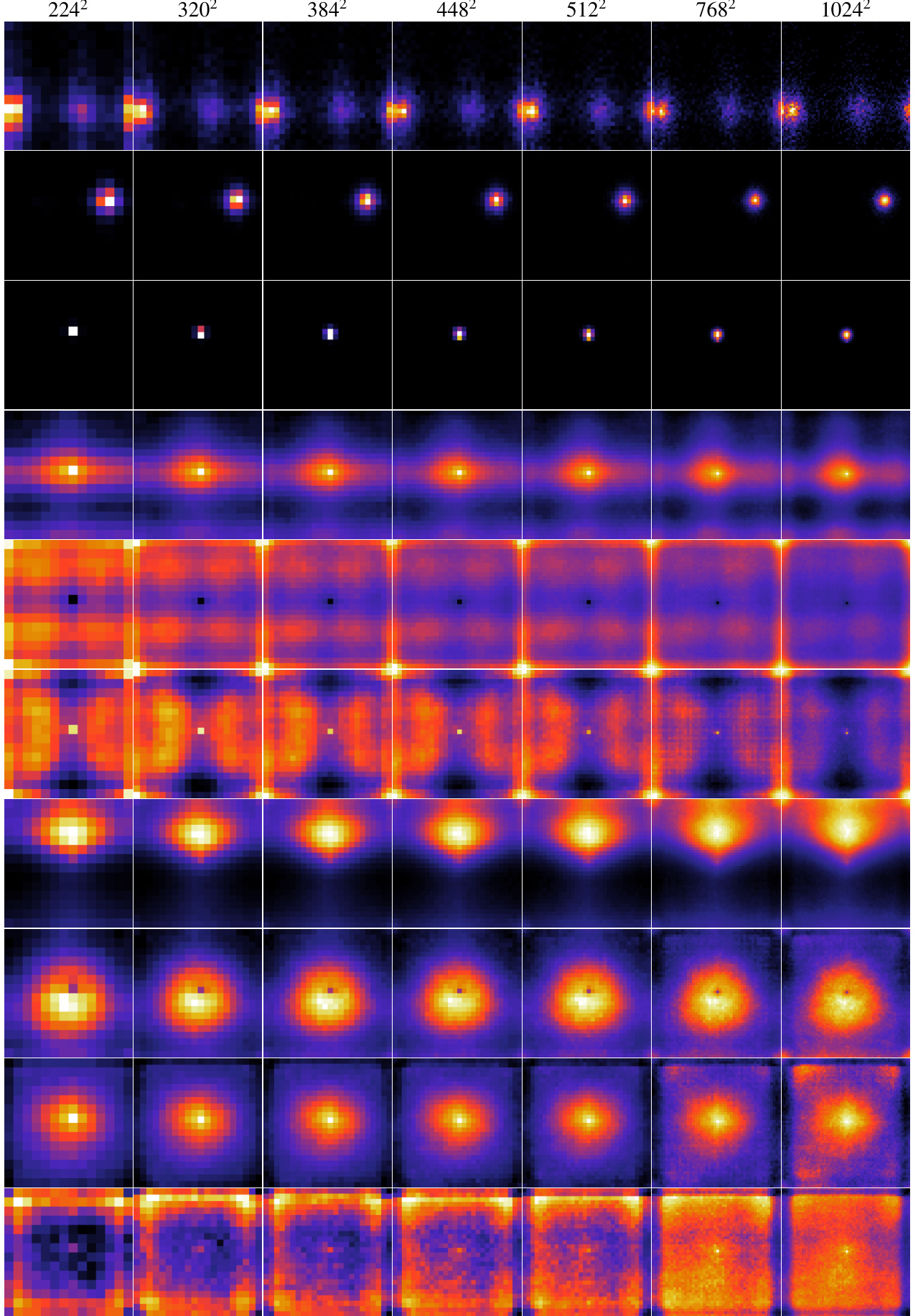
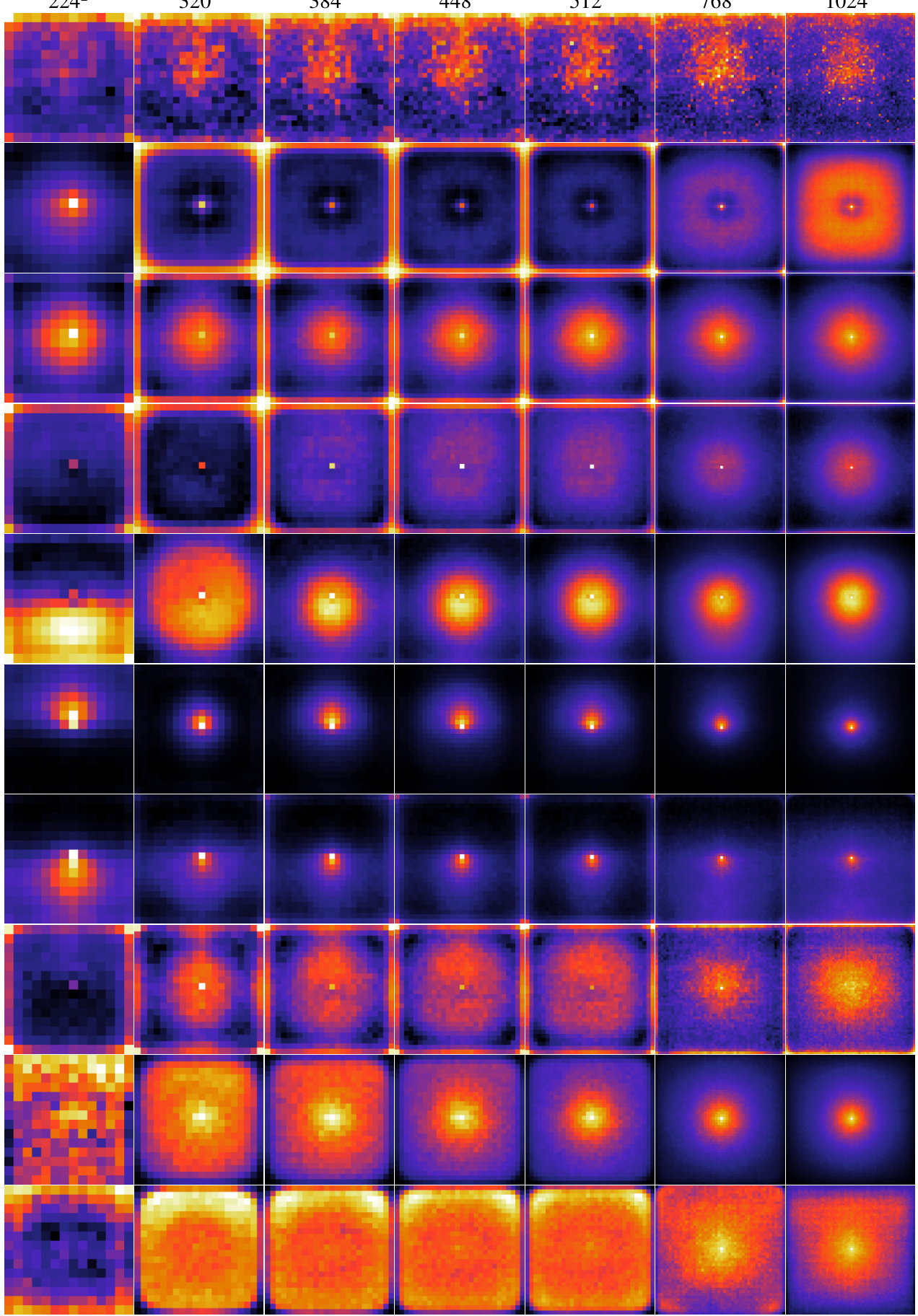
This figure visualizes the logit lens predictions of several different vision transformer models on a subset of images from the ImageNet-S dataset. The logit lens is a technique used to interpret the learned representations within a model by projecting the patch embeddings into the learned class embedding space. Each row represents a different model (LH-180, LH-90, LH-45, 2D-ALiBi, 2D-ROPE, Factorized, 2D-sincos, 1D-learn, Fourier, RPE-learn), and each column represents a different image from the ImageNet-S dataset. The top row shows the ground truth segmentation masks, while the subsequent rows depict how each model interprets and segments the corresponding images. The figure shows how the various methods differ in their ability to capture fine-grained spatial information and accurately predict the class labels for each patch, highlighting differences in the spatial representations learned by different positional encoding techniques.
This figure shows the average class identifiability across different layers of the model for both CLS (class) tokens and patch tokens. Class identifiability measures how easily the correct class can be identified from the token’s class projection. The scores range from 0 (not recoverable) to 1 (perfectly recoverable). The figure allows comparison of the class identifiability across various position encoding methods (Fourier, RPE-learn, LookHere variants, 2D-ALiBi, 2D-ROPE, Factorized, 2D-sincos, 1D-learn) across the layers of the model. It helps in understanding the difference in how each position encoding method affects the ability to recover class information from the model’s representations.

This figure displays the results of an experiment comparing different position encoding methods for Vision Transformers (ViTs) on the ImageNet dataset. ViT-B/16 models were trained at 224x224 pixel resolution and then tested at various resolutions up to 1024x1024 pixels. The experiment aimed to assess the ability of these models to extrapolate to higher resolutions (i.e. generalize to larger images). The plot shows the top-1 accuracy achieved by each method at different test resolutions. LookHere, the proposed method by the authors, shows better extrapolation performance compared to existing methods, especially at higher resolutions, with the narrower fields of view performing particularly well.

This figure presents measurements of head diversity, attention distance, and patch similarity by layer for various position encoding methods. It helps to show how different methods influence the diversity of attention head behavior and how they impact the spatial focus and relationships between patches. The metrics provide insights into the learning patterns and spatial reasoning capabilities of Vision Transformers (ViTs) with different positional encoding schemes.

This figure presents the results of an experiment comparing different position encoding methods for vision transformers (ViTs) on the ImageNet dataset. ViT-B/16 models were trained at 224x224 pixel resolution and then tested at various resolutions up to 1024x1024 pixels. The experiment compared seven baseline position encoding methods and three variants of a novel method called LookHere. The results show that LookHere improves extrapolation ability, especially when using narrower fields of view at the highest resolutions.

This figure shows the results of an experiment comparing different position encoding methods for Vision Transformers (ViTs) on the ImageNet dataset. ViT-B/16 models were trained at 224x224 pixel resolution and then tested at various resolutions up to 1024x1024 pixels. The experiment included three variants of the proposed method, LookHere, along with several other state-of-the-art (SoTA) methods. The results show the top-1 accuracy for each method, demonstrating that LookHere variants generally outperform the SoTA methods and that those with narrower fields of view work best at the highest resolution.

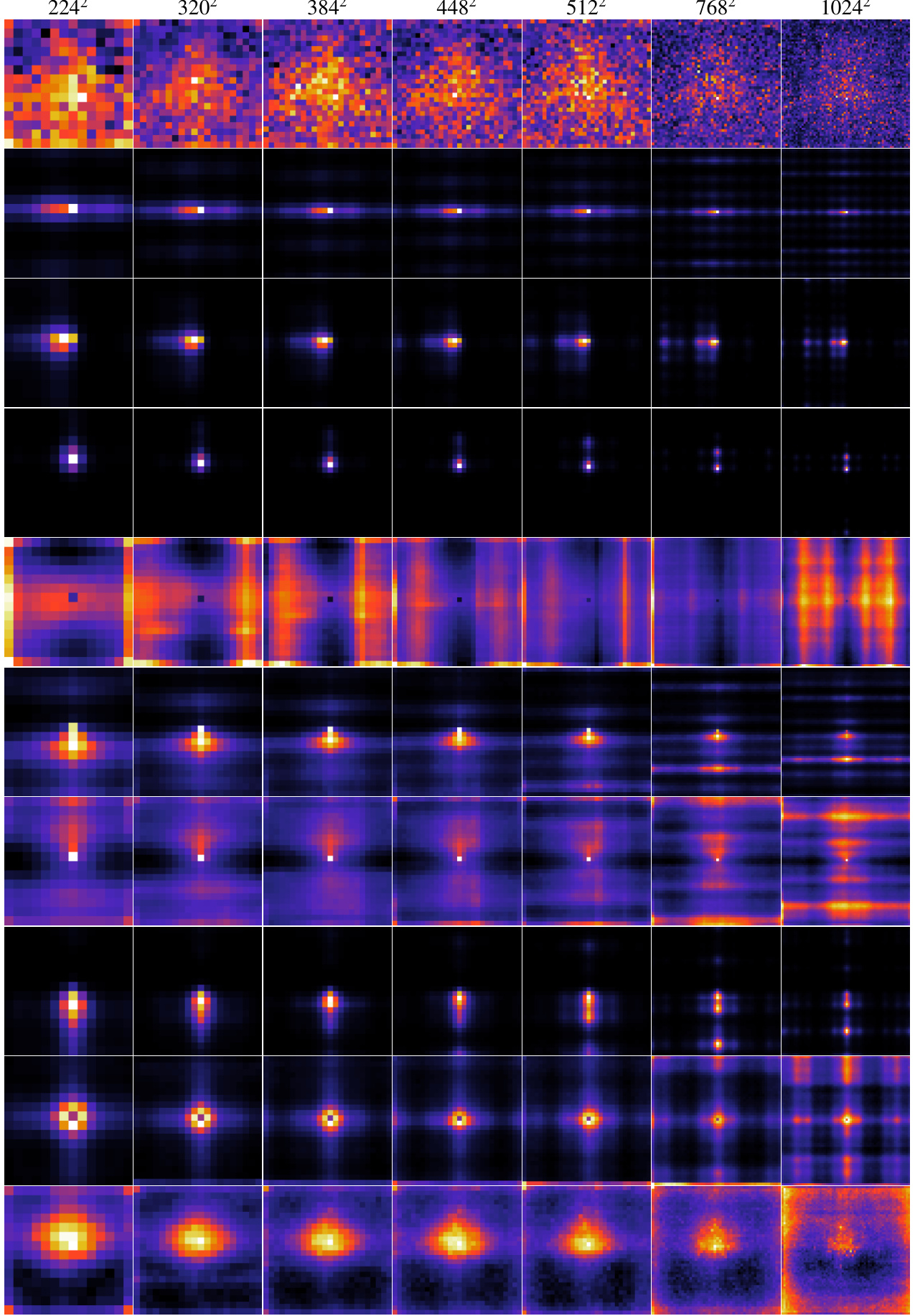
This figure visualizes the attention maps of ten attention heads from a 1D-learn model at seven different resolutions (224x224, 320x320, 384x384, 448x448, 512x512, 768x768, and 1024x1024). The colormap represents the attention weights, with darker colors indicating stronger attention. The query patch is located in the center of each attention map. The visualizations are averaged across 5,000 images from the ImageNet dataset, giving an overall view of the attention patterns learned by the model at various resolutions.
This figure visualizes the attention maps of ten attention heads from a model using 1D-learn positional encoding. The attention maps are shown for seven different resolutions (2242, 3202, 3842, 4482, 5122, 7682, and 10242 pixels). Each row represents a different head, showing how its attention is distributed across the input image at various resolutions. The colormap indicates the attention weight, with darker colors representing higher attention weights and brighter colors representing lower attention weights. The query is always in the center of the image. The attention maps are averaged across 5,000 images to highlight typical behavior.

This figure shows how LookHere modifies the attention matrix. The left panel shows a learned attention matrix. The center panel shows the LookHere mask and bias matrix, with black cells indicating masked areas and bluish-green cells indicating biased areas. The right panel shows a visual example of the field of view (FOV) for a query patch. The final attention matrix is created by subtracting the LookHere matrix from the learned attention matrix and then applying a softmax function.

This figure displays the top-1 accuracy results of different position encoding methods on ImageNet, with training conducted at 224x224 resolution and testing performed at various resolutions up to 1024x1024. The results highlight the superior extrapolation capabilities of the proposed LookHere method, especially its variants with narrower fields of view (FOVs), compared to existing methods such as 2D-RoPE, 2D-ALiBi, etc. The plot demonstrates that LookHere is robust to higher resolutions and significantly improves upon existing state-of-the-art position encodings in extrapolation tasks.

This figure presents the results of an experiment comparing different position encoding methods for Vision Transformers (ViTs) on the ImageNet dataset. ViT-B/16 models were trained at a resolution of 224x224 pixels and then tested at various resolutions up to 1024x1024 pixels. The experiment included three variations of the proposed LookHere method, along with several other baseline methods. The plots show the Top-1 accuracy for each method at each tested resolution, demonstrating the superior extrapolation performance of LookHere, especially at higher resolutions. Narrower fields of view within LookHere models yielded the best results at the highest resolution.
This figure illustrates the LookHere method’s core mechanism. The left panel shows a learned attention matrix, with colors representing attention weights. The center panel displays the LookHere mask and bias matrix, applied to the attention matrix. Black cells in the mask indicate no attention (masked), while shaded cells show attention with bias (relative patch distance). The right panel shows a visual representation of the field of view (FOV) for a single query patch. The final step is element-wise subtraction of the LookHere matrix from the learned attention matrix before applying a softmax function to obtain the final attention weights (A¹).
This figure presents the results of the experiment comparing different positional encoding methods on ImageNet. Models based on Vision Transformers (ViT-B/16) were trained at a resolution of 224x224 pixels (224²) for 150 epochs. The performance of each model was then evaluated at various resolutions up to 1024x1024 pixels (1024²). The figure shows that the proposed LookHere method outperforms other methods at higher resolutions (extrapolation). Different variants of the LookHere method are presented with various fields of view (FOV). The hyperparameter search (8 runs) was carried out to ensure fair comparison among the methods.
This figure shows the performance of different position encoding methods for Vision Transformers (ViTs) on ImageNet dataset. ViT-B/16 models were trained at a resolution of 224x224 pixels (224²) and tested at various resolutions up to 1024x1024 pixels (1024²). The figure plots the top-1 accuracy for each method at different test resolutions. The results demonstrate the impact of the position encoding method on the ability of ViTs to generalize to different image sizes (extrapolation). The three LookHere variants (LH-180, LH-90, LH-45) consistently outperform other methods, particularly at higher resolutions. The narrow field-of-view variants of LookHere perform best at the highest resolution.
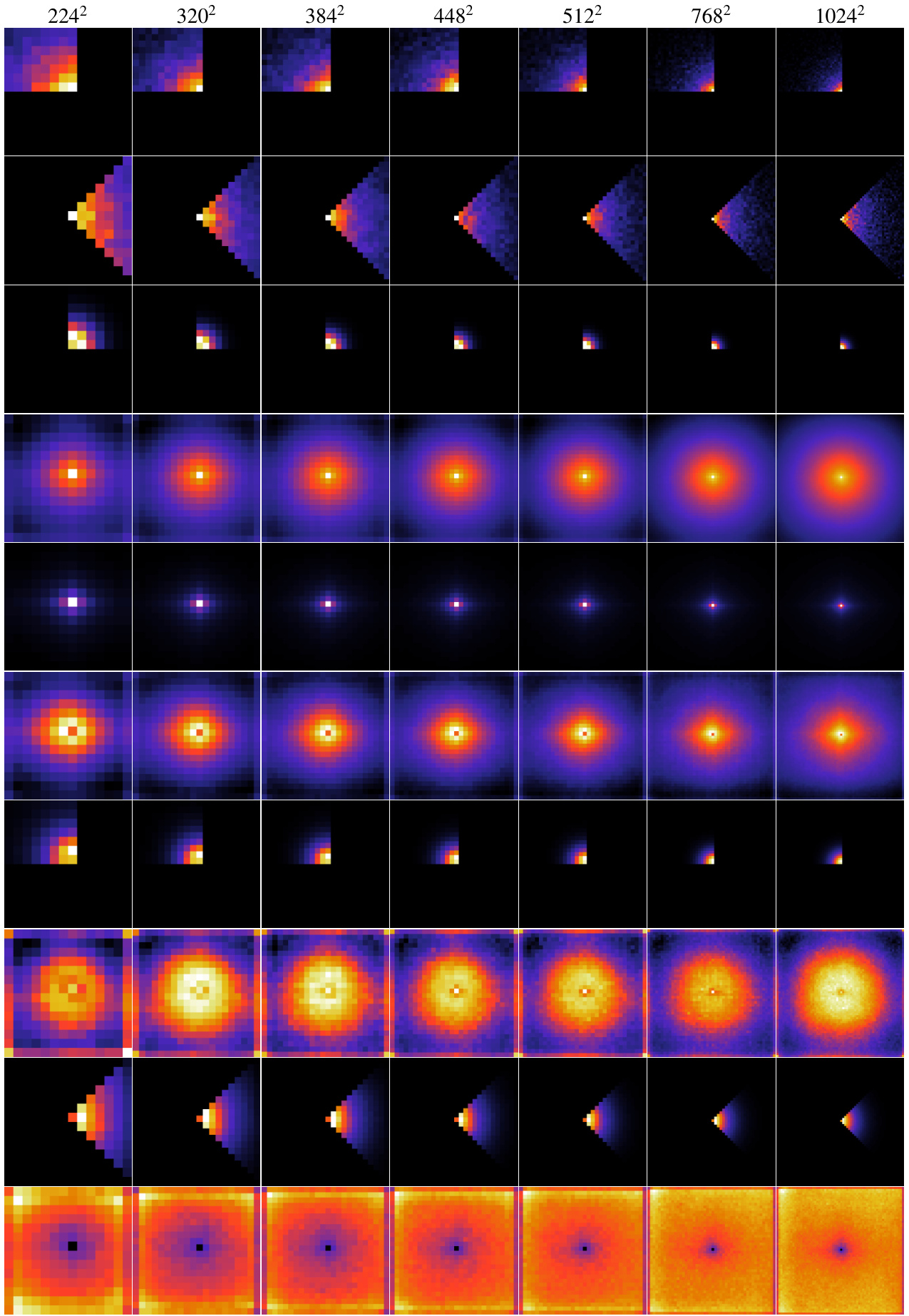
This figure visualizes the attention maps of ten attention heads of the LH-45 model at seven different resolutions (224x224, 320x320, 384x384, 448x448, 512x512, 768x768, and 1024x1024). The query is located in the center of each image, and the colormap represents the attention weights. The visualization is averaged over 5,000 images from the minival set. This figure helps in understanding how the attention mechanism behaves at different resolutions and how the LH-45 model focuses its attention.

This figure visualizes the attention maps of ten attention heads from the LH-45 model at different resolutions (224x224, 320x320, 384x384, 448x448, 512x512, 768x768, and 1024x1024). The colormap represents the attention weights, with darker shades indicating stronger attention. The query patch is located in the center. The figure shows how the attention patterns change as the resolution increases, highlighting the model’s ability to adapt its attention mechanism to different image scales.
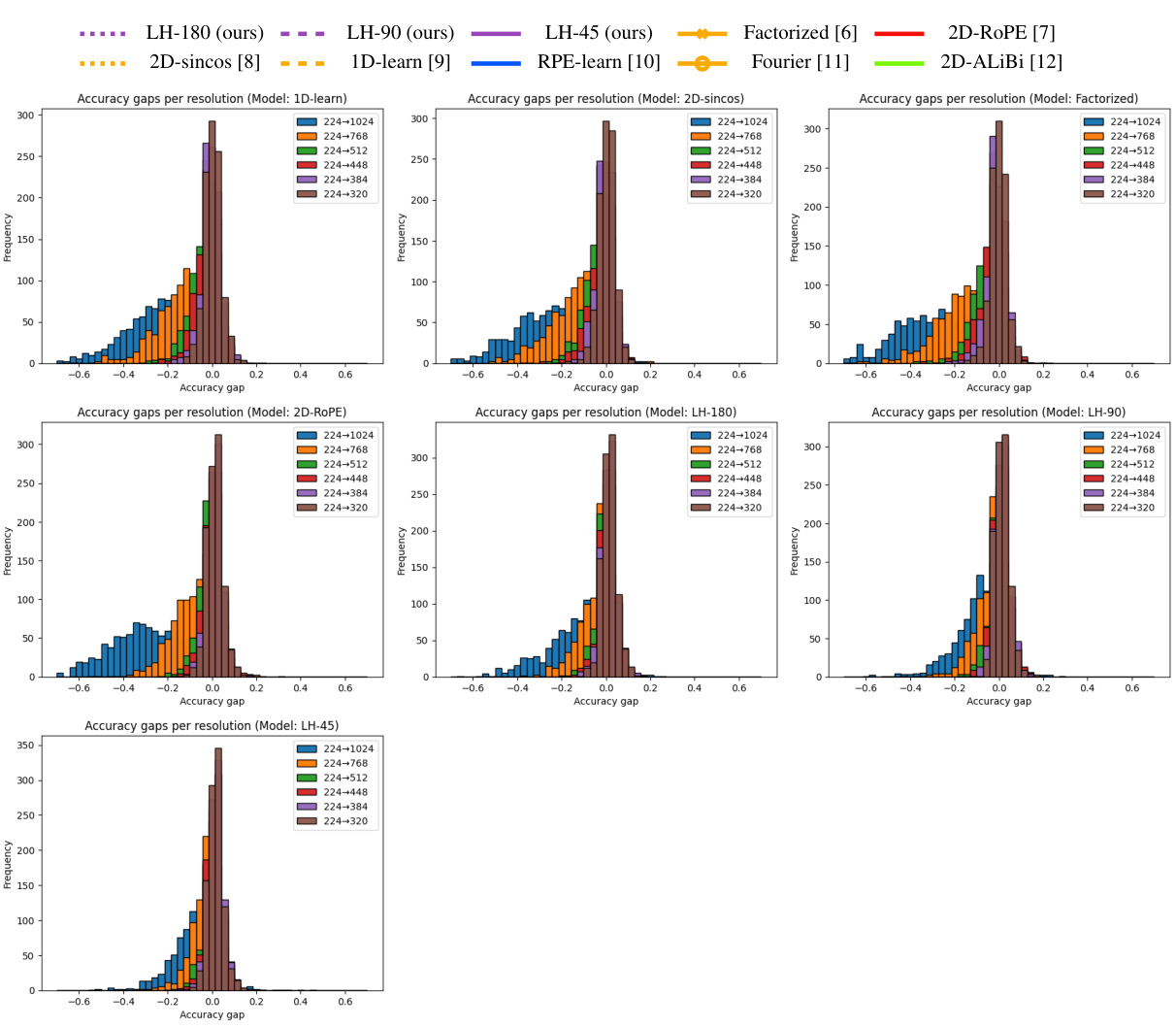
This figure displays the top-1 accuracy of different ViT-B/16 models trained on ImageNet at a resolution of 224x224 pixels and then tested on various resolutions ranging from 224x224 to 1024x1024 pixels. The models differ only in their position encoding methods. The results show the performance of seven baseline position encoding methods and three variations of the LookHere method proposed in the paper. LookHere consistently outperforms the baseline methods, especially at higher resolutions. The 8-run hyperparameter sweep ensures fair comparisons. The results highlight the superiority of LookHere, particularly its variants with narrower fields of view, in extrapolating to higher resolution images without further training.

This figure displays the top-1 accuracy of different vision transformer models with varying position encoding methods. The models were trained on ImageNet at a resolution of 224x224 pixels and then tested at resolutions ranging from 224x224 to 1024x1024 pixels. The results show how well each method extrapolates to higher resolutions, without further training. The three variants of LookHere consistently outperform other methods, especially at the highest resolution (1024x1024). The performance of LookHere variants with narrower fields of view is particularly noteworthy.
This figure displays the performance of different position encoding methods on image classification using Vision Transformers (ViTs). Models were trained on ImageNet at 224x224 pixel resolution and then tested at various resolutions ranging up to 1024x1024 pixels. The results show the top-1 accuracy for each method. The figure highlights that the authors’ proposed LookHere method, particularly with narrower fields of view (FOVs), demonstrates superior extrapolation capabilities compared to existing state-of-the-art methods.
This figure presents the results of an experiment comparing the performance of various position encoding methods for Vision Transformers (ViTs) on the ImageNet dataset. ViT-B/16 models were trained at a resolution of 224x224 pixels and then evaluated at resolutions ranging from 224x224 to 1024x1024. The results illustrate the impact of different position encoding techniques on the models’ ability to extrapolate to higher resolutions. The authors’ proposed method, LookHere, outperforms existing state-of-the-art (SOTA) methods, especially at the highest resolution (1024x1024). The different variations of LookHere (LH-180, LH-90, LH-45) achieve slightly varying results with LH-45 showing the best performance at 1024x1024, demonstrating that narrower fields of view might be more beneficial for high-resolution extrapolation.

This figure presents the results of the experiment comparing various position encoding methods for Vision Transformers (ViTs). Eight different ViT models (including three variants of the proposed LookHere method) were trained on ImageNet at 224x224 resolution and tested at resolutions up to 1024x1024 pixels. The results show that LookHere significantly improves extrapolation, achieving the best performance at the highest resolution, especially with narrower fields of view.

This figure displays the top-1 accuracy of various ViT-B/16 models with different position encoding methods, tested at resolutions ranging from 224x224 to 1024x1024 pixels. The models were trained on ImageNet at 224x224 resolution for 150 epochs. The consistent architecture across models ensures a fair comparison. Each method underwent an 8-run hyperparameter sweep. The results show that LookHere variants consistently outperform other methods, particularly at higher resolutions, with narrower fields of view performing best.

This figure presents the results of an experiment comparing different position encoding methods for Vision Transformers (ViTs) on the ImageNet dataset. Models were trained at a resolution of 224x224 pixels and then tested at resolutions ranging up to 1024x1024 pixels. The comparison shows the performance of various position encoding methods, including the proposed LookHere method and several baselines, in terms of top-1 accuracy. The results illustrate the ability of the models to extrapolate to larger image sizes without further training, with LookHere showing significant improvement, particularly at the highest tested resolutions. The three LookHere variants (LH-180, LH-90, LH-45) each use different field-of-view (FOV) sizes for the attention masks. The figure shows that narrower FOVs result in better performance at higher resolutions.
This figure displays the performance of different position encoding methods on the ImageNet dataset when training is done at a resolution of 224x224 pixels and testing is performed at resolutions ranging from 224x224 to 1024x1024 pixels. The consistent model architecture across all runs helps in establishing a fair comparison. The results reveal that LookHere variants exhibit superior extrapolation capabilities, specifically the ones using narrower fields of view, showing the best performance at the highest tested resolution.
More on tables

This table presents the Top-1 accuracy results for various position encoding methods applied to Vision Transformers (ViTs). The models are all ViT-B, trained on ImageNet for 150 epochs at 224x224 resolution. The table shows the best and average Top-1 accuracy across 8 hyperparameter sweeps for each method, giving a robust comparison. The results indicate the performance of different position encoding techniques on a standard image classification task.
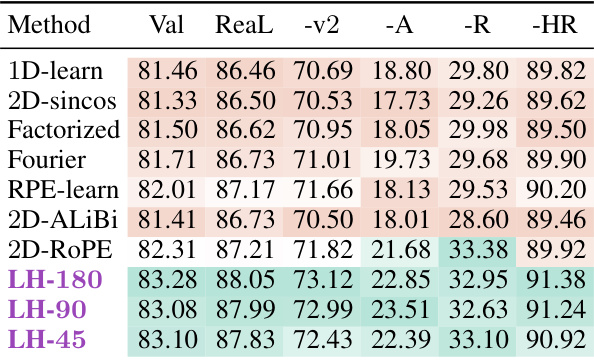
This table presents the top-1 accuracy results for various Vision Transformer (ViT) models trained on ImageNet dataset for 150 epochs. The models are evaluated at a resolution of 224x224 pixels. The table compares different position encoding methods, including LookHere (LH-180, LH-90, LH-45) and state-of-the-art methods such as 2D-ROPE. The ‘Best’ column shows the highest accuracy achieved across 8 hyperparameter sweeps, while the ‘Avg’ column represents the average accuracy across these runs. This provides insights into the performance variations resulting from hyperparameter tuning for different position encoding techniques.

This table presents the Top-1 accuracy results for various vision transformer models (ViT-B) trained on ImageNet for 150 epochs. The models were trained and evaluated at a resolution of 224x224 pixels. The table shows both the best and average accuracy scores across eight different hyperparameter runs, allowing for a fair comparison between different position encoding methods. The results highlight the performance of various position encoding techniques on the standard ImageNet validation dataset.

This table presents the top-1 accuracy results for various vision transformer (ViT) models trained on ImageNet for 150 epochs and evaluated at a resolution of 224x224 pixels. The table compares different position encoding methods, showing both the best and average performance across eight hyperparameter searches for each method. This allows for a fair comparison of the different methods’ performance, and provides a more robust indication of their effectiveness beyond a single, potentially optimal hyperparameter setting. The models are all ViT-B models. The results are crucial for understanding the effectiveness of each position encoding in the context of the ViT architecture.

This table presents the top-1 accuracy results for various ViT-B models trained on ImageNet for 150 epochs. The models were trained and evaluated at a resolution of 224x224 pixels. The table shows both the best and average top-1 accuracy across eight hyperparameter sweeps for each model. This allows for a fair comparison of different position encoding methods, and demonstrates the performance of LookHere in comparison to existing methods.

This table presents the Top-1 accuracy results achieved by various Vision Transformer (ViT) models trained on the ImageNet dataset for 150 epochs at a resolution of 224x224 pixels. The models differ only in their position encoding methods. For each position encoding method, 8 different hyperparameter settings were evaluated. The table shows both the best and average Top-1 accuracy across these 8 runs, providing a robust comparison of the effectiveness of different position encoding techniques in the context of ViT models.

This table presents the Top-1 accuracy results for various Vision Transformer (ViT) models trained on the ImageNet dataset for 150 epochs. The models were trained and evaluated at a resolution of 224x224 pixels. The table shows both the best and average accuracy across eight different hyperparameter settings (8-run hyperparameter sweep) for each of the listed position encoding methods, providing a comprehensive comparison of their performance on the ImageNet validation set.

This table presents the Top-1 accuracy results for Vision Transformer (ViT)-B models trained on ImageNet for 150 epochs. The models were trained and evaluated at a resolution of 224x224 pixels. The table shows the best and average performance across eight different hyperparameter settings for various position encoding methods, including the proposed LookHere method and several baseline methods. The results provide a comparison of the performance of different position encoding techniques on image classification.

This table presents the Top-1 accuracy results for Vision Transformer-Base/16 (ViT-B/16) models trained on the ImageNet dataset for 150 epochs. The models were trained and evaluated at a resolution of 224x224 pixels. The table shows both the best and average performance across eight different hyperparameter settings, allowing for a robust comparison of different position encoding methods.

This table presents the top-1 accuracy results for various Vision Transformer (ViT) models trained on the ImageNet dataset for 150 epochs. The models were trained and evaluated at a resolution of 224x224 pixels. The table shows both the best and average accuracy across eight hyperparameter runs for each model, enabling a comparison of performance and robustness across different position encoding methods. The results are crucial for evaluating the effectiveness of different position encoding methods in vision transformers.
Full paper#