↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Cross-domain few-shot learning (CDFSL) faces challenges when using Vision Transformers (ViTs) due to large domain gaps affecting transferability. Existing methods struggle to effectively transfer knowledge from large source datasets to target datasets with limited samples. The paper reveals that the query-key attention mechanism in ViTs, while effective for discriminability in the source domain, lacks transferability across domains. This leads to ineffective attention in the target domain, hindering performance.
To address this, the researchers propose a novel method involving attention temperature adjustment. By multiplying the attention mechanism by a temperature parameter, they find that even reducing the attention map to a uniform distribution improves the target domain performance. They interpret this as a remedy for the ineffective target-domain attention caused by the query-key mechanism. Further, they propose a method to boost ViT’s transferability by adjusting attention mechanisms during training to resist learning query-key parameters and encourage learning non-query-key ones. Experimental results demonstrate consistent outperformance of state-of-the-art methods across four CDFSL datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical issue in cross-domain few-shot learning, a field with many real-world applications. By identifying and addressing the low transferability of the query-key attention mechanism in Vision Transformers, this research opens new avenues for improving the performance of these models, particularly in domains with limited data. This has broad implications for various fields where deep learning is used.
Visual Insights#
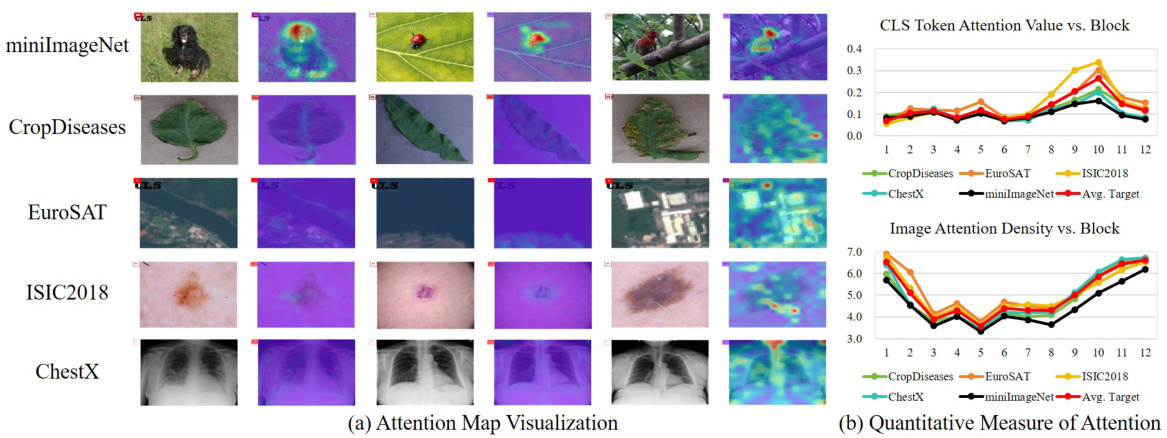
This figure visualizes and quantifies the attention mechanism of Vision Transformers (ViTs) in cross-domain few-shot learning. Panel (a) shows heatmaps of attention weights for different datasets, highlighting that ViTs trained on miniImageNet (source domain) struggle to focus effectively on relevant image regions in target domains. Instead, they often focus disproportionately on the classification (CLS) token and/or noisy image regions. Panel (b) provides a quantitative analysis. It graphs the attention weight on the CLS token and the density of attention across image tokens for each dataset. The consistent drop in attention to image features in the target domains, compared to miniImageNet, supports the claim that the temperature adjustment in the attention mechanism alleviates this issue by addressing ineffective target domain attention.

This table presents the ablation study of removing the attention network from the last block of the Vision Transformer (ViT) model. It shows the impact of different attention mechanisms (Self-Attention (SA), Identity SA, Cosine SA, Average SA) on the classification accuracy across five datasets (miniImageNet, CropDiseases, EuroSAT, ISIC2018, ChestX). The results demonstrate the impact of self-attention on both source and target domain performance.
In-depth insights#
ViT Transferability#
The core issue explored in the paper is Vision Transformer (ViT) transferability in cross-domain few-shot learning (CDFSL). A key observation is that ViT’s strong performance on large datasets doesn’t automatically translate to success in CDFSL scenarios with limited data and significant domain shifts. The paper highlights the ineffective target-domain attention in ViTs as a major factor limiting transferability. This is attributed to the high discriminability but low transferability of the query-key attention mechanism. A simple yet effective solution is proposed: introducing a temperature parameter to the attention mechanism, which improves target domain performance even with a uniform attention map. This suggests that the temperature adjustment remedies the ineffective target-domain attention, primarily caused by the query-key parts. The research emphasizes the trade-off between the high discriminability of query-key components and their limited transferability, proposing to improve transferability by focusing on non-query-key aspects of the ViT architecture. The experiments strongly suggest that adjusting the attention temperature is a key factor in enhancing ViT’s transferability in CDFSL settings.
Attn Temp Impact#
The section ‘Attn Temp Impact’ would explore how altering the attention mechanism’s temperature in Vision Transformers (ViTs) affects cross-domain few-shot learning (CDFSL). A lower temperature, surprisingly, improves target domain performance, even resulting in a uniform attention map. This suggests the query-key attention mechanism in ViTs, while effective for discriminative learning in the source domain, hinders transferability to target domains with large domain gaps. The analysis would likely dissect why reduced temperature helps, proposing that it remedies ineffective target-domain attention by preventing overfitting to source-domain features. The optimal temperature would balance discriminability (high in the source domain) and transferability (low in the source, but improved in the target domain). Experiments would validate this, demonstrating consistent performance gains across various CDFSL datasets. This investigation is novel and offers a simple yet effective method to improve ViT transferability in CDFSL, highlighting the crucial role of attention temperature.
Query-Key Analysis#
A query-key analysis of a Vision Transformer (ViT) in a cross-domain few-shot learning (CDFSL) context would likely focus on the role of the query and key matrices in the self-attention mechanism, particularly concerning their transferability across different domains. The core question would be whether the attention mechanism’s discriminative power within the source domain translates effectively to the target domain, which typically has significantly different data characteristics. A key finding might be that while query-key attention excels at discerning features in the source domain, this discriminative ability comes at the cost of reduced transferability. This could manifest as the model focusing excessively on the class token (CLS token) in the target domain while neglecting other important image features. The analysis would likely involve visualizing and quantifying attention weights to understand this phenomenon and its impact on performance. A potential solution, suggested by the attention temperature adjustment, is to reduce the discriminative nature of the query-key mechanism by either regularizing or attenuating its influence to enhance transferability. Therefore, a deep dive into the query-key interaction is crucial to understand the limitations of ViT in CDFSL and to develop strategies that mitigate the negative impact of domain gaps on the attention mechanism’s effectiveness.
CDFSL Method#
The core of a successful CDFSL method lies in effectively bridging the domain gap between source and target datasets. This necessitates strategies that enhance the model’s transferability while mitigating negative transfer. A promising approach involves modifying the attention mechanism within a Vision Transformer (ViT) architecture. Specifically, techniques focusing on attention temperature adjustment offer a compelling method for regulating the discriminability and transferability of attention weights. By carefully controlling temperature parameters, the model can be steered toward focusing on features that generalize well across domains, thus enhancing performance with limited target data. Further improvements might involve incorporating data augmentation strategies that specifically address the characteristics of the target domain, or exploring techniques to resist overfitting to the source data during the pre-training phase. This might include methods that encourage the learning of non-query-key parameters within the ViT model, thus improving its adaptability to the unique traits of the target domain. Careful consideration of the trade-off between discriminability and transferability is key. While high discriminability is crucial for performance within the source domain, excessive focus on source-specific features can lead to poor generalization. The optimal method seeks a balance that effectively leverages the knowledge gained from the source while adapting to the target domain’s distinct characteristics. Future improvements could include adaptive mechanisms for dynamically adjusting attention temperature or a more sophisticated approach for selecting the most transferable features.
Future Works#
Future work could explore several promising avenues. Extending the attention temperature approach to other vision tasks beyond cross-domain few-shot learning, such as general image classification or object detection, could reveal broader applicability and effectiveness. Investigating the interaction between attention temperature and other hyperparameters, such as the learning rate or model architecture, would provide a more nuanced understanding. A deeper investigation into why the query-key mechanism exhibits limited transferability is needed. This could involve analyzing attention maps across diverse domains to identify specific patterns. The influence of different data augmentation techniques on the effectiveness of the proposed method requires further exploration. Finally, a comprehensive evaluation across a wider range of datasets and network architectures would enhance the robustness and generalizability claims, helping to establish the proposed approach’s practical value.
More visual insights#
More on figures

This figure visualizes and quantifies the attention mechanism of Vision Transformers (ViTs) in cross-domain few-shot learning. Part (a) shows heatmaps of attention weights, highlighting that ViTs trained on a source domain struggle to focus on relevant image regions in the target domains; instead, they inappropriately focus on the CLS token or noisy regions. Part (b) provides quantitative analysis by plotting attention values on the CLS token and attention density on image tokens. The consistently lower values for miniImageNet (source domain) compared to target domains supports the claim that target-domain attention is ineffective, and the temperature adjustment is a remedy.

This figure illustrates the proposed method for source-domain training. It shows a ViT block with the attention mechanism. A binary variable, τ, is introduced to randomly drop out (set to 0) or keep (set to 1) the attention network. By randomly setting τ to 0, the learning of query-key attention parameters is resisted and the non-query-key parts are enhanced, improving the model’s transferability in cross-domain few-shot learning.
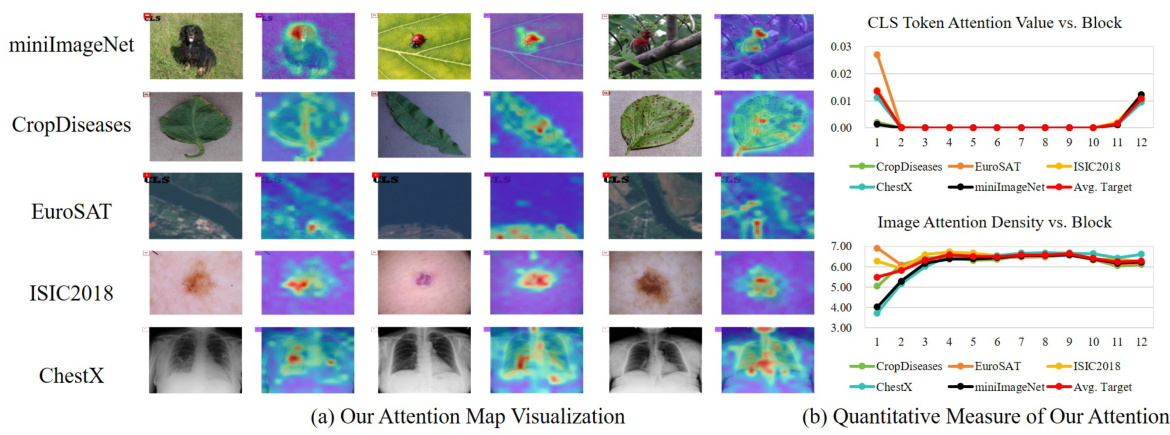
This figure visualizes and quantitatively analyzes the attention maps of the improved model. (a) shows that the model now correctly attends to image features instead of only the CLS token, focusing on meaningful regions. (b) demonstrates that the attention values and densities are consistent across source and target domains, highlighting improved transferability.

This figure presents an ablation study on the proposed method, showing the impact of different components on domain similarity and accuracy. (a) shows that domain similarity consistently improves with the proposed method. (b) shows that the accuracy gap between different attention mechanisms is reduced with the proposed method. (c) shows the effect of the probability of abandoning query-key attention on accuracy, indicating a high probability helps transferability. (d) demonstrates the necessity of including all blocks in the attention abandonment process. The results highlight the effectiveness of the proposed approach in improving cross-domain transferability.

This figure shows sample images from the source domain (miniImageNet) and four target domains used in the cross-domain few-shot learning experiments. The source domain contains images of diverse objects (animals, landscapes, objects), while each target domain shows a specific image category: CropDiseases (plant diseases), EuroSAT (satellite imagery), ISIC2018 (skin lesions), and ChestX (chest X-rays). The visual differences highlight the significant domain gaps that the proposed method addresses.

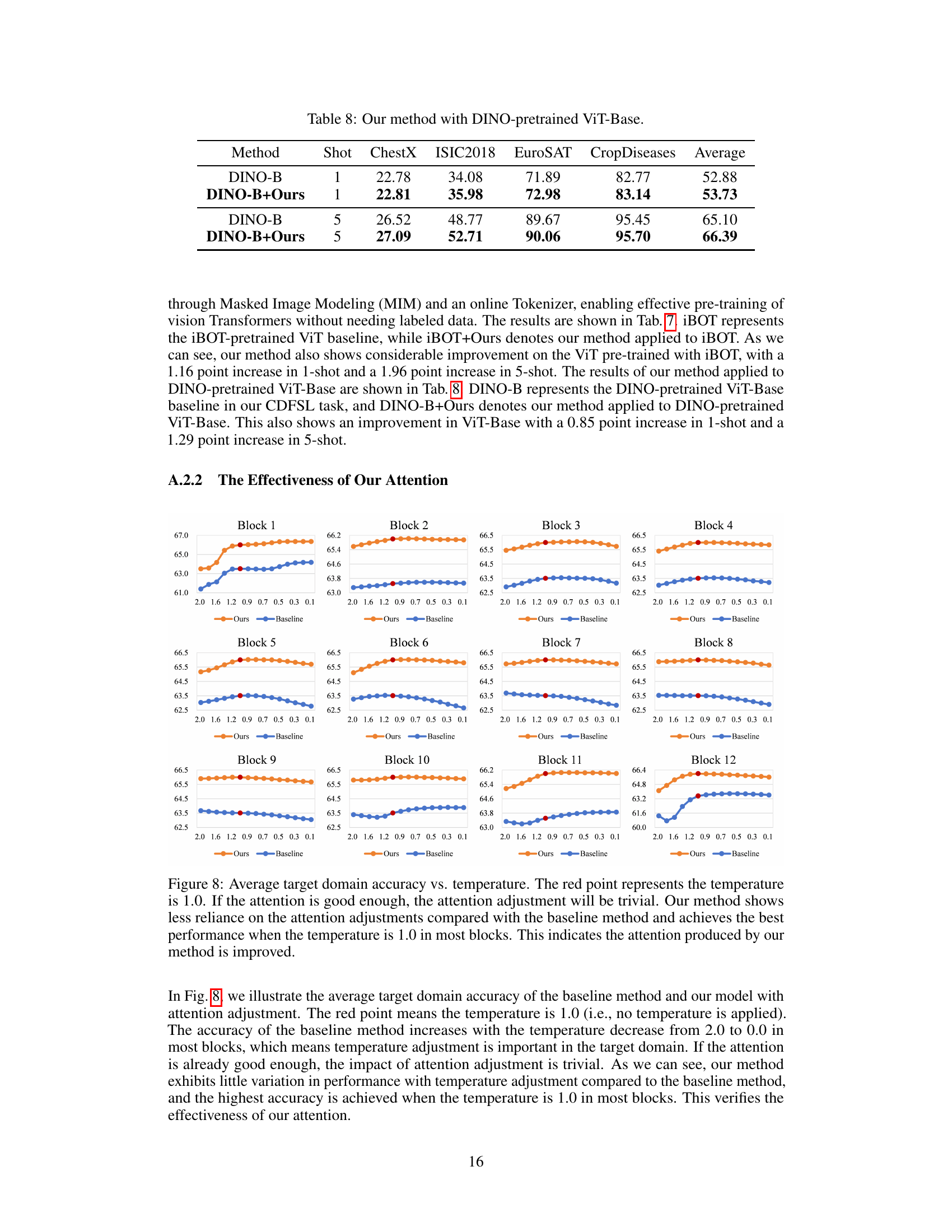
This figure shows the average target domain accuracy for both the proposed method and the baseline method across different temperature values (from 0.1 to 2.0) for each of the 12 blocks in the ViT architecture. The red point on each curve indicates a temperature of 1.0 (no temperature adjustment). The results show that the proposed method is less sensitive to temperature adjustments than the baseline, indicating that the attention mechanism in the proposed method is more effective and requires less fine-tuning.
More on tables

This table presents the domain similarity results calculated using the Centered Kernel Alignment (CKA) method. It compares the similarity between the source domain (miniImageNet) and the target domains (CropDiseases, EuroSAT, ISIC2018, ChestX) for different ablated attention modules in the Vision Transformer (ViT) network. The modules ablated include the input tokens only, the input tokens with self-attention, input tokens with identity self-attention, input tokens with cosine self-attention, and input tokens with average self-attention. A higher CKA value indicates higher similarity between domains, showing lower domain transferability. The table helps in the analysis of how different attention mechanisms affect the transferability of ViT across different domains.
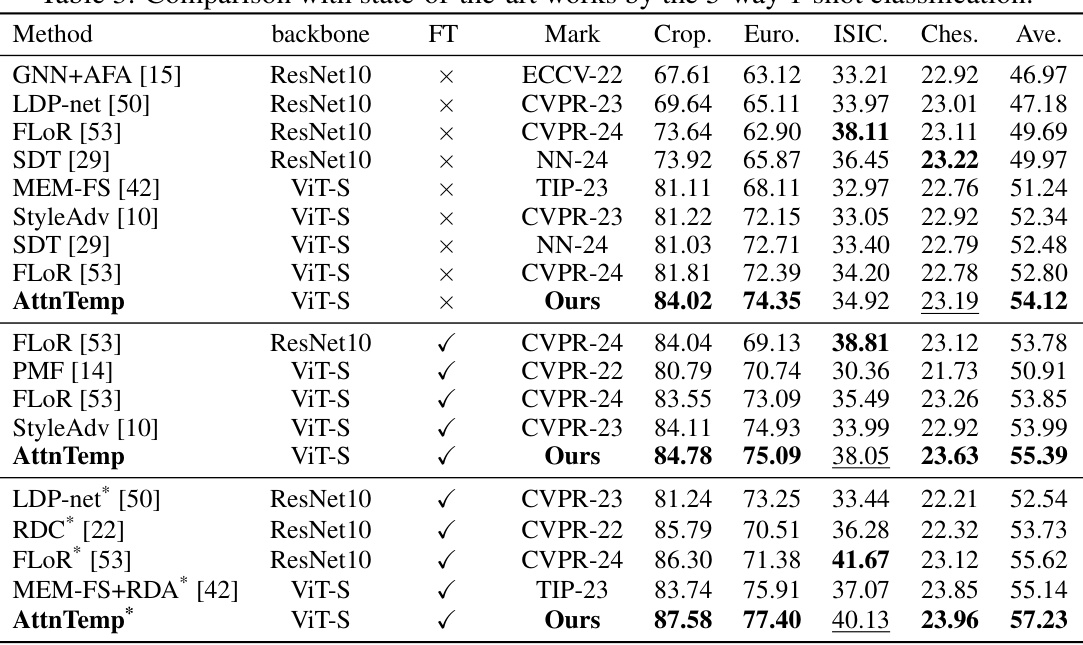
This table compares the proposed AttnTemp method with other state-of-the-art methods on a 5-way 1-shot classification task across four benchmark datasets (CropDiseases, EuroSAT, ISIC2018, and ChestX). It shows the average accuracy achieved by each method on each dataset, broken down by whether or not fine-tuning (FT) was used. The table allows for a comparison of performance between different backbone networks (ResNet10 and ViT-S) and highlights the improvement achieved by the AttnTemp method.
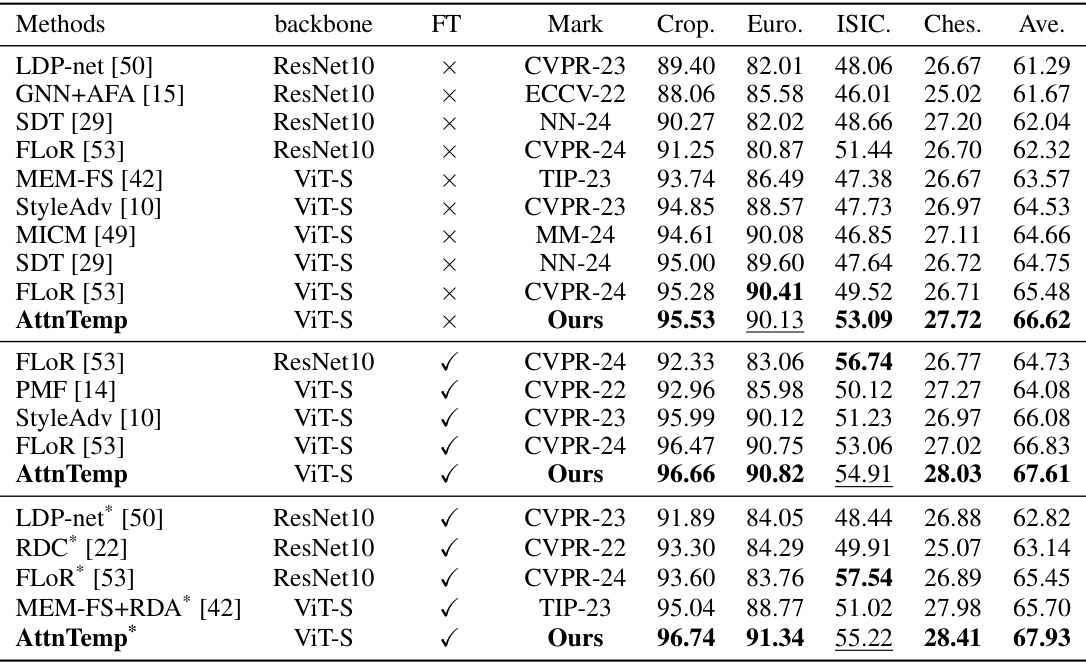
This table compares the proposed AttnTemp method with other state-of-the-art methods on a 5-way 1-shot classification task. It shows the backbone network used (ResNet10 or ViT-S), whether fine-tuning (FT) was employed, the conference and year of publication, and the accuracy achieved on four different target datasets (Crop, Euro, ISIC, Ches) and the average accuracy across all four datasets. The table helps demonstrate the improved performance of AttnTemp compared to existing approaches.
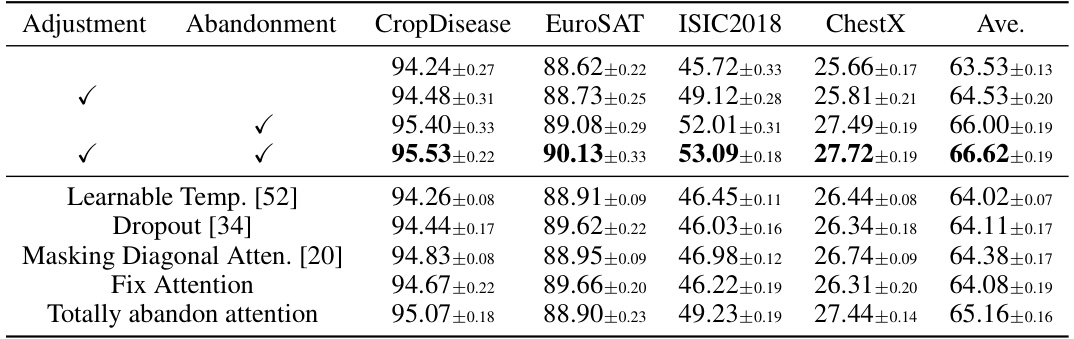
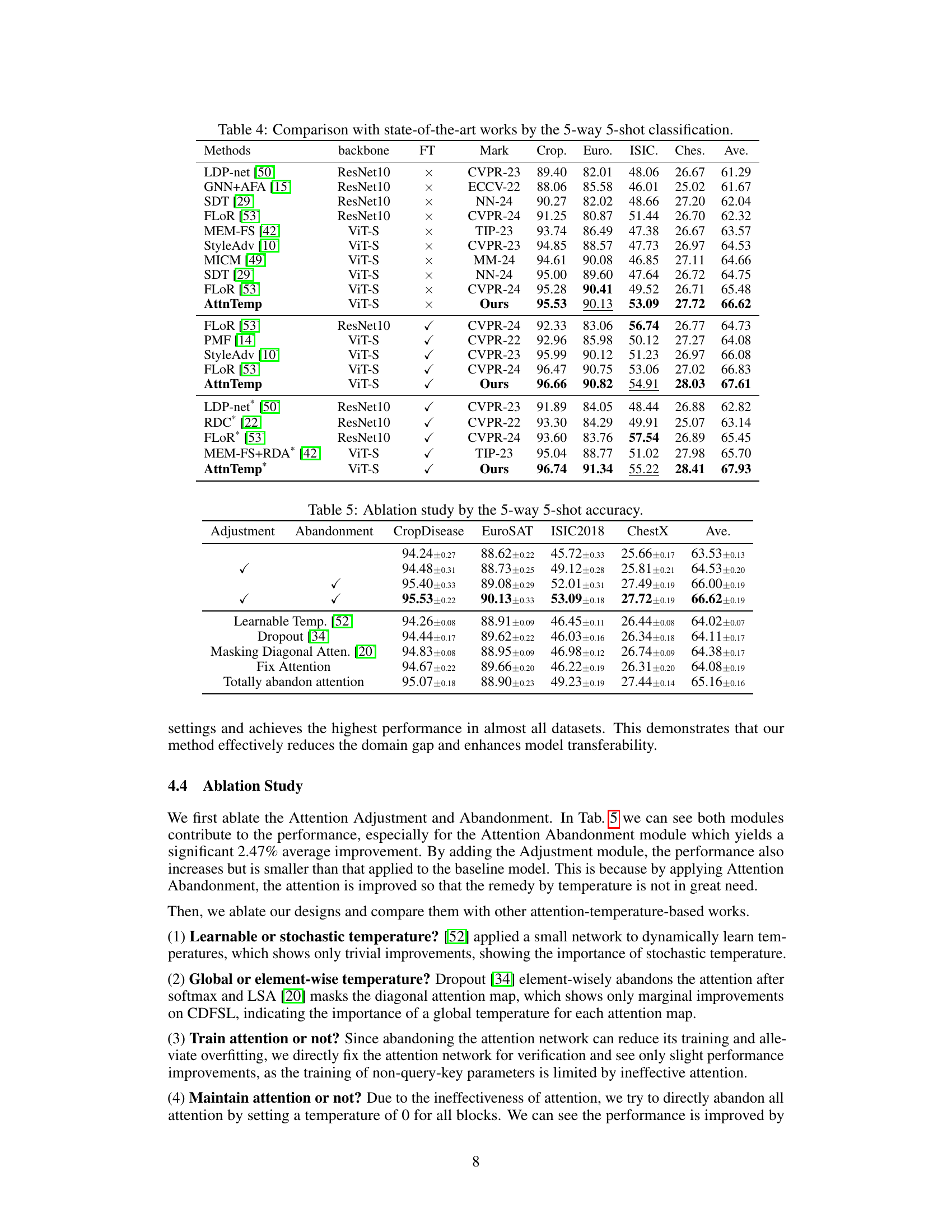
This table presents the ablation study of the proposed method on the 5-way 5-shot accuracy task. It compares the performance of different variants of the method, specifically varying whether the attention adjustment and abandonment modules are used. The results are presented in terms of accuracy for four target datasets (CropDisease, EuroSAT, ISIC2018, ChestX) and their average.

This table presents a comparison of the baseline (BL) and the proposed method’s performance across different ViT blocks (1-12). It shows the Centered Kernel Alignment (CKA) similarity scores, measuring the similarity between the feature representations learned by the baseline and the proposed method across various blocks. The table also lists the accuracy (Acc.) for both methods on the target domain, illustrating the improvement in performance achieved by the proposed method, which enhances the transferability of the attention networks and improves the accuracy of target domain classification.

This table presents the ablation study results on four target datasets (ChestX, ISIC2018, EuroSAT, CropDiseases) using 1-shot and 5-shot settings. It compares the performance of the baseline iBOT (Image BERT pre-training) method with the proposed AttnTemp method (Attention Temperature). The results show that the proposed method consistently improves the accuracy on all four datasets and in both shot settings, indicating the effectiveness of the attention temperature adjustment technique in enhancing cross-domain few-shot learning.

This table presents a comparison of the performance of the baseline method (DINO-B) and the proposed method (DINO-B+Ours) using a ViT-Base model pretrained with DINO. The results are shown for both 1-shot and 5-shot settings across four target datasets (ChestX, ISIC2018, EuroSAT, CropDiseases). The average accuracy across all four datasets is also provided for each setting and method.
Full paper#