↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Image-to-video (I2V) generation using diffusion models has made significant strides. However, existing models often struggle to generate videos with sufficient motion, a phenomenon attributed to ‘conditional image leakage’. This occurs because the model excessively relies on the static input image during the generative process, neglecting the dynamic information embedded within the noisy input at later time steps. This over-reliance on the input image leads to videos with noticeably less motion and less dynamic scenes.
To address this issue, the authors propose a two-pronged approach. Firstly, they modify the inference process by initiating video generation from an earlier time step. Secondly, they introduce a time-dependent noise distribution to the conditional image during training, progressively increasing noise at larger timesteps to reduce the model’s dependence on it. This dual strategy is validated across various I2V diffusion models using benchmark datasets, resulting in videos with significantly improved motion scores, reduced errors, and maintained image alignment and temporal consistency. The results demonstrate a superior overall performance, particularly in terms of motion accuracy and control.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image-to-video generation because it identifies and solves a critical, previously overlooked issue: conditional image leakage. This problem, where models over-rely on the input image and produce videos with less motion than expected, is widely applicable. The solutions proposed—an improved inference strategy and a novel time-dependent noise distribution—are generalizable and significantly improve motion control. This work opens new avenues for enhancing the realism and dynamics of AI-generated videos.
Visual Insights#

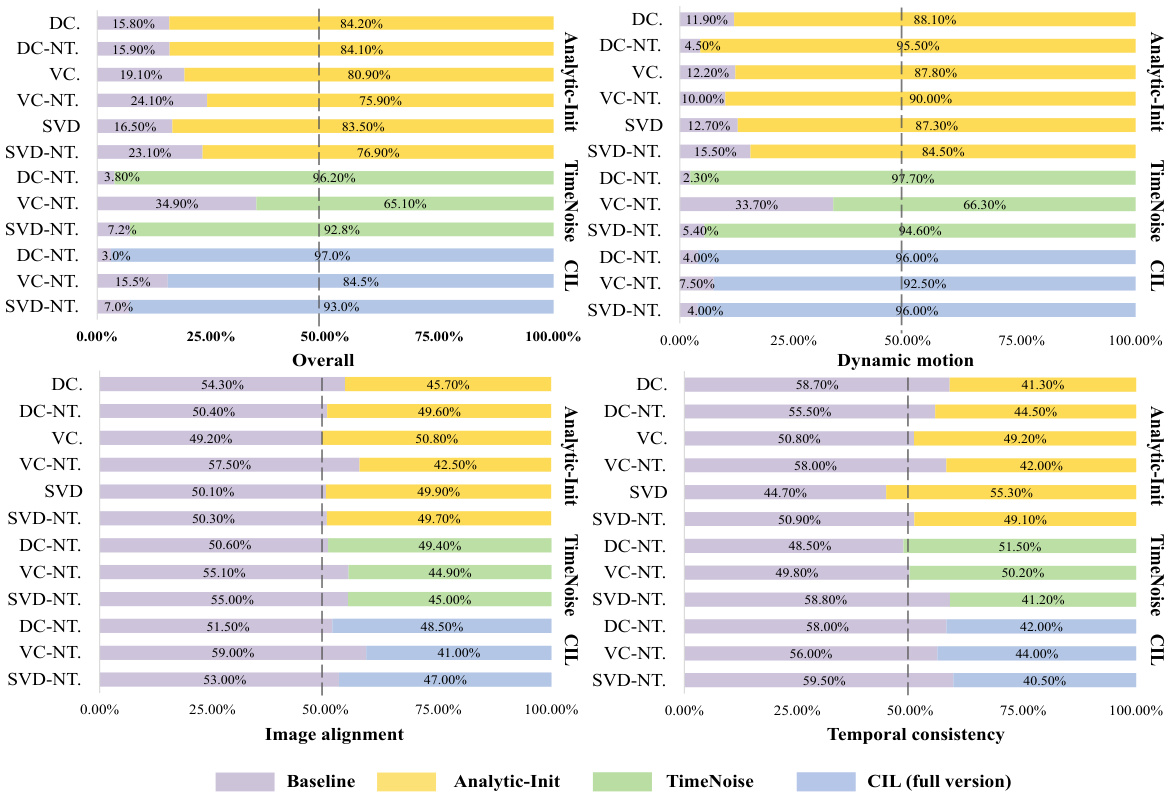
This figure shows a comparison of motion scores between existing image-to-video diffusion models (I2V-DMs) and the proposed method. The input motion score (Input MS) represents the motion content of the input video. The output motion score (Output MS) is the motion content of the video generated by the model. Existing I2V-DMs consistently produce videos with lower motion scores than expected, regardless of the input motion score. The proposed method, however, generates videos with motion scores that are more accurately aligned with the Input MS, showing improved motion control.
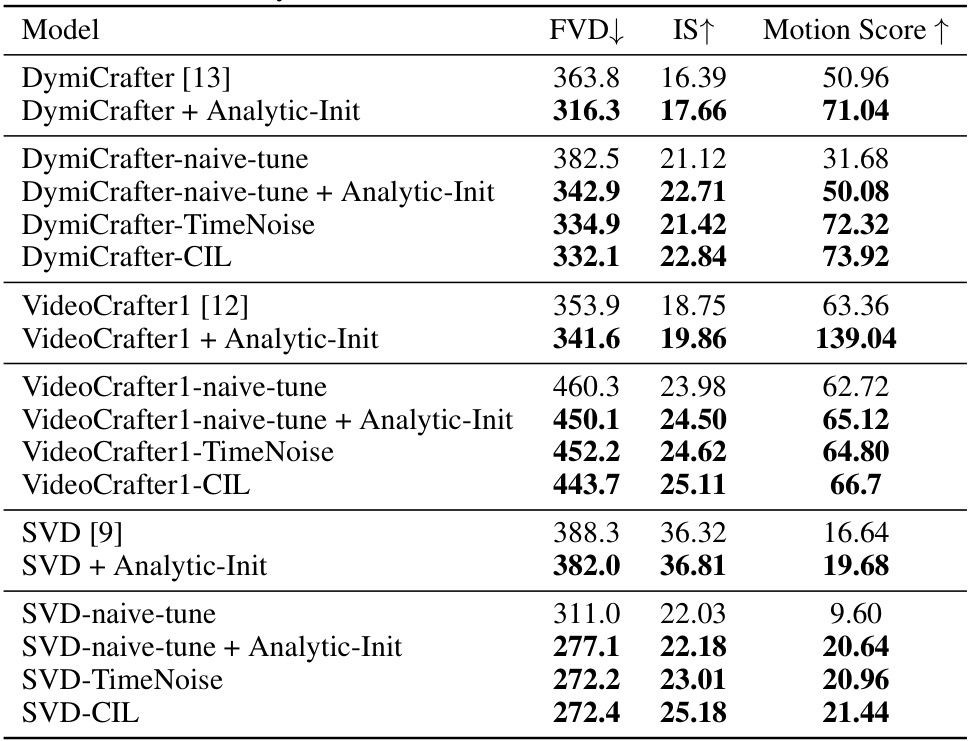
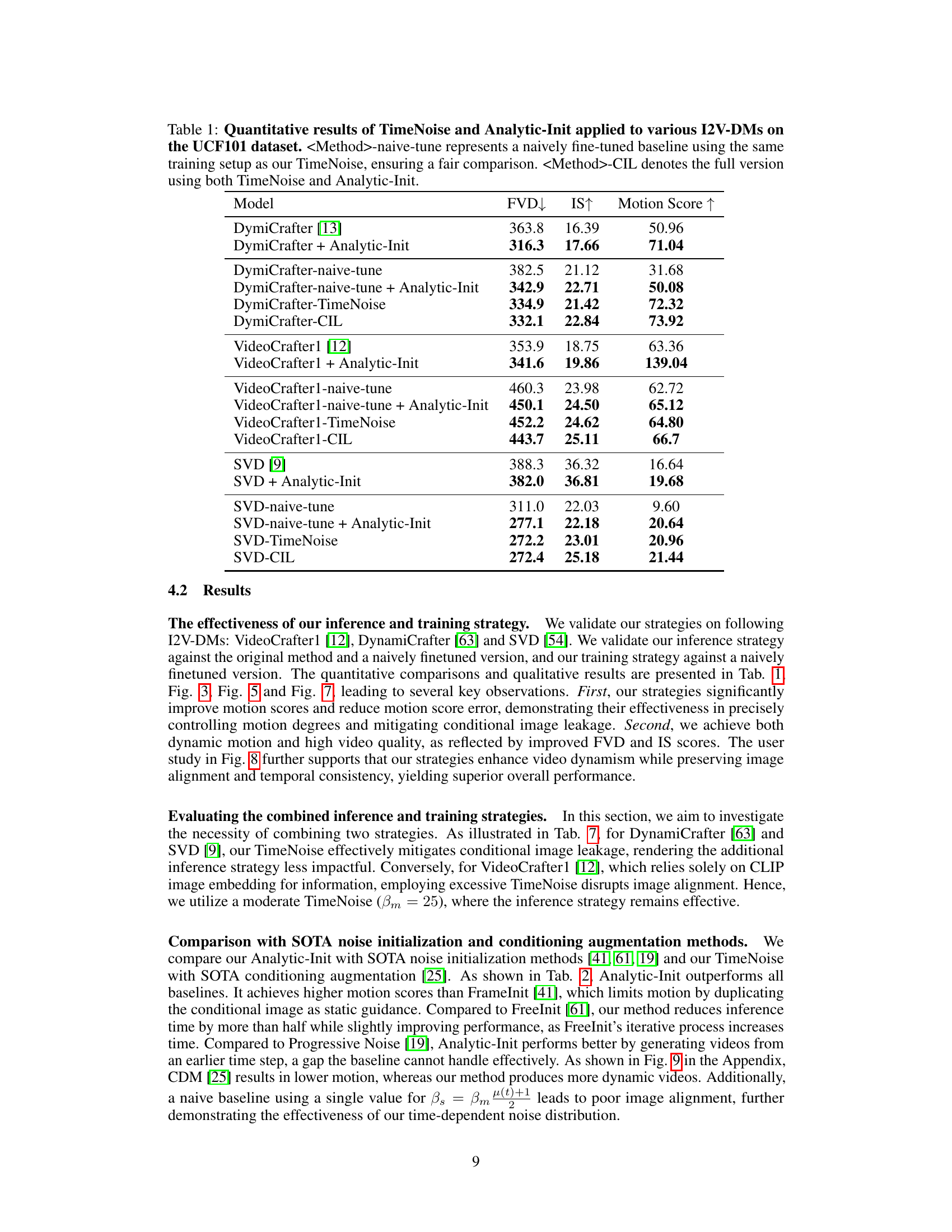
This table presents a quantitative comparison of the proposed TimeNoise and Analytic-Init methods against baseline I2V-DMs on the UCF101 dataset. It shows the performance of several models (DymiCrafter, VideoCrafter1, and SVD) under different conditions: baseline, with Analytic-Init only, with TimeNoise only, and with both methods combined. The metrics used are Fréchet Video Distance (FVD), Inception Score (IS), and Motion Score (MS). Lower FVD and higher IS and MS values indicate better performance.
In-depth insights#
Conditional Image Leak#
The concept of “Conditional Image Leak” in image-to-video diffusion models highlights a critical challenge: the model’s over-reliance on the provided conditional image, especially during later stages of the diffusion process. This leads to videos with reduced motion and less dynamic content than expected. The core issue is that as noise is progressively added during generation, the noisy input loses detail, but the conditional image remains sharp. The model prioritizes the clearer conditional image over the noisy input’s motion information, effectively suppressing the temporal dynamics that should be generated. This leak is especially problematic in image-to-video generation where accurate motion reconstruction is paramount. Addressing this requires strategies that either limit the model’s reliance on the conditional image at later time steps or modify the conditional input itself to reduce its dominance over the diffusion process. Solutions involve starting the generation process earlier (avoiding unreliable later steps), using a modified initial noise distribution, or introducing time-dependent noise into the conditional image. By addressing this issue, diffusion models can generate more realistic and dynamic videos.
Analytic-Init & TimeNoise#
The proposed methods, Analytic-Init and TimeNoise, address the issue of conditional image leakage in image-to-video diffusion models. Analytic-Init tackles the training-inference discrepancy by optimizing the initial noise distribution, thus ensuring smoother transitions and improved visual quality, particularly when starting the generation process earlier. TimeNoise directly addresses image leakage during training by introducing a time-dependent noise schedule to the conditional image, reducing the model’s over-reliance on static input at later stages. The combination of these techniques significantly improves video generation, resulting in videos with more dynamic motion and greater adherence to the conditional image content while maintaining high visual fidelity. This two-pronged approach is validated through extensive empirical results, demonstrating superior performance compared to baselines across various metrics, including motion scores and perceptual quality assessments. The synergistic effect of both methods highlights the importance of considering both inference and training aspects when tackling the challenge of conditional image leakage.
I2V-DM Motion Control#
I2V-DM (Image-to-Video Diffusion Model) motion control presents a significant challenge in AI video generation. Current I2V-DMs often struggle to produce videos with the expected level of dynamic motion, exhibiting a phenomenon called “conditional image leakage.” This leakage stems from the models over-relying on the static input image at later stages of the diffusion process, neglecting the noisy input that carries crucial motion information. Effective motion control requires mitigating this leakage, improving the model’s ability to leverage the noisy input while maintaining image fidelity. This can be approached by modifying the training process to introduce time-dependent noise to the input image, making the model less reliant on its initial state. Furthermore, improving inference involves starting the video generation from an earlier time step, avoiding the most unreliable points in the diffusion process. Optimal initialization of the noise distribution can also enhance performance by reducing training-inference mismatch. The ultimate goal is to achieve a balance between generating high-motion videos that accurately reflect the input image and maintaining temporal and spatial consistency, allowing for precise and natural motion control.
CIL Mitigation Strategies#
The core of addressing Conditional Image Leakage (CIL) lies in mitigating the model’s over-reliance on the conditional image, especially during later stages of the diffusion process. This necessitates a two-pronged approach focusing on both inference and training. Inference strategies primarily involve starting the generation process from an earlier time step, circumventing the unreliable, heavily corrupted later stages where CIL is most pronounced. This is further enhanced by using an analytically derived initial noise distribution that optimally bridges the training-inference gap, improving visual quality and motion accuracy. On the training side, the key is to strategically introduce time-dependent noise to the conditional image. By applying higher noise levels at larger time steps, the model’s dependency on the conditional image is disrupted, and more natural video motion is encouraged. This carefully balanced approach aims to optimize model learning, ensuring the generated videos retain the fidelity of the input image while simultaneously exhibiting more realistic, dynamic motion. The effectiveness of these combined strategies is empirically validated, showcasing significant improvements in motion scores while maintaining image alignment and temporal consistency.
Future I2V Research#
Future research in image-to-video (I2V) generation should prioritize addressing the limitations of current diffusion models. Improving motion realism and diversity is crucial, moving beyond simple, repetitive movements to generate videos with nuanced, natural-looking motion. This requires exploring new architectures, loss functions, and training strategies. Furthermore, enhancing controllability over video generation is important, enabling users to fine-tune aspects like speed, style, and object behavior. This could involve incorporating more sophisticated conditioning mechanisms or developing interactive tools. Addressing conditional image leakage remains a key challenge; future work should focus on techniques that effectively balance using the conditional image for content while relying on the noise for motion generation. Finally, improving efficiency and scalability is necessary to make I2V accessible for wider applications. This may include developing faster algorithms, exploring more efficient model architectures, or creating methods to better leverage pretrained models.
More visual insights#
More on figures
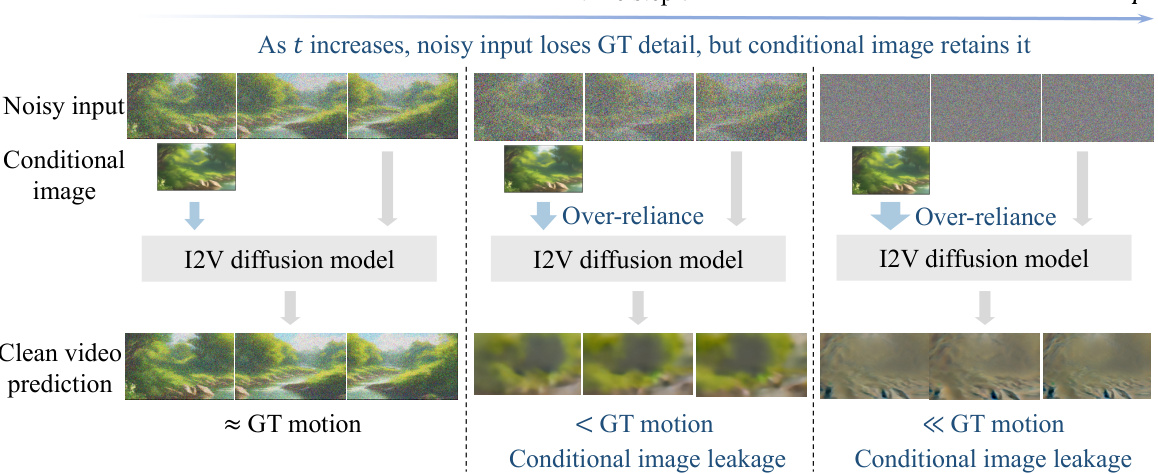
This figure illustrates the phenomenon of conditional image leakage in image-to-video diffusion models. As the diffusion process advances (time step increases), the noisy input representing motion information gets increasingly corrupted. However, the conditional image (the input image guiding the video generation) retains a lot of detail about the target video. This causes the model to heavily rely on the conditional image, ignoring the increasingly noisy input. As a consequence, the resulting video has significantly less motion than expected, which is the effect of conditional image leakage.
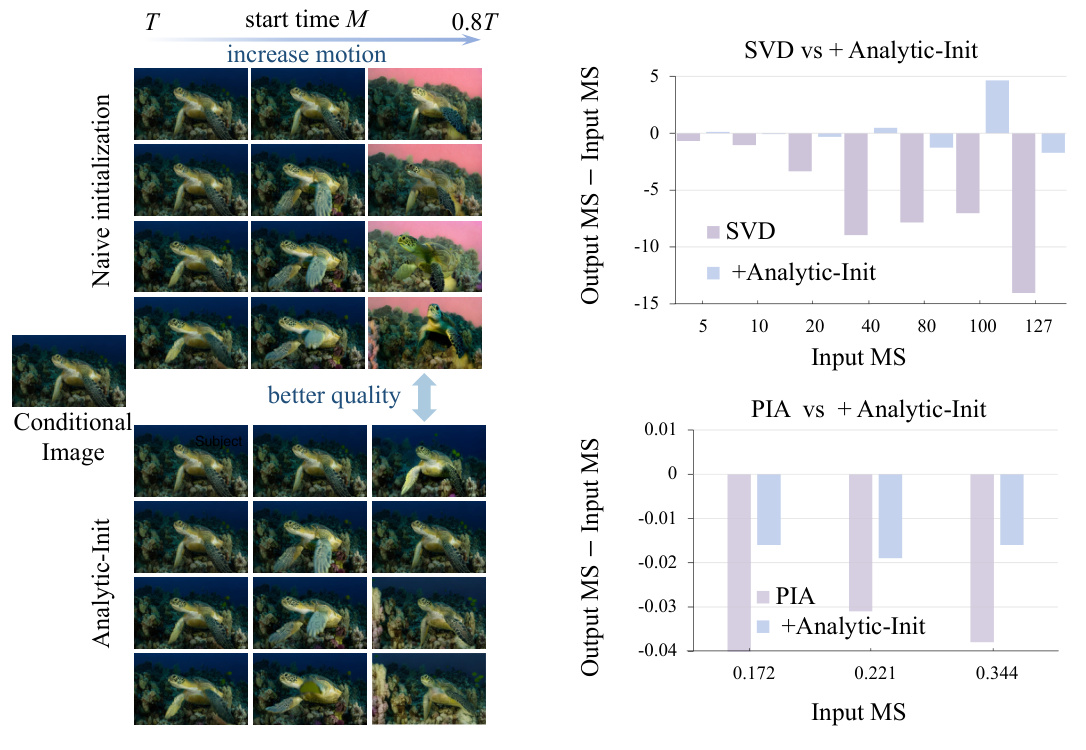
This figure shows the benefits of using Analytic-Init, a method proposed in the paper to improve image-to-video generation. The left panel (a) demonstrates that starting the generation process from an earlier time step (M) increases motion, but excessively early start times reduce image quality due to a training-inference gap. Analytic-Init bridges this gap, improving image quality even when starting early. The right panel (b) quantitatively shows how Analytic-Init reduces the error in motion scores, indicating a reduction in conditional image leakage.
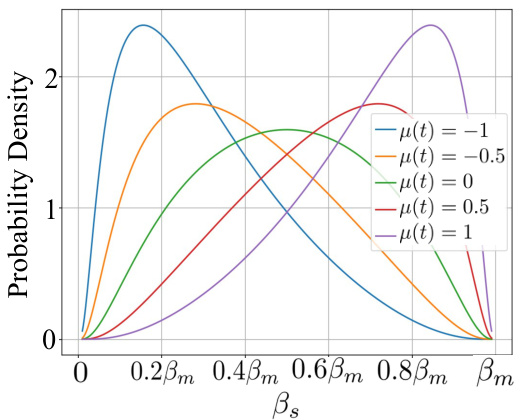
This figure visualizes the TimeNoise, a time-dependent noise distribution, and its hyperparameters’ impact on video generation. Panel (a) shows the probability density function of the noise distribution, demonstrating its ability to favor high noise levels at larger time steps (t) and gradually decrease noise levels as time progresses. Panel (b) illustrates how the center (µ(t)) of the distribution monotonically increases with time, further highlighting the time-dependent nature. Lastly, panel (c) shows the effect of tuning hyperparameters ‘a’ and ‘Bm’ on a balance between increasing video motion and maintaining image alignment, indicating a trade-off where higher noise levels can lead to more motion but potentially less accurate image alignment.
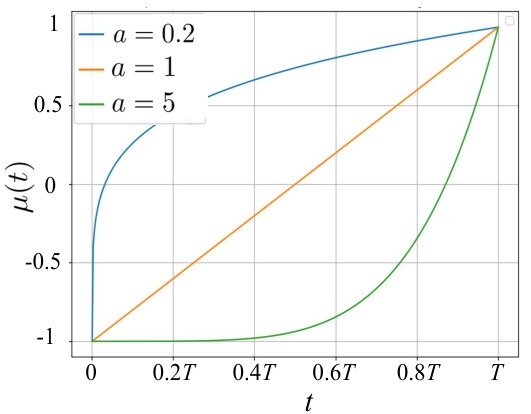
This figure visualizes the TimeNoise and its hyperparameters. Subfigure (a) shows the time-dependent noise distribution pt(Bs), which favors high noise levels at large t and gradually shifts to lower noise levels as t decreases. Subfigure (b) illustrates the monotonically increasing behavior of μ(t), the distribution center. Subfigure (c) demonstrates the impact of tuning hyperparameters α and βm on the trade-off between dynamic motion and image alignment.

This figure visualizes the TimeNoise distribution and its hyperparameters’ effects. Panel (a) shows how the probability density of the time-dependent noise (pt(Bs)) changes across different time steps (t), favoring higher noise levels at later steps and gradually reducing noise levels as the generation progresses. Panel (b) illustrates how the distribution center (μ(t)) changes monotonically over time, allowing for flexible control of the noise level. Panel (c) demonstrates the impact of tuning hyperparameters ‘a’ (influencing the shape of μ(t)) and ‘Bm’ (maximum noise) on the balance between motion and image alignment. Higher noise levels enhance motion but can reduce image alignment.

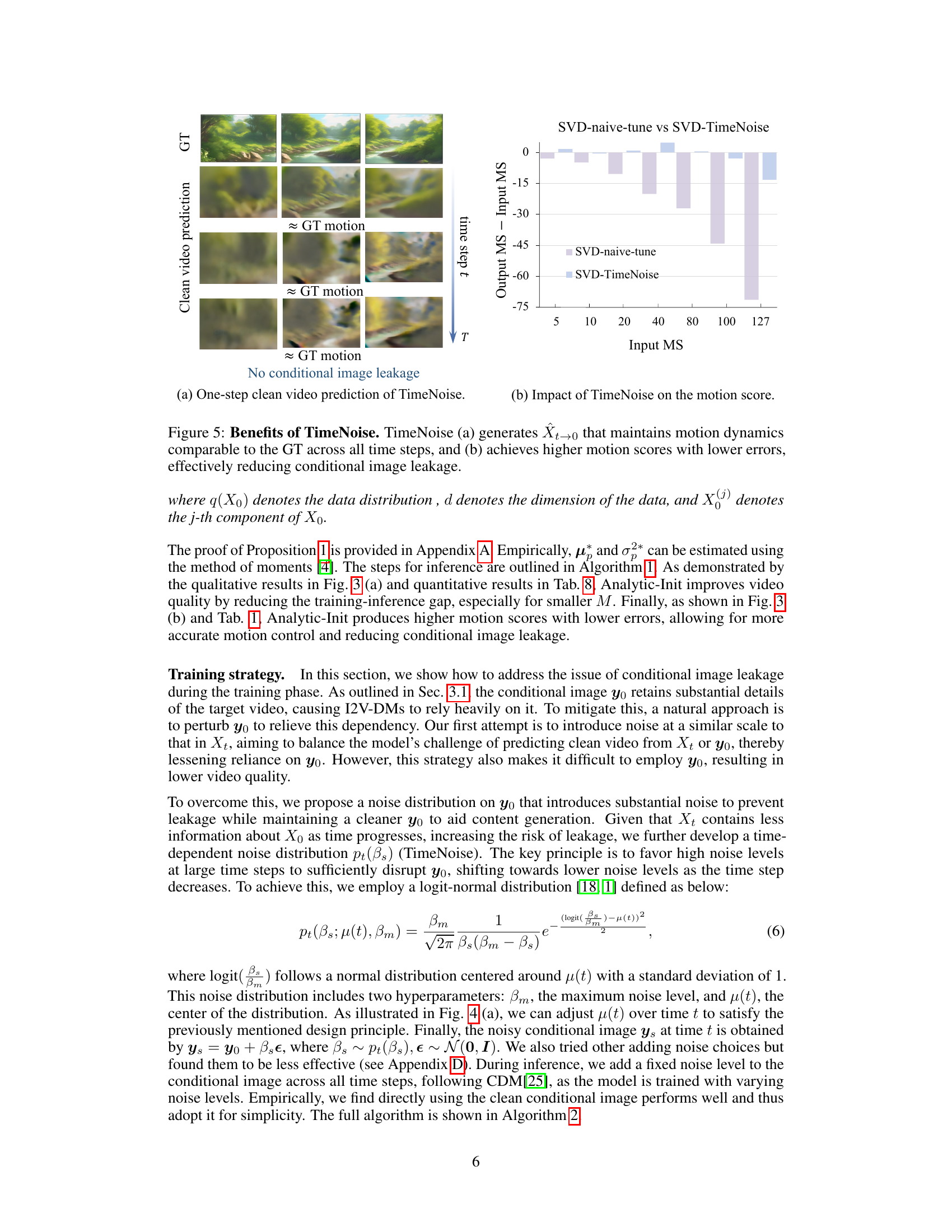
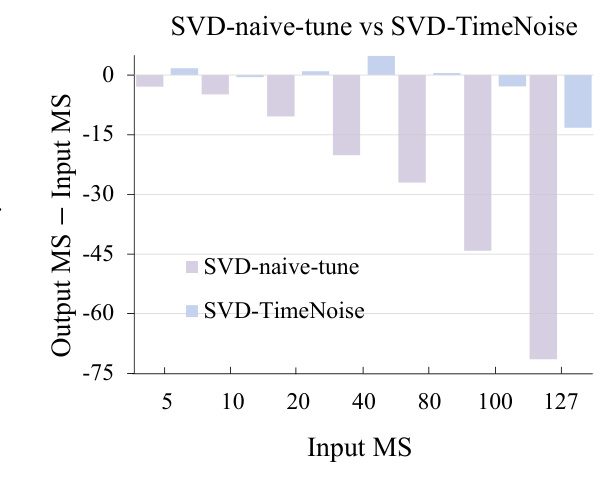
This figure demonstrates the effectiveness of the proposed TimeNoise method in mitigating conditional image leakage. (a) shows that one-step predictions from noisy inputs using TimeNoise maintain motion comparable to ground truth across different time steps. This contrasts with previous methods which show a reduction in motion at later time steps. (b) quantifies the improvement showing higher motion scores and lower errors with TimeNoise compared to a baseline.
This figure shows a comparison of motion scores between existing image-to-video diffusion models (I2V-DMs) and the proposed method. The x-axis represents the input motion scores, and the y-axis represents the difference between the output and input motion scores. Existing I2V-DMs consistently produce lower output motion scores than expected, regardless of the input motion score. In contrast, the proposed method’s output motion scores are more variable, sometimes higher and sometimes lower than expected, but always with a smaller error. This indicates that the proposed method addresses the issue of conditional image leakage, allowing for more accurate motion control.

This figure compares the results of several image-to-video generation models, including I2VGen-XL, VideoCrafter1, SVD, and the authors’ proposed method. It demonstrates how the authors’ method addresses the issue of conditional image leakage, which causes existing models to generate videos with less motion than expected. The comparison highlights that while other methods either compromise image alignment or produce unrealistic motion (static objects with camera movements), the proposed method generates videos with both natural object movements and dynamic camera movements.

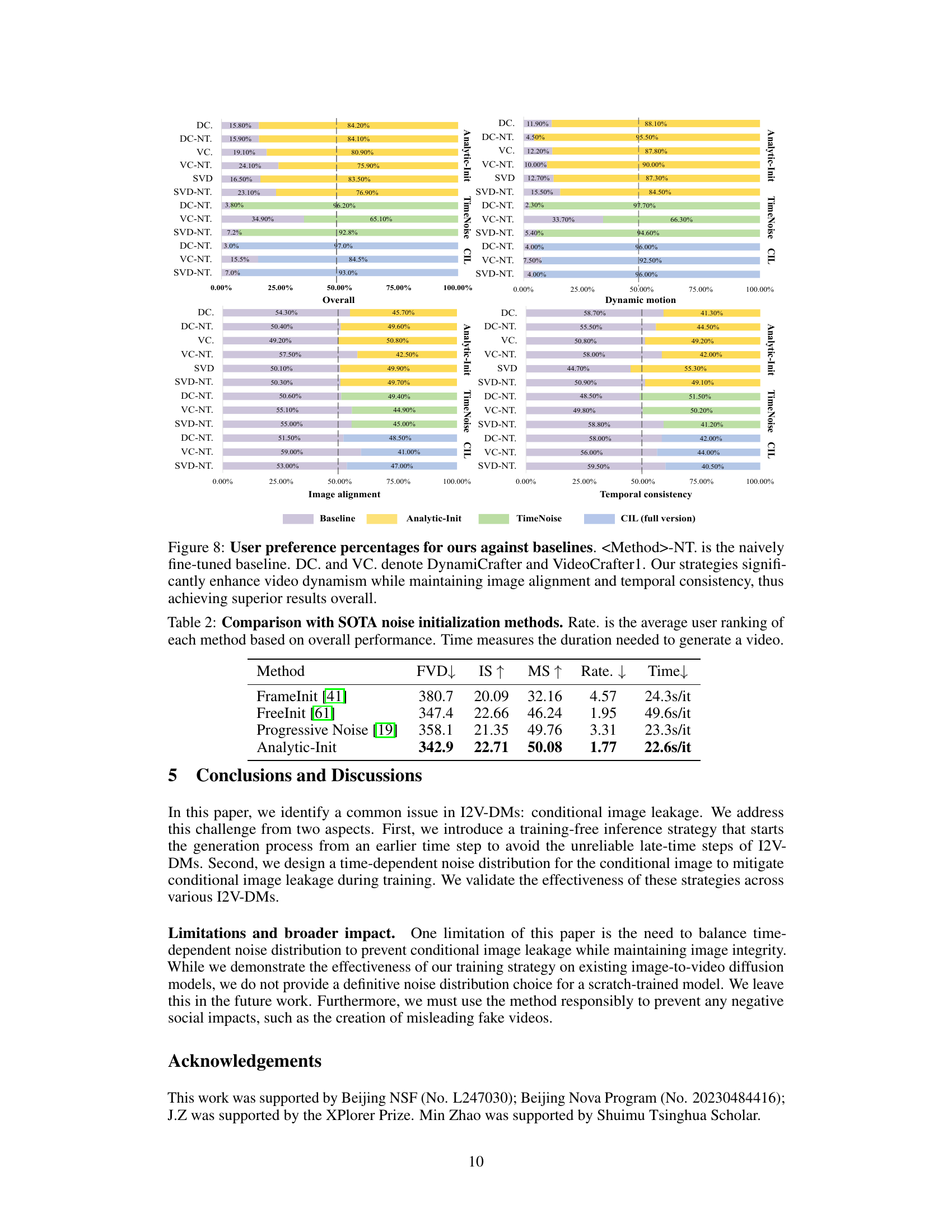
This figure shows the qualitative results of applying TimeNoise and Analytic-Init to different image-to-video diffusion models (I2V-DMs). It compares the results of baseline models with those enhanced by the proposed methods. The figure demonstrates that the proposed methods improve the dynamism of generated videos while preserving image alignment and temporal consistency.
This figure compares the results of three different image-to-video generation models (I2VGen-XL, VideoCrafter1, and the authors’ model) in terms of their ability to generate videos with dynamic object movement while maintaining image alignment. I2VGen-XL and VideoCrafter1 show some mitigation of conditional image leakage, but at a cost of reduced image alignment. SVD, on the other hand, prioritizes generating videos with high motion scores but often does so by creating camera movement and largely stationary objects, rather than more natural dynamic object movement. The authors’ method is presented as achieving both natural and dynamic movement with good image alignment.

This figure compares the visual quality of videos generated by four different methods: a baseline method, a method using a constant noise level, a method using CDM (Conditional Diffusion Model), and the proposed method (TimeNoise). The conditional image shows a kitten approaching a bowl. The baseline method produces a video with a blurry kitten and some artifacts. The constant noise method produces a slightly better result but still has some blurriness. CDM produces a video with acceptable image quality but less motion. The proposed method (TimeNoise) produces a video with sharp details, good motion, and the best overall visual quality.

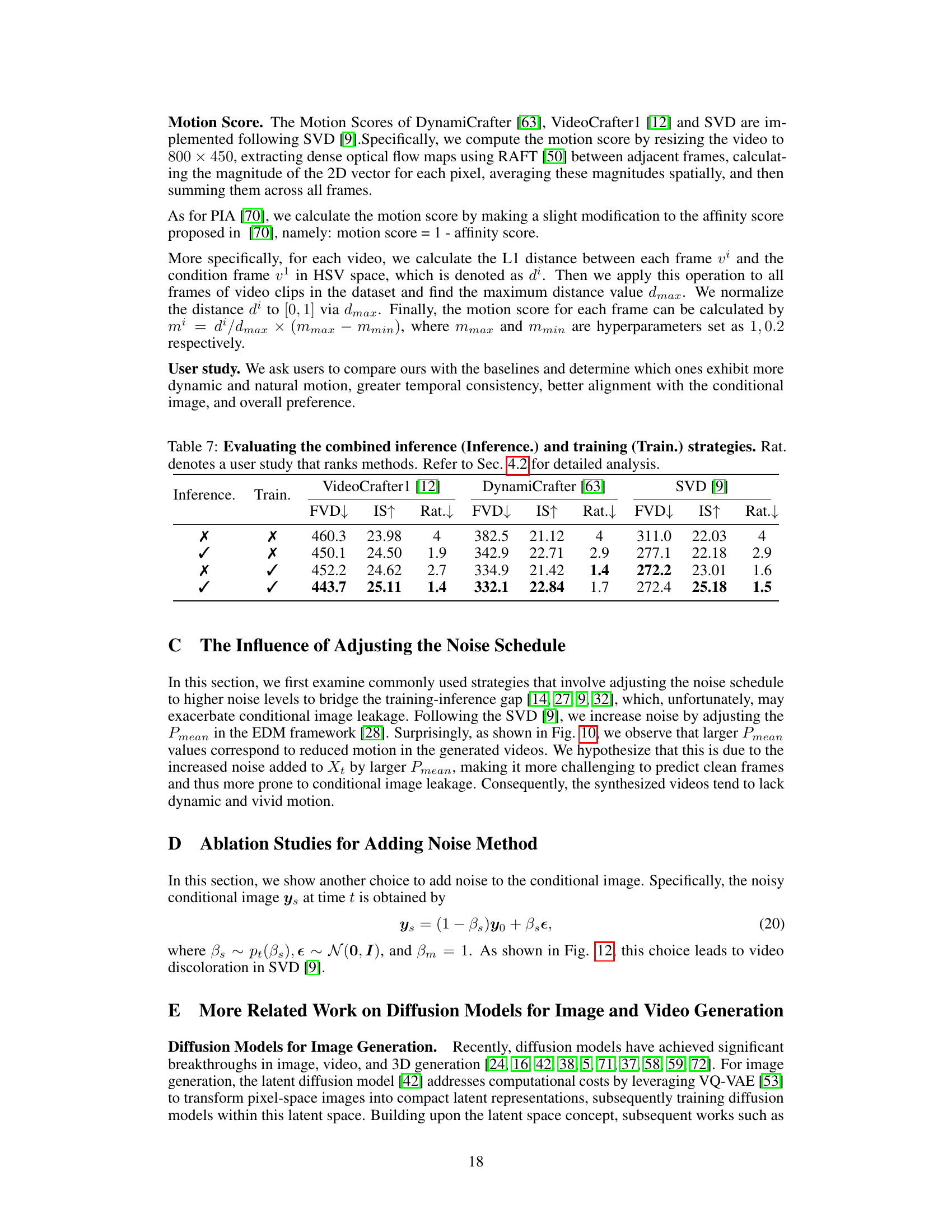
This figure shows that increasing noise levels (by adjusting the noise schedule towards more noise) in the process of video generation leads to a greater over-reliance on the conditional image by the model. This, in turn, results in generated videos that lack dynamic motion and therefore worsen the issue of conditional image leakage.

This figure compares the results of three different image-to-video generation models. The first two, I2VGen-XL and VideoCrafter1, reduce conditional image leakage but at the cost of reducing image alignment in the generated videos. The third model, the authors’ proposed method, achieves both high motion scores and natural, dynamic object movements.

This figure shows the qualitative results of applying the proposed TimeNoise and Analytic-Init methods to different image-to-video diffusion models (I2V-DMs). It visually demonstrates that the proposed methods improve the dynamism of the generated videos while preserving the alignment of the images and consistency in the temporal aspects. The models compared are SVD, VideoCrafter1, and DynamiCrafter. The images show example video frames generated by different models.

This figure demonstrates the phenomenon of conditional image leakage in image-to-video diffusion models. As the diffusion process progresses (time step t increases), the noisy input loses detail, whereas the conditional image retains substantial detail. This causes the model to over-rely on the conditional image, resulting in generated videos that lack motion compared to the ground truth.
More on tables
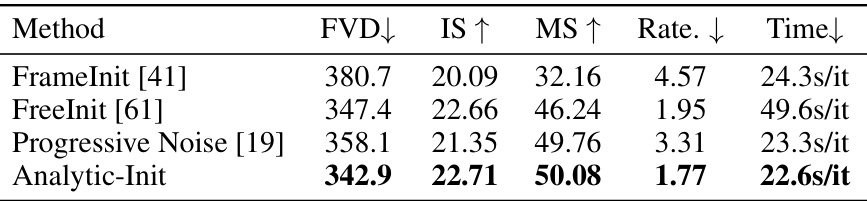
This table presents a quantitative comparison of different image-to-video diffusion models (I2V-DMs) on the UCF101 dataset. It evaluates the performance of several models with and without the proposed TimeNoise and Analytic-Init techniques. The results are measured using the Fréchet Video Distance (FVD), Inception Score (IS), and Motion Score (MS). The table also includes results for naively fine-tuned versions of each model to provide a baseline comparison.

This table presents a quantitative comparison of the proposed TimeNoise and Analytic-Init methods against baseline models for image-to-video generation on the UCF101 dataset. It shows the improvements in terms of FVD (Fréchet Video Distance), IS (Inception Score), and Motion Score achieved by incorporating the proposed techniques into different I2V-DM architectures. Naive fine-tuning baselines are also included for comparison.
This table presents a quantitative comparison of the proposed methods (TimeNoise and Analytic-Init) against several baselines on the UCF101 dataset. It evaluates different image-to-video diffusion models (I2V-DMs), showing the Fréchet Video Distance (FVD), Inception Score (IS), and Motion Score (MS) for each model. The results are broken down to show the impact of each proposed method individually and then combined. Lower FVD scores and higher IS and MS scores indicate better performance.
This table presents a quantitative comparison of the performance of different image-to-video diffusion models (I2V-DMs) on the UCF101 dataset. It compares baseline models against models incorporating the proposed TimeNoise and Analytic-Init methods, both individually and in combination. The results are evaluated using Fréchet Video Distance (FVD), Inception Score (IS), and Motion Score (MS). The table shows the effectiveness of the proposed methods in improving the quality and motion characteristics of generated videos.

This table presents a quantitative comparison of different image-to-video diffusion models (I2V-DMs) on the UCF101 dataset. It evaluates the performance of three models (DynamiCrafter, VideoCrafter1, and SVD) with and without the proposed methods (TimeNoise and Analytic-Init). The results are reported in terms of Fréchet Video Distance (FVD), Inception Score (IS), and Motion Score (MS). A baseline is established using a naively tuned version of each model. The table allows one to compare the effectiveness of the TimeNoise and Analytic-Init techniques individually and in combination, highlighting their impact on various metrics related to the generated videos.

This table presents a quantitative comparison of different image-to-video diffusion models (I2V-DMs) on the UCF101 dataset. It evaluates the performance of these models with and without the proposed TimeNoise and Analytic-Init techniques. The metrics used are Fréchet Video Distance (FVD), Inception Score (IS), and Motion Score (MS). Different model variants are shown, indicating whether only TimeNoise, only Analytic-Init, or both techniques (CIL) were applied. Lower FVD is better, higher IS and MS are better. The ’naive-tune’ variants provide baseline comparisons where only one of the two proposed methods is applied to highlight their individual contributions.
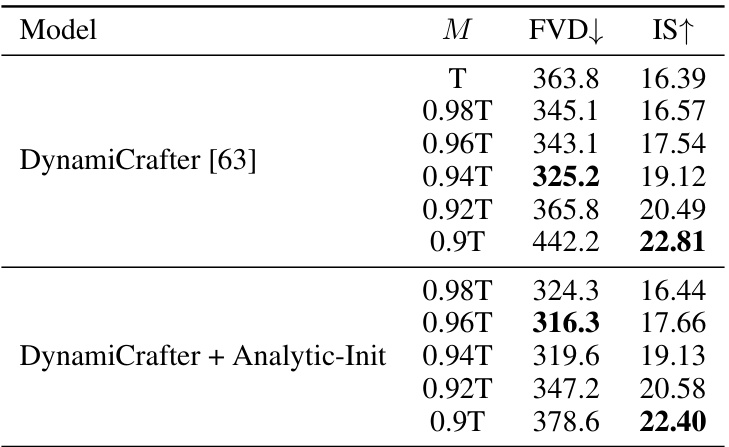
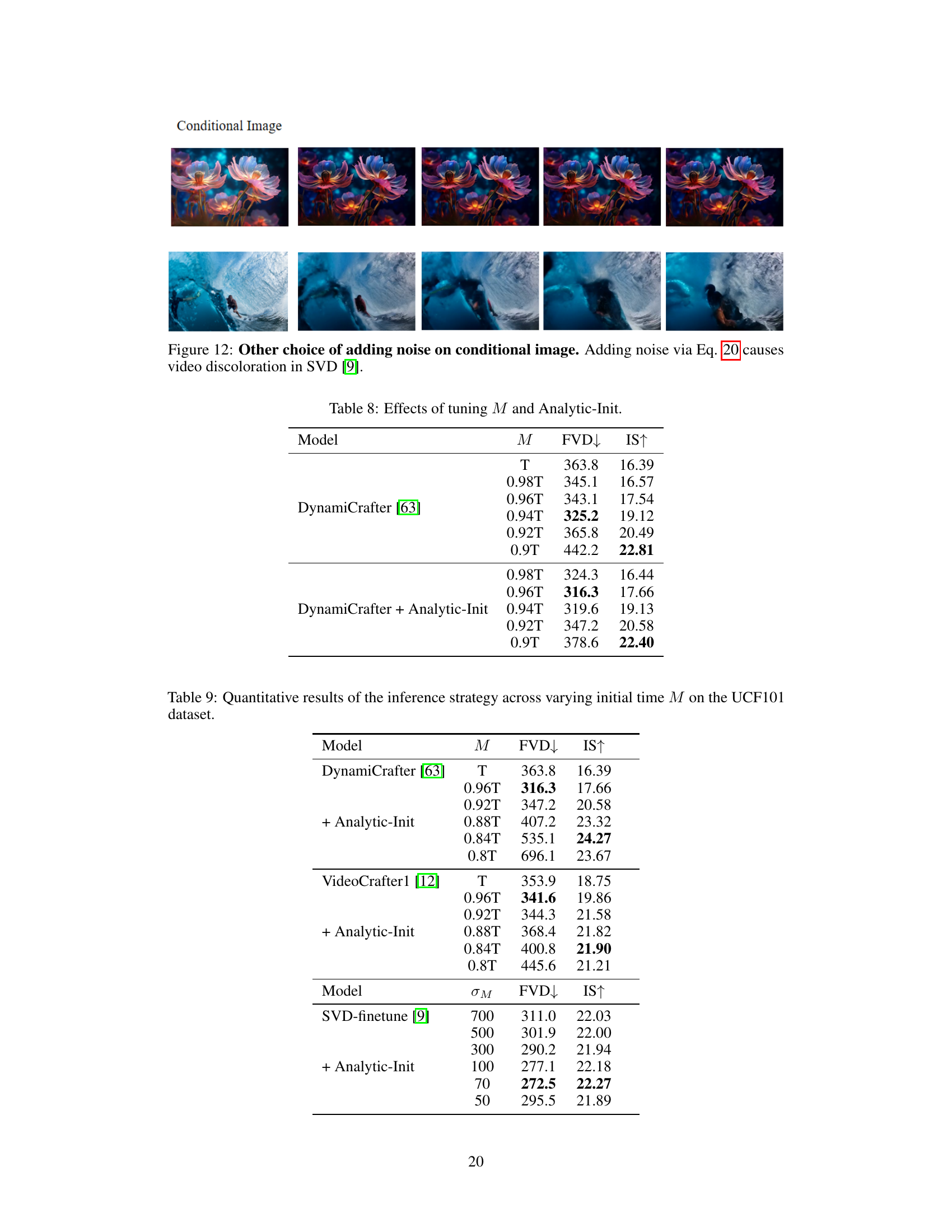
This table presents the quantitative results obtained by varying the starting time step (M) and applying the Analytic-Init method for the DynamiCrafter model. The table shows the impact of these modifications on the FVD and IS scores, which are used to assess video quality and motion score respectively. The results help illustrate how choosing an optimal starting time and leveraging the Analytic-Init technique can improve video generation performance.
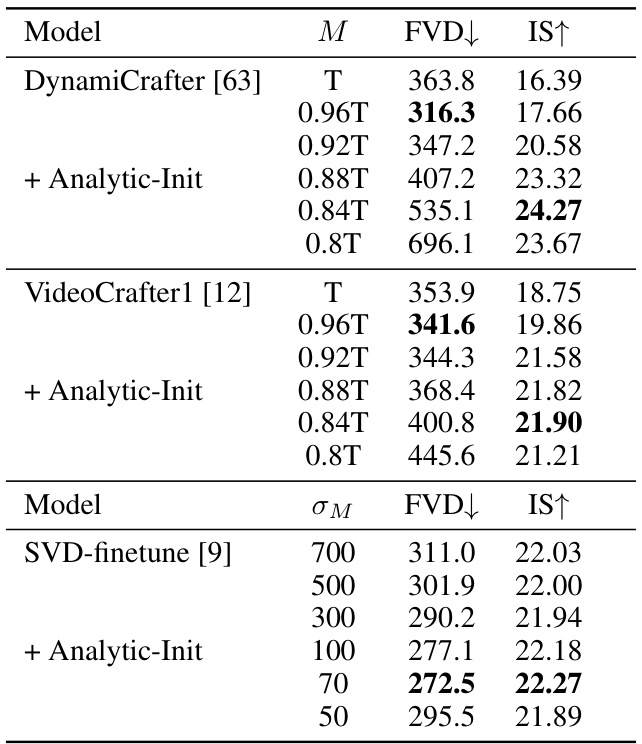
This table presents a quantitative comparison of the proposed TimeNoise and Analytic-Init methods against various image-to-video diffusion models (I2V-DMs) on the UCF101 dataset. It shows the Fréchet Video Distance (FVD), Inception Score (IS), and Motion Score for each model, comparing baselines against models incorporating the proposed techniques, both individually and combined. The results demonstrate the effectiveness of the proposed methods in improving video generation quality in terms of motion, visual fidelity, and overall performance.
Full paper#