↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but struggle with complex reasoning tasks. Current methods like prompt engineering or fine-tuning are often inefficient or require significant data. This paper tackles this issue by introducing a novel self-play training approach.
The researchers developed a two-player adversarial game called “Adversarial Taboo.” LLMs act as both attacker and defender, learning to reason more effectively through iterative self-play and reinforcement learning. The findings show significant performance improvements on various reasoning benchmarks, surpassing traditional methods. This suggests that self-play may offer a more efficient and generalizable way to improve LLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel self-play training method (SPAG) to enhance LLM reasoning abilities. SPAG leverages an adversarial language game to iteratively improve LLMs, offering a potential solution to the challenge of enhancing reasoning capabilities without relying on extensive human-labeled data or complex prompt engineering techniques. This opens new avenues for research into more efficient and generalizable LLM training methods.
Visual Insights#
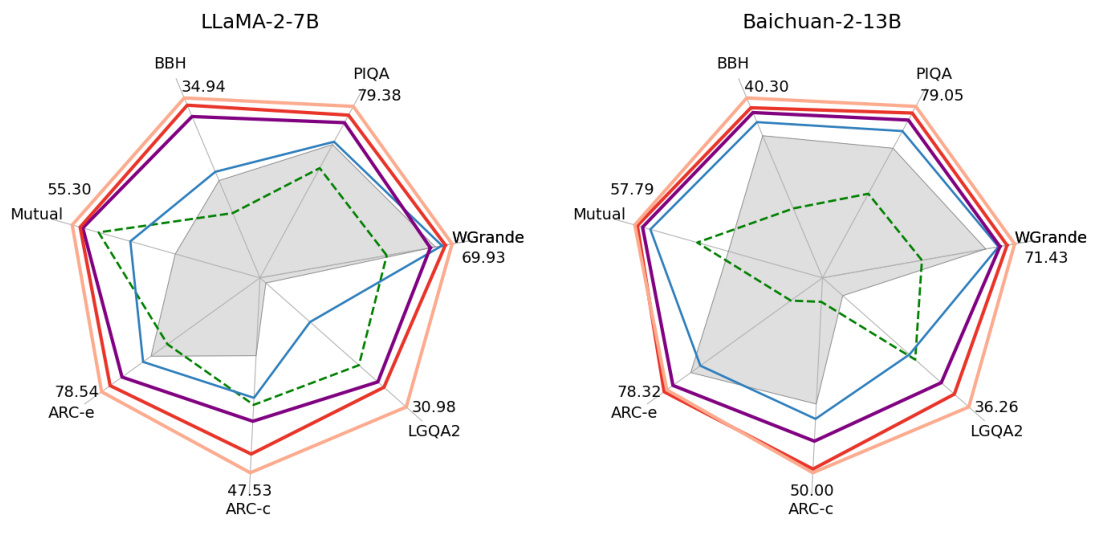
This radar chart visualizes the performance improvement of LLMs on various reasoning benchmarks after undergoing self-play training using the Adversarial Taboo game. Each axis represents a different benchmark (BBH, Mutual, ARC-e, ARC-c, LGQA2, WGrande, PIQA), and the values are normalized. The chart shows three data points for each LLM (LLaMA-2-7B and Baichuan-2-13B): the baseline, and the performance after one and two epochs of self-play training. The results indicate consistent performance gains across the benchmarks as the number of training epochs increase.
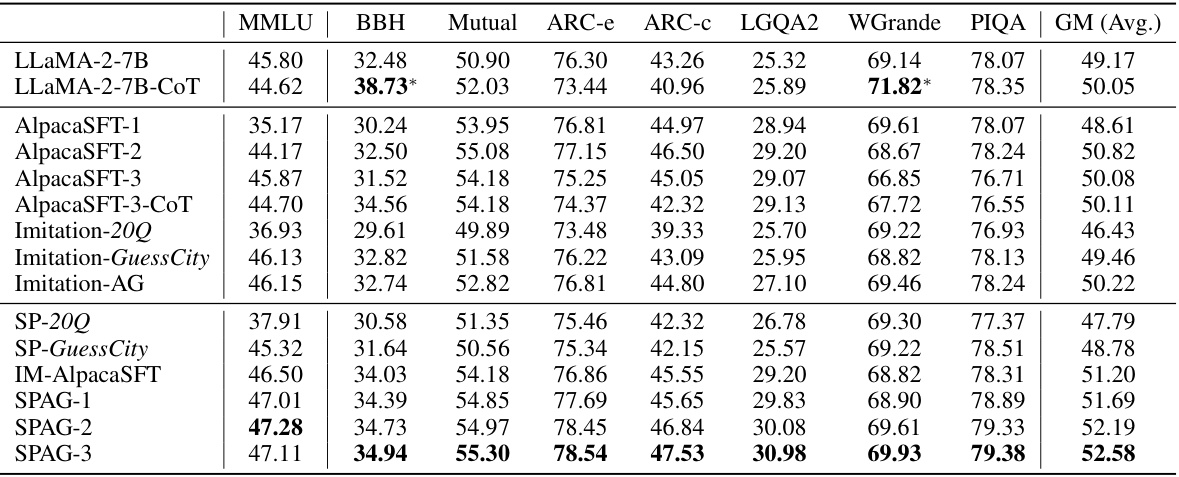
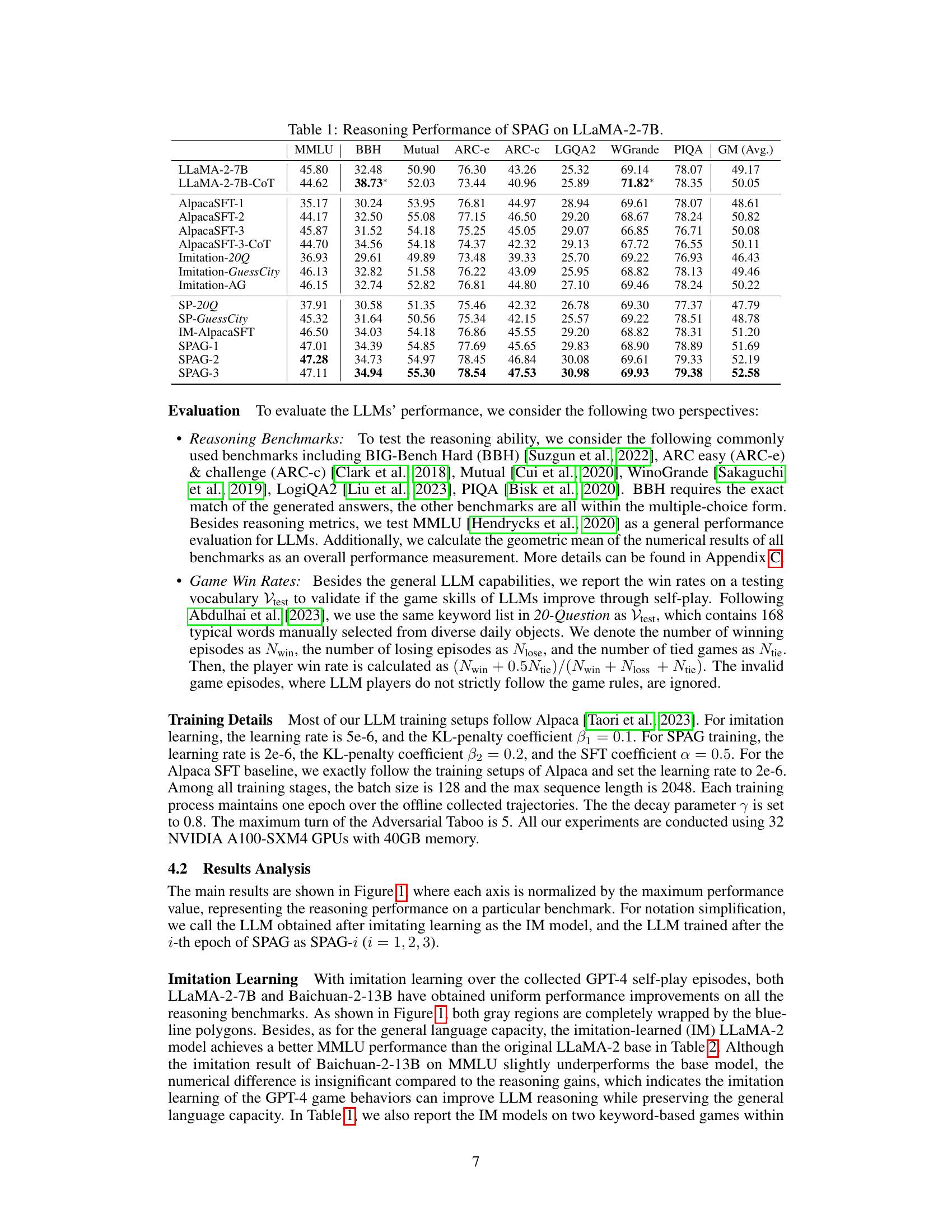
This table presents the results of evaluating the performance of the Self-Playing Adversarial Language Game (SPAG) method on the LLaMA-2-7B large language model (LLM). It compares the reasoning performance of LLaMA-2-7B before and after training using SPAG against several baseline methods, including Chain-of-Thought prompting (COT), Alpaca fine-tuning (SFT), and imitation learning of GPT-4 playing the Adversarial Taboo game. The evaluation is done across various reasoning benchmarks (MMLU, BBH, Mutual, ARC-e, ARC-c, LGQA2, WGrande, PIQA) and also includes the geometric mean (GM) score of all benchmark results for a comprehensive comparison. The results show the improvement achieved by using SPAG.
In-depth insights#
Adversarial LLM#
Adversarial LLMs represent a significant advancement in the field of large language models (LLMs). By framing LLM training as a game between an attacker and a defender, adversarial methods enhance robustness and reasoning capabilities. The attacker attempts to generate misleading or incorrect input, while the defender strives to produce accurate and coherent outputs. This adversarial setup pushes LLMs beyond simple pattern recognition to develop more nuanced understanding of language and context. Such techniques are particularly crucial in high-stakes scenarios, where reliability and resistance to manipulation are paramount. However, designing effective adversarial LLM training requires careful consideration of several factors, including the choice of attack strategies, the evaluation metrics used, and the potential for unintended biases or vulnerabilities to emerge. The balance between pushing LLM limits and maintaining safety and ethical considerations is vital. Further research is needed to fully explore the potential of adversarial LLMs and to develop methods that can mitigate the risks associated with such techniques.
SPAG Training#
The paper introduces Self-Play of Adversarial Game (SPAG) as a novel training approach for enhancing Large Language Model (LLM) reasoning capabilities. SPAG leverages the Adversarial Taboo game, a two-player adversarial setting where an attacker tries to subtly lead the defender into revealing a target word, while the defender must infer the word without consciously mentioning it. This game inherently encourages sophisticated reasoning and nuanced language use from both players. The process involves using an LLM to act as both the attacker and defender, iteratively playing against itself. Reinforcement learning is employed to improve the LLM’s strategy, based on the game’s outcome (win, lose, or tie). The results demonstrate that LLMs trained using SPAG exhibit improved reasoning abilities across a range of benchmark tasks, suggesting that this self-play method is an effective way to improve LLM reasoning without requiring extensive human-labeled data or complex prompting techniques. The iterative nature of the SPAG process, where the model continually refines its strategy, highlights the potential for continuous improvement and the power of self-play in enhancing LLMs.
Reasoning Gains#
Analysis of reasoning gains in LLMs reveals significant improvements across various benchmark tasks following self-play training within an adversarial language game. Self-play, specifically, proves more effective than other methods like Chain-of-Thought prompting or supervised fine-tuning. The magnitude of improvement varies across different LLMs and tasks, showcasing the complex interplay between model architecture, training data, and the adversarial nature of the learning process. While improvements are observed consistently across multiple reasoning benchmarks, the gains are not uniform across all tasks, highlighting potential limitations and areas for future research. The continuous improvement with each self-play iteration further underscores the potential of adversarial game-based training as an effective approach to enhance LLM reasoning capabilities. Further investigation is needed to understand the limits of these gains and the reasons behind the variability in performance across different tasks.
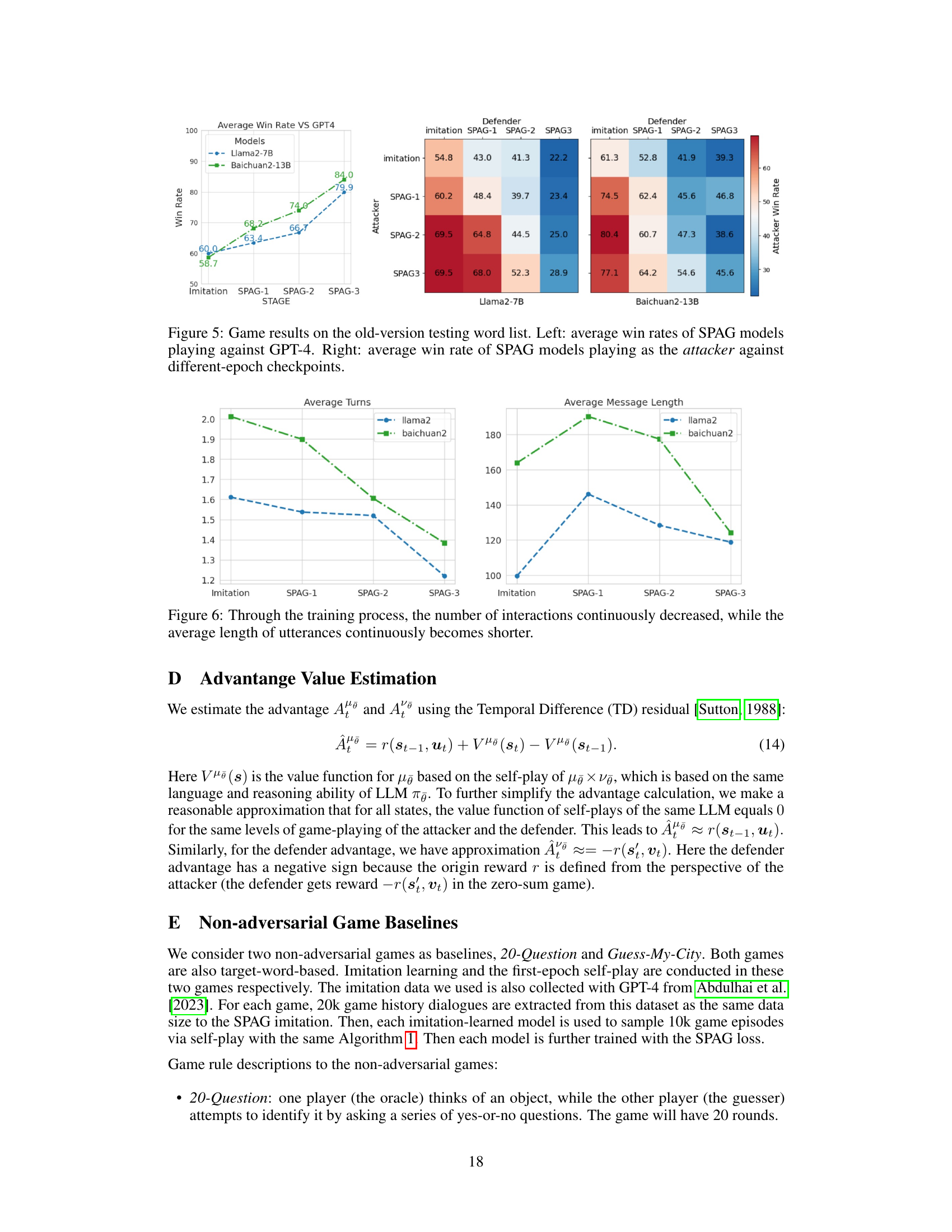
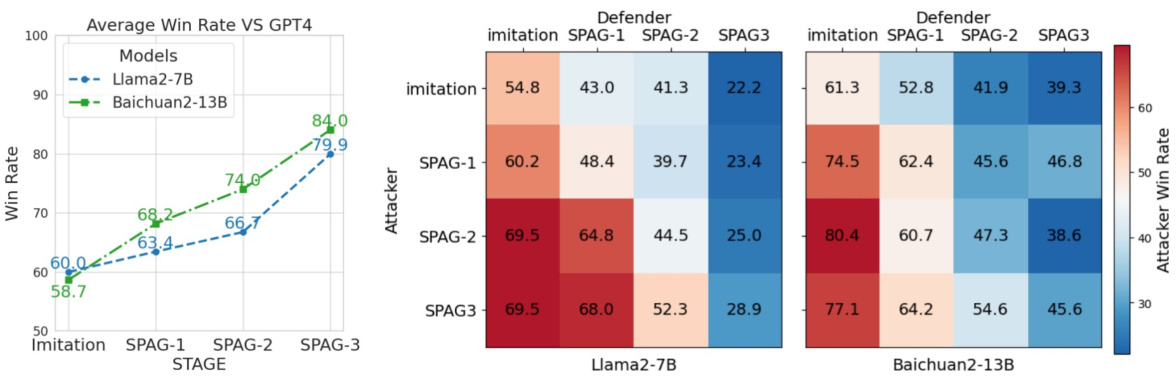
Game Win Rates#
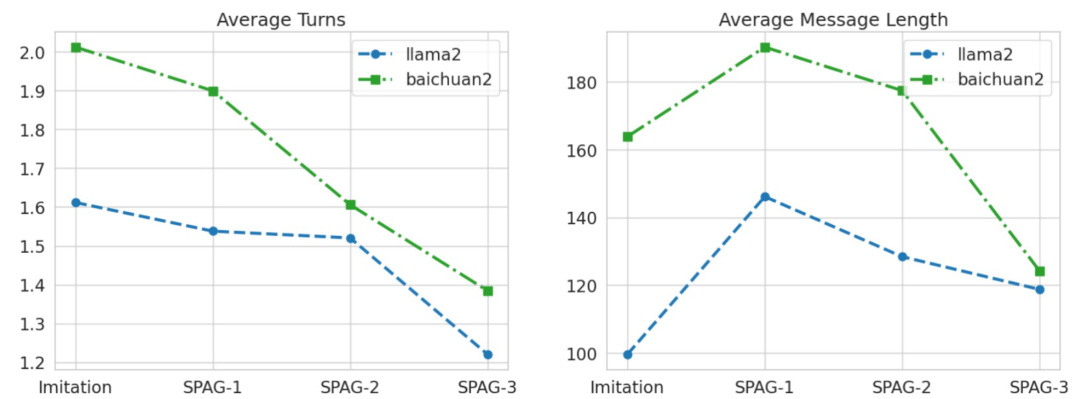
Analyzing game win rates offers valuable insights into the effectiveness of the self-play training method. By pitting LLMs against each other in an adversarial language game, researchers can measure the impact of their training on the models’ strategic reasoning capabilities. High win rates for the trained LLMs against both untrained models and even against GPT-4 highlight a significant enhancement in reasoning and strategic thinking. Furthermore, tracking win rates across different training epochs provides a dynamic view of the LLMs’ improvement trajectory, demonstrating whether the self-play process leads to continuous growth or plateaus. This metric is crucial because it directly evaluates the ability of LLMs to utilize their improved reasoning in a practical application (the game itself). However, sole reliance on win rates overlooks the qualitative aspects of the LLMs’ gameplay, such as strategy diversity and the types of conversational tactics employed. A comprehensive analysis should combine win rates with qualitative assessment of gameplay for a more nuanced understanding of the models’ performance. Further investigation could explore the correlation between win rates and performance on external reasoning benchmarks.
Future of LLMs#
The future of LLMs is bright, yet uncertain. Ongoing research into improving reasoning and reducing biases is crucial, addressing current limitations in factual accuracy and ethical considerations. Self-supervised learning and reinforcement learning techniques hold immense promise, potentially leading to LLMs capable of complex problem-solving and nuanced understanding. Adversarial training methods like the one explored in this paper show significant potential to enhance reasoning capabilities. However, challenges remain, including mitigating the risks of misuse and ensuring fairness, which requires careful consideration of broader societal impacts. The development of more robust evaluation metrics is essential for objectively assessing progress and guiding future research. Ultimately, the trajectory will depend heavily on addressing ethical concerns, fostering responsible innovation, and strategically focusing research on practical applications that benefit society.
More visual insights#
More on figures

This figure shows how the performance of several large language models (LLMs) improves on various reasoning benchmarks after undergoing self-play training using an adversarial language game called Adversarial Taboo. The x-axis of each subplot represents a different benchmark, and the y-axis shows the normalized reasoning accuracy. The different colored lines represent different stages of training (epochs) of the SPAG method. The figure visually demonstrates that iterative self-play enhances the LLMs’ reasoning capabilities across multiple benchmarks.

This figure shows the improvement in reasoning ability of LLMs after training with the Self-Playing Adversarial Language Game (SPAG) method. The radar chart displays the performance on several reasoning benchmarks (MMLU, BBH, Mutual, ARC-e, ARC-c, LGQA2, WGrande, PIQA) before SPAG training (LLaMA-2-7B, Baichuan-2-13B, AlpacaSFT baselines) and after 1, 2, and 3 epochs of SPAG training. The improvement is consistent across all benchmarks, indicating that SPAG enhances LLM reasoning abilities.
This figure shows the improvements in reasoning abilities of LLMs (Large Language Models) after undergoing self-play training using an adversarial language game called Adversarial Taboo. The radar charts display performance across multiple reasoning benchmarks (BBH, Mutual, ARC-e, ARC-c, LGQA2, WGrande, PIQA). Each point represents the performance on a specific benchmark, with the axes normalized. The three SPAG-epoch lines show that performance consistently improves with each iteration of the self-play training process.
This figure shows the performance improvement of Large Language Models (LLMs) after undergoing self-play training using an adversarial language game called Adversarial Taboo. The graph displays the improvements across several reasoning benchmarks (MMLU, BBH, Mutual, ARC-e, ARC-c, LGQA2, WGrande, PIQA) after 1, 2, and 3 epochs of self-play. The y-axis represents the normalized reasoning score, and the higher the score, the better the performance on the benchmark. Each axis is normalized using the maximum answer accuracy value observed for that specific benchmark, providing a comparable view of the relative improvements across benchmarks.
More on tables
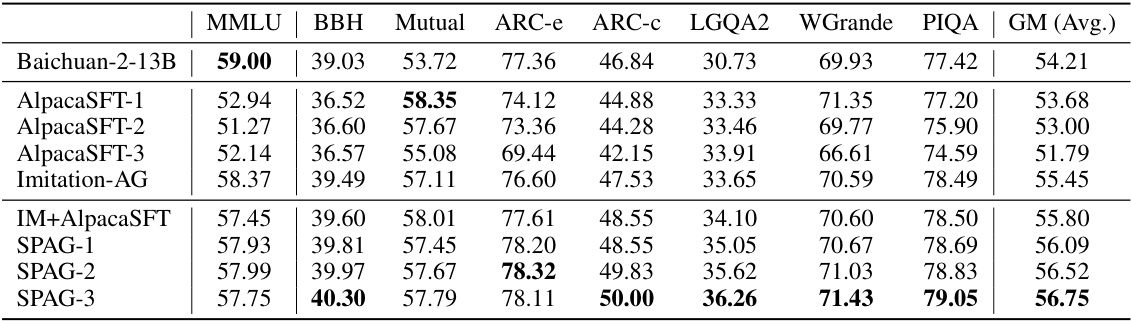
This table presents the performance of the Self-Playing Adversarial Language Game (SPAG) method on the LLaMA-2-7B model across various reasoning benchmarks. It compares the performance of the base LLaMA-2-7B model, models trained with Chain-of-Thought prompting, different Alpaca fine-tuned models, and models trained with the SPAG method after imitation learning and multiple self-play iterations. The benchmarks used include MMLU, BBH, Mutual, ARC-e, ARC-c, LGQA2, Winogrande, and PIQA. The table shows improvements in reasoning ability across several benchmarks after SPAG training.

This table presents the performance of the Self-Playing Adversarial Language Game (SPAG) method on the LLaMA-2-7B language model across various reasoning benchmarks. It compares the performance of the baseline LLaMA-2-7B model against several variations, including models trained with Chain-of-Thought prompting, Alpaca fine-tuning (with multiple epochs), and models that underwent imitation learning based on GPT-4 gameplay followed by SPAG training (across multiple epochs). The benchmarks include diverse reasoning tasks and measure accuracy or success rate. The table also includes the geometric mean (GM) across all benchmarks, providing a summary of overall performance. This helps show the relative gains of the SPAG method compared to baselines.

This table presents the performance of the Self-Playing Adversarial Language Game (SPAG) method on the LLaMA-2-7B model across various reasoning benchmarks. It compares the performance of the base LLaMA-2-7B model against several variations, including those trained with Chain-of-Thought prompting (CoT), multiple epochs of supervised fine-tuning (AlpacaSFT), imitation learning based on GPT-4 gameplay (Imitation), self-play on other games (SP-20Q, SP-GuessCity, IM-AlpacaSFT), and various epochs of SPAG training (SPAG-1, SPAG-2, SPAG-3). Benchmarks include MMLU, BBH, Mutual, ARC-e, ARC-c, LGQA2, WGrande, and PIQA, representing diverse reasoning tasks. The geometric mean (GM) is also calculated to provide a single overall performance score across all benchmarks.

This table presents the performance of LLMs on various reasoning benchmarks. It compares the baseline LLaMA-2-7B model with several variations including those trained using Chain-of-Thought prompting, those fine-tuned using Alpaca, those trained using imitation learning based on GPT-4 gameplay of Adversarial Taboo, and those trained using the Self-Play of Adversarial Game (SPAG) method. The results show improvements in reasoning ability across multiple benchmarks with each iteration of SPAG training, demonstrating the effectiveness of the self-play method.
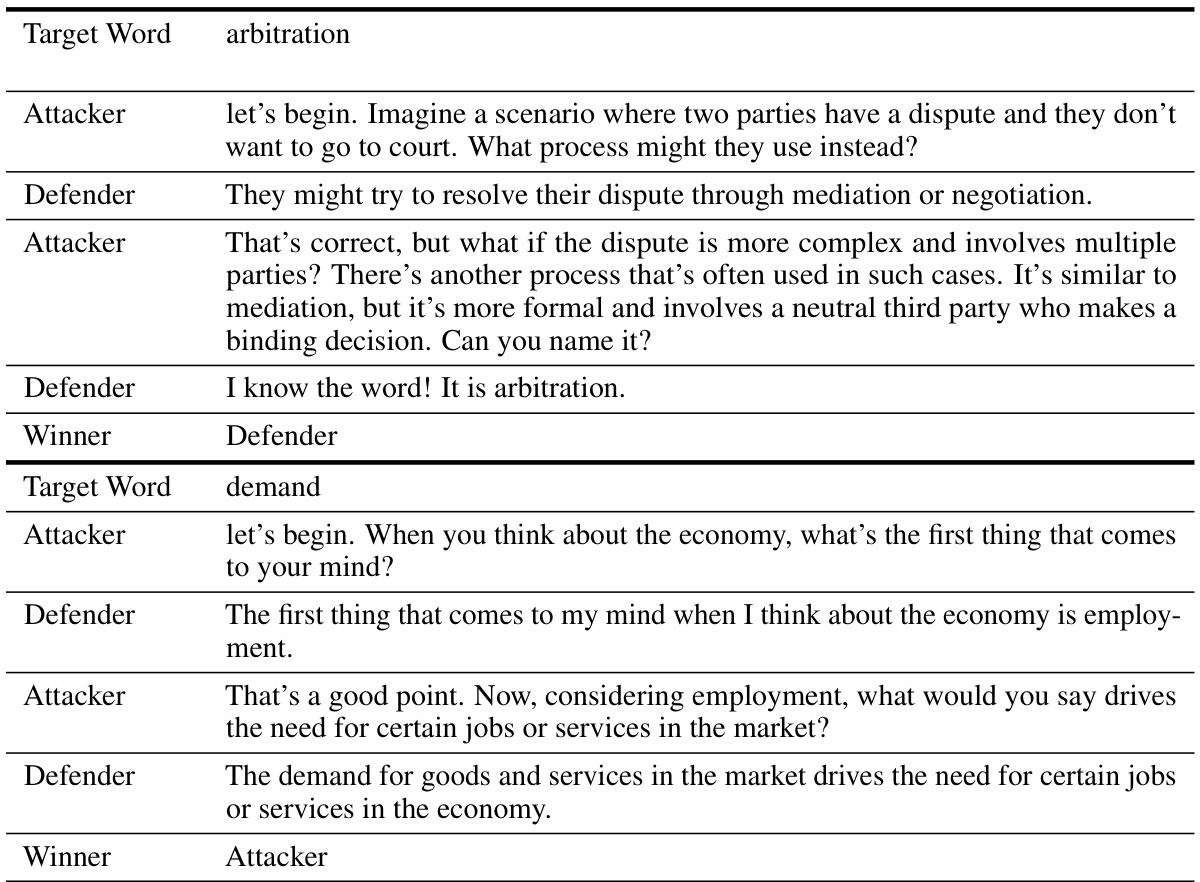
This table presents the performance of the Self-Playing Adversarial Language Game (SPAG) method on the LLaMA-2-7B model across various reasoning benchmarks. It compares the baseline LLaMA-2-7B model’s performance with several variations, including those enhanced by Chain-of-Thought prompting, Alpaca fine-tuning, imitation learning from GPT-4, and multiple epochs of SPAG training. Benchmarks include MMLU, BBH, Mutual, ARC-e, ARC-c, LogiQA2, Winogrande, PIQA, and a geometric mean (GM) of all benchmark scores. This allows for a comprehensive assessment of how SPAG improves reasoning capabilities compared to other methods.

This table presents the performance of the Self-Playing Adversarial Language Game (SPAG) method on the LLaMA-2-7B language model across various reasoning benchmarks. It compares the performance of the base LLaMA-2-7B model, models fine-tuned with Chain-of-Thought prompting, models trained with imitation learning from GPT-4, and models improved iteratively through the SPAG self-play training. The benchmarks include MMLU, BBH, Mutual, ARC-e, ARC-c, LogiQA2, Winogrande, and PIQA, along with the average geometric mean across all benchmarks. The table demonstrates the consistent improvement in reasoning abilities achieved by the SPAG method as training epochs increase.
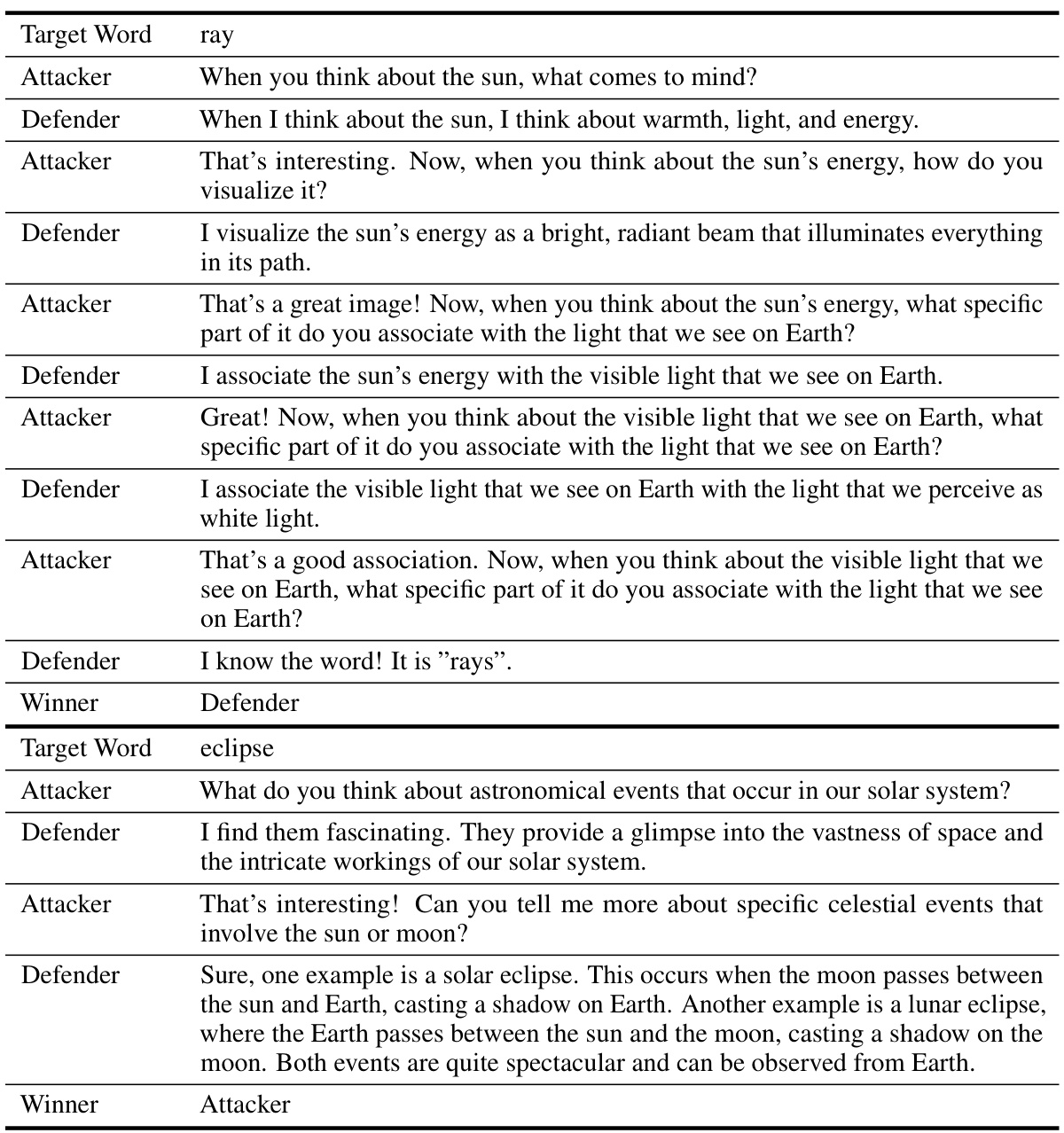
This table presents the performance of the Self-Playing Adversarial Language Game (SPAG) method on the LLaMA-2-7B large language model across various reasoning benchmarks. It compares the performance of the base LLaMA-2-7B model against several variations, including models fine-tuned with Chain-of-Thought prompting, models trained through imitation learning of GPT-4 gameplay, and models enhanced through multiple epochs of SPAG training. The benchmarks cover diverse reasoning tasks, including commonsense reasoning, logical reasoning, and knowledge-based reasoning. The results show improvement across various metrics, indicating the effectiveness of SPAG in enhancing LLM reasoning capabilities.

This table presents the performance of the Self-Playing Adversarial Language Game (SPAG) method on the LLaMA-2-7B model across various reasoning benchmarks. It compares the baseline LLaMA-2-7B model’s performance with several other models, including those trained using Chain-of-Thought prompting and supervised fine-tuning with Alpaca. The table also shows the results of the imitation learning stage (using GPT-4 data) and multiple self-play training epochs (SPAG-1, SPAG-2, SPAG-3). The benchmarks used span various reasoning tasks and are measured in terms of accuracy.
Full paper#