TL;DR#
Current approaches to motion comprehension and generation often rely on single-modality control signals, limiting their ability to handle the complexity of human motion in realistic settings. Existing models also struggle with information loss during motion tokenization and lack the capability to leverage synergies between different motion-related tasks. These shortcomings highlight the need for a more advanced, unified framework capable of integrating multiple modalities and handling diverse tasks seamlessly.
M³GPT addresses these challenges with a novel multimodal, multitask framework. It uses a unified representation space for text, music, and motion data by employing discrete vector quantization. The model directly generates motion in the raw motion space, minimizing information loss. Finally, M³GPT leverages text as a bridge to connect various motion tasks, enabling mutual reinforcement and improved performance. This innovative approach sets a new standard in motion understanding and generation, showcasing superior performance and zero-shot generalization capabilities.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision, machine learning, and AI for its novel multimodal framework and potential applications in AR/VR, gaming, and virtual reality. M³GPT’s success in bridging motion comprehension and generation across diverse modalities opens exciting avenues for future research such as improving long-term motion prediction and exploring novel control mechanisms.
Visual Insights#
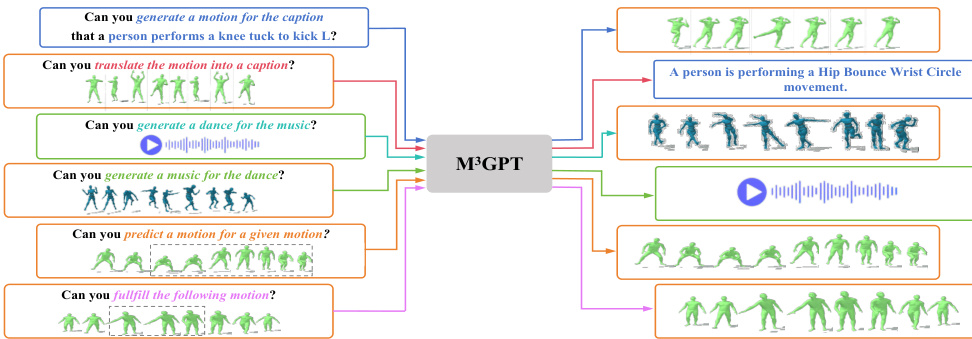
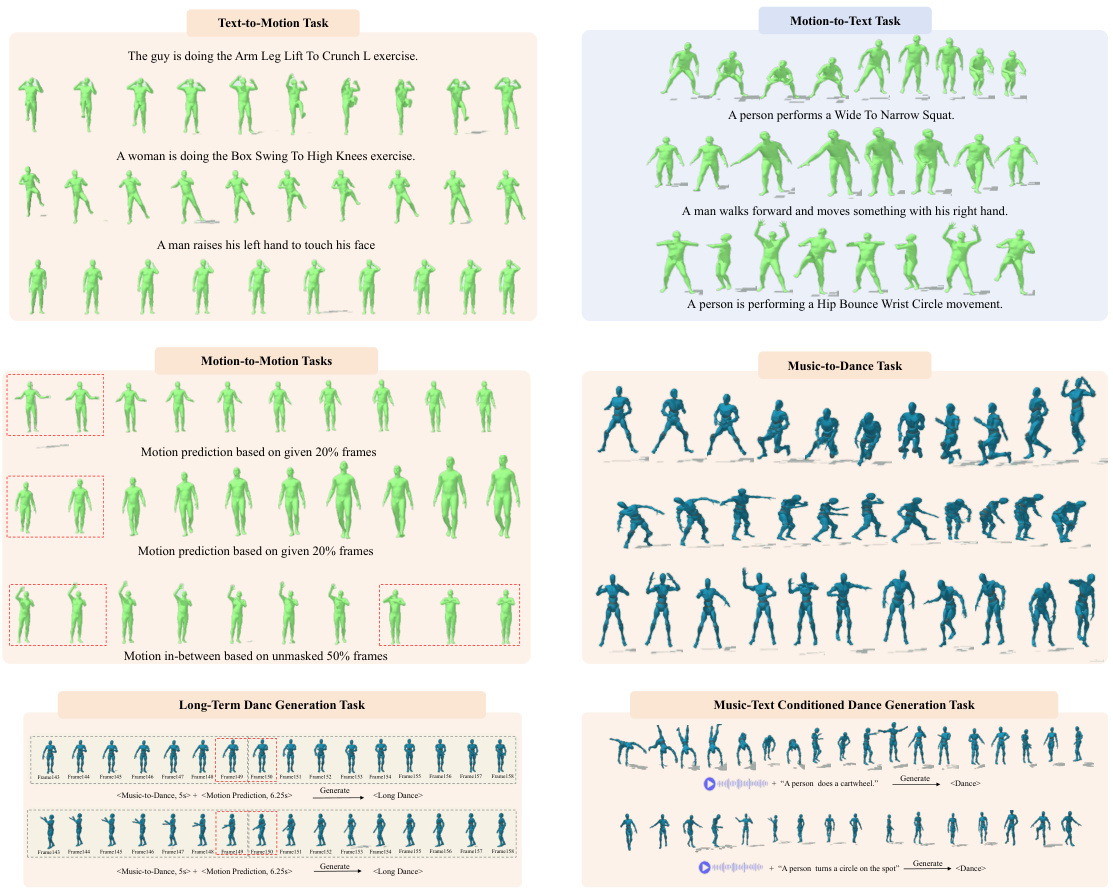
🔼 This figure illustrates the six core motion-related tasks that the proposed M³GPT model can perform. These tasks demonstrate both comprehension and generation capabilities. The figure visually shows examples of each task by using different modalities as input. Masked motion sequences in some cases highlight the in-filling abilities of the model. Text, music and motion data are used as input and output modalities.
read the caption
Figure 1: M³GPT can handle core motion comprehension and generation tasks, including text-to-motion, motion-to-text, music-to-dance, dance-to-music, motion prediction, and motion in-between. The motion sequences within the dashed-line areas are masked in the input.

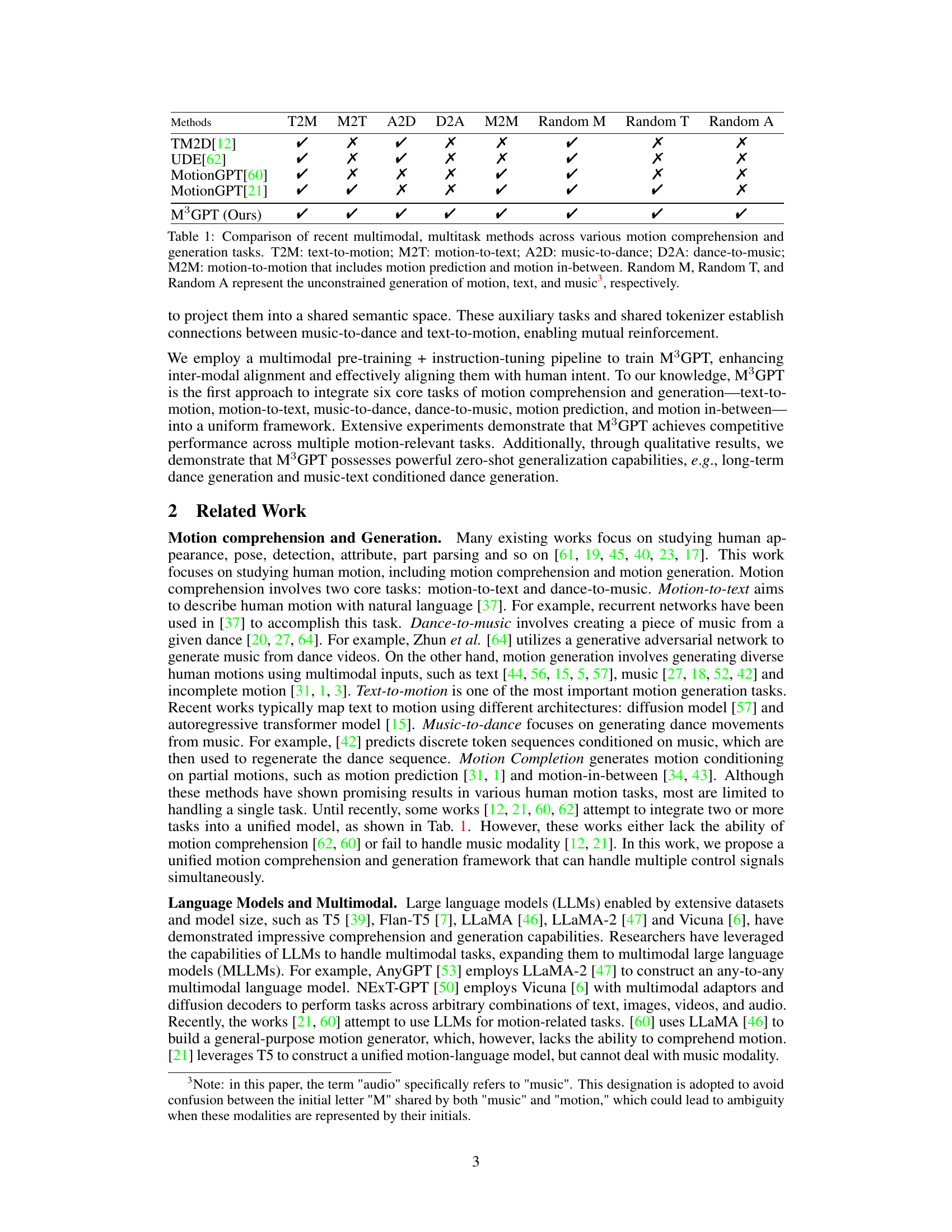
🔼 This table compares several recent multimodal and multitask methods focusing on motion comprehension and generation. It assesses their capabilities across six key tasks: text-to-motion (T2M), motion-to-text (M2T), music-to-dance (A2D), dance-to-music (D2A), motion-to-motion (including prediction and in-between sequences, M2M), and unconstrained generation of motion, text, and music (Random M, Random T, Random A). A checkmark (✓) indicates a method’s ability to perform each task.
read the caption
Table 1: Comparison of recent multimodal, multitask methods across various motion comprehension and generation tasks. T2M: text-to-motion; M2T: motion-to-text; A2D: music-to-dance; D2A: dance-to-music; M2M: motion-to-motion that includes motion prediction and motion in-between. Random M, Random T, and Random A represent the unconstrained generation of motion, text, and music³, respectively.
In-depth insights#
Multimodal Fusion#
Multimodal fusion, in the context of motion comprehension and generation, presents a significant challenge and opportunity. The core idea revolves around effectively integrating information from diverse sources, such as text, music, and raw motion data, to achieve a more holistic understanding and more nuanced generation of movement. A critical aspect is the representation of these different modalities in a shared space, enabling seamless interaction and mutual influence. Successful fusion methods should minimize information loss and handle the inherent heterogeneity of different data types. Simple concatenation is inadequate; sophisticated techniques like attention mechanisms, vector quantization, or transformer-based encoders are often employed to achieve meaningful integration. The ultimate goal is to enable systems to generate motions that are not only accurate and realistic, but also reflect the nuanced combination of inputs – a dance responding to both the emotional tone of music and the specific instructions provided in text, for example. The effectiveness of a multimodal fusion technique is judged by its ability to improve performance on downstream tasks, such as motion prediction and generation, compared to models relying on single modalities. Challenges include finding appropriate representations, handling missing or noisy data, and ensuring that the fusion process captures the intended interplay between modalities, rather than simply averaging or overshadowing any single input. Future research will likely focus on exploring more advanced fusion strategies, possibly leveraging unsupervised or self-supervised learning methods to better capture intricate relationships between modalities.
LLM for Motion#
The application of Large Language Models (LLMs) to motion presents exciting possibilities. LLMs excel at understanding and generating complex sequential data, making them well-suited for representing and manipulating motion sequences. A key advantage is the ability to bridge diverse modalities. For instance, text descriptions can be directly translated into motion data, opening doors for intuitive control and generation of animations. Similarly, music or other audio can be used to drive motion generation, creating synchronized and expressive animations. The integration of LLMs also allows for multi-task learning, enabling models to perform motion prediction, motion in-betweening, and even motion style transfer. However, challenges remain. Motion data is often high-dimensional and complex, requiring efficient representation and encoding techniques to be effectively integrated with the LLMs. Further research is needed to address the issue of information loss when converting continuous motion data into discrete token representations used by LLMs. Careful consideration must be given to model architecture and training methodologies to fully harness the potential of LLMs in this domain. The development of robust evaluation metrics that capture both the quantitative and qualitative aspects of generated motion is also crucial.
Zero-Shot Motion#
Zero-shot motion generation, a fascinating area of AI research, focuses on generating novel motions without explicit training examples for that specific motion. This capability is crucial for enabling AI systems to exhibit true generalization and creativity. The core challenge lies in learning a rich, generalizable representation of motion dynamics that transcends individual instances. Successful approaches often leverage large language models (LLMs) or other powerful generative models pre-trained on extensive datasets. These models learn underlying patterns and structures of motion, allowing them to synthesize new motions based on diverse input modalities, such as text descriptions or music. However, ensuring the quality, coherence, and fidelity of zero-shot generated motions remains a significant hurdle. While impressive results have been demonstrated, issues such as generating realistic and physically plausible motions and handling complex, nuanced motion patterns still need to be addressed. Furthermore, the ability of zero-shot motion models to generalize to unseen motion styles or environments is a key area for future research. Addressing these challenges could potentially unlock numerous applications across gaming, animation, robotics, and virtual/augmented reality.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a machine learning model. By removing or deactivating parts, researchers gauge their impact on overall performance. This helps determine which components are essential and which may be redundant or detrimental. A well-executed ablation study should explore a range of variations and ideally present quantitative results, for example, accuracy changes when a specific module is removed. Careful consideration of interactions between components is crucial, since removing one part might unexpectedly affect another. A comprehensive ablation study should provide valuable insights into the model’s architecture and decision-making process, clarifying how each part contributes to the overall performance and potentially guiding the development of improved or more efficient model designs. The effectiveness of the ablation study relies on the choice of components to be ablated, and the results should be interpreted cautiously, acknowledging potential confounding effects and the limitations of the methodology.
Future Work#
Future research directions stemming from this work could significantly expand the capabilities and applications of M³GPT. Improving the model’s handling of long-duration sequences is crucial, as current limitations prevent seamless generation of extended motion pieces. Exploring different LLMs as backbones could reveal improvements in performance or efficiency. Incorporating additional modalities, such as haptic feedback or environmental context, promises richer and more nuanced motion understanding and generation. Furthermore, enhancing the model’s ability to handle various styles and genres of motion and music, beyond those included in the training dataset, would be a valuable advancement. Finally, investigating the model’s potential for applications in areas such as virtual reality, character animation, and human-computer interaction warrants further exploration and could unlock significant breakthroughs in motion-related technologies. The model’s robustness and performance in zero-shot scenarios should be carefully investigated.
More visual insights#
More on figures
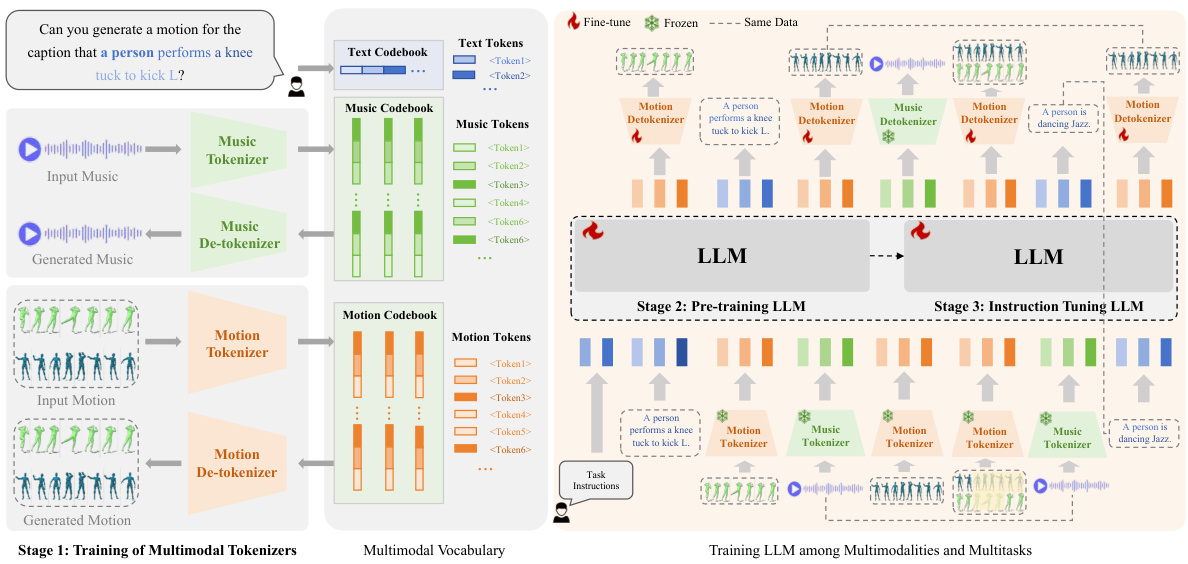
🔼 This figure shows a detailed overview of the M³GPT framework’s architecture and training process. M³GPT leverages multimodal tokenizers to convert raw motion and music data into discrete tokens, which are then processed by a motion-aware language model (LLM). The training is a three-stage process: 1) Training of Multimodal Tokenizers: This stage focuses on training separate tokenizers for text, music, and motion data. These tokenizers convert the raw data into discrete tokens that can be understood by the LLM. 2) Pre-training LLM: In this stage, the LLM is pre-trained on a large dataset of multimodal data, enabling it to understand the relationships between different modalities (text, music, motion). 3) Instruction Tuning LLM: This stage fine-tunes the pre-trained LLM using task-specific instructions, allowing it to perform various motion-related tasks, such as text-to-motion, music-to-dance, and motion prediction.
read the caption
Figure 2: An overview of the M³GPT framework. M³GPT consists of multimodal tokenizers and a motion-aware language model. The training process of M³GPT consists of three stages: multimodal tokenizers training, modality-alignment pre-training, and instruction tuning.
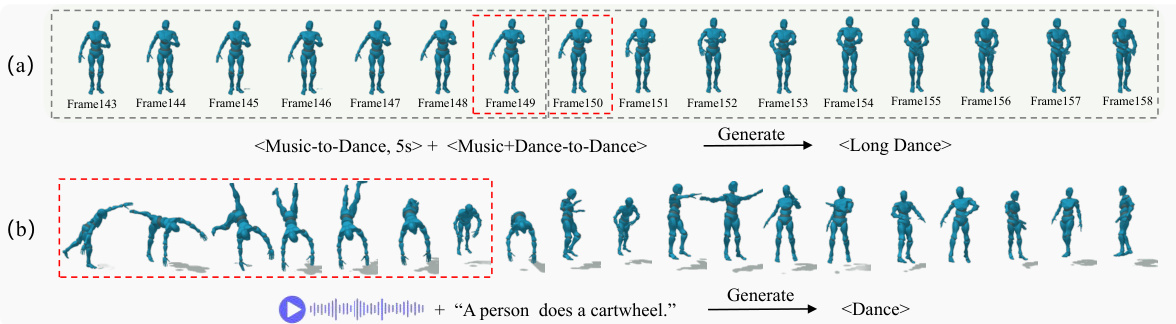
🔼 This figure shows two examples of M³GPT’s zero-shot generalization capabilities in dance generation. (a) demonstrates long-duration dance generation, where M³GPT generates a coherent dance sequence from a single music input by recursively generating short segments. (b) demonstrates music and text-conditioned dance generation, where M³GPT generates a dance sequence that both synchronizes with a music input and incorporates actions described in a text input.
read the caption
Figure 3: Qualitative results for long-term dance and music-text conditioned dance generation of M³GPT.
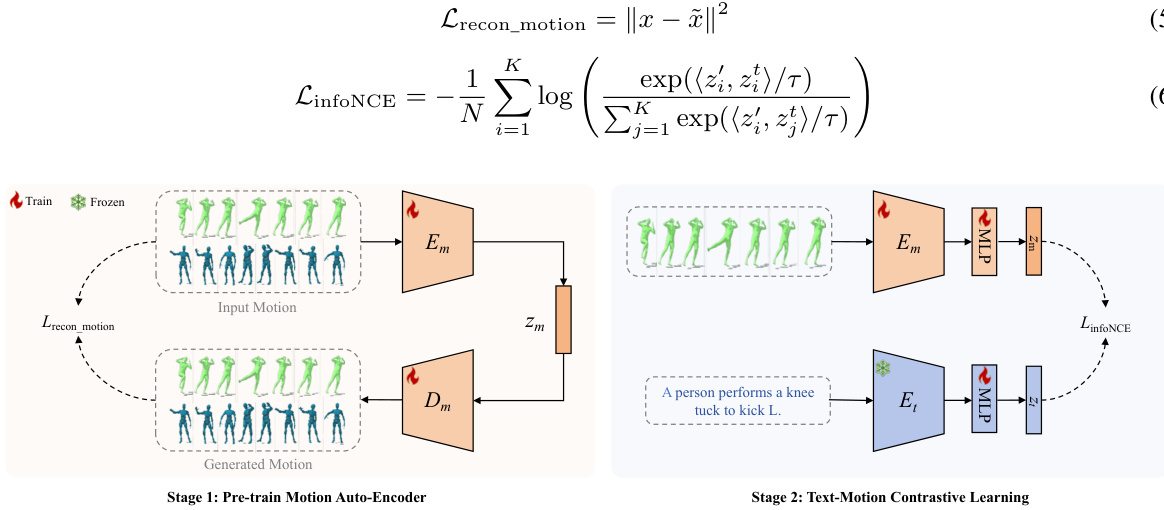
🔼 This figure illustrates the architecture of the M³GPT framework, highlighting the three main components: multimodal tokenizers (for compressing raw motion and music data into discrete tokens), a motion-aware language model (LLM) that understands and generates motion tokens, and a three-stage training process. The training process consists of multimodal tokenizer training, modality alignment pre-training, and instruction tuning to improve the model’s ability to comprehend and generate motion.
read the caption
Figure 2: An overview of the M³GPT framework. M³GPT consists of multimodal tokenizers and a motion-aware language model. The training process of M³GPT consists of three stages: multimodal tokenizers training, modality-alignment pre-training, and instruction tuning.

🔼 This figure shows the overall framework of M³GPT, which comprises three main components: multimodal tokenizers, a motion-aware language model, and a three-stage training process. The tokenizers are responsible for converting raw motion and music data into discrete tokens, allowing seamless integration with text. The language model leverages these tokens to perform various motion-related tasks. The three-stage training process includes training the tokenizers, pre-training the model for modality alignment, and finally fine-tuning it using instructions. This iterative process enables M³GPT to effectively handle diverse motion-related tasks.
read the caption
Figure 2: An overview of the M³GPT framework. M³GPT consists of multimodal tokenizers and a motion-aware language model. The training process of M³GPT consists of three stages: multimodal tokenizers training, modality-alignment pre-training, and instruction tuning.
🔼 This figure presents a visual overview of the M³GPT framework, detailing its three core components: multimodal tokenizers, a motion-aware language model, and the three-stage training process. The tokenizers are responsible for converting raw data (text, music, motion) into a unified representation. The motion-aware language model then processes these unified representations, learning to generate motion data given various inputs. The training process is depicted in three stages: First, the multimodal tokenizers are trained. Second, a modality-alignment pre-training phase occurs to align and unify representations. Finally, an instruction tuning phase further refines the model’s ability to follow instructions for generating motion.
read the caption
Figure 2: An overview of the M³GPT framework. M³GPT consists of multimodal tokenizers and a motion-aware language model. The training process of M³GPT consists of three stages: multimodal tokenizers training, modality-alignment pre-training, and instruction tuning.

🔼 This figure illustrates the architecture of the M³GPT framework, which comprises three main components: multimodal tokenizers (for converting raw motion and music data into discrete tokens), a motion-aware language model (based on LLMs, to understand and generate motion tokens), and a three-stage training process (multimodal tokenizers training, modality-alignment pre-training, and instruction tuning). The diagram visually depicts the flow of data through these components and highlights the interactions between them during training and inference.
read the caption
Figure 2: An overview of the M³GPT framework. M³GPT consists of multimodal tokenizers and a motion-aware language model. The training process of M³GPT consists of three stages: multimodal tokenizers training, modality-alignment pre-training, and instruction tuning.
More on tables

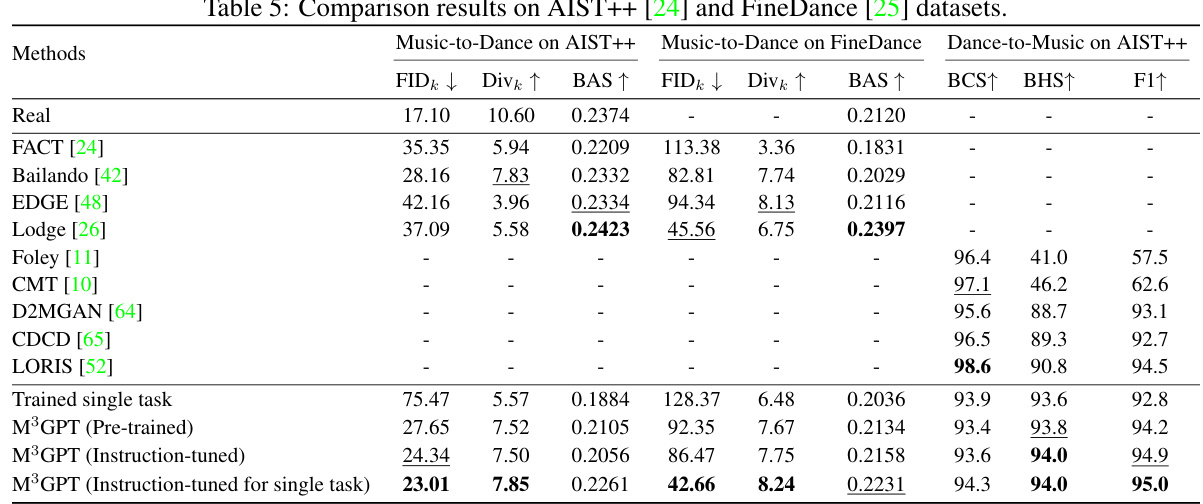
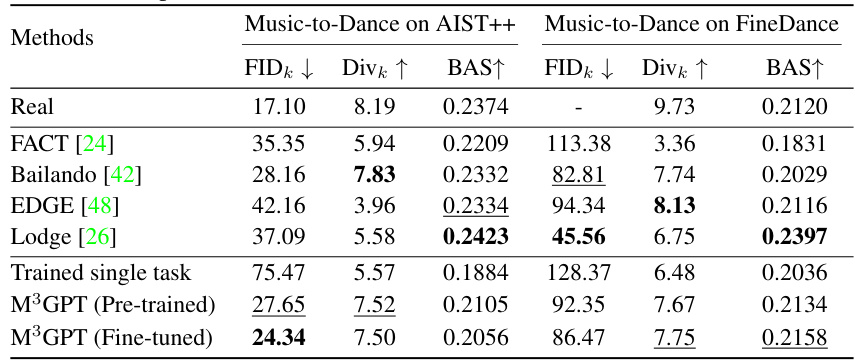
🔼 This table presents the ablation study results to demonstrate the effectiveness of synergy learning and joint optimization of the language model (LLM) and motion de-tokenizer in the M³GPT model. It compares the performance of different model configurations across two tasks: text-to-motion and music-to-dance. The configurations vary in terms of whether or not joint optimization and additional auxiliary tasks (T2D and A2T) are included. Metrics like FID, Diversity, R-Precision, and BAS are used to assess performance. The table shows the improved results when both joint optimization and synergy learning are applied, indicating the effectiveness of the M³GPT’s multitask learning strategy.
read the caption
Table 2: Evaluation of synergy learning and joint optimization of LLM and motion de-tokenizer on Text-to-Motion (Motion-X [29]) and Music-to-Dance (AIST++ [24]). T2M: Text-to-Motion. A2D: Music-to-Dance. T2D: Text-to-Dance. A2T: Music-to-Text. Trained single task refers to a model trained and tested on a single task. Pre-trained and Instruction-tuned indicate the model after pre-training (stage2) and instruction tuning (stage3), followed by direct testing on each task. The arrows (↑) indicate that higher values are better. The arrows (↓) indicate that smaller values are better. Bold indicates the best result.

🔼 This table compares several state-of-the-art multimodal and multitask methods for motion comprehension and generation. It assesses their capabilities across six tasks: text-to-motion (T2M), motion-to-text (M2T), music-to-dance (A2D), dance-to-music (D2A), motion-to-motion (M2M - encompassing prediction and in-betweening), and unconstrained generation of motion, text, and music. The table helps illustrate the unique capabilities of M³GPT (the authors’ proposed method) in handling multiple modalities and tasks simultaneously.
read the caption
Table 1: Comparison of recent multimodal, multitask methods across various motion comprehension and generation tasks. T2M: text-to-motion; M2T: motion-to-text; A2D: music-to-dance; D2A: dance-to-music; M2M: motion-to-motion that includes motion prediction and motion in-between. Random M, Random T, and Random A represent the unconstrained generation of motion, text, and music³, respectively.

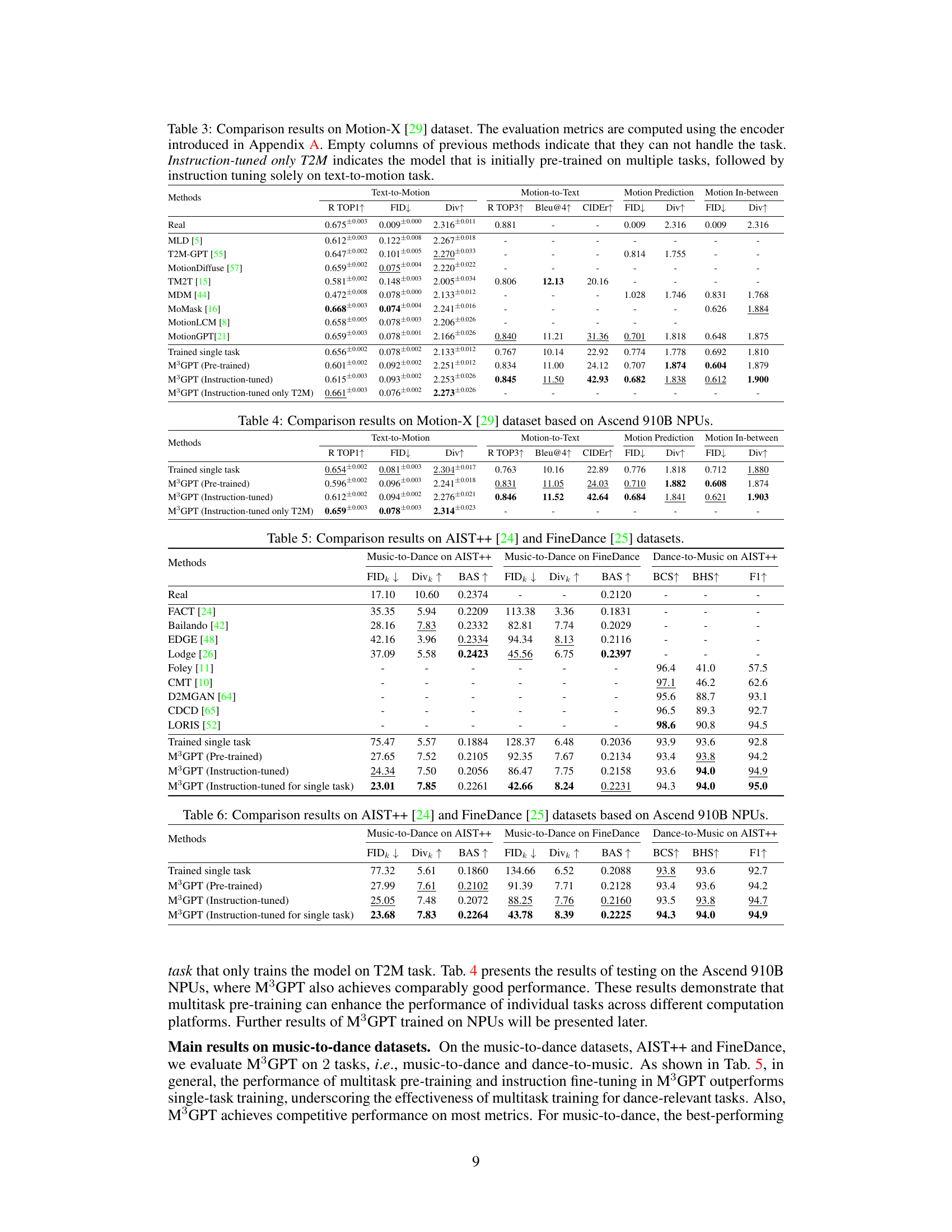
🔼 This table compares the performance of M³GPT with other state-of-the-art models on the Motion-X dataset for four tasks: text-to-motion, motion-to-text, motion prediction, and motion in-between. The metrics used for evaluation are R TOP1, FID, Div, R TOP3, Bleu@4, CIDEr, and MPJPE. The table highlights that M³GPT achieves competitive performance, particularly when fine-tuned on a single task, indicating the effectiveness of its multitask training approach.
read the caption
Table 3: Comparison results on Motion-X [29] dataset. The evaluation metrics are computed using the encoder introduced in Appendix A. Empty columns of previous methods indicate that they can not handle the task. Instruction-tuned only T2M indicates the model that is initially pre-trained on multiple tasks, followed by instruction tuning solely on text-to-motion task.
🔼 This table compares several state-of-the-art multimodal and multitask methods for motion comprehension and generation. It evaluates their performance across six core tasks: text-to-motion (T2M), motion-to-text (M2T), music-to-dance (A2D), dance-to-music (D2A), motion-to-motion (including prediction and in-between), and unconstrained generation of motion, text, and music. The table helps to illustrate the capabilities and limitations of each approach in handling different modalities and task combinations.
read the caption
Table 1: Comparison of recent multimodal, multitask methods across various motion comprehension and generation tasks. T2M: text-to-motion; M2T: motion-to-text; A2D: music-to-dance; D2A: dance-to-music; M2M: motion-to-motion that includes motion prediction and motion in-between. Random M, Random T, and Random A represent the unconstrained generation of motion, text, and music, respectively.

🔼 This table compares different training strategies for the M³GPT model on two tasks: Text-to-Motion and Music-to-Dance. It shows the impact of jointly optimizing the Language Model (LLM) and motion detokenizer, and the effect of adding auxiliary tasks (Text-to-Dance and Music-to-Text) to enhance synergy between the tasks. The results are evaluated using standard metrics for each task, such as FID, Diversity, and R-Precision, allowing a direct comparison of various training methods. The table highlights that joint optimization and the inclusion of auxiliary tasks lead to significant improvements in performance.
read the caption
Table 2: Evaluation of synergy learning and joint optimization of LLM and motion de-tokenizer on Text-to-Motion (Motion-X [29]) and Music-to-Dance (AIST++ [24]). T2M: Text-to-Motion. A2D: Music-to-Dance. T2D: Text-to-Dance. A2T: Music-to-Text. Trained single task refers to a model trained and tested on a single task. Pre-trained and Instruction-tuned indicate the model after pre-training (stage2) and instruction tuning (stage3), followed by direct testing on each task. The arrows (↑) indicate that higher values are better. The arrows (↓) indicate that smaller values are better. Bold indicates the best result.

🔼 This table compares several state-of-the-art multimodal and multitask methods in motion comprehension and generation. It assesses their capabilities across six key tasks: text-to-motion (T2M), motion-to-text (M2T), music-to-dance (A2D), dance-to-music (D2A), motion-to-motion (M2M, including prediction and in-between), and unconstrained generation of motion, text, and music. The table helps to illustrate the relative strengths and weaknesses of each method in handling different types of multimodal motion tasks.
read the caption
Table 1: Comparison of recent multimodal, multitask methods across various motion comprehension and generation tasks. T2M: text-to-motion; M2T: motion-to-text; A2D: music-to-dance; D2A: dance-to-music; M2M: motion-to-motion that includes motion prediction and motion in-between. Random M, Random T, and Random A represent the unconstrained generation of motion, text, and music³, respectively.

🔼 This table presents the ablation study results to show the effectiveness of synergy learning and joint optimization of LLM and motion de-tokenizer. It compares the performance of different model variations on Text-to-Motion and Music-to-Dance tasks, highlighting the impact of adding auxiliary tasks (T2D, A2T) and joint optimization of the motion de-tokenizer. The metrics used are R-TOP1, FID, Div for text-to-motion and FIDk, Divk, BAS for music-to-dance.
read the caption
Table 2: Evaluation of synergy learning and joint optimization of LLM and motion de-tokenizer on Text-to-Motion (Motion-X [29]) and Music-to-Dance (AIST++ [24]). T2M: Text-to-Motion. A2D: Music-to-Dance. T2D: Text-to-Dance. A2T: Music-to-Text. Trained single task refers to a model trained and tested on a single task. Pre-trained and Instruction-tuned indicate the model after pre-training (stage2) and instruction tuning (stage3), followed by direct testing on each task. The arrows (↑) indicate that higher values are better. The arrows (↓) indicate that smaller values are better. Bold indicates the best result.

🔼 This table compares several existing multimodal and multitask methods for motion comprehension and generation, highlighting their capabilities across various tasks. The tasks include text-to-motion (T2M), motion-to-text (M2T), music-to-dance (A2D), dance-to-music (D2A), motion-to-motion (including prediction and in-betweening - M2M), and unconstrained generation of motion, text, and music (Random M, Random T, Random A). A checkmark indicates the method’s ability to perform each specific task.
read the caption
Table 1: Comparison of recent multimodal, multitask methods across various motion comprehension and generation tasks. T2M: text-to-motion; M2T: motion-to-text; A2D: music-to-dance; D2A: dance-to-music; M2M: motion-to-motion that includes motion prediction and motion in-between. Random M, Random T, and Random A represent the unconstrained generation of motion, text, and music³, respectively.

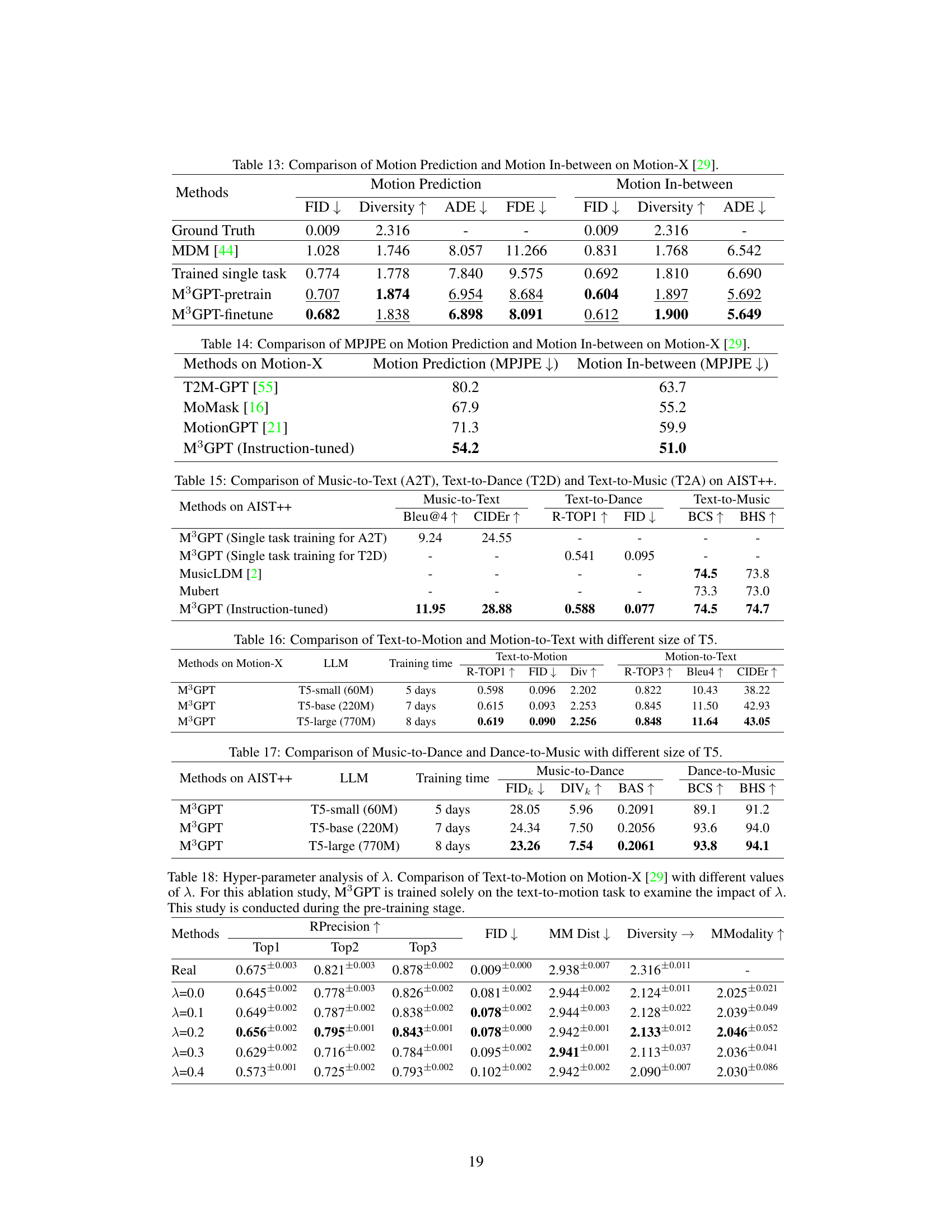
🔼 This table presents a comparison of various methods on the Motion-X dataset for several motion-related tasks. It shows the performance of different methods across four core tasks: text-to-motion, motion-to-text, motion prediction, and motion in-between. The metrics used for evaluation include R-Precision, FID, Diversity, Bleu, CIDEr, and BertScore, reflecting different aspects of motion generation and comprehension quality. The ‘Instruction-tuned only T2M’ column highlights the performance when the model is initially pre-trained on multiple tasks and then fine-tuned specifically for the text-to-motion task.
read the caption
Table 3: Comparison results on Motion-X [29] dataset. The evaluation metrics are computed using the encoder introduced in Appendix A. Empty columns of previous methods indicate that they can not handle the task. Instruction-tuned only T2M indicates the model that is initially pre-trained on multiple tasks, followed by instruction tuning solely on text-to-motion task.
🔼 This table presents the ablation study results, comparing different training strategies for the M³GPT model on two tasks: Text-to-Motion and Music-to-Dance. It shows the impact of joint optimization of the Language Model (LLM) and motion de-tokenizer, and the synergy gained by including auxiliary tasks (Text-to-Dance and Music-to-Text) in the training process. The results are presented in terms of several metrics for each task, showing the performance improvements from various model configurations.
read the caption
Table 2: Evaluation of synergy learning and joint optimization of LLM and motion de-tokenizer on Text-to-Motion (Motion-X [29]) and Music-to-Dance (AIST++ [24]). T2M: Text-to-Motion. A2D: Music-to-Dance. T2D: Text-to-Dance. A2T: Music-to-Text. Trained single task refers to a model trained and tested on a single task. Pre-trained and Instruction-tuned indicate the model after pre-training (stage2) and instruction tuning (stage3), followed by direct testing on each task. The arrows (↑) indicate that higher values are better. The arrows (↓) indicate that smaller values are better. Bold indicates the best result.

🔼 This table presents the ablation study results focusing on two aspects: the effectiveness of joint optimization of LLM and motion de-tokenizer and the synergy learning of multitasks. It compares the performance of different model variations across text-to-motion and music-to-dance tasks, highlighting the impact of joint optimization and the inclusion of auxiliary tasks (text-to-dance and music-to-text) on the overall results. The metrics used include FID, diversity (Div), and R-precision for text-to-motion, and FIDk, diversity (Divk), and BAS for music-to-dance, reflecting both the quality and diversity of the generated motions/dances.
read the caption
Table 2: Evaluation of synergy learning and joint optimization of LLM and motion de-tokenizer on Text-to-Motion (Motion-X [29]) and Music-to-Dance (AIST++ [24]). T2M: Text-to-Motion. A2D: Music-to-Dance. T2D: Text-to-Dance. A2T: Music-to-Text. Trained single task refers to a model trained and tested on a single task. Pre-trained and Instruction-tuned indicate the model after pre-training (stage2) and instruction tuning (stage3), followed by direct testing on each task. The arrows (↑) indicate that higher values are better. The arrows (↓) indicate that smaller values are better. Bold indicates the best result.

🔼 This table presents the ablation study results, comparing different training methods and their effects on text-to-motion and music-to-dance tasks. It shows the impact of jointly optimizing the language model (LLM) and motion detokenizer, as well as the effect of including synergy learning via auxiliary tasks (text-to-dance and music-to-text). The results are evaluated using standard metrics for each task, and the comparison highlights the benefits of the proposed training strategies in enhancing both fidelity and diversity of generated motions and dances.
read the caption
Table 2: Evaluation of synergy learning and joint optimization of LLM and motion de-tokenizer on Text-to-Motion (Motion-X [29]) and Music-to-Dance (AIST++ [24]). T2M: Text-to-Motion. A2D: Music-to-Dance. T2D: Text-to-Dance. A2T: Music-to-Text. Trained single task refers to a model trained and tested on a single task. Pre-trained and Instruction-tuned indicate the model after pre-training (stage2) and instruction tuning (stage3), followed by direct testing on each task. The arrows (↑) indicate that higher values are better. The arrows (↓) indicate that smaller values are better. Bold indicates the best result.

🔼 This table presents the ablation study results to show the effectiveness of the synergy learning and joint optimization of LLM and motion de-tokenizer on two tasks: Text-to-Motion and Music-to-Dance. It compares different model configurations, showing the performance impact of adding auxiliary tasks (T2D and A2T), re-optimizing the motion de-tokenizer, and the effects of pre-training and instruction-tuning stages. The results, in terms of metrics like R-Precision, FID, and Diversity, highlight the impact of these choices on the accuracy and quality of motion and dance generation.
read the caption
Table 2: Evaluation of synergy learning and joint optimization of LLM and motion de-tokenizer on Text-to-Motion (Motion-X [29]) and Music-to-Dance (AIST++ [24]). T2M: Text-to-Motion. A2D: Music-to-Dance. T2D: Text-to-Dance. A2T: Music-to-Text. Trained single task refers to a model trained and tested on a single task. Pre-trained and Instruction-tuned indicate the model after pre-training (stage2) and instruction tuning (stage3), followed by direct testing on each task. The arrows (↑) indicate that higher values are better. The arrows (↓) indicate that smaller values are better. Bold indicates the best result.
Full paper#