↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Global routing is crucial for chip design, but existing learning-based methods often suffer from significant overflow, hindering their real-world applicability. Traditional methods use heuristics to solve the NP-complete Rectilinear Steiner Tree (RST) problem, often leading to suboptimal solutions and high overflow. Learning-based approaches have shown potential, but existing approaches struggle with overflow and scaling to large nets.
NeuralSteiner, the proposed method, tackles this problem by learning to predict optimal Steiner points using a neural network which considers both spatial and overflow information. A post-processing algorithm then uses these predicted points to construct an overflow-avoiding RST. This approach reduces overflow by up to 99.8% on benchmark datasets, significantly outperforming state-of-the-art methods and demonstrating the power of AI-driven optimization in chip design. The method also shows improved scalability compared to existing approaches, further enhancing its practical value.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical issue of overflow in global routing, a significant bottleneck in modern chip design. By proposing a novel learning-based approach, NeuralSteiner, it offers a potential solution to improve routing efficiency and scalability, opening new avenues for research in AI-driven chip design. The results are significant as they show a marked reduction in overflow without sacrificing wire length, a problem that has plagued previous learning-based methods. This work pushes the boundaries of what’s possible in chip design optimization using AI.
Visual Insights#

This figure illustrates the overflow-avoiding global routing process using NeuralSteiner. It starts with a real-world chip layout and shows the steps involved in predicting Steiner points, constructing a net augmented graph, and generating overflow-avoiding rectilinear Steiner trees (RSTs). It compares the results with HubRouter, highlighting NeuralSteiner’s ability to avoid congestion.
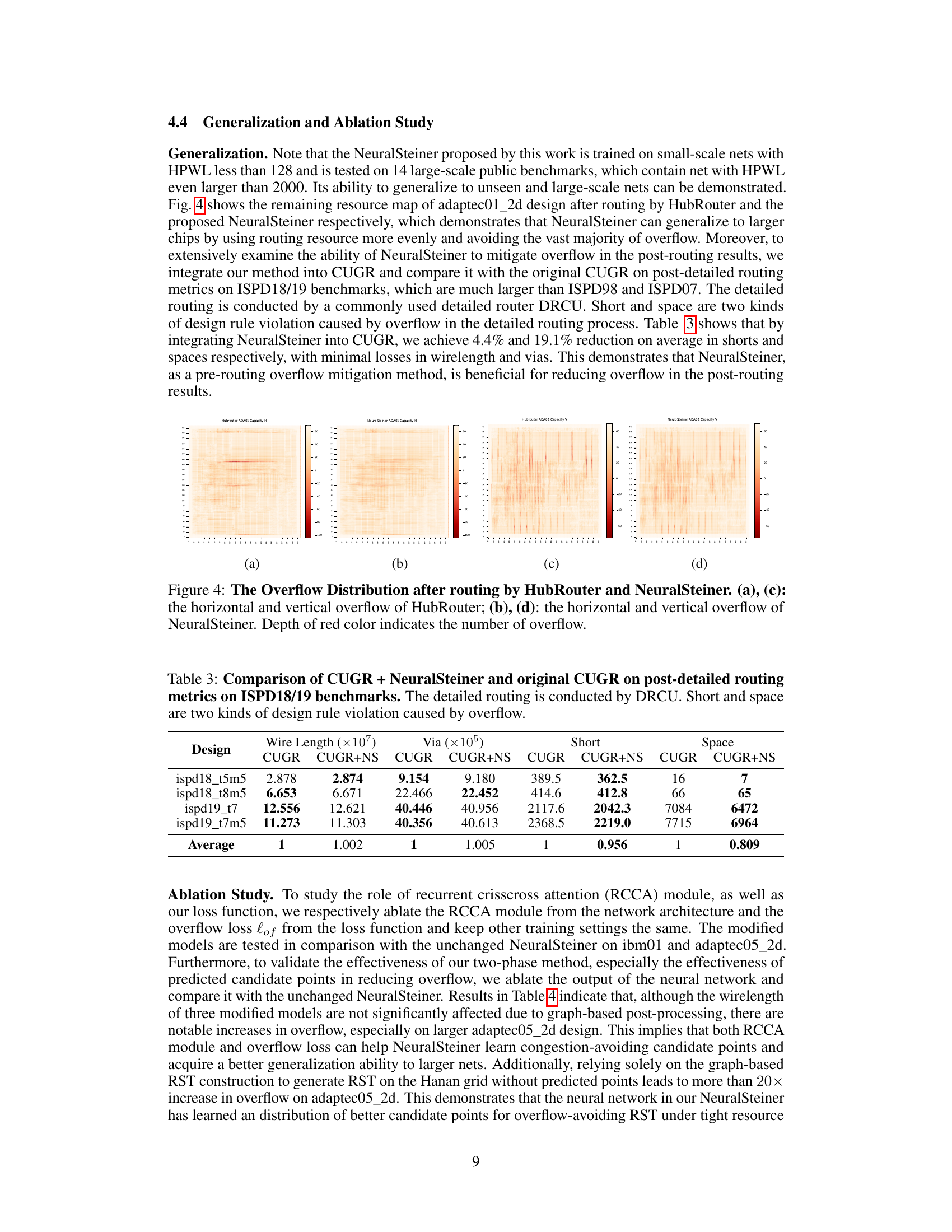
This table presents a comparison of the wirelength and running time of NeuralSteiner against two traditional global routers (GeoSteiner, Boxrouter, FLUTE+ES) and three variants of the HubRouter model (HR-VAE, HR-DPM, HR-GAN) on six benchmark datasets (ibm01-06) from ISPD98. The optimal results for wirelength and time are highlighted in bold. It demonstrates the performance of NeuralSteiner in terms of both wirelength and speed compared to existing methods.
In-depth insights#
Steiner Tree Learning#
Steiner tree learning in the context of chip design focuses on leveraging machine learning to optimize the construction of Steiner trees, crucial for efficient global routing. The core challenge lies in finding the optimal placement of Steiner points to minimize wirelength while adhering to design constraints and avoiding signal congestion (overflow). Traditional methods rely on heuristics that are computationally expensive and struggle to scale with the complexity of modern chip designs. Learning-based approaches offer a promising alternative, potentially enabling faster and more effective routing solutions by learning optimal Steiner point placement from data. However, a key area of focus is on developing techniques that explicitly address the overflow problem. Simply minimizing wirelength can lead to excessive congestion, rendering the solution impractical. Therefore, successful Steiner tree learning for chip design necessitates a holistic approach that considers both wirelength and overflow, effectively learning to navigate the complex trade-off between these two competing objectives.
Overflow Mitigation#
Overflow mitigation in chip design is a critical challenge, focusing on managing the congestion of routing resources. NeuralSteiner addresses this by predicting Steiner points that consider both spatial layout and overflow information. This approach deviates from traditional methods that primarily focus on wirelength optimization, often neglecting the potential for congestion. The learned Steiner tree construction leverages a post-processing algorithm to generate overflow-avoiding rectilinear Steiner trees (RSTs). This two-phase approach is shown to significantly reduce overflow compared to state-of-the-art deep generative methods, which is a key advancement. Furthermore, NeuralSteiner’s ability to scale to larger nets without modification demonstrates its potential practical impact. However, the dependency on heuristic RST construction could limit efficiency and might necessitate further investigation into more sophisticated methods for creating congestion-free routes.
Neural Network Design#
A robust neural network architecture is crucial for effective learning in any application. In the context of overflow-avoiding global routing, the network design needs to efficiently integrate spatial and overflow information. This would likely involve convolutional layers to capture local patterns in the chip layout and recurrent connections (e.g., LSTMs or GRUs) to model long-range dependencies. Attention mechanisms, such as the crisscross attention used in the paper, are key to weigh the importance of different regions for accurate Steiner point prediction. The choice of activation functions, loss functions (focal loss is particularly suitable for imbalanced datasets), and optimizers significantly impacts training speed and performance. Furthermore, the network’s ability to generalize to unseen chip designs depends heavily on architectural choices and data augmentation strategies employed during training. Finally, the design should facilitate parallel processing to handle the complexity and scale of large-scale netlists efficiently.
Parallel Routing#
Parallel routing in chip design aims to significantly speed up the routing process by concurrently handling multiple nets. Traditionally, routing is a sequential process, processing one net at a time. However, this approach becomes computationally expensive as the number of nets increases, making it crucial to explore parallel strategies. Identifying independent nets that do not interfere with each other during the routing process is key to parallelization. These nets can be processed simultaneously without impacting the correctness or quality of the resulting routes. Efficient algorithms are needed to identify these independent nets and effectively manage resources during parallel processing. The challenges include ensuring connectivity, handling potential conflicts or congestion, and achieving a good balance between speed and wirelength. Effective parallel routing methods are vital for handling the ever-increasing complexity of modern chip designs, promising a reduction in overall routing time and enabling faster chip fabrication.
Future Enhancements#
Future enhancements for this research could focus on several key areas. Improving the efficiency of the RST construction algorithm is crucial; the current greedy approach, while effective, could be optimized. Exploring alternative algorithms, such as those based on dynamic programming or approximation techniques, could yield faster and potentially better solutions. Another area ripe for improvement lies in expanding the network architecture. More sophisticated deep learning models, perhaps incorporating attention mechanisms or graph neural networks, could lead to more accurate predictions of Steiner points and improved overall performance. Finally, rigorous testing and validation across a wider range of chip designs and netlist complexities is needed to further establish the robustness and generalizability of the approach. Addressing these enhancements would pave the way for NeuralSteiner to become a truly impactful global routing solution.
More visual insights#
More on figures

This figure illustrates the overall pipeline of the NeuralSteiner method. (a) shows the parallel processing of non-overlapping nets, enhancing efficiency. (b) details the first phase: a neural network predicts candidate points for RSTs using spatial and overflow information. (c) presents the second phase, where a net augmented graph is created based on predictions, leading to overflow-avoiding RST generation.
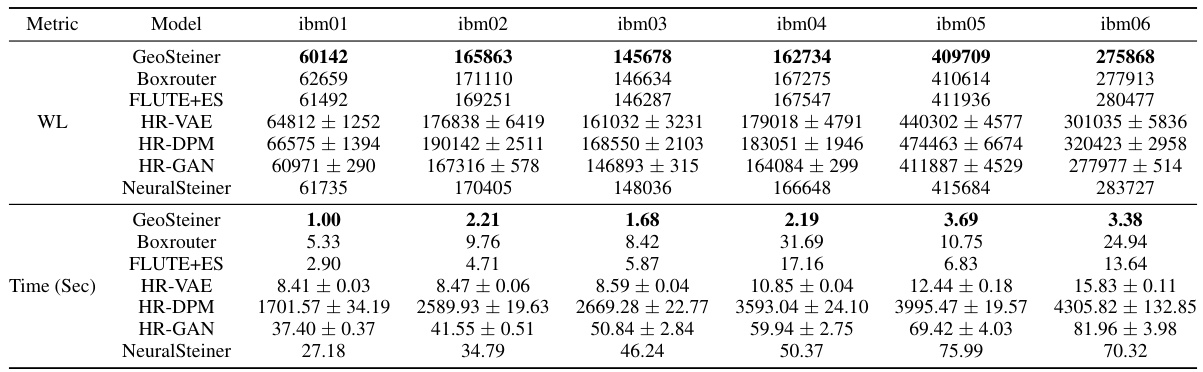
This figure compares the overflow performance of NeuralSteiner against several other methods, including Geosteiner and three variants of HubRouter, across six benchmark datasets (ibm01-ibm06) from ISPD98. It visually represents the total overflow count for each method on each dataset. Noticeably, NeuralSteiner demonstrates a significant reduction in overflow compared to the other approaches, particularly on the ibm05 dataset where it only produces 18 overflows.
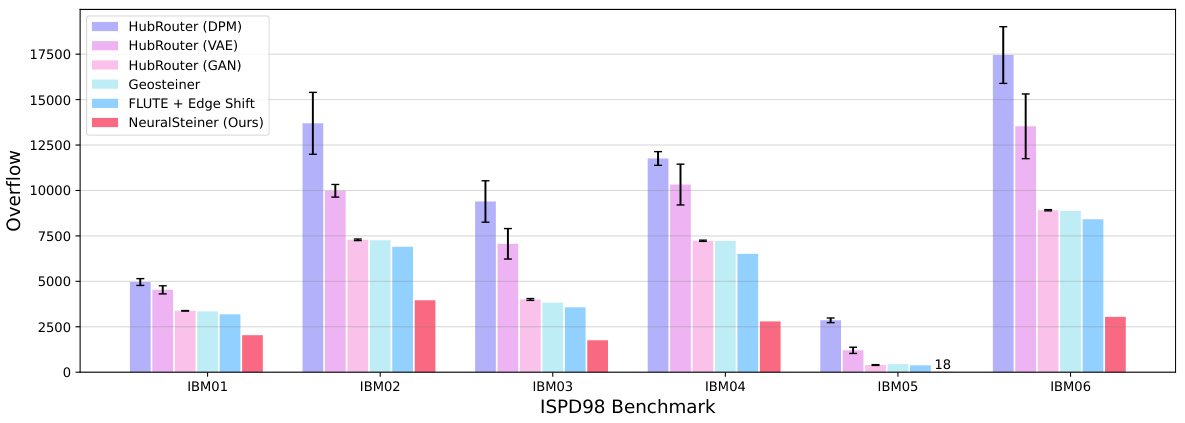
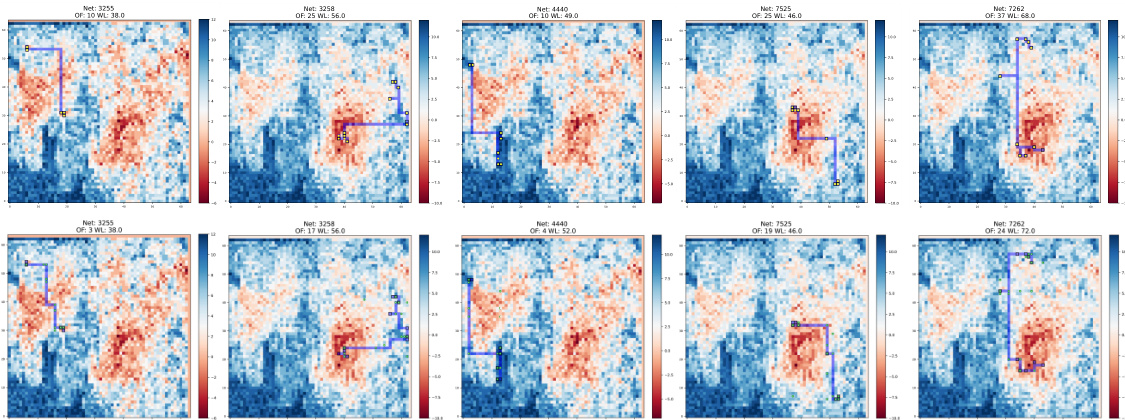
This figure visualizes the overflow distribution after global routing using HubRouter and the proposed NeuralSteiner method. It presents four heatmaps: (a) and (c) show the horizontal and vertical overflow for HubRouter, respectively, while (b) and (d) do the same for NeuralSteiner. The color intensity (depth of red) represents the magnitude of overflow in each grid cell. This allows for a direct visual comparison of the overflow reduction achieved by NeuralSteiner compared to HubRouter, highlighting its effectiveness in mitigating congestion during the chip routing process.

This figure demonstrates the overflow-avoiding global routing process using NeuralSteiner. It shows the chip layout, grid graph, Hanan grid, resource and pin maps, and routing results. The comparison between HubRouter and NeuralSteiner highlights NeuralSteiner’s ability to avoid overflow while maintaining connectivity.
This figure demonstrates the overflow-avoiding global routing approach proposed in the paper using a real-world example. It visually illustrates different steps of the process: (a) shows the original chip layout, (b) the grid graph representation, (c) the Hanan grid, (d) the resource and pin maps, (e) HubRouter’s prediction and stripe mask, (f) HubRouter’s congested routing result, (g) NeuralSteiner’s candidate points and net augmented graph (NAG), and (h) the final congestion-free routing result generated by NeuralSteiner. The figure highlights the improvement of NeuralSteiner in avoiding overflow while maintaining connectivity.
More on tables
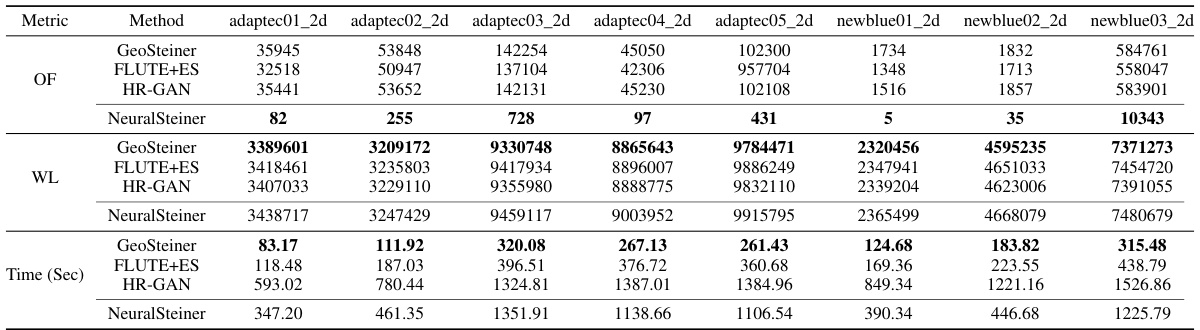
This table presents a comparison of the wirelength and runtime performance of NeuralSteiner against two traditional global routing baselines (GeoSteiner and Boxrouter) and three variations of the HubRouter method (using VAE, DPM, and GAN). The comparison is conducted using six benchmark datasets from ISPD98 (ibm01-06). The table highlights the optimal results for wirelength and runtime in bold, showcasing the relative performance of each method across different metrics.
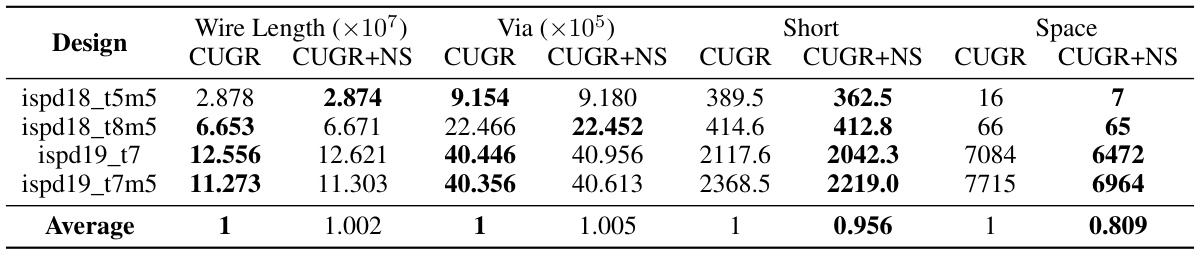
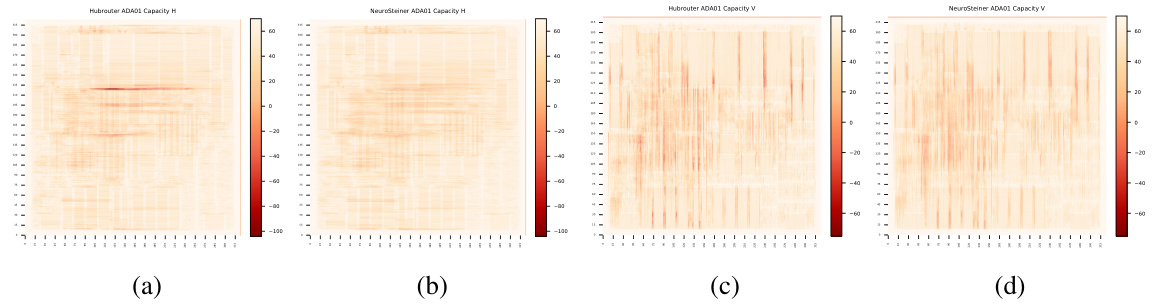
This table compares the performance of CUGR (a traditional global router) with and without the integration of NeuralSteiner on post-detailed routing metrics for ISPD18 and ISPD19 benchmarks. The detailed routing is performed using DRCU. It shows the wire length, number of vias, number of shorts, and number of spaces (design rule violations due to overflow) for each benchmark. The average improvement in reducing design rule violations by integrating NeuralSteiner is also presented.
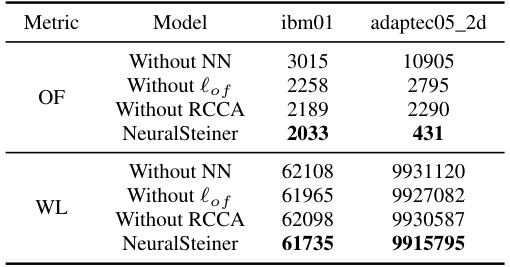
This table presents the results of an ablation study conducted to evaluate the impact of different components of the NeuralSteiner model on its performance. The study removes either the neural network entirely, the overflow loss function ((\ell_{of})), or the Recurrent Crisscross Attention (RCCA) module, one at a time. The table compares the overflow (OF) and wirelength (WL) metrics for the modified models against the full NeuralSteiner model on two example chip designs (ibm01 and adaptec05_2d). This allows for an assessment of the relative contribution of each component to the overall performance of the model in terms of both overflow reduction and wirelength.

This table compares the performance of NeuralSteiner against other state-of-the-art global routing methods on a set of large-scale benchmark datasets from ISPD07. The metrics compared are overflow, wirelength, and runtime. NeuralSteiner shows significant improvements in overflow reduction with minimal wirelength increase. The optimal results (lowest overflow, shortest wirelength and fastest runtime) are highlighted in bold.

This table presents a comparison of the wirelength and runtime performance of NeuralSteiner against two traditional global routing methods (GeoSteiner and Boxrouter) and three variations of the HubRouter model (using VAE, DPM, and GAN) on six benchmark datasets from ISPD98 (ibm01-06). The results highlight NeuralSteiner’s performance in terms of wirelength and runtime, indicating its efficiency and competitiveness compared to state-of-the-art methods.

This table presents a comparison of the wirelength and running time of NeuralSteiner against two traditional baselines (GeoSteiner and Boxrouter) and three variants of HubRouter (using VAE, DPM, and GAN) on six benchmark datasets (ibm01-06) from ISPD98. The optimal results for wirelength and time are highlighted in bold. It shows NeuralSteiner’s performance in terms of wirelength and speed compared to existing methods.
This table compares the wirelength and running time of NeuralSteiner against two traditional methods (GeoSteiner and Boxrouter) and three variations of the HubRouter method (using VAE, DPM, and GAN) on six benchmark datasets (ibm01-06 from ISPD98). The optimal results for wirelength and runtime are highlighted in bold. It demonstrates NeuralSteiner’s performance relative to existing state-of-the-art methods.

This table compares the performance of NeuralSteiner against three other state-of-the-art global routers (GeoSteiner, FLUTE + Edge Shift, and HubRouter with GAN) on eight large-scale benchmark datasets from ISPD07. The metrics compared are overflow, wirelength, and runtime. NeuralSteiner demonstrates a significant reduction in overflow with a minimal increase in wirelength compared to the other methods.

This table compares the performance of CUGR (a traditional global router) with and without the NeuralSteiner method integrated. The comparison is based on post-detailed routing metrics from ISPD18/19 benchmarks, focusing on wire length, via count, shorts, and spaces (design rule violations caused by overflow). It demonstrates NeuralSteiner’s effectiveness in reducing overflow by showing significant improvements in shorts and spaces.
Full paper#