↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Many generative AI tasks utilize diffusion models; however, their slow multi-step sampling process hinders real-world applications. Current distillation methods either need multiple steps or degrade performance. This creates a need for efficient single-step alternatives.
This paper introduces Score Implicit Matching (SIM), a novel distillation technique that efficiently transforms pre-trained diffusion models into single-step generators. SIM uses a unique approach based on score-based divergences, bypassing the need for training data and preserving the quality of outputs. The approach outperforms existing methods on benchmark image and text-to-image tasks, showing a significant step forward in making diffusion models more practical.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on diffusion models because it presents a novel and efficient method to distill complex, multi-step diffusion models into simpler, one-step models without sacrificing performance. This significantly reduces computational costs and speeds up generation, making diffusion models more accessible and applicable across various fields. The techniques are particularly relevant to those working on text-to-image generation and other high-capacity AIGC models, paving the way for improved efficiency and scalability in those applications. It also introduces a novel theoretical framework which can be extended to improve diffusion distillation overall.
Visual Insights#

This figure presents a human preference study comparing image generation quality. Three images are shown for three different prompts. The rightmost column uses the one-step Latent Consistency Model of PixelArt-a. The left two columns show images generated by the proposed SIM-DiT-600M model and the 14-step PixelArt-a teacher diffusion model, respectively, for each prompt. The user is asked to identify the best quality image, with the answer provided in the appendix.
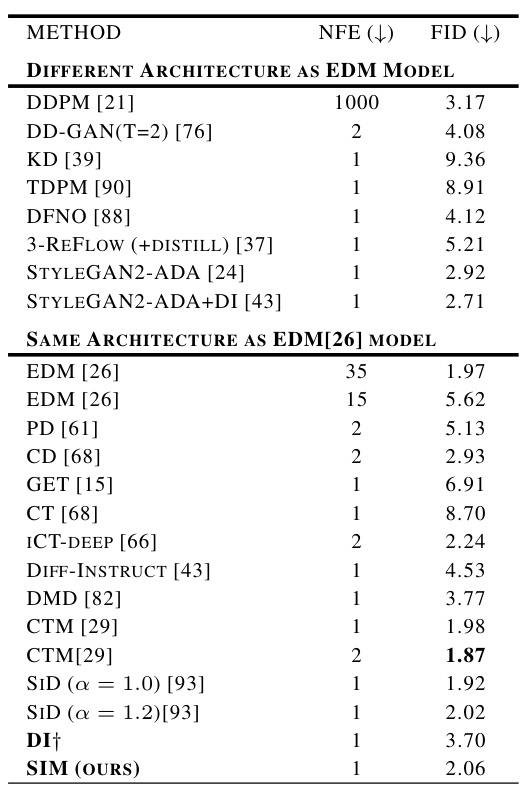
This table presents the FID (Frechet Inception Distance) scores for various generative models on the CIFAR-10 dataset, comparing unconditional image generation. Lower FID indicates better image quality. The table compares models with different architectures, highlighting the performance of the proposed SIM model against others using the same or different architecture as the teacher model. The NFE (number of forward diffusion evaluations) column indicates the computational cost of generating samples. The ‘†’ symbol indicates methods that were reproduced by the authors for fair comparison.
In-depth insights#
Score Implicit Matching#
The proposed framework, Score Implicit Matching (SIM), offers a novel approach to distilling pre-trained diffusion models. Instead of directly minimizing the intractable score-based divergence, SIM cleverly computes gradients for a wide class of score-based divergences, enabling efficient training of one-step generator models. This is achieved through the score-gradient theorem, which allows for exact gradient computation despite the intractability of the divergence itself. The flexibility of SIM is highlighted by its ability to accommodate diverse distance functions, surpassing previous methods that relied on specific divergences like KL or Fisher. SIM’s empirical performance is compelling, demonstrating state-of-the-art results on CIFAR-10 and achieving near lossless distillation of a transformer-based text-to-image model, showcasing its potential for high-quality, one-step image generation.
One-Step Distillation#
One-step distillation in the context of diffusion models presents a significant advancement by directly generating high-quality samples with a single forward pass, thereby bypassing the computationally expensive iterative sampling process inherent in traditional diffusion models. This efficiency gain is crucial for deploying these models in resource-constrained environments and real-time applications. The core challenge lies in effectively transferring the knowledge encoded in a pre-trained, multi-step diffusion model to a single-step generator without substantial performance degradation. Successful one-step distillation methods must carefully balance model capacity and the complexity of the knowledge transfer mechanism. This often involves novel loss functions, training strategies, and potentially architectural modifications to the generator network to ensure that it can capture the intricate data distribution learned by its multi-step counterpart. While achieving single-step generation, it’s vital to maintain the quality and diversity of generated samples, which typically requires careful hyperparameter tuning and possibly additional regularization techniques. The success of one-step distillation techniques directly impacts the practicality and broader accessibility of diffusion models, making it an active and important area of research.
Diffusion Model Advances#
Diffusion models have witnessed significant advancements, transitioning from computationally expensive, multi-step samplers to more efficient single-step alternatives. Score-based methods have been pivotal, enabling the approximation of score functions that guide the generation process. The development of novel loss functions, such as those based on score divergences, and training techniques that bypass the need for explicit score calculations have significantly improved efficiency. Furthermore, transformer-based diffusion models have demonstrated impressive results in applications like text-to-image generation, showcasing increased scalability and high-quality output. The community’s ongoing efforts aim to resolve challenges like mode collapse, improve sample diversity, and further reduce computational demands to facilitate broader applications and wider accessibility of this powerful generative modeling technique. Future advances are expected to lead to more robust, efficient, and versatile diffusion models.
CIFAR & T2I Results#
The ‘CIFAR & T2I Results’ section would ideally present a comprehensive evaluation of the proposed Score Implicit Matching (SIM) method across diverse image generation tasks. For CIFAR-10, the focus should be on quantitative metrics like FID and Inception Score, comparing SIM’s single-step generation performance against multi-step baselines and other state-of-the-art one-step methods. Key insights would emerge from analyzing the FID and IS scores, highlighting SIM’s advantages in terms of sample quality and efficiency. Regarding T2I results, the evaluation needs to extend beyond simple FID scores to incorporate qualitative assessment. This could involve human evaluation metrics like aesthetic scores, user preference studies, or qualitative comparisons of generated images to assess visual fidelity, detail, and adherence to text prompts. Demonstrating superior performance on a challenging, high-quality T2I benchmark, potentially using an industry-standard model like SDXL, would be crucial. The section needs to meticulously compare SIM’s performance against strong competitors such as SDXL-Turbo and HYPER-SDXL. Detailed discussion of the trade-offs between performance gains and computational cost is important for practical applications. A thorough analysis that covers the quantitative and qualitative aspects of SIM’s performance across both CIFAR and T2I benchmarks would help in fully understanding its strengths and limitations.
Future Research#
The research paper’s ‘Future Research’ section could explore several promising avenues. Generalizing SIM to other generative models beyond diffusion models is crucial to broaden its impact. Investigating the use of alternative distance functions or divergence measures within the SIM framework could reveal improved performance or stability. Furthermore, the authors should investigate ways to incorporate real data into SIM to enhance sample quality and address potential limitations. Exploring different architectures or model sizes would help assess SIM’s scalability and identify potential bottlenecks. Lastly, a thorough analysis of failure cases and potential biases within the one-step generation could yield valuable insights and guide improvements. Addressing robustness to noisy or incomplete data is essential for practical applications. Overall, a comprehensive investigation into these areas would greatly strengthen the contributions and applications of SIM.
More visual insights#
More on figures
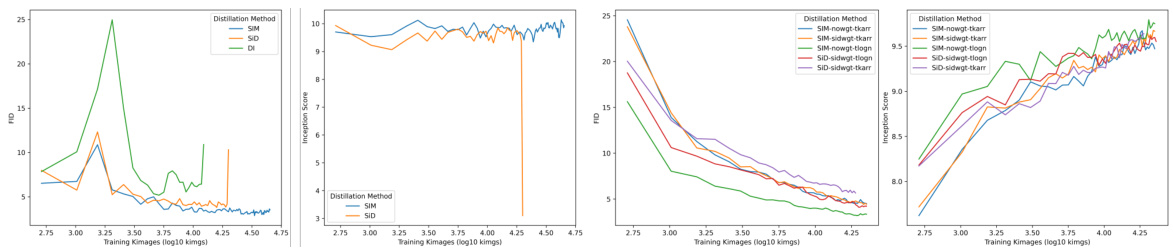
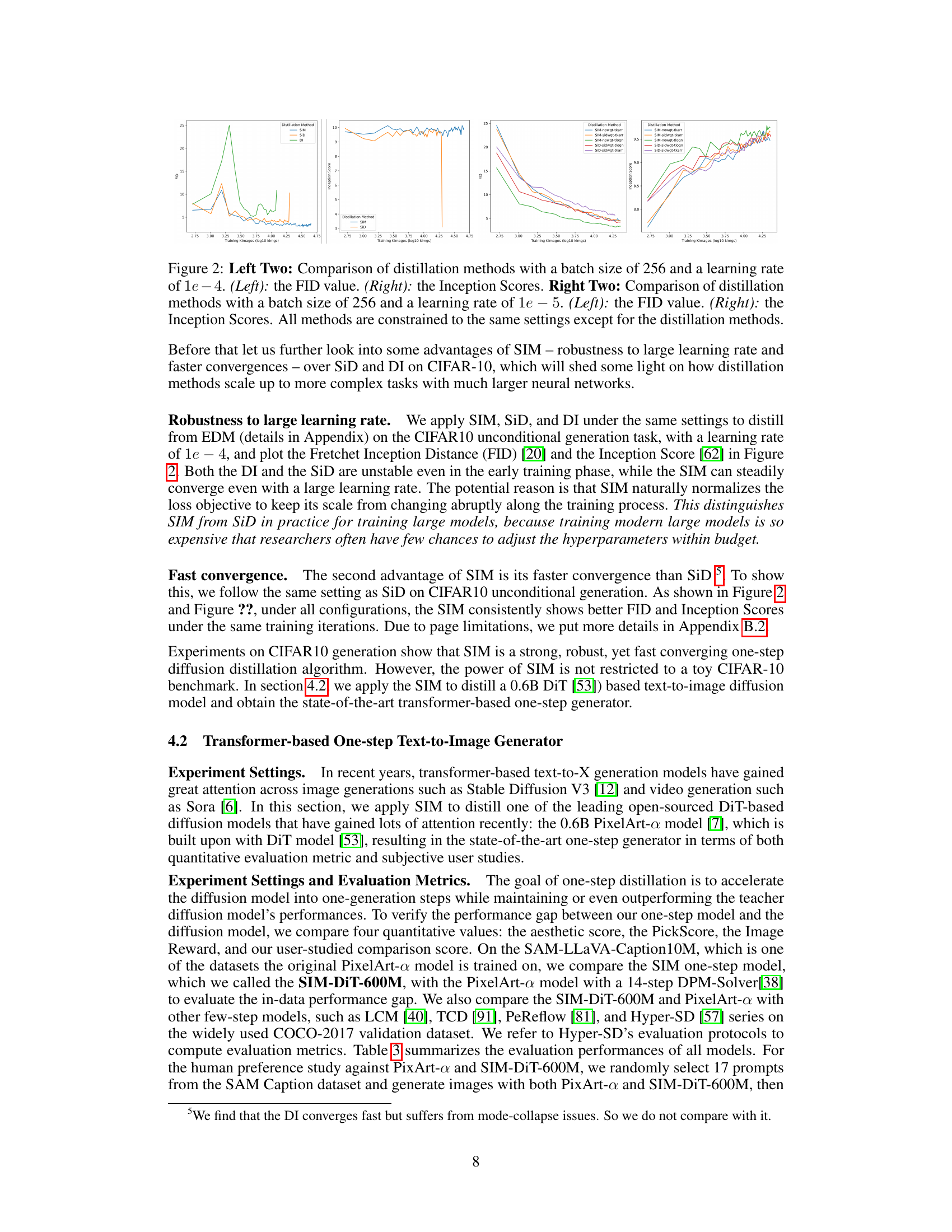
This figure compares the performance of different distillation methods (SIM, SiD) under various learning rates (1e-4, 1e-5) and batch sizes (256). The left two subfigures show FID (Frechet Inception Distance) and Inception Score values, respectively, for the 1e-4 learning rate experiments. The right two subfigures display the same metrics, but for the 1e-5 learning rate experiments. The results demonstrate that SIM is more robust to the choice of hyperparameters than SiD, achieving faster convergence and more stable performance across both learning rates.

This figure compares the image generation quality of SIM-DiT-600M against other leading few-step text-to-image models, including SDXL-Hyper, SDXL-TCD, SDXL-Turbo, SDXL-Lightning, and LCM-PixArt-alpha. The comparison focuses on image details, lighting, and overall aesthetic quality. The prompts used to generate these images can be found in Appendix B.7 of the paper.

This figure presents a human preference study comparing image generation quality. Three columns showcase images: the rightmost shows a one-step Latent Consistency Model, while the leftmost two are randomly ordered images from a one-step SIM-DiT-600M model and a 14-step PixelArt-a diffusion model. Users are asked to identify the better-quality image, with the correct answer provided in the appendix. This study highlights the ability of the one-step SIM model to produce comparable image quality to the 14-step model.

This figure compares the performance of different distillation methods (SIM and SiD) under various settings. The left two subfigures show FID and Inception Scores for a batch size of 256 and learning rate of 1e-4, highlighting SIM’s robustness to hyperparameters. The right two subfigures present the same metrics but with a smaller learning rate of 1e-5, further emphasizing SIM’s superior performance and faster convergence compared to SiD.

This figure presents a human preference study comparing image generation quality. Three columns of images are shown, each generated using a different method. The rightmost column shows images from a one-step Latent Consistency Model, while the left two columns feature images from a one-step SIM-DiT-600M model and a 14-step PixelArt-a diffusion model (the order is randomized). Readers are prompted to choose which images they prefer, with the answer revealed in Appendix B.1. This comparison highlights the effectiveness of the SIM-DiT-600M model in achieving one-step generation quality close to that of a multi-step method.

This figure shows the images generated by a one-step Score Implicit Matching (SIM) model on the CIFAR10 dataset, conditioned on class labels. The FID score of 1.96 indicates high-quality image generation. The figure demonstrates the model’s ability to generate realistic and diverse images within a single step, a significant improvement over traditional diffusion models that require many steps for comparable results.

This figure shows the images generated by a one-step generator trained using the Score Implicit Matching (SIM) method on the CIFAR10 dataset. The images are class-conditional, meaning that the generator was trained to produce images of a specific class (e.g., cat, dog, bird). The FID score (Frechet Inception Distance) of 1.96 indicates high-quality image generation, comparable to the performance of more computationally expensive multi-step diffusion models.
This figure compares the performance of SIM, SiD, and DI under different learning rates (1e-4 and 1e-5) and batch size (256) in terms of FID and Inception Score. The left two subfigures show the results with a learning rate of 1e-4, while the right two subfigures show the results with a learning rate of 1e-5. The plots demonstrate SIM’s robustness to higher learning rates and faster convergence compared to the other methods.
More on tables

This table presents the FID (Frechet Inception Distance) scores for various generative models on the CIFAR-10 dataset, focusing on unconditional image generation. Lower FID scores indicate better image quality. The table compares the performance of the proposed SIM method to other state-of-the-art diffusion models, with a particular emphasis on models using the same architecture as the EDM (Energy-based Diffusion Model) that serves as the baseline for the SIM distillation. The NFE (Number of Function Evaluations) column shows the number of steps in the generation process.
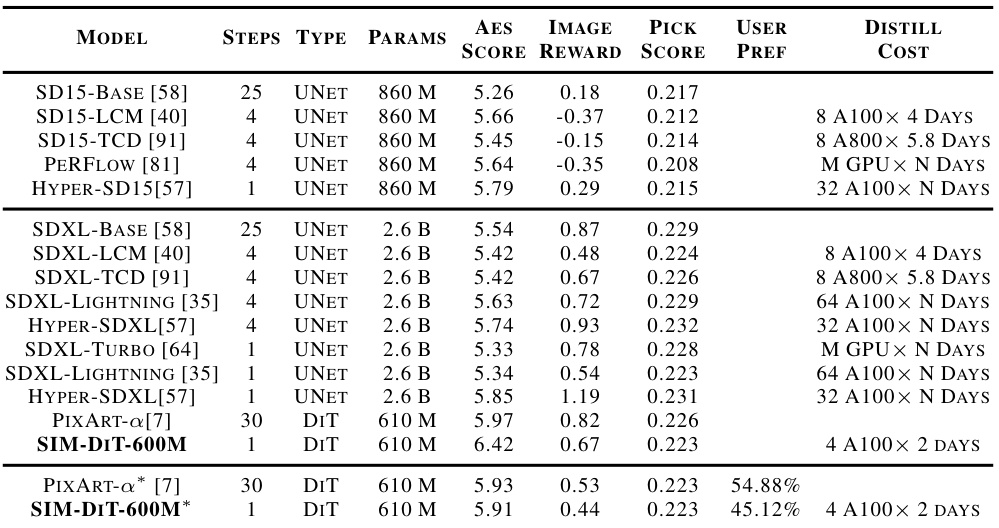
This table quantitatively compares the SIM-DiT-600M model’s performance with other state-of-the-art text-to-image models on the COCO-2017 validation dataset. Metrics include Aesthetic Score, Image Reward, Pick Score, and User Preference (based on a human preference study). The table also notes the computational cost of training each model, highlighting the efficiency of SIM-DiT-600M. A separate row shows a comparison on the SAM-LLaVA-Caption10M dataset.

This table presents the results of unconditional image generation on the CIFAR-10 dataset using various methods. The table compares different approaches in terms of Number of Function Evaluations (NFE) needed for image generation and the Fréchet Inception Distance (FID) score, a measure of sample quality (lower is better). The methods are categorized into those with different architectures compared to the EDM model and those with the same architecture. The goal is to showcase the single-step generator’s performance against the original multi-step diffusion model in terms of both efficiency and image quality.
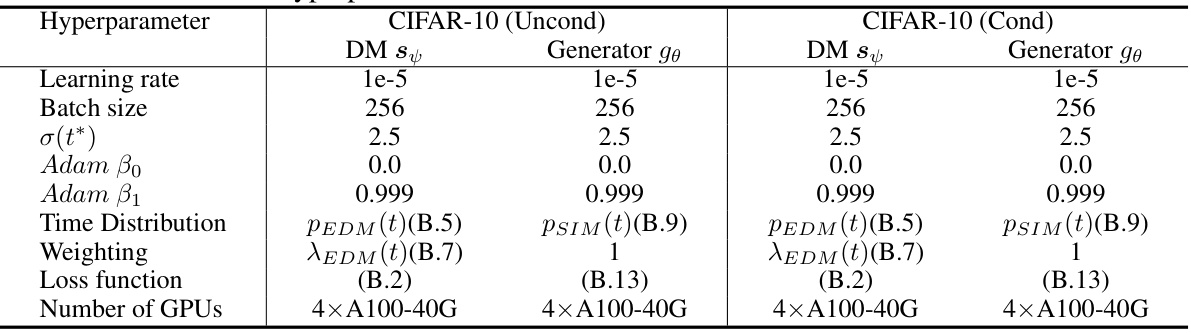
This table lists the hyperparameters used in the Score Implicit Matching (SIM) experiments on the CIFAR-10 dataset using the EDM diffusion model. It shows the settings for both the teacher diffusion model (DM s) and the one-step generator model (Generator gθ) for both unconditional and class-conditional generation. Hyperparameters include the learning rate, batch size, the chosen time step (σ(t*)), Adam optimizer parameters (β0, β1), the time distribution used (either PEDM or PSIM), the weighting function (λEDM or 1), the loss function used (B.2 or B.13), and the number of GPUs used.
Full paper#