↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Adapting automatic speech recognition (ASR) models to various domains (noise, accents, etc.) typically requires significant amounts of labeled data, a costly and time-consuming process. This significantly limits the deployment of ASR models to real-world scenarios where such data may be scarce or unavailable. Existing unsupervised domain adaptation methods often struggle with this, often requiring source data or achieving suboptimal results. The paper addresses these issues by introducing a novel framework.
The proposed method, STAR, leverages unlabeled data for unsupervised adaptation of ASR models. It introduces a new indicator that assesses the quality of pseudo-labels generated during the decoding process, effectively guiding model updates. Experiments demonstrated that STAR significantly outperforms existing self-training approaches and even approaches the performance of supervised adaptation on certain datasets, without the need for source data. This makes the method significantly more efficient, robust, and versatile for real-world applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in speech recognition and related fields due to its novel approach to unsupervised domain adaptation. It tackles the challenge of adapting speech models to new domains without requiring labeled data, a significant bottleneck in ASR development. The high data efficiency and generalizability of the proposed method, STAR, open up new avenues for cost-effective and robust speech technology. This research significantly advances source-free unsupervised domain adaptation, paving the way for more accessible and adaptable ASR systems.
Visual Insights#
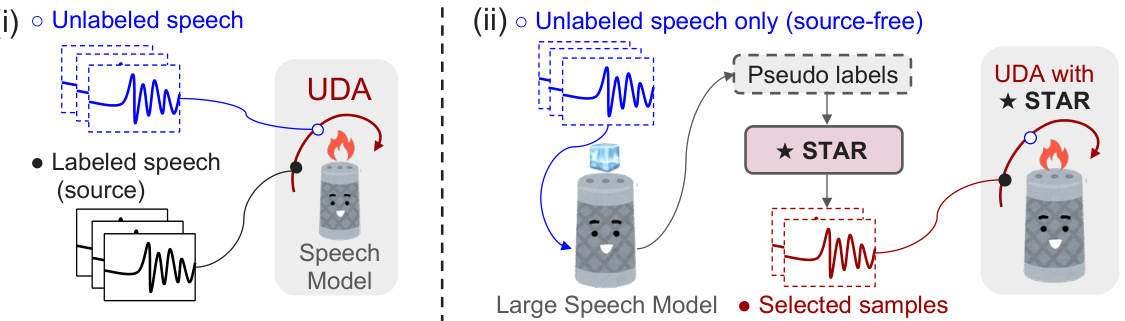
This figure illustrates two scenarios of unsupervised domain adaptation (UDA) for automatic speech recognition (ASR). The left panel (i) shows the standard UDA problem, where labeled source data and unlabeled target domain data are used to adapt the ASR model. The right panel (ii) shows the source-free UDA approach proposed in the paper, called STAR. In this scenario, only unlabeled data from the target domain is used. The STAR framework selects high-quality pseudo labels from the unlabeled target data and uses them to guide the model’s adaptation at the token level, enhancing the model’s robustness in diverse target domains such as noise and accents.
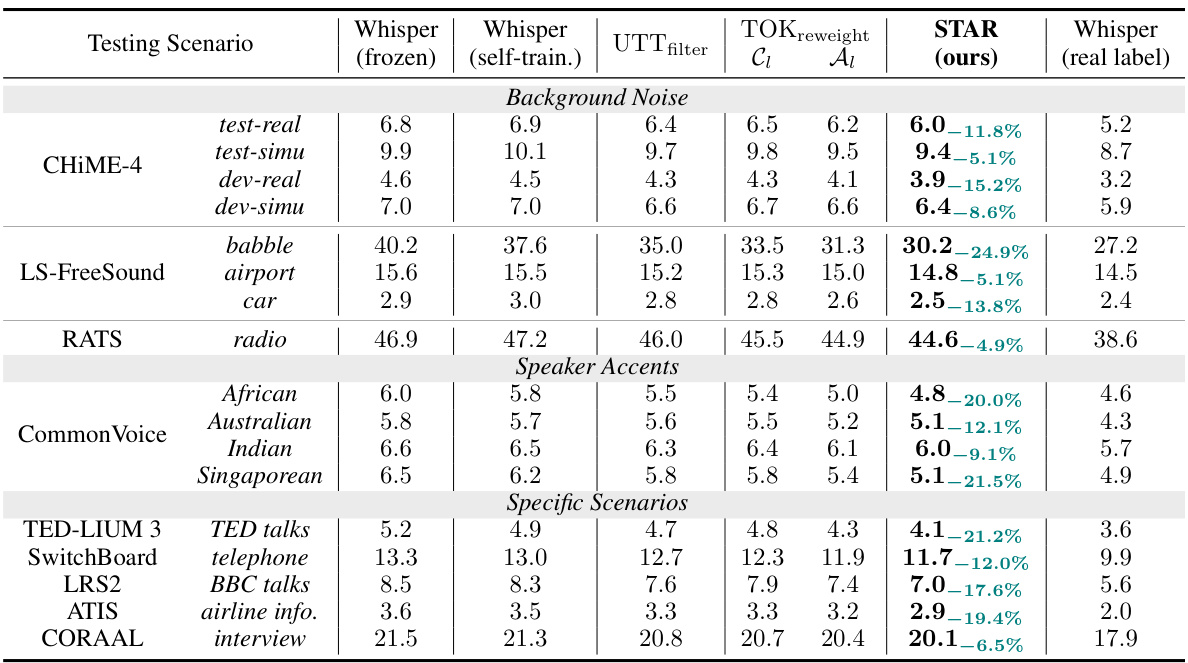
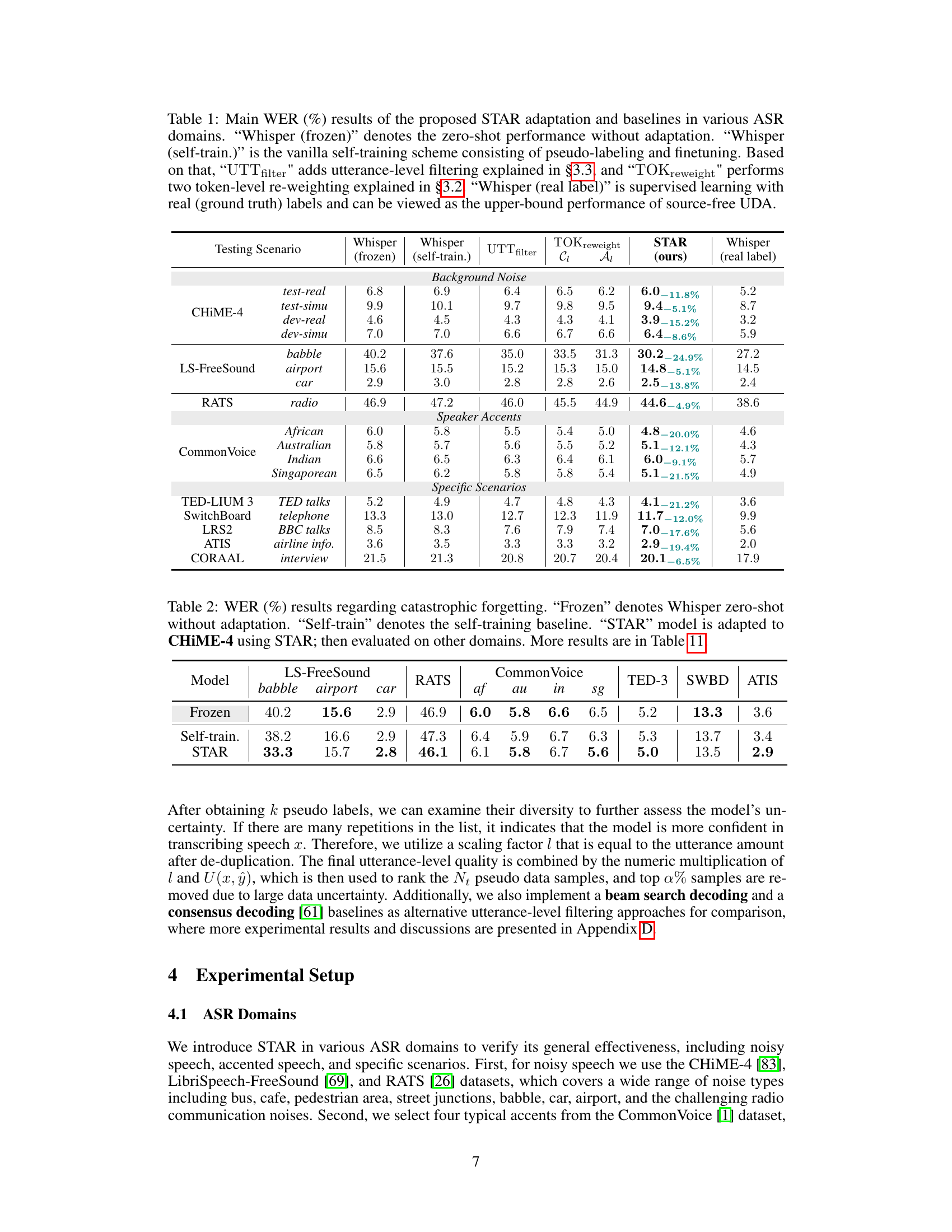
This table presents the Word Error Rate (WER) results for different ASR models and methods across various testing scenarios (noise, accents, specific tasks). It compares the performance of the proposed STAR method against baselines like zero-shot Whisper, self-training with and without utterance-level filtering and token re-weighting, and the upper-bound performance achieved by supervised learning with ground truth labels.
In-depth insights#
STAR: Source-Free UDA#
The proposed STAR framework tackles the challenge of source-free unsupervised domain adaptation (UDA) in Automatic Speech Recognition (ASR). STAR’s novelty lies in its ability to effectively leverage unlabeled target domain data without relying on source data, a significant departure from traditional UDA methods. This is achieved through a novel indicator that assesses the token-level quality of pseudo-labels generated during decoding, thus guiding a more informed and effective model adaptation. The approach demonstrates high data efficiency, requiring minimal unlabeled data, and exhibits impressive adaptability across various ASR foundation models. This source-free approach is particularly valuable for scenarios where obtaining labelled data is costly or impossible, and is designed for compatibility with popular large-scale models. Experimental results highlight substantial WER improvements, often approaching supervised performance in several domains and showing robustness to catastrophic forgetting. The success of STAR emphasizes the potential of refined self-training for robust, efficient, and versatile ASR adaptation in diverse conditions.
Token-Level Quality#
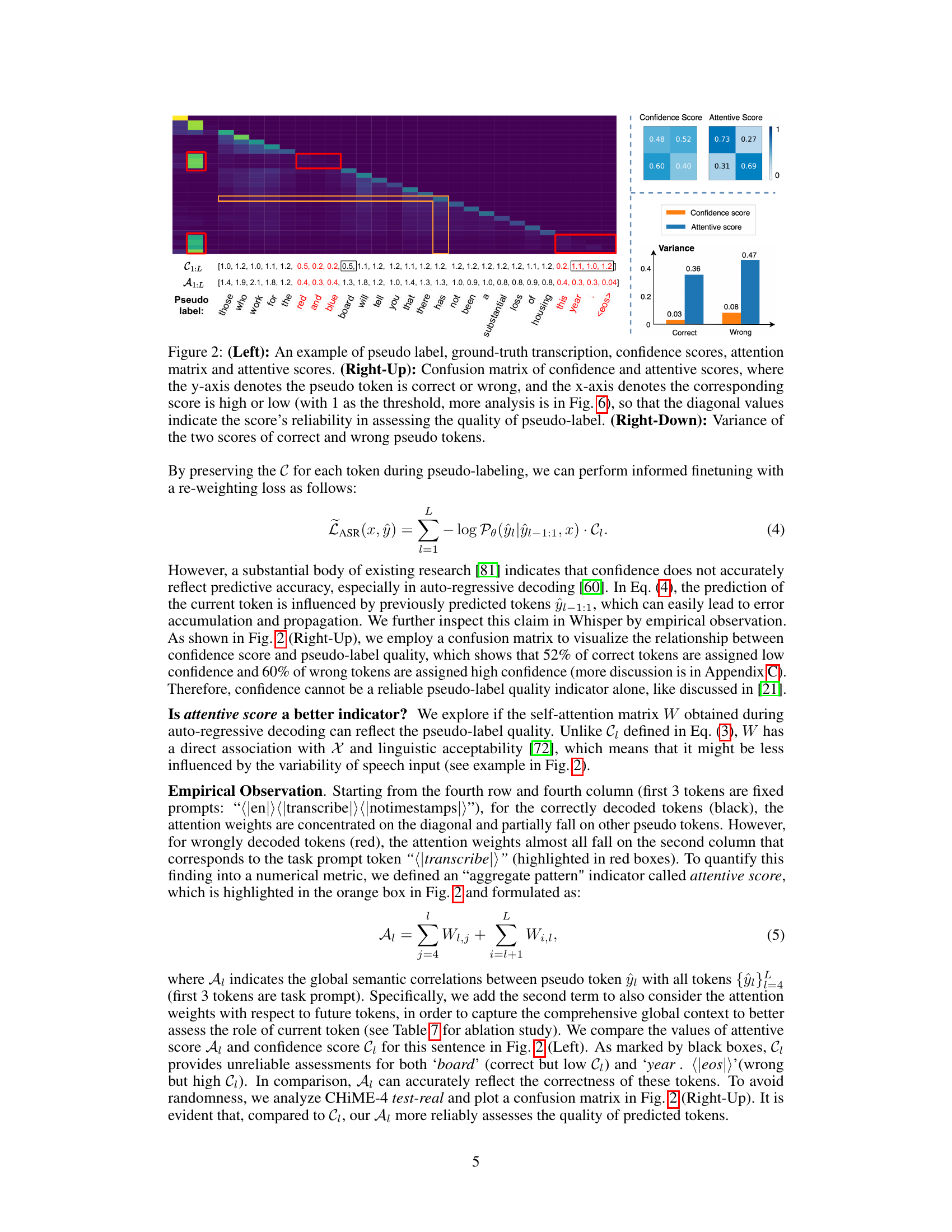
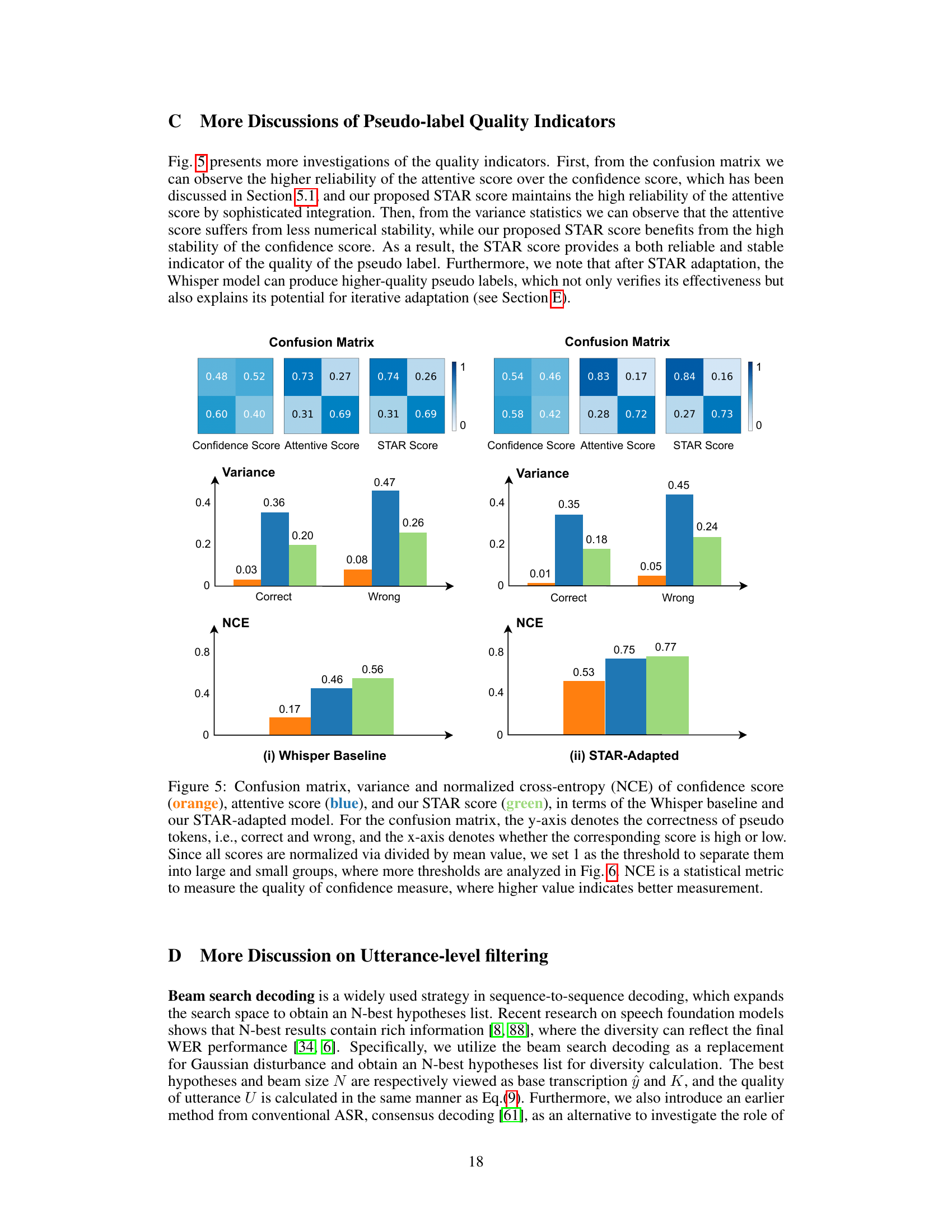
Assessing token-level quality in automatically generated transcriptions is crucial for effective unsupervised domain adaptation in speech recognition. The authors grapple with the unreliability of standard confidence scores, highlighting their overconfidence and susceptibility to error propagation. Their innovative approach leverages self-attention weights, creating an attentive score that better reflects linguistic acceptability and token correctness. However, this attentive score exhibits numerical instability, leading to the development of a composite STAR indicator that combines reliability and stability. This STAR indicator ultimately guides model updates, leading to significant improvements in speech recognition performance across diverse domains. By addressing the limitations of existing methods, the focus on token-level quality is a key contribution to robust and efficient unsupervised adaptation.
Catastrophic Forgetting#
Catastrophic forgetting, the tendency of neural networks to forget previously learned information when adapting to new data, is a significant challenge addressed in the paper. The authors demonstrate that their proposed Self-Taught Recognizer (STAR) method effectively mitigates this issue. This is a particularly important finding in the context of unsupervised domain adaptation (UDA), where the model is trained on unlabeled target data without access to the original training data. STAR’s ability to prevent catastrophic forgetting highlights its robustness and efficiency, enabling seamless adaptation to diverse scenarios without the need for retraining with source data. This is achieved by a novel indicator assessing the quality of pseudo-labels, guiding model updates and preventing the adapted model from losing its knowledge of previously learned features. The results demonstrate that STAR outperforms existing UDA methods in various tasks, highlighting the practical importance of preventing catastrophic forgetting in real-world ASR adaptation.
ASR Model Generality#
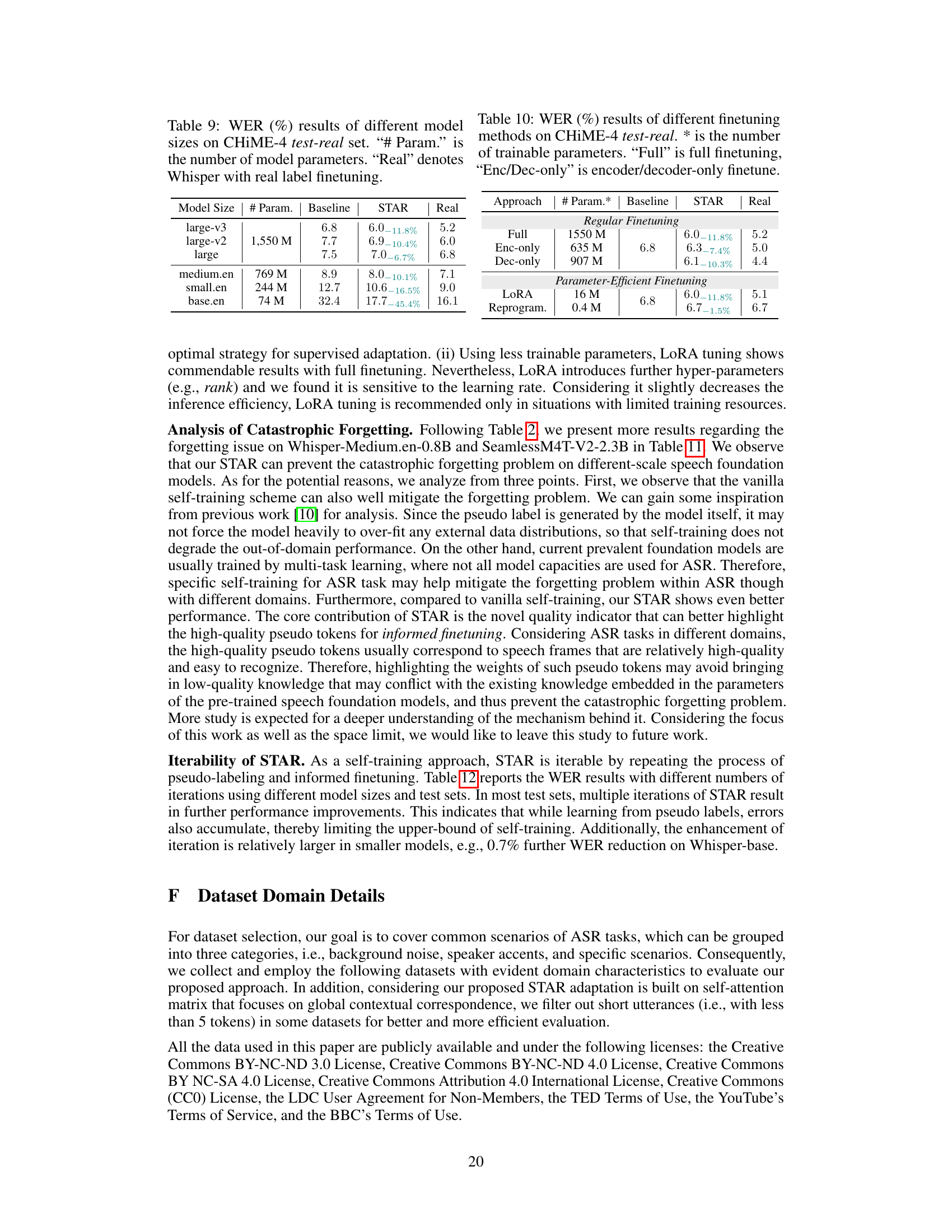
The adaptability of the proposed STAR framework across diverse ASR models is a crucial aspect. The paper demonstrates successful adaptation on various foundation models, including those based on transformer-related architectures, showcasing its versatility and broad applicability. This generalizability is a key strength of STAR, as it implies that the methodology is not model-specific and is likely transferable to future advancements in ASR technology. STAR’s success across models with varying sizes and training data highlights its robustness, indicating that its performance is not heavily reliant on specific architectural details or massive datasets. This speaks to its potential for wide-scale implementation, reducing reliance on specific models and potentially democratizing access to advanced ASR adaptation techniques.
Data Efficiency#
The research demonstrates remarkable data efficiency in adapting speech foundation models. Less than one hour of unlabeled target domain data is sufficient to achieve substantial performance gains. This efficiency is a crucial advantage, drastically reducing the time and cost associated with traditional data collection and annotation processes. The core of this efficiency stems from a novel indicator which precisely assesses pseudo-label quality, guiding model updates effectively. This high data efficiency makes the approach highly practical and scalable, particularly for resource-constrained applications or situations where obtaining large labeled datasets is infeasible. The model’s capacity for effective unsupervised adaptation with minimal data significantly broadens the applicability of speech foundation models.
More visual insights#
More on figures
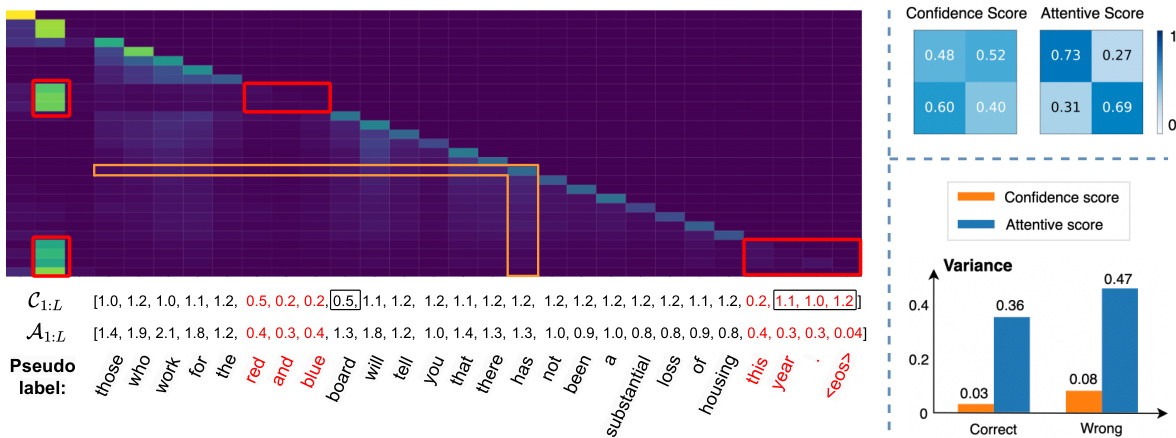
This figure presents a detailed analysis of pseudo-label quality assessment using confidence and attentive scores. The left panel shows an example with pseudo label, ground truth, confidence scores, attention matrix and attentive scores. The top-right panel is a confusion matrix comparing confidence and attentive scores against the correctness of pseudo tokens. The bottom-right panel shows the variance of the two scores for both correct and incorrect pseudo tokens, highlighting the reliability and stability of each score in evaluating pseudo-label quality.

This figure shows the word error rate (WER) achieved by the STAR model on four different datasets (CHiME-4 test-real, Common Voice African, TED-LIUM 3, and ATIS) as a function of the amount of unlabeled training data used. The x-axis represents the number of unlabeled training samples, and the y-axis represents the WER. Each line represents a different dataset. The figure demonstrates the data efficiency of the STAR model; the minimum amount of data needed to achieve the best performance (indicated by a star) is quite small for each dataset, suggesting that STAR can effectively adapt to various domains with limited unlabeled data.

This figure visualizes spectrograms of clean speech and noisy speech with two types of noise: airport and babble. The clean speech shows clear patterns, while the noisy speech shows significant corruption, especially babble noise which masks the speech patterns more completely than airport noise. This visual comparison highlights the distinct acoustic differences between clean and noisy speech domains, which are important factors influencing ASR performance.

This figure demonstrates the difference between confidence scores and attentive scores in evaluating the quality of pseudo labels. The left panel shows an example of a pseudo label, ground truth, confidence scores, the attention matrix and derived attentive scores. The top-right panel provides a confusion matrix visualizing the relationship between confidence and attentive scores and the quality of pseudo labels. The bottom-right panel compares the variance of both scores for correct and incorrect pseudo tokens.

This figure shows a comparison of different metrics for evaluating the quality of pseudo-labels generated by the ASR model. The left panel shows an example of a pseudo-label, the ground truth, confidence scores, attention matrix, and attentive scores for a single utterance. The top-right panel presents a confusion matrix comparing confidence scores and attentive scores to the accuracy of the pseudo-labels (correct/incorrect). The bottom-right panel displays the variance of both scores for correct versus incorrect pseudo-labels. This demonstrates the reliability and stability of the proposed attentive score in assessing pseudo-label quality for guiding model adaptation.

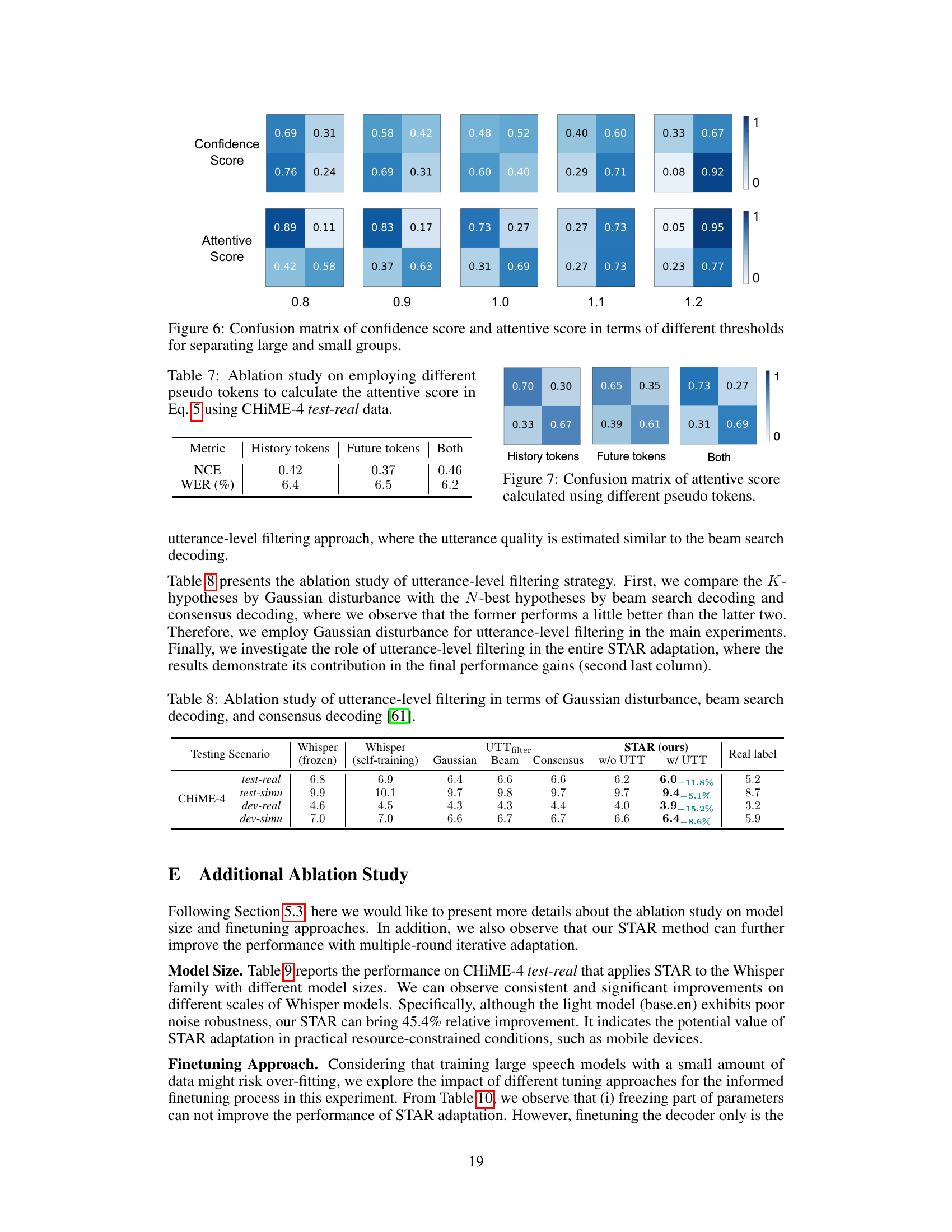
This figure displays three confusion matrices, each showing the performance of confidence scores and attentive scores at different thresholds. Each matrix compares the accuracy of classifying pseudo-labels as either correct or incorrect based on the values of the scores. The three matrices represent different approaches to aggregating the attention weights: using only history tokens, only future tokens, or both history and future tokens. The color intensity represents the proportion of correctly or incorrectly classified tokens. This helps illustrate the relative strengths and weaknesses of each scoring method in assessing the quality of the pseudo-labels for guiding model adaptation.
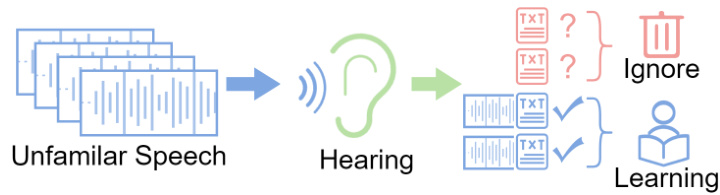
This figure illustrates the difference between unsupervised domain adaptation (UDA) and source-free UDA. The left side shows a typical UDA setting where both labeled source data and unlabeled target data are used to train a model. In contrast, the right side depicts a source-free UDA setting where only unlabeled target data is used. The STAR method is shown as a way to select high-quality pseudo-labels and guide model adaptation at the token level in a source-free setting.
More on tables

This table presents the Word Error Rate (WER) results of the STAR model and baselines. The ‘Frozen’ column shows the performance of the Whisper model without any adaptation. The ‘Self-train.’ column represents the performance of the vanilla self-training approach. The ‘STAR’ column shows the performance of the proposed STAR model after adapting to the CHIME-4 dataset. The table demonstrates that STAR effectively prevents catastrophic forgetting, maintaining good performance on unseen domains after finetuning on CHIME-4. The results are shown for multiple datasets representing various noise and accent conditions.
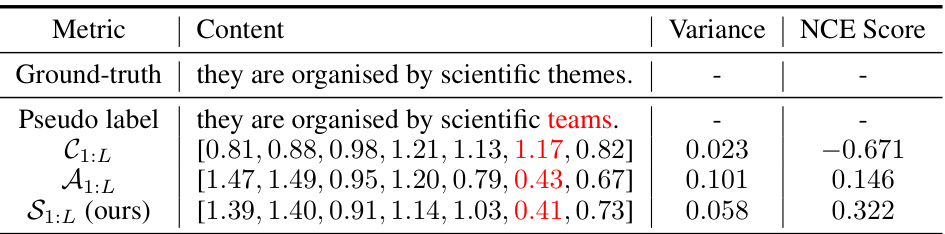
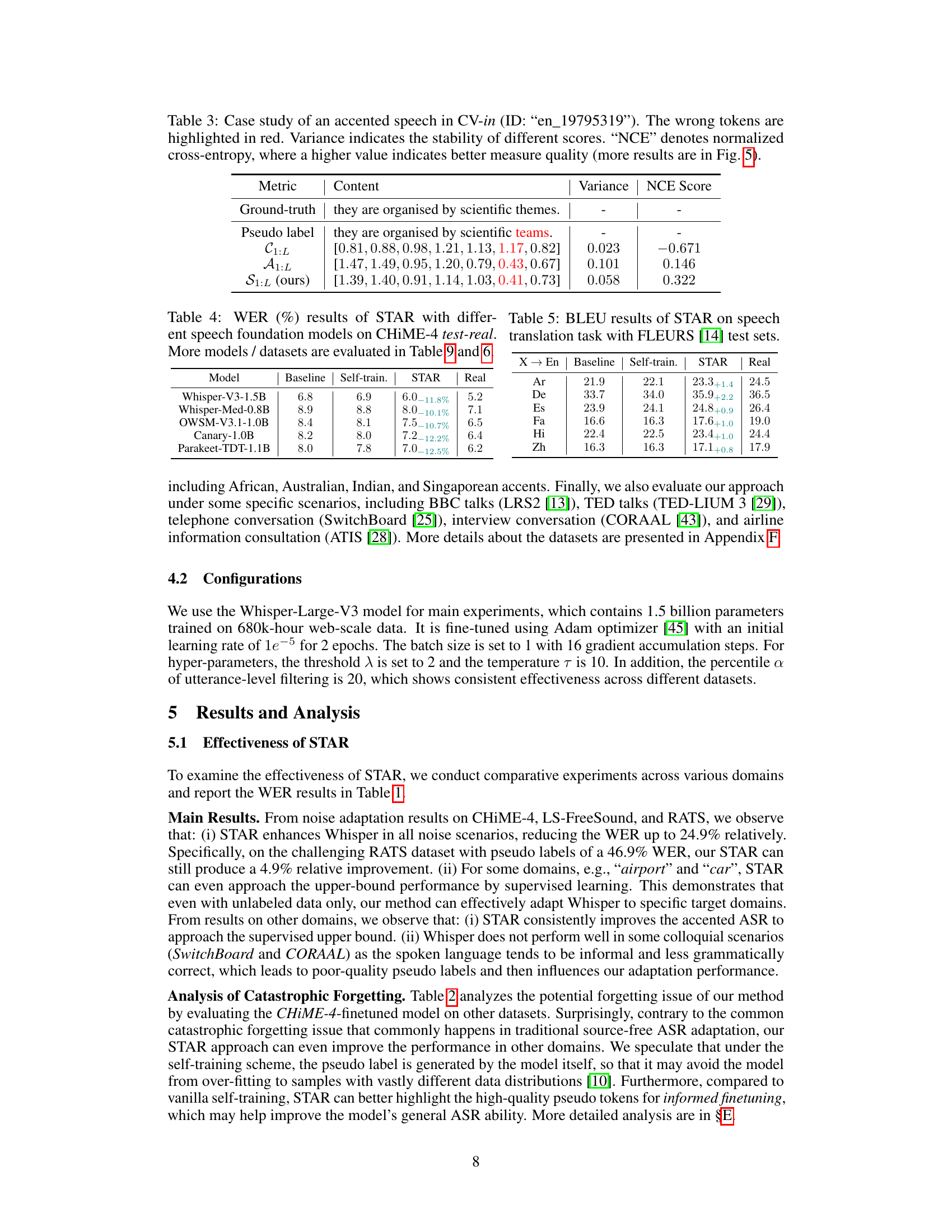
This table shows a case study of an accented speech using the Common Voice dataset. It compares the ground truth transcription with the pseudo labels generated by the model, also providing confidence scores, attentive scores, and STAR scores. The variance and normalized cross-entropy (NCE) scores are also included to assess the quality of these indicators. The wrong tokens are highlighted in red.

This table presents the BLEU scores achieved by the STAR method on speech translation tasks, using the FLEURS benchmark. It compares the performance of STAR against baseline methods, self-training, and the performance achieved using real labels (ground truth). The results show improvements across multiple language pairs after using STAR for adaptation, demonstrating its applicability to speech translation in addition to speech recognition.

This table presents the Word Error Rate (WER) results of the STAR adaptation method using the SeamlessM4T-Large-V2 speech foundation model on the CHiME-4 test sets. It compares the performance of the STAR method against a baseline, a self-training approach, and supervised learning using real labels. The results are broken down by different test set scenarios (test-real, test-simu, dev-real, dev-simu), showing the relative WER reduction achieved by STAR in each condition.

This table presents the results of an ablation study conducted to evaluate the impact of different sets of pseudo tokens on the calculation of the attentive score (Eq. 5). The study uses the CHiME-4 test-real dataset. Three different methods for selecting tokens are compared: using only history tokens, using only future tokens, and using both history and future tokens. The table shows the impact of this variation on two metrics: Normalized Cross-Entropy (NCE) and Word Error Rate (WER). The results indicate which combination of pseudo tokens leads to the most effective attentive score.

This table presents the Word Error Rate (WER) comparison of different methods for adapting the Whisper ASR model to various domains (noise, accents, scenarios). It compares the zero-shot performance of the model, a baseline self-training approach, the proposed STAR method with and without utterance-level filtering and token re-weighting, and finally the supervised learning performance (upper bound). The WER reduction achieved by STAR is also shown.

This table presents the Word Error Rate (WER) results for different ASR adaptation methods on various datasets. It compares the performance of the proposed STAR method against baselines including a frozen Whisper model (zero-shot), self-training with and without utterance and token-level filtering, and finally supervised training (using real labels). The table shows the WER for different noise conditions, accents, and specific scenarios, allowing a comprehensive comparison of STAR’s effectiveness across diverse domains.

This table compares the performance of different finetuning approaches (full, encoder-only, decoder-only, LoRA, and reprogramming) on the CHiME-4 test-real dataset. It shows the Word Error Rate (WER), the number of trainable parameters for each approach, and the relative WER reduction achieved by the STAR method compared to the baseline.
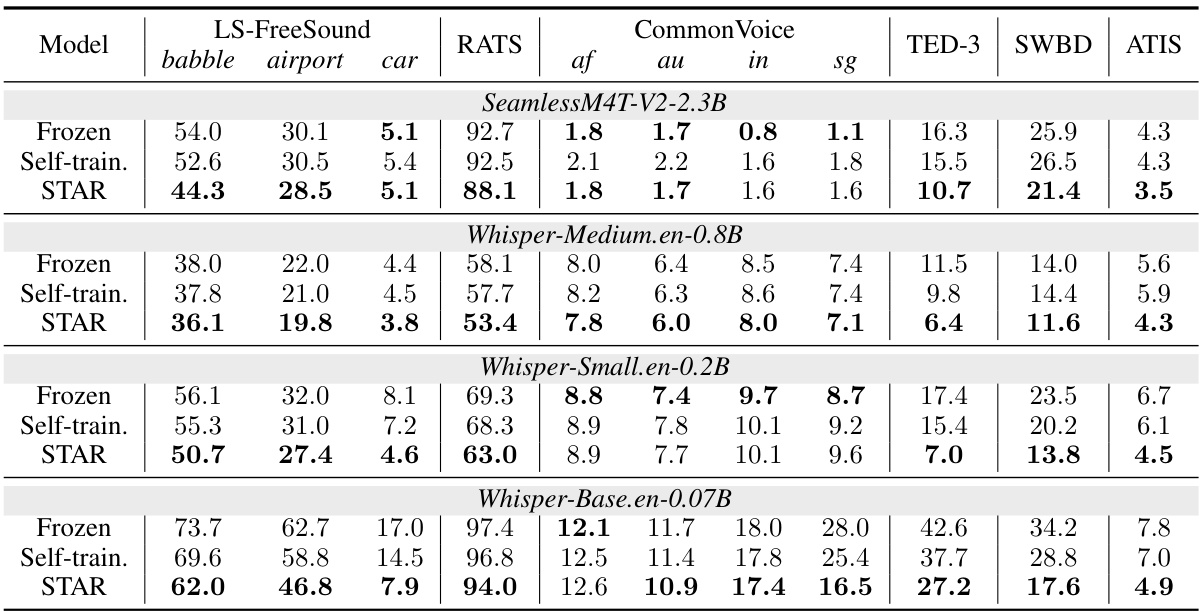
This table presents the Word Error Rate (WER) results for different ASR models (Whisper with different configurations and other models) across various scenarios (background noise, speaker accents, specific scenarios). It compares the performance of the proposed STAR method with baselines like zero-shot, self-training, and supervised learning, highlighting STAR’s effectiveness in unsupervised domain adaptation.

This table presents the Word Error Rate (WER) for different ASR models (Whisper with various modifications and a real label baseline) across a range of testing scenarios (background noise, speaker accents, and specific situations). It compares the performance of the proposed STAR method with other baselines, highlighting the relative WER reduction achieved by STAR and illustrating its effectiveness in various conditions.
Full paper#