↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for protecting images generated by customized diffusion models are largely “prompt-specific”, meaning they only work well against attacks using the same prompts they were trained on. This limits their real-world applicability. Malicious actors could easily bypass these defenses by using slightly different prompts. This poses a significant risk, especially for personal photos or artistic works.
This paper introduces Prompt-Agnostic Adversarial Perturbation (PAP), a new defense method that addresses this limitation. PAP models the distribution of possible prompts and generates perturbations that are effective against a wider range of prompts. The results of extensive experiments show that PAP significantly outperforms existing methods in protecting against image manipulation. This robust and generalizable approach is a significant advancement in the field of image security and generative AI.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on diffusion models and image security. It addresses a critical vulnerability by developing a novel, prompt-agnostic defense mechanism against malicious image manipulation. The generalizability and effectiveness of the proposed method opens new avenues for research in improving the robustness and safety of generative AI systems, impacting the development of secure and responsible AI applications. The study’s extensive experimentation and open-source code further enhance its value and impact within the research community.
Visual Insights#
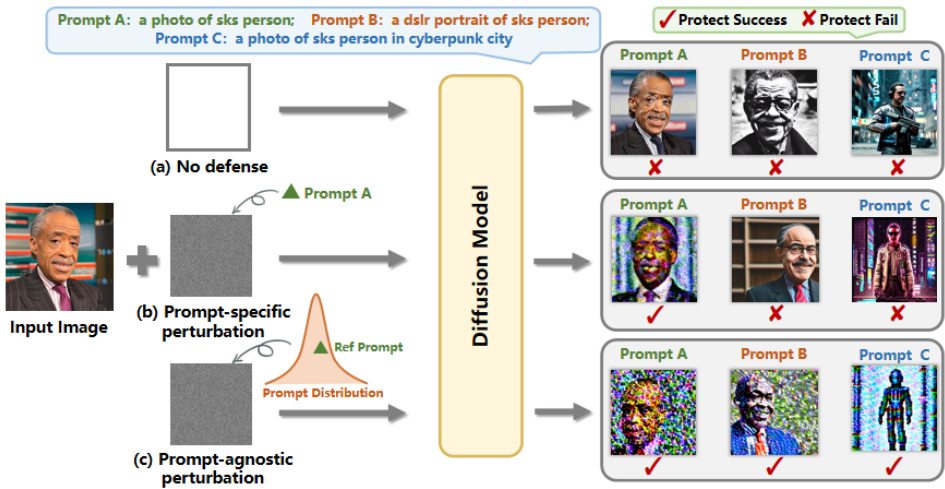
This figure illustrates the effectiveness of the proposed PAP (Prompt-Agnostic Perturbation) method compared to methods without defense and prompt-specific methods. It shows three scenarios: (a) a portrait without any defense, which is easily modified by the diffusion model; (b) a portrait protected using a prompt-specific perturbation, which is only effective against the specific prompt it was trained on (Prompt A); and (c) a portrait protected with the PAP method, which effectively protects the portrait from modification regardless of the prompt used (Prompts A, B, and C). The PAP method achieves this robustness by modeling the prompt distribution, instead of relying on pre-defined prompts.
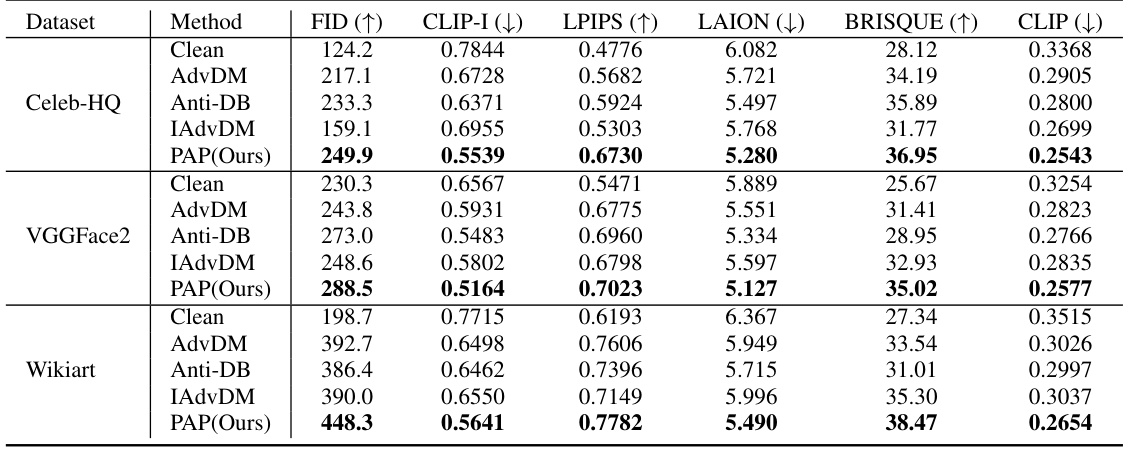
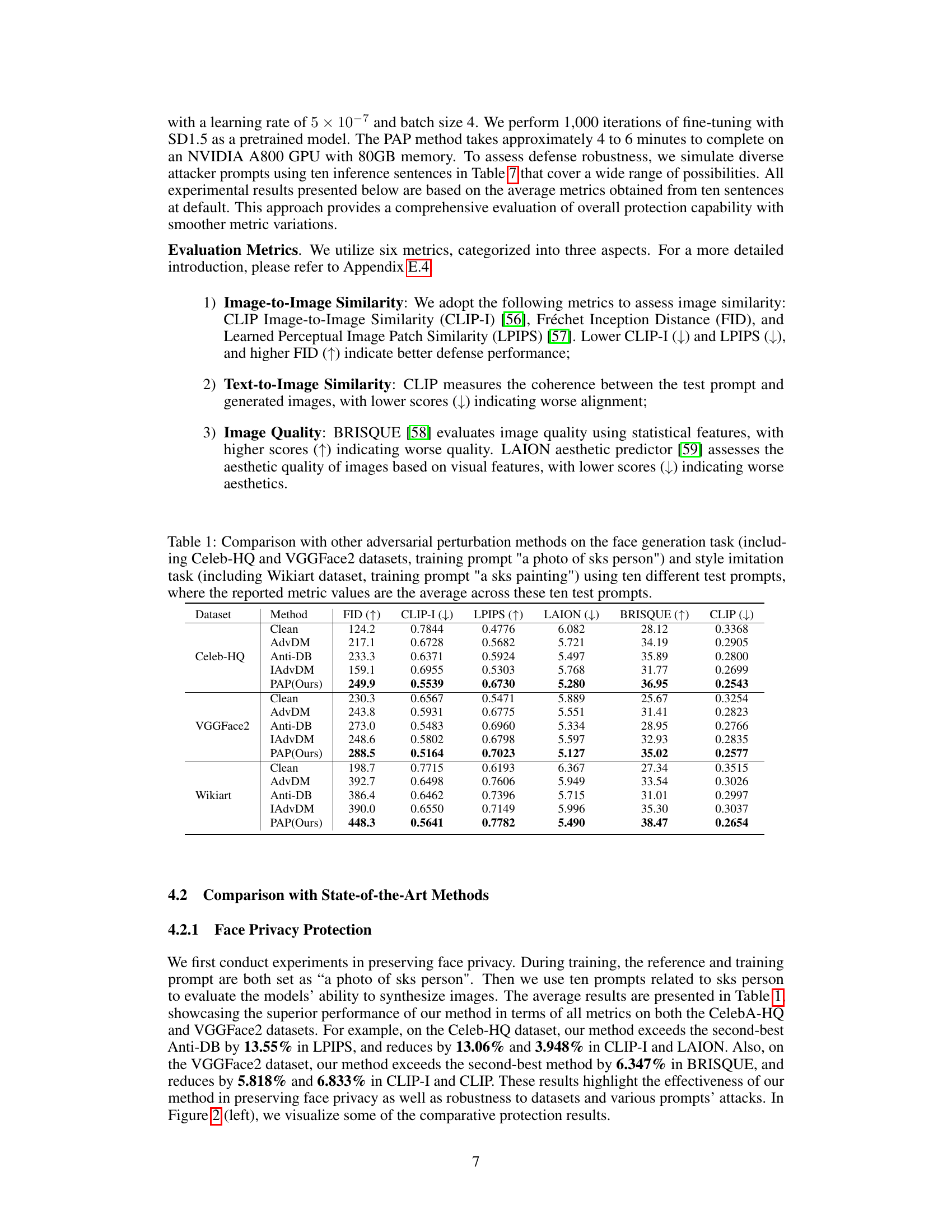
This table presents a comparison of different adversarial perturbation methods (AdvDM, Anti-DB, IAdvDM, and PAP) on three datasets (Celeb-HQ, VGGFace2, and Wikiart) for face generation and style imitation tasks. For each dataset and method, the table shows the average values across ten different test prompts for six metrics: FID, CLIP-I, LPIPS, LAION, BRISQUE, and CLIP. Higher FID and BRISQUE values indicate worse performance, while lower values for the remaining metrics indicate better performance. This table highlights the performance of the proposed PAP method relative to existing methods.
In-depth insights#
Prompt Agnostic Defense#
Prompt-agnostic defense in the context of diffusion models addresses a crucial vulnerability. Traditional methods often focus on defending against specific prompts used during training, leaving the model susceptible to attacks using unseen or unexpected prompts. A truly robust defense must be prompt-agnostic, meaning it protects against a wide range of prompts without needing prior knowledge of the attacker’s specific input. This requires understanding and modeling the underlying distribution of prompts to anticipate attacks. Modeling the distribution allows for a more generalizable and resilient defense strategy, as opposed to individually defending against each possible prompt. A key challenge is to devise methods for calculating these prompt distributions, and techniques like Laplace approximation can be valuable tools in this process. Improving generalizability is key here, as it allows the defense to adapt to new or unexpected attacks rather than relying on a finite set of known prompts. The efficacy of such a system hinges on its ability to generate perturbations that effectively mask or obfuscate sensitive information within images. Evaluating performance also requires careful selection of metrics that account for both the effectiveness of the defense and the overall quality of the generated images.
Laplace Approximation#
The Laplace approximation, in the context of this research paper, is a crucial technique for efficiently modeling the distribution of prompts in a high-dimensional space. Instead of directly dealing with the complex, potentially intractable true distribution, it offers a computationally feasible method for approximating it using a simpler Gaussian distribution. This is achieved by performing a second-order Taylor expansion around the mode (peak) of the true distribution, effectively capturing the local curvature using the Hessian matrix. The Gaussian approximation significantly simplifies subsequent calculations, such as generating prompt-agnostic perturbations, by utilizing the known properties of Gaussian distributions. However, it is vital to acknowledge the limitations of this approximation, as the accuracy relies heavily on the true distribution’s smoothness and concentration around its mode. Approximation errors are also inherent; thus, the researchers carefully consider these and provide analysis. The use of Laplace approximation for prompt distribution modeling represents a key methodological contribution, enabling the creation of a robust and efficient defense mechanism against adversarial attacks on diffusion models.
PAP Generalization#
Prompt-Agnostic Adversarial Perturbation (PAP) demonstrates strong generalization capabilities. Unlike prompt-specific methods, which struggle when encountering unseen prompts, PAP’s robustness stems from its modeling of the underlying prompt distribution. This allows it to generate perturbations effective against a wide range of prompts, including those not seen during training. The Laplace approximation employed in PAP effectively captures the prompt distribution, enhancing its generalizability. Extensive experiments across face privacy and artistic style protection tasks showcase its superior performance against other methods, highlighting its practical applicability and improved defense stability. This prompt-agnostic approach is a key advancement, addressing the limitations of previous methods and demonstrating PAP’s potential for broader applications in securing generative AI models.
Diffusion Model Attacks#
Diffusion models, while revolutionary for image generation, introduce vulnerabilities. Attacks on these models exploit their generative nature to produce undesirable outputs, including generating fake images of individuals (deepfakes) or replicating copyrighted art. These attacks often leverage the model’s sensitivity to input prompts, introducing carefully crafted adversarial prompts to elicit malicious results. Defense strategies are crucial, focusing on techniques like adversarial training or adding imperceptible perturbations to images to disrupt the generation process. A critical area of research is developing prompt-agnostic defenses, protecting against a broader range of attacks beyond those seen during training. This is crucial for enhancing the robustness and security of diffusion models in real-world applications.
Future Work: Semantics#
The section on “Future Work: Semantics” in this research paper would ideally delve into the limitations of using a continuous Gaussian distribution to model prompt semantics. The authors should acknowledge that sampling from this distribution may not always yield semantically coherent prompts, potentially impacting the robustness of the proposed method. Future research should explore alternative approaches to prompt modeling, such as incorporating discrete semantic spaces or leveraging techniques that ensure the sampled prompts are both semantically meaningful and sufficiently close to the mean of the distribution. This could involve methods that explicitly constrain the sampled prompts to remain within a region of high semantic coherence or using techniques like dimensionality reduction to identify the most informative aspects of the prompt space. Investigating the impact of different prompt representation techniques, such as word embeddings or other vector representations, on the performance and robustness of the proposed prompt-agnostic perturbation would be valuable. Finally, a discussion on how to effectively incorporate prior knowledge about the prompt distribution and its relation to the underlying image content in the prompt modeling process would significantly strengthen the paper. Developing a more rigorous and practical approach to prompt distribution modeling is crucial for advancing the field of prompt-agnostic adversarial perturbation.
More visual insights#
More on figures

This figure presents a qualitative comparison of different adversarial perturbation methods for protecting images from tampering by diffusion models. The left side shows results on the VGGFace2 dataset (faces), while the right side shows results on the Wikiart dataset (paintings). Each row represents a different method: Clean (no defense), AdvDM, Anti-DreamBooth, IAdvDM, and PAP (the proposed method). Each column shows the results for a different test prompt. The figure demonstrates that the proposed PAP method is robust to unseen prompts, unlike the other methods which perform poorly on prompts different from the one they were trained on.

This figure illustrates the effectiveness of the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method in protecting images from diffusion model tampering. It compares three scenarios: (a) no defense, where the portrait is easily modified; (b) prompt-specific perturbation, which only works well on the prompts it was trained on; and (c) PAP, which successfully defends against both seen and unseen prompts.
This figure compares three different scenarios of protecting a portrait from being manipulated by a diffusion model. (a) shows a portrait without any defense, which is easily modified. (b) shows a portrait protected using a prompt-specific method. This method is effective only for prompts it was trained on, failing to protect against unseen prompts. (c) shows the proposed prompt-agnostic adversarial perturbation (PAP) method, which is robust to both seen and unseen prompts, successfully protecting the portrait.

This figure illustrates the difference between no defense, prompt-specific perturbation, and the proposed prompt-agnostic adversarial perturbation (PAP) method for protecting images from tampering using diffusion models. It shows how easily a portrait can be modified without any defense (a), how prompt-specific methods fail to generalize to unseen prompts (b), and how PAP successfully protects the portrait against both seen and unseen prompts (c).

This figure illustrates the effectiveness of the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method compared to methods without defense and prompt-specific perturbation methods. It shows how easily a portrait can be modified using a diffusion model without any defense (a). It demonstrates that prompt-specific methods only work well for prompts they were trained on (b), failing when encountering unseen prompts. Finally, it highlights that PAP successfully protects the portrait from tampering, even with unseen prompts (c), showcasing its robustness and generalizability.

This figure illustrates the effectiveness of the proposed PAP method by comparing it against other methods. The leftmost image shows a portrait that can easily be manipulated without any defense. The middle image demonstrates that prompt-specific methods only work well for seen prompts but fail for unseen ones. Finally, the rightmost image shows that the proposed PAP is effective for both seen and unseen prompts, protecting the portrait from tampering.

This figure illustrates the effectiveness of the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method in protecting portraits from tampering by diffusion models. It compares three scenarios: (a) No defense: A portrait is easily modified by the diffusion model using different prompts. (b) Prompt-specific perturbation: A perturbation is generated to protect against a specific prompt (Prompt A). However, it is ineffective against unseen prompts (Prompt B and C). (c) PAP: The proposed prompt-agnostic perturbation is effective against both seen and unseen prompts, demonstrating robustness and generalization.

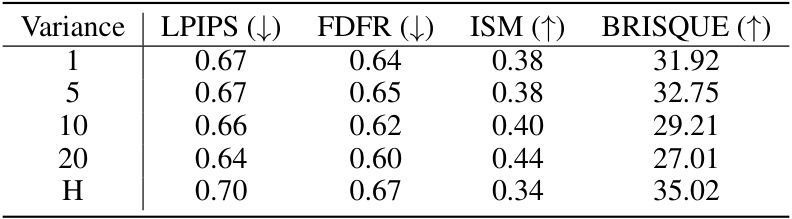
This figure shows the results of applying the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method to protect images on VGGFace2 dataset. The top row displays the original ‘clean’ images. The subsequent rows demonstrate the adversarial examples generated by PAP with varying noise budgets (0.01, 0.03, 0.05, 0.10, 0.15). The noise budget is a hyperparameter controlling the strength of the perturbation. A higher noise budget generally leads to stronger protection (making the image less recognizable) but also more visible distortion.

This figure illustrates the effectiveness of the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method in protecting images from diffusion model tampering. It compares three scenarios: (a) no defense, where the image is easily modified; (b) prompt-specific perturbation, which only works well for prompts seen during training; and (c) the proposed PAP method, which is robust to both seen and unseen prompts, demonstrating improved defense stability.

This figure compares the performance of different methods (Clean, AdvDM, Anti-DB, IAdvDM, and PAP) in protecting images from being manipulated by a diffusion model. The left side shows the results for face images (VGGFace2 dataset), while the right side shows the results for paintings (Wikiart dataset). Each method is tested against various prompts, including unseen ones. The results demonstrate that PAP is the most robust method, effectively protecting images against manipulation regardless of the prompt used. Other methods struggle when the prompt changes to one that wasn’t used during training.

This figure illustrates the effectiveness of the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method in protecting images from being manipulated by diffusion models. It compares three scenarios: (a) no defense, where the image is easily tampered with; (b) prompt-specific perturbation, where the defense only works for specific prompts it has been trained on; and (c) PAP, which is robust to both seen and unseen prompts, effectively protecting the image from tampering.

The figure illustrates the effectiveness of the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method compared to methods without defense and prompt-specific methods. It shows how easily a portrait can be manipulated by a diffusion model without any defense (a). It then demonstrates the limitations of prompt-specific methods which only work well for prompts seen during training (b). Finally, it showcases the robustness of PAP, which effectively protects the portrait even against unseen prompts (c).

This figure shows a comparison of the results obtained using the Anti-DreamBooth (Anti-DB) method and the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method. The top row uses CelebA-HQ dataset with the training prompt ‘a photo of sks person’, and the bottom row uses Wikiart dataset with the training prompt ‘a sks painting’. For each dataset, the figure shows the original image, adversarial examples generated using the Anti-DB method, and adversarial examples generated by PAP under different test prompts. The results demonstrate that PAP is more robust to unseen prompts than the Anti-DB method, which shows inferior performance for test prompts other than the training prompt.

This figure compares three scenarios: (a) a portrait without any defense, easily modified by the diffusion model; (b) a portrait protected using a prompt-specific method that only works well on the training prompt (Prompt A), failing to protect against unseen prompts (Prompts B and C); (c) a portrait protected using the proposed PAP method, which remains robust against both seen and unseen prompts.
More on tables

This table presents a comparison of the proposed PAP method against several other state-of-the-art adversarial perturbation methods. The comparison is done across three different datasets (Celeb-HQ, VGGFace2, and WikiArt) and two different tasks (face generation and style imitation). For each dataset and task, the table shows the performance of each method on six different metrics: FID, CLIP-I, LPIPS, LAION, BRISQUE, and CLIP. Ten different test prompts were used, and the table reports the average metric scores across those prompts.

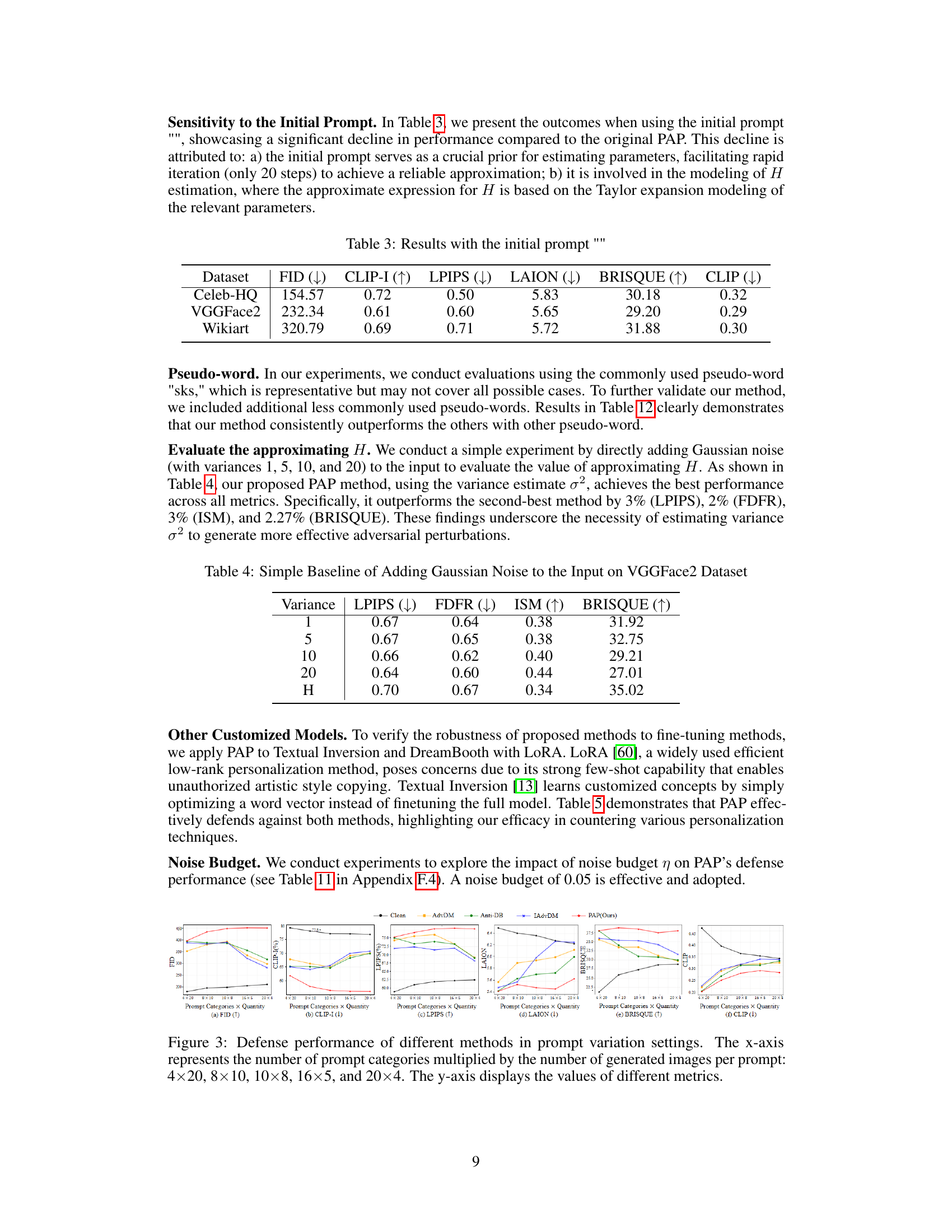
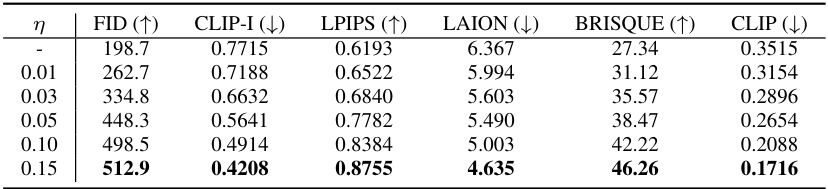
This table presents the results obtained when using an empty string as the initial prompt. It highlights the decline in performance compared to the original PAP results, demonstrating the importance of the initial prompt in the parameter estimation and Hessian approximation.
This table compares the performance of the proposed PAP method against existing methods (AdvDM, Anti-DB, IAdvDM) across three datasets (Celeb-HQ, VGGFace2, Wikiart) and two tasks (face generation and style imitation). It evaluates the methods using six metrics: FID, CLIP-I, LPIPS, LAION, BRISQUE, and CLIP. The results shown are the average of the results from ten different test prompts to evaluate robustness to unseen prompts.

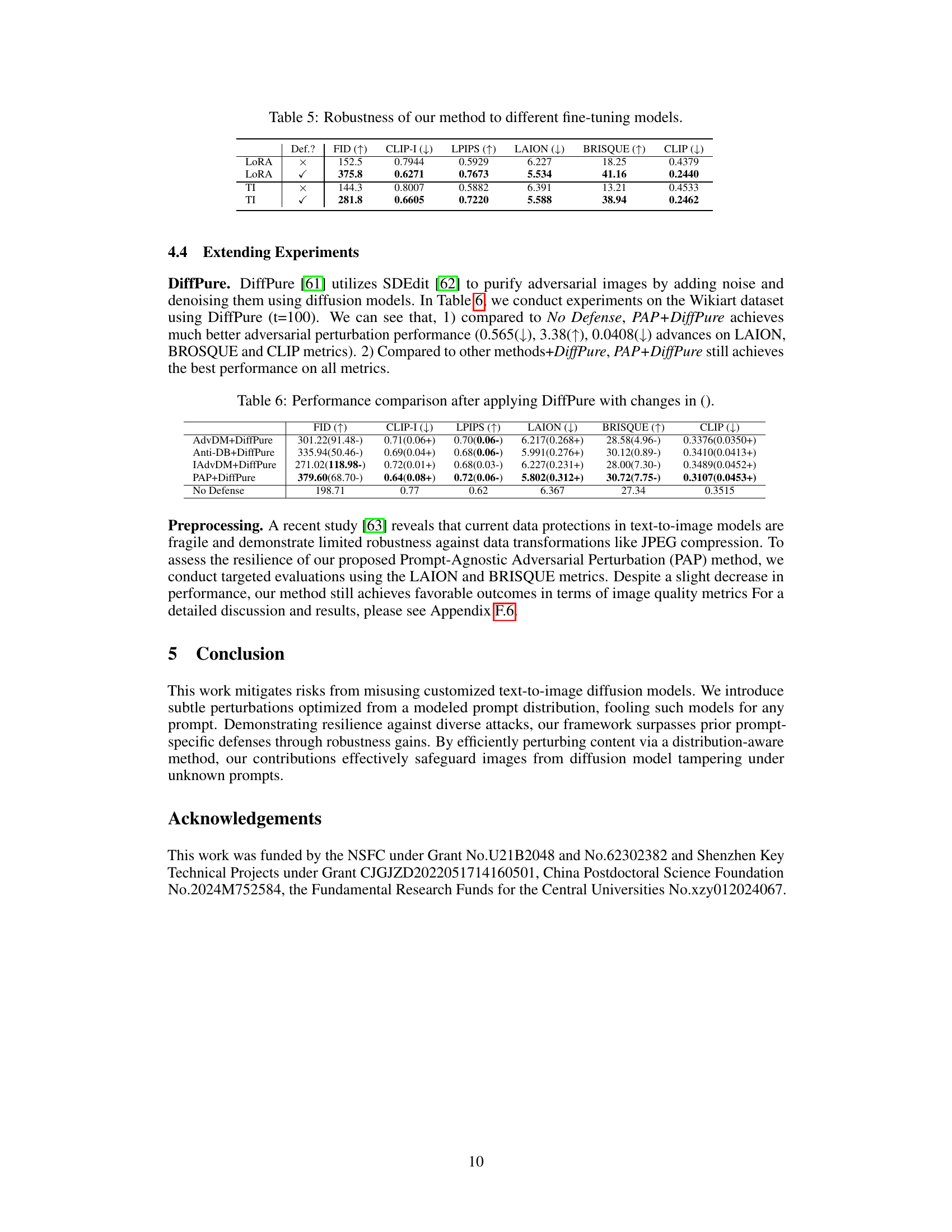
This table presents the results of applying the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method to different fine-tuning models, namely LoRA and Textual Inversion (TI). It demonstrates the robustness of PAP across various customization techniques. The table shows that the PAP method is effective in protecting images even when the underlying model is fine-tuned using these methods. For each model and configuration (with and without PAP), the table reports six metrics: FID (Fréchet Inception Distance), CLIP-I (CLIP Image-to-Image Similarity), LPIPS (Learned Perceptual Image Patch Similarity), LAION (LAION aesthetic predictor), BRISQUE (BRISQUE image quality assessor), and CLIP (CLIP text-to-image similarity). Higher FID, LPIPS, and BRISQUE scores indicate better protection, while lower CLIP-I, LAION, and CLIP scores suggest better defense performance.

This table compares the performance of the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method against other state-of-the-art methods for protecting images from adversarial attacks. The comparison is done across three datasets (Celeb-HQ, VGGFace2, and WikiArt) and includes six evaluation metrics that assess image similarity, text-image coherence, and image quality. Ten different test prompts were used to evaluate the robustness of each method.

This table presents a comparison of the proposed PAP method against other state-of-the-art adversarial perturbation methods (AdvDM, Anti-DB, IAdvDM). The comparison is performed across three different datasets (Celeb-HQ, VGGFace2, Wikiart) and for both face generation and style imitation tasks. Ten different test prompts were used for each dataset and the results represent the average across these prompts. The metrics used for comparison include FID, CLIP-I, LPIPS, LAION, BRISQUE, and CLIP, providing a comprehensive evaluation of performance across image quality, similarity to the original images, and alignment with the provided prompts.

This table compares the performance of the proposed PAP method against existing adversarial perturbation methods (AdvDM, Anti-DB, and IAdvDM) across three datasets (Celeb-HQ, VGGFace2, and Wikiart) and using ten different test prompts. The metrics used are FID, CLIP-I, LPIPS, LAION, BRISQUE, and CLIP. Higher FID and BRISQUE values indicate worse performance, while lower values are better for the rest of the metrics. The results demonstrate the superior performance of PAP in terms of defense stability and generalization to unseen prompts.

This table compares the performance of the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method against several state-of-the-art methods for protecting images from adversarial attacks. The comparison is done across three datasets (Celeb-HQ, VGGFace2, and WikiArt) and two task types (face privacy protection and artistic style protection). Multiple metrics are used to evaluate the effectiveness of each method, including FID, CLIP-I, LPIPS, LAION, BRISQUE, and CLIP. The results show that PAP consistently outperforms the other methods across all datasets and metrics.

This table presents a comparison of the proposed PAP method with other state-of-the-art adversarial perturbation methods. The comparison is done on three different datasets (Celeb-HQ, VGGFace2, and Wikiart) and across ten different test prompts. The metrics used for comparison include FID, CLIP-I, LPIPS, LAION, BRISQUE, and CLIP. The results show that the PAP method outperforms other methods in most cases, demonstrating its effectiveness in protecting images from adversarial attacks.
This table compares the performance of the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method against existing methods (AdvDM, Anti-DreamBooth, and IAdvDM) across three datasets: Celeb-HQ, VGGFace2, and WikiArt. For each dataset and method, six metrics are reported: FID, CLIP-I, LPIPS, LAION, BRISQUE, and CLIP. These metrics assess image-to-image similarity, text-to-image similarity, and image quality. The results show the average performance across ten different test prompts.
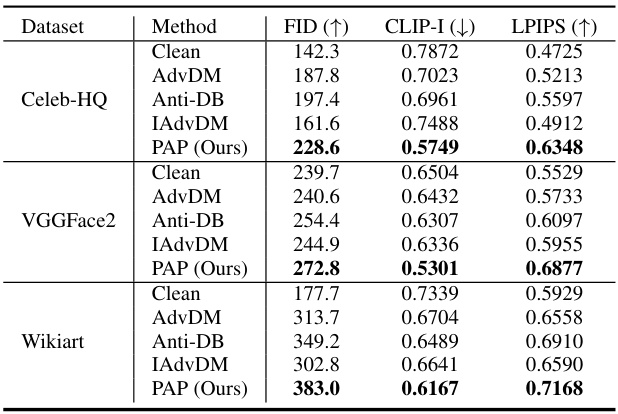
This table compares the performance of the proposed PAP method against three other state-of-the-art adversarial perturbation methods (AdvDM, Anti-DB, and IAdvDM) across three different datasets (Celeb-HQ, VGGFace2, and Wikiart). The results are averaged over ten different test prompts for each method and dataset. Metrics include FID (higher is better), CLIP-I (lower is better), LPIPS (lower is better), LAION (lower is better), BRISQUE (higher is better), and CLIP (lower is better), assessing image and text similarity, and overall image quality.
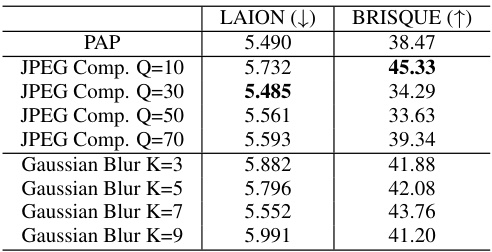
This table compares the performance of the proposed PAP method against other state-of-the-art adversarial perturbation methods (AdvDM, Anti-DB, IAdvDM) on three datasets (Celeb-HQ, VGGFace2, WikiArt). The comparison is performed across six metrics measuring image and text-image similarity, image quality, and visual aesthetics. Each dataset uses a different task (face generation or style imitation), and results are averaged across ten different test prompts to assess the generalization capability of each method. The ‘Clean’ row represents the baseline performance without any adversarial perturbation.

This table presents the results of the experiment when using the initial prompt ‘’. It compares the performance of the model with different metrics (FID, CLIP-I, LPIPS, LAION, BRISQUE, CLIP) when using the initial prompt ’’ against using the original prompt. The results show that using the initial prompt results in a significant decline in performance compared to the original PAP.

This table presents a comparison of the proposed PAP method with several other state-of-the-art adversarial perturbation methods. The comparison is done across three different datasets (Celeb-HQ, VGGFace2, and Wikiart) and two different tasks (face generation and style imitation). For each dataset and task, the table shows the average performance across ten different test prompts for several metrics evaluating image similarity, text-image similarity, and image quality. This allows for a comprehensive comparison of the methods under various conditions and provides insights into the robustness and generalization capabilities of each approach.

This table compares the performance of the proposed Prompt-Agnostic Adversarial Perturbation (PAP) method against several other state-of-the-art methods for protecting images from adversarial attacks. The comparison is done across three datasets (Celeb-HQ, VGGFace2, and Wikiart) and six metrics (FID, CLIP-I, LPIPS, LAION, BRISQUE, and CLIP). The results show the average performance across 10 different test prompts for each method. This provides a comprehensive evaluation of the methods’ robustness to various prompts and datasets.
Full paper#