↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Dataset distillation aims to create smaller, efficient training datasets while maintaining model performance. Existing methods focus on complex synthetic data generation, but their effectiveness remains unclear, largely due to the lack of common principles among them. This paper investigates this issue by focusing on the role of labels and its quality.
The research employs a series of ablation experiments and a simple baseline of randomly sampled images with soft labels. Surprisingly, this simple approach achieves performance comparable to state-of-the-art methods. The paper identifies soft labels as the crucial factor, revealing that labels with structured information are much more beneficial than labels that just contain probabilistic information. Moreover, the research provides empirical scaling laws and a Pareto frontier, outlining the optimal trade-off between data quantity and label informativeness for maximizing learning efficiency. This work fundamentally alters our understanding of dataset distillation, suggesting the need to focus more on label quality and less on complex synthetic data generation.
Key Takeaways#
Why does it matter?#
This paper challenges the conventional wisdom in dataset distillation by demonstrating that soft labels, not synthetic data generation, are the key to success. This has major implications for research and development efforts, potentially saving significant computational resources. The empirical scaling laws and Pareto frontier provided are crucial for optimizing data-efficient learning, and the study also suggests new directions for improving distillation methods.
Visual Insights#
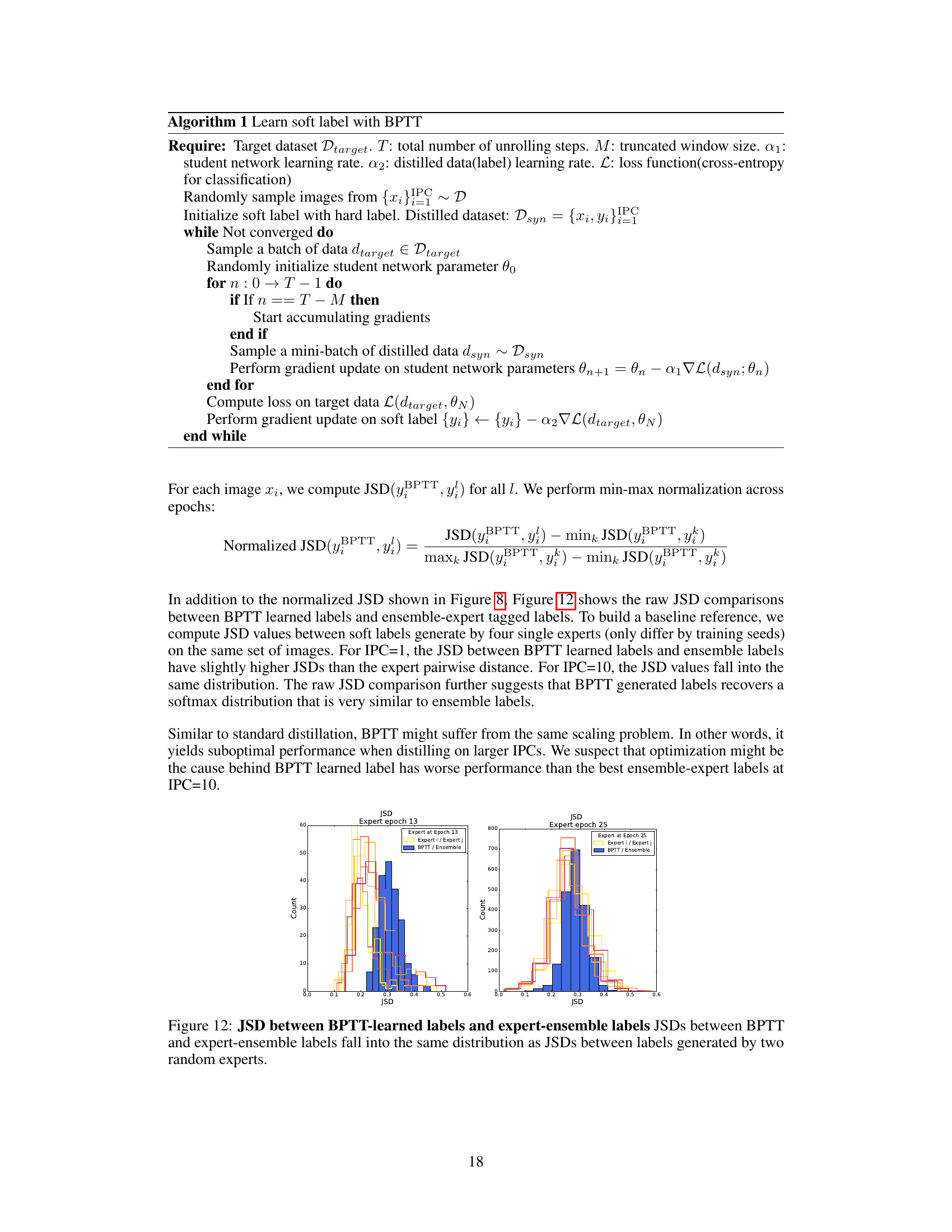
The figure on the left shows example synthetic images generated by different dataset distillation methods. The figure on the right is a graph comparing the student test accuracy of different distillation methods (using both soft and hard labels) against a random baseline using training data with hard labels. The graph shows that soft labels are crucial for the success of dataset distillation.

This table benchmarks several state-of-the-art (SOTA) dataset distillation methods against two baselines: a CutMix augmented soft labels baseline and a simpler soft label baseline. The SOTA methods and the baselines are evaluated on the ImageNet-1K dataset using different numbers of images per class (IPC). The results demonstrate that the soft label baselines, which use randomly selected training images and soft labels generated by a pre-trained model, can achieve comparable performance to the more complex SOTA methods, especially as the IPC increases. This challenges the conventional wisdom that sophisticated synthetic data generation is crucial for dataset distillation.
In-depth insights#
Soft Labels’ Power#
The concept of “Soft Labels’ Power” in dataset distillation centers on the surprising effectiveness of probabilistic labels (soft labels) compared to traditional hard labels. Soft labels, representing a probability distribution over classes rather than a single definitive label, provide a richer signal during training. This richness allows for a more nuanced understanding of the data’s underlying structure, improving learning efficiency even with limited data. The power of soft labels stems from their ability to encode semantic relationships between classes and capture uncertainty. This is particularly crucial in data-efficient settings, such as dataset distillation, where preserving essential information while reducing data size is paramount. The research highlights that the success of many state-of-the-art dataset distillation methods isn’t solely due to sophisticated synthetic data generation techniques, but rather the incorporation of soft labels. Moreover, not all soft labels are created equal; they must contain structured, semantically meaningful information to be beneficial. The optimal soft label structure varies with dataset size and is intrinsically linked to the knowledge encoded within those labels. This insight establishes a crucial connection between dataset distillation and knowledge distillation, leading to a potential Pareto frontier where knowledge from an expert model can compensate for a reduced dataset size.
Distillation Methods#
Dataset distillation methods aim to compress large training datasets into smaller, more manageable subsets while preserving model performance. Several categories exist, including meta-model matching, which focuses on aligning the behavior of models trained on the original and distilled datasets. Distribution matching methods emphasize similarity in the output distributions, while trajectory matching techniques aim to replicate the training dynamics. The choice of method depends on the specific application and computational constraints. However, a critical factor often overlooked is the use of soft labels, which are probabilistic class assignments rather than hard, one-hot encodings. These methods demonstrate the importance of label quality, suggesting that structured information within soft labels significantly improves the effectiveness of distillation, potentially outweighing the complexity of generating synthetic images.
Data-Efficient Learning#
Data-efficient learning, a crucial aspect of modern machine learning, seeks to maximize model performance while minimizing the amount of training data required. The research explores this concept through the lens of dataset distillation, focusing on how to compress large datasets into smaller, more manageable counterparts without sacrificing accuracy. A key finding is the pivotal role of soft (probabilistic) labels in achieving data efficiency, surpassing the importance of sophisticated synthetic data generation techniques. The study reveals that soft labels containing structured information are crucial, and that the optimal level of label detail varies depending on the size of the compressed dataset. This leads to the establishment of an empirical Pareto frontier, showcasing the trade-off between data quantity and the quality of knowledge encoded in soft labels. The research further demonstrates a data-knowledge scaling law, highlighting the possibility of achieving high accuracy with minimal data, if the soft labels are optimized for knowledge transfer. These findings challenge conventional wisdom and open up new directions for improving both dataset distillation and the broader field of data-efficient learning.
Distillation Limits#
The heading ‘Distillation Limits’ invites exploration of inherent boundaries in dataset distillation. A key limitation is the difficulty in perfectly capturing the essence of a large dataset within a much smaller distilled version. This limitation stems from the complexity of data, the existence of intricate relationships between data points, and the non-linearity of many machine learning models. Methods focused on generating synthetic data struggle to replicate the subtle nuances and implicit information present in the original dataset. Another limit is the difficulty of identifying truly optimal distillation methods, because distillation performance varies depending on several factors such as the model architecture, the specific dataset, and the evaluation metric. Soft labels, while helpful, are not a universal solution. Their efficacy depends on their informational content and structure. Simply using soft labels doesn’t guarantee successful distillation; the labels themselves must be of high quality and capture informative relationships. Furthermore, the computational cost of generating high-quality synthetic data can be substantial, potentially offsetting the benefits of data reduction. Finally, the scalability to very large datasets (e.g., ImageNet) remains a significant challenge. Existing methods often struggle to effectively distill these datasets without significant performance degradation.
Future Directions#
The study’s “Future Directions” section could productively explore several avenues. Investigating the interplay between image synthesis strategies and soft label generation is crucial, potentially leading to more efficient and effective distillation methods. It’s also important to explore the applicability of soft label techniques beyond image classification, assessing how they might improve data-efficient learning across diverse domains and modalities. The work could also address the challenges of scaling data distillation to massive datasets. Current approaches struggle with larger datasets; advancements are needed for broader adoption. Finally, a deeper examination of the specific types of structured information within soft labels is needed to better understand their impact on learning and develop optimal strategies for creating and leveraging such information. This could involve exploring new methodologies for label generation, especially methods independent of expert models.
More visual insights#
More on figures
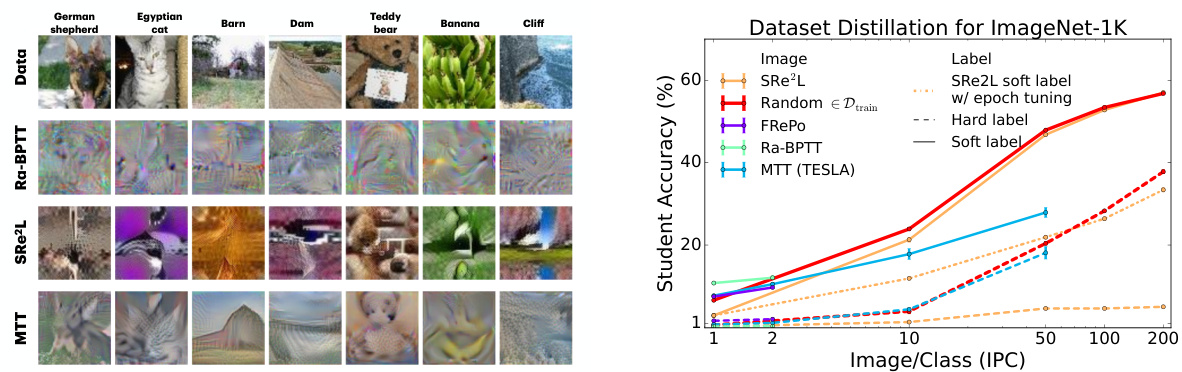
This figure shows the relationship between expert test accuracy, student test accuracy, and the average entropy of soft labels. The left panel demonstrates that student performance improves as expert accuracy increases, indicating that the quality of soft labels is tied to expert performance. The right panel shows that as the average entropy of soft labels decreases, student accuracy initially improves, but then plateaus and eventually decreases at very low entropy values. This suggests there’s an optimal level of entropy, where sufficient uncertainty in the labels aids student learning, but excessive certainty hinders generalization.
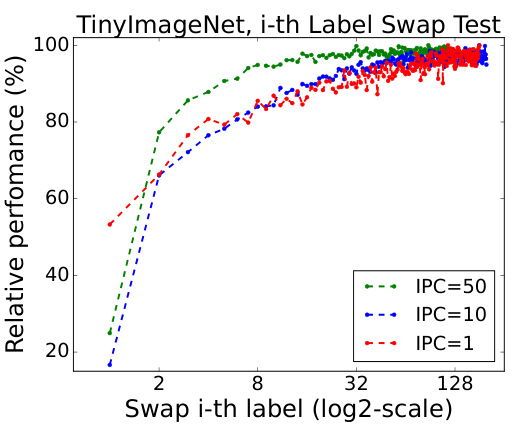
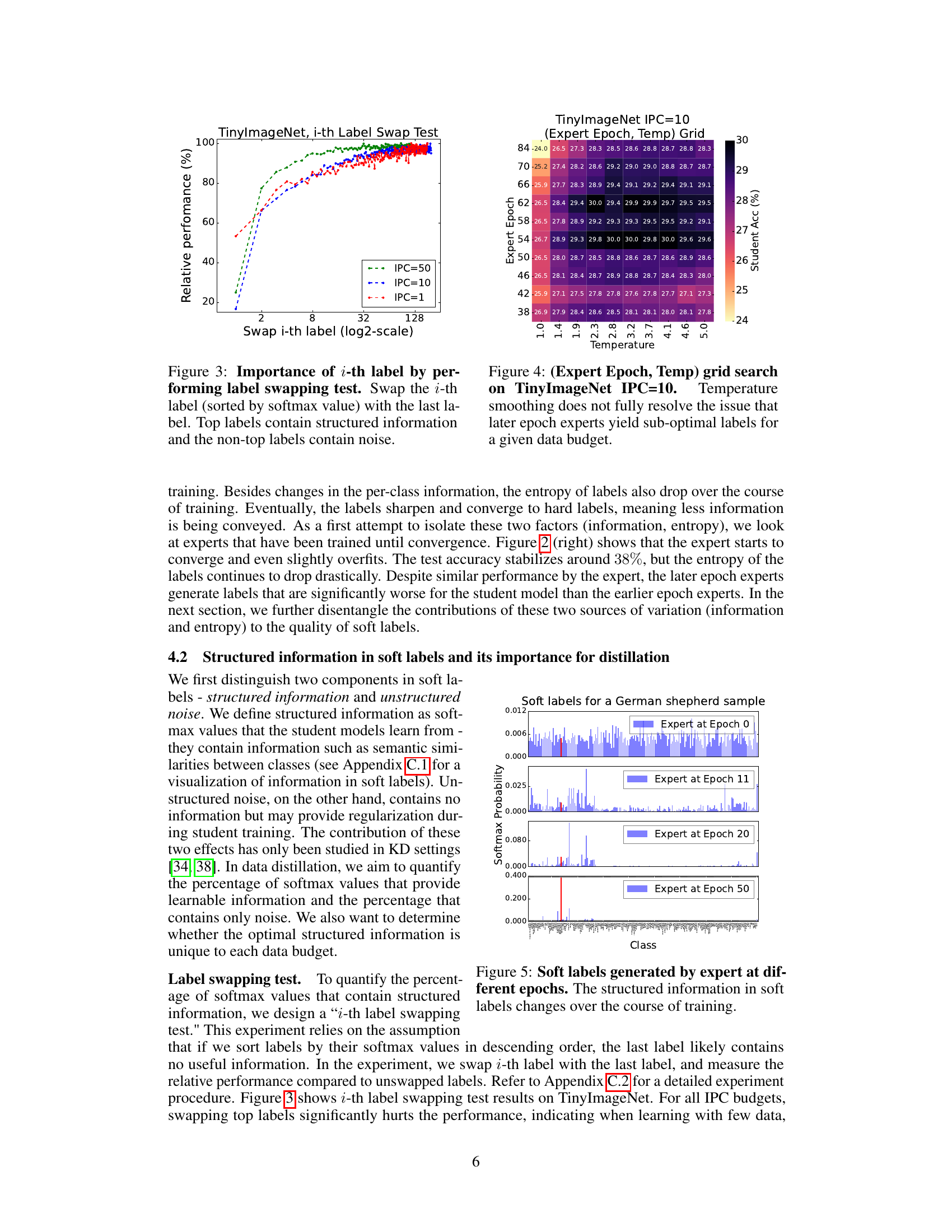
This figure shows the results of an experiment designed to assess the impact of label order on model performance in a dataset distillation setting. Specifically, it shows how swapping the i-th label (ranked by its softmax probability) with the least probable label affects the model’s relative performance. The results across different images-per-class (IPC) budgets (1, 10, 50) demonstrate that the most probable labels carry structured information crucial for model learning, while less probable labels contribute mainly noise.
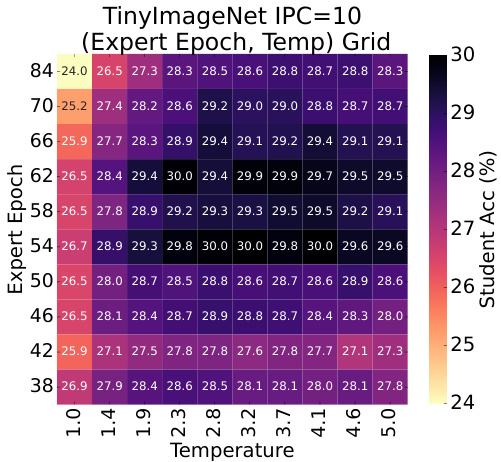
This figure shows the results of a grid search experiment conducted on the TinyImageNet dataset with 10 images per class (IPC=10). The experiment investigated the impact of two hyperparameters: the expert epoch (the training epoch at which the expert model’s predictions are used as soft labels) and the temperature used for softmax probability smoothing. The heatmap displays the student model’s test accuracy for different combinations of expert epoch and temperature. The results indicate that even with temperature smoothing, using soft labels generated from later training epochs (overfit expert) does not necessarily lead to improved student performance, suggesting that label quality is not solely determined by entropy.

This figure shows the soft labels generated by an expert model at different epochs for a single example image (a German Shepherd). It highlights how the probability distribution across classes changes as the expert model trains. Early epochs show a flatter distribution, reflecting less certainty, while later epochs show a sharper distribution, with higher probability assigned to the correct class. This illustrates the concept of structured information evolving within soft labels over the course of training.
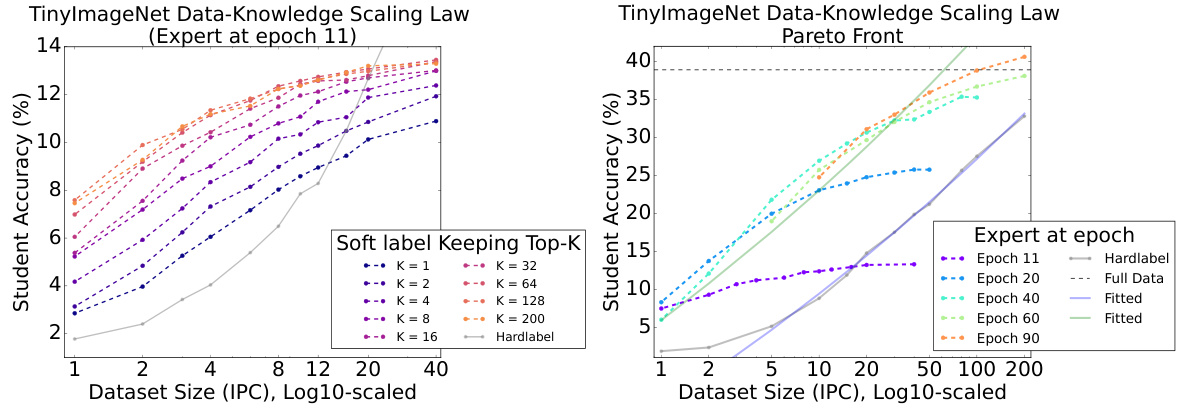
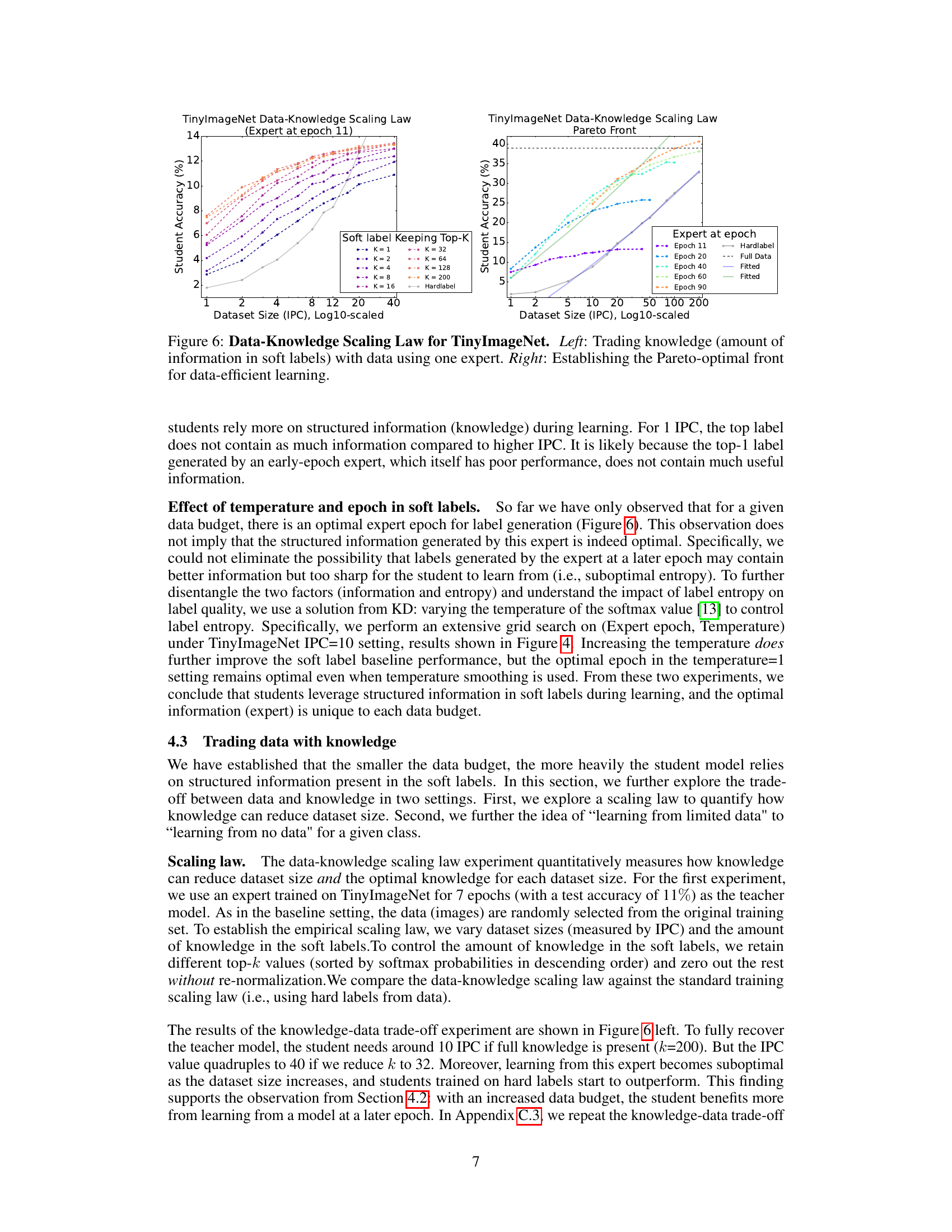
This figure presents two graphs illustrating the trade-off between knowledge (soft labels from an expert model) and data (number of images per class) in achieving good student model accuracy on the TinyImageNet dataset. The left graph shows how, for a given expert model at a specific epoch, using more of the top-ranked soft labels (higher K) allows for improved student accuracy even with smaller datasets. The right graph illustrates the Pareto frontier, displaying the optimal balance between dataset size and student accuracy across multiple expert epochs. Different colors represent different expert epochs, demonstrating that the optimal balance varies depending on the expert’s training stage.
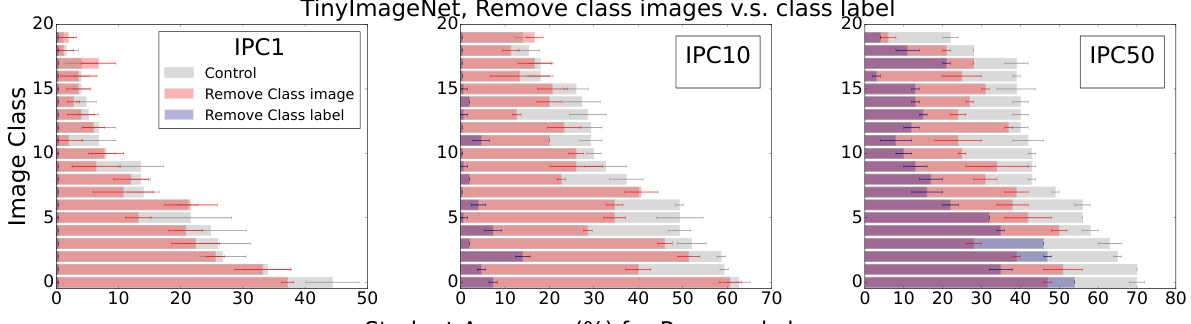
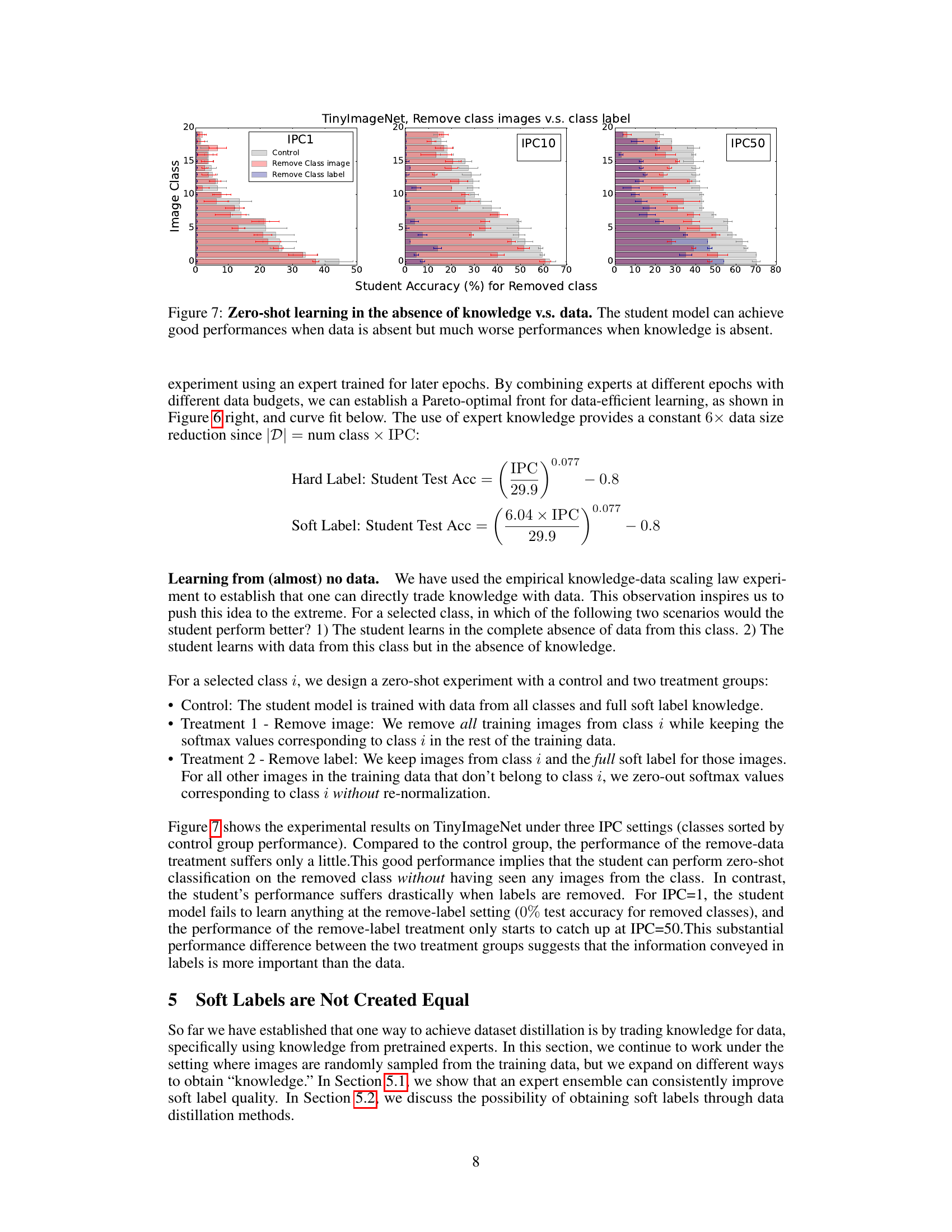
This figure shows the results of a zero-shot learning experiment where either the images or labels for a specific class were removed from the training data. The student model’s performance is compared across three different data budget settings (IPC1, IPC10, and IPC50) under three conditions: (1) a control group where all data and labels are available; (2) a group where images for the target class are removed but the labels for that class are still included in other datapoints; and (3) a group where the labels for the target class are removed but the corresponding images are still included in the training data.The results indicate that the student model can still perform reasonably well when the image data is absent, but its performance severely suffers when class labels are absent. This demonstrates the significance of soft labels in data-efficient learning.
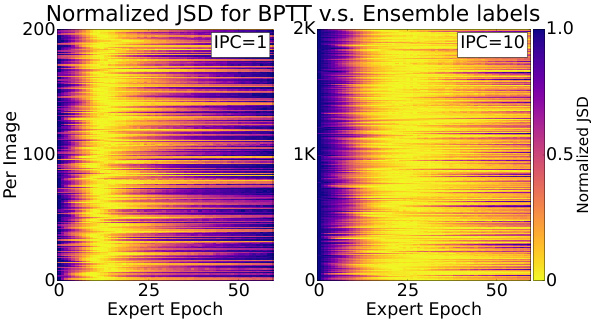
This figure visualizes the Jensen-Shannon Distance (JSD) between soft labels generated by the Back-Propagation Through Time (BPTT) method and those generated by an ensemble of experts on the TinyImageNet dataset. The heatmaps show the normalized JSD for each image across different expert epochs. The results indicate that BPTT, without explicit expert training, produces labels similar to those from early-stopped experts, suggesting that BPTT implicitly captures the same label information.
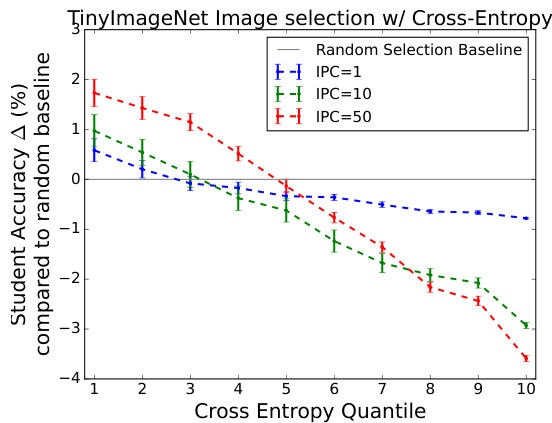
This figure shows the results of an experiment where the authors used cross-entropy to select training images for their soft label baseline method. They divided the training images into ten quantiles based on their cross-entropy scores (lower scores indicating easier samples). The figure plots the change in student test accuracy compared to the random selection baseline for different cross-entropy quantiles and for three different data budgets (images per class, IPC). The results show a small but consistent improvement when selecting the easiest samples (quantile 1), while selecting the hardest samples significantly hurts performance. This suggests that using cross-entropy for image selection, in addition to soft labels, can further boost the performance of the soft label baseline approach.
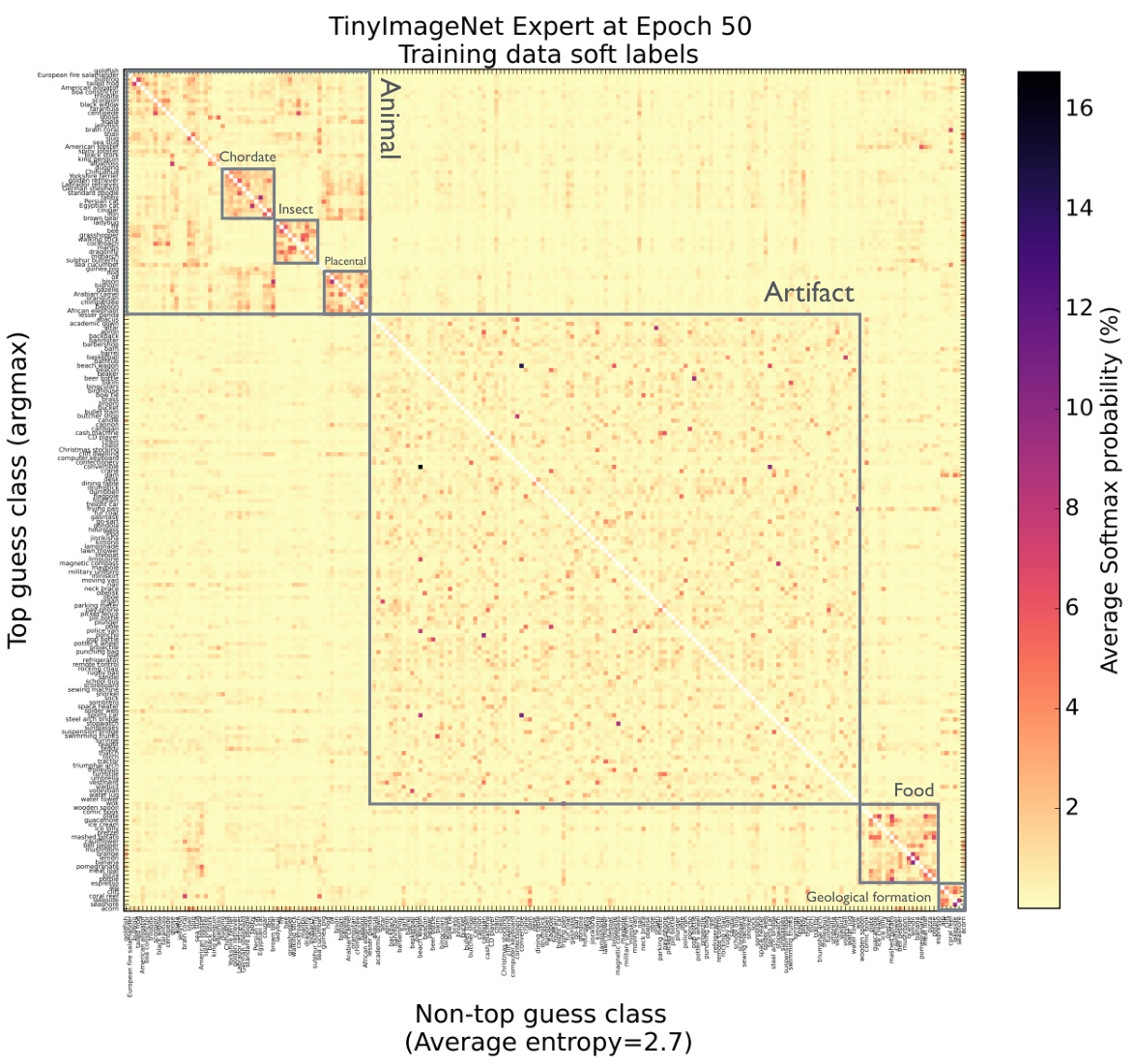
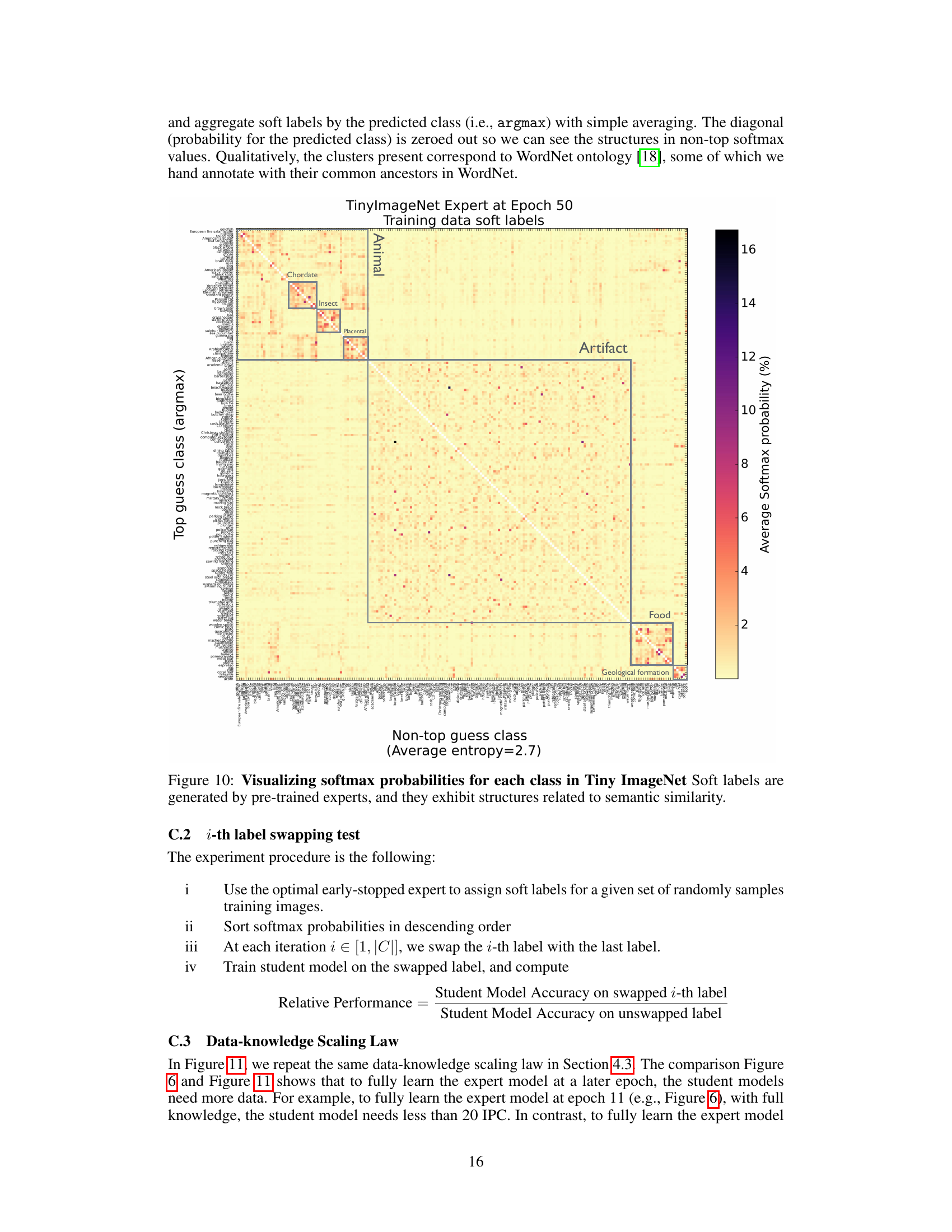
This figure visualizes the soft labels generated by a pre-trained expert model on the TinyImageNet dataset. The heatmap shows the average softmax probabilities for each class, excluding the highest probability class (the diagonal is zeroed out). The resulting visualization highlights clusters of classes with semantic similarities, reflecting relationships between classes as represented in the WordNet ontology. This suggests that the soft labels capture structured semantic information beyond individual class labels, a key finding of the paper.

This figure shows the results of an experiment designed to explore the relationship between the amount of data and the amount of knowledge needed to achieve a certain level of accuracy in a student model. The experiment uses a later-epoch expert (epoch 46) compared to the earlier epoch expert used in Figure 6. The results show that using a later-epoch expert requires significantly more data to achieve the same level of accuracy as using an earlier epoch expert. The data-knowledge scaling law is investigated by varying the size of the dataset (IPC) and the amount of knowledge retained from the expert (top K softmax values). The figure demonstrates a trade-off between data and knowledge, highlighting how additional knowledge can compensate for smaller datasets, but that this compensation diminishes as the dataset size increases.
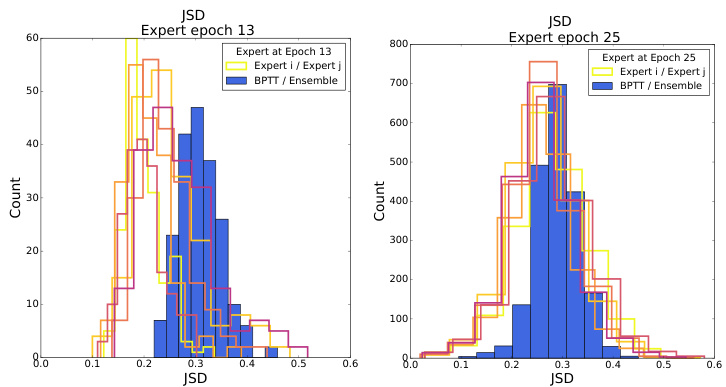
This figure shows the Jensen-Shannon Distance (JSD) between labels generated by the BPTT method and labels generated by an ensemble of experts, for different expert epochs and image counts per class (IPC). The normalized JSD is used to compare the distributions. The results suggest that the BPTT method, without explicitly training experts, is able to recover labels similar to those from early-stopped experts, indicating the information contained in the labels may be a key factor for dataset distillation.
More on tables

This table compares the performance of state-of-the-art (SOTA) data distillation methods with a simple baseline using randomly sampled training images and soft labels. It shows that the baseline, despite its simplicity, achieves comparable performance to the SOTA methods, especially on larger datasets, highlighting the importance of soft labels in dataset distillation.
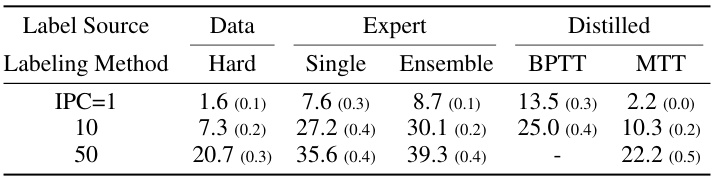
This table compares different label generation strategies on the TinyImageNet dataset. It shows student test accuracy results using hard labels derived directly from the data, soft labels generated by a single expert model, soft labels generated by an ensemble of expert models, soft labels learned using the Back-Propagation Through Time (BPTT) distillation method, and soft labels obtained via the Matching Training Trajectories (MTT) distillation method. The table highlights the improvement in performance achieved by using ensemble soft labels and the effectiveness of using the BPTT method to learn labels.

This table compares the performance of several state-of-the-art (SOTA) dataset distillation methods against a simple baseline that uses randomly sampled images and soft labels (the ‘SI Baseline’). The comparison is done on a downsized version of the ImageNet-1K dataset, with the number of images per class (IPC) limited to 1 or 2. The results show that even a simple baseline using soft labels achieves comparable performance to the SOTA methods, especially when scaling to larger datasets is considered.

This table presents the results of an experiment designed to assess the sensitivity of the soft label baseline to random image selection. The soft label baseline, a method for dataset distillation, involves selecting images randomly from a training dataset and using them with soft labels. The experiment used six different random seeds to select images for the TinyImageNet dataset at three different images-per-class (IPC) values: 1, 10, and 50. The table shows that the student test accuracy remains relatively stable across the different random seeds, indicating that the soft label baseline is robust to random image selection, a key finding in the paper.

This table presents the results of an experiment designed to assess the robustness of the soft label baseline to variations in expert training. Six different expert models were trained, each with a unique random seed. For each expert model, the student model’s performance was evaluated at various image-per-class (IPC) values (1, 10, and 50). The table shows that the student test accuracy remains relatively stable across different expert models, indicating that the soft label baseline is not highly sensitive to variations in the expert training process.
This table benchmarks several state-of-the-art (SOTA) dataset distillation methods against two baselines: a CutMix augmented soft labels baseline and a soft label baseline. The SOTA methods are evaluated on the ImageNet-1K dataset using various image/class (IPC) ratios. The table highlights that the soft label baseline, which uses randomly sampled training images paired with soft labels, achieves performance comparable to more complex SOTA methods. Notably, only SRe2L, among the SOTA methods, scales well to ImageNet-1K.
Full paper#