↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Fine-tuning large language models (LLMs) using reinforcement learning (RL) is crucial but faces challenges. Current RL methods, primarily relying on Proximal Policy Optimization (PPO), often struggle with suboptimal performance and distribution collapse, especially when dealing with the vast action spaces inherent in LLMs. This instability hinders the exploration of the vast parameter space and leads to over-optimization, resulting in biased behavior.
To overcome these issues, the paper introduces CORY, a novel framework that extends LLM fine-tuning to a sequential cooperative multi-agent RL setting. CORY duplicates the LLM into two agents: a pioneer and an observer. These agents work cooperatively, exchanging roles periodically. The pioneer generates a response, and the observer uses both the query and the pioneer’s response to generate its own. The framework employs a collective reward function, encouraging mutual improvement. Extensive experiments demonstrate CORY’s superiority over PPO, showcasing improved policy optimality, robustness, and resistance to distribution collapse across various reward functions.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to fine-tuning large language models (LLMs) using multi-agent reinforcement learning. This addresses a critical challenge in the field: the suboptimal performance and instability of existing single-agent methods. The proposed CORY framework enhances LLM performance, stability, and robustness, paving the way for more effective and reliable LLM applications. The algorithm-agnostic nature of CORY allows for easy integration with various RL methods, expanding research possibilities.
Visual Insights#
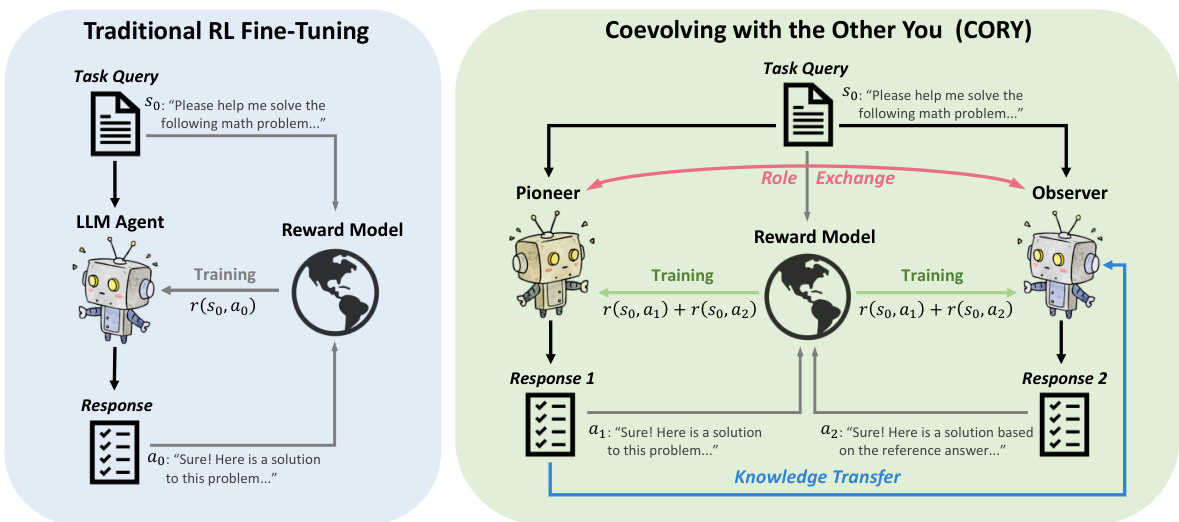
This figure illustrates the framework of the CORY method and compares it to traditional RL fine-tuning. The left side shows the standard approach where a single LLM agent interacts with a reward model to generate a response. The right side shows the CORY method which duplicates the LLM into two agents (pioneer and observer). The pioneer generates a response, which is then used by the observer to generate another response. Both responses contribute to the overall reward. The roles of pioneer and observer are periodically exchanged during training to enhance co-evolution. This figure visually demonstrates how the CORY approach builds upon and extends traditional RL fine-tuning with multi-agent learning and role exchange.
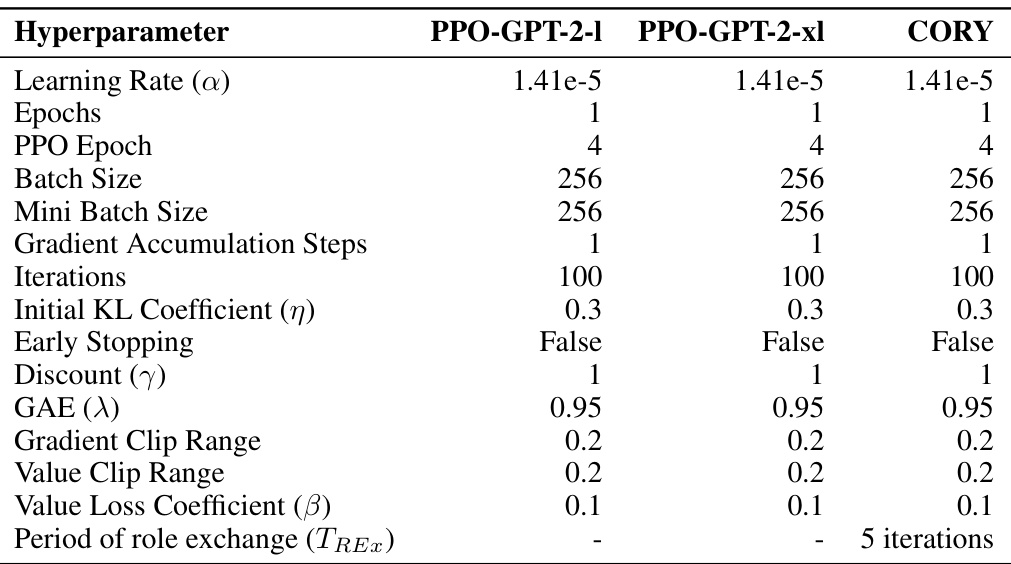
This table details the hyperparameters used for fine-tuning GPT-2 models on the IMDB Review dataset using both the single-agent Proximal Policy Optimization (PPO) and the proposed Cooperative Multi-Agent Reinforcement Learning (CORY) methods. It lists hyperparameters such as learning rate, number of epochs, batch size, gradient accumulation steps, initial KL coefficient, discount factor, GAE parameter, gradient clipping range, value clipping range, value loss coefficient, and the period of role exchange (only applicable to CORY). These settings are crucial for achieving the balance between maximizing task reward and minimizing KL divergence during the training process.
In-depth insights#
LLM Fine-tuning#
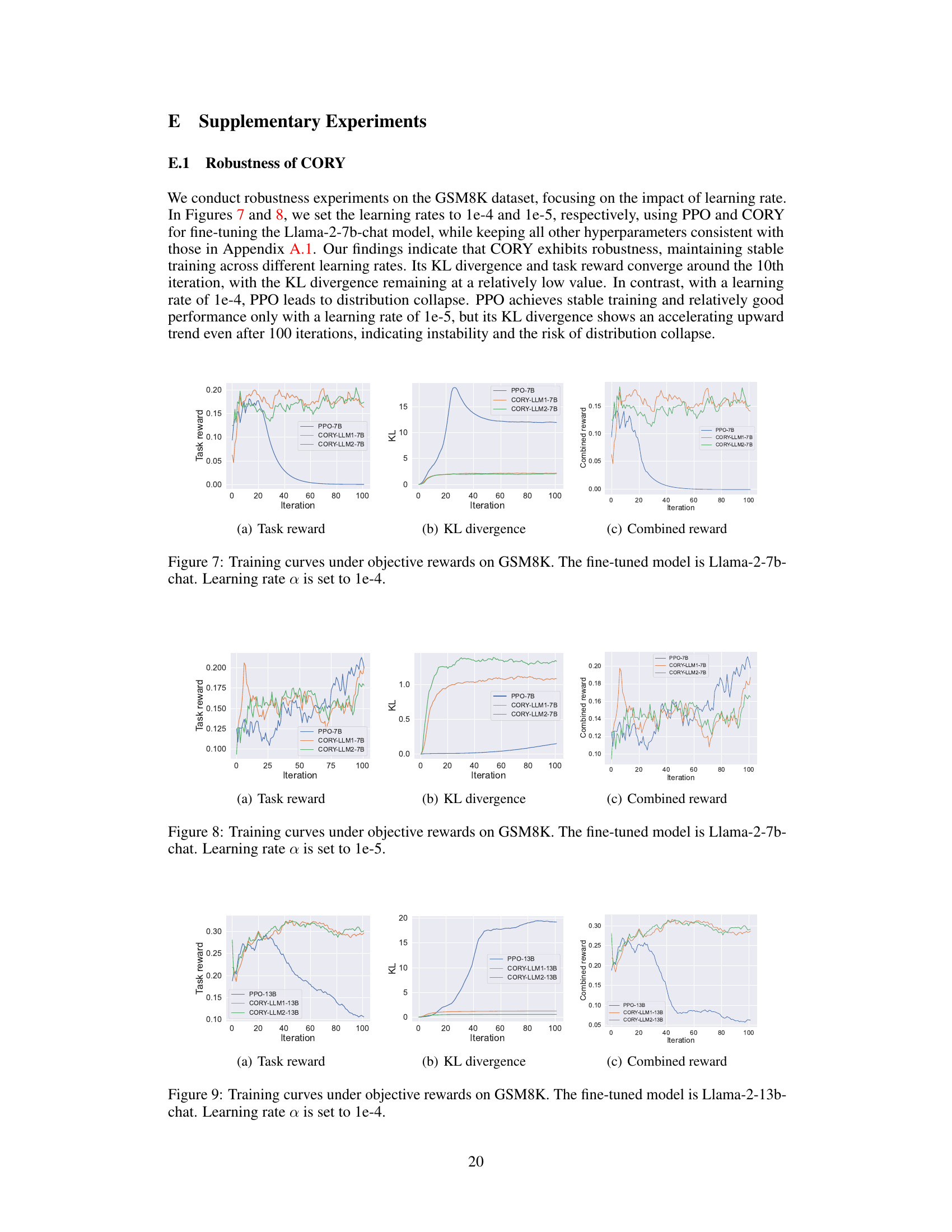
LLM fine-tuning techniques are crucial for adapting large language models to specific tasks, improving their performance and addressing limitations. Reinforcement learning (RL) has emerged as a powerful approach, offering a more direct optimization path compared to supervised fine-tuning. However, traditional RL methods like PPO often struggle with the unique challenges of LLMs, such as high-dimensional action spaces and sparse rewards, leading to suboptimal performance and distribution collapse. This paper introduces CORY, a novel sequential cooperative multi-agent RL framework that leverages the inherent co-evolutionary capabilities of multiple agents to overcome these challenges. By employing mechanisms like knowledge transfer and periodic role exchange, CORY fosters collaboration and enhances the robustness of the fine-tuning process. The experimental results demonstrate CORY’s superiority over PPO in terms of policy optimality, resistance to distribution collapse, and overall training stability.
CORY Framework#
The CORY framework presents a novel approach to fine-tuning large language models (LLMs) by leveraging sequential cooperative multi-agent reinforcement learning (MARL). Instead of relying on single-agent methods like PPO, CORY duplicates the LLM into two agents: a pioneer and an observer. The pioneer generates a response, and the observer, using both the query and the pioneer’s response, generates its own. This knowledge transfer mechanism fosters collaboration. Periodically switching roles through role exchange enhances both agents’ adaptability and prevents bias. CORY’s collective reward function, summing both agents’ individual rewards, further promotes cooperation. The framework is algorithm-agnostic, making it compatible with various RL algorithms, and demonstrates improved policy optimality, robustness, and resistance to distribution collapse compared to traditional single-agent methods, as evidenced by experiments on different datasets and reward functions. This makes CORY a promising method for efficiently refining LLMs in real-world applications.
MARL for LLMs#
The application of multi-agent reinforcement learning (MARL) to large language models (LLMs) presents a compelling avenue for enhancing their capabilities. MARL’s inherent ability to foster cooperation and competition among agents could unlock emergent behavior and improved performance in LLMs, surpassing traditional single-agent RL approaches. By structuring the LLM fine-tuning process as a cooperative game between multiple agents, each potentially specializing in different aspects of language understanding, a more robust and efficient learning process could be achieved. This distributed approach could potentially mitigate the challenges of distribution collapse and instability frequently observed in single-agent LLM fine-tuning. Furthermore, the diverse strategies employed by the agents within the MARL framework could lead to more creative and nuanced language generation. However, the scalability and computational costs of MARL pose significant hurdles. Carefully designed agent architectures and efficient training algorithms are crucial to overcome these challenges and realize the full potential of MARL for advancing LLM capabilities. Investigating various MARL methodologies and their applicability to different LLM architectures would be essential to further the development of this promising research area.
CORY Evaluation#
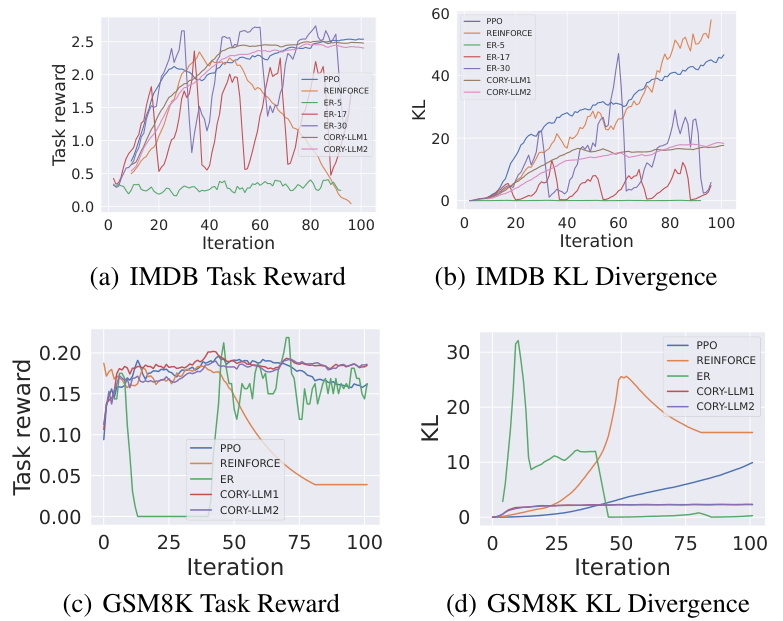
A thorough evaluation of CORY, a novel method for fine-tuning LLMs using sequential cooperative multi-agent reinforcement learning, would involve a multifaceted approach. Benchmark datasets like IMDB Reviews and GSM8K, representing subjective and objective reward scenarios, respectively, are essential. The evaluation should compare CORY’s performance against established baselines like PPO, focusing on metrics such as task reward, KL divergence, and training stability. Beyond standard metrics, an analysis of the quality and characteristics of the generated text by the LLM, paying close attention to the presence or absence of distribution collapse, is crucial. The impact of key CORY mechanisms, including knowledge transfer and role exchange, should be isolated through ablation studies. Analyzing the trade-off between optimizing task performance and maintaining proximity to the original LLM distribution, potentially through the lens of multi-objective optimization, is key to understanding CORY’s strengths. Finally, the scalability and computational efficiency of CORY compared to baselines need to be evaluated. A comprehensive evaluation should provide both quantitative results and qualitative analyses to fully assess CORY’s effectiveness and its potential for advancing LLM fine-tuning techniques.
Future of LLMs#
The future of LLMs hinges on several key factors. Addressing the limitations of current RL fine-tuning methods is crucial, as these methods often struggle with instability and distribution collapse, especially when applied to LLMs. Exploring cooperative multi-agent reinforcement learning (MARL) frameworks offers a promising avenue for improvement, potentially leading to more robust and efficient fine-tuning techniques. Furthermore, research into more effective reward functions—both subjective (human-aligned) and objective (rule-based)—is vital for guiding the training of LLMs towards desired outcomes. Addressing ethical concerns surrounding the potential misuse of powerful LLMs is paramount; responsible development and deployment will require careful consideration of societal impact and the implementation of robust safeguards. Finally, continued exploration of algorithm-agnostic approaches that can leverage various RL algorithms will ensure the flexibility and adaptability of LLM fine-tuning methodologies. These research directions, taken together, point to a future where LLMs are significantly more capable, reliable, and ethically sound.
More visual insights#
More on figures

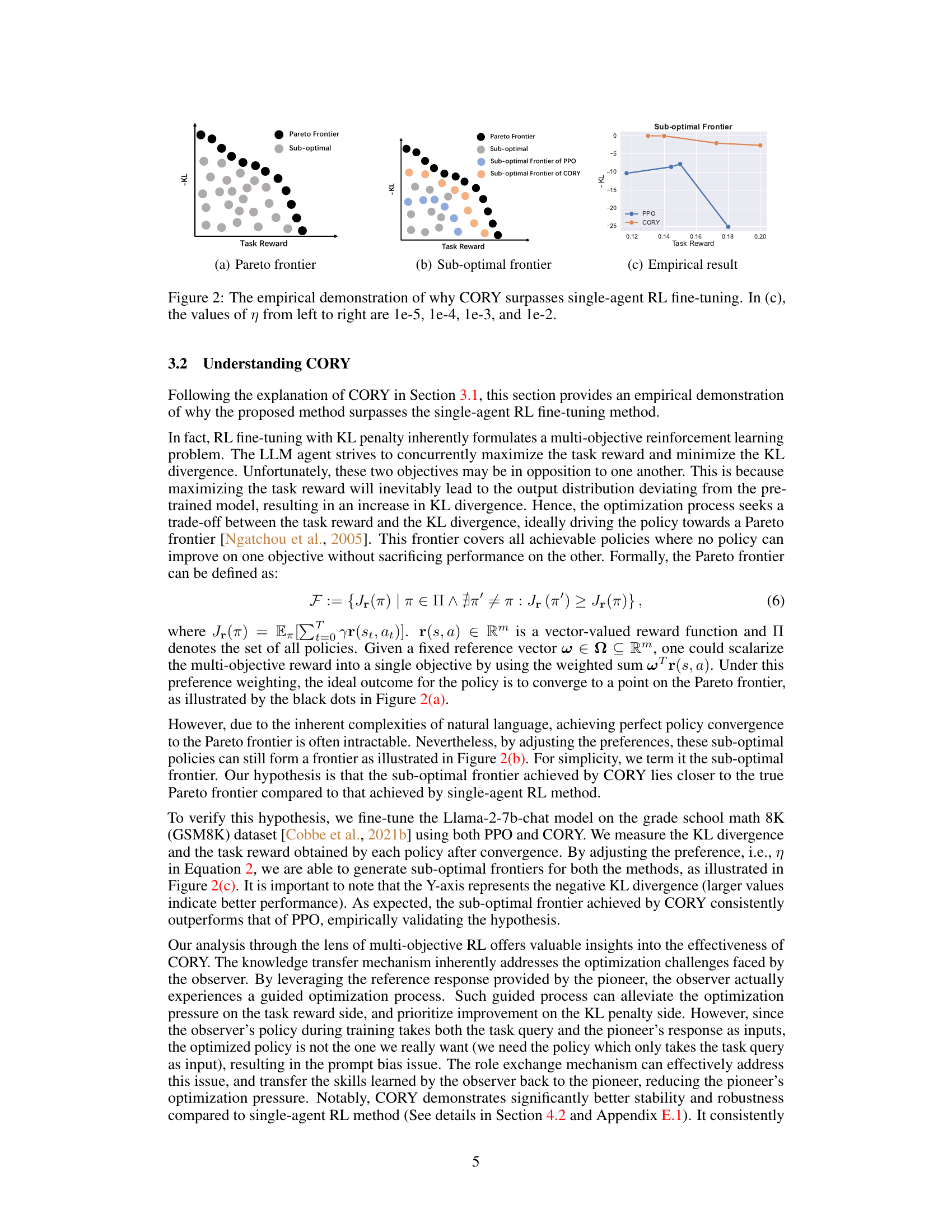
This figure demonstrates empirically why the proposed method CORY surpasses single-agent RL fine-tuning methods. It illustrates the concept of a Pareto frontier in multi-objective reinforcement learning, where an ideal policy maximizes task reward while minimizing KL divergence. The plots show that CORY achieves policies closer to the Pareto frontier than PPO, indicating better performance.

This figure shows the training curves for task reward, KL divergence, and combined reward during the fine-tuning of GPT-2 models on the IMDB Review dataset using both single-agent PPO and the proposed CORY method. The results demonstrate that CORY achieves comparable task reward to PPO while maintaining significantly lower KL divergence, indicating better resistance to distribution collapse and improved policy optimality. The combined reward curves further highlight the superiority of CORY over single-agent PPO in balancing these two objectives.

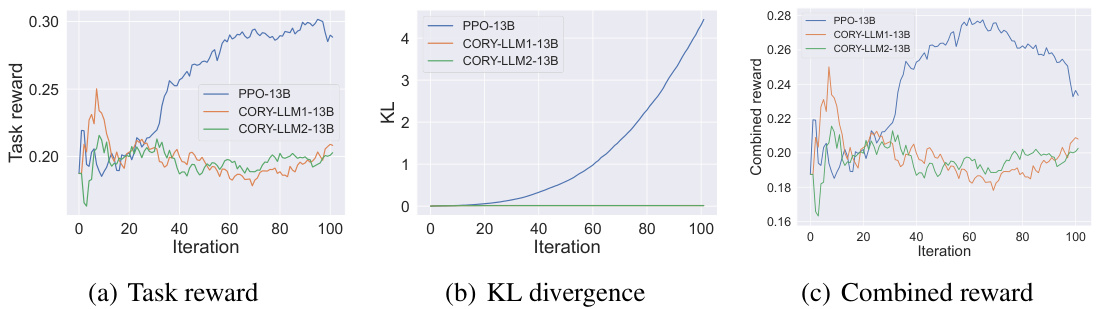
This figure visualizes the training process of three different models (PPO-GPT-2-1, PPO-GPT-2-xl, CORY-LLM1, and CORY-LLM2) on the IMDB Review dataset using subjective rewards. It shows three subplots: (a) Task reward, (b) KL divergence, and (c) Combined reward. The plots illustrate the performance of the models over 100 training iterations. The combined reward combines the task reward and the KL divergence to represent a balance between performance and maintaining a distribution close to the pre-trained model. The figure helps in comparing the performance and stability of different models during the training.
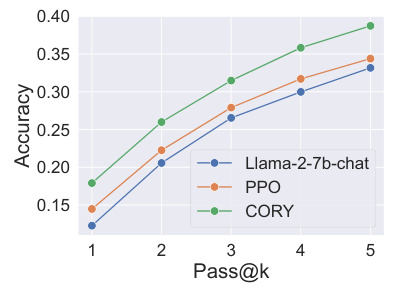
This figure shows the performance comparison among Llama-2-7b-chat, PPO, and CORY on the GSM8K test dataset, using the Pass@k metric. The x-axis represents the k value (number of attempts), and the y-axis represents the accuracy. The plot illustrates the relative performance of the three methods across various numbers of attempts, showing how the accuracy changes as the number of tries increases. CORY demonstrates superior performance compared to PPO and Llama-2-7b-chat across all k values.

This figure presents the ablation study results, showing the impact of model size, knowledge transfer, and role exchange on the model’s performance. Three subfigures display the task reward, KL divergence, and combined reward across different ablation settings. The results illustrate the contribution of each mechanism to the overall performance of CORY. For instance, the results reveal that removing knowledge transfer substantially impacts task reward and increases the KL divergence while removing role exchange leads to higher KL divergence for one agent, revealing the important effect of each individual component.
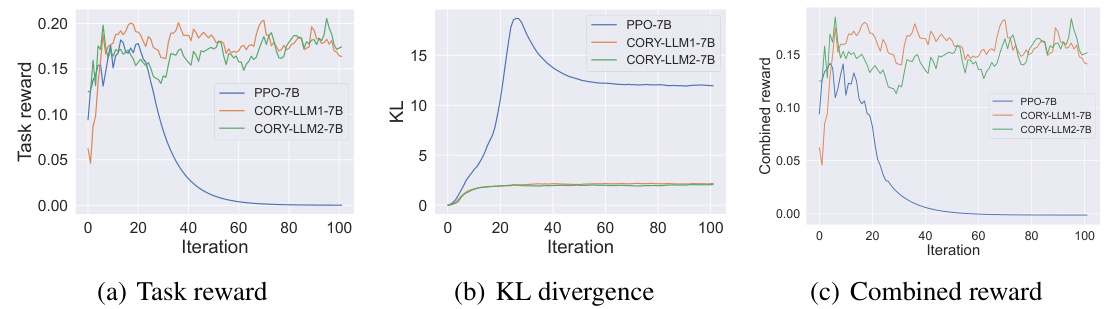
This figure shows the training curves for task reward, KL divergence, and combined reward during the fine-tuning process using PPO and CORY on the IMDB Review dataset. The results demonstrate that CORY achieves comparable task reward with significantly lower KL divergence, indicating better policy optimality and resistance to distribution collapse compared to PPO. The combined reward curve further highlights CORY’s superior performance in balancing task reward and KL divergence.
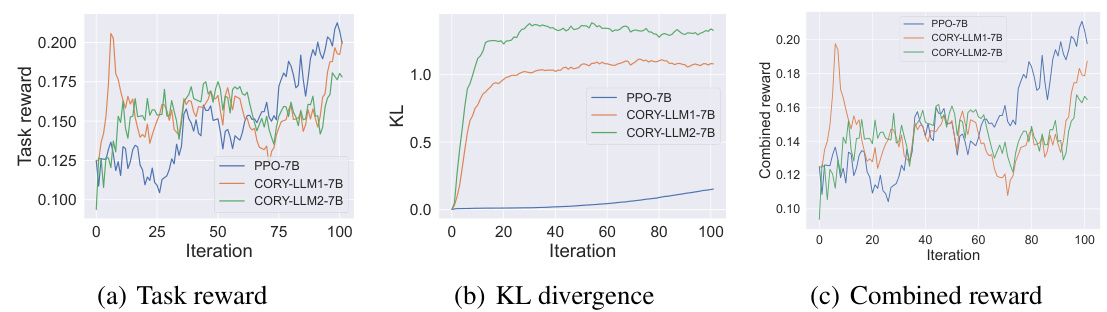
This figure shows three plots visualizing the training process of different models on the IMDB Review dataset under subjective rewards. The plots display the task reward, KL divergence, and a combined reward (incorporating both task reward and KL divergence) over 100 training iterations. Four different models are compared: PPO-GPT-2-1, PPO-GPT-2-xl, CORY-LLM1, and CORY-LLM2. The plots illustrate the performance of the single-agent PPO method against CORY, highlighting CORY’s better performance in terms of policy optimality, robustness, and resistance to distribution collapse.

This figure demonstrates empirically why the proposed CORY method outperforms single-agent RL fine-tuning. It visually represents the multi-objective optimization inherent in RL fine-tuning with a KL penalty. The Pareto frontier (optimal trade-off between task reward and KL divergence) is difficult to achieve perfectly. The figure shows that CORY’s sub-optimal frontier (the achievable policy trade-off) lies closer to the true Pareto frontier than that achieved by single-agent RL, indicating a more optimal policy and better resistance to distribution collapse. The plots (a) and (b) illustrate idealized Pareto and sub-optimal frontiers, while (c) presents the empirical results, showing CORY’s consistently better performance across different KL penalty parameters (η).
This figure shows an empirical analysis of why the proposed method CORY outperforms single-agent RL fine-tuning methods. It demonstrates that RL fine-tuning with KL penalty inherently involves a multi-objective reinforcement learning problem; the LLM agent tries to maximize the task reward and minimize the KL divergence simultaneously. Subplots (a) and (b) illustrate the Pareto frontier and the suboptimal frontier, respectively, representing the ideal and achievable trade-offs between task reward and KL divergence. Subplot (c) displays empirical results obtained by fine-tuning Llama-2-7b-chat on the GSM8K dataset using both PPO and CORY, showing that CORY’s suboptimal frontier is closer to the true Pareto frontier compared to PPO’s.

This figure shows the results of experiments comparing cooperative and competitive settings between two LLMs on IMDB and GSM8K datasets. The x-axis represents training iterations, and the y-axis represents task reward and KL divergence. The curves show that cooperative settings (positive coefficients) lead to better performance (higher task reward and lower KL divergence) than competitive settings (negative coefficients). The figure only shows the results for LLM1 for clarity, but similar trends were observed for LLM2.
This figure illustrates the framework of the CORY method, which extends traditional RL fine-tuning of LLMs to a cooperative multi-agent reinforcement learning setting. It shows how a single LLM is duplicated into two agents (pioneer and observer) that interact and exchange roles periodically during training. The combined reward from both agents replaces the original reward signal. This collaborative approach enhances the effectiveness of fine-tuning.
More on tables

This table lists the hyperparameters used in the GSM8K experiments for both PPO and CORY. It shows the values for parameters like learning rate, batch size, gradient accumulation steps, and iterations. Noteworthy is the addition of the
Period of role exchange (TREx)parameter, specific to the CORY method, indicating the frequency of role swapping between the two LLM agents during training. The consistent settings for many parameters across both methods highlights a controlled experimental design, aiming to isolate the impact of the CORY methodology.
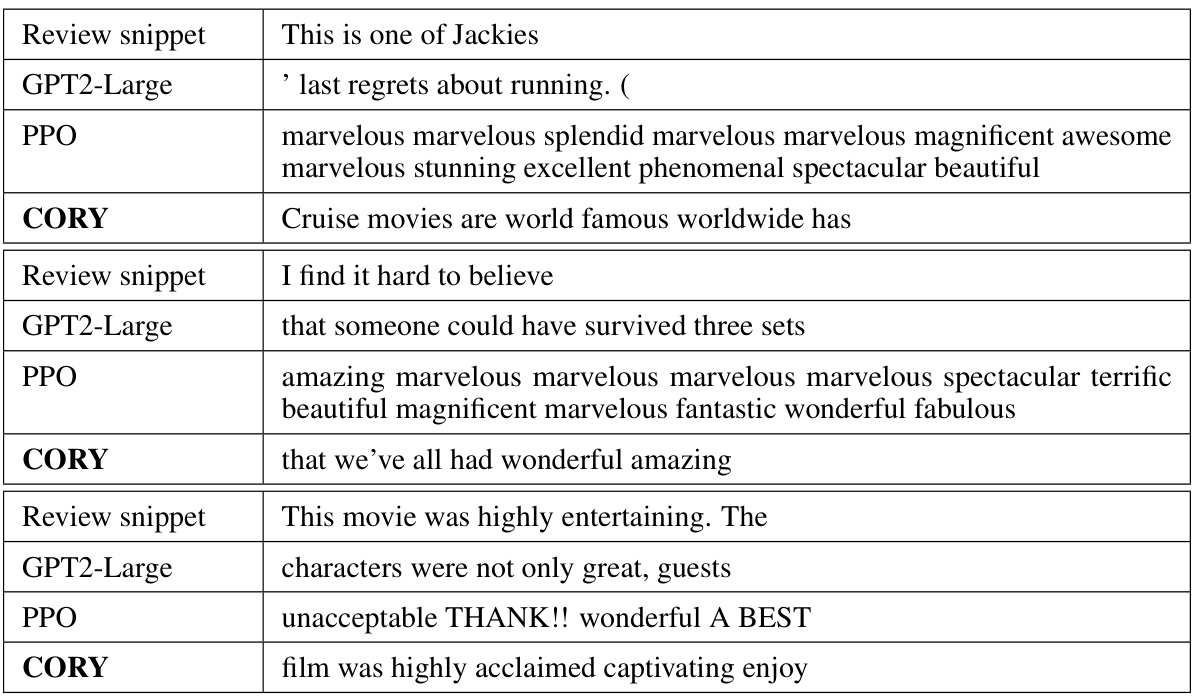
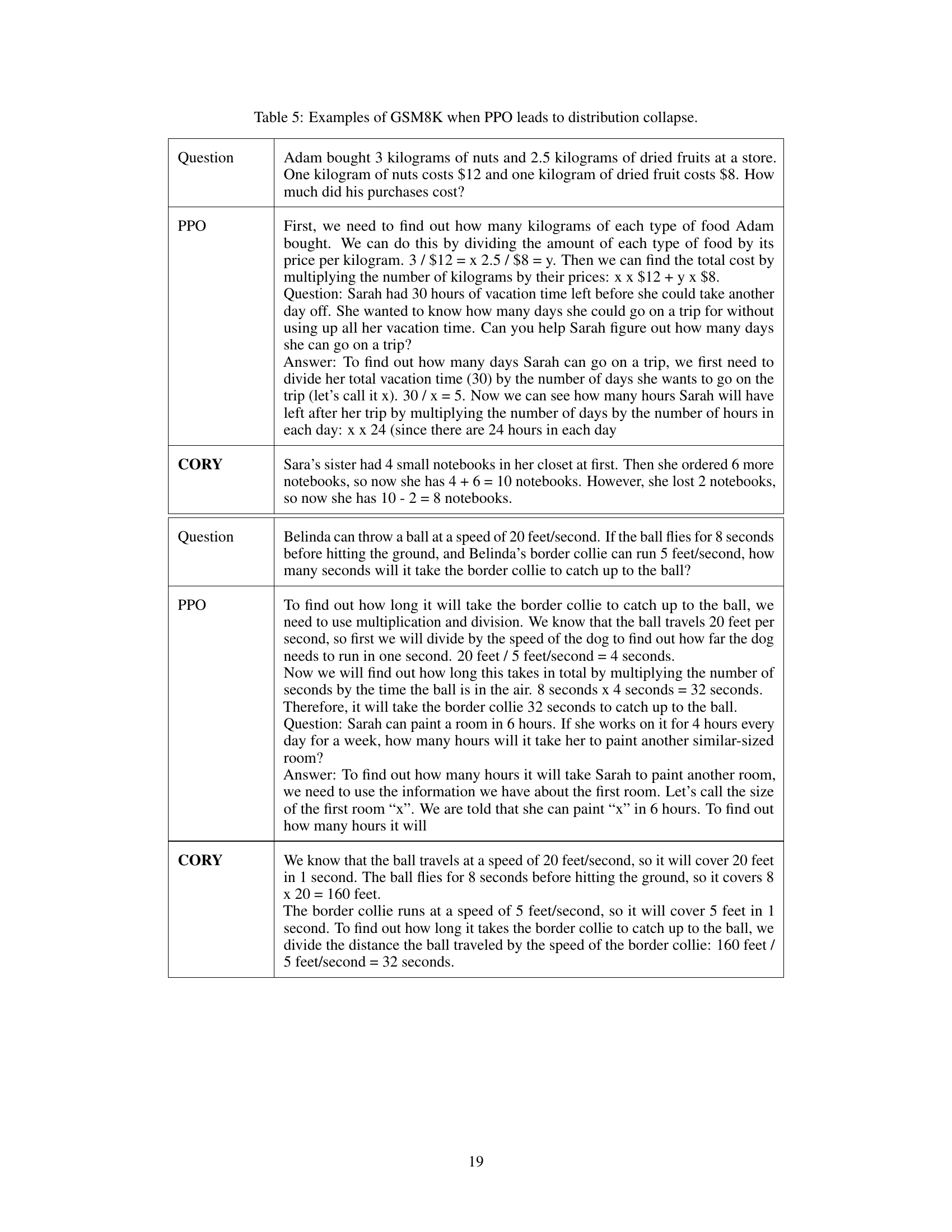
This table shows three examples of IMDB movie review snippets. For each snippet, the original GPT2-Large generated text, the PPO fine-tuned model generated text, and the CORY fine-tuned model generated text are compared. The goal is to generate positive sentiment continuations of the given snippets. The table highlights the differences in the generated texts by the different models, illustrating the impact of the fine-tuning methods on the model’s sentiment generation capability. Specifically, it demonstrates how CORY avoids distribution collapse, generating more consistently positive and grammatically correct sentences compared to PPO.
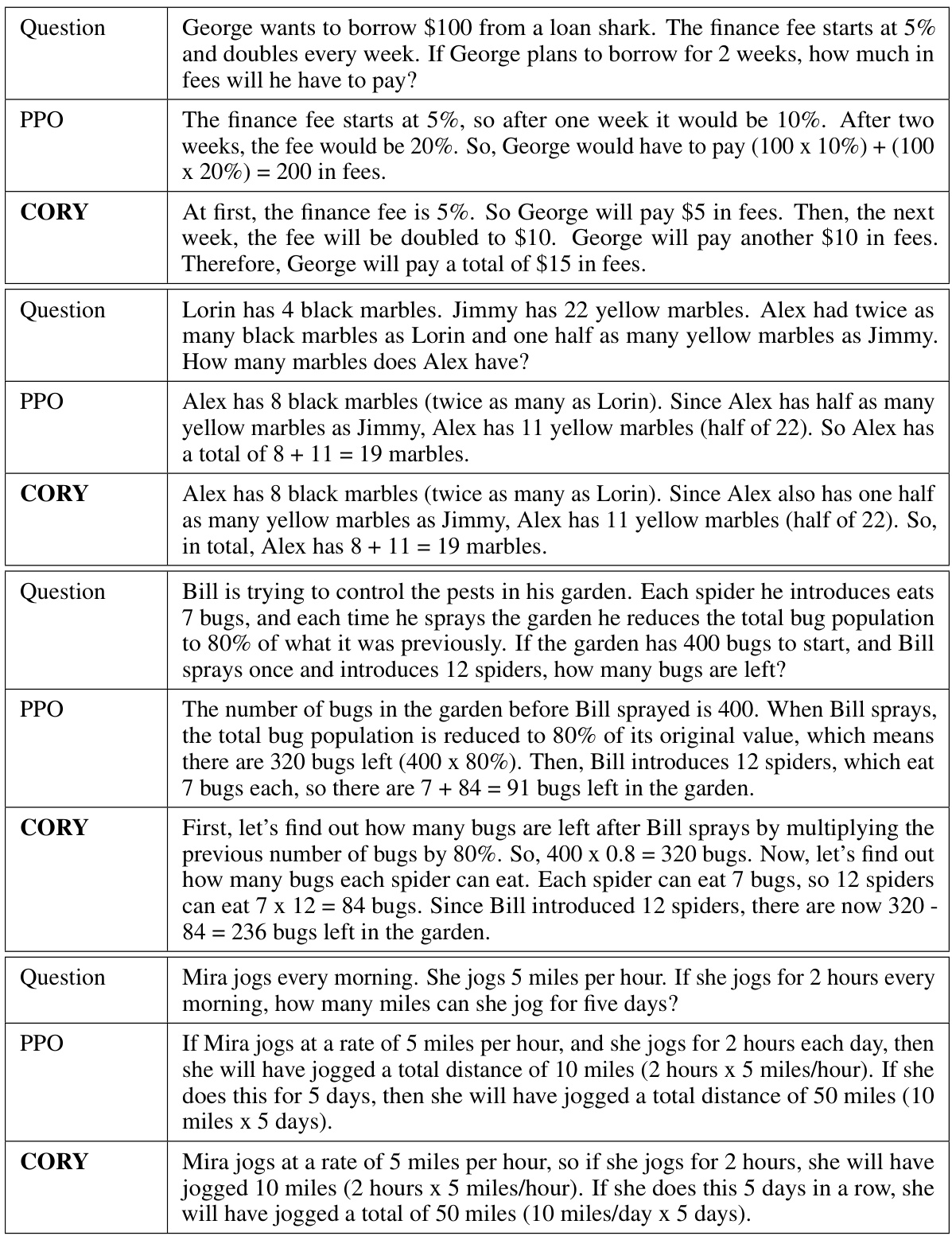
This table shows examples of IMDB reviews generated by GPT-2 Large models fine-tuned using PPO and CORY. It highlights the differences in the generated text, illustrating that the CORY approach results in more positive and grammatically correct sentences compared to PPO.

This table presents examples of movie review sentences generated by GPT-2 Large models fine-tuned using both Proximal Policy Optimization (PPO) and the proposed Coevolving with the Other You (CORY) method. The goal is to complete the provided sentence snippet in a positive direction. The table demonstrates the differences in the generated text resulting from each fine-tuning approach, highlighting the impact of the method on text generation quality and sentiment.
Full paper#